块并用不同的线程分别处理每个数据块的流。这样一来,你就可以自动把给定操作的工作负荷分配给多核处理器的所有内核,让它们都忙起来。让我们用一个简单的例子来试验一下这个思想。假设你需要写一个方法,接受数字n作为参数,并返回从1到给定参数的所有数字的和。一个直接(也许有点土)的方法是生成一个无穷大的数字流,把它限制到给定的数目,然后用对两个数字求和的Binaryoperator来归约这个流,如下所示:限制到前n个数生成自然数无限流
public static long sequentialSum(longn)(return Stream.iterate1,i->i+1}.limit(n)对所有数字求.reduce(0L,Long::sum);和来归纳流
用更为传统的Java术语来说,这段代码与下面的选代等价:
public static long iterativeSum(long n){long result=0:for (long i=lLii<= ni i++){
result += ii
return result;这似乎是利用并行处理的好机会,特别是很大的时候。那怎么人手呢?你要对结果变量进行同步吗?用多少个线程呢?谁负责生成数呢?谁来做加法呢?根本用不着担心啦。用并行流的话,这问题就简单多了!
7.1.1 将顺序流转换为并行流
你可以把流转换成并行流,从而让前面的函数归约过程(也就是求和)并行运行--对顺序流调用para1le1方法:
public static long parallelSum(long n){return Stream.iterate(lL,i->i+1)limit(n)
parallel()//将流转换为并行流
reduce(0L,Long::sum);
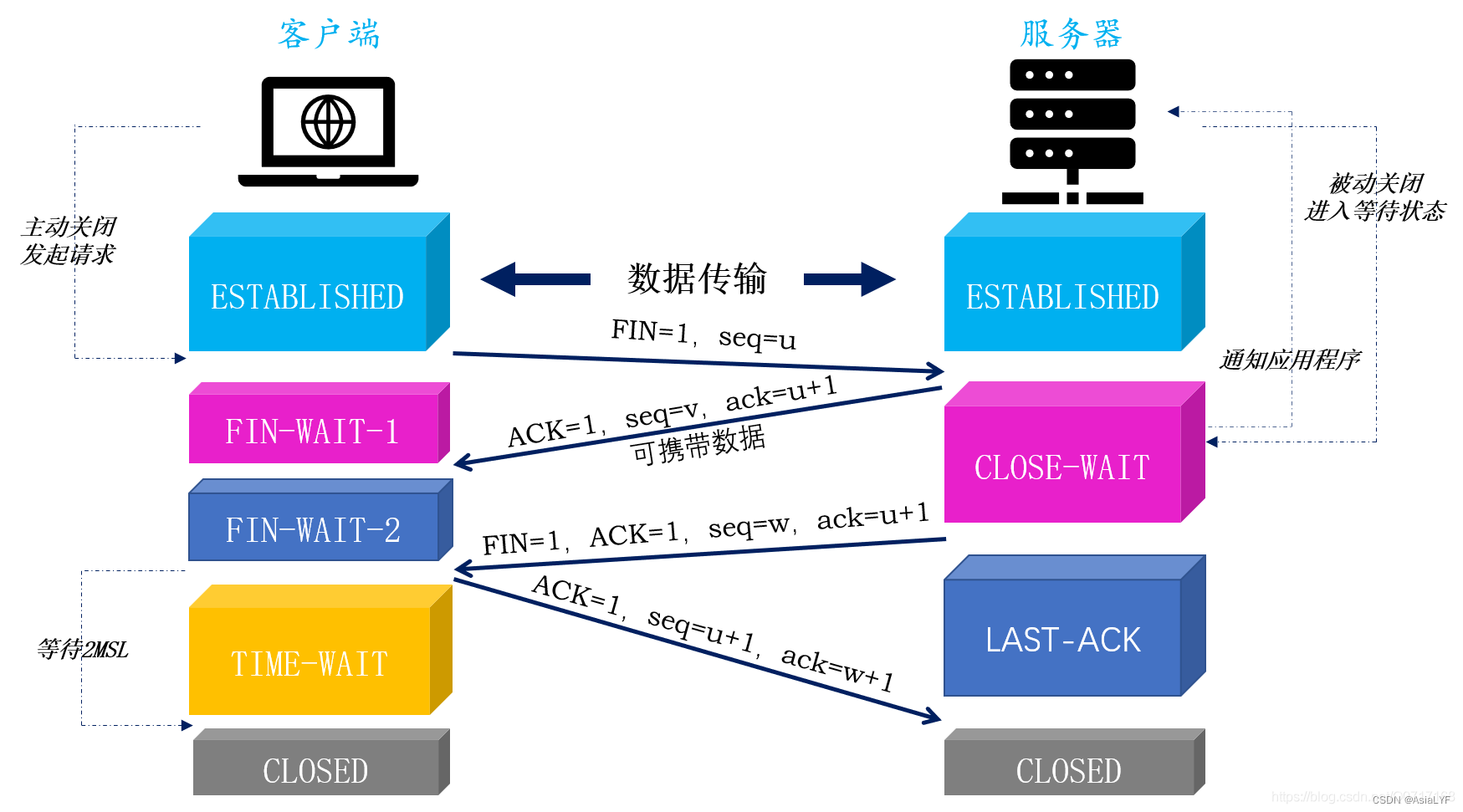
在上面的代码中,对流中所有数字求和的归纳过程的执行方式和5.4.1节中说的差不多。不同之处在于stream在内部分成了几块。因此可以对不同的块独立并行进行归纳操作,如图7-1所示最后,同一个归纳操作会将各个子流的部分归纳结果合并起来,得到整个原始流的归纳结果。
7.1.4 高效使用并行流
一般而言,想给出任何关于什么时候该用并行流的定量建议都是不可能也毫无意义的,因为任何类似于“仅当至少有一千个(或一百万个或随便什么数字)元素的时候才用并行流 )”的建议对于某台特定机器上的某个特定操作可能是对的,但在略有差异的另一种情况下可能就是大错特错。尽管如此,我们至少可以提出一些定性意见,帮你决定某个特定情况下是否有必要使用并行流。
口如果有疑问,测量。把顺序流转成并行流轻而易举,但却不一定是好事。我们在本节中已经指出,并行流并不总是比顺序流快。此外,并行流有时候会和你的直觉不一致,所以在考虑选择顺序流还是并行流时,第一个也是最重要的建议就是用适当的基准来检查其性能。
口留意装箱。自动装箱和拆箱操作会大大降低性能。Java8中有原始类型流(Intstream、Longstream、Doublestream)来避免这种操作,但凡有可能都应该用这些流。口有些操作本身在并行流上的性能就比顺序流差。特别是1imit和finaFirst等依赖于元素顺序的操作,它们在并行流上执行的代价非常大。例如,findany会比findFirst性能好,因为它不一定要按顺序来执行。你总是可以调用unorderea方法来把有序流变成无序流。那么,如果你需要流中的n个元素而不是专门要前n个的话,对无序并行流调用1imit可能会比单个有序流(比如数据源是一个List)更高效。口还要考虑流的操作流水线的总计算成本。设是要处理的元素的总数,Q是一个元素通过流水线的大致处理成本,则N*Q就是这个对成本的一个粗略的定性估计。Q值较高就意味着使用并行流时性能好的可能性比较大。
口对于较小的数据量,选择并行流几乎从来都不是一个好的决定。并行处理少数几个元素的好处还抵不上并行化造成的额外开销。
口要考虑流背后的数据结构是否易于分解。例如,rrayList的拆分效率比LinkeaList高得多,因为前者用不着遍历就可以平均拆分,而后者则必须遍历。
方法创建的原始类型流也可以快速分解。最后,你将在7.3节中学到,你可以自己实现Spliterator来完全掌控分解过程。
口流自身的特点,以及流水线中的中间操作修改流的方式,都可能会改变分解过程的性能。例如,一个SIZED流可以分成大小相等的两部分,这样每个部分都可以比较高效地并行处理,但筛选操作可能丢弃的元素个数却无法预测,导致流本身的大小未知。口还要考虑终端操作中合并步骤的代价是大是小(例如co11ector中的combiner方法)如果这一步代价很大,那么组合每个子流产生的部分结果所付出的代价就可能会超出通过并行流得到的性能提升。
表7-1按照可分解性总结了一些流数据源适不适于并行。