1.概述
前面我们介绍了内核态线性地址空间划分,及在内核态运行时,如何利用伙伴系统完成连续可用物理页框申请和释放。如何利用小块内存分配器实现高效的动态内存分配和释放。如何利用vmalloc,vfree完成线性地址连续但物理地址不连续的多个页框的分配和释放。
这里,我们介绍用户态线性地址空间划分,及在用户态运行时,如何通过mmap来获得和释放用户态线性地址空间,用户态分配的线性地址空间要正常访问,必然得通过页表关联到物理页,这个过程一般放在后续访问节点触发得缺页异常处理中完成。更复杂的是,用户态线性地址空间虽然关联了物理页,视mmap映射到内存还是文件,关联到文件时,还需和文件的区域建立关联。同时,无论映射到内存还是文件,又可区分为私有映射,共享映射。这会使得用户态线性区的管理会比内核态更复杂。我们将在这里分析其运行原理。
2.用户态线性地址空间

整体上看每个进程的用户态线性地址空间将由以上几个固定部分组成。
(1). 代码段
映射到可执行程序文件中代码段部分。可执行文件中代码位于此部分。
(2). 数据段
映射到可执行程序文件中数据段部分。可执行文件中已经初始化的全局和静态数据放在这里。
(3). BSS段
建立此映射用于在这里放置可执行文件中未初始化的全局和静态变量。这些变量在文件中不占空间。但加载程序运行时,需为其分配线性空间一般程序中访问。分配的空间一般采用置0来进行初始化。
(4). 用户态的动态内存申请和释放一般通过c库提供的malloc和free来进行
malloc,free中针对堆部分空间进行管理,完成空间分配和释放。
堆这个部分一般是尺寸可变的,其尾端可以变大实现堆扩展,收缩实现堆区域收缩。
(5). 映射区域
我们可执行程序中用到的动态库,每个动态库被加载时加载程序通过mmap获得线性区域来放置其代码段,数据段,BBS段。我们代码逻辑中可通过mmap建立文件映射实现文件访问,我们代码逻辑中可通过mmap建立匿名映射实现大段线性空间申请,这些操作都将在这部分进行。
(6). 用户态栈
进程在用户态运行时,有自己的栈来存储临时数据。进程启动运行时的启动参数,环境变量也存储在这部分。
值得注意的是,无论针对64位还是32位系统,其用户态线性区域均由上述各个部分组成。只是,64为下用户态线性空间尺寸一般为:
2
47
B
2^{47}B
247B,32位下一般为:
3
G
B
3GB
3GB
3.用户态线性地址空间的两种布局
3.1.经典布局
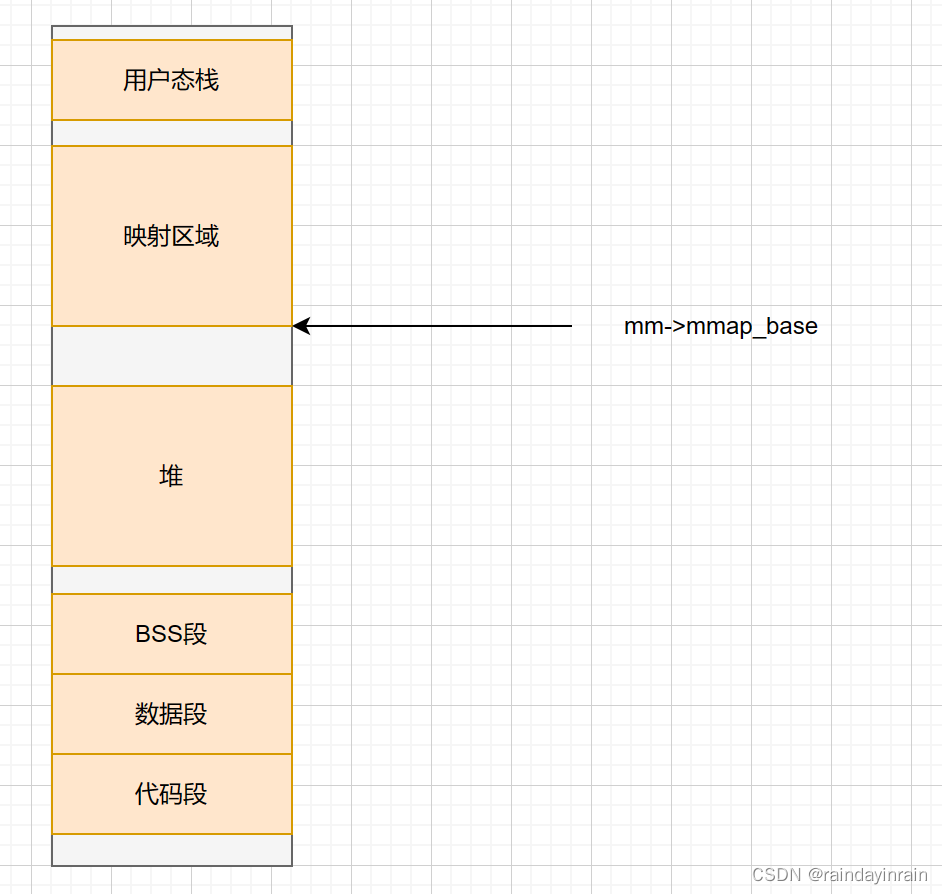
此种布局下,映射区域部分中每个通过mmap得到的线性区域必须从mm->mmap_base开始向后搜索,直到在用户态空间找到可用区域。
32位下,mm->mmap_base值一般是
2
30
2^{30}
230。
在此种布局下,堆区域尺寸受到较明显限制,典型的32位系统,此布局下堆区域至多可达到1GB。但优势是栈区域可自由扩展,直到遇到某个mmap区域为止。
3.2.新布局
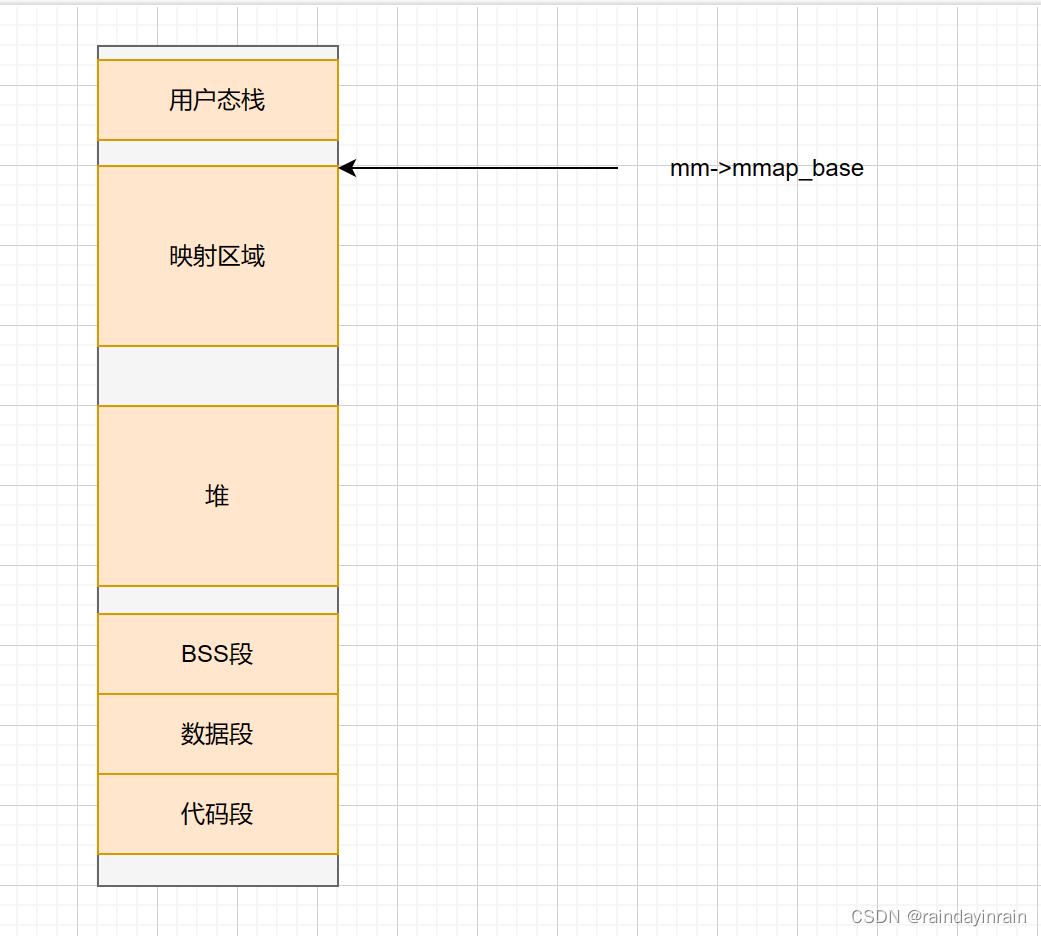
此局部下,需要先限制用户态栈区域最大尺寸。
这样,我们可在栈区域之后某个位置设置mm->mmap_base。
此布局下,映射区域部分中每个通过mmap得到的线性区域必须从mm->mmap_base开始向前搜索,直到在堆区域之后找到某个可用的线性区域。
在此种布局下,堆区域尺寸受到的限制较小,典型的32位系统,此布局下堆区域至多可达到约3GB。但劣势是栈区域尺寸固定。
在64系统上,由于可用的线性地址空间巨大,总是采用经典布局。32位上两种布局皆可能采用。
4.mmap系统调用实现
用户态线性区通过mmap实现线性区分配使用.
值得注意的是通过mmap获得的线性区可分为四种类型:
(1). 匿名映射&私有映射
通过此种方式得到的线性区,用于为进程获取用户态缓存空间.如用户态栈,堆,及需分配大块用户态缓存时,均需通过此方式得到线性区.匿名是相对于文件映射而言的,即线性区指向的物理页框内的数据是进程管控的,和磁盘等外设上数据没关系.
(2). 匿名映射&共享映射
通过此方式得到的线性区,除了用于进程自身获取大块用户态缓存,还可用于父子进程将实现共享内存通信.由于限制在父子进程,使用较为受限.我们不对其做过多分析.
(3). 文件映射&私有映射
通过此种方式得到的线性区,一般用于加载动态库.
文件映射的意思是线性区指向的物理页框内的数据是来自于文件对应区域的数据.
私有映射的意思是要么通过线性区执行数据的只读访问,若通过线性区执行数据写入操作,必须另外分配新的页框,拷贝老数据到新页框,修改进程页表,再写入到新页框对应位置.相应的线性区映射类型自动转换为匿名映射&私有映射.
(4). 文件映射&共享映射
通过此种方式可以多进程实时共享文件数据,直接修改文件自身.
文件映射的意思是线性区指向的物理页框内的数据是来自于文件对应区域的数据.
共享映射的意思是通过线性区执行数据写入操作,直接写入到关联页框.
关联页框被写入后将标记为脏页,系统自动负责将脏页内容写回到磁盘文件.
值得注意的是:
(1). 系统对文件系统上文件正常下均引入文件页高速缓存.文件内每一页的数据一般只会存在一个一个物理页框中.系统通过address_space对象实现文件页高速缓存的管理.
(2). 通过mmap获得用户态线性区时,线性区除了上述四种类型可供指定外,还可指定其他属性,如线性区的权限要求,权限一般分为只读,读写,执行.还有其他诸如线性区是否可扩展,扩展方向等.
下面分析mmap主要实现过程:
(1). 各种限制与参数合法性检测.
注意下几种不合法场景:
a. 文件共享映射下,要求写权限,但文件不支持.
b. 文件共享映射下,文件以append模式访问下,要求写权限的.
c. 文件私有映射下,文件可以不支持写,但需支持读.因为此时并不会实际写文件本身.
(2). 结合建议地址,从遍历所有已经分配线性区,选出一个满足尺寸要求的可用线性区.
(3). 线性区标志集合构造.
注意下几个情况:
a. 文件共享映射下,要求写时,标志集合包含VM_SHARED.要求读时,标志集合不含VM_SHARED,也不含VM_MAYWRITE.
b. 匿名共享映射下,无论读写,标志集合包含VM_SHARED.
(4). 取得可用线性区前一线性区.验证是否可与其合并.合并下合并后直接结束.我们分析不合并后续处理.
(5). 为新线性区分配vma对象,初始化.
(6). 若是文件映射,需设置好vma的vm_ops.
(7). 若是共享匿名映射,实际上转变为特殊文件系统上dev/zero文件的文件映射来处理.匿名共享映射一般用于父子进程通信.我们不过多分析.
(8). 新区域的vma需加入进程vma链表,进程vma红黑树结构.
值得注意的是:
a. 针对以VM_LOCKED方式申请的用户态线性区域,在mmap阶段会手动引发缺页异常.完成物理页分配,映射区域页表设置的工作.文件映射下,会以文件对应区域内容填充物理页.以VM_LOCKED方式得到的物理页不会被页框回收过程所回收.
b. 非VM_LOCKED下执行mmap,我们指示划分出可用用户态线性区域并加入结构.并未实际执行物理页分配,页表设置等工作.
5.munmap系统调用实现
(1). 各种合法性检测
(2). 验证是否存在某个区域包含待释放区域,若是,则处理区域拆分.我们不考虑拆分.主要关注释放区域处理.
(3). 释放区域对应的页表项需清理.对应的物理页递减其引用数.
(4). 释放区域的vma需从进程vma链表,进程vma红黑树中移除.
6.对malloc,free的分析
malloc,free是c库提供的用于内存分配,内存释放的函数.
其操作的区域是进程的堆区域.
针对进程堆区域这一连续可用线性区域,在其上构建诸如类似内核伙伴系统,固定尺寸内存分配器这样的结构来管理这片可用区域上的内存分配和释放便是malloc,free的任务.
值得注意的是:
堆这片线性区域可以扩展,可以收缩.这得借助于系统调用sys_brk.
7.缺页异常
由于我们初始执行mmap得到的可用的用户态线性区域,既没作页表的准备,也没作物理页的准备.
所以,初次访问这样的线性地址时,将引发缺页异常.
实际上,对线性地址的任何非法访问均引起缺页异常.
我们可以梳理下,缺页异常各种场景,及每种场景下处理策略:
(1). 访问内核态线性地址引发
直接映射区域部分一般启动阶段已经完成页表注册.一般不会触发缺页异常.
进程访问vmalloc区域或其他非直接映射区域可能引发.
先拷贝内核全局页表中对应页表项到进程.再检查页表项是否有效.无效或其他情况,皆为无效访问场景.
(2). 访问用户态线性地址引发
a. 访问的线性地址不属于进程任何现有线性区
若访问位置紧靠用户态栈,尝试栈扩展来解决.
否则,属于无效访问.用户态线性地址的无效访问一般将给引发进程发送段错误信号.
b. 访问的线性地址属于某个线性区,但页表项为空.
线性区通过mmap分配后,进程的页表未同步修改时,初次访问线性地址场景.
c. 访问的线性地址属于某个线性区,但页表项非空.但显示物理页不存在.
对匿名映射,页框由于页框回收被交换出去后,再次访问触发此场景.
对文件映射,页框由于页框回收被回收后,再次访问触发此场景.
d. 访问的线性地址属于某个线性区,页表项存在.但权限错误.
对文件私有映射,且线性区要求写权限时,初次读取线性地址引发的缺页异常处理中,页表项并不会设置写权限.此后,继续对线性地址执行写入触发此场景.
缺页异常主体处理流程简要描述:
(1). 访问内核态线性地址引发时
(1.1). 内核模式引发,且属于no page错误类型
将属于内核主线程页表中线性地址对应页表项拷贝到进程页表.
若拷贝到有效页表项,则解决此异常.
否则,进入bad_area_nosemaphore.
(1.2). 其他场景
进入bad_area_nosemaphore.
(2). 访问用户态线性地址引发时
(2.1). 中断上下文引发,或当前进程不是用户态进程
进入bad_area_nosemaphore.
(2.2). 内核模式引发,且异常地址在异常表中搜索不到处理函数
此场景对应系统调用中访问用户态线性地址引发的异常,先尝试寻找修复程序.
进入bad_area_nosemaphore.
(2.3). 从进程所有已经分配线性区寻找容纳引发访问异常地址所在线性区,找不到容纳的就找在其右边最靠近其的.
a. 若找不到这样的线性区
进入bad_area.
b. 找到一个容纳其的vma
进入good_area.
c. 找到右边最靠近其的一个vma
若此vma不支持向下扩展,进入bad_area.
若在用户态引发,且异常地址距离用户态栈顶相距超过128,依然进入bad_area.
其他情况,通过扩展用户态栈来解决异常.
缺页异常特定场景处理:
(1). good_area
这里的场景对应的是访问用户态线性地址引发异常,且此线性地址落在进程已经分配的某个vma内.
(1.1). 分析场景
a. 若属于写访问,但页表项不支持写
_1.若隶属的线性区不支持写访问,转到bad_area.
_2.设置写访问标志.
b. 若属于写访问,但页表项不存在
_1.若隶属的线性区不支持写访问,转到bad_area.
_2.设置写访问标志.
c. 若属于读访问,但页表项不支持读
转到bad_area.
d. 若属于读访问,但页表项不存在
若隶属的线性区不支持读,转到bad_area
(1.2). 在handle_mm_fault中实际解决异常.
(2). bad_area处理
参考bad_area_nosemaphore处理
(3). bad_area_nosemaphore处理
这里的场景对应的是访问到了无效的线性地址.
(3.1). 若用户态引发
采用给进程发SIGSEGV信号来解决.
(3.2). 若内核态引发
转到 no_context.
(4). no_context处理
这里的场景对应的是内核态下访问了无效的线性地址
(4.1). 采用引导异常线性地址搜索异常表,找到处理程序下,设置regs->rip指向处理程序后,结束.
(4.2). 不存在异常处理程序时,将使得系统停用.
(5). out_of_memory处理
此场景对应bad_area的handle_mm_fault处理中返回了标志out_of_memory的错误.
若是用户态访问引发的,停止引发异常进程.
若是内核态访问引发的,转到no_context.
(6). do_sigbus处理
此场景对应bad_area的handle_mm_fault处理中返回了标志do_sigbus的错误.
若是用户态引发的,给引发异常进程发SIGBUS信号.
若是内核态访问引发的,转到no_context.
异常修复处理:
分析handle_mm_fault过程.
结合上述背景,能走到的handle_mm_fault这里.必然是访问了用户态线性地址引发了异常,且进程存在包含此线性地址的vma.
引发此场景存在三种可能:
1.线性地址对应页表项不存在
2.页表项存在,但present标志为空
3.页表项存在,present标志非空,但权限错误(只能是页表项不支持写,不支持读的前面过滤掉了)
其执行流程可简要描述为:
(1). 保证页表中各级页表存在.
(2). 若属于页表项不存在,转到do_no_page处理.
(3). 若属于页表项存在,但present未设置
若页表项包含file标志,转到do_file_page处理.
若页表项不含file标志,转到do_swap_page处理.
(4). 若页表项存在,且present设置
预期此时只能是写访问异常.转到do_wp_page处理.
do_no_page处理:
当我们通过mmap获得线性区,此后首次访问线性地址时引发此场景.
(1). 若vma的vm_ops未设置,或vm_ops->nopage未设置
匿名映射下会如此.转到do_anonymous_page处理.
(2). 这里应该是文件映射场景
执行vma->vm_ops->nopage.
这个步骤预期完成页框分配,文件内容填充等操作.
存储了文件内容的页框收到文件的基树统一管理来实现文件的页高速缓存机制.
(3). 针对文件映射下的私有映射的写访问
(3.1). 此时此vma将从文件映射转变为匿名映射,为此需为其分配一个struct anon_vma.
然后将vma加入到anon_vma代表的链式结构.
(3.2). 分配新页框,用vma->vm_ops->nopage返回页框内容填充新页框.相应的返回页框引用数递减.
(4). 设置页表项,使其指向正确页框.使其包含vma的页表标志.
(5). 文件私有映射写访问时,还需设置页表项的可写标志.
(6). 文件私有映射写访问时,还需为新页框设置index(代表了页框对应文件内偏移),mapping指向新页框隶属的线性区所隶属的anon_vma结构.设置其_mapcount为1.
(7). 其他情况的文件映射,只需递增页框的_mapcount即可.
do_anonymous_page处理:
这里对应的是匿名映射首次访问时的处理.
其处理流程为:
(1). 先是构造一个和vma权限要求一致的页表项,但取消页表项的可写标志.让此页表项指向一个特殊的全局的称为零页的特殊页框.
(2). 若是读访问引发的缺页异常,设置页表项并返回即可.
(3). 若是写访问引发的缺页异常
a.需为其分配一个struct anon_vma.
然后将vma加入到anon_vma代表的链式结构.
b. 分配新页框.
c. 设置页表项,指向新页框,按vma权限标志设置,设置其dirty位,线性区支持写时,设置其可写标志位.
d. 为新页框设置index(代表了页框对应线性区的偏移),mapping指向新页框隶属的线性区所隶属的anon_vma结构.设置其_mapcount为1.
do_file_page处理:
暂不分析.涉及到页框回收.
do_swap_page处理:
暂不分析.涉及到页框回收.
do_wp_page处理:
结合上面场景.
文件映射,且私有映射,映射时支持写权限,且初次读访问,后续写访问时,会执行到这里.
此时,参考文件私有映射,初次写访问时,额外分配新页框,拷贝原内容,设置页表,vma分配并加入anon_vma链表,设置page相关字段处理.
匿名映射,且私有映射,映射时支持写权限,且初次读访问,后续写访问时,会执行到这里.
此时,参考匿名私有映射,初次写访问时,额外分配新页框,设置页表,vma分配并加入anon_vma链表,设置page相关字段处理.