虽然OpenAI发布了一系列基于GPT模型的产品,在不同领域取得了很高的成就。但是作为LLM领域绝对的领头羊,OpenAI没有按照其最初的Open初衷行事。无论是ChatGPT早期采用的GPT3,还是后来推出的GPT3.5和GPT4模型,OpenAI都因为担心被滥用而拒绝对模型进行开源,选择了订阅付费模式。
对于大型科技公司来说,自研LLM模型几乎是不可避免的,无论是为了展示实力还是出于商业竞争的目的。然而,对于缺乏计算能力和资金的中小企业以及希望基于LLM开发衍生产品的开发者来说,选择开源显然是更理想的选择。
在众多开源的LLMs中,清华大学和智谱AI的GLM系列由于其出色的效果,引起了广大关注。在2022年11月,斯坦福大学的大模型中心对全球范围内的30个重要大模型进行了深度评估。GLM-130B是唯一被选中的亚洲模型,在评价指标上也展现出了与GPT-3 175B相当的表现。
GLM系列的模型众多,大部分都是对标GPT系列的模型,如下图所示。

- GLM:由清华大学、北京智源人工智能研究院等联合发布的百亿模型,使用自回归填空目标进行预训练,并可以在各种自然语言理解和生成任务上进行微调。
- GLM-130B:由清华智谱AI于2022年8月开源,是基于GLM继续开发的,在归一化、激活函数、掩码机制等方面进行了优化,打造的高精度千亿规模中英双语语言模型。
- CodeGeeX:CodeGeeX是一个具有130亿参数的多编程语言代码生成预训练模型,但它并不是基于GLM架构的,而是一个单纯的从左到右的自回归Transformer解码器。CodeGeeX使用华为MindSpore框架实现,在20多种编程语言的代码语料库(总计超过8500亿Token)上进行了两个月预训练。CodeGeeX支持Python、C++、Java、JavaScript和Go等多种主流编程语言的代码生成,能够在不同编程语言之间进行准确的代码翻译转换。CodeGeeX2则是基于ChatGLM2-6B开发的。
- ChatGLM:ChatGLM是基于GLM-130B进行指令微调得到的千亿对话模型,解决了GLM-130B在处理复杂问题、动态知识和人类可理解场景方面的限制和不足。ChatGLM-6B是在相同技术训练后开源的小规模参数量版本,方便开发者进行学习和二次开发。
GLM 百亿模型
论文:https://arxiv.org/abs/2103.10360
代码仓库:https://github.com/THUDM/GLM
背景
预训练模型主要有3种架构,自回归模型GPT、自编码模型BERT和编码-解码模型T5。
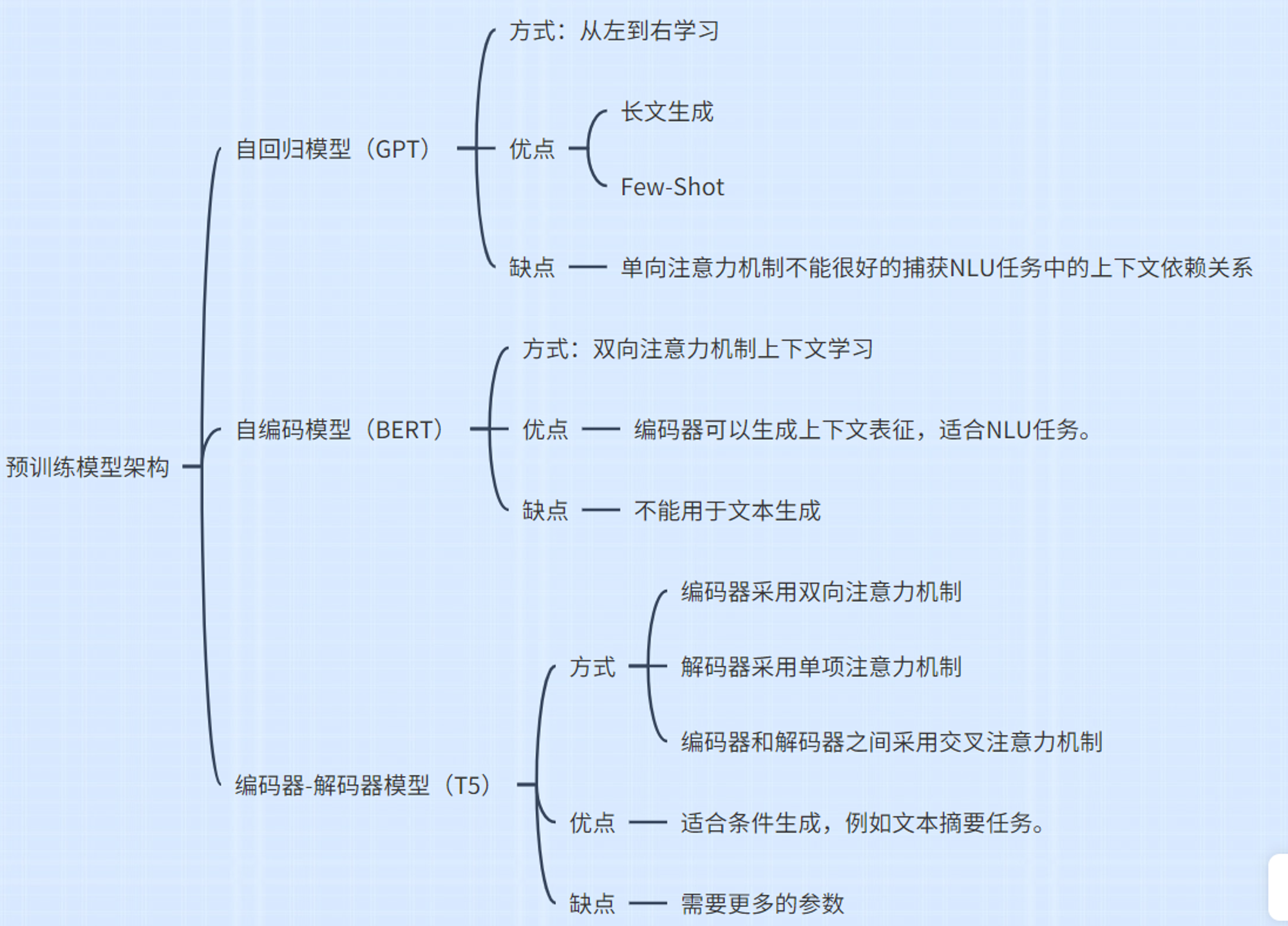
方法
GLM的模型架构使用了单一的Transformer,采用了自回归填空任务进行训练,通过双向注意力对masked字段进行自回归预测。
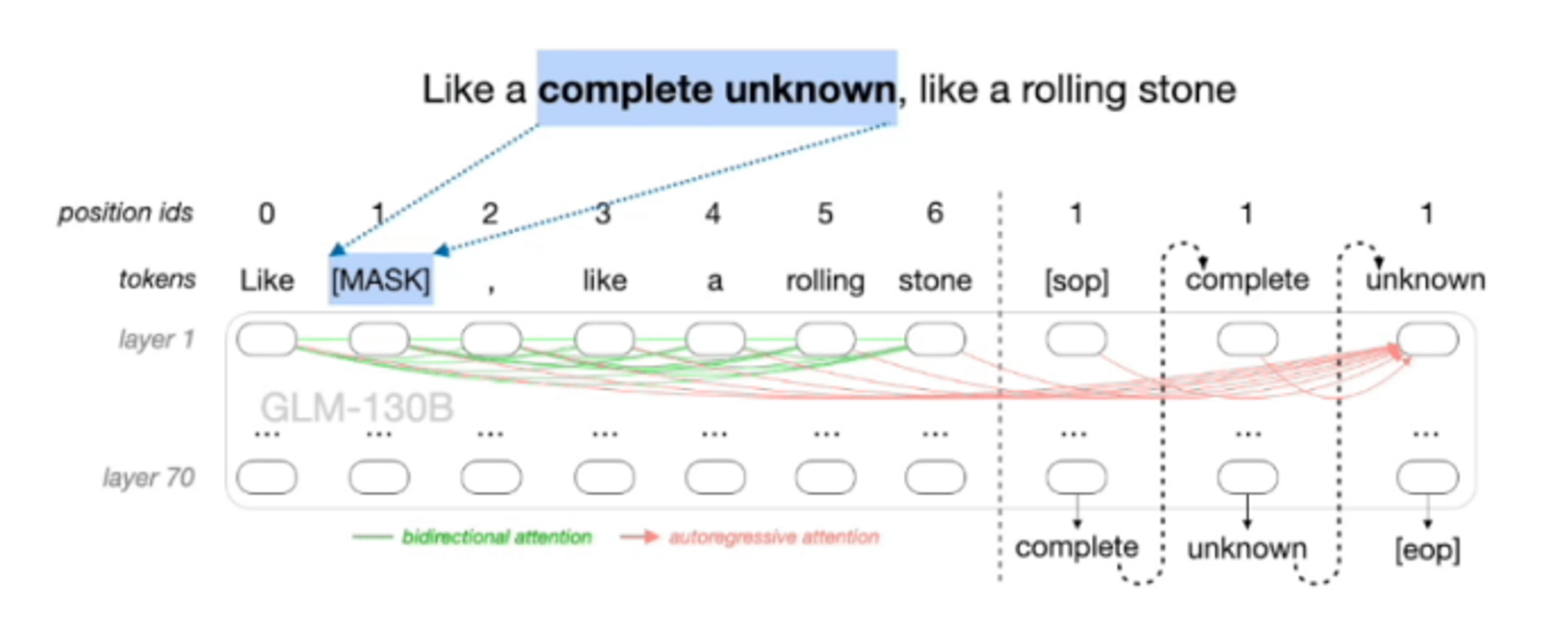
自回归填空任务,就是通过先破坏(mask)原始文本的部分,然后再对mask的部分进行预测重建。例如,输入一个句子,然后随机连续的掩盖一段文本区间,之后通过自回归预测来还原这些被mask的部分。与其它任务不同的是,GLM在mask的输入部分使用了和BERT相同的双向注意力,在生成预测的一侧则使用了自回归的单向注意力。
如下图所示,对于输入“Like a complete unknown, like a rolling stone”,首先会随机mask掉一些单词或句子,例如图中的“complete unknown”,然后在编码器阶段,可以使用双向注意力学习掩码处的特征,最后在解码器生成文本时,使用单项注意力通过自回归的方式依次生成被mask的单词。
输入文本 x = [ x 1 , . . . , x n ] x = [x_1, ..., x_n] x=[x1,...,xn],对多个文本 spans { s 1 , . . . , s n } \text{spans} \{s_1, ..., s_n\} spans{s1,...,sn}进行采样,用单个[MASK] token替换,形成损坏的文本 x c o r r u p t x_{corrupt} xcorrupt。然后以自回归的方式从 x c o r r u p t x_{corrupt} xcorrupt预测spans中的tokens,可以访问损坏的文本和先前预测的span。
max θ E z ∼ Z m [ ∑ i = 1 m log p θ ( s z i ∣ x corrupt , s z < i ) ] \max _{\theta} \mathbb{E}_{\boldsymbol{z} \sim Z_{m}}\left[\sum_{i=1}^{m} \log p_{\theta}\left(\boldsymbol{s}_{z_{i}} \mid \boldsymbol{x}_{\text {corrupt }}, \boldsymbol{s}_{\boldsymbol{z}_{<i}}\right)\right] θmaxEz∼Zm[i=1∑mlogpθ(szi∣xcorrupt ,sz<i)]
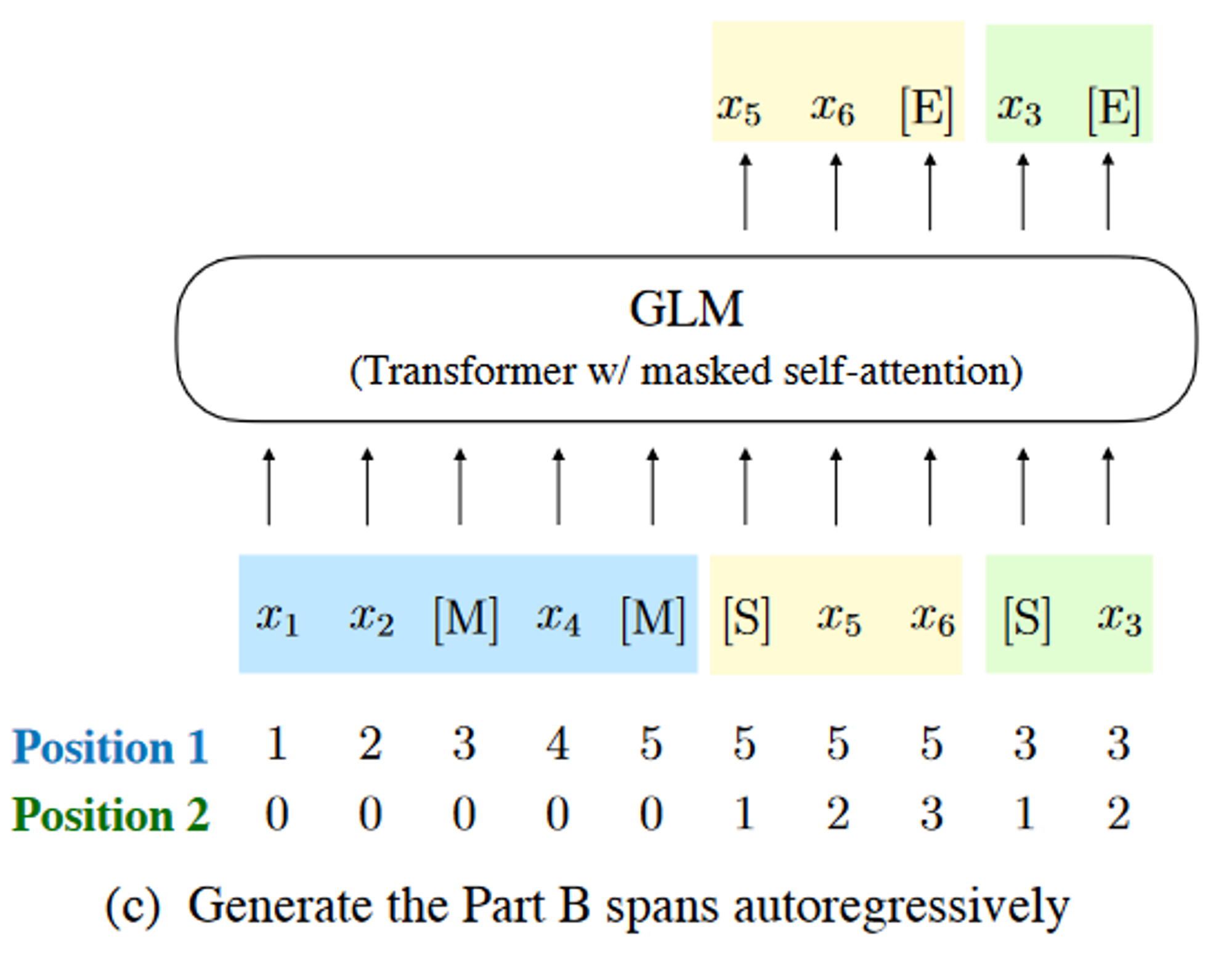
输入x被分成两部分:A表示x_corrupt,B表示被mask的span。A中的token可以互相关注,B中的token只能关注A以及B的前缀,看不到后缀。如下图所示,从输入文本中采样两个span: [x3] 和 [x5, x6],A中的span用[M]替换。另外,为了充分捕获不同span之间的相互依赖性,span是随机排序的。

然后自回归生成B的时候,每一个span都已[S]开头作为输入,以[E]结尾作为输出,如下图所示。2D位置编码分别表示span内和span间的位置。
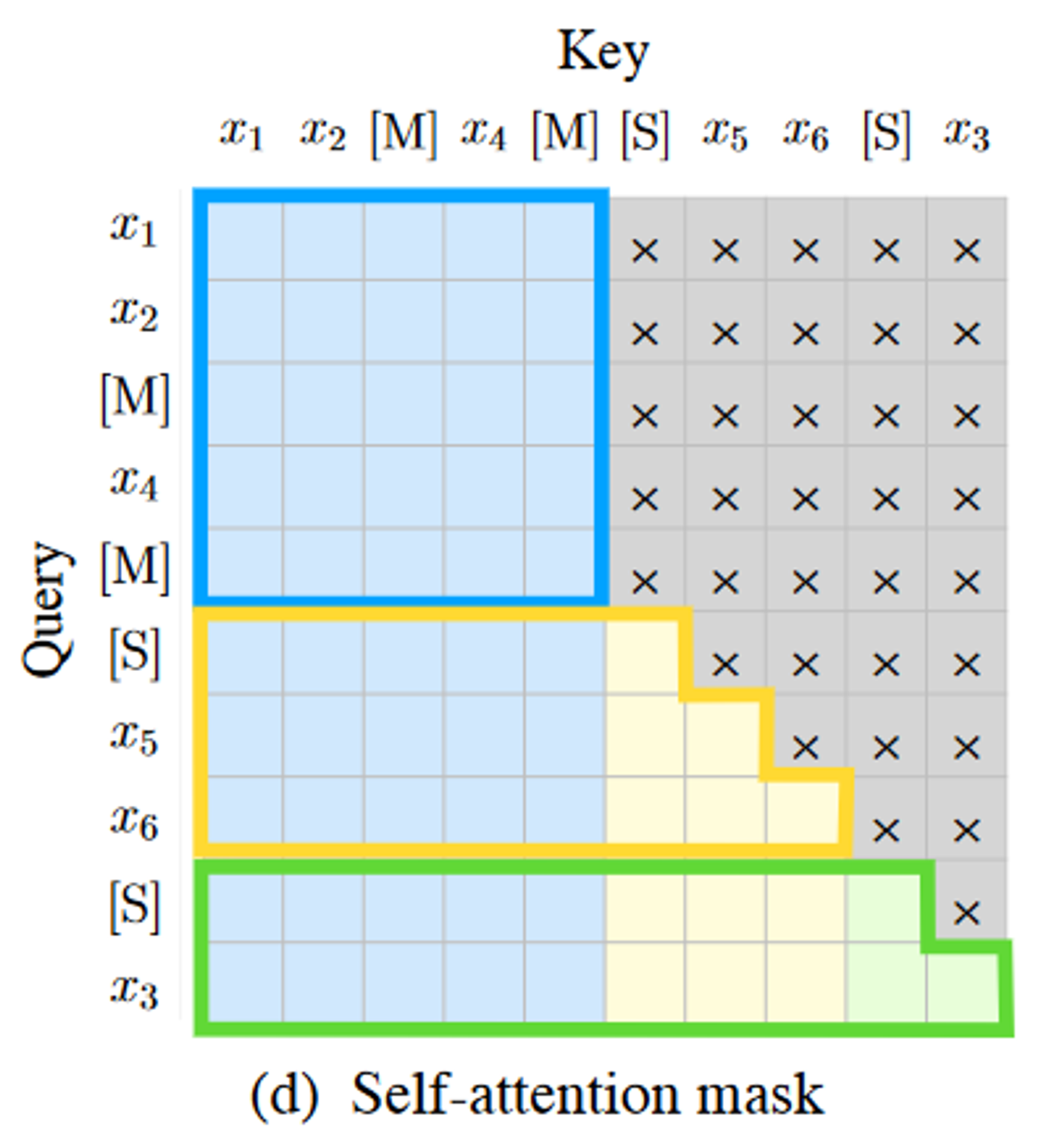
下图表示了注意力掩码,灰色的位置表示被掩盖,A部分(蓝色)的tokens可以互相关注,但不能关注B部分,B部分(黄色和绿色)的tokens可以关注A部分和B部分的前缀。
预训练任务
GLM根据mask的长度不同分为两种方式:单词级别(mask)和文档级别(gMASK)。在实际使用中,可以根据任务需求设置不同方式的mask比例。例如,如果希望模型具有较强的生成能力,可以提高文档级别gMASK的比例,如果只是希望模型具有短文本的自然语言理解能力,可以提高单词级别mask的比例。
在预训练阶段GLM就采用了多任务学习。任务一是生成长文本,即文档级生成。从输入文本采样长度为50%-100%上的span。目标就是训练长文本生成能力。任务二是填空,针对句子级生成。从输入文本采样完整的多个句子,要覆盖原始输入的15%左右。目标是训练生成完整的句子或段落的能力。
2D位置编码
第一个位置编码表示token在x_{corrupt}中的位置,对于mask的span,位置编码等于它对应的[MASK]的位置。第二个位置编码表示span内token的相对距离。两个位置编码都通过可学习的Embedding投影为两个向量
2D位置编码有两个优点:① 模型在重建mask的span时对长度不敏感;② 这种设计适合下游任务,因为生成文本的长度事先是未知的。
下游任务微调
传统方式:将预训练模型最后一层生成的序列或token输入一个线性分类器,预测正确的标签。
GLM的微调方式:将NLU分类任务重新定义为填空的生成任务。
例如,给定有标签样本(x, y),通过一个包含掩码token的模式字符串将输入文本x转换为完形填空题c(x)。情感分类任务:{SENTENCE}. It’s really [MASK].
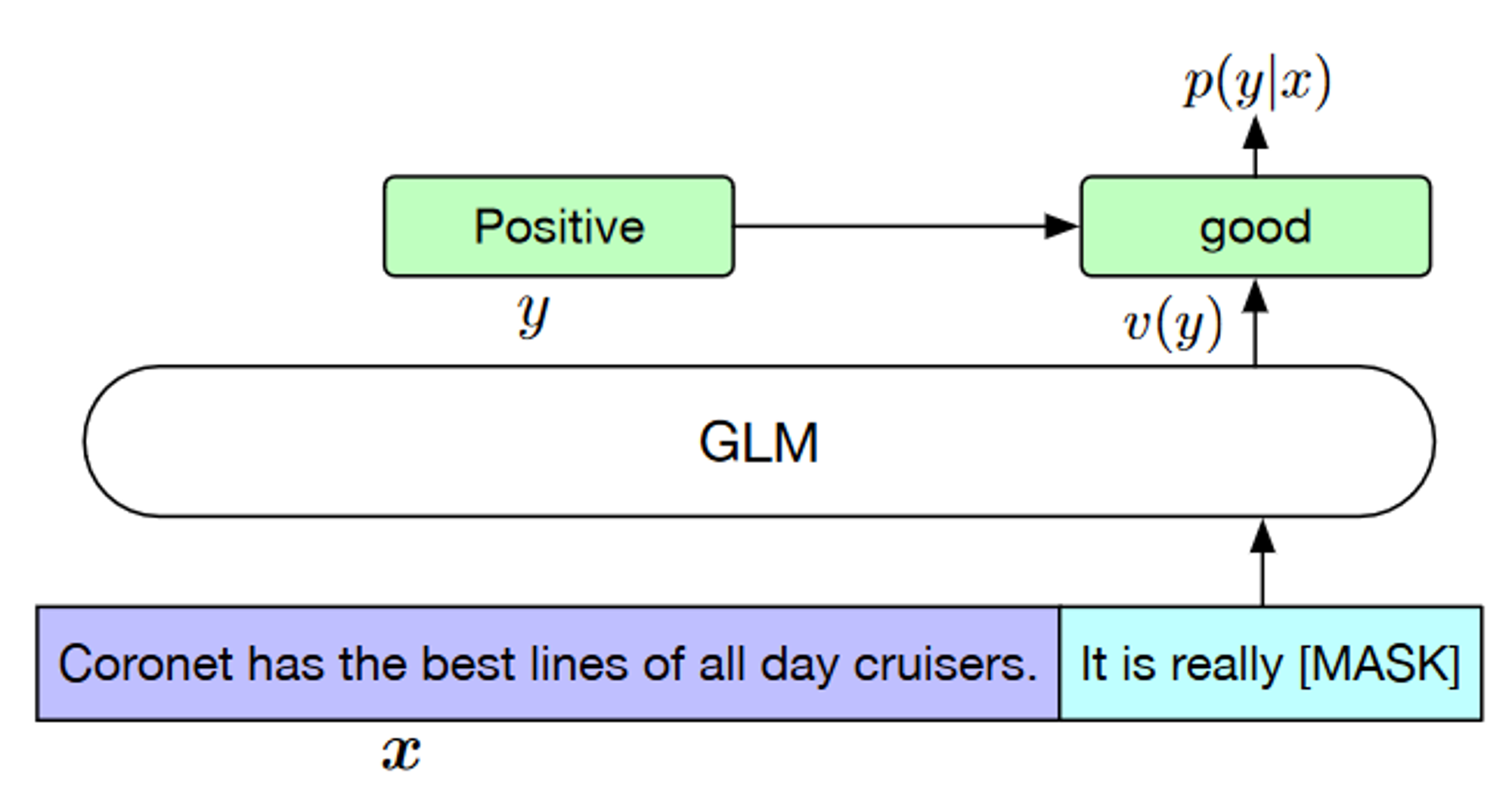
GLM-130B 千亿模型
论文:https://arxiv.org/abs/2210.02414
代码仓库:https://github.com/THUDM/GLM-130B
本文介绍了如何预训练一个100B规模的GLM-130B模型,包括模型设计、工程、效率和稳定性等方面的训练策略,以及如何量化出一个普通玩家可承受的推理模型。GLM-130B是一个双语模型,2022年5月6日到7月3日之间,在一个由96个NVIDIA DGX-A100(8×40G)GPU节点组成的集群上训练了超过4000亿个token。
为什么是130B?
- 在单个A100(4×40G)服务器上可推理
- INT4量化后可以在4×RTX 3090(24G)或8×RTX 2080Ti(11G)上推理
模型架构
GLM是基于Transformer的语言模型,通过自回归填空进行训练。
Layer Normalization
层标准化的位置也有讲究,分为三种:Pre-LN、Post-LN和Sandwich-LN,其结构如下图所示。顾名思义,Pre-LN就是将层标准化放在残差连接之前,能够让模型的训练更加稳定,但是模型效果略差。Post-LN将层标准化放在残差连接之后,对参数的正则化的效果更强,虽然模型效果更好,但是可能会导致模型训练不稳定,这是由于网络深层的梯度范式逐渐增大导致的。那么,自然而然的可以想到将两者结合起来,于是就有了Sandwich-LN,在残差连接之前和之后都加入一个层标准化。Cogview(清华与阿里共同研究的文生图模型)就使用了Sandwich-LN来防止产生值爆炸的问题,但是仍然会出现训练不稳定的问题,可能会导致训练崩溃。
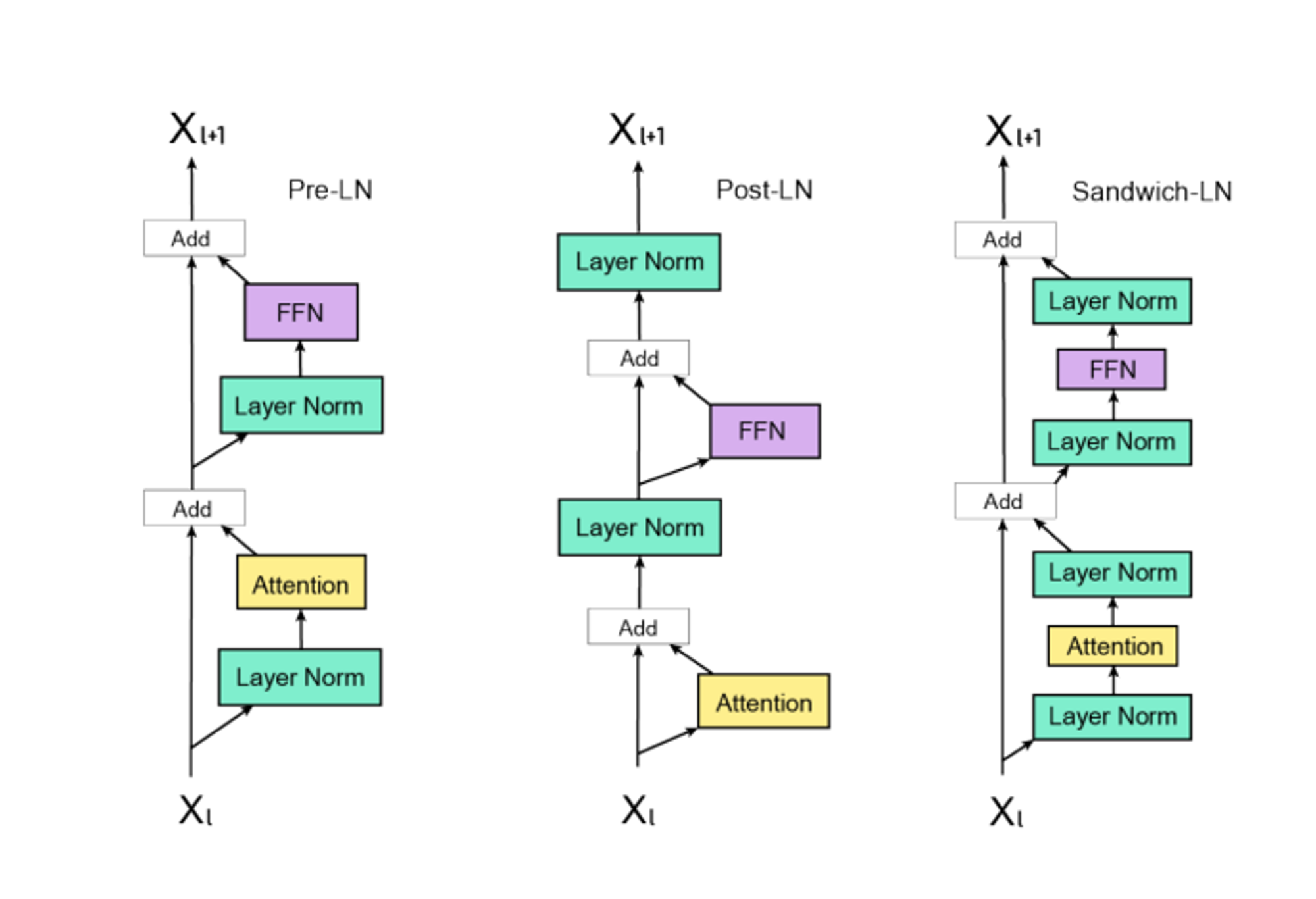
在NLP的早期阶段,例如BERT,由于其神经网络层数相对较浅,通常会采用Post-LN,而随着模型的发展,Transformer结构开始增加更多的层数,例如GPT,这给训练稳定性带来了挑战,因此,研究人员开始使用Pre-LN,以提高深层Transformer模型的训练稳定性。
为了解决模型训练不稳定的问题,论文“DeepNet: Scaling Transformers to 1000 Layers”(https://arxiv.org/abs/2203.00555)中提出了DeepNorm,从论文名字就可以看出,该工作将Transformer模型扩展到了1000层,是一个非常深的网络。Pre-LN之所以会让模型训练更稳定,是因为标准化的输出可以缓解子层(注意力机制和前馈神经网络)梯度消失和梯度爆炸的问题。DeepNorm其实是一种Post-LN的方案,但是在执行层标准化之前up-scale了残差连接,也就是说
DeepNorm
(
x
)
=
LayerNorm
(
α
⋅
x
+
Network
(
x
)
)
, where
α
=
(
2
N
)
1
2
\text { DeepNorm }(x) = \text { LayerNorm }(\alpha \cdot \boldsymbol{x}+\operatorname{Network}(\boldsymbol{x})) \text {, where } \alpha=(2 N)^{\frac{1}{2}}
DeepNorm (x)= LayerNorm (α⋅x+Network(x)), where α=(2N)21,也就是说,DeepNorm会在层标准化之前以参数扩大残差连接。DeepNorm能够防止模型在训练过程中出现过大的参数更新,将参数的更新范围限制在一定的常数值内,以此来让模型的训练过程更加稳定。
位置编码
绝对位置编码以其实现简单、计算速度快的优点受到欢迎,而相对位置编码则因为其直观地体现了相对位置信号,往往能带来更好的实际性能。
旋转位置编码(Rotary Position Embedding,RoPE)将相对位置信息集成到了线性注意力层中,虽然按照定义应该属于相对位置编码,但是其在性能上超越了绝对位置编码和经典的相对位置编码,并且它其实是以绝对位置编码的方式实现了相对位置编码。
RoPE主要是对注意力层中的查询(query, q)向量和键(key, k)向量注入了绝对位置信息,然后用更新的后的这两个向量来做内积,就会引入相对位置信息。
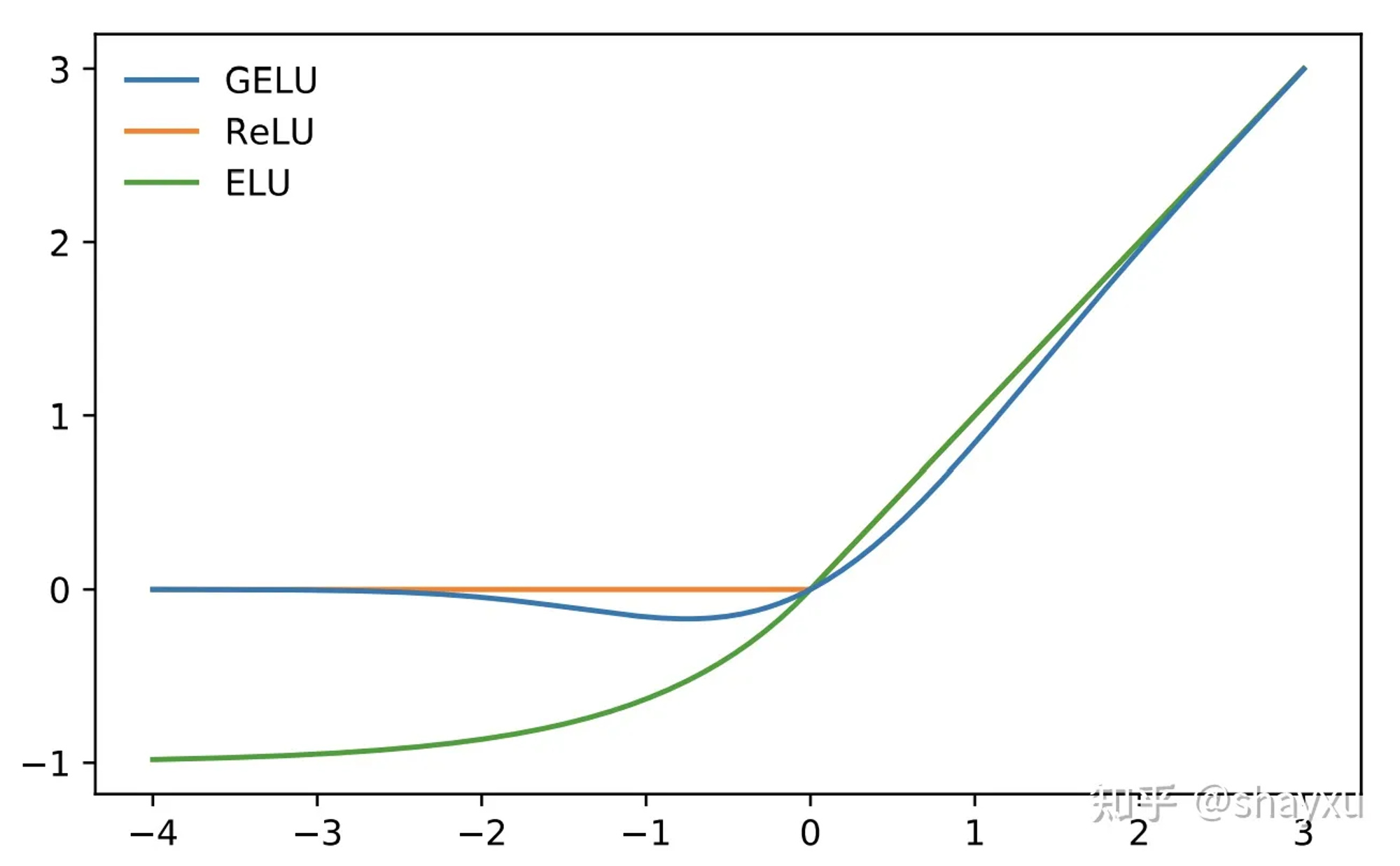
FFNs
采用了GELU激活函数,相比于ReLU激活函数,在处理负数时不会直接裁剪到0,因此可以缓解神经元死亡的问题。
预训练
自监督自回归填空
用训练集中95%的tokens用于自监督自回归填空训练。
- [MASK]:掩盖训练序列中30%的span用于填空,spans的长度服从泊松分布(λ=3),长度加起来是输入的15%。context window: 4×512 tokens。
- [gMASK]:掩盖剩下的70%的序列,保留前缀作为上下文,用[gMASK]掩盖其余序列,掩码长度服从均匀分布。context window: 2048 tokens
多任务学习
用训练集中5%的tokens用于多任务学习。预训练阶段的多任务学习比微调更有用,并且设置在预训练阶段可以防止破坏LLMs的通用生成能力。GLM-130B在预训练阶段中就包含了语言理解、生成和信息提取在内的多种指令数据集。
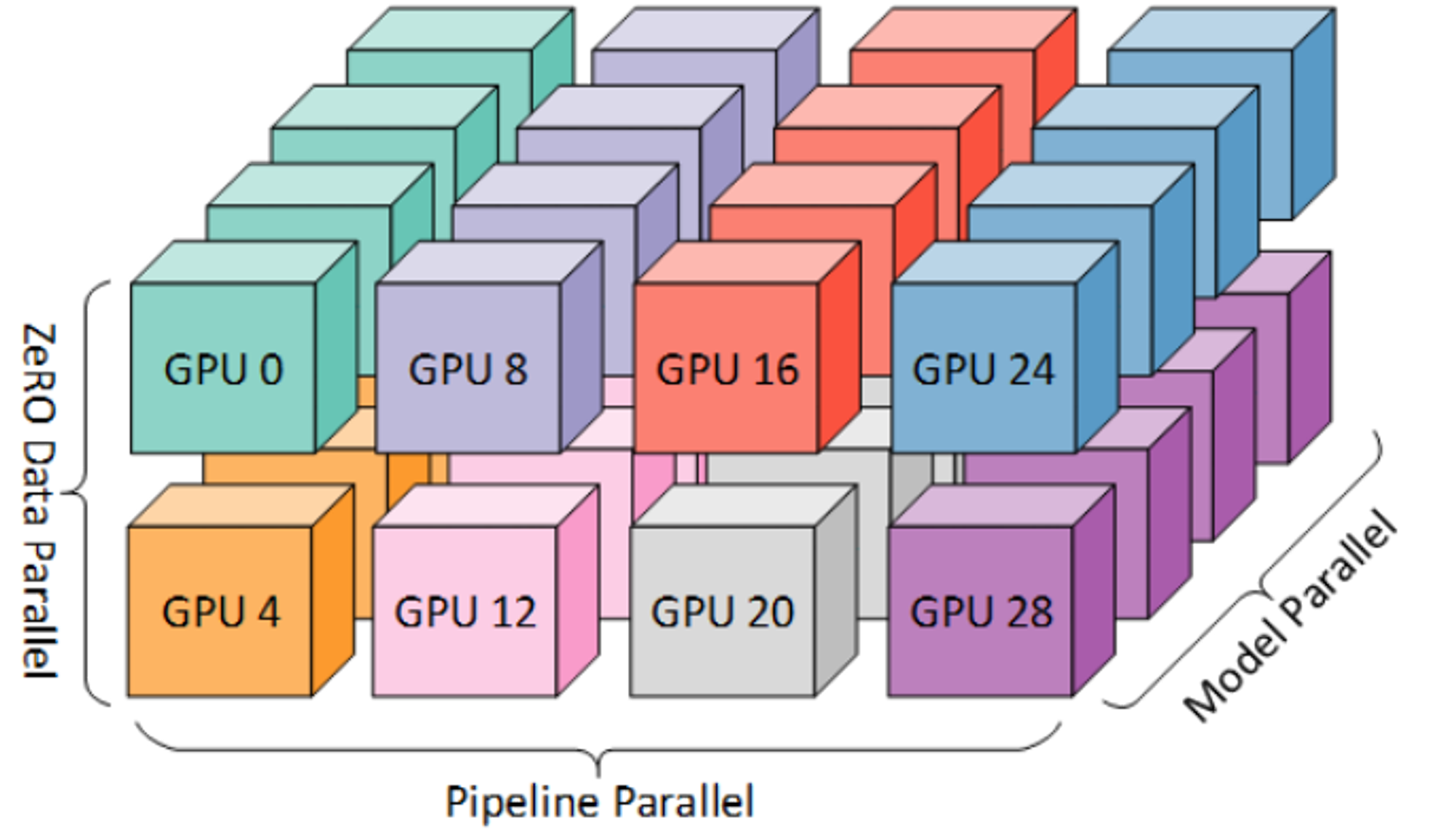
分布式训练
在一组由96台DGX-A100 GPU(8×40G)服务器组成的集群上进行了为期60天的训练。目标是尽可能处理更多的tokens,因为根据之前的研究表明,大多数现有的大型语言模型在训练过程中通常未充分训练。
更多有关分布式训练的内容可以参考我另外一篇文章:
震惊!我竟然在1080Ti上加载了一个35亿参数的模型(ZeRO, Zero Redundancy Optimizer)_estimate_zero3_model_states_mem_needs_all_live-CSDN博客
训练稳定性
混合精度
一般的混合精度训练:FP16用于前向传播和反向传播,FP32用于优化器状态和权重参数。
由于FP16的精度较低,经常会遇到loss突刺,并且越是训练后期越频繁。有的能够自行恢复,有的会导致梯度范数突然飙升,甚至出现NaN损失。OPT-175B通过手动跳过问题数据和调整超参数来解决,BLOOM-176B通过Embedding范数来解决。
混合精度在Transformer放大时可能会出现很多问题。
- 如果使用Pre-LN,Transformer主干的值在深层网络中会非常大。这在GLM-130B中通过基于DeepNorm的Post-LN解决,使得值域始终有界。
- 随着模型规模的扩大,注意力分数的增幅也越来越大,超过了FP16的取值范围。
- CogView中通过PB-Relax去除注意力计算中的bias和deduct extremum value,但是对GLM-130B没用。
- BLOOM-176B中,用BP16代替了FP16。但是BP16比FP16多消耗了15%的GPU显存,并且BP16并不适用于大部分的GPU。
- BLOOM-176B的另一个解决方案是使用BF16对Embedding进行norm,但这会牺牲模型性能。
Embedding层梯度收缩
梯度范数可以作为训练崩塌的指示,通常会发生在梯度范数出现突刺之后几步。这种突刺通常是由于Embedding层的异常梯度导致的,在GLM-130B训练的早期,梯度范数往往比其它层要大几个数量级。
在Vision模型中可以通过冻结patch projection layer来解决,但是LM不行。在CogView中可以通过梯度收缩解决损失突刺,稳定训练过程。
word embedding
=
word embedding
∗
α
+
word embedding.detach()
∗
(
1
−
α
)
\text{word embedding} = \text{word embedding} * \alpha + \text{word embedding.detach()} * (1-\alpha)
word embedding=word embedding∗α+word embedding.detach()∗(1−α)
在最终GLM-130B的训练中只经历过3次损失异常,都可以通过缩放Embedding层的梯度来稳定。
ChatGLM
ChatGLM系列只在GitHub上进行了开源,虽然相关模型可以直接下载使用,但是并没有论文,不知道一些具体的实现细节。
ChatGLM-6B: https://github.com/THUDM/ChatGLM-6B

ChatGLM2-6B: https://github.com/THUDM/ChatGLM2-6B
ChatGLM3: https://github.com/THUDM/ChatGLM3

多模态

CogVLM
论文:https://arxiv.org/abs/2311.03079
代码仓库:https://github.com/THUDM/CogVLM
CogVLM是一个视觉语言模型(Visual Language Model)。
传统构建视觉语言模型的方法:冻结LLM,将图像特征映射到语言模型的输入空间,属于浅层对齐。但是它的问题是缺乏深度融合,视觉特征和语言特征不平等。虽然也有一些解决方案,即在预训练或SFT时也训练LLM(例如Qwen-VL),但这种方法可能会降低模型的泛化能力,特别是在NLP任务上。
CogVLM提出了一种新的方法:在注意力层和FFN层通过可训练的视觉专家模块,来对齐冻结的预训练LLM和图像编码器,增加了更深层的视觉理解能力。实验结果表明,这种方法在不牺牲NLP任务性能的前提下,实现视觉语言特征的深度融合。并且由于原始LLM的所有参数固定,因此当输入序列中不包含图像时,其行为与原始LLM中的行为相同。在保持FLOPs不变的情况下,参数量可以增加一倍。
方法
在LLM的每一层加入可训练的视觉专家,序列中的图像特征使用新的QKV矩阵,MLP层使用文本特征。
模型架构
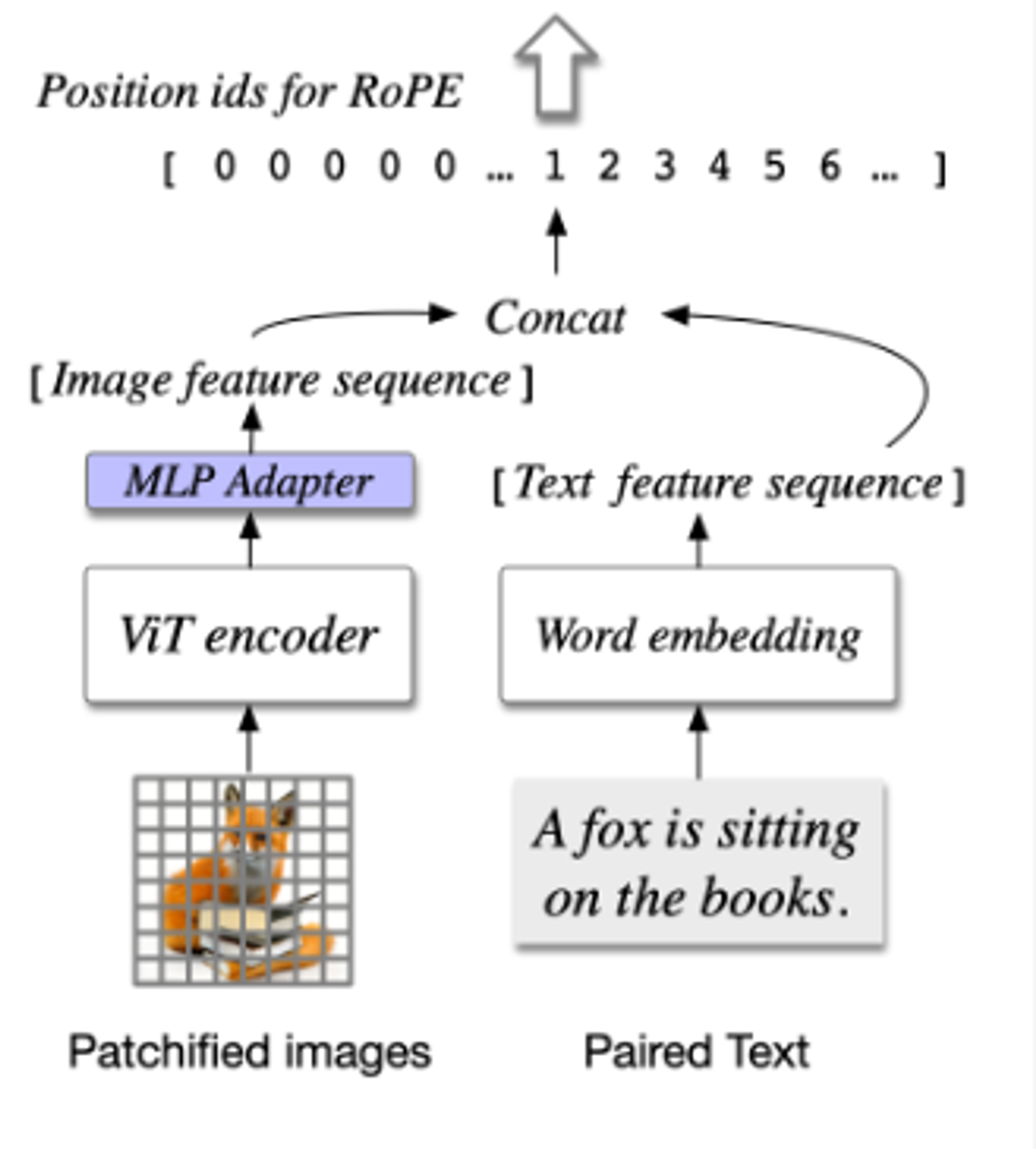
通过预训练的ViT对图像进行处理,并将其映射到与文本特征相同的空间。
- ViT编码器。EVA2-CLIP-E,移除了最后一层,因为主要用于对比学习。
- MLP适配器。用两层MLP将ViT的输出映射到跟文本特征相同的空间,所有图像特征在LLM中共享相同的位置id。
- 预训练LLM。Vicuna1.5-7B。一个因果掩码被应用于所有的注意力操作,包括图像特征之间的注意力。
- 视觉专家模块。
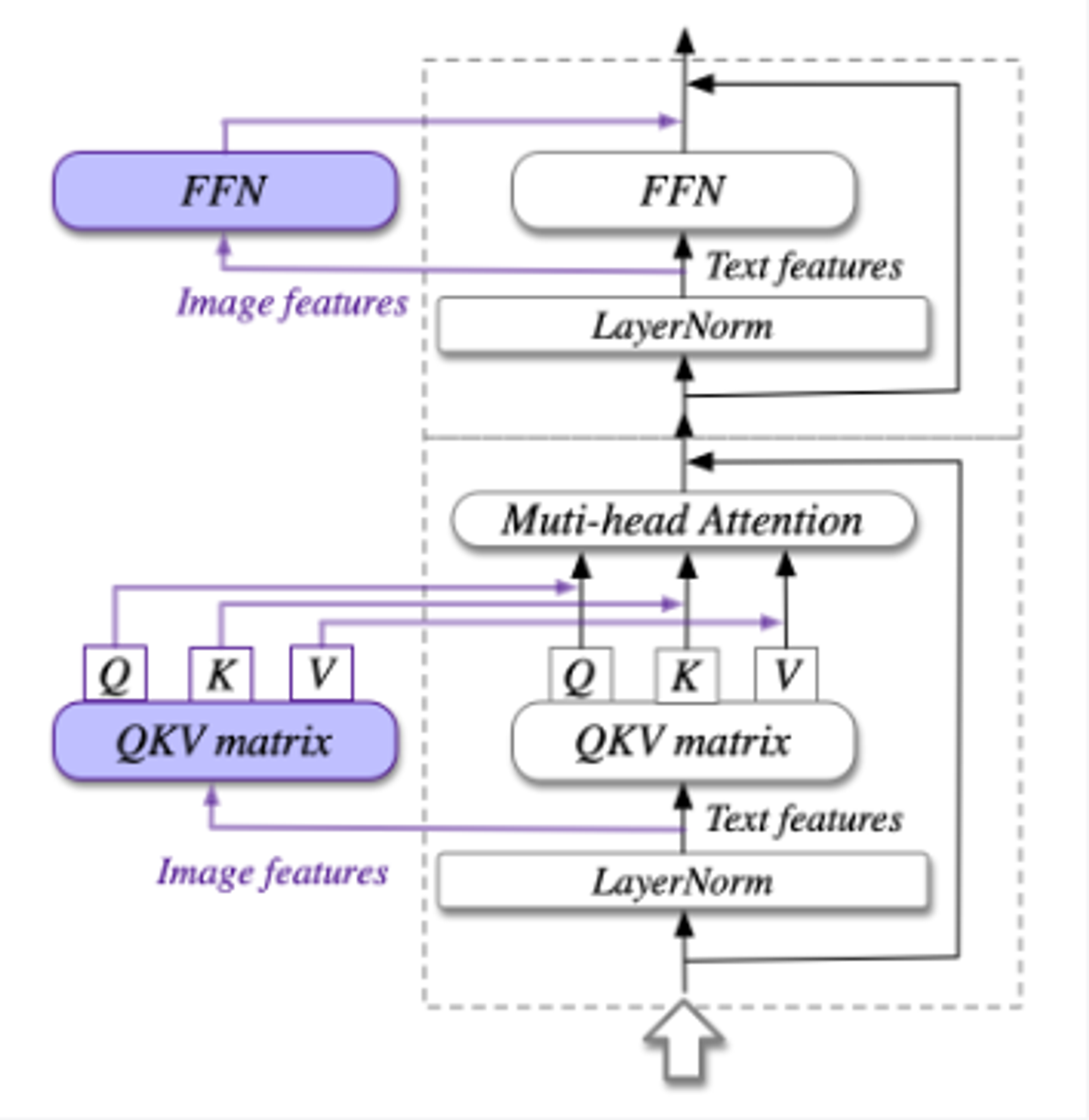
在每一层中添加视觉专家模块,实现深度视觉-语言特征对齐。图像特征具有不同的QKV矩阵和FFN,形状跟预训练LLM相同,并由它们初始化。只有紫色部分是可训练的。
注意力层的输入: X ∈ R B × H × ( L I + L T ) × D X \in \mathbb{R}^{B \times H \times\left(L_{I}+L_{T}\right) \times D} X∈RB×H×(LI+LT)×D,其中B:batch size,L_I和L_T:图片和文本序列的长度,H:注意力头的数量,D:隐藏层维度。X可以分解成X_I和X_T,分别表示图像隐藏层状态和文本隐藏层状态。
注意力层的计算: Attention ( X , W I , W T ) = softmax ( Tril ( Q K T ) D ) V \operatorname{Attention}\left(X, W_{I}, W_{T}\right)=\operatorname{softmax}\left(\frac{\operatorname{Tril}\left(Q K^{T}\right)}{\sqrt{D}}\right) V Attention(X,WI,WT)=softmax(DTril(QKT))V,其中Tril(·)表示下三角掩码。W_I和W_T分别表示视觉专家和原始LM的QKV矩阵。FFN层的计算: FFN ( X ) = concat ( FFN I ( X I ) , FFN T ( X T ) ) \operatorname{FFN}(X)=\operatorname{concat}\left(\operatorname{FFN}_{I}\left(X_{I}\right), \operatorname{FFN}_{T}\left(X_{T}\right)\right) FFN(X)=concat(FFNI(XI),FFNT(XT))。
Q = concat ( X I W I Q , X T W T Q ) K = concat ( X I W I K , X T W T K ) V = concat ( X I W I V , X T W T V ) \begin{array}{l}Q=\operatorname{concat}\left(X_{I} W_{I}^{Q}, X_{T} W_{T}^{Q}\right) \\K=\operatorname{concat}\left(X_{I} W_{I}^{K}, X_{T} W_{T}^{K}\right) \\V=\operatorname{concat}\left(X_{I} W_{I}^{V}, X_{T} W_{T}^{V}\right)\end{array} Q=concat(XIWIQ,XTWTQ)K=concat(XIWIK,XTWTK)V=concat(XIWIV,XTWTV)
位置编码
在LLM中的RoPE中,所有视觉token共享一个位置id,因为它们在输入到ViT时已经封装了位置信息。
传统位置编码的缺点:
- 编码序列过于冗长
- 查询更多地关注与其距离较近的图像序列,即图像的下半部分。
新的编码方式减轻了LLM中token之间远程衰减的影响。
预训练
数据
开源数据集:LAION-2B和COYO-700M。
自制visual grounding数据集,包含40M图片,图像描述中的每个名词都与边界框相关联,以表示图像中的位置。通过spaCy提取名词,然后使用GLIPv2预测边界框。图像-文本对从LAION - 115M中采样。过滤并保留4000万张图像的子集,以确保75 %以上的图像至少包含2个边界框。
训练
- 任务:image caption。在1.5B图像-文本对上进行了120000次迭代,batch size为8192。
- 任务:image caption + referring expression comprehension (REC)。一共进行了60000次迭代,batch size为1024。在后面30000次迭代中,将输入分辨率从224×224变为490×490。
REC:给定一个物体的文本描述,在图像中预测边界框。例如:Question: Where is the object? Answer: [[x_0, y_0, x_1, y_1]].
可训练参数总数:6.5B。
对齐
CogVLM-Chat
数据集分为两部分:
- VQA数据集:VQAv2、OKVQA、TextVQA、OCRVQA、ScienceQA
- 类似LLaVA-Instruct的多轮对话数据集:LRV-Instruction、LLaVAR
数据的完整性和质量是重点。
在不同的数据集上进行同意的有监督指令微调,以1e - 5的学习率和1024的批处理量进行了6000次迭代。为了增强和保证训练的稳定性,激活了视觉编码器的参数,并将其学习率调整为其余训练参数的十分之一。
CogVLM-Grounding
4种任务
- Grounded Captioning (GC):面向图像的任务,输出图片中的所有名词及其边界框。
- Referring Expression Generation (REG):面向图像的任务,图像中的每个边界框都标注上精确的表征和描述性文本。
- Referring Expression Comprehension (REC):面向文本的任务,每个对象描述关联到多个边界框。
- Grounded Visual Question Answering (GroundedVQA):VQA任务,问题可能包括给定图像的参考区域。
数据集:Flickr30K Entitie、RefCOCO、Visual7W、VisualGenome、Grounded CoT-VQA。
CogAgent
论文:https://arxiv.org/abs/2312.08914
代码仓库:https://github.com/THUDM/CogVLM
背景
人类在电子产品上花了大量的时间通过GUI进行操作。
LLMs很难理解并与GUI进行交互,这限制了它们的自动化水平,因此最近一些工作开始研究基于Agent的交互LLMs。
难点主要有3个:
- 缺乏交互的标准API
- 图标、图片、图表、空间关系等重要信息很难直接用文字表达
- 即使网页是通过代码语言渲染的,但canvas和iframe也难以通过HTML控制
基于视觉语言模型(Visual Language Model, VLM)的Agents可以克服这些难点,不完全依赖于HTML或者OCR结果,而是直接感知可视化的GUI信号。
但是问题在于,大部分VLM只能处理分辨率较低(224或490)的图像,难以满足电脑或手机屏幕分辨率的要求。原因是高分辨率会带来高时间和内存开销。自注意力模块的开销与视觉tokens(patches)的数量呈二次方关系,而patches的数量与图像的边长又呈二次方关系。
当然现在也有一些解决方案,Qwen-VL提出了一种位置感知的视觉语言适配器来压缩图像特征,但序列长度仅降低了4倍,并且仅能处理448×448的最大分辨率。Kosmos-2.5采用感知重采样模块来减少图像序列长度,但重采样后的序列也还是太长了,只能应用于受限的文本识别任务。
这篇论文提出了一个新的解决方案:CogAgent,这是一个基于CogVLM开发的,18B参数的视觉语言模型,专用于GUI的理解和规划。通过高/低分辨率的图像编码器,CogAgent支持1120×1120分辨率的输入,并且能够识别微小的页面元素和文本。
模型架构
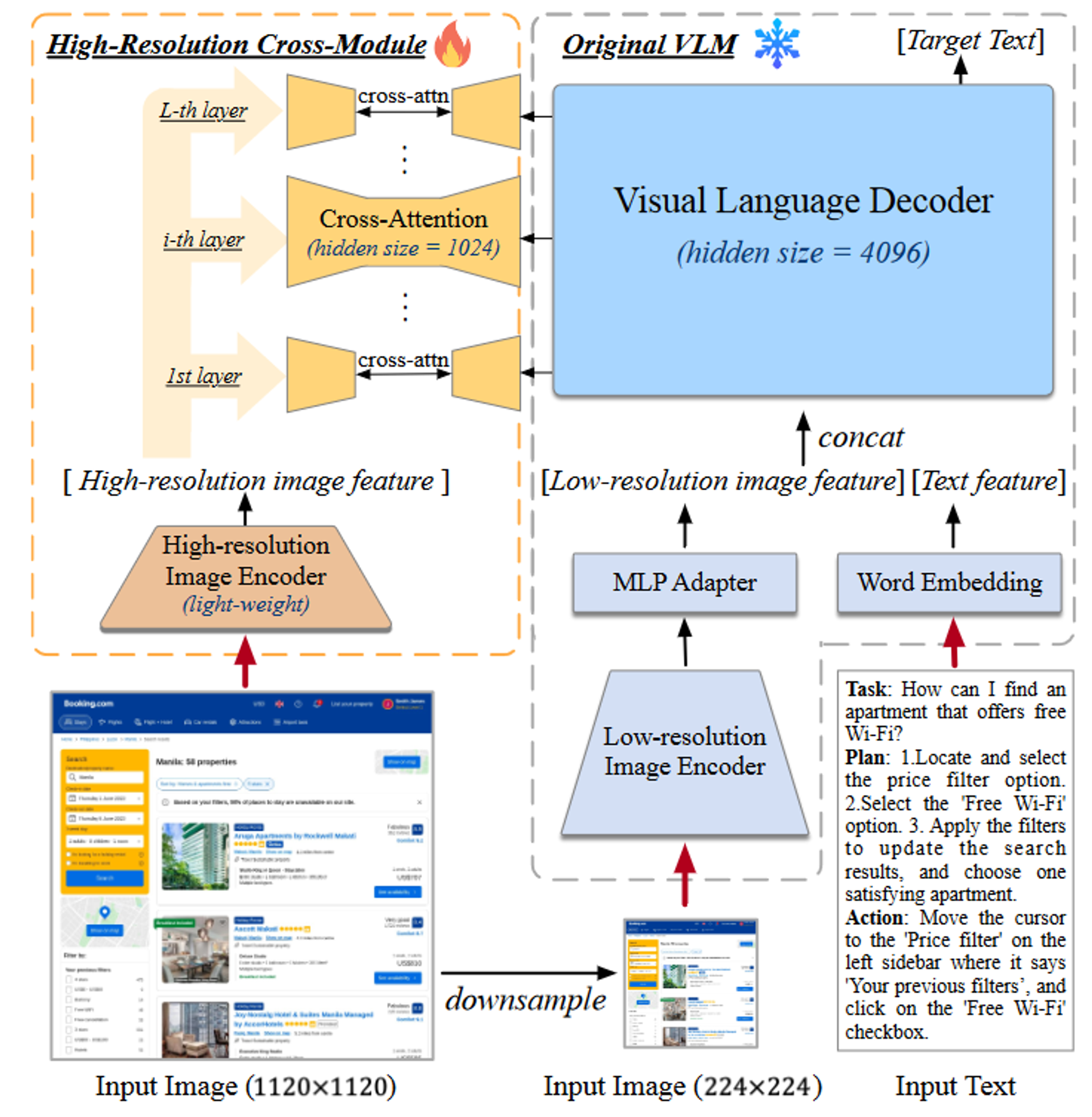
整体来看,CogAgent采用预训练的CogVLM-17B(右)作为基座模型,并且添加了一个交叉注意力模块(左)来处理高分辨率图像。
采用EVA-CLIP-E作为低分辨率图像(224×224)的编码器,并辅以MLP适配器,将其输出映射到VLM解码器的特征空间。解码器处理低分辨率图像特征序列和文本特征序列的组合输入,自回归输出目标文本。
如CogAgent模型架构图所示,高分辨率交叉模块是作为一个新的分支,接受1120×1120像素的图像。高分辨率交叉模块采用EVA2-CLIP-L作为视觉编码器,利用小尺寸隐藏层的交叉注意力将高分辨率图像特征与VLM解码器的每一层进行融合。
处理流程是这样的,输入一张图片,将其大小调整为1120×1120和224×224,分别送入高分辨率的交叉模块和低分辨率分支,然后编码成两个大小不同的图像特征序列
X
h
i
X_{hi}
Xhi和
X
l
o
X_{lo}
Xlo。VLM的解码器保留了其原有的计算,唯一的改变是在每个解码器层中集成了
X
h
i
X_{hi}
Xhi和隐藏状态之间的交叉注意力。
解码器第i层的注意力层的输入隐藏层状态:
X
i
n
i
∈
R
B
×
(
L
I
l
o
+
L
T
)
×
D
dec
X_{\mathrm{in}_{i}} \in \mathbb{R}^{B \times\left(L_{I_{\mathrm{lo}}}+L_{T}\right) \times D_{\text {dec }}}
Xini∈RB×(LIlo+LT)×Ddec
交叉模块的图像编码器的输出隐藏层状态:
X
h
i
∈
R
B
×
(
L
I
h
i
)
×
D
h
i
X_{\mathrm{hi}} \in \mathbb{R}^{B \times\left(L_{I_{\mathrm{hi}}}\right) \times D_{\mathrm{hi}}}
Xhi∈RB×(LIhi)×Dhi
其中,B:batch size,
L
I
l
o
L_{I_{\mathrm{lo}}}
LIlo:低分辨率图像长度,
L
I
h
i
L_{I_{\mathrm{hi}}}
LIhi:高分辨率图像长度,
L
T
L_{T}
LT:文本序列,
D
d
e
c
D_{\mathrm{dec}}
Ddec:解码器隐藏层大小,
D
h
i
D_{\mathrm{hi}}
Dhi:高分辨率图像编码器输出隐藏层大小。
每一层的注意力计算过程为:
- 多头注意力: X i ′ = MSA ( layernorm ( X i n i ) ) + X i n i X_{i}^{\prime}=\operatorname{MSA}\left(\text { layernorm }\left(X_{\mathrm{in}_{i}}\right)\right)+X_{\mathrm{in}_{i}} Xi′=MSA( layernorm (Xini))+Xini
- 多头交叉注意力: X out i = MCA ( layernorm ( X i ′ ) , X h i ) + X i ′ X_{\text {out }_{i}}=\operatorname{MCA}\left(\text { layernorm }\left(X_{i}^{\prime}\right), X_{\mathrm{hi}}\right)+X_{i}^{\prime} Xout i=MCA( layernorm (Xi′),Xhi)+Xi′
优点:高分辨率交叉模块可以看作是对低分辨率图像特征的补充,从而有效地利用了预训练好的低分辨率模型。
预训练
预训练阶段的目标是希望模型能够通过高分辨率图像识别不同字体、方向、大小和颜色的文字,可以在图像中定位并检测文本和物体,并且可以理解GUI图像,例如网页等。
数据
- 文字识别
- 基于NLP预训练数据集的文本合成渲染,可以理解为将文本转换为不同的字体、大小、方向和颜色等,然后合成到LAION-2B的图像上。
- OCR数据集,部署了一个Paddle-OCR提取COYO和LAION-2B中的文字和其bounding boxes。
- 学术文献数据,参考Nougat,利用arXiv上发布的LaTeX构建了一个图像文本对数据集。
- 视觉定位:使用从LAION-115M中采样的图像-标题对构建了40M的图像视觉定位数据集,将图像中的物体与bounding boxes相关联,提供其位置。
- GUI数据
- 两个任务
- GUI参考表达式生成(Referring Expression Generation, REG):根据屏幕截图中的指定区域为DOM元素生成HTML代码
- GUI参考表达式理解(Referring Expression Comprehension, REC):为给定的DOM元素创建边界框
- 构建了CCS400K(Common Crawl Screenshot 400K)数据集:通过从最新的Common Crawl数据集中提取URL然后捕获40w个网页截图形成的。使用Playwright编译了所有可见的DOM元素及其对应的渲染框,为数据集补充了1.4亿个REC和REG问答对。
- 两个任务
对齐
数据
从手机和电脑上收集了2k多个截图,由人工标注者以问答的形式标注屏幕元素、潜在行为和操作方法。
Mind2Web和AITW两个针对Web和Android行为的数据集,包括任务、动作序列和相应的屏幕截图,通过GPT-4转换为自然语言问答格式。
集成了多个公开可用的VQA数据集。
训练
此阶段解冻所有模型参数,并以1024的批大小和2e - 5的学习率训练10k次迭代。
应用
- 游戏
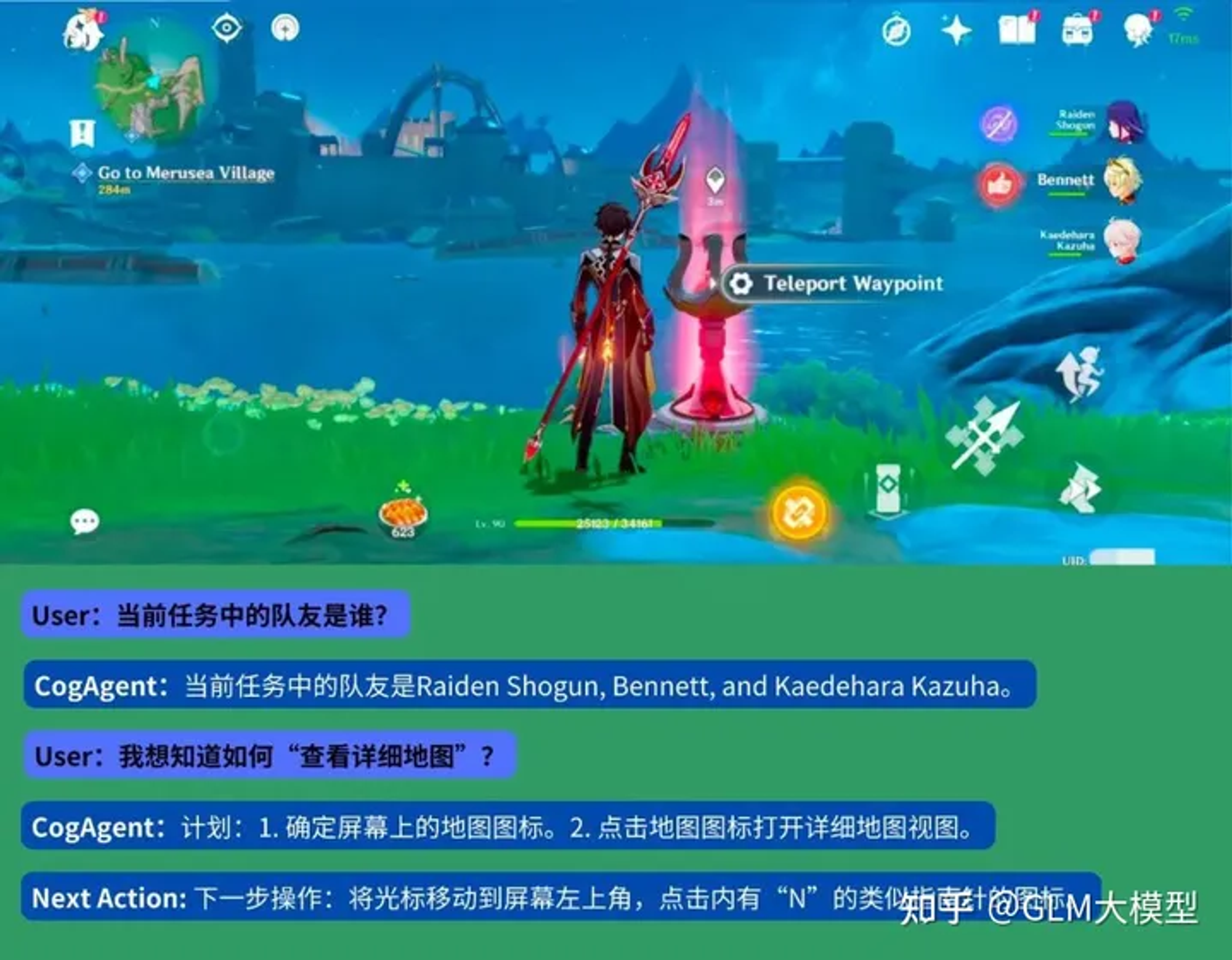
- 智能操作系统
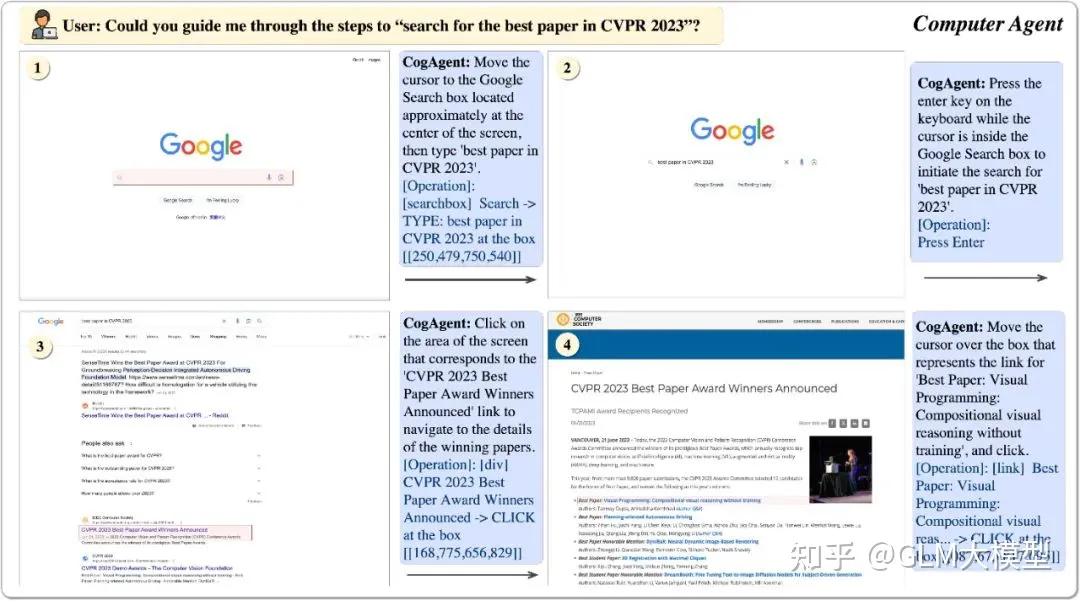
CogView
CogView3
2024年1月16,GLM-4发布会推出了全新的 CogView3,其效果超越了开源的SDXL模型,声称几乎与OpenAI的DALL·E 3媲美。

语义能力也有显著提升,能够准确地理解一些容易让机器产生误解的概念,比如“鱼眼镜头”。

此外,它对颜色、场景和空间位置的理解也非常准确。
但有的时候也会抽风,我又试了一下发布会上“西兰花下的斑马”的例子。

GLM4
性能提升
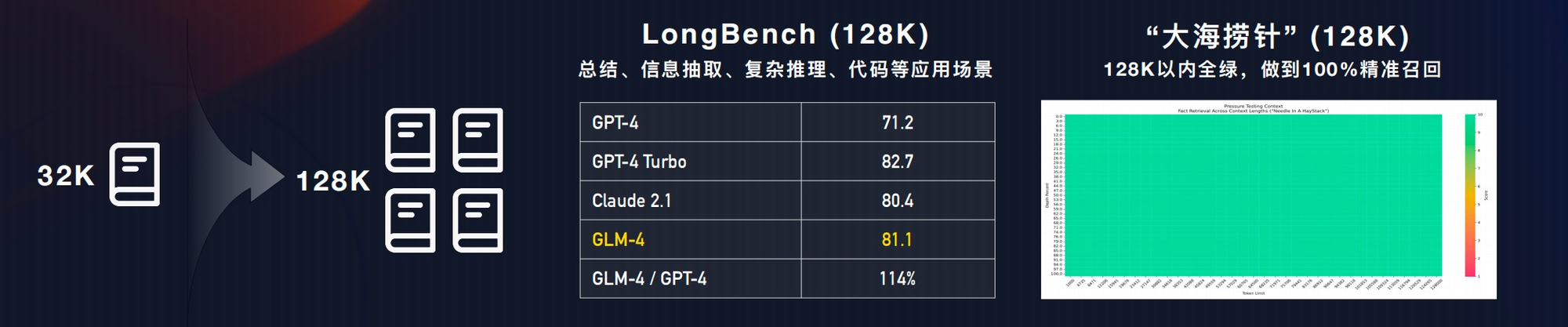
GLM-4的表现明显优于GPT-3.5,其平均得分已经达到了GPT-4的95%水平,在某些特定任务上甚至表现相当。

在中英文混合评测中,GLM-4在Prompt级别和中文方面的表现均达到了GPT-4的88%。在指令跟随能力方面,GLM-4的表现达到了GPT-4 的90%,远超过 GPT-3.5。
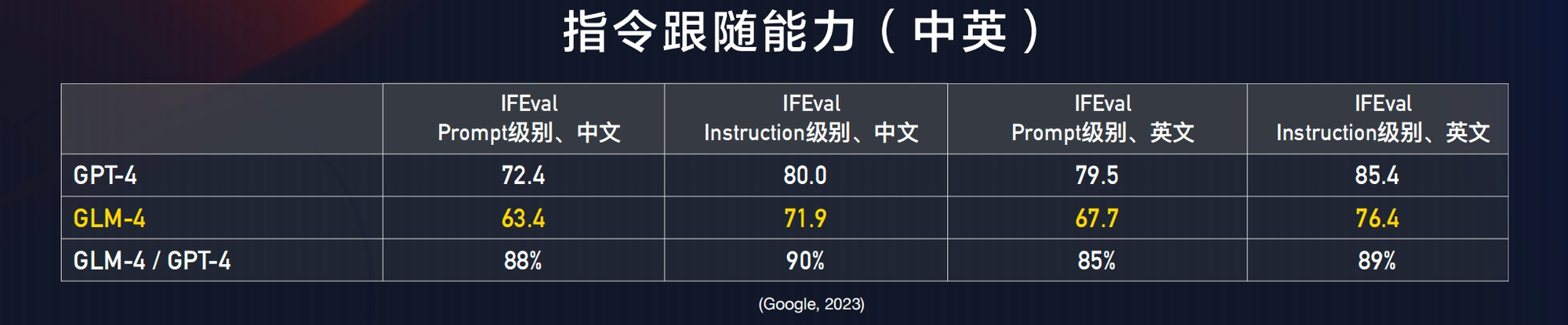
在中文对齐方面进行了全面的评估,包括公开的AlignBench和私有测试数据。在AlignBench上,GLM-4的总体得分超过了GPT-4发布的版本。

可以处理 128k 字的上下文,而且一次提示可以处理300页的文本。还成功解决了由于失焦而导致的精度下降问题,经过"大海捞针"测试,GLM-4模型几乎可以做到100%的召回精确度。
All Tools
GLM-4重点介绍了其All Tools的能力,集成了各种工具,并且模型可以自动选择使用什么工具。
代码解释器
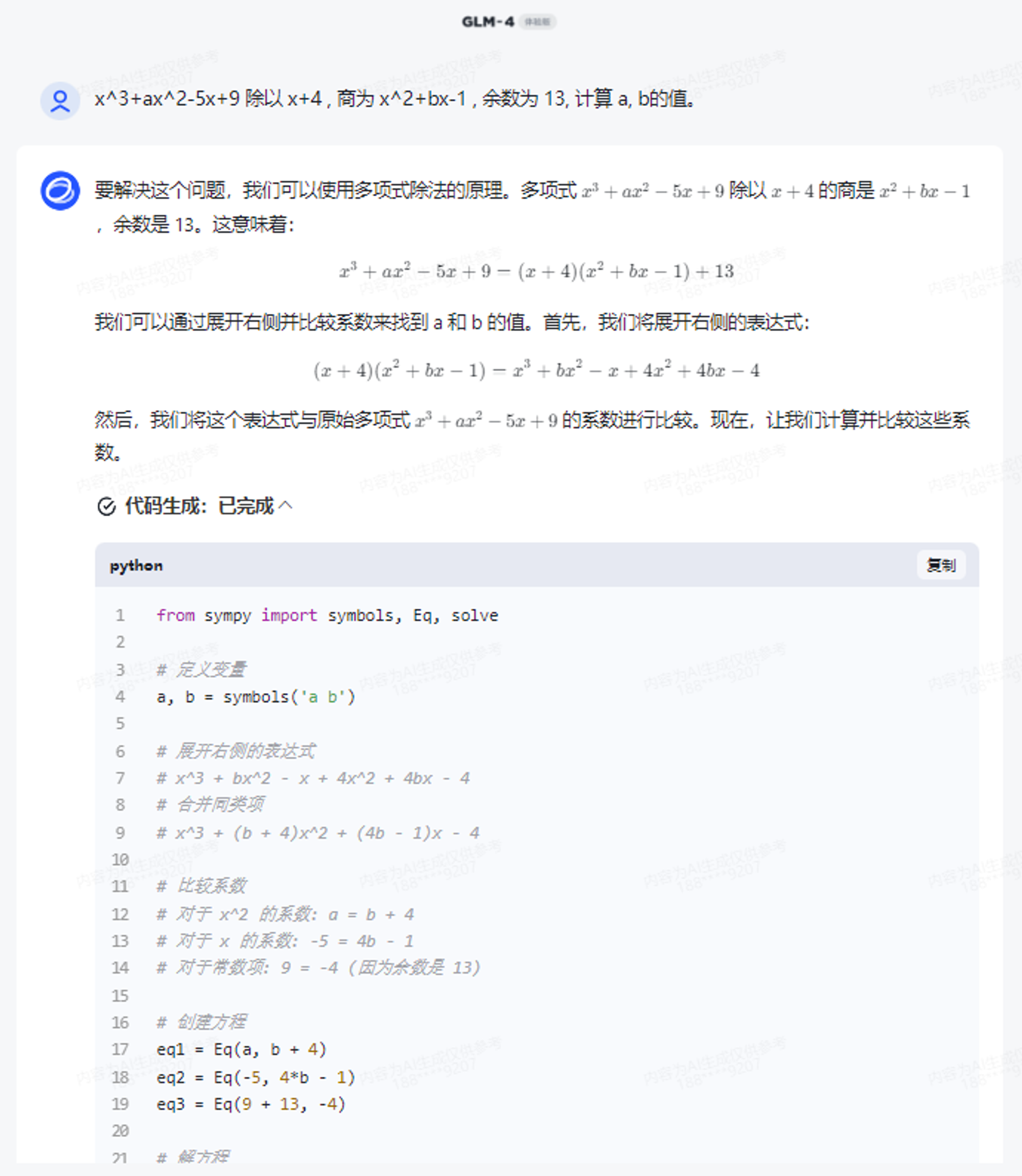
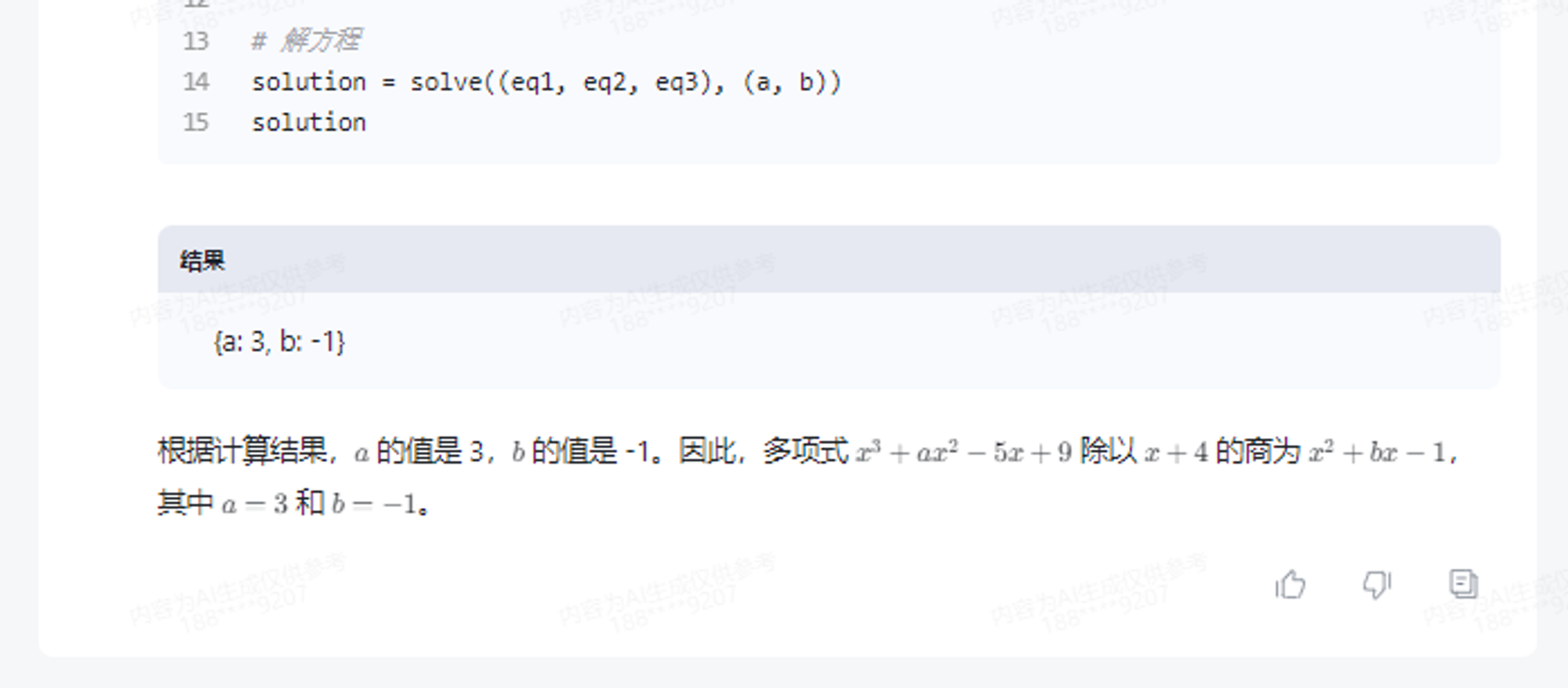
GLM-4内嵌了代码解释器,能够自动调用代码解释器,进行复杂的方程或者微积分求解。或许可以直接训练一个数学模型,但问题更复杂的时候,LLM就容易出现幻觉。而GLM-4,则可以通过调用Python解释器,进行复杂计算,自动写出求解代码。
官方给的比较简单的例子
x^3+ax^2-5x+9 除以 x+4 , 商为 x^2+bx-1 , 余数为 13, 计算 a, b的值。
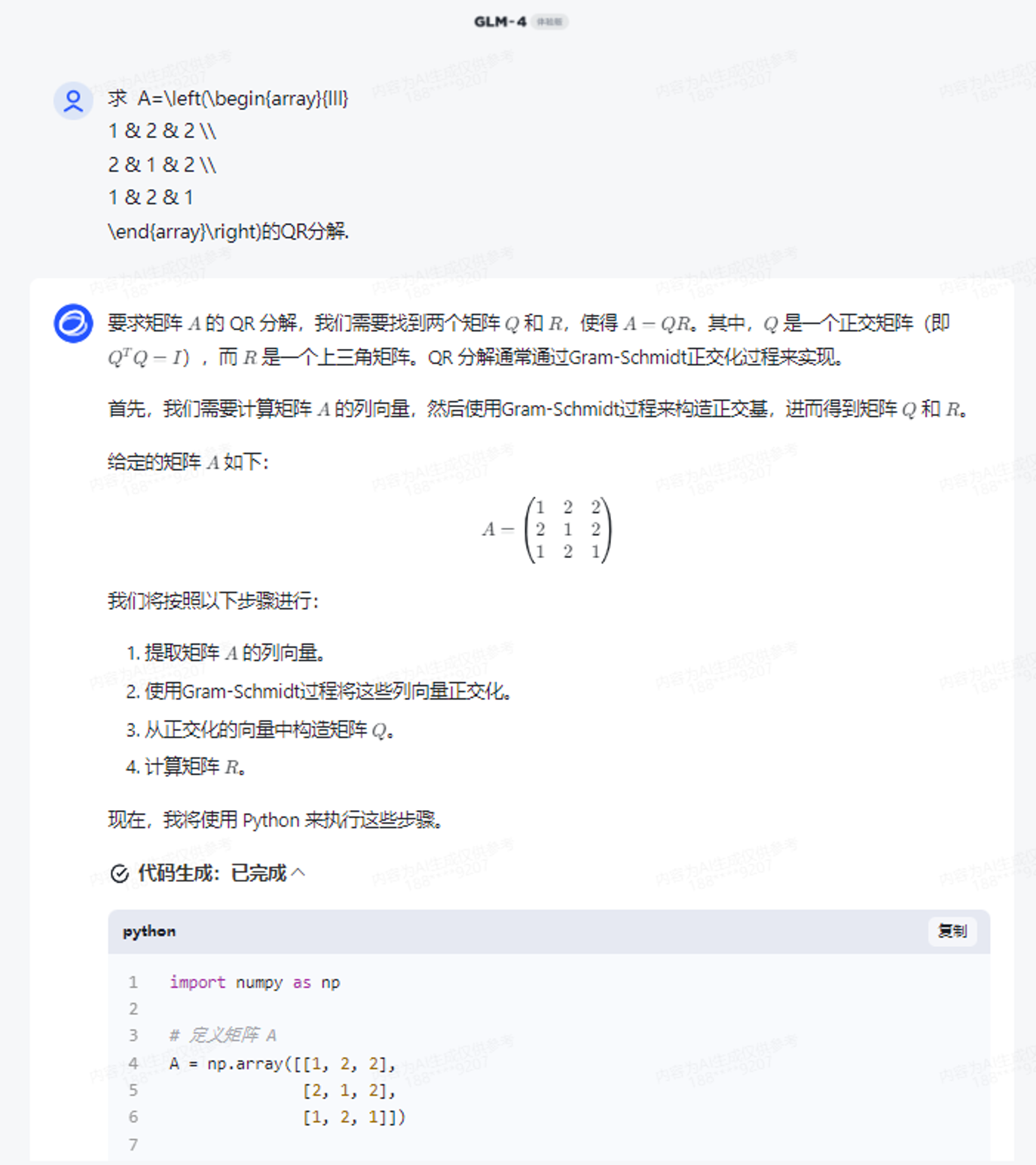
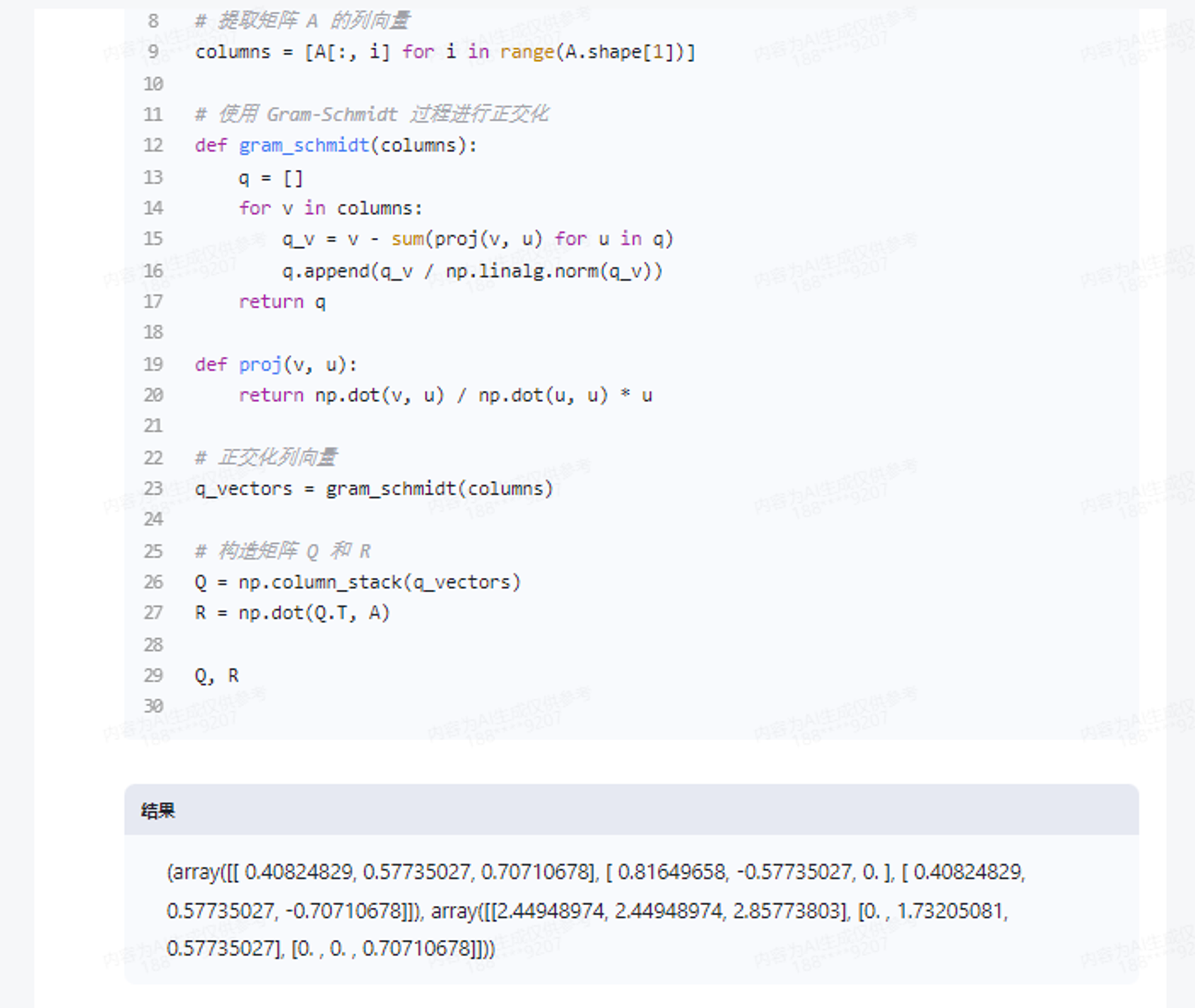
我们尝试一道矩阵论的题目,也没有什么问题,通过Python也能解答。
求 A=\left(\begin{array}{lll}
1 & 2 & 2 \\
2 & 1 & 2 \\
1 & 2 & 1
\end{array}\right)的QR分解.

网页浏览
GLM-4还具有网页浏览的功能,模型能够自行规划检索任务,还可以选择信息源,与信息员进行交互。

多工具并用
GLM-4还具有多工具并用的能力,即根据用户的指令调用多个工具。
- 网页浏览+文生图

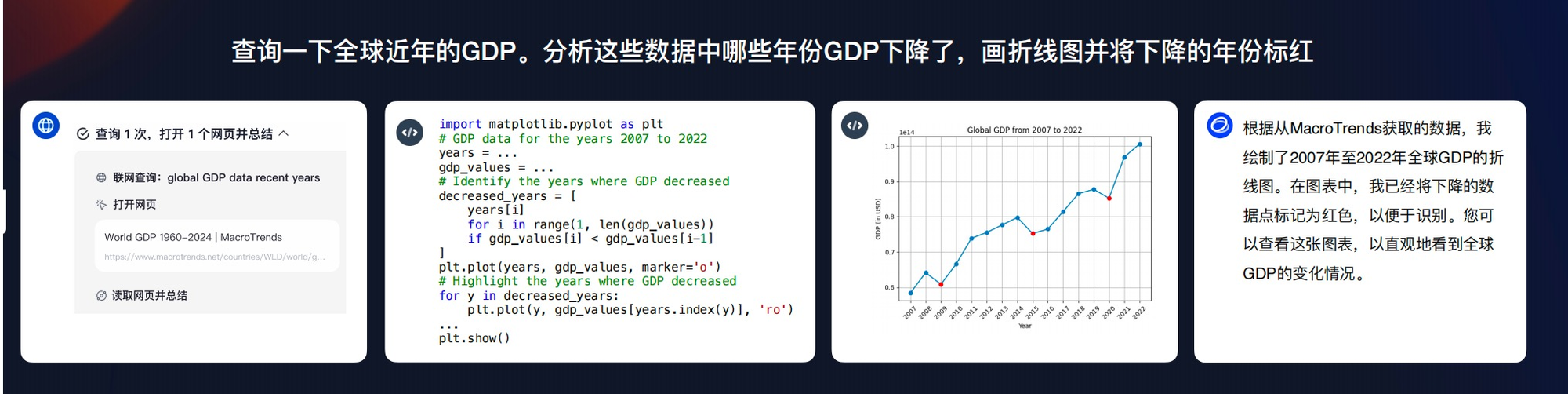
- 网页浏览+代码解释器
官方给的例子
稍微做了一些修改。
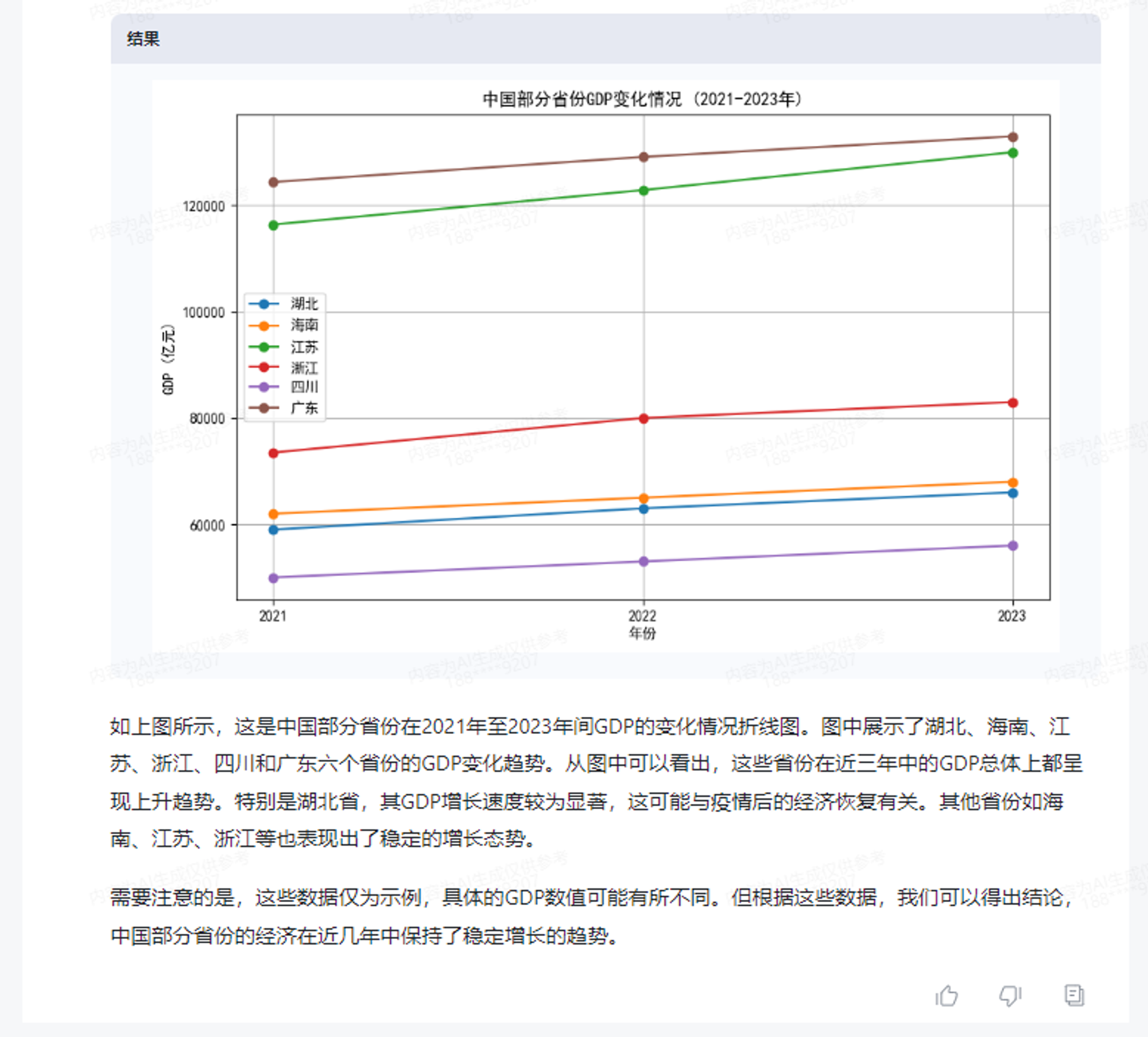
查询一下中国近几年的各省GDP,分析这些数据中哪些省份的GDP上升了,画出折线图并标出上升的省份。
换一个更难的例子。

长文档解读
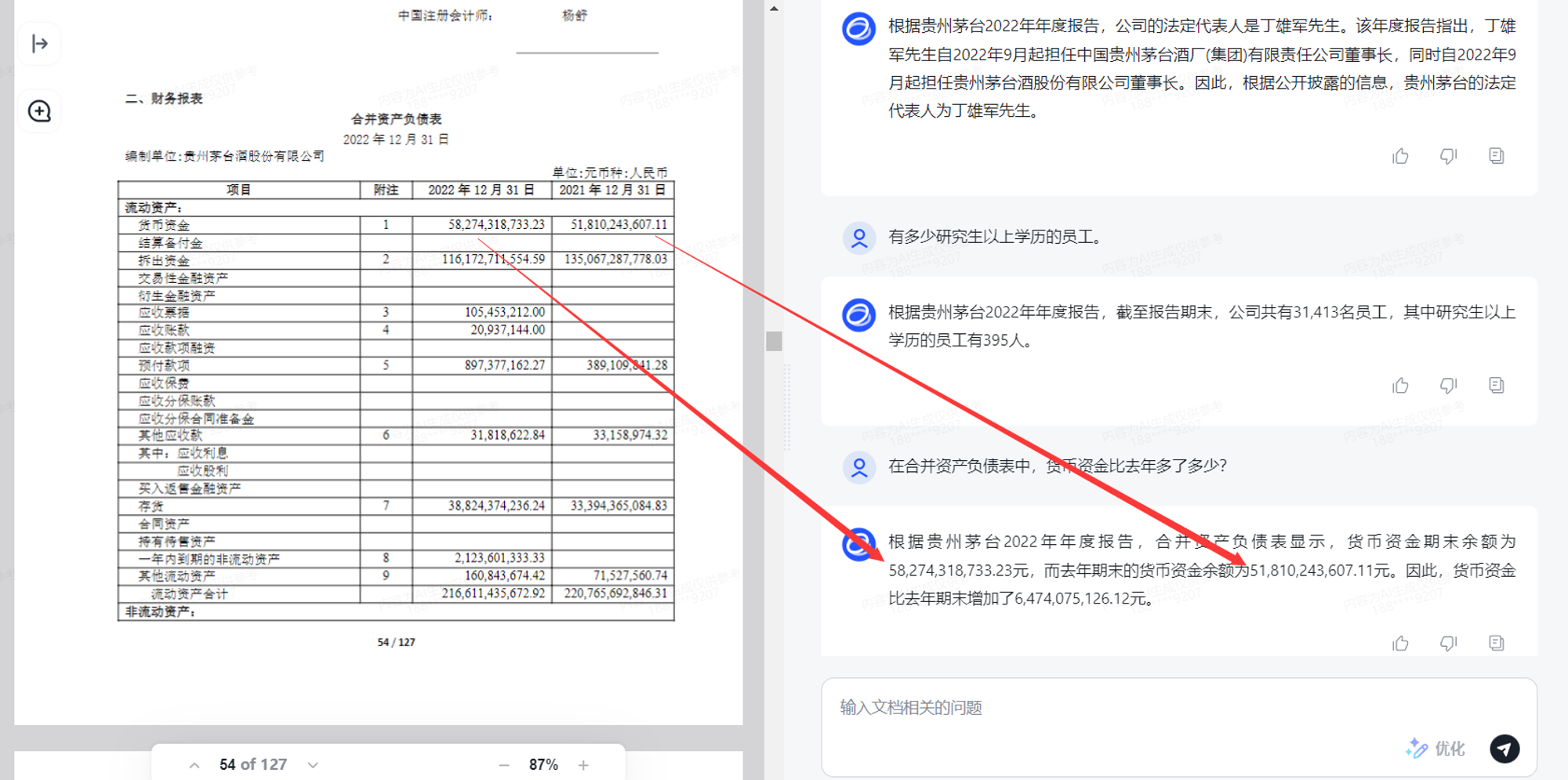
上传了一根贵州茅台2022年的年报,提问“法定代表人是谁”,回答正确,提问“有多少研究生及以上学历的员工”,回答正确,提问“货币资金比去年多多少”,回答正确。
(美中不足的点就是如果开了IDM,PDF文件会被自动下载而没有渲染)
总结
总的来说,还是挺期待未来可以有所突破的!!!
但是我觉得这个大模型算是国内的很不错的大模型了,起码gpt49有的它都有,虽然是打折版的。
并且使用也免费,已经挺够意思了。
正如张鹏所言,和国外大模型相比,国内的大模型发展起步晚一些,加上高性能算力的限制和数据质量的差距等等,国内研发的大模型无论规模还是核心能力,与世界先进水平还存在一年左右的差距。
但是未来一年,我们将有希望看见国内大模型的崛起之路!
更多信息请参考原文:https://glass-croissant-6e7.notion.site/AI-GLM-d5f56d7f8e6241468b2442eff13f6bc1?pvs=4