当键入网址后,到网页显示,其间发生了什么(下)
掘金地址
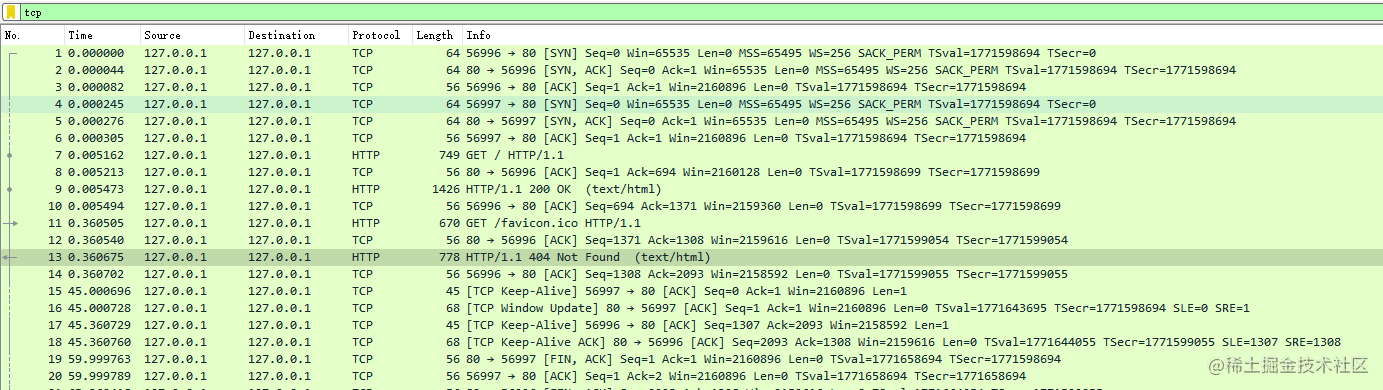
键入 localhost ,通过 Wireshark 抓包分析,抓包结果如下图所示
抓包结果
我们知道 HTTP 协议是运行在 TCP/IP 基础 之上的。 浏览器 通过 HTTP 接收和发送数据,要通过 TCP 建立 可靠连接。
抓包分析
对开始的三个包进行分析 , web 服务器的端口号是 80 ,从 浏览器的端口号 56996
到 80按照 TCP 协议 , 要进行三次握手与Web 服务器进行连接。从抓包结果来看,浏览器到服务器经过三个包 SYN``````SYN/ACK``````ACK之后,浏览器与web服务器建立连接。 出现 56997 是因为长连接的特性。
建立连接之后,浏览器按照HTTP协议制定的规范通过 TCP 协议发送了一个GET HTTP/1.1 的请求报文。之后,80端口—>56996 端口 发送了一个应答ACK(确认已经收到了这个请求报文)这个 ACK在 TCP 层面,所以 浏览器所在的层面 http协议是看不到的。
之后 WEB服务器会根据 HTTP协议 去解析这个请求报文,明白浏览器此时想要进行什么操作。
例如这里 是要获取一个HTML 页面 ,web 服务器 会从 磁盘里 将这个 html 页面读取出来,再拼成 HTTP 报文的格式,相应给 浏览器。返回 HTTP/1.1 200 OK的报文。之后 浏览器 再发送一个ACK应答给服务器,向服务器确认,响应报文收到了。
至此,浏览器收到了响应数据,也就是解析报文。这里服务器返回了一个 html 文件,浏览器就会调用排版引擎处理这个响应数据,展示出相应的页面。

之后 浏览器 会自动请求 favicoon.ico (网站logo)的资源文件,我们没有设置这个图标 , 返回一个 404 Not Found。
由于 长连接 的特性 这里的四次挥手 并没有发生
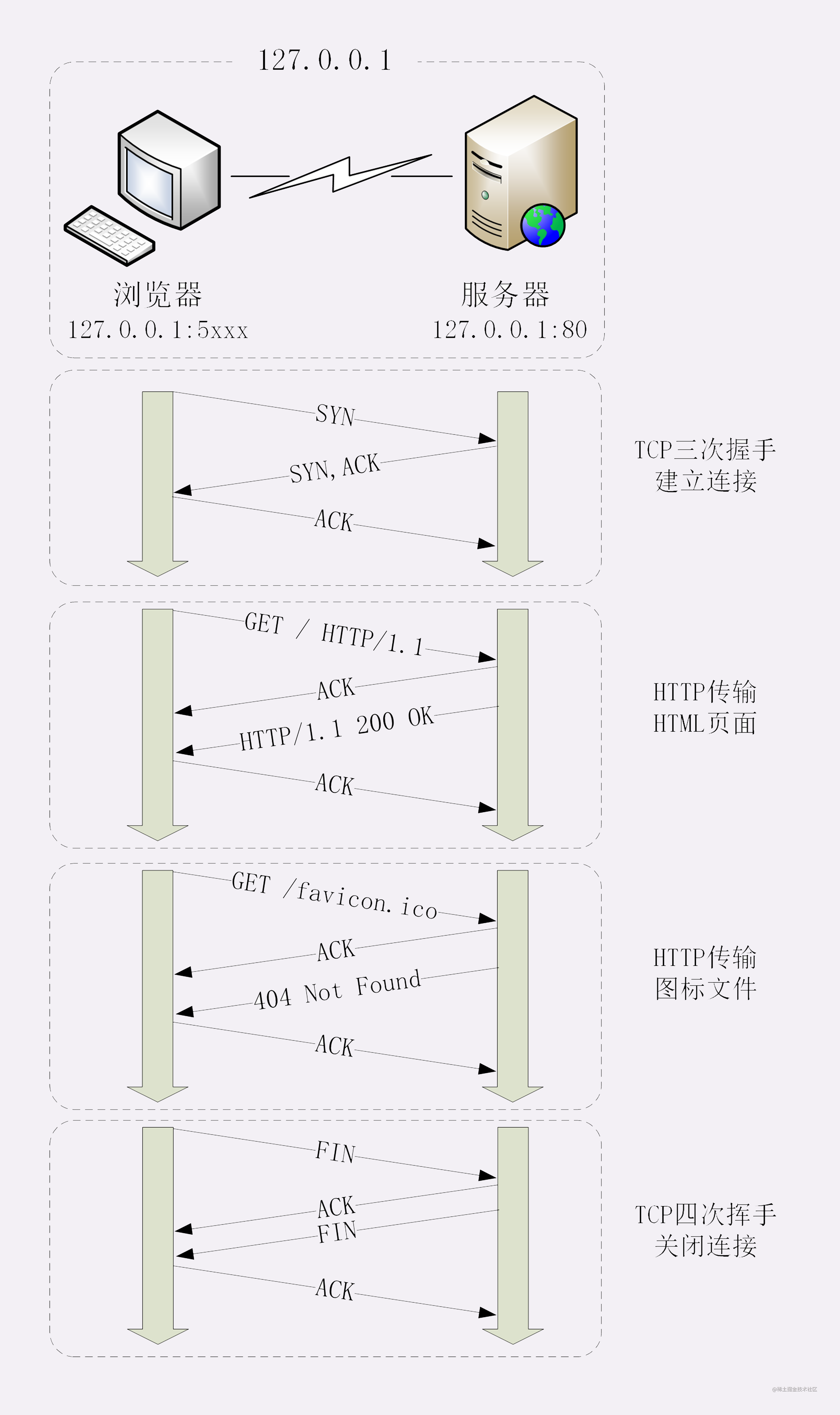
小结 浏览器 HTTP 请求过程
- 从地址栏 输入获得 服务器的 IP地址 和端口号 (通常我们使用域名)
- TCP 三次握手 与 服务器建立连接
- 浏览器发送报文给 服务器 ,告诉服务器他想要干啥
- 服务器收到报文后处理该请求,拼接好报文后返回给浏览器。
- 浏览器解析响应数据。
HTTP 报文结构 (HTTP 协议的核心部分)
HTTP 协议在规范文档里详细定义了报文的格式,规定了组成部分,解析规则,还有处理策略,所以可以在 TCP/IP 层之上实现更灵活丰富的功能,例如连接控制,缓存管理、数据编码、内容协商等等
HTTP 协议 是一个 纯文本 的协议,所以头数据都是ASCII 码的文本,可以很容易地用肉眼阅读,不用借助程序解析也能够看懂。
HTTP 协议规定报文必须有 header,但可以没有 body,而且在 header 之后必须要有一个“空行”,也就是“CRLF”。
HTTP 请求报文结构图 即 解释

解释 :
- 起始行: 表示 请求或响应的基本信息。
- 头部 : key-value 的请示更详细的说明报文
- 空行 : 在 头部 和消息实体之间 规定必须要有一个空行(CRLF “\r\n”)
- 实体 : 实际传输的数据,可以是纯文本,图片,视频等二进制的数据。
抓包 HTTP 请求报文结构示例
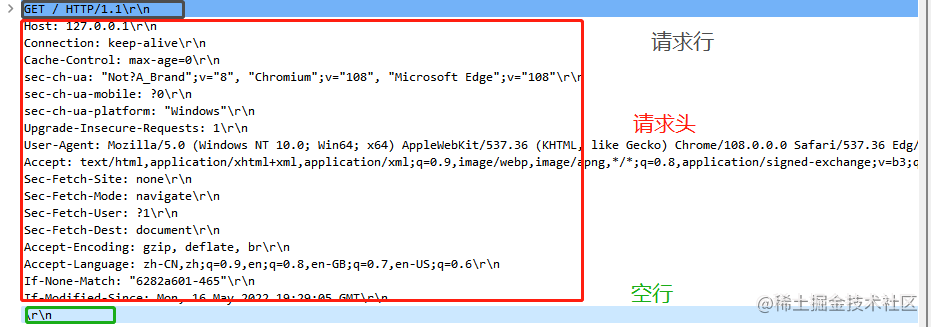
这里的 请求头正确来讲 应该是 消息头
请求行 解释
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HoyXLsnc-1673014149574)(https://p1-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/2a7ca441f87d405ba678125ae0f78ac3~tplv-k3u1fbpfcp-watermark.image?)]
三部分组成 :
- 请求方法 (Method): GET/POST/PUT/DELETE ····· , 表示对资源进行的操作
- 请求目标(URI) : 一个 URI , 标记请求方法要操作的资源 ;
- 版本号 (Version) : 请求所使用的 HTTP 协议版本。
请求行结构 :

三部分连接起来就是(结合上面例子解释) : 浏览器使用 GET方法请求 服务器/ 这个目录下的文件,使用的是 HTTP/1.1版本号 请求,请服务器也用 HTTP/1.1恢复我的请求。
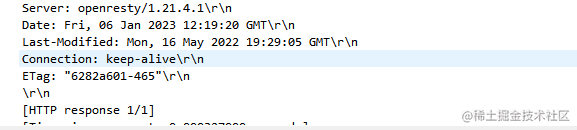
状态行(响应过来的报文的header)解释
抓包结构示意

状态行 : 服务器响应的状态
三部分组成 :
- 请求版本号 : 响应所使用的 HTTP 协议版本。
- 状态码 : 一个三位数 , 表示处理的结果。在 HTTP_DAY01 说明了各种常见状态码的解释。
- 原因 : 数字状态码的补充说明,翻译前面的数字,帮助我们理解状态码的含义。
三部分连接起来就是(结合上面例子解释) : 这个请求我收到了,使用的HTTP协议号是 HTTP/1.1 , 状态码是 304 ,自你上次访问以来,你所请求的资源在我的缓存区并未修改,你到本地所保存的网页里找吧☺。
头部字段
头部字段 加上 请求行/状态行 就形成了 请求头/响应头
抓包示例
特点 :
- 由 key - value 组成 最后用 CRLF 结束
- 非常灵活,可以任意添加自定义头,可扩展性强。
注意点 :
- key 不区分大小写
- key 写的时候 不能用
_或者space字符 - key 后必须紧跟
:,不能有space(如果出现space, 会出现400 Bad Request),而 value 前的space可以任意多 - key 顺序无意义
- key 理论来讲不能重复
HTTP 头部重复了,会怎么样?
这种情况在规范内尚未明确,根据浏览器内部处理逻辑的不同,结果可能并不一致。
有些浏览器会优先处理第一次出现的首部字段,而有的浏览器则会优先处理最后出现的首部字段。
HTTP 常用的 key
- 通用 key : 请求头 、 响应头 都可以有。
- 请求 key : 只能出现在请求头中,对请求信息的补充。
- 响应 key : 只能出现在响应头中,对响应数据的补充。
- 实体 key :专门描述 body 的 额外信息。
HTTP 对报文的解析,实际上就是对头字段进行处理。
最基本的头部字段
- HOST : 请求key 必须出现,没有他 就会 bad request. 相当于 路由重定向。
- User-Agent : 请求key,服务器可以根据他返回最合适的页面。但由于历史原因,变得毫无意义。可以实现简单的返爬虫策略。

- Date : 通用key, 但通常只出现在 响应头中,表示HTTP 报文创建的时间,客户端通过使用这个时间,搭配其他头部字段,决定缓存策略。
- Server : 响应 key ,告诉客户端 是谁在给你提供web 服务。 不必要出现 , 可能导致安全隐患,通常 不要这个字段 , 或者 给他一个 垃圾信息 。
- Content-Length : 通用key,body的长度(请求头或者响应头CRLF后面数据的长度),服务器看到这个字段,知道数据长度,可以直接接收,如果没有,就是不定长, 就要 开启 chunked 方式分段传输。