分享嘉宾 | 陈艺虹
文稿整理 | William
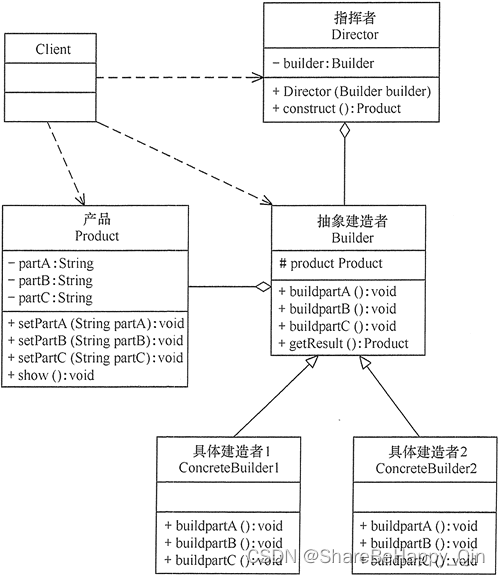
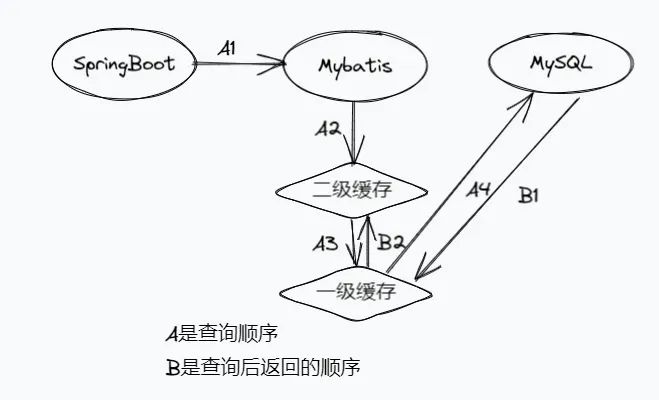
Knowledge Graph Completion(KGC)
知识图谱一般会有多个节点,包括性别、国家等各种各样的节点(也可理解为实体),节点之间会有不同的关系,可以通过其他的一些节点预测出当前节点的其他信息。恢复这些信息是将所有的候选信息进行排序,优化如下损失函数,再按最大似然概率得到推荐信息。
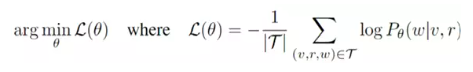
Factorization-based Models vs Graph Neural Networks for KGC
知识图谱补全一般有两类模型:
第一种是factorization-based models,如图1左边所示。非常简单的几个矩形合在一起,竖着的长方形代表subject in bedding,横着的长方形代表object in bedding,蓝色的则是relation in bedding,将各个之间的关系进行嵌入后内积相乘,即可得到结果。值得注意的是K表示隐藏向量长度。
该类模型的推理效率非常高,在一些常用的计算平台上部署起来非常简单。最大的问题若一个新的节点在当前图谱里找不到对应节点,则模型无法使用。
第二类是graph neural networks for KGC,如图1右边所示。直接是message图,通过不同节点的计算流图画出方向,不同的颜色代表不一样的类型。有两个可以自行设计的地方:
①接受信息的是可学习的方式,可以设计几个特征学习层
②可以利用求和或平均池化等操作集合信息到中央节点
该类模型的优点是即使存在一个新的节点,也能进行预测,此外还会计算考虑节点信息以及neighborhood信息。但问题在于预测的效果不好,而且很难去扩展到比较深的图神经网络。

图1 知识图谱补全的两种类型
Implicit Message-Passing within FMs
FM的优化过程会包含一些隐式的message传递,但如果把优化过程加入到表达式里面,可以看到message传递后梯度优化的过程:当开始优化时,从邻居节点拿属性进行更新中心节点,然后所有邻居节点都会更新,会出现向外的neighborhood(表示为+)和向内的neighborhood (表示为-),同时全局正则化也会计算相加。拿如果进行第二次梯度更新,就会得到类似的第二层message passing,以此类推,如图2所示。
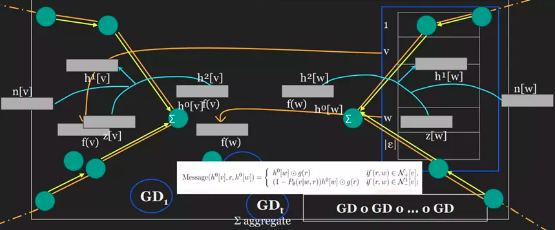
图2 FMs的隐式消息传递
The ReFactor GNN
每一个guardian decent其实包含了一个message passing layer,那可以创建一个新的图神经网络来捕捉这种消息传递机制,不同的方向会有不同的消息,重要的是不同的边的类型会被考虑。如果把factorization best models的梯度下降优化过程实现成一个message passing layer,可以直接把指针分解的梯度优化过程写入message passing lay里面,就可实现了一个message part。
优化训练如图3所示,橙色区域代表运算的memory,当需要从memory里面读取相应的节点,可以直接抽取再送进message passing layer,然后进行更新,得到下一层。当得到结果的时候,只要把它写回到memory里面。如果下一轮某一条边或某一个节点的更新需要当前节点状态的时候,就可以直接提取,而不用从零去重新计算,即可实现计算的高效性。

图3 优化训练框图
计算效率高有如下作用:
(1)可以用一个储存神经网络去逼近一个张量分解模型的性能
(2)可以将其扩展到更深层网络,提高模型性能
(3)使得添加层数变得比较简单,global regulation也比较好
(4)可以用到其他的知识图谱以外的学习上
Experiments over Inductive KGC
先简单介绍实验里面用到的一些baseline:
第一个是完全不做pretrain,意义在于能有效的比较得出不同节点特征的有效性
第二个是一些Rule-based的方法,比如Neural-LP,DRUM,Rule-N
第三个是重点的图神经网络模型,能检测不同的层数会如何去影响它的性能
第四个是Pairwise的图神经网络,比如GralL,LNBFNet
将只有random feature和只有meaningful的texture feature的文本信息送进预训练的语言模型,将其输出来作为节点特征,其余模型的操作一样,这些网络最后的性能表现如图4所示。
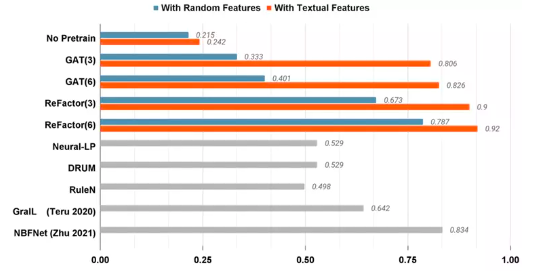
图4 模型性能对比
可以发现预训练模型对random feature的性能有0.215,对有意义的texture feature有0.242,差别不是很大。图神经网络将文本信息用的淋漓尽致,当是random feature时只有0.33,性能比较差,但当输入为有意义的texture feature,则性能可以达到0.8,不顾图神经网络的层数与性能没有太多的关系。ReFactor的性能对比与图神经网络差不多,不过在random feature会比图神经网络高0.35左右。GralL是第一个开始做该方法的测试,性能表现不错。





![[VP]河南第十三届ICPC大学生程序竞赛 L.手动计算](https://img-blog.csdnimg.cn/adace8a661994a7898be25677db546a2.png)
