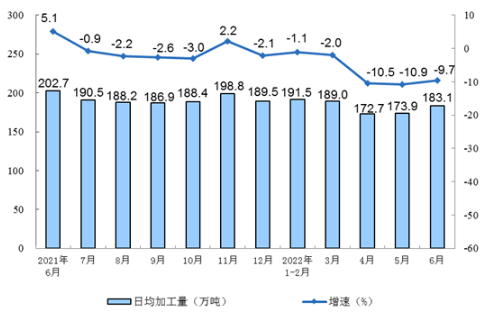
最近学习了spark sql执行流程,从网上搜到了大都是sql解析、analyzer、optimizer阶段、sparkplan阶段,但是我比较好奇的是,这几个阶段是怎么串起来的,于是花了好几天着重从源码层面看看了看具体实现,写了几点自己认为应该注意的地方。
1、command命令的执行过程
spark sql的命令主要分为两种形式:command和普通DML操作。
command从源码测可以看到它属于logicalPlan阶段
从官方文档的解释可以看出,它处理主要是show databases;use ;create table;alter table等 DDL的操作。
它的主要继承子类为RunnableCommand,在它的子类LeafRunnableCommand的具体实现中可以看到DDL的一些命令。
但是我看这些command的时候,发现一些百思不得其解的事情。
![]()
这个RunnableCommand的核心方法为run方法,可以看到它的返回值为Seq[ROW], 并不是我所认为的sparkPlan。
不是说,所有的logicalPlan都要转为sparkPlan,然后再启动spark任务吗?这里为什么没有呢?
后来我查资料的时候,发现org.apache.spark.sql.execution.command.commands.scala文件中存在以下两个trait. ExecutedCommandExec和DataWritingCommandExec
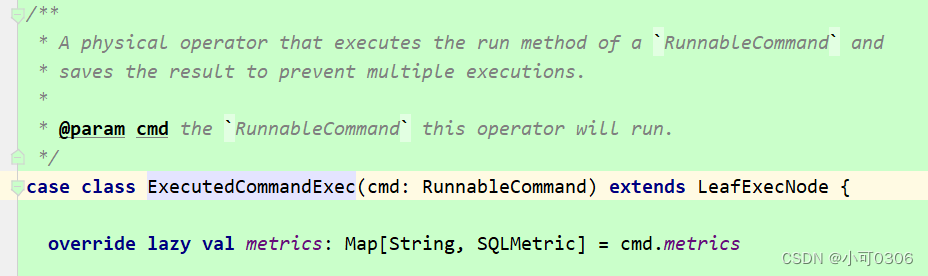
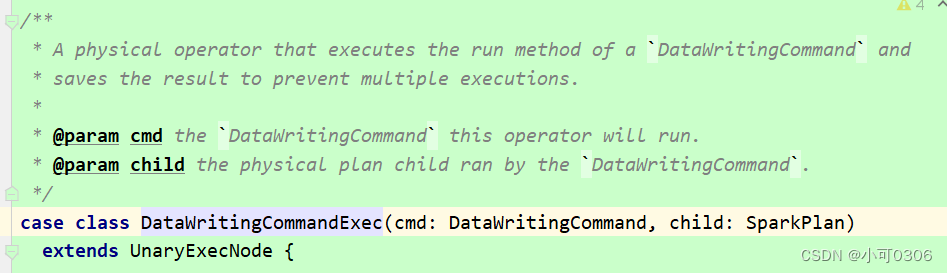
在SparkStrategies.scala文件的BasicOperators strategy中使用了这两个类。

这个BasicOperators在sparkPlanners中进行了定义。
这里就明白了,也就是说大部分的command命令,他们使用的strategy是默认的。也就是说这里并不违背所有logicalPlan必须在sparkPlan里面才能执行的要求。
2、catalog体系
spark3当前里面分为两种catalog,sessioncatalog,v2sessioncatalog。
它们都由CatalogManager来进行管理。
v2SessionCatalog主要是为了解决multi catalog准备的,需要在配置文件中新增自定义的数据源。
用户需要实现新增的TableCatalog中提供的方法,去访问自己的表、namespace等元数据信息。
这些catalog是如何使用的?
analyzer阶段的构造函数为catalogmanager;
optimizer阶段也会使用catalogmanager;
在物理执行计划阶段也会使用catalogmanager;
![[VP]河南第十三届ICPC大学生程序竞赛 L.手动计算](https://img-blog.csdnimg.cn/adace8a661994a7898be25677db546a2.png)


![[总结] DDPM Diffusion模型各阶段训练和采样过程方案细节和代码逻辑汇总](https://img-blog.csdnimg.cn/54423ce28df744f3941eaa8e73ea957e.png)