java前端编译器和后端编译器的作用
Java前端编译器:javac 编译,在程序运行前,将 源文件 转化为 字节码 即 .class 文件
Java 程序最初只能通过解释器解释执行,即 JVM 对字节码逐条解释执行,因此执行速度比较慢。
字节码与平台无关
Java后端编译器:JIT 编译,在程序运行期间,将字节码转化为机器码
机器码与平台相关
JIT 即时编译 Just In Time
当 JVM 发现某个方法或代码块执行特别频繁时,就将其认定为 热点代码(Hot Spot Code)。在程序运行期间,JVM 将这些热点代码编译为与本地平台相关的机器码,并进行各层次的优化,从而提升热点代码的执行效率。
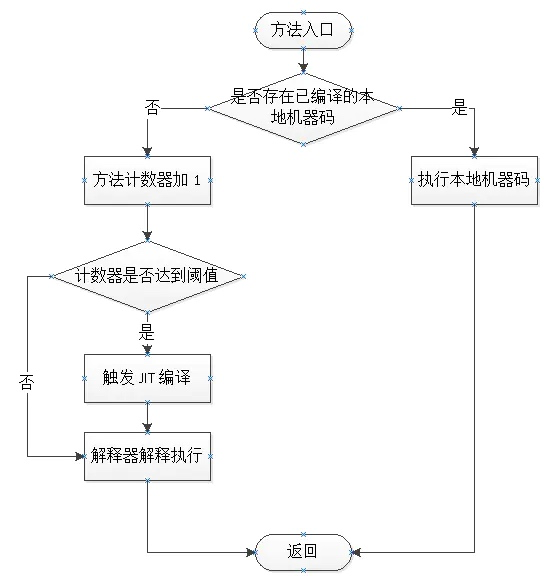
如何检测热点代码(Hot Spot Code):
基于 采样 的热点检测:检查各个线程的栈顶。
基于 计数器 的热点检测:HotSpot 虚拟机采用:
方法计数器:统计每个方法调用的次数
回边计数器:统计每个方法中循环体代码执行的次数
JIT的设置及优化
初级调优
HotSpot 虚拟机内置两个 JIT 编译器:
客户模式 Client Compiler,即 C1 编译
无采样,立即 JIT 编译,轻量优化
JIT 编译的类较多,可能导致代码缓存不够用
速度较快,适用于短暂的应用程序
服务器模式 Server Compiler,即 C2 编译
采集一万次调用样本后深度编译优化
JIT 编译的类较少
启动速度较慢,运行起来后性能逐步提升
每次 GC,计数器衰减一半
可以设置 -XX:-UseCounterDelay 来禁止衰减
Java 8 支持多层编译,即程序启动时使用 C1 编译,样本足够后使用 C2 编译:
禁止多层编译:-XX:-TieredCompilation
启用多层编译:-XX:+TieredCompilation
优化代码缓存
如果缓存过小,有些热点代码可能不会被 JIT 编译。
C1 编译的类较多,可能导致代码缓存不够用。
设置代码缓存大小:-XX:ReservedCodeCacheSize = 32m
编译阈值
即计数器的阈值,默认为10000,即方法计数器和回边计数器的总和达到了10000就触发 JIT 编译。
设置编译阈值:-XX:CompileThreshold = 10000
内联 Inline
将方法的代码复制到发起调用的方法里,以消除方法调用。
因为调用一个小方法可能比直接执行该小方法对应的代码更耗时。
-XX:MaxInlineSize=35byte:能被内联的方法最大字节码大小
-XX:FreqInlineSize=325byte:频繁调用的方法能被内联的最大字节码大小
如何让方法更容易被内联:拆分不常访问的路径。例如:
public void f() {
if(most case) {
...
}
else {
... // 将不常访问的路径的代码拆分到函数 g() 中
... // 以降低整体代码的大小,使得 most case 中的代码可以被内联
}
}打印 JIT 编译信息
java -XX:+PrintCompilation -XX:+UnlockDiagnosticVMOptions -XX:PrintInline > a.out