深度剖析数据在内存中的存储
- C进阶:数据在内存中的存储
- 深度剖析数据在内存中的存储
- 数据类型介绍
- 类型的基本归类
- 整型家族
- 浮点数家族:
- 构造类型:
- 指针类型:
- 空类型:
- 整型在内存中的存储
- 原码、反码、补码
- 原码反码补码的相互转换
- 整型数据的取值范围计算
- 大小端字节序的介绍
- 大小端字节序的引入
- 大小端字节序的概念
- 为什么要有大端和小端之分
- 大小端的一道练习
- 浮点数在内存中的存储
- 常见的浮点数
- 浮点数存储的引入
- 浮点数存储规则
C进阶:数据在内存中的存储
深度剖析数据在内存中的存储
本章内容其实更像是一种修炼内功,其实并不一定会考或者怎么样,但是绝对能够让我们的知识面更广,对知识的理解加深,看一些代码能够理解的更加深刻,也可以说提高我们的编程素养。
本节内容重点有以下几个方面:
1.数据类型详细介绍
2.整型在内存中的存储:原码、反码、补码
3.大小端字节序判断以及介绍
4.浮点数在内存中的存储解析
数据类型介绍
我们已经学过了基本的内置类型:
char 字符类型
short 短整型
int 整型
long 长整型
long long 更长的整型
float 单精度浮点数
double 双精度浮点数
要知道的有:
- 它们每个占内存存储空间的大小
类型的意义:
- 每个类型开辟内存空间的大小决定了使用范围
- 决定了看待内存空间里数据的视角
类型的基本归类
整型家族
整型家族有以下类型:
char:(下面解释为什么char类型归到整型家族)
- unsigned char
- signed char
short:
unsigned short[int]
signed short[int]
int:
unsigned int
signed int
long:(长整型不一定比整型长,范围是大于等于)
unsigned long[int]
signed long[int]
long long:
- unsigned long long[int]
- signed long long[int]
括号里的int是可以省略的,也就是说:

这里还有值得注意的就是char也是归在整型家族里面,这里肯定会有人有疑问,我们来解释一下,还记得我们一开始学C语言就提到的那张ASCII码表吗,里面记录了每个字符的ASCII码值,我们说过计算机中其实是只有0和1两个数字的,为了存储数据我们是为每个字符编了一个值,用这个值来代表字符用来存储。说到这里我想你就理解了为什么char类型要归到整型家族里面,就是因为char类型本质是以ASCII码值来进行存储的。
浮点数家族:
浮点数家族就比较简单了:
- float
- double
只有float和double两种,但是你先不要高兴的太早,实际上浮点数的存储是要比整型存储更复杂的,我们后面会详细分析。float和double这两种类型具体区别下面也会解释。
构造类型:
构造类型有:
- 数组类型
- 结构体类型 struct
- 枚举类型 enum
- 联合体 union
指针类型:
- int* pi
- char* pc
- float* pf
- void* pv
空类型:
void表示空类型,也叫无类型。
通常用于函数的返回类型,函数参数,指针类型。
接下来就是我们要学习的重点了,整型和浮点型在内存中的存储。
整型在内存中的存储
我们知道一个变量的创建是要在内存中开辟空间的。空间的大小是根据不同的类型而决定的 。
我们今天要重点学的就是数据在开辟内存中到底是如何进行存储的。
原码、反码、补码
计算机中有三种表示二进制的方法,即原码、反码、补码。
三种表示方法均有符号位和数值位两部分,符号位用0表示正,1表示负。而数值位正数的原反补码均相同。
负数情况稍微有点复杂,
- 原码:直接将数值按照正负数的形式翻译成二进制即可。
- 反码:原码符号位不变,其他位按位取反即得到反码。
- 补码:反码+1得到补码。
在计算机系统中,数值一律按照补码来进行存储,整型也不例外。
原因是:
原因在于,使用补码,可以将符号位和数值域统一处理;
同时,加法和减法也可以统一处理(CPU只有加法器);
此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
计算机是计算不了减法的,当我们用原码来计算时,会发现出问题了,
例如1+(-1),

关于原码反码补码的一些相关知识,例如计算等等,我在之前的博客中有详细解释过,需要的可以自行点击链接查看,
C语言操作符大全(其二),隐式转换,整形提升,结构成员,算术转换,保姆式解析_比昨天强一点就好的博客-CSDN博客
C语言操作符大全(其一),细致讲解,C语言底层逻辑剖析,保姆式解析_比昨天强一点就好的博客-CSDN博客
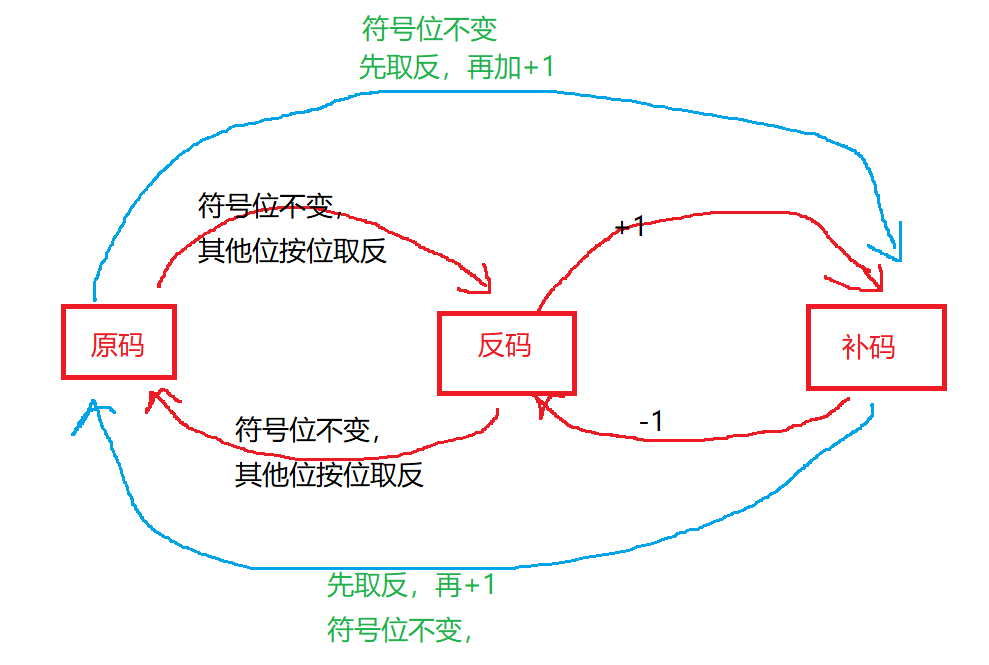
原码反码补码的相互转换
原码反码补码的相互转换可以用一张图来表示:
整型数据的取值范围计算
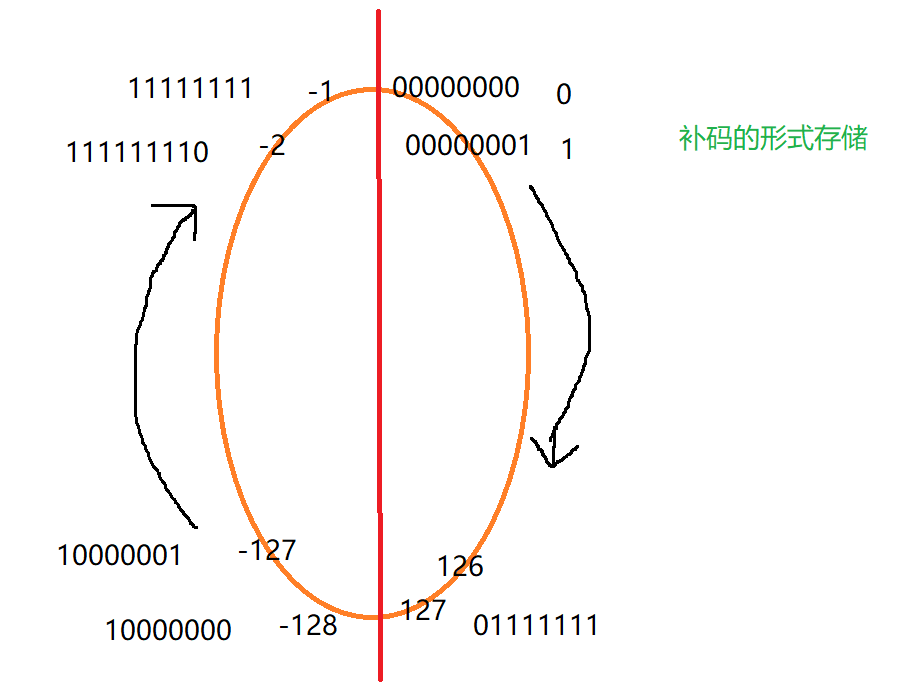
我们以char类型为例,介绍一下数据类型的取值范围是怎么计算出来的:

上图就是char类型的取值范围怎么就算出来的。还有一个有趣的图来帮助记忆。
大小端字节序的介绍
大小端字节序的引入
我们可以定义两个变量查看一下内存中的情况,
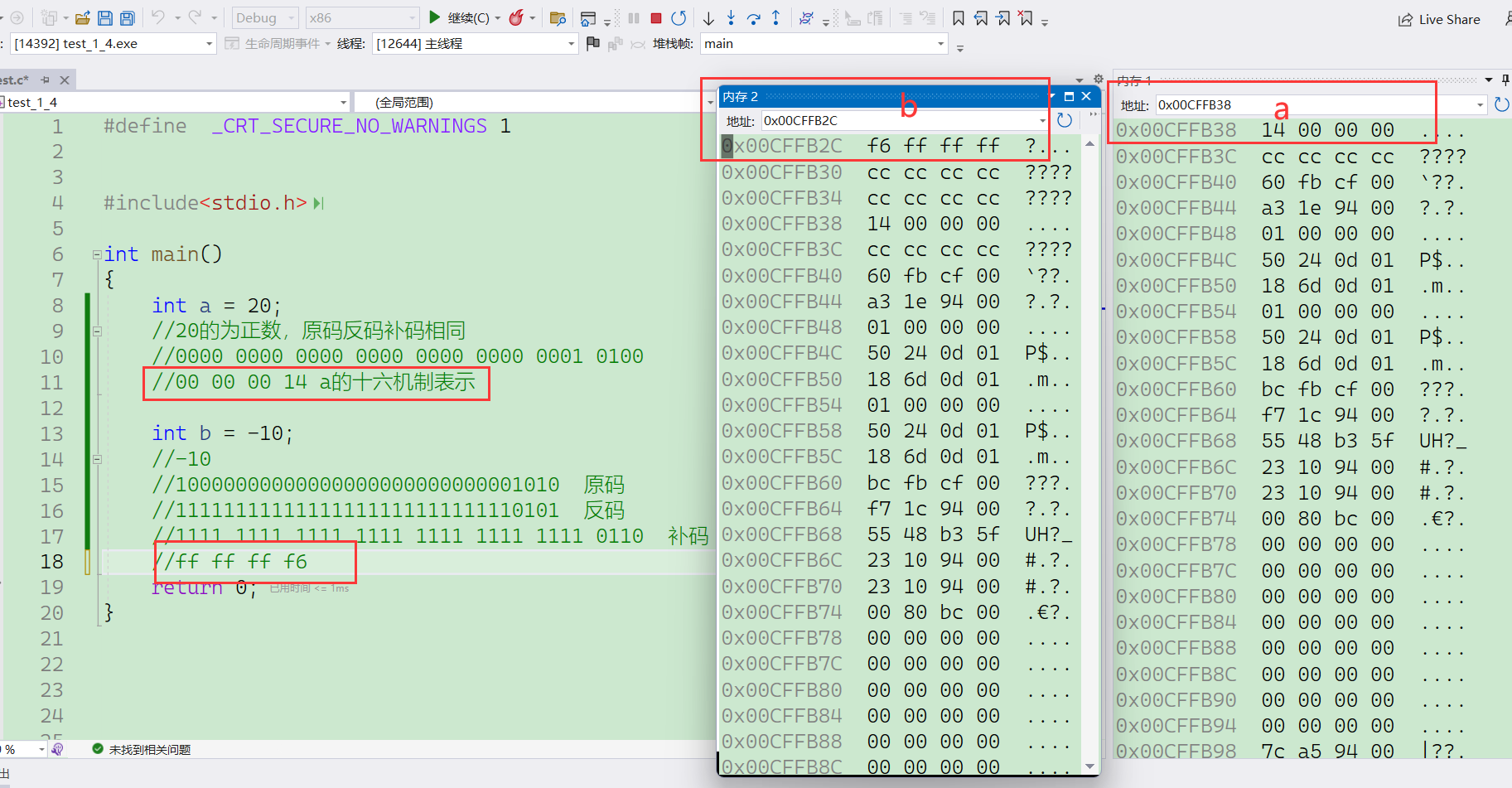
我们将二进制转化为十六进制去查看内存中的数据可以看到是正确的,但是似乎又有点问题,为什么是倒着放的。这就要引出下面我们要学到的大小端字节序了。
大小端字节序的概念
什么是大小端?
- 大端字节序存储是指以字节为单位,把数据的高位放在内存的低位地址(低地址)中,把数据的低位保存在内存的高位地址(高地址)中。
- 小段字节序存储是指以字节为单位,把数据的高位放在内存的高位地址(高地址)中,把数据的低位保存在内存的低位地址(低地址)中。
初看概念似乎有些难以理解,数据的高位低位,内存中的高地址低地址,我们可以通过下面一个图来理解一下。
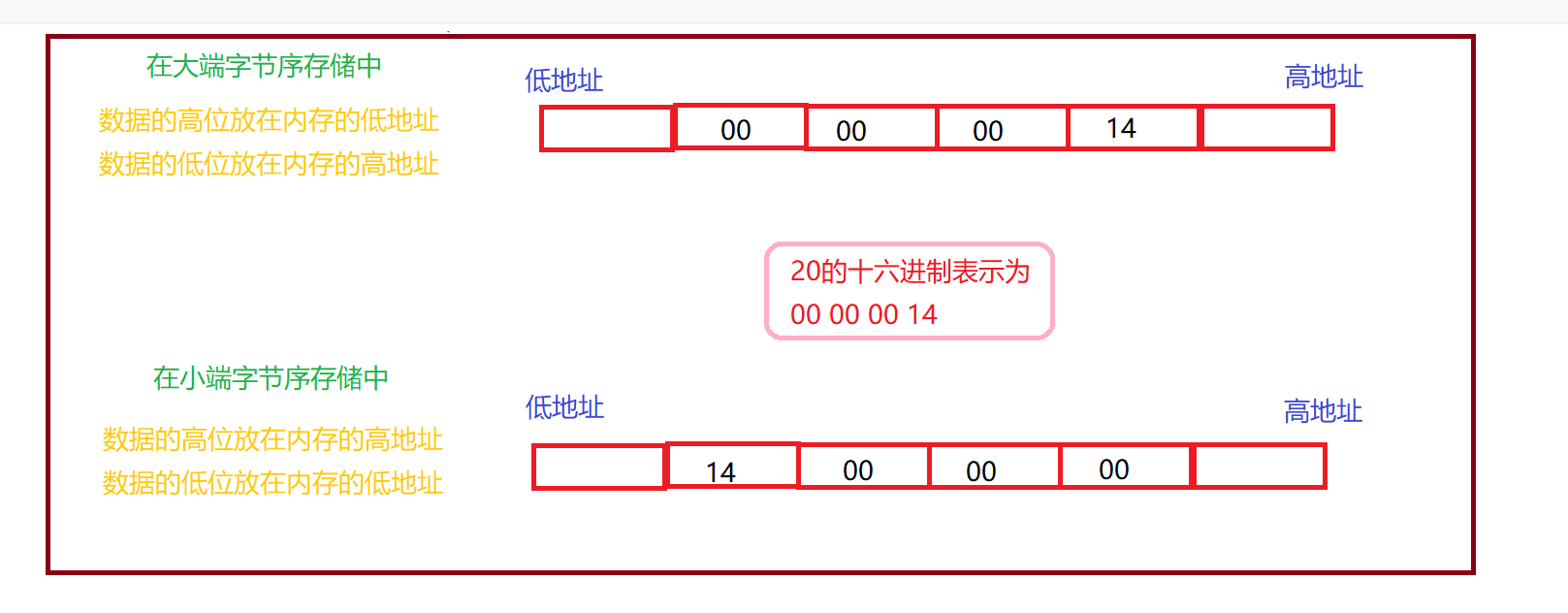
这样我们就理解了,大小端字节序存储到底是个什么东西,并且我们还知道了我们使用的机器是小端存储,一般情况下我们大部分常见的主机都是小端存储模式,而大端字节序主要应用在服务器上,大小端字节序就是用来存放数据的两种方式,数据一定是按照字节为单位存储的,其实本质上来说,甚至可以把乱序存放每一个字节的的数据,但是如果你乱序放入,当你用的时候,还得能够拿出来才可以,那么对于乱序就不太友好了,所以我们最终是采用了这两种方式,那么为什么是这两种而不是只留下一种呢。
为什么要有大端和小端之分
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8 bit。但是在C语言中除了8 bit的char之外,还有16 bit的short型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如:一个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为高字节, 0x22 为低字节。对于大端模式,就将 0x11 放在低地址中,即 0x0010 中, 0x22 放在高地址中,即 0x0011 中。小端模式,刚好相反。我们常用的 X86 结构是小端模式,而 KEIL C51 则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
这些看一下了解即可,不理解也没关系。就是处理器的位数不同,导致了数据存储的问题,最终留下了大小端这两种存储方式。
大小端的一道练习
百度2015年系统工程师笔试题:
请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序。
根据我们上面对大小端的理解,我们举一个例子,假设是1,用下图来分析一下,

现在唯一的问题就是怎么拿到第一个字节的内容,这时候我们要想到指针,并且是char* 的指针,指向的是一个字节的内容。想到这里我们的代码就很好写了。
代码如下:
//百度2015年系统工程师笔试题:
//请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序。
#include <stdio.h>
int check_sys(int* p)
{
return *((char*)(p));//先将int*转换成char*截断拿到第一个字节内容,直接解引用返回即可
}
int main()
{
int a = 1;
//00 00 00 01
//01 00 00 00
int ret=check_sys(&a);//实现判断的函数
if (ret == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
浮点数在内存中的存储
常见的浮点数
- 3.14
- 1E10 //1E10的意思表示为1.0*10^10
浮点数存储的引入
我们来看下面一个浮点数存储的例子,
int main()
{
int n = 9;
float* pFloat = (float*)&n;
printf("n的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
*pFloat = 9.0;
printf("num的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
return 0;
}
请问结果是什么,我们来看一下结果。
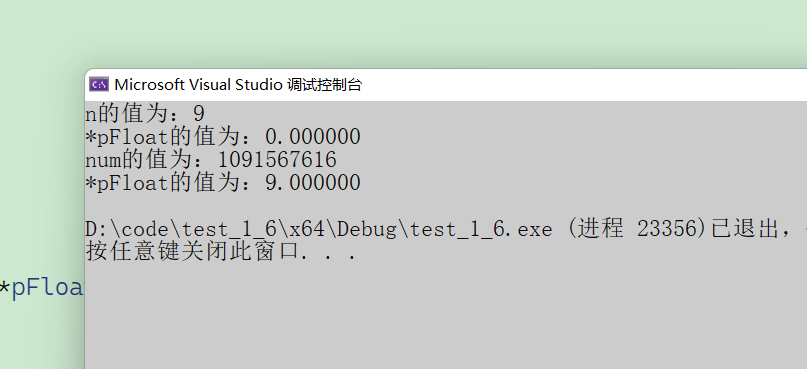
看到这个结果,num 和 *pFloat 在内存中明明是同一个数,为什么浮点数和整数的解读结果会差别这么大?我觉得大部分人应该都是懵逼的状态,但是不要着急,接下来我们要学习的就是浮点数在内存中的存储。
之所以提出这个例子就是为了让你知道浮点型数据的存储和整型是完全不同的,学习浮点数存储的时候就将整型数据的存储完全舍弃掉。对于浮点数是完全没有什么原码反码补码的概念的。
浮点数存储规则
根据国际标准IEEE(电气和电子工程协会)754,任意一个二进制浮点数V可以表示成下面的形式 :
( − 1 ) S ∗ M ∗ 2 E (-1)^S* M *2^E (−1)S∗M∗2E
- (-1)^S代表符号位,S=0时,为正数;S=1,为负数;
M表示有效数字,大于等于1,小于2;
2^E代表指数位;
初看很懵,没有关系,我们举例来说明:

这样看来就可以明白任意一个二进制浮点数都可以表示为
(
−
1
)
S
∗
M
∗
2
E
(-1)^S* M *2^E
(−1)S∗M∗2E
IEEE 754规定:
对于32位的浮点数,最高的1位是符号位S,接着的8位是指数E,剩下的23位为有效数字M

对于64位的浮点数,最高的1位是符号位S,接着的11位是指数E,剩下的52位为有效数字M
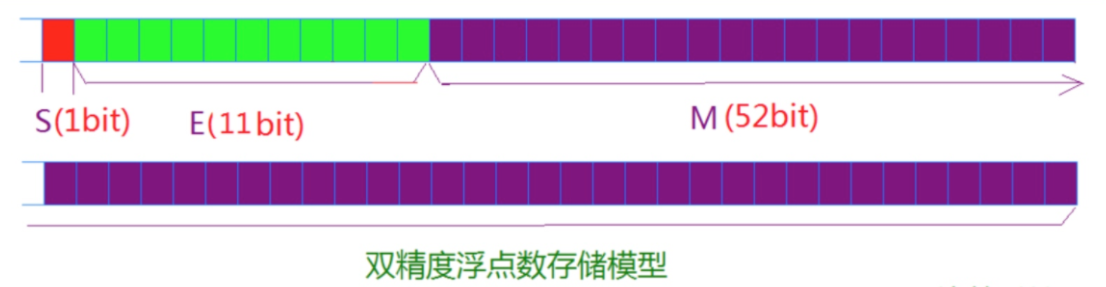
我们以32位平台为例来解释一下浮点数存储模型,
首先看M,M是有效数字有23位,但是我们说过M的范围是大于等于1,小于2,也就是1.xxxxxxxxx,所以第一位必定是1,所以我们将第一位在保存时舍去,只保留后面的xxxxxxxxx,等到读取的时候再把1加上去,这样做的目的是节省一位有效空间,就可以让精度更高一些,本来可以保存23位有效数字,但是这样做的话就可以保存24位有效数字。
指数E的情况就更复杂一些:
首先E是一个无符号整数(unsigned int),所以假设E是8位,那么E的范围是0255;如果E为11位,那么它的范围是02047,但是我们知道在科学计数法中指数是可以出现负数的,所以IEEE 754规定存入内存时E必须再加上一个中间值,对于8位,加上的是127;对于11位,加上的是1023。
例如2^10,E为10存入内存时要存入10+127=137,即10001001。
上面是E存入时的情况,接下来是E取出时的情况:
当E不全为0或者1时:
这时,先计算出指数E然后减去127(或1023),得到的即为E的真实值,再将有效数字M加上第一位的1,之后位数不够补0即可。
当E全为0时:
直接用1-127(或者1-1023)来表示E的真实值,有效数字不再加上第一位的1,直接还原成0.xxxxxx的小数,这样为了表示接近于0的很小的数字。因为一个很小的数再乘以2^(-126)无穷接近于0。
当E全为1时:
如果有效数字全为0,则表示正负无穷大,正负取决于S。因为2^256次方已经接近于无穷大了(32位平台)。
以上就是浮点数在内存中存储的规则,但是只是这样看我相信肯定是懵逼的状态,所以下面我们举例来理解到底是什么意思,之后再回过来理解,

这里是一个非常简单的例子,实际上有很多浮点数是没有办法精确存储的,例如3.14,你是没有办法将它用二进制形式准确表示出来的,所以有时候题目最后的结果要求是小数,在定义时最好就直接定义为浮点数类型,不要习惯整型就偷懒,最后再强制转换,很容易出现精度的问题。
这时候我们再回过头来看一下我们的引入举的例子,我们来解释一下为什么是会出现这种现象。

int main()
{
int n = 9;
//9可以表示为
//0x 00 00 00 09 //十六进制
//0000 0000 0000 0000 0000 0000 0000 1001 //二进制
//
//s=0,e=00000000,m=00000000000000000010001
//e全为0,e=1-127=-126,所以表示为0.xxxxxxx,不再补有效位的第一个1,
//直接写成(-1)^0*0.00000000000000000001001*2^(-126)
//这个数非常非常非常小,所以以%f的形式去打印打印出来的当然是0了
//
float* pFloat = (float*)&n;
printf("n的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat); //以浮点数的角度看待打印出的是0
*pFloat = 9.0;
//将9.0去还原出它的二进制1001.0
//表示为 (-1)^0*1.001*2^3
// s=0,m=001(舍弃前面的1),e=3
// e存入的是3+127=130 即10000010
//0 10000010 001 00000000000000000000 //9.0的二进制序列
//用整型的角度来看待这个二进制序列,转换成原码
//00111110111011111111111111111111
//这就是一个相当大的数字了
//
printf("num的值为:%d\n", n);//以整型的角度去看待浮点数打印出特别大的一个值
printf("*pFloat的值为:%f\n", *pFloat);
return 0;
}
这样我们就彻底理解了浮点数在内存中的存储规则。还是开头说的,其实这部分内容真的很难考到,学习这些知识更像是一种修炼内功,让我们理解的更加透彻,拓展我们的知识面,如果遇到这样的现象能够去解释,关于素养的这种实际价值就靠自己体会了。好了,以上就是C进阶数据在内存中的存储内容。