架构与设计
- 一、背景和起源
- 二、框架概述
- 1.设计特点
- 三、架构图
- 1.UI交互层
- 2.Driver驱动层
- 3.Compiler
- 4.Metastore
- 5.Execution Engine
- 四、执行流程
- 1.发起请求
- 2.获取执行计划
- 3.获取元数据
- 4.返回元数据
- 5.返回执行计划
- 6.运行执行计划
- 7.运行结果获取
- 五、数据模型
- 1.DataBase数据库
- 2.Table表
- 2.1 MANGED_TABLE 内部表
- 2.2 EXTERNAL_TABLE 外部表
- 2.3 INDEX_TABLE 索引表
- 2.4 VIRTUAL_VIEW 视图表
- 3.Partition分区
- 3.1 静态分区
- 3.2 动态分区
- 4.Bucket桶
- 总结
- 参考链接
一、背景和起源
大数据存储和处理框架Hadoop提供了对数据的存储、分析、任务调度的处理。其中的MapReduce可以对数据进行处理和分析的,但是MapReduce的编程比较繁琐并且修改不方便,对于一些单次处理和交互式分析非常不便。为了支持对数据仓库中数据的分析、简化用户使用数仓门槛,基于Hadoop的一套数据仓库分析系统Hive应运而生。Hive将结构化数据文件映射为一张数据库表,提供了丰富的SQL查询方式分析存储在Hadoop分布式文件系统的数据。将查询SQL语句转化成MapReduce任务进行执行。
二、框架概述
1.设计特点
支持通过SQL对数据仓库中数据进行访问,比如提取、转化、加工、分析等
支持将不同数据格式添加数据结构
可以直接访问大数据存储系统中的文件,比如HDFS、HBase等
三、架构图

Hive是构建在Hadoop之上,会将SQL转化成MapReduce任务在Hadoop集群进行执行,然后将结果保存在HDFS上,整体架构如上。
1.UI交互层
用户提交查询和其他操作
2.Driver驱动层
接受用户sql语句
调用编译器对Sql语句进行编译
调用执行引擎进行任务的执行
3.Compiler
基于Metastore中元数据对语句进行语义分析和解析查询生成执行计划
4.Metastore
存储数仓中表和分区的元数据,包括列信息、列类型信息、序列化器和反序列化器、存储文件等。
5.Execution Engine
hive生成的执行计划是一个由Stages组成的逻辑DAG图,执行引擎主要是将逻辑DAG图在Hadoop上进行调度和执行,最后转化成MapReduce的map task或reduce task进行运算。
四、执行流程
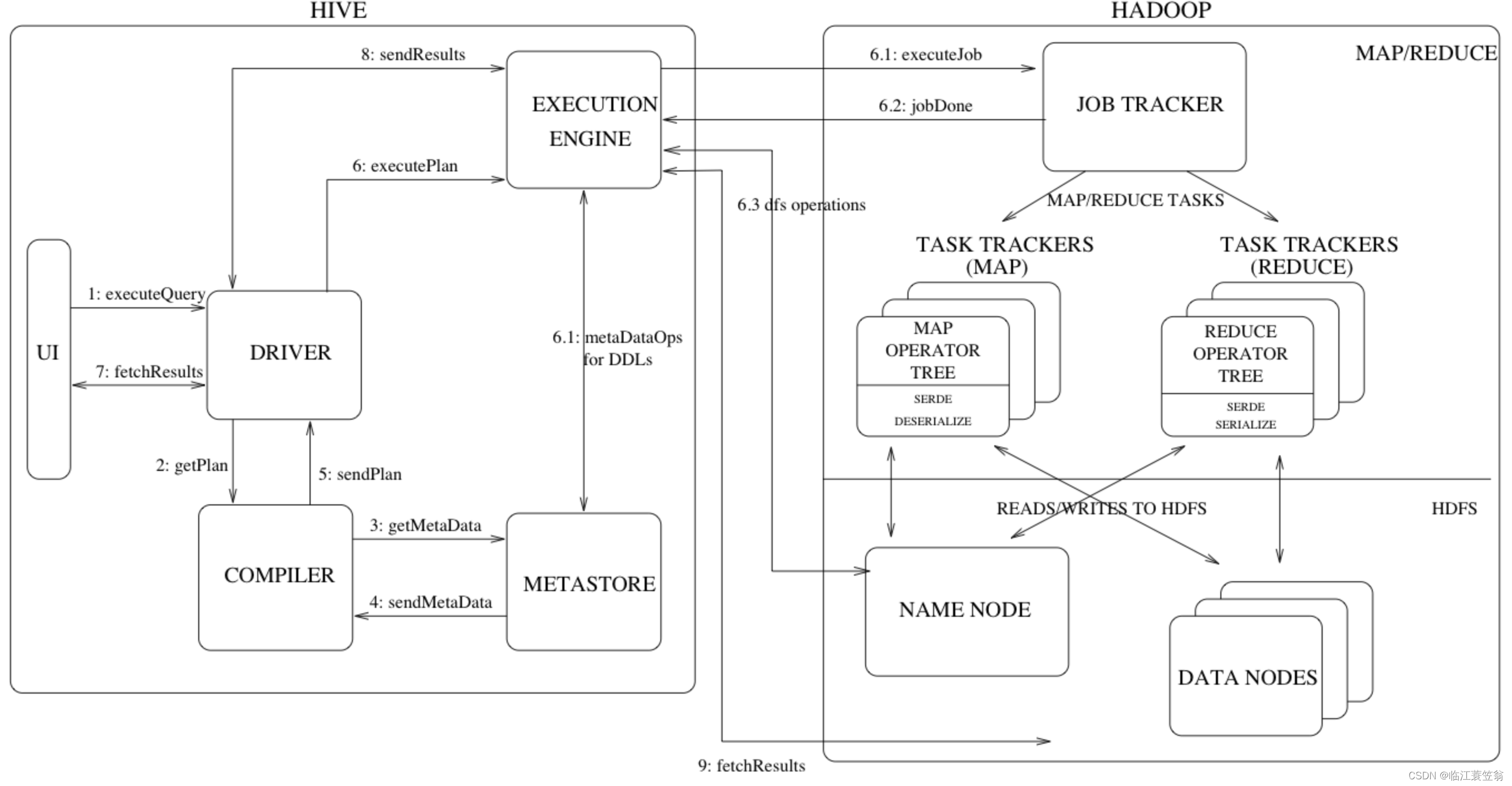
1.发起请求
UI交互层发起执行请求到Driver驱动层
2.获取执行计划
Driver驱动层将用户请求发送到编译器获取执行计划
3.获取元数据
编译器将sql语句中相关表和分区信息发送到MetaStore获取相关元数据
4.返回元数据
MetaStore返回对应元数据
5.返回执行计划
根据表和分区的元数据对sql的解析和优化,生成逻辑执行计划。该计划是一个DAG图,每个stage对应一个MapReduce的map或者reduce操作。
6.运行执行计划
将执行计划发送到Execution Engine,执行引擎会将逻辑执行计划提交到Hadoop中以MapReduce形式进行执行。
7.运行结果获取
UI交互层获取运行结果。
五、数据模型
hive主要将数据以以下几种数据模型进行组织,分别是DataBase、Table、Partition和Bucket。
1.DataBase数据库
相当于关系型数据中的命名空间,将数据库中数据隔离到不同的数据库模型中。
2.Table表
表是由描述表的元数据和存储的数据组成。数据存储在分布式文件系统中,元数据存储在关系型数据库中。表对应分布式文件系统的一个目录。Hive表分为以下四种:
2.1 MANGED_TABLE 内部表
内部表数据是由hive进行存储和管理的,默认存储位置为/user/hive/warehouse目录。
2.2 EXTERNAL_TABLE 外部表
外部表数据不会存储到hive相关目录下。当删除外部表时,hive只删除表的元数据,不会删除表数据。
2.3 INDEX_TABLE 索引表
索引表是为了提高表某些列的查询速度,包含指定列的值、对应的HDFS文件路径、偏移量的一张表。当查询时可以利用此索引表提高查询速度,避免全表扫描。
2.4 VIRTUAL_VIEW 视图表
视图是一组数据的逻辑表示,是sql语句的结果集
3.Partition分区
分区是根据表的某列值划分为不同分区,分区对应分布式系统中表目录下的一个子目录。分区基于分区键把具有相同分区键值的数据存储在一个子目录下。分区有两种类型:
3.1 静态分区
静态分区的分区数量和分区值都是固定的,新增分区和加载数据到分区时,需要提前指定分区名。
3.2 动态分区
动态分区的分区数量和分区值都是不确定的,会根据数据值自动创建新的分区。
4.Bucket桶
hive还支持将表或者分区中数据更细粒度的划分为桶,每个桶的数据对应分布式系统中子目录下的一个文件。
分桶表创建命令:
CREATE TABLE table_name
PARTITIONED BY (partition1 data_type, partition2 data_type,….)
CLUSTERED BY (column_name1, column_name2, …)
SORTED BY (column_name [ASC|DESC], …)]
INTO num_buckets BUCKETS;
总结
Hive是一个基于Hadoop的数仓分析工具,将分布式系统中的数据映射成结构化数据。提供丰富的SQL查询方式对数仓中的数据进行访问。一般不会存储数据、只会保存元数据到Hive中。Hive根据元数据信息将查询语句转化成执行计划,此执行计划由stage组成的DAG图,调用Hadoop中的MapReduce运行执行计划得到对应结果。
参考链接
1.Apache Hive
2.Hive Home
3.Hive Architecture