全局唯一id生成器
Redis 生成
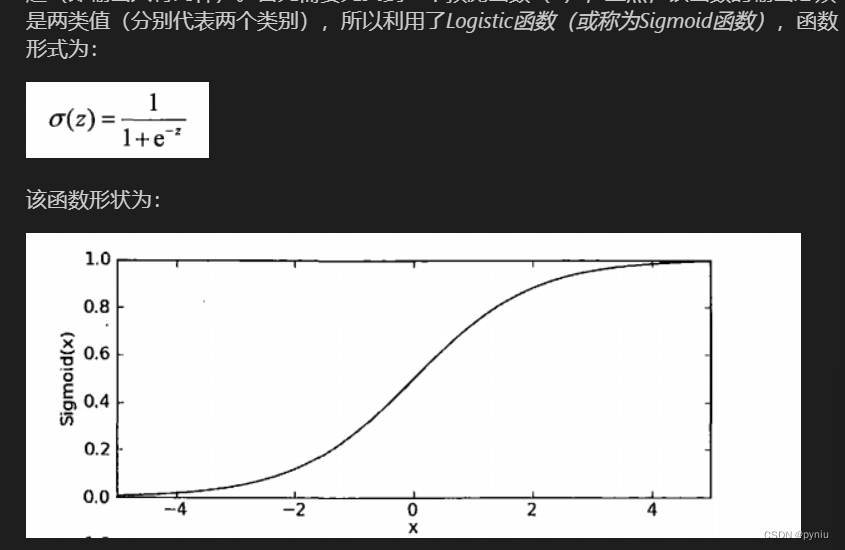
前提知识~~ 时间戳
时间戳这个东西我们老是听到,却可能不是特别了解
首先,时间戳是从1970年1月1号0点0分开始的秒数,我查了蛮多资料,理论上来说,时间戳是没有上限的,而我们一般用位数来限制这里的上限,比如32位
我们来实际计算一下
32位的二进制, 2的32次方 - 1 = 4294967296 - 1 = 4294967295
因为时间戳表示的是秒数,所以这里就是32位下,最大的秒数
一天的秒数为 86400
365天的秒数为31536000
那么32位的时间戳是 4294967295 / 31536000 = 136年
像现在是2024年,已经过了54年了,那么还有82年就要过期了
搞清楚这里的计算,我们后面就不会突然觉得,诶这里会不会超出上限
如何实现Redis全局id
首先我们要搞清楚为什么要全局id,全局id的作用是什么
第一: 唯一性,我们不能一套系统很多种全局id的生成器把,不能都用mysql自动生成id把,那样会混论,尤其是分布式系统
第二: 安全性,为了不让黑客知道我们生成id的规律,我们要加点佐料进去,例如时间戳
第三: 高可用 + 高性能 + 递增性 高可用就是,一个单点故障了,另外的一个服务器可以顶上,高性能就是生成的快,递增性就是为了我们业务的正常递增
所以我们就有redis生成全局id
这上面都符合,特别是高可用,可以用redis集群来保证,但是安全性,就要用不同的方法来实现了
这里是一种设计方法
设计的详解
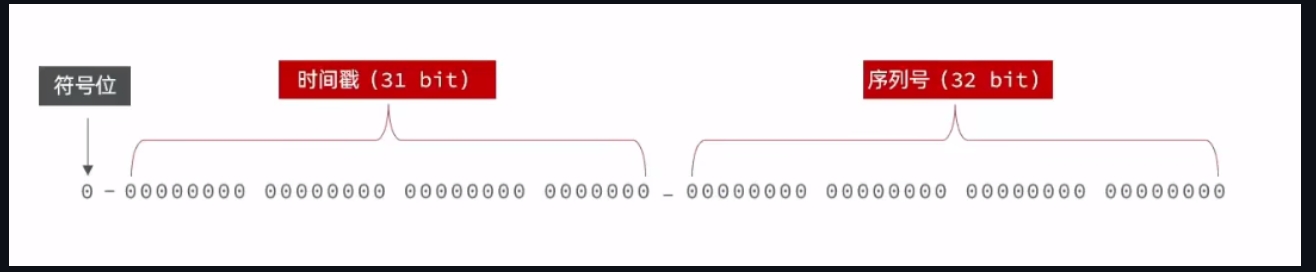
时间戳31位,序列号32位
这里的全局id的意思就是,每一秒内的序列号作为全局id
这里的设计就很不错,这样很大程度上解决了问题,你可能会想要是1s内,超出了2的32次方怎么办,好办,就多写几位,压缩时间戳的位数
我们再来讲讲这里的时间戳的上限,如果是31位的化,那么最大就是2的31次方- 1 = 2147483648 - 1 = 2147483647
一年的秒数(365天) = 2147483647
2147483647 / 31536000 = 68 年 约等于68年, 现在是2024年 离1970年已经54年了,所以按道理来说14年后就过期了 也就是2038年
这里的序列号,就用redis的自增来实现
实际代码
/**
* 全局唯一id生成器 Redis实现
* @author jjking
* @date 2024-02-07 20:27
*/
@Component
public class RedisIdWorker {
@Autowired
private RedisTemplate redisTemplate;
/**
* 生成id
* @param keyPrefix 业务的前缀key
* @return
*/
public long nextId(String keyPrefix) {
//生成时间戳
LocalDateTime now = LocalDateTime.now();
long timestamp = now.toEpochSecond(ZoneOffset.UTC);
//生成序列号
String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
long count = redisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
return timestamp << 32 | count;
}
}
这里比较有意思的点是两个点
第一: 是这里的redis生成序列号的点,特别要加入业务代码的前缀,不然全都用一个不就乱了套了,还有就是redis的value是有位数上限的,好像是2的64次方,所以这里还是会超出上限的,那么为了解决这个问题,就用了这里的时间来做区别,这样基本就不会有问题了
第二: ,这里的返回结果的计算也蛮有意思,首先是时间的位数向左边移动了32位,这里的意思就是腾出32位给序列号,然后再用位运算 或,来加上这里的序列号
特别要注意这里的或,很有意思,0 | 0 还是0 0 | 1 那么就是1,所以这里可以直接加上,这个得想一想才能想明白
UUID生成
UUID就比较耳熟能祥了,我这里写一个生成的范例
@Test
public void test1() {
String uuid = UUID.randomUUID().toString();
System.out.println(uuid);
}

可以看出来,他的位数分布是8-4-4-4-12位,一共是32位16进制数
我们来计算一下,总共多少字节,我们先转为为二进制,一位16进制,是4位二进制,那么 总共有32 * 4 = 128位二进制 一个字节是8位二进制
128 / 8 = 16字节
我们上面的redis生成的id是64位的,他的一半8个字节
所以,他的第一个缺点就是太大了,占内存
而且,这个uuid,也不太安全
但是他的优点就是性能还算蛮高的,还没有网络消耗
雪花算法 (重中之重)
先来了解雪花算法生成的id组成
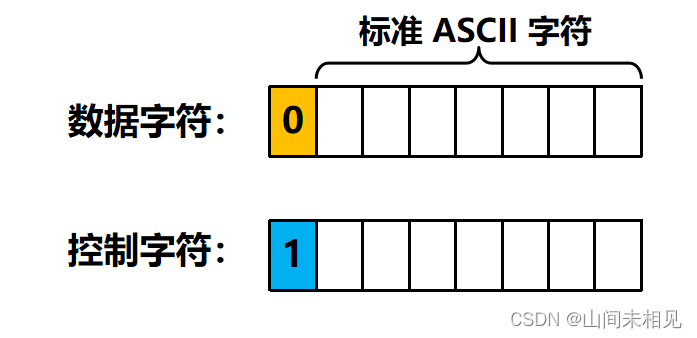
- 最高位 固定为 0 ,符号位,因为生成的id都为正数,固定为0
- 41位 时间戳 单位 毫秒 经过计算最多可以使用69年
- 10 位机器码 = 5位 数据中心id + 5位 工作机器id
- 12 位序列号
这个样子有点类似于我们redis生成的id,不过序列号少了,并且是毫秒级的,还有一个机器码
我这里摘的是糊涂工具包中的雪花算法id,并且简略了一些无关辅助代码
代码
package com.hmdp.utils;
import cn.hutool.core.date.SystemClock;
import cn.hutool.core.util.IdUtil;
import cn.hutool.core.util.StrUtil;
import java.io.Serializable;
import java.util.Date;
/**
* Twitter的Snowflake 算法<br>
* 分布式系统中,有一些需要使用全局唯一ID的场景,有些时候我们希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成。
*
* <p>
* snowflake的结构如下(每部分用-分开):<br>
*
* <pre>
* 符号位(1bit)- 时间戳相对值(41bit)- 数据中心标志(5bit)- 机器标志(5bit)- 递增序号(12bit)
* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
* </pre>
* <p>
* 第一位为未使用(符号位表示正数),接下来的41位为毫秒级时间(41位的长度可以使用69年)<br>
* 然后是5位datacenterId和5位workerId(10位的长度最多支持部署1024个节点)<br>
* 最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)
* <p>
* 并且可以通过生成的id反推出生成时间,datacenterId和workerId
* <p>
* 参考:http://www.cnblogs.com/relucent/p/4955340.html<br>
* 关于长度是18还是19的问题见:https://blog.csdn.net/unifirst/article/details/80408050
*
* @author Looly
* @since 3.0.1
*/
public class Snowflake implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 默认的起始时间,为Thu, 04 Nov 2010 01:42:54 GMT
*/
public static long DEFAULT_TWEPOCH = 1288834974657L;
/**
* 默认回拨时间,2S
*/
public static long DEFAULT_TIME_OFFSET = 2000L;
private static final long WORKER_ID_BITS = 5L;
// 最大支持机器节点数0~31,一共32个
@SuppressWarnings({"PointlessBitwiseExpression", "FieldCanBeLocal"})
//-1L 为 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 (1L的补码)
//左移5为 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1110 0000
//-1L为 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111
// ^ 异或是不同为1,相同为0
// 结果为 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0001 1111
private static final long MAX_WORKER_ID = -1L ^ (-1L << WORKER_ID_BITS);
private static final long DATA_CENTER_ID_BITS = 5L;
// 最大支持数据中心节点数0~31,一共32个
@SuppressWarnings({"PointlessBitwiseExpression", "FieldCanBeLocal"})
//和上面的最大工作id一样的道理
private static final long MAX_DATA_CENTER_ID = -1L ^ (-1L << DATA_CENTER_ID_BITS);
// 序列号12位(表示只允许workId的范围为:0-4095)
private static final long SEQUENCE_BITS = 12L;
// 机器节点左移12位
private static final long WORKER_ID_SHIFT = SEQUENCE_BITS;
// 数据中心节点左移17位
private static final long DATA_CENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS;
// 时间毫秒数左移22位
private static final long TIMESTAMP_LEFT_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATA_CENTER_ID_BITS;
// 序列掩码,用于限定序列最大值不能超过4095
//计算机的负数是用补码表示的
//1L 0000000000000000000000000000000000000000000000000000000000000001
//1L 反码 1111111111111111111111111111111111111111111111111111111111111110
//1L 补码 1111111111111111111111111111111111111111111111111111111111111111 补码 = 反码 + 1
//这里是 -1L(64位1) 往左移动12位 111111111111111111111111111111111111111111111111 0000 0000 0000 0000
// ~ 取反 000000000000000000000000000000000000000000000000 1111 1111 1111 1111
//结果为 2的12次方 - 1 = 4095
@SuppressWarnings("FieldCanBeLocal")
private static final long SEQUENCE_MASK = ~(-1L << SEQUENCE_BITS);// 4095
//起始时间
private final long twepoch;
private final long workerId;
private final long dataCenterId;
private final boolean useSystemClock;
// 允许的时钟回拨数
private final long timeOffset;
private long sequence = 0L;
private long lastTimestamp = -1L;
/**
* @param epochDate 初始化时间起点(null表示默认起始日期),后期修改会导致id重复,如果要修改连workerId dataCenterId,慎用
* @param workerId 工作机器节点id
* @param dataCenterId 数据中心id
* @param isUseSystemClock 是否使用{@link SystemClock} 获取当前时间戳
* @param timeOffset 允许时间回拨的毫秒数
* @since 5.7.3
*/
public Snowflake(Date epochDate, long workerId, long dataCenterId, boolean isUseSystemClock, long timeOffset) {
//如果没有给起始的时间就用默认的起始时间
if (null != epochDate) {
this.twepoch = epochDate.getTime();
} else{
// Thu, 04 Nov 2010 01:42:54 GMT
this.twepoch = DEFAULT_TWEPOCH;
}
//工作机器id <= 31
if (workerId > MAX_WORKER_ID || workerId < 0) {
throw new IllegalArgumentException(StrUtil.format("worker Id can't be greater than {} or less than 0", MAX_WORKER_ID));
}
if (dataCenterId > MAX_DATA_CENTER_ID || dataCenterId < 0) {
throw new IllegalArgumentException(StrUtil.format("datacenter Id can't be greater than {} or less than 0", MAX_DATA_CENTER_ID));
}
this.workerId = workerId;
this.dataCenterId = dataCenterId;
this.useSystemClock = isUseSystemClock;
this.timeOffset = timeOffset;
}
/**
* 根据Snowflake的ID,获取机器id
*
* @param id snowflake算法生成的id
* @return 所属机器的id
*/
public long getWorkerId(long id) {
return id >> WORKER_ID_SHIFT & ~(-1L << WORKER_ID_BITS);
}
/**
* 根据Snowflake的ID,获取数据中心id
*
* @param id snowflake算法生成的id
* @return 所属数据中心
*/
public long getDataCenterId(long id) {
return id >> DATA_CENTER_ID_SHIFT & ~(-1L << DATA_CENTER_ID_BITS);
}
/**
* 根据Snowflake的ID,获取生成时间
*
* @param id snowflake算法生成的id
* @return 生成的时间
*/
public long getGenerateDateTime(long id) {
return (id >> TIMESTAMP_LEFT_SHIFT & ~(-1L << 41L)) + twepoch;
}
/**
* 下一个ID
*
* @return ID
*/
public synchronized long nextId() {
//获取当前时间戳
long timestamp = genTime();
//如果小于上次的时间,这里有问题,时间回拨!
if (timestamp < this.lastTimestamp) {
if(this.lastTimestamp - timestamp < timeOffset){
// 容忍指定的回拨,避免NTP校时造成的异常
timestamp = lastTimestamp;
} else{
// 如果服务器时间有问题(时钟后退) 报错。
throw new IllegalStateException(StrUtil.format("Clock moved backwards. Refusing to generate id for {}ms", lastTimestamp - timestamp));
}
}
//如果等于上次的时间,说明,此时是同一毫秒,递增序列号
if (timestamp == this.lastTimestamp) {
//SEQUENCE_MASK为4095,这里的运算看上面的解释,这个相当于最大值
//SEQUENCE_MASK 为 00000000000000000000000000000000000000000000 0000 1111 1111 1111 1111
//假设此时的序列号为4095(sequence) 那么前面是4096 00000000000000000000000000000000000000000000 0001 0000 0000 0000 0000
//这样子与,0 & 0 = 0 ----- 0 & 1 = 0 ----- 1 & 1 = 1
//所以最后结果为 00000000000000000000000000000000000000000000 0000 0000 0000 0000 0000
final long sequence = (this.sequence + 1) & SEQUENCE_MASK;
//如果此时为0说明,已经到了4095了,到达上限,应该等待下一个毫秒
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
this.sequence = sequence;
} else {
sequence = 0L;
}
//赋值此时的上一次时间戳(毫秒)
lastTimestamp = timestamp;
return ((timestamp - twepoch) << TIMESTAMP_LEFT_SHIFT)
| (dataCenterId << DATA_CENTER_ID_SHIFT)
| (workerId << WORKER_ID_SHIFT)
| sequence;
}
/**
* 循环等待下一个时间
*
* @param lastTimestamp 上次记录的时间
* @return 下一个时间
*/
private long tilNextMillis(long lastTimestamp) {
long timestamp = genTime();
// 循环直到操作系统时间戳变化
while (timestamp == lastTimestamp) {
timestamp = genTime();
}
if (timestamp < lastTimestamp) {
// 如果发现新的时间戳比上次记录的时间戳数值小,说明操作系统时间发生了倒退,报错
throw new IllegalStateException(
StrUtil.format("Clock moved backwards. Refusing to generate id for {}ms", lastTimestamp - timestamp));
}
return timestamp;
}
/**
* 生成时间戳
*
* @return 时间戳
*/
private long genTime() {
return this.useSystemClock ? SystemClock.now() : System.currentTimeMillis();
}
// ------------------------------------------------------------------------------------------------------------------------------------ Private method end
}
会有点长,但是核心的东西就一段
我们直接来看这一段
/**
* 下一个ID
*
* @return ID
*/
public synchronized long nextId() {
//获取当前时间戳
long timestamp = genTime();
//如果小于上次的时间,这里有问题,时间回拨!
if (timestamp < this.lastTimestamp) {
if(this.lastTimestamp - timestamp < timeOffset){
// 容忍指定的回拨,避免NTP校时造成的异常
timestamp = lastTimestamp;
} else{
// 如果服务器时间有问题(时钟后退) 报错。
throw new IllegalStateException(StrUtil.format("Clock moved backwards. Refusing to generate id for {}ms", lastTimestamp - timestamp));
}
}
//如果等于上次的时间,说明,此时是同一毫秒,递增序列号
if (timestamp == this.lastTimestamp) {
//SEQUENCE_MASK为4095,这里的运算看上面的解释,这个相当于最大值
//SEQUENCE_MASK 为 00000000000000000000000000000000000000000000 0000 1111 1111 1111 1111
//假设此时的序列号为4095(sequence) 那么前面是4096 00000000000000000000000000000000000000000000 0001 0000 0000 0000 0000
//这样子与,0 & 0 = 0 ----- 0 & 1 = 0 ----- 1 & 1 = 1
//所以最后结果为 00000000000000000000000000000000000000000000 0000 0000 0000 0000 0000
final long sequence = (this.sequence + 1) & SEQUENCE_MASK;
//如果此时为0说明,已经到了4095了,到达上限,应该等待下一个毫秒
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
this.sequence = sequence;
} else {
sequence = 0L;
}
//赋值此时的上一次时间戳(毫秒)
lastTimestamp = timestamp;
return ((timestamp - twepoch) << TIMESTAMP_LEFT_SHIFT)
| (dataCenterId << DATA_CENTER_ID_SHIFT)
| (workerId << WORKER_ID_SHIFT)
| sequence;
}
我们来总结一下,这个核心代码的代码逻辑
我们要生成id的化,需要几部分 时间戳 + 机器码 + 序列号
机器码也就是我们服务器的标识,一般是我们字节写的,所以不用考虑这个
重点在于时间戳 + 序列号
时间戳的生成: 当前时间戳,并且是毫秒级的
时间戳的生成,代码很简单,所以也不要终点考虑
序列号的生成(重点): 第一: 我们需要校验这里的时间戳,是否有问题,也就是当前时间比上一次的时间还早,出现时间回拨问题
第二: 我们得校验此时的序列号是否超过上限,如果超过上限,那么置此时的序列号为0,并且等待下一毫秒,将此时的时间戳更新
最重要的问题就是这两,相比较,比较简单的问题是这里的超过上限问题,这里也很简单,就是循环等待下一毫秒,到达下一毫秒更新此时的时间戳,序列号也已经设置好了为0
最难也是最重要的问题,时间回拨问题,这里的位运算问题,还是很好理解的,只要会位运算,都能解决
但是我这里特别不能搞懂,为啥这里要用位运算
类似于如下代码
// 序列掩码,用于限定序列最大值不能超过4095
//计算机的负数是用补码表示的
//1L 0000000000000000000000000000000000000000000000000000000000000001
//1L 反码 1111111111111111111111111111111111111111111111111111111111111110
//1L 补码 1111111111111111111111111111111111111111111111111111111111111111 补码 = 反码 + 1
//这里是 -1L(64位1) 往左移动12位 111111111111111111111111111111111111111111111111 0000 0000 0000 0000
// ~ 取反 000000000000000000000000000000000000000000000000 1111 1111 1111 1111
//结果为 2的12次方 - 1 = 4095
@SuppressWarnings("FieldCanBeLocal")
private static final long SEQUENCE_MASK = ~(-1L << SEQUENCE_BITS);// 4095
这里的mask就是,相当于最大值,我不能明白的是,为什么不直接写4095L 或者写2的12次方 - 1,这里的12次方的12 一样也可以写成这里的 SEQUENCE_BITS 为啥要搞这个位运算???,我查了一下,都没有这方面的问题,如果你懂的化,可以私信我,谢谢了
时钟回拨问题
我也是看别人说,会有这个时钟回拨问题,问题的出现在于,有可能运维人员手动的更改了服务器的时间,或者两个服务器时间不同,需要同步时间,就会导致这里的时钟回拨问题
解决方案:
第一种方案: 是如果是时间回拨只是一两次,并且时间跨度不是很大的化,例如1 到 3秒,那么就直接等,那么几秒,这样子相当于有冗余,但是影响也不是很大,但这种操作,不能再并发量很高的时候操作,不然肯定出问题
第二种方案: 就是美团 和百度的方案
这两的方案我就先不研究了,到时候我真的懂了,就来更新这里的博客,我估计我也看不懂