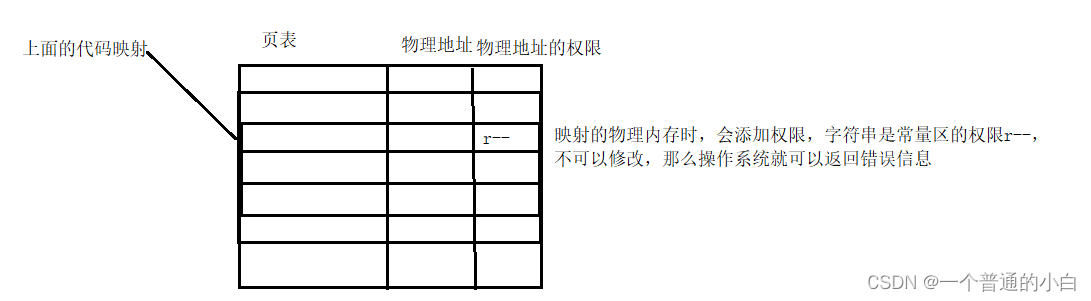
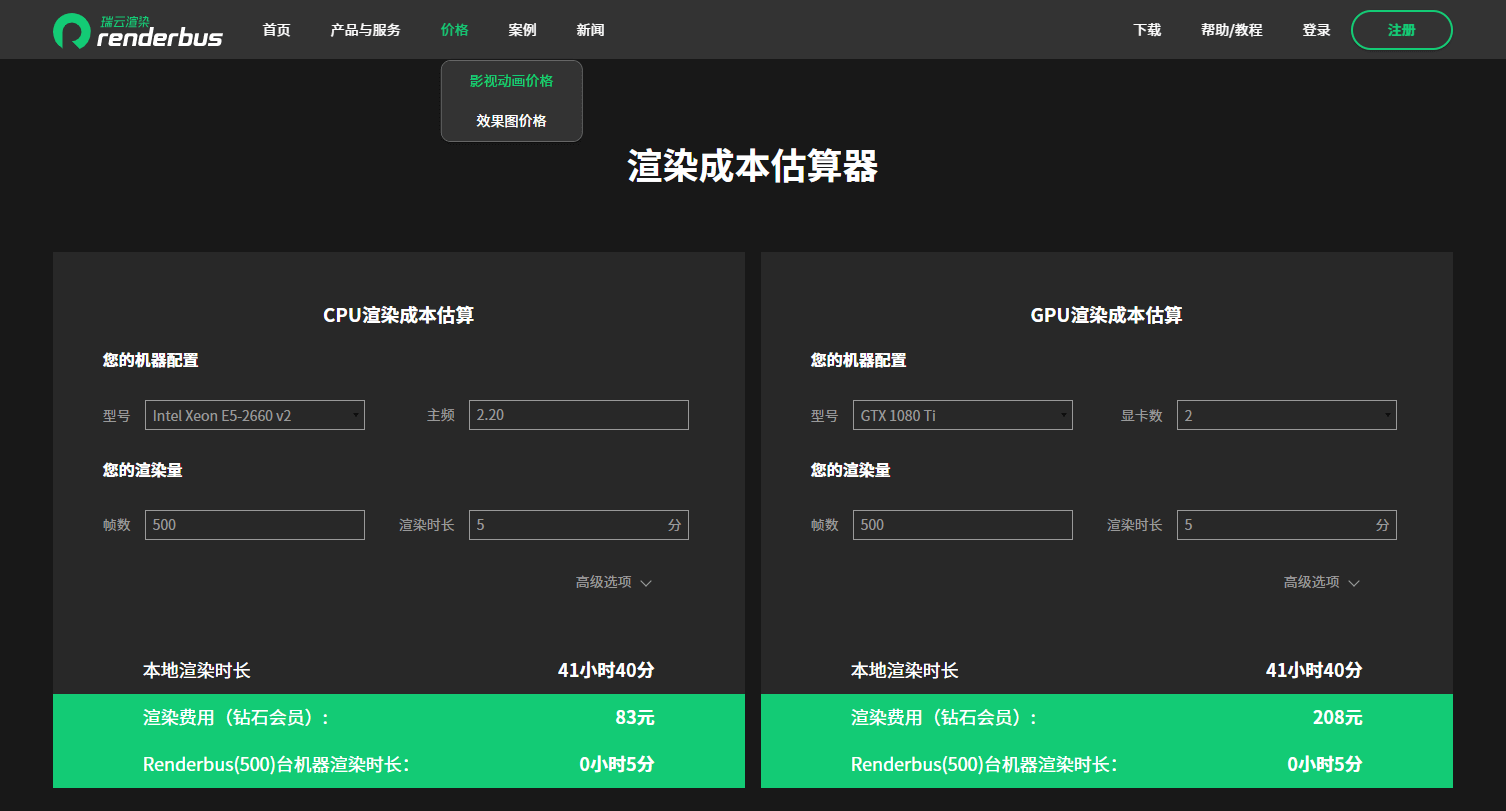
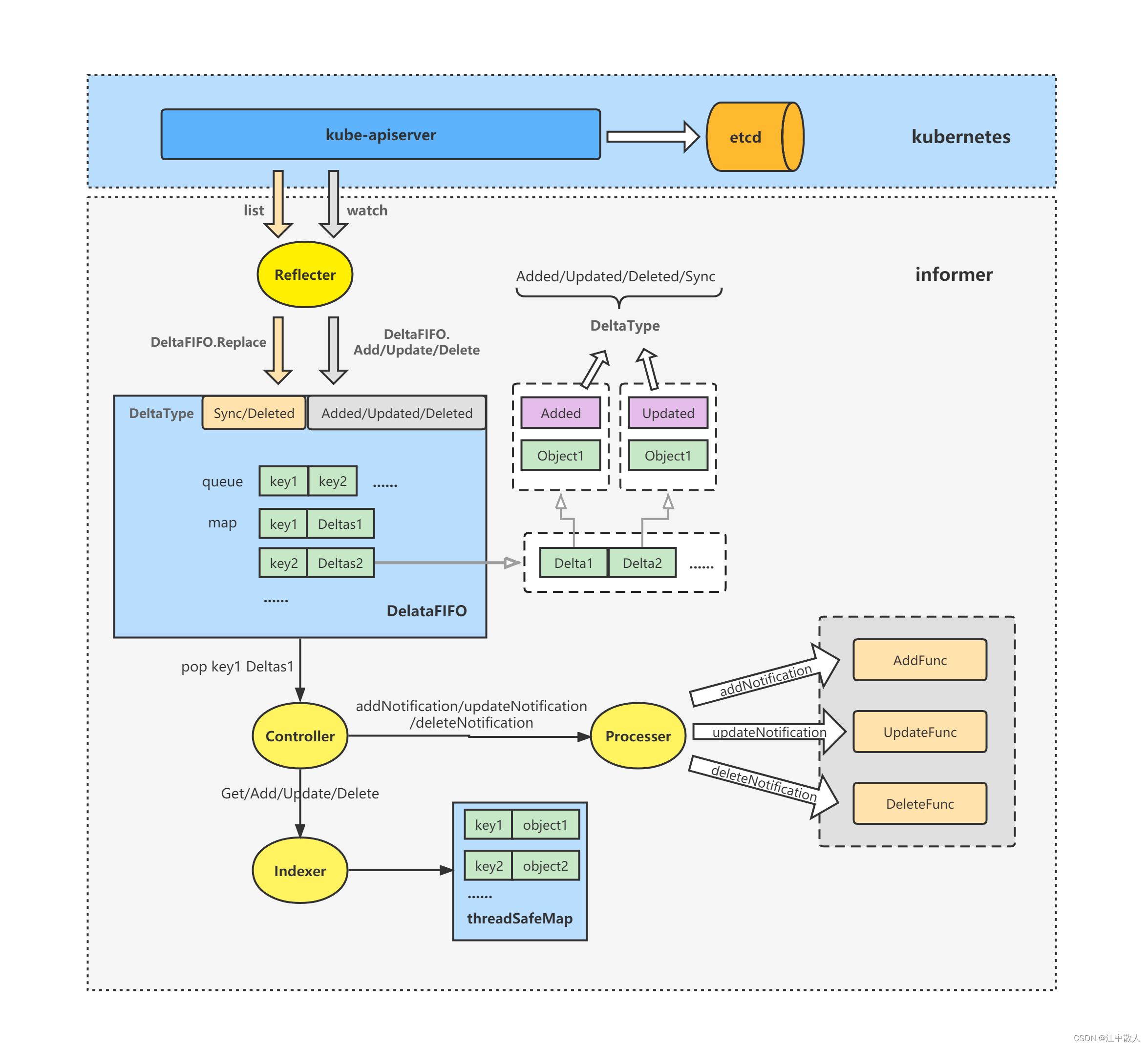
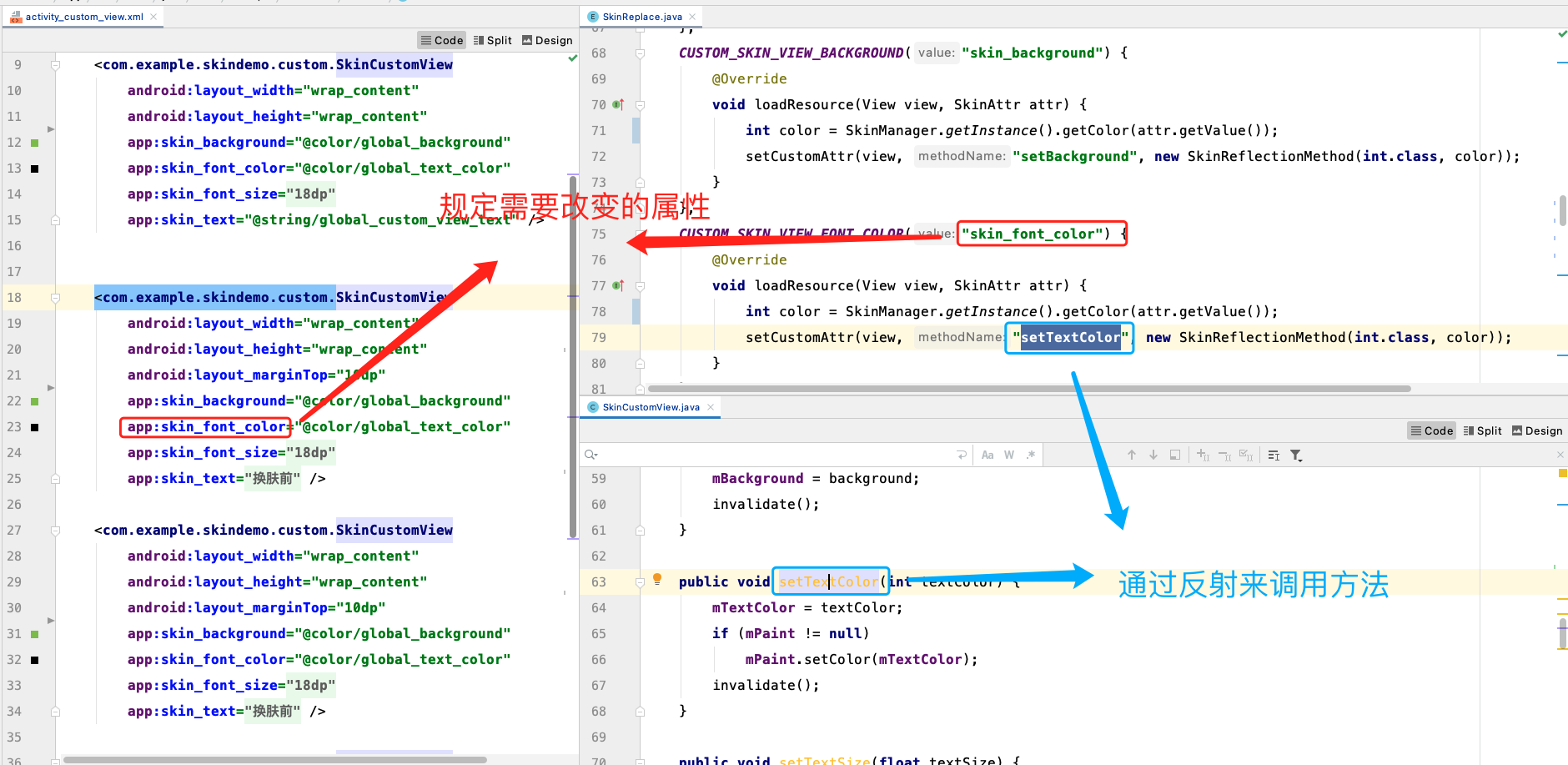
就提取excel文本框的内容,提供两种方法
一、
转成pdf,识别pdf文字
该方法需要注意两点:
1.似乎只能识别选中的文字(图片不行)
2.会受到精度影响(即有可能识别出错字)
以下是代码
先转存为pdf格式
import win32com.client
excel = win32com.client.DispatchEx('Excel.Application')
excel.Visible = False # 是否可视化
wb = excel.Workbooks.Open(input_path, UpdateLinks=False, ReadOnly=False)
ws = wb.Worksheets(Name)
#打印设置
ws.PageSetup.Zoom = False
ws.PageSetup.FitToPagesTall = False
ws.PageSetup.FitToPagesWide = 1
#导出为pdf
ws.ExportAsFixedFormat(0, output_path)
wb.Close(0)
excel.Quit()再识别pdf中的文本
with pdfplumber.open(file) as pdf:
for ys in range(len(pdf.pages)):
page = pdf.pages[ys]
content = page.extract_text().split('\n')
#接下来进行你对数据的处理二、
直接提取单元框的内容
该方法需要注意:
提取的单元框顺序是乱的(我还没看懂)
import xlwings as xw
path=r"C:\Users\dds\Desktop\ddd.xls"
app = xw.App(visible=True,add_book=False)
wb=app.books.open(path)
con=[] #实例化列表存储数据
for sheet in wb.sheets:
i=0
con.append(['']) #跨行数据应为二维数组
con.append([sheet.name])
for shape in sheet.shapes:
#print(shape) #可以打印出来看格式,或者采用下面图片的方法
if shape.name.startswith('Rectangle'): #也有文章用TextBox,实际情况实际分析
if shape.text:
con.append([shape.text.replace('\n',' ')])
i+=1
print(sheet.name,str(i))
wb.sheets.add().name='文本' #创建新表储存数据
sht=wb.sheets['文本']
sht.range('A1:A%d'%(len(con))).value=con
wb.save(r'C:\Users\dds\Desktop/asd.xls')
wb.close()
app.quit()也可用这个(仅供参考)
查阅的时候还见到一些其他方法如直接解析excel等,但个人不太喜欢,故没有收录