论文标题:Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
论文作者:Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Eric Jang, Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Kuang-Huei Lee, Sergey Levine, Yao Lu, Linda Luu, Carolina Parada, Peter Pastor, Jornell Quiambao, Kanishka Rao, Jarek Rettinghouse, Diego Reyes, Pierre Sermanet, Nicolas Sievers, Clayton Tan, Alexander Toshev, Vincent Vanhoucke, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Mengyuan Yan, Andy Zeng
作者单位: Robotics at Google,Everyday Robots
论文原文:https://arxiv.org/abs/2204.01691
论文出处:–
论文被引:635(01/05/2024)
项目主页:https://say-can.github.io/
论文代码:https://github.com/google-research/google-research/tree/master/saycan
Abstract
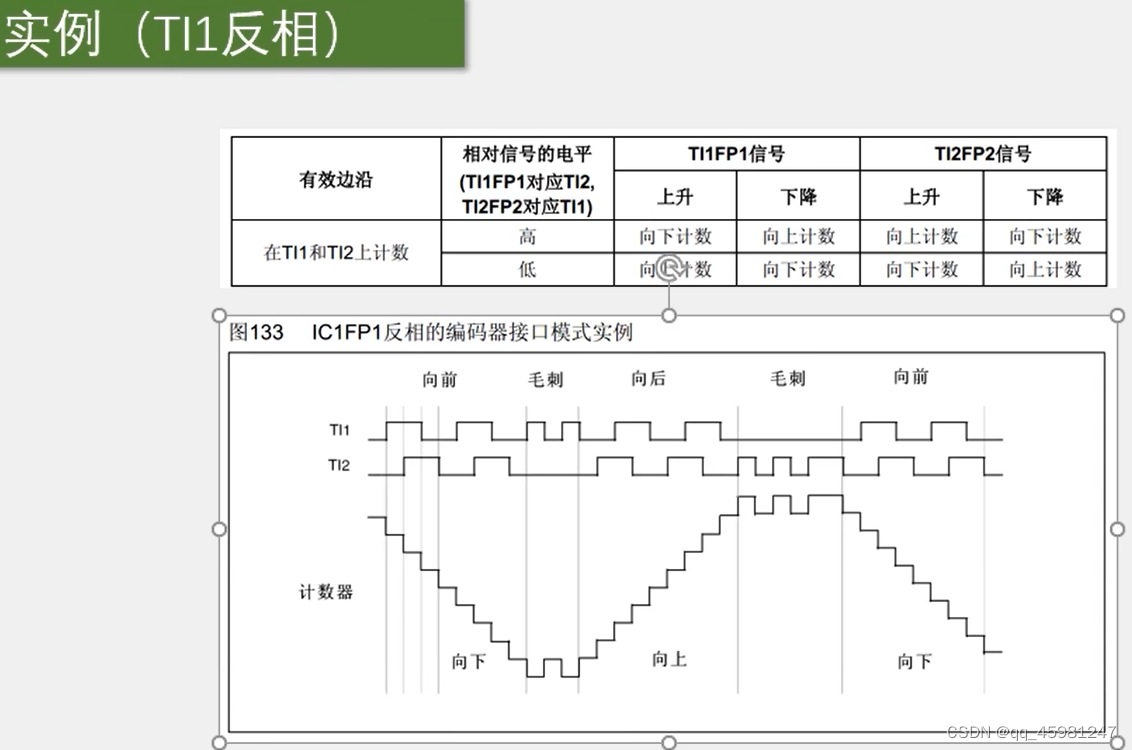
大型语言模型可以编码大量有关世界的语义知识。这些知识对于旨在根据以自然语言表达的高层次(high-level),时间扩展指令(instruction)行动的机器人来说极为有用。然而,语言模型的一个显著弱点是缺乏真实世界的经验,因此很难在给定的具身环境(embodiment)中利用它们进行决策。例如,要求语言模型描述如何清理溢出物,可能会得到合理的叙述,但对于需要在特定环境中执行这项任务的特定Agent(如机器人)来说,可能并不适用。我们建议通过预先训练的技能(skills)来提供真实世界的基础,这些技能用于约束模型,以提出既可行又符合上下文的自然语言行动。机器人可以充当语言模型的 “手和眼睛”,而语言模型则提供有关任务的高层次语义知识。我们展示了如何将低层次技能与大型语言模型相结合,从而使语言模型提供有关执行复杂和时间扩展指令的程序(procedures)的高层次知识,而与这些技能相关的值函数(value functions)则提供将这些知识与特定物理环境联系起来所需的基础。我们在一些真实世界的机器人任务中对我们的方法进行了评估,结果表明我们的方法需要以真实世界为基础,而且这种方法能够在移动机械臂(manipulator)上完成长视距(long-horizon),抽象的自然语言指令。
1 Introduction
最近在大型语言模型(LLMs)训练方面取得的进展使系统能够根据提示(prompts)生成复杂文本,回答问题,甚至就广泛的主题进行对话。这些模型从网络挖掘的文本库中吸收了大量知识,我们可能会想,机器人能否利用这些模型中编码的日常任务知识来执行现实世界中的复杂任务?但是,具身Agent(embodied agents)如何才能提取并利用 LLMs 的知识来完成实际任务呢?
这个问题提出了一个重大挑战。LLMs 不基于物理世界,无法观察到自己对任何物理过程造成的后果[1]。这不仅会导致 LLMs 犯下错误,还会导致它们对指令的解释不合理或对特定物理环境不安全。图 [1] 显示了一个例子——一个能够执行 “捡起海绵” 或 “走到餐桌前” 等技能的厨房机器人可能会被要求帮助清理溢出物(我的饮料洒了,你能帮忙吗?)。语言模型可能会做出合理的回答,但这种回答对机器人来说可能并不可行。如果场景中没有吸尘器,或者机器人无法使用吸尘器,那么 “你可以试试用吸尘器” 就是不可能的。通过提示工程(prompt engineering),LLM 可能有能力将高层次指令拆分成子任务,但如果不了解机器人的能力以及机器人和环境的当前状态,LLM 是无法做到这一点的。
受这个例子的启发,我们研究了如何提取 LLM 中的知识,使机器人等具身Agent能够遵循高层次文本指令的问题。机器人配备了一套学习到的 “原子” 行为技能(“atomic” behaviors skills),能够进行低层次视觉运动控制。除了要求 LLM 对指令进行简单的解释外,我们还可以利用 LLM 对单项技能在完成高层次指令的可能性(likelihood)进行评分。然后,如果每项技能都有一个诸如值函数(value function)的负担能力函数(affordance function)来量化其在当前状态下成功的可能性,那么它的值就可以用来对技能的可能性进行加权。这样,LLM 描述了每种技能对完成指令的贡献概率,而负担能力函数则描述了每种技能成功的概率——将两者结合起来,就得出了每种技能成功执行指令的概率。负担能力函数使 LLM 感知到当前场景,而将完成度约束在技能描述中,使得 LLM 可以感知机器人的能力。此外,这种组合还能产生机器人为完成指令而执行的完全可解释的步骤序列,即通过语言表达的可解释计划。
我们的方法 SayCan 提取并利用了有物理基础的任务(physically-grounded tasks)中 LLM 的知识。LLM (Say) 提供了一个任务基础,以确定高层次目标的有用行动,而学习到的负担能力函数 (Can) 则提供了一个世界基础,以确定在执行计划时可以采取哪些行动。我们将强化学习(RL)作为一种学习语言条件的值函数(value functions)的方法,这种函数提供了世界上可能发生的事情的负担能力。我们在 101 个真实世界的机器人任务中对所提出的方法进行了评估,这些任务包括移动机器人在真实厨房中以零样本的方式完成大量语言指令。我们的实验证明,SayCan 可以执行时间上延伸的抽象指令(abstract instructions)。通过负担能力函数将 LLM 在真实世界中执行(grounding),其性能比未在真实环境中执行的基线提高了近一倍。此外,通过评估系统在不同 LLM 下的性能,我们发现只需增强底层语言模型,就能提高机器人的性能。
2 Preliminaries
Large Language Models.
语言模型试图对文本 W = { w 0 , w 1 , w 2 , … , w n } W=\{w_0,w_1,w_2,…,w_n\} W={w0,w1,w2,…,wn},字符串序列 w w w 的概率 p ( W ) p(W) p(W) 进行建模。这通常通过链式规则将概率因子分解为 p ( W ) = ∏ j = 0 n p ( w j ∣ w < j ) p(W)=\prod^n_{j=0} p(w_j| w_{<j}) p(W)=∏j=0np(wj∣w<j) 来实现。使得从先前的字符串预测每个连续的字符串。最近由基于神经网络的注意力架构[2]发起的突破已经实现了大型语言模型(LLM)的有效扩展。这样的模型包括 Transformer[2],BERT[3],T5[4],GPT-3[5],Gopher[6],LAMDA[7],FLAN[8]和PaLM[9],每个模型都显示出越来越大的容量(数十亿个参数和万亿字节的文本)以及跨任务泛化的能力。
本工作利用 LLM 中包含的大量语义知识来确定解决高层次指令的有用任务。
Value functions and RL.
我们的目标是能够准确预测一项技能(由语言命令给出)在当前状态下是否可行。我们使用基于时差的强化学习(TD)来实现这一目标。具体来说,我们定义了一个马尔可夫决策过程(MDP) M = ( S , A , P , R , γ ) \mathcal{M} = (\mathcal{S}, \mathcal{A}, P, \mathcal{R}, \mathcal{\gamma}) M=(S,A,P,R,γ),其中 S \mathcal{S} S 和 A \mathcal{A} A 是状态空间和行动空间, P : S × A × S → R + P : \mathcal{S} × \mathcal{A} × \mathcal{S} → \mathbb{R}_+ P:S×A×S→R+ 是状态转换概率函数, R : S × A → R \mathcal{R} : \mathcal{S} × \mathcal{A} → \mathbb{R} R:S×A→R 是奖励函数, γ \mathcal{γ} γ 是 discount 系数。
TD 方法的目标是学习状态或状态-动作值函数(Q-function) Q π ( s , a ) Q^π (s, a) Qπ(s,a),它表示从状态s和动作a开始,然后是策略π产生的动作时的奖励的 discount 总和,即 Q π ( s , a ) = E a ~ π ( a ∣ s ) ∑ t R ( s t , a t ) Q^π(s, a)=\mathbb{E}_{a~π} (a|s) \sum_t \mathcal{R}(s_t, a_t) Qπ(s,a)=Ea~π(a∣s)∑tR(st,at)。Q-function 可以通过近似动态编程方法来学习,从而优化以下损失:
L T D ( θ ) = E ( s , a , s ′ ) ∼ D [ R ( s , a ) + γ E a ∗ ∼ π Q θ π ( s ′ , a ∗ ) − Q θ π ( s , a ) ] L_{TD} (θ) = E_{(s,a,s')∼\mathcal{D}} [R(s,a) + \gamma \mathbb{E}_{a^*∼π} Q^π_{\theta}(s^′, a^*) - Q^π_{\theta}(s,a)] LTD(θ)=E(s,a,s′)∼D[R(s,a)+γEa∗∼πQθπ(s′,a∗)−Qθπ(s,a)],其中 D \mathcal{D} D 是状态和动作的数据集,θ 是 Q 函数的参数。
在这项工作中,我们利用基于 TD 的方法来学习额外以语言命令为条件的值函数,并利用这些方法来确定给定命令在给定状态下是否可行。在undiscounted,奖励稀疏的情况下,如果Agent成功,则在episode结束时获得 1*.0 的奖励,反之则为 0.*0,通过 RL 训练的值函数对应于一个负担能力函数[10],该函数指定了在给定状态下某项技能是否可行。在我们的设置中,我们充分利用了这一直觉,并通过稀疏奖励任务的值函数来表达 affordances。
3 SayCan: Do As I Can, Not As I Say
Problem Statement.
我们的系统接收用户提供的自然语言指令 i,该指令描述了机器人应该执行的任务。指令可以很长,很抽象或模棱两可。我们还假设,我们得到了一组技能 ∏ \prod ∏,其中每个技能 π ∈ ∏ π \in \prod π∈∏ 都能执行一项简短的任务,例如拾起一个特定的物体,并附带简短的语言描述 l π \mathscr{l}_π lπ (例如:“找到一块海绵”)和一个负担能力函数 p ( c π ∣ s , l π ) p(c_π |s, \mathscr{l}_π) p(cπ∣s,lπ),其表示从状态 s s s 成功完成具有描述 l π \mathscr{l}_π lπ 的技能的概率。直观地说, p ( c π ∣ s , l π ) p(c_π |s, \mathscr{l}_π) p(cπ∣s,lπ) 意味着 “如果我让机器人做 l π \mathscr{l}_π lπ,它会做吗?”。在 RL 术语中, p ( c π ∣ s , l π ) p(c_π |s, \mathscr{l}_π) p(cπ∣s,lπ) 是技能的值函数,如果成功完成,奖励为 1,否则,为 0。
如上所述, l π \mathscr{l}_π lπ 表示技能 π 的文本标签, p ( c π ∣ s , l π ) p(c_π |s, \mathscr{l}_π) p(cπ∣s,lπ) 表示如果从状态 s 执行,则具有文本标签 l π \mathscr{l}_π lπ 的技能 π 成功完成的概率,其中 c π c_π cπ 是伯努利随机变量。LLM 提供了 p ( l π ∣ i ) p(\mathscr{l}_π |i) p(lπ∣i),即技能的文本标签是用户指令的有效下一步的概率。然而,我们感兴趣的是某一技能成功完成指令的概率,将其记为 p ( c i ∣ i , s , l π ) p(c_i |i, s, \mathscr{l}_π) p(ci∣i,s,lπ)。假设成功的技能在 i i i 上取得进展的概率为 p ( l π ∣ i ) p(\mathscr{l}_π |i) p(lπ∣i)(即它是正确技能的概率),而失败的技能取得进展的概率为零,我们可以将其因式分解为 p ( c i ∣ i , s , l π ) ∝ p ( c π ∣ s , l π ) p ( l π ∣ i ) p(c_i |i, s, \mathscr{l}_π) ∝ p(c_π |s, \mathscr{l}_π) p(\mathscr{l}_π |i) p(ci∣i,s,lπ)∝p(cπ∣s,lπ)p(lπ∣i)。这相当于将给定指令的技能语言描述概率 p ( l π ∣ i ) p(\mathscr{l}_π |i) p(lπ∣i)(我们称之为任务基础)与当前世界状态下该技能可能存在的概率 p ( c π ∣ s , l π ) p(c_π |s, \mathscr{l}_π) p(cπ∣s,lπ)(我们称之为世界基础)相乘。
Connecting Large Language Models to Robots.
虽然大型语言模型可以利用从大量文本中学到的丰富知识,但它们并不一定能将高层次指令分解为适合机器人执行的低层次指令。如果问一个语言模型 “机器人如何给我送一个苹果”,它可能会回答 “机器人可以去附近的商店为你买一个苹果”。虽然这个回答对提示语来说是合理的,但对具身Agent来说却不一定可行,因为具身Agent拥有的能力是固定且受约束的。因此,为了让语言模型适应我们的问题陈述,我们必须以某种方式告知它们,我们特别希望将高层次指令分解为可用的低层次技能序列。其中一种方法是谨慎的提示工程(prompt engineering)[5, [11],这是一种诱导语言模型输出特定响应结构的技术。提示工程在上下文文本(提示)中为模型提供了具体任务和模型将模仿的响应结构的示例;附录 D.3 中显示了这项工作中使用的提示以及消融实验。然而,这并不足以将输出完全限制在一个具身Agent可接受的基本技能范围内,事实上,有时它可能会产生不可接受的动作或语言,而这些动作或语言的格式又不便于解析为单个步骤。
评分语言模型(Scoring language models)通过输出语言模型分配给固定输出的概率,为有限制的回答开辟了一条途径。语言模型表示潜在 completions p ( w k ∣ w < k ) p(w_k |w<k) p(wk∣w<k) 的分布,其中 w k w_k wk 是出现在文本中 k-th 位置的单词。典型的生成应用程序(如对话Agent)会从该分布中采样或解码最大似然completions,我们也可以使用该模型对从一组选项中选出的候选completions进行评分。在 SayCan 中,给定一组低层次技能 ∏ \prod ∏,其语言描述 l ∏ \mathscr{l}_{\prod} l∏ 和指令 i i i,我们计算技能语言描述 l π ∈ l ∏ \mathscr{l}_{\pi} ∈ \mathscr{l}_{\prod} lπ∈l∏ 在执行指令 i i i 上取得进展的概率: p ( l π ∣ i ) p(\mathscr{l}_π |i) p(lπ∣i),对应于查询模型的潜在completions。根据语言模型,通过 l π = a r g m a x l π ∈ l ∏ p ( l π ∣ i ) \mathscr{l}_π = arg max_{\mathscr{l}_π \in \mathscr{l}_{\prod}} p(\mathscr{l}_π|i) lπ=argmaxlπ∈l∏p(lπ∣i) 计算出最佳技能。一旦选定,该过程将通过迭代选择一种技能并将其附加到指令中来进行。实际上,在这项工作中,我们将规划构建为用户和机器人之间的对话,在对话中,用户提供高级指令(e.g., “How would you bring me a coke can?”),语言模型以明确的序列("I would: 1. l π \mathscr{l}_{\pi} lπ ", e.g., “I would: 1. find a coke can, 2. pick up the coke can, 3. bring it to you”)回答。
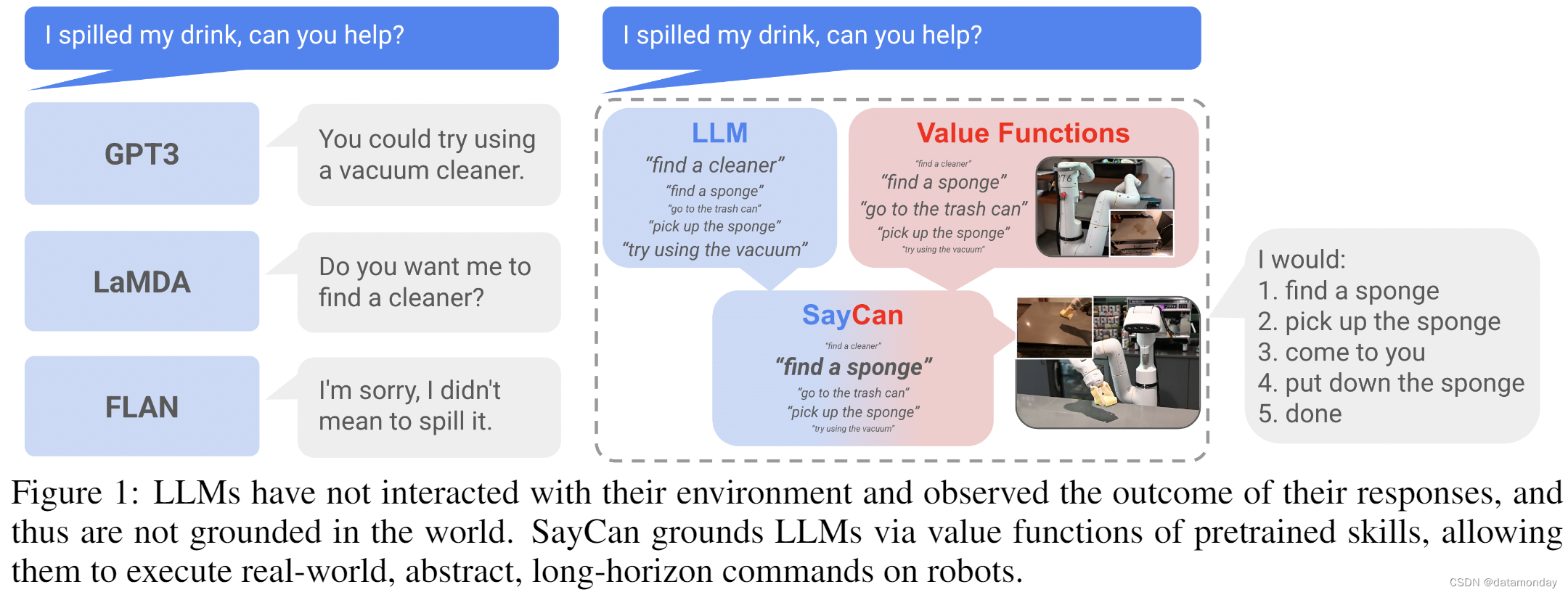
这样做的另一个好处是可解释性,因为模型不仅能输出生成的响应,还能给出许多可能响应的可能性概念。图 3(以及附录图 12 中的更多细节)显示了将 LLM 强制转化为语言模式的过程,其中任务集是低层次策略所能胜任的技能,而提示工程则显示了规划示例以及用户与机器人之间的对话。通过这种方法,我们能够有效地从语言模型中提取知识,但这也留下了一个大问题:虽然通过这种方法获得的指令解码总是由机器人可用的技能组成,但这些技能不一定适合在机器人当前所处的特定情况下执行所需的高层次任务。例如,如果我让机器人 “给我拿一个苹果”,如果它的视线中没有苹果,或者它的手中已经有一个苹果,那么最佳的技能组合就会发生变化。
SayCan.
SayCan 的主要理念是通过值函数——捕捉特定技能在当前状态下成功的对数可能性的负担能力函数——来建立大型语言模型。给定一个技能 π ∈ ∏ π \in \mathscr{\prod} π∈∏,其语言描述 l π \mathscr{l}_π lπ 及其相应的值函数,该值函数提供了 p ( c π ∣ s , l π ) p(c_π |s, \mathscr{l}_π ) p(cπ∣s,lπ),即 l π \mathscr{l}_π lπ 所描述的技能在状态 s 完成 c 的概率,如此便形成了一个负担能力空间 { p ( c π ∣ s , l π ) } π ∈ ∏ \{p(c_π |s, \mathscr{l}_π)\}_{π \in \prod} {p(cπ∣s,lπ)}π∈∏。该值函数空间包括所有技能的负担能力[12](见图 2)。对于每种技能,负担能力函数和 LLM 概率相乘,最终选出最有可能的技能,

即 π = a r g m a x π ∈ ∏ p ( c π ∣ s , l π ) p ( l π ∣ i ) π = arg max_{π \in \prod} p(c_π |s, \mathscr{l}_π)p(\mathscr{l}_π |i) π=argmaxπ∈∏p(cπ∣s,lπ)p(lπ∣i)。一旦选择了技能,Agent就会执行相应的策略,并修改 LLM 查询,将 l π \mathscr{l}_π lπ 包括在内,然后再次运行该过程,直到选择了终止标记(e.g., “done”)为止。图 3 显示了这一过程,算法 1 对其进行了描述。这两个镜像过程共同导致了对 Say- Can 的概率解释,其中 LLM 提供了技能对高层次指令有用的概率,而 affordances 则提供了成功执行每个技能的概率。将这两种概率结合在一起,就能得出该技能促进执行用户下达的高层次指令的概率。
4 Implementing SayCan in a Robotic System
Language-Conditioned Robotic Control Policies.
要实现 SayCan 的实例化,我们必须为它提供一组技能,每种技能都有一个策略,一个值函数和一个简短的语言描述(例如,“pick up the can”)。这些技能,值函数和描述可以通过各种不同的方式获得。在我们的实施过程中,我们采用 BC-Z 方法 [13] 或 MT-Opt 方法 [14] 进行强化学习,通过基于图像的行为克隆来训练单个技能。无论技能的策略是如何获得的,我们都使用通过 TD 备份训练的值函数作为该技能的负担力模型。虽然我们发现,在数据收集过程的当前阶段,BC 策略的成功率更高,但 RL 策略提供的值函数作为一种抽象概念,对于将控制能力转化为对场景的语义理解至关重要。为了摊销训练多种技能的成本,我们分别采用了多任务 BC 和多任务 RL,即不对每种技能训练单独的策略和值函数,而是训练以语言描述为条件的多任务策略和模型。但这种描述只与低层次技能相对应——SayCan 中的 LLM 的职责仍然是解释高层次指令并将其分解为单个低层次技能描述。
为了给语言策略设定条件,我们使用了一个预训练的大型句子编码器语言模型 [15]。我们在训练过程中冻结语言模型参数,并使用通过输入每种技能的文本描述生成的嵌入。这些文本嵌入被用作指定执行哪种技能的策略和值函数的输入(所用架构的详情见附录 C.1)。由于用于生成文本嵌入的语言模型并不一定与用于规划的语言模型相同,因此 SayCan 能够利用不同的语言模型,以适应不同的抽象层级——相对于更精细地表达特定技能,SayCan 更能理解与多种技能相关的规划。
Training the Low-Level Skills.
我们利用 BC 和 RL 策略训练程序,分别获得语言条件化的策略和值函数。为了完成对我们所考虑的底层 MDP 的描述,我们提供了奖励函数以及策略和值函数所使用的技能规范。如前所述,对于技能规范,我们使用了一组简短的自然语言描述,并将其表示为语言模型嵌入。我们使用稀疏奖励函数,如果成功执行了语言命令,则在episode结束时奖励值为 1*.0,否则为 0.*0。语言指令执行的成功与否由人类评定,评定者会得到一段机器人执行技能的视频,以及给出的指令。如果三位评分者中有两位一致认为机器人成功完成了该技能,则该episode将被贴上正奖励的标签。
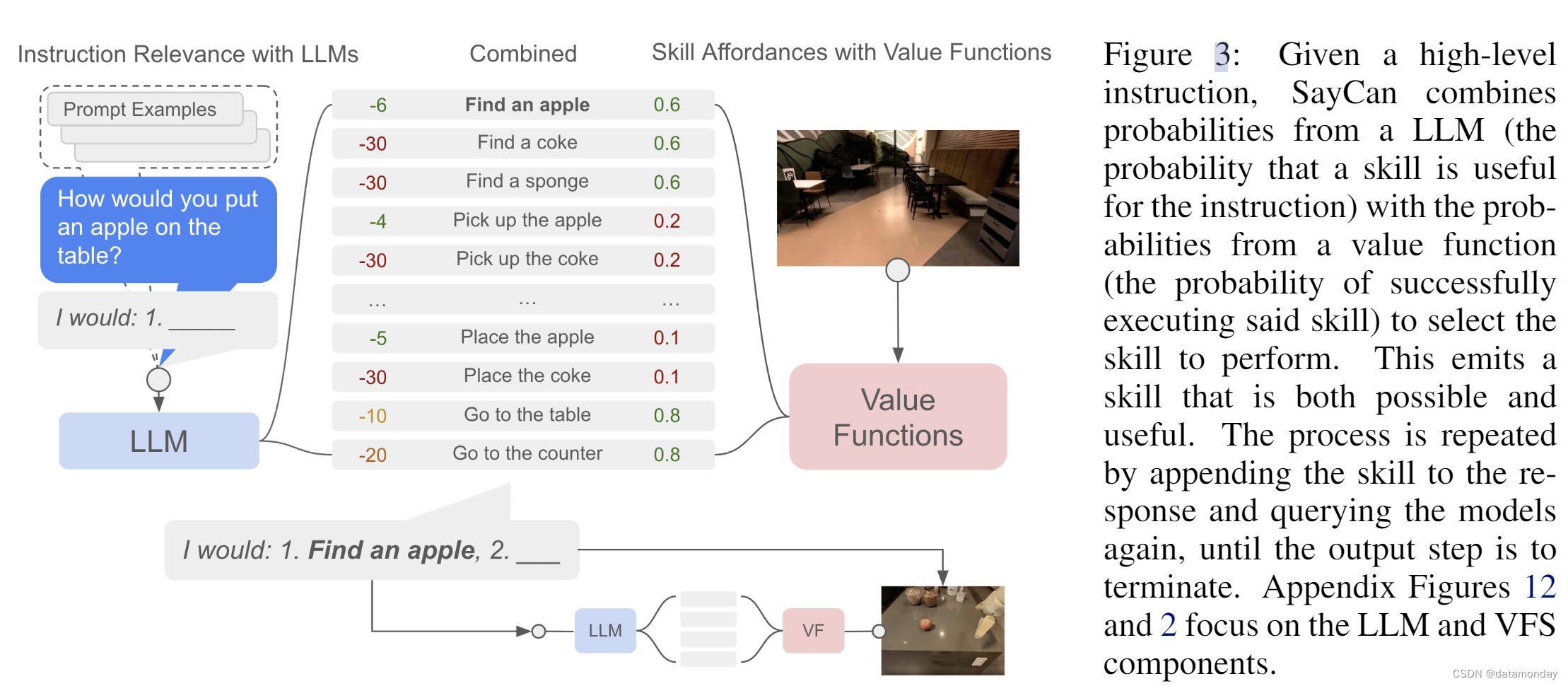
为了在现实世界中大规模学习语言条件 BC 策略,我们在 BC-Z [13] 的基础上使用了类似的策略网络架构(如图 10 所示)。为了学习以语言为条件的 RL 策略,我们在 Everyday Robots 模拟器中使用 MT-Opt [14],并使用 RetinaGAN sim-to-real transfer [16]。我们通过利用模拟演示来引导模拟策略的性能,以提供baseline,然后通过在线数据收集不断提高RL性能。我们使用的网络架构与 MT-Opt 类似(如图 9 所示)。我们的策略的动作空间包括末端执行器姿势的六个自由度,抓手打开和关闭指令,机器人移动底座的 x-y 位置和偏航方向 delta 以及终止动作。有关数据收集和训练的更多详情,请参见附录 C.2 节。
Robotic System and Skills.
在控制策略方面,我们使用移动机械臂机器人研究了一系列不同的操作和导航技能。受机器人在厨房环境中可能使用的常见技能的启发,我们提出了 551 种技能,涵盖 7 个技能系列和 17 个物体,其中包括拾取,放置和重新排列物体,打开和关闭抽屉,导航到不同位置以及将物体放置到特定配置中。在本研究中,我们使用了那些最适合通过组合和规划实现更复杂行为的技能,以及那些在当前数据收集阶段性能较高的;更多详情,请参阅附录 D。
5 Experimental Evaluation
Experimental Setup.
我们在两个办公室厨房环境中使用移动机械臂和一组物体操作和导航技能对 SayCan 进行了评估。图 4 显示了环境设置和机器人。我们使用了 15 个常见于办公室厨房的物体和 5 个具有语义意义的已知位置(两个柜台,一张桌子,一个垃圾桶和用户位置)。我们在两个环境中测试了我们的方法:一个是真实的办公室厨房,另一个是模仿厨房的模拟环境,这也是训练机器人技能的环境。使用的机器人是 Everyday Robots 公司生产的移动机械臂。配有 7 自由度机械臂和双指抓手。使用的 LLM 是 540B PaLM [9],除非对 LLM 消融另有说明。我们将使用 PaLM 的 SayCan 称为 PaLM-SayCan。

Instructions.
为了评估 PaLM-SayCan,我们测试了来自 7 个指令系列的 101 个指令,表 1 汇总了这些指令,附录 E.1 列举了这些指令。这些指令是为了测试 SayCan 的各个方面而开发的,其灵感来源于通过 Amazon Mechanical Turk 进行的众包和厨房用户的亲身体验,以及 ALFRED [17] 和 BEHAVIOR [18] 等基准。这些指令跨越了多个变化轴:时间范围(从单个基元到连续 10 多个基元),语言复杂性(从结构化语言到完全众包请求)和体现(机器人和环境状态的变化)。表 1 详细列出了每个系列的示例。
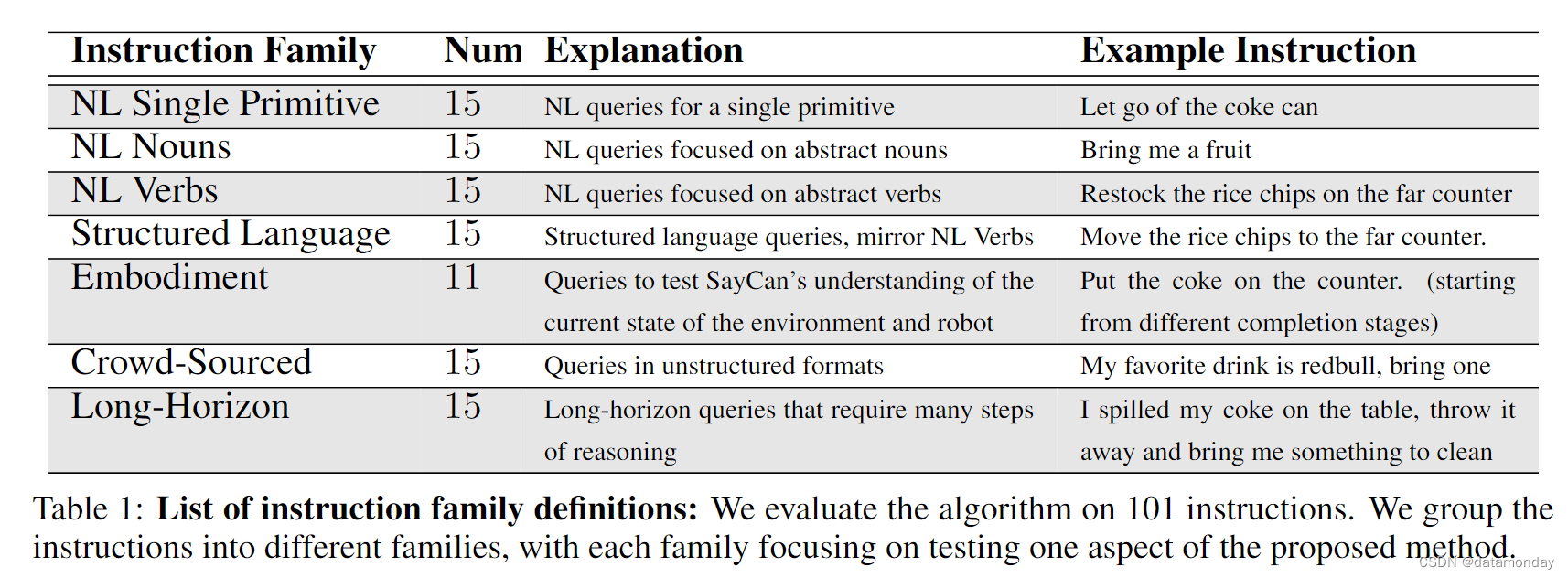
Metrics.
为了解所提方法的性能,我们测量了两个主要指标。
第一个指标是规划成功率(plan success rate),它衡量的是模型选择的技能对指令而言是否正确,而不管这些技能是否实际成功执行。我们要求 3 名人类评分员指出模型生成的计划是否能实现指令,如果 3 名评分员中有 2 人认为该计划有效,则该计划被标记为成功。请注意,对于许多指令来说,可能有多个有效的解决方案。例如,如果指令是 “带上海绵,扔掉苏打罐”,那么计划可以选择先带上海绵或先扔掉苏打罐。
第二个指标是执行成功率(execution success rate),用于衡量完整的 PaLM-SayCan 系统是否真正成功执行了所需指令。我们请 3 名人类评分员观看机器人的执行情况。评分者被要求回答 “机器人是否完成了任务字符串指定的任务 ?” 如果 3 位评分者中有 2 位一致认为执行成功,我们就认为执行成功。
5.1 Results
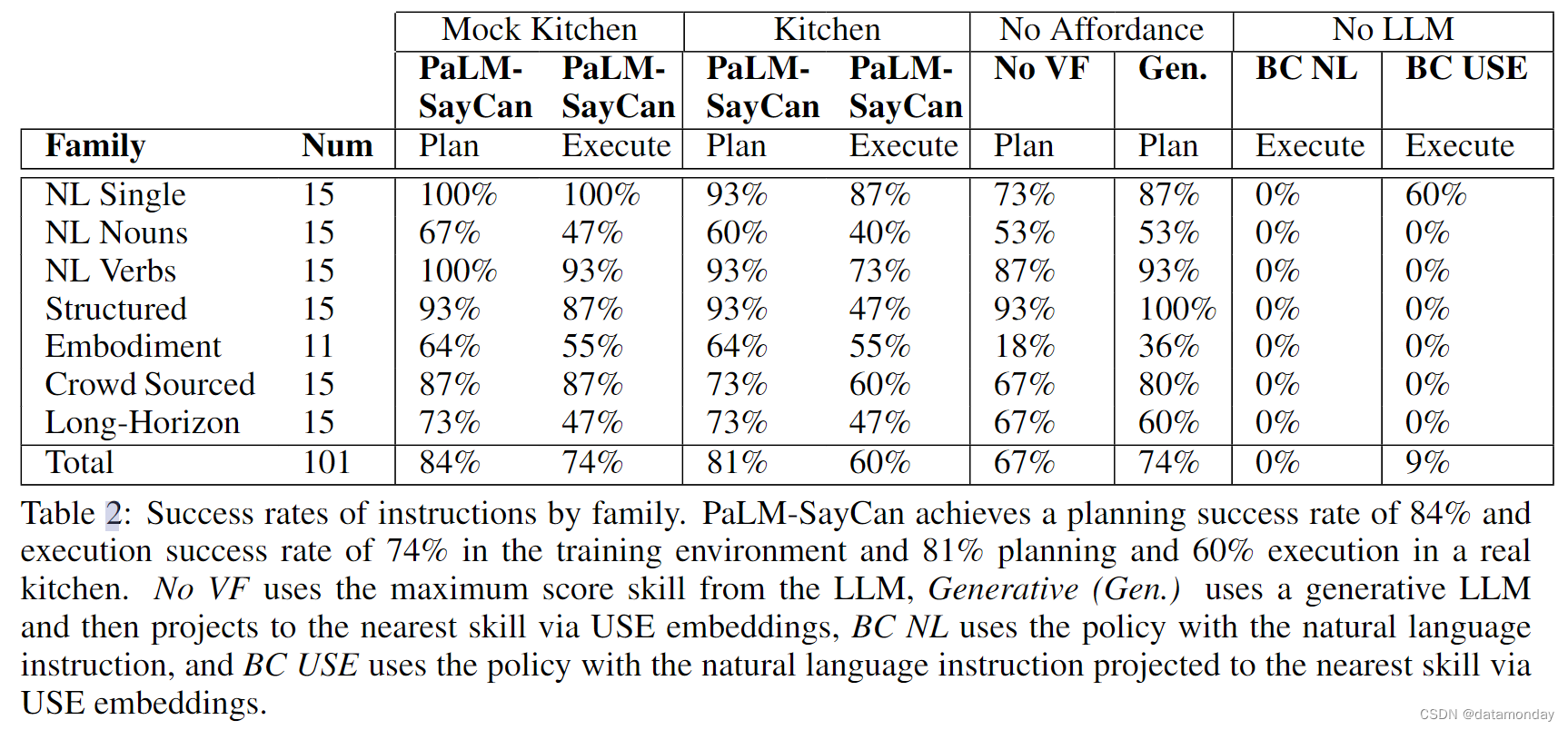
表 2 显示了 PaLM-SayCan 在 101 项任务中的表现。在模拟厨房中,PaLM- SayCan 的规划成功率为 84%,执行率为 74%。我们还在实验室之外的真实厨房中对 PaLM-SayCan 进行了研究,以验证策略和值函数在此环境中的性能。我们发现,规划性能降低了 3%,执行性能降低了 14%,这表明 PaLM-SayCan 及其基本策略在整个厨房中的通用性相当好。完整的任务列表和结果见附录表 5,实验展开和决策过程的视频见项目网站:say-can.github. io。
图 5 显示了两个长视距查询和由此产生的滚动。这些任务要求 PaLM-SayCan 在不出错的情况下规划许多步骤,并要求机器人在厨房的很大一部分区域进行导航和交互。每次查询都需要 PaLM-SayCan 理解指令中隐含的上下文。在图 5a 中,算法必须理解操作员要求的是 “recover from a workout” 的东西,即健康的东西,因此它带来的是水和苹果,而不是汽水和薯片。此外,算法必须了解排序和历史,即它已经带来了饮料,现在必须在终止前带来零食。在图 5b 中,PaLM-SayCan 必须跟踪哪些物体是需要处理的 “它们”,以及海绵应该被带到哪里。

图 6 着重介绍了 PaLM-SayCan 的决策过程及其可解释性。通过可视化算法两边的输出,可以理解决策过程是如何解决指令的。这样,用户就能了解 PaLM-SayCan 将哪些选项视为语言补全(completions),以及它认为哪些选项是可能的。我们发现序列顺序是可以理解的(先接近物体再拾起物体,先拾起物体再将其拿过来)。图 6 显示,虽然查询提到了可乐,但 PaLM-SayCan 理解重要的物体是要清洁的东西,因此带来了海绵。附录 E.6 在图 14-17 中显示了更多带有复杂决策,体现接地和长视距任务的推出,在图 16 中显示了失败。我们相信,这种实时和清晰的可解释性为更多的互动操作开辟了道路。

在表 2 中比较不同指令系列的性能时(关于指令系列的解释,请参见表 1),我们发现自然语言名词的性能比自然语言动词差,这是因为可能的名词数量(15 个物体和 5 个地点)与动词数量(6 个)的关系。结构化语言任务(旨在消除拼写解决方案与理解查询所造成的性能损失)的计划正确率为 93%,而与之对应的自然语言动词任务的计划正确率为 100%。这表明语言模型能有效解析查询。具身任务的计划正确率为 64%,一般来说,失败的原因是负担能力函数分类错误。PaLM-SayCan 计划并执行了众包自然查询,其性能与其他指令系列相当。PaLM-SayCan 在最具挑战性的长视距任务中表现最差,大多数失败都是由于 LLM 提前终止造成的(例如,带来了一个物体,但没有带来第二个)。我们还发现,PaLM-SayCan 在处理否定(如 “给我拿一个不是苹果的零食”)和模棱两可的引用(如要求提供含咖啡因的饮料)时很吃力,这是底层语言模型继承下来的一个已知问题[19]。总体而言,65% 的错误属于 LLM 故障,35% 属于负担能力函数故障。
回到我们最初的例子,“我打翻了东西,你能帮忙吗?”,一个不接地气的语言模型会回应 “我可以叫你清洁工” 或 “我可以帮你吸干净” 这样的语句,而对于我们的机器人来说,这些都是不合理的。我们已经证明,PaLM-SayCan 会回答 “我会:1. 找到一块海绵,2. 拿起海绵,3. 把海绵拿给你,4. 完成”,并能在真实厨房中的机器人身上执行这一系列操作。这需要对所需顺序进行长视距推理,对指令的抽象理解,以及对环境和机器人能力的了解。
Ablating Language.
为了研究 LLM 的重要性,我们使用语言条件策略进行了两次消融实验(见第 4-4 节)。在 BC NL 中,我们将完整的指令 i 输入策略——-这种方法代表了标准 RL 或基于 BC 的指令跟踪方法 [13,20,21,22]。在 BC USE 中,我们通过通用句子编码器(USE)嵌入[15]将高层次指令投射到已知语言指令集中,嵌入指令,所有任务和序列任务的组合集(例如,我们既考虑 “捡可乐罐”,也考虑 "1.找到可乐罐,2.捡可乐罐 "等),并选择余弦相似度最高的指令。表 2 中的结果说明了语言 grounding 的必要性,其中 BC NL 在所有任务中的得分率为 0%,而 BC USE 在单一基元任务中的得分率为 60%,但在其他任务中的得分率为 0%。
Ablating Value Functions.
表 2 说明了能力基础的必要性。我们将 PaLM-SayCan 与(1)无值函数(No VF)和(2)生成式(Generative)进行比较,前者去除了值函数基础(即选择最大语言分数技能),后者使用 LLM 的生成输出,然后通过 USE 嵌入将每个计划技能投射到其最大余弦相似度技能上。后者实际上与[23]相比,失去了明确的选项概率,因此可解释性较差,而且无法与负担能力概率相结合。对于生成法,我们也尝试了 BERT 嵌入[3],但发现效果不佳。No VF 方法和生成方法的表现类似,规划成功率分别为 67% 和 74%,比 PaLM-SayCan 的 84% 差。
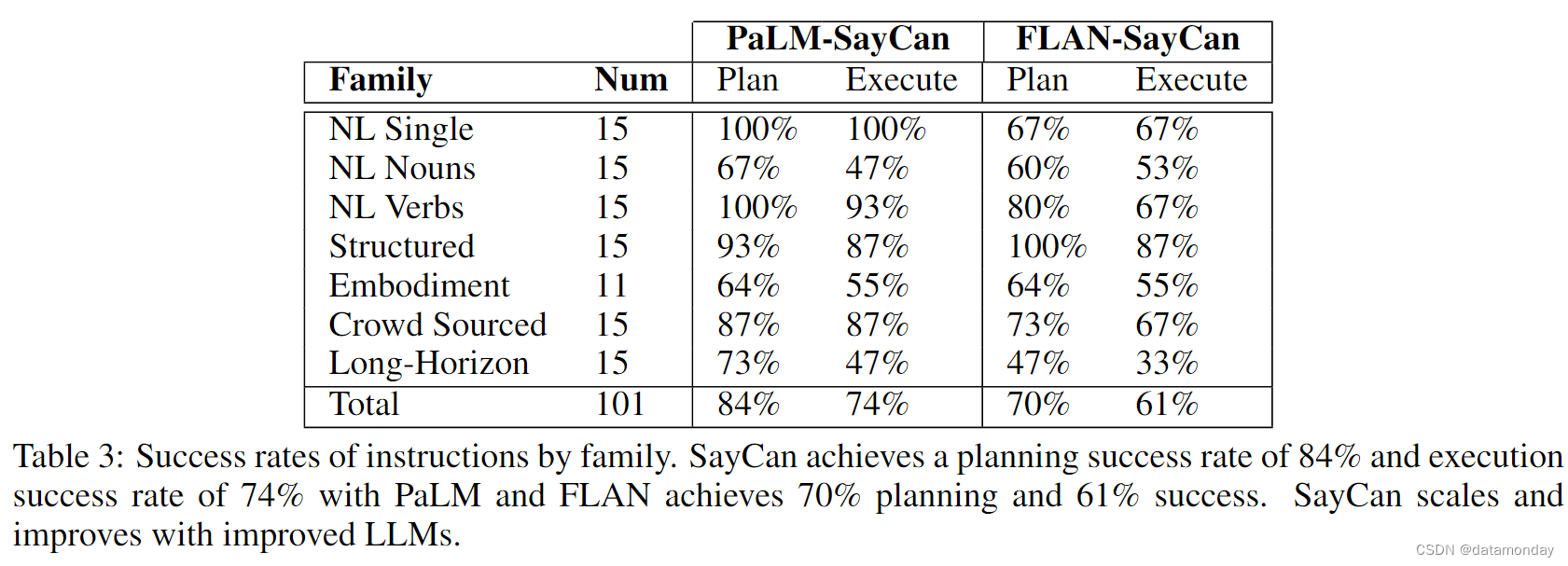
虽然语言模型的生成性能有望随着语言模型的改进而提高,但目前还不清楚 LLM 的大小如何影响最终的机器人成功率。表 3 显示了运行完整 SayCan 算法的机器人上的 PaLM 540B 和 FLAN。结果显示,使用 PaLM 的系统(PaLM-SayCan)在 84% 的时间内选择了正确的技能序列,并在 74% 的时间内成功执行了这些技能,与 FLAN 相比,错误率降低了一半。这尤其令人兴奋,因为这是我们第一次看到语言模型的改进如何转化为机器人技术的类似改进。这一成果预示着语言处理领域和机器人技术领域可以在未来相互协作,共同进步。
5.2 Case Studies of New Capabilities of PaLM-SayCan
PaLM-SayCan 实现了新的功能。首先,我们以抽屉操作为例,展示了将新技能融入系统非常容易。其次,我们展示了通过利用思维链推理,我们能够解决需要推理的复杂任务。最后,我们展示了该系统可以处理多语言查询,而无需明确设计。
Adding Skills: Drawer Manipulation (Appendix E.3).
SayCan 可以整合新技能,只需将新技能添加为 LLM 的选项,并提供相应价值即可功能,并在提示中用该技能添加一个示例。例如,有了打开,关闭和放入抽屉等技能,SayCan 就能解决 "将可乐和百事可乐重新放入抽屉 "这样的任务。在 21 次查询中,我们发现规划率为 100%,执行率为 33%(由于连锁操作策略失效),其他指令的性能没有任何损失。
Chain of Thought Reasoning.
SayCan 可以与最近改进 LLM 推理的工作相结合,例如 Chain of Thought [24]。Vanilla SayCan 的一个局限是它不能处理涉及否定的任务。这是从underline语言模型中继承下来的,并在 NLP 界进行了研究 [19]。不过,我们发现通过使用思维链提示[24],我们可以在这方面改进 SayCan。
对于基于思维链提示的 SayCan,我们需要修改提示语,使其包含一个名为 “解释” 的部分。我们还稍微改变了使用语言模型的方式。我们不再直接使用评分界面对可能的选项进行排序,而是首先使用 LLM 的生成式解码创建一个解释,然后使用评分模式,将解释纳入提示。完整的提示见附录 E.4 清单 3。

表 4 显示了该模型在评估时成功推出的几个案例。我们可以看到,通过思维链提示,该模型可以处理否定句和需要推理的任务。
Multilingual Queries (Appendix E.5).
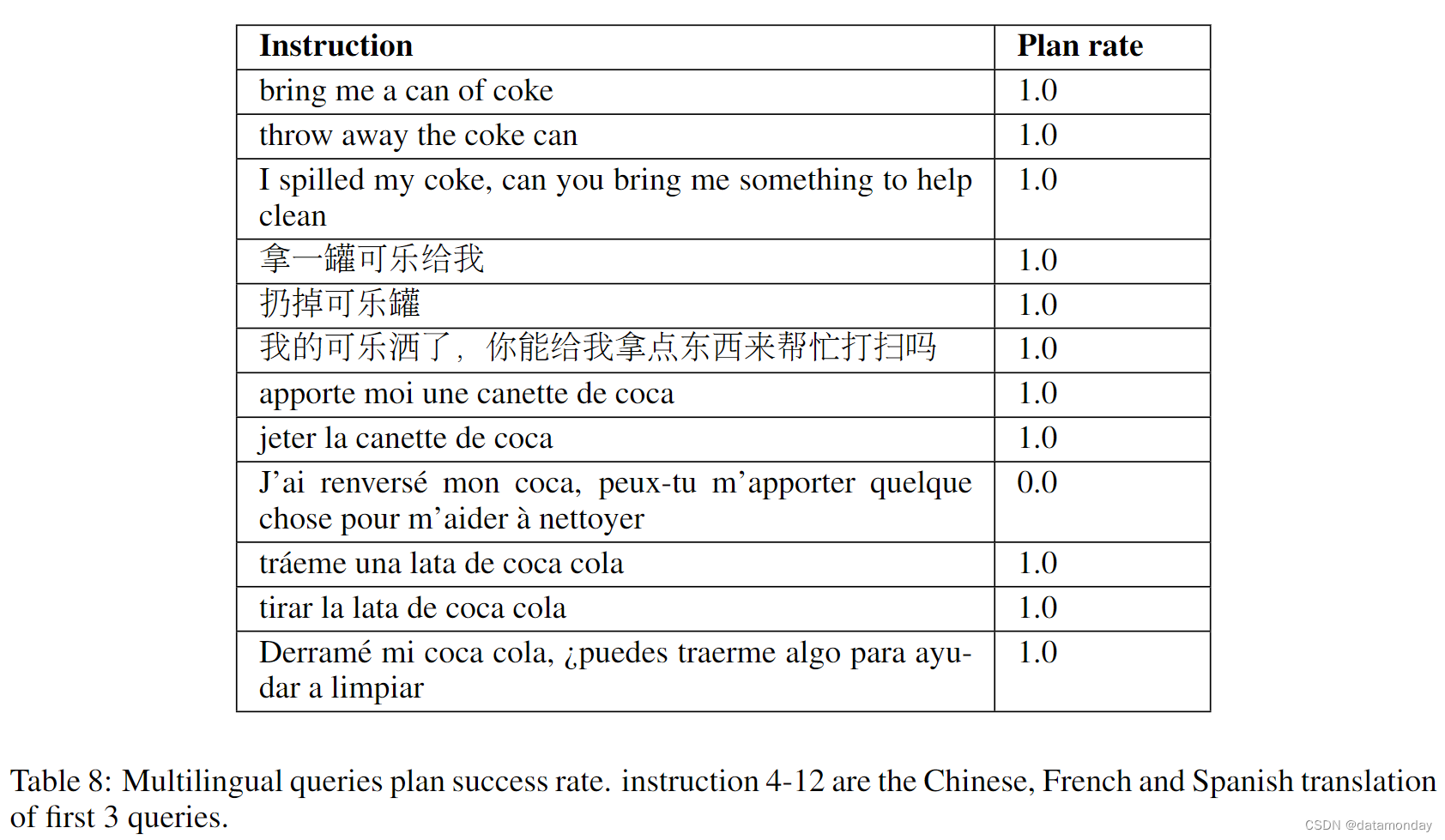
虽然 PaLM-SayCan 没有明确设计为处理多语言查询,但它能够处理多语言查询。LLM 是在多语种语料库中训练出来的,因此 SayCan 可以处理英语以外的多语种查询。表 8 总结了 SayCan 处理多语言查询的结果。表 8 总结了 SayCan 处理多语言查询的结果,当查询从英语改为中文,法语和西班牙语时,规划成功率几乎没有下降。
Closed-Loop Planning.
如本文所述,SayCan 只能在当前决策步骤中通过值函数接收环境反馈,这意味着如果技能失效或环境发生变化,可能无法获得必要的反馈。由于具有可扩展性和自然语言接口,Huang 等人[25] 在 SayCan 的基础上,通过内心独白(inner monologue)利用环境反馈(如来自success detectors,场景描述或甚至人类反馈) ,从而实现闭环规划。
6 Open Source Environment
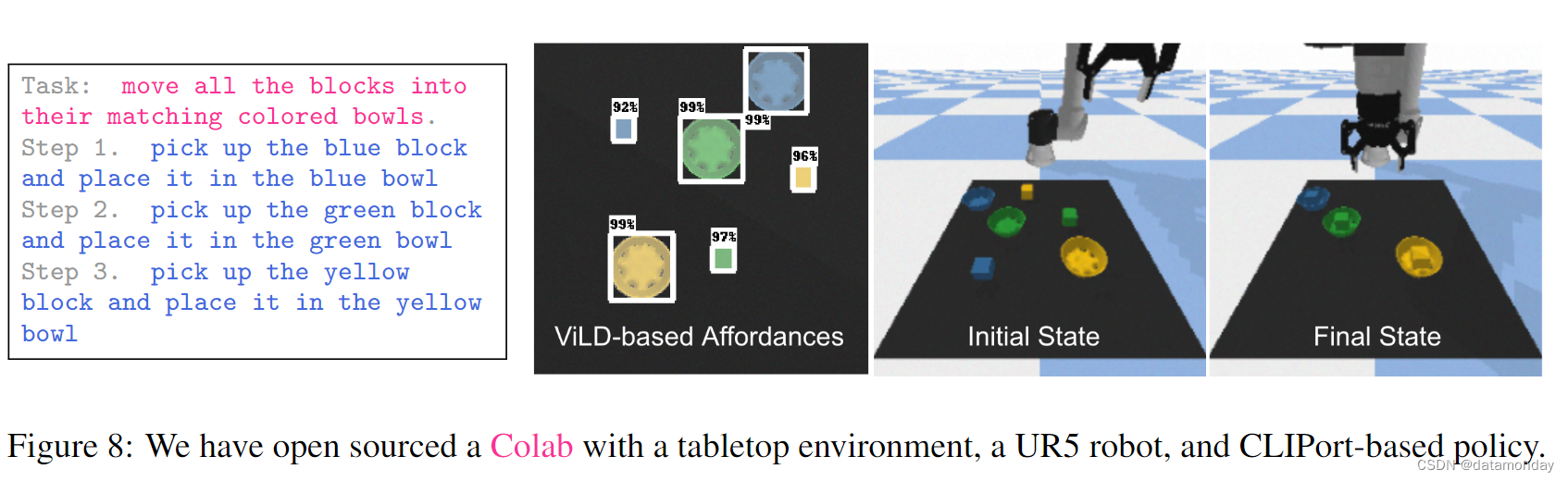
我们在谷歌 Colab 笔记本中开源了 SayCan 的实现,环境如图 8 所示,是一个装有 UR5 机器人和随机生成的彩色积木和碗的桌面。底层策略由 CLIPort [26] 实现,经过训练后可输出拾取和放置位置。由于缺乏该策略的值函数,因此使用 ViLD 物体检测器[27]来实现负担能力。GPT-3 被用作开源语言模型[5]。利用 LLM 输出代码结构的能力,步骤以 “拾取物体并将其放置到位置” 的形式输出。
7 Related Work
Grounding Language Models.
大量的工作都集中在语言的基础研究上[28, 29]。最近的工作研究了如何通过训练现代语言模型接受额外的环境输入[30, 31, 32, 33, 34]或直接输出动作[35, 36, 37],使其接地(grounding)。还有人通过提示工程将语言植入环境中 [24]。与 SayCan 同时,Huang 等人[23] 使用提示工程来提取时间扩展计划,但没有任何额外的机制来确保接地,大致相当于我们实验中的 "生成 "基线。上述方法都是在没有与物理环境进行交互的情况下进行训练的,因此限制了它们对具身交互进行推理的能力。
在交互中建立语言模型的一种方法是利用预先训练的 LLM 表征学习下游网络 [38, 22, 21, 39, 40, 41, 42, 43]。另一种方法是利用互动数据(如互动的奖励或排名反馈)对语言模型进行微调[11, 44, 45]。在我们的工作中,SayCan 能够通过以前训练过的值函数将语言模型建立在给定的环境中,从而以零样本的方式(即无需额外训练)实现一般的,长期的行为。
Learning Language-Conditioned Behavior.
关于如何将语言与行为联系起来的研究由来已久 [46, 47, 48, 49, 50]。之前的大量研究都是通过模仿学习 [51, 22, 20, 13, 26, 37] 或强化学习 [52, 53, 49, 54, 55, 56, 21, 41]来学习语言条件行为。这些先前的研究大多集中在低层次指令的执行上,例如拾放任务和其他机器人操作的初级指令 [20, 22, 56, 21, 13, 26],不过也有一些方法涉及模拟领域中的长期复合任务 [57, 58, 54]。与后面这些研究一样,我们的研究重点是完成时间上扩展的任务。不过,我们工作的核心是通过提取和利用大型语言模型中的知识来解决此类任务。之前的研究已经探讨了预训练的语言嵌入如何提高对新指令 [38, 22, 21] 和新的低层次任务 [13] 的泛化能力,而我们则通过将 LLMs 置于机器人的负担能力范围内,从 LLMs 中提取更多的知识。这样,机器人就可以使用语言模型进行规划。
Task Planning and Motion Planning.
任务和运动规划[59, 60]是一个将任务排序以解决高层次问题的问题,同时确保给定的具身环境的可行性(任务规划 [61,62,63];运动规划 [64])。通常,这一问题通过符号规划 [61, 63] 或优化 [65, 66] 来解决,但这些方法需要明确的基元和约束条件。最近,机器学习已被用于实现抽象任务规范,允许通用基元或放松约束 [67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78]。其他机器学习来分层解决此类长期问题 [79, 80, 12, 81, 54]。SayCan 利用 LLM 关于世界的语义知识来解释指令并理解如何执行指令。正如我们的机器人实验所证明的那样,LLM 的使用和学习到的底层策略的通用性使我们能够完成长视距,抽象的任务,并有效地扩展到现实世界。
8 Conclusions, Limitations and Future Work
我们介绍了 SayCan,这是一种能够利用大型语言模型中的丰富知识并将其应用于完成具身任务的方法。在现实世界中,我们利用预先训练好的技能,然后利用这些技能来调节模型,使其选择既可行又适合上下文的自然语言操作。更具体地说,我们使用强化学习的方法来学习单个技能的值函数,这些技能提供了世界上可能发生的情况,然后使用这些技能的文本标签作为语言模型评分的潜在响应。这种组合产生了一种共生关系(symbiotic relationship),即技能及其值函数可以充当语言模型的 “手和眼睛”,而语言模型则提供有关如何完成任务的高层次语义知识。我们在一些真实世界的机器人任务中对所提出的方法进行了评估,这些任务涉及一个移动机械臂机器人在一个真实的厨房中完成一大套长视距自然语言指令。我们还展示了我们的方法的一个令人兴奋的特性,即只需增强底层语言模型,就能提高机器人的性能。
虽然 SayCan 提供了一种将语言模型建立在Agent的负担能力的约束下的可行方法,但它也有一些局限性。
- 首先,这种方法继承了 LLM 的局限性和偏差[82, 83],包括对训练数据的依赖性。
- 其次,尽管 SayCan 允许用户使用自然语言命令与Agent进行交互,但系统的主要瓶颈在于底层技能的范围和能力。为了说明这一点,我们在附录 E 中介绍了具有代表性的失败案例。未来的工作将扩大技能范围并提高其鲁棒性,从而缓解这一限制。
- 此外,在现阶段,系统还无法轻松应对个别技能在报告高值的情况下仍然失效的情况,不过可以通过适当提示语言模型进行纠正来解决这一问题。
未来的工作还有许多其他潜在的途径。这项工作提出的一个自然问题是,如何利用通过真实世界的机器人经验为 LLM 奠定基础所获得的信息来改进语言模型本身,无论是在事实性方面,还是在对真实世界的环境和物理进行常识推理的能力方面。此外,由于我们的方法使用通用的值函数对负担能力进行评分,因此考虑以同样的方式纳入其他基础来源(如非机器人环境)也很有意义。
未来,研究自然语言是否是机器人编程的正确本体也很有意义:自然语言自然包含了来自环境的上下文和语义线索,并提供了一个抽象层次,使机器人能够根据自身感知和负担能力决定如何执行策略。与此同时,与后视目标图像[84]等相比,自然语言需要监督,对于某些任务来说,自然语言可能不是最具描述性的媒介。
最后,SayCan 提出了一种将语言理解和机器人技术的挑战联系起来并将其因素化的特殊方法,还可以提出许多进一步的扩展方案。诸如将机器人规划与语言相结合 [85],使用语言模型作为策略的预训练机制 [44] 以及许多其他将语言与交互相结合的方法 [21, 22, 38, 86] 等想法,都是未来令人兴奋的研究方向。
C RL and BC Policies
C.1 RL and BC Policy Architecture
C.2 RL and BC Policy Training
C.3 RL and BC Policy Evaluations
D SayCan Details and Parameters
D.1 SayCan Details
D.2 Policies and Affordance Functions
D.3 LLM Prompt
E Experiments
E.1 Tasks
E.2 Ablating Over Language Model Size
E.3 Adding Skills: Drawer Manipulation
E.4 Chain of Thought Reasoning






![[SAP ABAP] 创建Package](https://img-blog.csdnimg.cn/direct/7d6e62cbed10459e9d882d57453bfd52.png)