进程间通信
- 一、SystemV 共享内存
- 1. 共享内存原理
- 2. 系统调用接口
- (1)创建共享内存
- (2)形成 key
- (3)测试接口
- (4)关联进程
- (5)取消关联
- (6)释放共享内存
- (7)测试通信
- 3. 共享内存的特性
- 二、SystemV 消息队列(了解)
- 1. SystemV 消息队列原理
- 2. 系统调用接口
- (1)创建消息队列
- (2)形成 key
- (3)发送/接收数据
- (4)释放消息队列
- 三、IPC在内核中的数据结构设计
- 四、SystemV 信号量
- 1. 引入概念
- 2. 理解信号量
- 3. 了解系统调用接口
- (1)申请信号量
- (2)释放信号量
- (3)操作信号量
一、SystemV 共享内存
1. 共享内存原理
那么我们知道,进程间通信的本质就是先让不同的进程看到同一份资源。我们以前学的管道都是基于文件的,那么我们还有其它方案进行进程间通信吗?有的,那么我们下面学习的共享内存就是由操作系统帮我们在地址空间中进行通信。
我们知道,每一个进程都有自己的 task_struct,也就是有自己的地址空间,然后通过让操作系统在物理内存创建一块内存空间,因为是操作系统,所以它也有资格修改进程的页表、地址空间等。然后将这块内存空间映射到对应进程地址空间的共享区中,最后给应用层返回这个起始的虚拟地址,如下图:
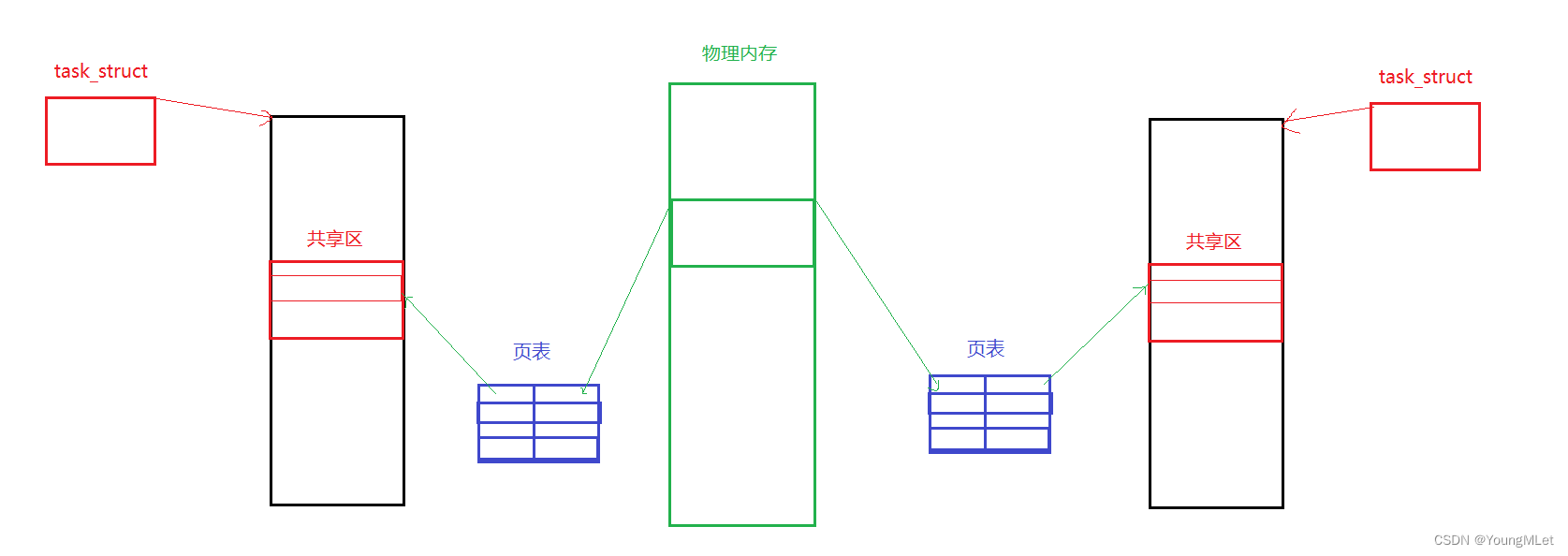
如上过程,就可以让不同的进程,看到了同一份资源!这个原理就叫做共享内存。
所以上面的步骤我们可以分为:
- 申请物理内存
- 将内存挂接(关联)到进程地址空间
- 返回起始地址
如何需要释放共享内存呢?首先需要将进程和共享内存去关联,再去释放共享内存。那么上面的操作,都不是进程直接做的,因为如果是进程去申请空间,那么这个空间就属于这个进程了!就不是共享内存了!所以这些操作都是由操作系统来做的!所以操作系统就必须需要给我们提供一系列的系统调用!
那么系统中肯定不止一两个进程进行进程通信,也就是物理内存中也不止一个共享内存,必定会有很多份,那么操作系统就要管理所有的共享内存!那么操作系统就要对这些共享内存先描述,再组织!所以内核中就得有一个 struct 结构体描述我们申请的共享内存有多大、有多少进程关联等等属性。
2. 系统调用接口
(1)创建共享内存
首先不管怎样,我们得在系统里创建一个共享内存,在 Linux 中创建一个共享内存的系统接口为:shmget(),手册如下:
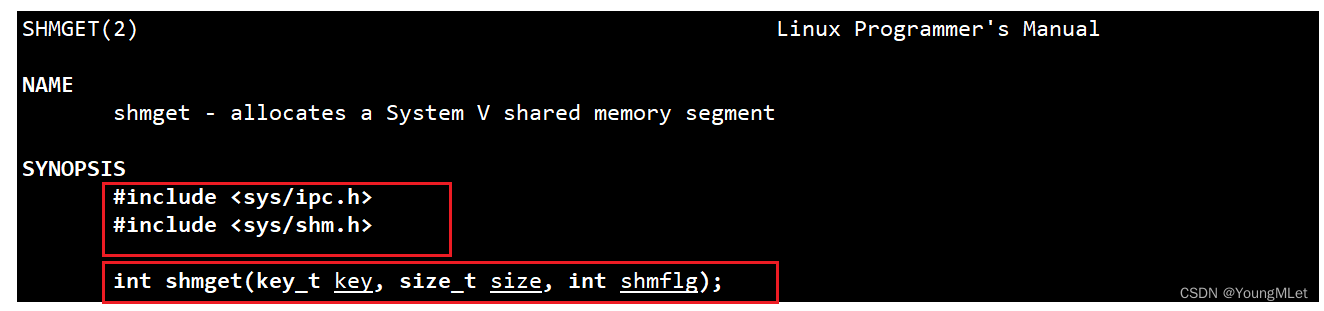

其中返回值,成功返回共享内存的标识符,是一个整数;否则返回 -1,错误码被设置。
- size
而 shmget() 中有三个参数,我们先看第二个参数 size,这个 size 就是需要创建共享内存的大小,单位是字节。
- shmflg
关于第三个参数 shmflg,我们先理解,有进程申请空间,就会有进程使用,那么创建共享内存只需要创建一次就够了,其它进程想在这个共享内存中通信的时候,不需要创建了,只需要获取这个共享内存就行了。所以在使用共享内存时,肯定需要通过某种方式去表示如何创建、如何获取这样的概念,那么 shmflg 就是可以表示这些内容,其中有如下选项:

以上两个选项我们一看就知道,我们以前在学文件的时候也接触过,它们就是宏,而且它们每一个比特位都是不重叠的,用来传标记给系统调用。
其中 IPC_CREAT 表示创建一个共享内存,如果不存在就直接创建,存在就直接获取并返回。如果这个选项单独使用就是以上效果。
IPC_CREAT | IPC_EXCL 表示创建一个共享内存,如果不存在就直接创建,存在就出错返回。那么这两个选项组合使用,就能确保我们申请的共享内存一定是一个新的!
而 IPC_EXCL 不单独使用。
- key
那么问题又来了,系统怎么知道这个共享内存是否存在呢?怎么保证让不同的进程看到同一个共享内存呢?所以这时候就要介绍第一个参数 key 了,就是通过这个参数 key 保证的!
关于参数 key,我们先理解,无论是创建共享内存还是获取共享内存,我们必须要拿到同一个 key,因为拿到同一个 key 才能保证访问的是同一个共享内存!所以 key 是一个数字,它是多少不重要,关键在于它必须在内核中具有唯一性,才能够保证让不同进程进行唯一性标识。
正因为有了 key,第一个进程就可以通过 key 创建共享内存,第二个进程之后,只要拿着同一个 key 就可以和第一个进程看到同一个共享内存了!
那么对于一个已经创建好的共享内存的 key 在哪呢?毫无疑问,key 在共享内存的描述对象中!
那么第一次创建的时候,这个 key 怎么有呢?首先我们需要确保这个 key 具有唯一性,而我们知道,路径天然就具有唯一性,所以我们就可以根据路径这样具有唯一性的属性形成对应的 key,那么在系统中有一个接口可以帮助我们形成一个 key,下面介绍。
(2)形成 key
其中手册如下:


返回值就是 key;第一个参数就是路径,第二参数是项目id;这两个参数我们都可以随意传,只要保证可以创建出具有唯一性的 key 即可,如果创建失败,我们只需要修改这两个参数即可。失败的原因可能有系统内存不足。或者 key 的唯一性不足等等。
其实 ftok() 就是一套算法,它会把我们的路径和项目 id 进行了数值的计算,转化为一个数字。
那么这个 key 为什么要我们用户自己形成呢?因为如果是操作系统帮我们形成,我们就无法将这个 key 交给另一个和我们通信的进程了,它也不知道我们需要和哪一个进程通信,只有我们用户才清楚!所以这个 key 是由用户约定的!
(3)测试接口
接下来我们就可以使用这两个接口进行测试了,我们也引入上一次写的日志函数进来,如下代码:
#define SHM_SIZE 4096
const string pathname = "/home/lmy";
const int proj_id = 0x2314;
log lg;
// 获取 key
key_t GetKey()
{
key_t k = ftok(pathname.c_str(), proj_id);
if(k < 0)
{
lg(Fatal, "ftok error: %s", strerror(errno));
exit(1);
}
lg(Info, "get ftok success, key is: %d", k);
return k;
}
// 创建共享内存
int GetShareMem()
{
key_t k = GetKey();
int shmid = shmget(k, SHM_SIZE, IPC_CREAT | IPC_EXCL);
if(shmid < 0)
{
lg(Fatal, "create shmget error: %s", strerror(errno));
exit(2);
}
lg(Info, "get shareMem success, shmid: %d", shmid);
return shmid;
}
我们启动一个进程A进行测试:
int main()
{
int shmid = GetShareMem();
sleep(10);
lg(Debug, "processA quit!");
return 0;
}
结果如下:
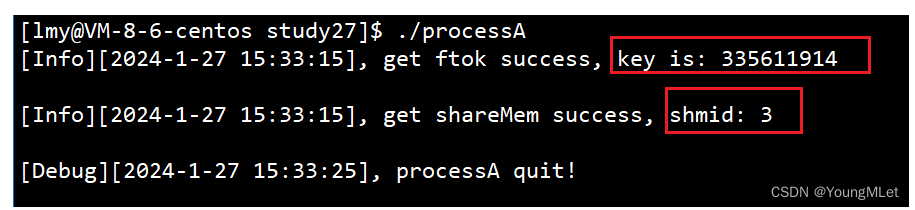
我们看到,返回的 key 和 shmid,它们为什么要同时存在呢?因为 key 是在操作系统内标定唯一性的;而 shmid 只在进程内用来标识资源的唯一性的!
为了方便观察我们可以将 key 打印成十六进制的;当我们创建好共享内存后,再去创建会如何呢?如下:

如上图,明明我们上次运行的进程A已经结束了,为什么重新创建会失败呢?首先我们可以使用 ipcs -m 查看操作系统内所有的 IPC 资源,如下:

其中 perms 是权限,我们还没有设置;nattch 表示当前这个共享内存有几个进程和它是关联的。
但是,我们的进程已经退出了,IPC资源还是存在的!这说明共享内存的生命周期是随内核的!如果用户不主动关闭,共享内存会一直存在,除非内核重启或者用户主动关闭。
那么我们可以使用指令 ipcrm -m shmid 直接删除,如下:

接下来我们就要把权限设置上,那么权限是在 shmget() 的接口第三个参数中设置,如下:
int shmid = shmget(k, SHM_SIZE, IPC_CREAT | IPC_EXCL | 0666);
我们重新运行观察结果,发现权限就有了:

当前有进程创建共享内存了,但是也要有进程获取到共享内存,所以接下来我们需要将接口修改一下,让其它进程也可以获取到共享内存,如下:
int GetShareMem(int flag)
{
key_t k = GetKey();
int shmid = shmget(k, SHM_SIZE, flag);
if(shmid < 0)
{
lg(Fatal, "create shmget error: %s", strerror(errno));
exit(2);
}
lg(Info, "get shareMem success, shmid: %d", shmid);
return shmid;
}
// 创建共享内存
int CreateShm()
{
return GetShareMem(IPC_CREAT | IPC_EXCL | 0666);
}
// 获取共享内存
int GetShm()
{
return GetShareMem(IPC_CREAT);
}
那么下面我们介绍一下共享内存的大小,我们在上面设置的大小是 4096 字节,如果我们将它设置成 4097 呢?我们尝试一下:

如上,大小被设置成了 4097 字节,但是共享内存的大小一般是 4096 的整数倍,我们上面设置的 4097 实际上操作系统申请的共享内存大小是 4096 * 2,但是供我们使用的只有 4097 字节!
(4)关联进程
我们现在已经有了共享内存,接下来就要进行对共享内存和进程进行挂接了。那么使用到的系统接口是:shmat(),手册如下:
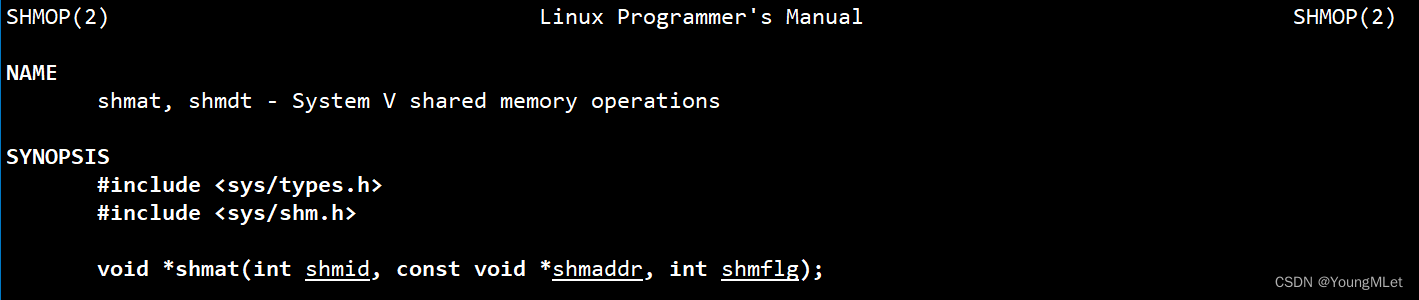

其中第一个参数 shmid 就是我们上面一直在说的 shmid,即创建或获取共享内存接口的返回值。第二个参数 shmaddr 就是我们想让当前的共享内存挂接到共享区的哪个位置,但是一般让系统决定挂接到哪里,所以设置为 nullptr 即可,那么最终挂接到的虚拟地址会以返回值的形式返回给我们。第三个参数 shmflg 就是有关挂接的权限,我们按照共享内存默认的权限即可,设置为0即可。
使用如下:
int main()
{
int shmid = CreateShm();
char* ret = (char*)shmat(shmid, nullptr, 0);
lg(Debug, "attach success");
sleep(3);
return 0;
}
挂接成功后:

进程退出后:

(5)取消关联
我们上面演示的结果中,都是进程退出后自动关闭关联的,那么我们也可以使用系统接口取消关联,对应接口为:shmdt(),手册如下:
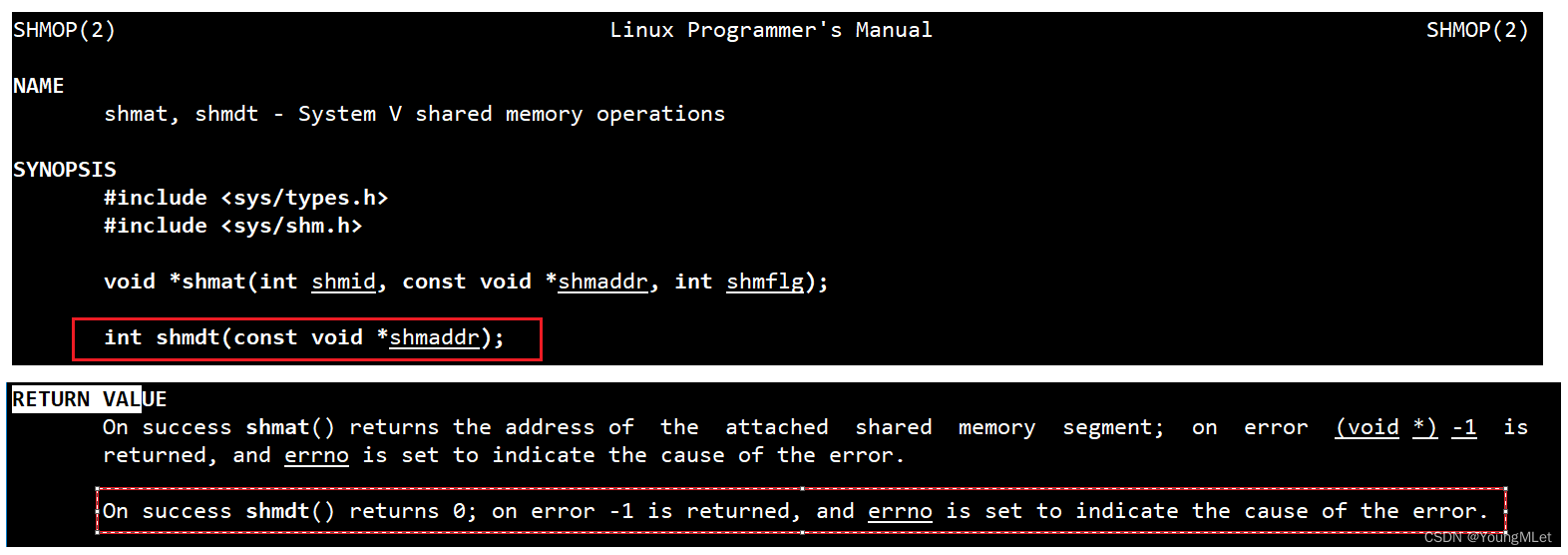
那么它只有一个参数 shmaddr,这个参数就是 shmat() 的返回值。
那么我们只需要传入起始地址就可以了吗?它怎么知道这个空间有多大呢?那么共享内存实际上被申请的时候,它有自己的管理属性,那么它自己会记录共享内存有多大,共享内存也必须是连续的,所以在进行地址空间映射的时候,从连续空间加上大小,我们就知道它的范围了,我们只需要知道从哪开始就行了。
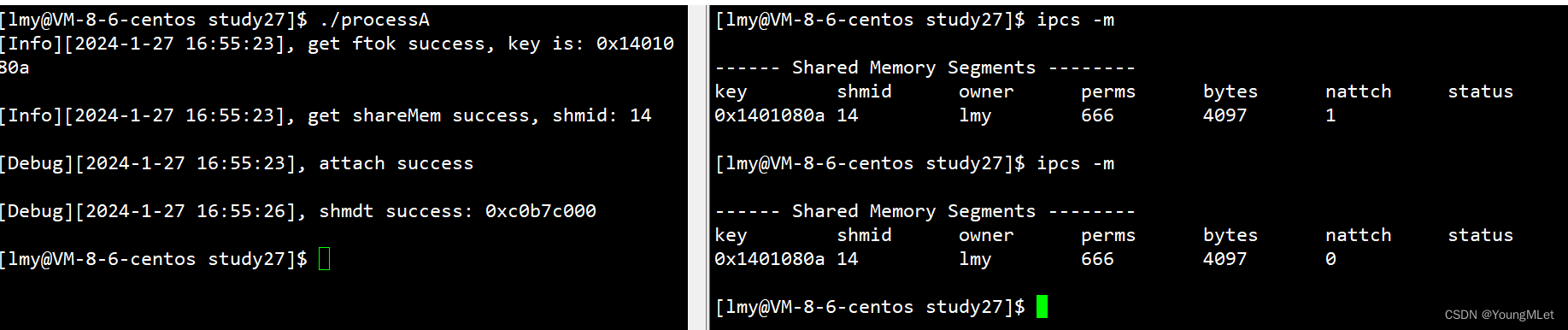
接下来我们对该接口进行测试:
int main()
{
int shmid = CreateShm();
char* ret = (char*)shmat(shmid, nullptr, 0);
lg(Debug, "attach success");
sleep(3);
int r = shmdt(ret);
if(r < 0)
{
lg(Fatal, "shmdt errot: %s", strerror(errno));
exit(3);
}
lg(Debug, "shmdt success: 0x%x", ret);
sleep(3);
return 0;
}
结果如下:
(6)释放共享内存
我们从上面知道,共享内存的生命周期是随内核的,所以每次进程退出后 IPC 资源还是存在的,那么我们也可以使用指令直接把它释放,但是我们还有对应的系统接口释放共享内存,其接口为:shmctl(),手册如下:

那么第一个参数就是共享内存的 id;关于第三个参数,struct shmid_ds 就是类似于内核当中的管理共享内存所对应的 struct 结构体。
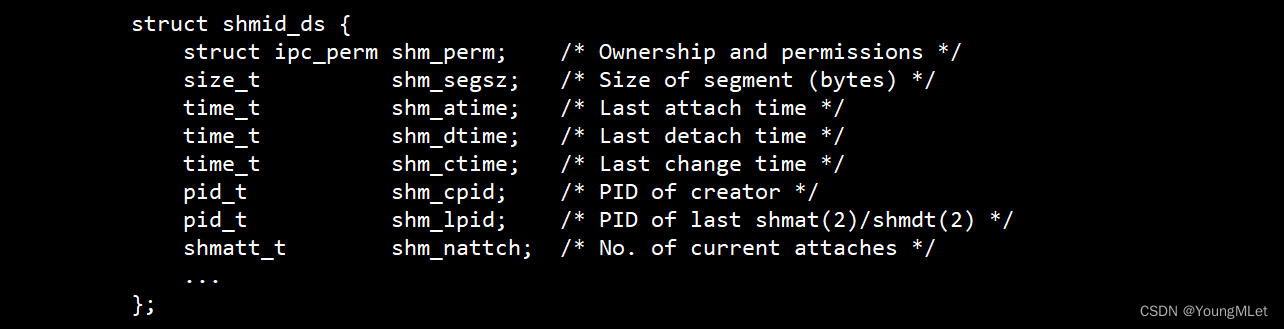
也就是说,它一定能让我们获取到共享内存的属性,那么我们要查看共享内存的属性还是修改还是什么呢?所以就有了第二个参数 cmd,表明我们要做什么操作,那么 cmd 的选项有如下:
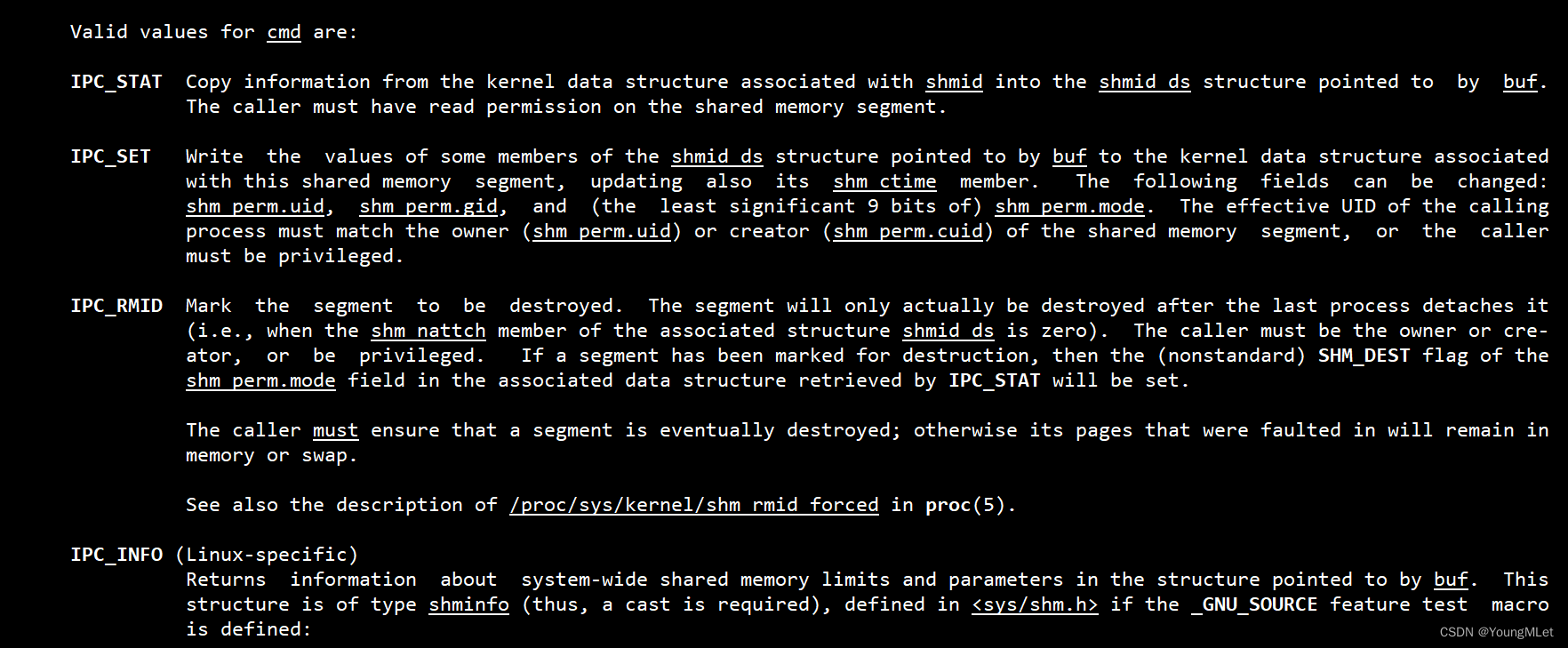
其中我们需要的是 IPC_RMID,它的作用是标记共享内存被删除。我们删除就不关注共享内存的属性了,所以第三个参数设为 nullptr 即可。那么返回值成功也是返回0,失败返回-1.
测试代码如下:
int main()
{
int shmid = CreateShm();
char* ret = (char*)shmat(shmid, nullptr, 0);
lg(Debug, "attach success");
sleep(3);
int r = shmdt(ret);
if(r < 0)
{
lg(Fatal, "shmdt errot: %s", strerror(errno));
exit(3);
}
lg(Debug, "shmdt success: 0x%x", ret);
sleep(3);
int n = shmctl(shmid, IPC_RMID, nullptr);
if(n < 0)
{
lg(Fatal, "shmctl errot: %s", strerror(errno));
exit(4);
}
lg(Debug, "destory shm done, shmaddr: 0x%x", ret);
sleep(3);
return 0;
}
结果如下:

(7)测试通信
上面操作我们已经把一个共享内存的整个生命周期写完了,下面就可以让两个进程实现通信了。
首先我们测试一下让两个进程看到同一份资源。代码如下:
进程A:
int main()
{
int shmid = CreateShm();
char* ret = (char*)shmat(shmid, nullptr, 0);
lg(Debug, "attach success");
sleep(3);
shmdt(ret);
lg(Debug, "shmdt success: 0x%x", ret);
sleep(3);
shmctl(shmid, IPC_RMID, nullptr);
lg(Debug, "destory shm done, shmaddr: 0x%x", ret);
sleep(3);
return 0;
}
进程B:
int main()
{
int shmid = GetShm();
char* ret = (char*)shmat(shmid, nullptr, 0);
lg(Debug, "attach success");
sleep(3);
shmdt(ret);
lg(Debug, "shmdt success: 0x%x", ret);
sleep(3);
return 0;
}
我们只需要观察共享内存中的 nattch 即可判断这两个进程是否已经看到了同一份资源:
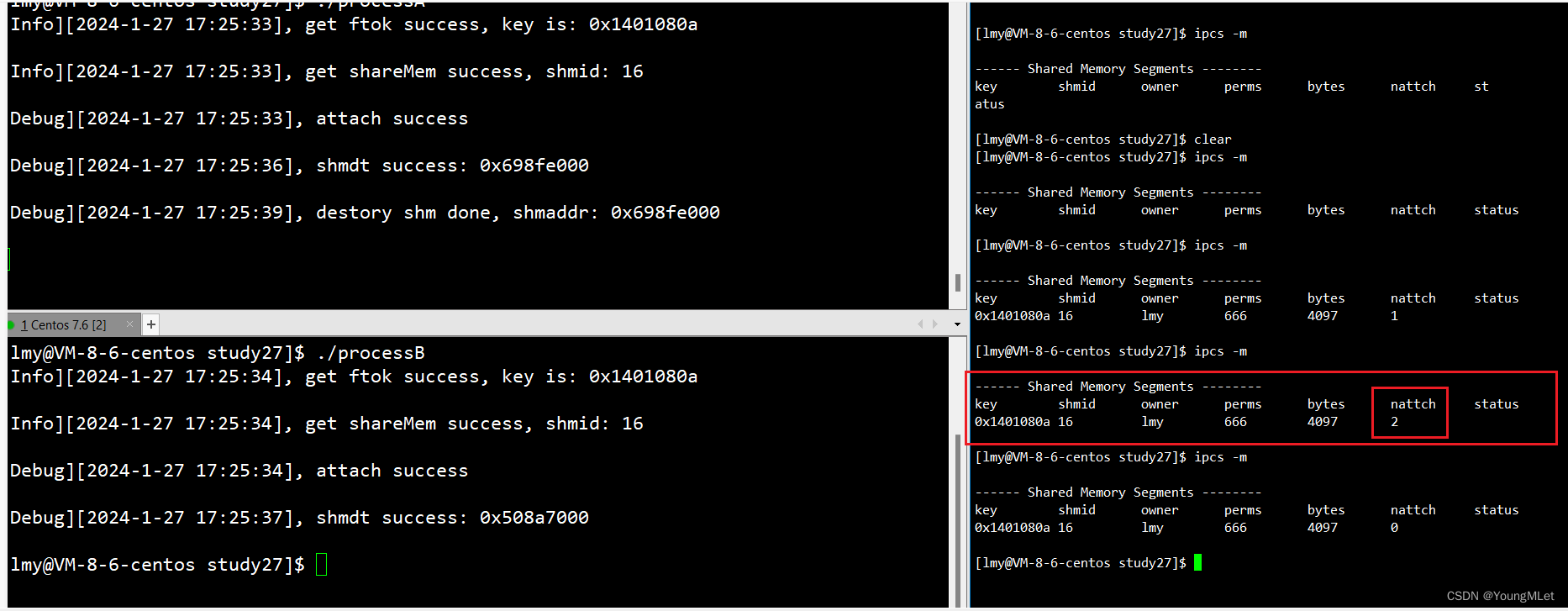
如上,我们就能让两个进程看到了同一份资源。
接下来就可以进行通信了,那么我们可以把两个进程中的日志和休眠函数都去掉;我们让进程A进行读取,即把共享内存当作字符串;进程B进行写入,代码如下:
进程A:
int main()
{
int shmid = CreateShm();
char* ret = (char*)shmat(shmid, nullptr, 0);
// 开始通信
while(true)
{
// 直接访问共享内存
cout << "processB say# " << ret << endl;
sleep(1);
}
shmdt(ret);
shmctl(shmid, IPC_RMID, nullptr);
return 0;
}
进程B:
int main()
{
int shmid = GetShm();
char* ret = (char*)shmat(shmid, nullptr, 0);
// 开始通信
while(true)
{
cout << "Please Enter# ";
fgets(ret, SHM_SIZE, stdin);
}
shmdt(ret);
return 0;
}
如下,我们就可以让两个进程进行通信了:
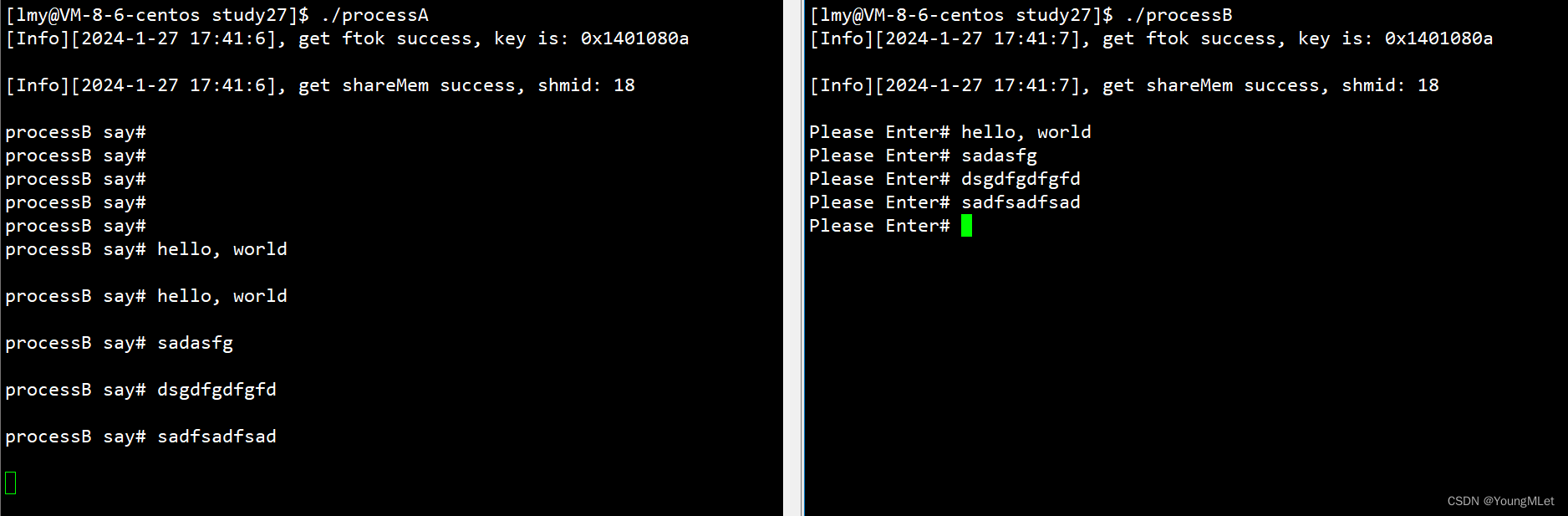
所以通过上面的演示,我们知道了一旦有了共享内存,挂接到自己的地址空间中,直接就可以把它当成自己的内存空间来用即可,不需要调用系统调用!而一旦有人把数据写入到共享内存,其实我们立马就能看到了,不需要经过系统调用就能看到数据了!
3. 共享内存的特性
- 首先我们上面演示的都是两个毫无关系的进程,所以共享内存不需要血缘关系;
- 共享内存没有数据,读端在读的时候会一直往下读,不会阻塞等待,也就是说,共享内存没有同步互斥之类的保护机制;
- 共享内存是所有的进程间通信中,速度最快的,因为它的拷贝最少;
- 共享内存内部的数据,由用户自己维护。
二、SystemV 消息队列(了解)
1. SystemV 消息队列原理
所谓的消息队列,也是由操作系统给我们提供一个内存空间,其实我们就是通过系统接口在操作系统里面创建一个消息队列。
那么想要两个进程进行通信,必须让不同的进程看到同一份资源,我们已经知道了这份资源可以是文件缓冲区、内存块,所以这个公共资源的种类的不同,决定了通信方式的不同。
那么消息队列的公共资源是一个队列,它允许不同的进程向内核中发送数据块,假设进程A将数据块入队列,进程B也将数据块入队列,那么进程A就可以从队列中读取到进程B的数据块。那么进程A和进程B怎么区分这些数据块呢?到底是自己的数据块还是对方的数据块?所以,它们必须区分开来,区分方式就是向内核发送的数据块是带类型的!这个类型就是区分是自己的数据块还是对方的数据块!如下图:
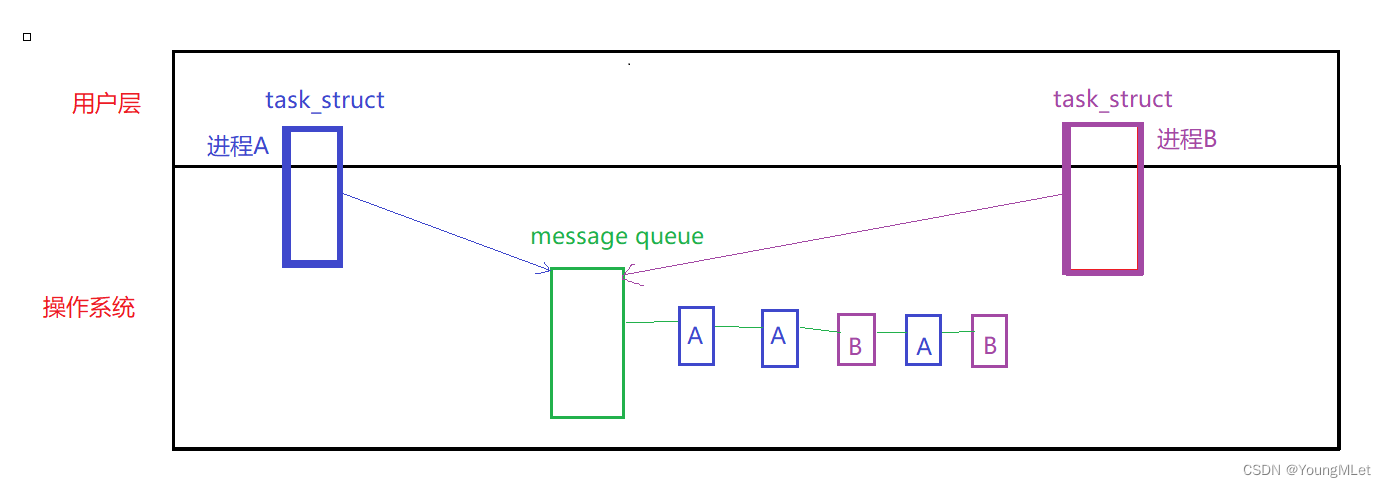
那么操作系统内部肯定不止一个消息队列,会有非常多的进程进行通信,所以操作系统还要管理消息队列,所以需要先描述,再组织!
我们现在介绍的消息队列和上面的学的共享内存都是 SystemV 标准的,那么它们的标准体现在哪里呢?我们对比一下它们的系统接口函数。
2. 系统调用接口
(1)创建消息队列
int msgget(key_t key, int msgflg);
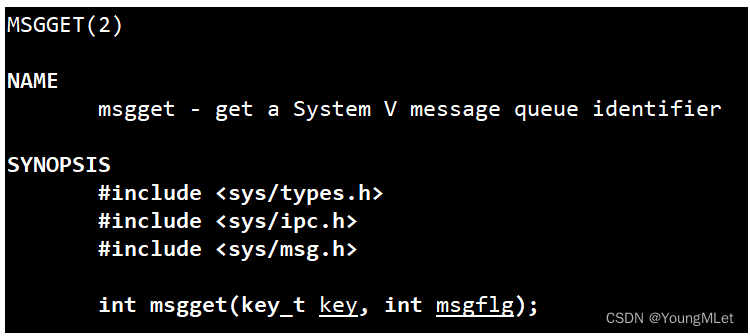
其中参数和返回值都是和共享内存类似的!
(2)形成 key
key_t ftok(const char *pathname, int proj_id);
而形成一个 key 和共享内存是一模一样的!
(3)发送/接收数据
发送数据:
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
其中 msqid 为向指定的消息队列发;msgp 为数据块的起始地址;msgsz 为数据块的大小;msgflg 设为0,阻塞式发就可以了;
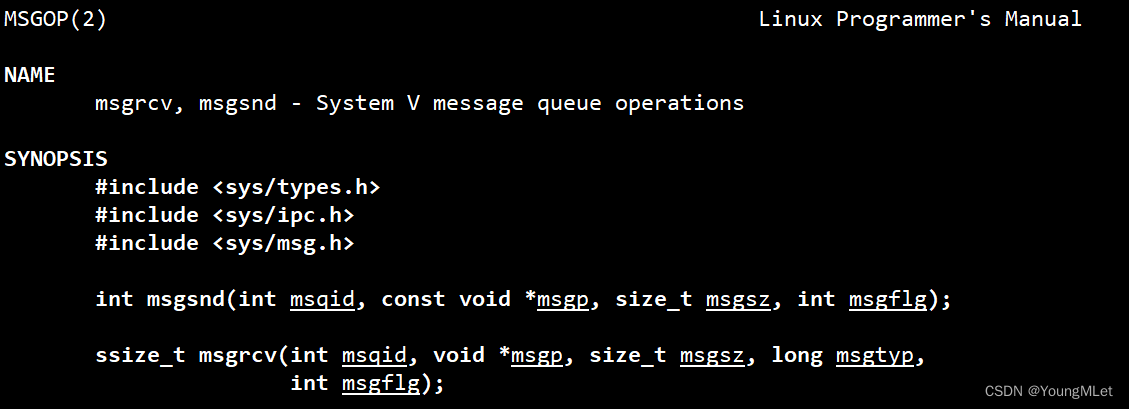
接收数据:
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp,
int msgflg);
前三个参数和上面的一样;msgtyp 是数据块的类型;最后一个参数也是和上面一样。其中我们可以看一看数据块的缓冲区,里面有数据块的类型和大小:

(4)释放消息队列
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
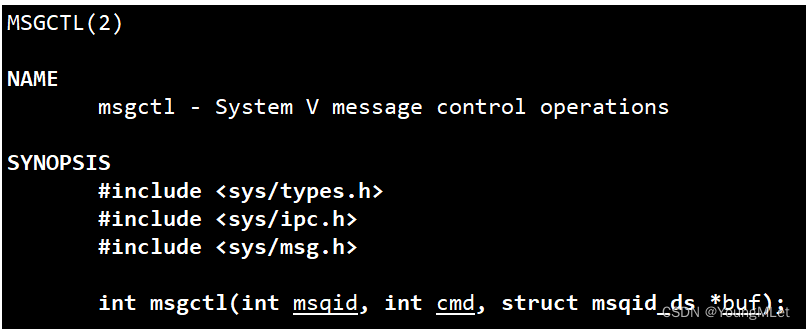
其中这三个参数也是和共享内存类似的!
另外,我们还可以用指令查看操作系统中的消息队列,例如 ipcs -q,如下:

kill 掉消息队列的指令为 ipcrm -q msqid.
三、IPC在内核中的数据结构设计
在介绍 IPC 在内核中的数据结构设计前,我们再先认识一个进程间通信的方式,就是信号量,信号量也和上面学的两个进程间通信方式一样,都是 SystemV 标准的,所以它们都有共同的标准。
例如它们都要在操作系统内部被先描述再管理起来,所以它们都有自己的结构体,被管理起来,我们可以看一下它们被描述的结构体,我们会发现它们都会有共同标准的结构体,也就是命名风格为 struct_xxxid_ds,而且第一个字段类型都是一样的,都是 struct ipc_perm xxx_perm,如下:
- 共享内存
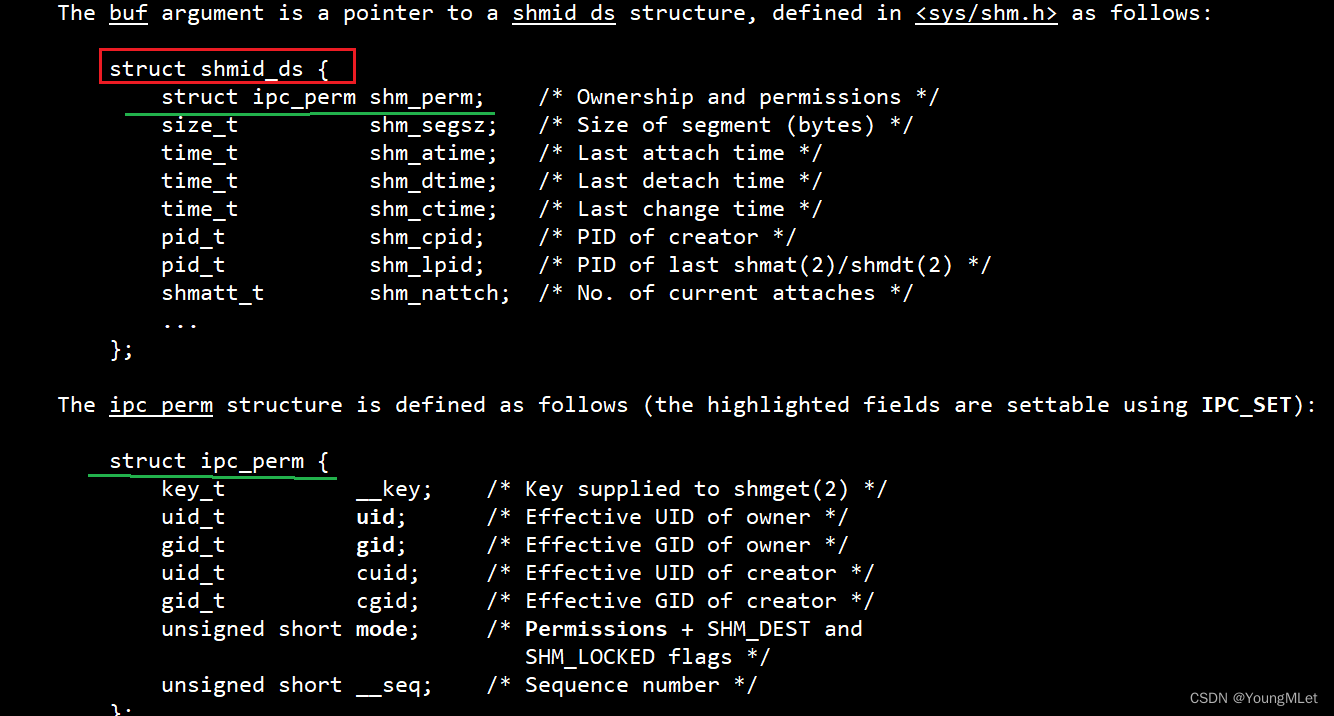
- 消息队列
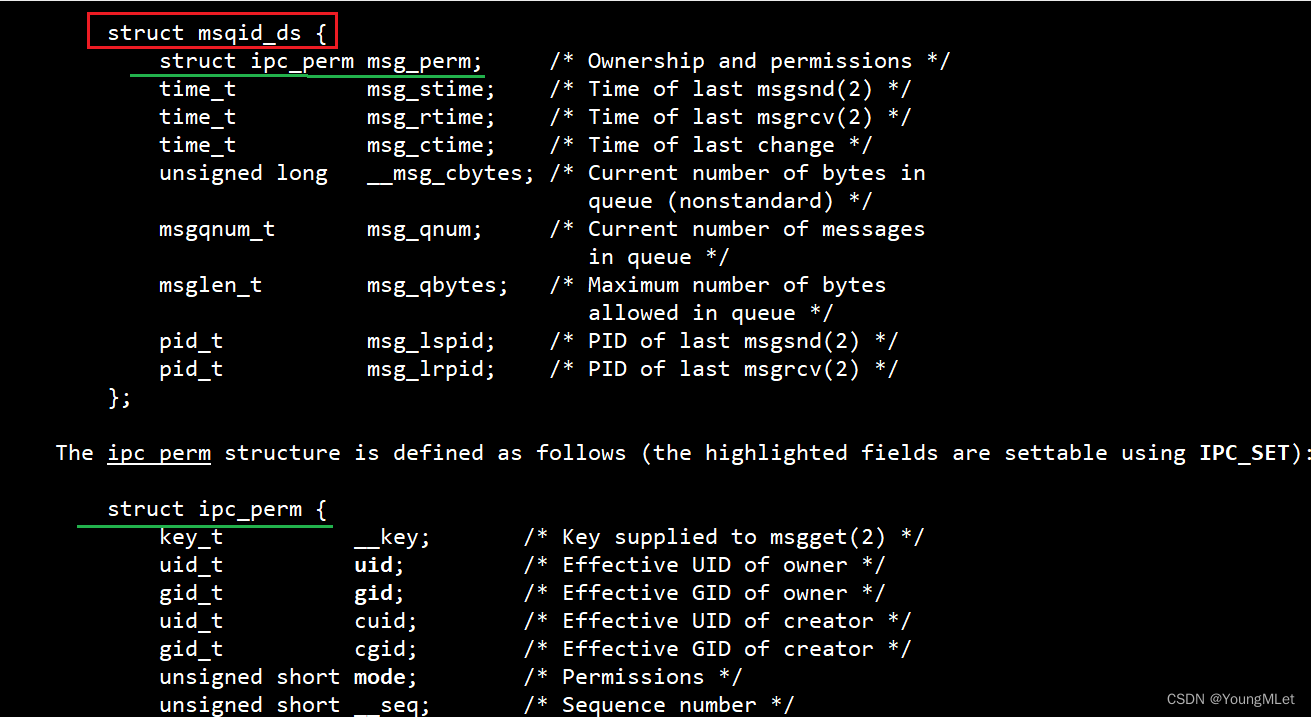
- 信号量
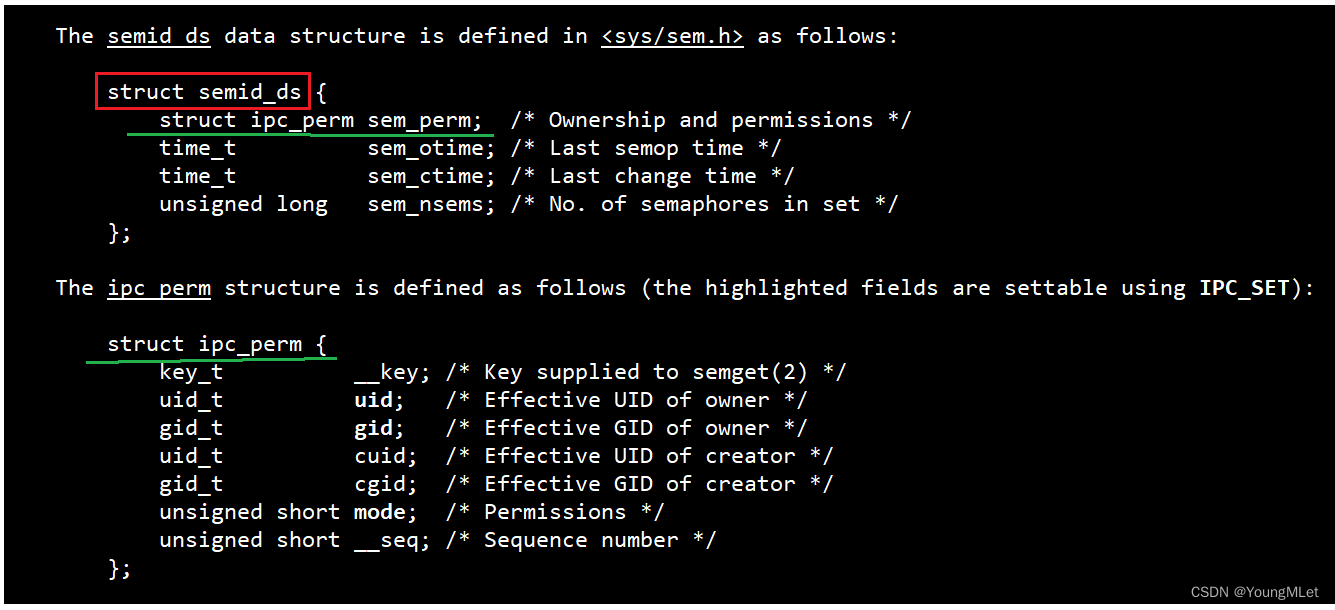
其中系统中的所有 IPC 资源是被整合在操作系统的一个 IPC 模块当中的。
那么我们看到,无论是共享内存、消息队列还是信号量,它们的第一个字段都是一样的,用的都是同一个结构体。由于操作系统以后管理它们,都是管理它们的数据结构,那么它是如何管理这些数据结构的呢?
其实在操作系统中,它是用数组进行管理的!这个数组的名字为 struct ipc_perm* array[];当我们创建共享内存、消息队列、信号量,它们的结构体中的第一个字段都是一样的,所以就将它们的第一个字段填入到该数组中,如下图:
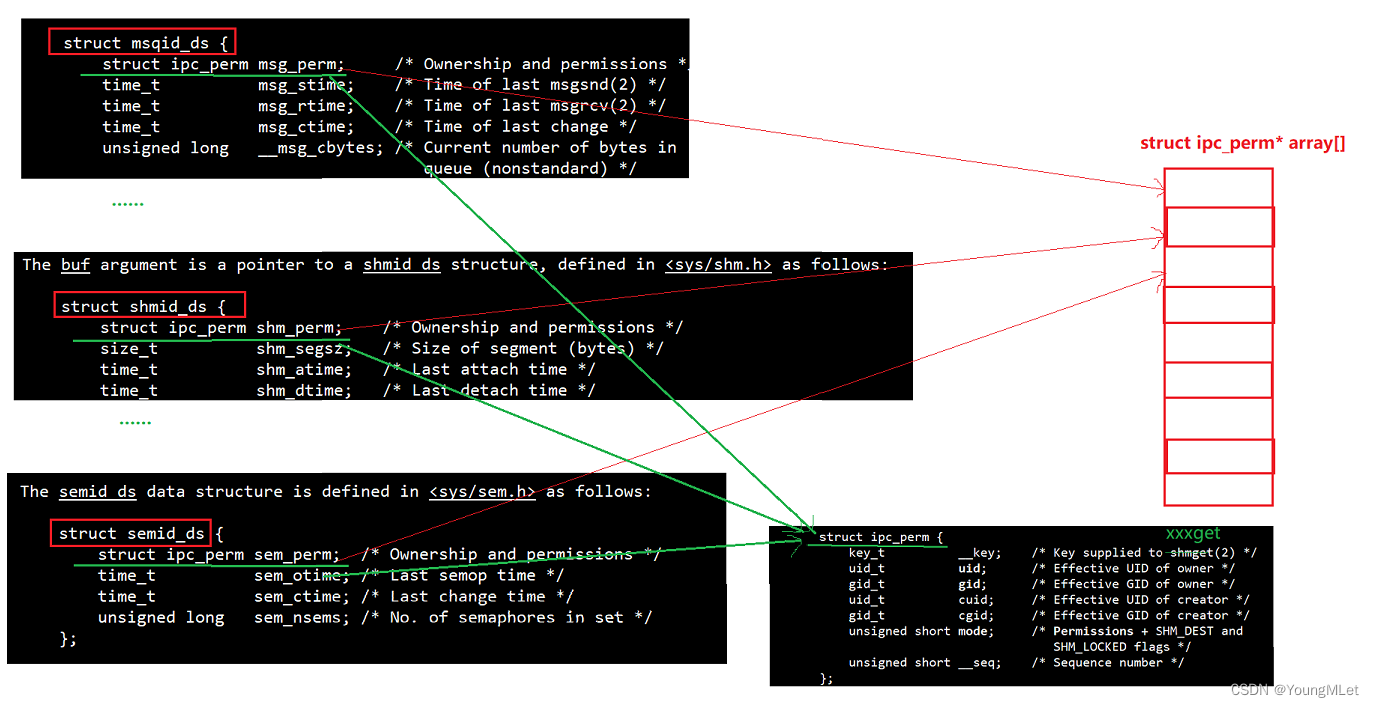
所以从此往后,操作系统要管理所有的 IPC 资源,先描述,对不同的资源有不同的描述方式;对所有的资源增删查改转化为对该数据进行增删查改!所以当我们访问某一个资源,操作系统就得定位某一个资源,它需要确定一个资源是否唯一,它就拿着我们给的 key 遍历这个数组,通过这个数组找到每一个IPC资源,通过比较它们第一个字段的结构体中的 __key 就能确认它是否已经被创建了;其中每一个 ipc_perm 结构,它都在数组里,所以它的数组下标就是对应的 shmid 或者 msqid 或者 semid.
那如果我们想访问某个资源的其它属性呢?也就是想访问操作系统所管理的结构的其它成员?其实在操作系统内部,当我们尝试访问某种资源的时候,我们知道它的结构体的第一个成员的地址是放入数组中的,比如这个数组中的某一个下标内容是 addr,那么接下来怎么访问其它属性呢?很简单,假设我们要访问的资源是共享内存的,只要进行 ((struct shmid_ds*)addr)->??? 即可!那么操作系统怎么知道它要强转成什么类型的资源呢?其实在操作系统内部能区分指针指向的对象的类型。
其实这种机制就是多态!struct ipc_perm 就是基类,其它被管理的结构体都是子类!也就是操作系统内部采用的是用C语言的方式实现的多态!
四、SystemV 信号量
1. 引入概念
我们在共享内存中,如果当进程A正在写入,写入了一部分,就被进程B读取走了,导致双方发送和接收的数据不完整,这就是数据不一致问题。那么这种问题应该如何解决呢?下面就要引入几个概念了。
- 数据不一致
进程A和进程B看到的同一份资源,叫做共享资源,而这份共享资源如果不加以保护,会导致数据不一致问题。
- 互斥访问
而我们可以通过加锁的方式加以保护,此时我们就是通过加锁来保证一种工作状态,叫做互斥访问。也就是说,任何时刻,只允许一个执行流访问共享资源,这就叫做互斥。
- 临界资源
我们一般把共享的,任何时刻只允许一个执行流访问的资源,称为临界资源,这种临界资源一般都是内存空间。
- 临界区
其实我们写的代码中,只有少部分代码在访问临界资源,这少部分访问临界资源的代码叫做临界区。
接下来我们解释一个现象,如果我们有多个进程,都往显示器打印,也就是在并发打印,为什么显示器上的消息会出现错乱混乱或者和命令行混在一起呢?因为显示器是文件,我们都往显示器上打印,所以本质上显示器也是共享资源,而这必将会导致数据不一致问题,而我们也没有对显示器资源加以保护,所以这是正常现象。
2. 理解信号量
其实信号量的本质就是一个计数器!它是用来描述临界资源中的资源数量的多少!
例如我们去看电影买票,我们还没有去看,先买票的本质就是对资源的预定机制。而在买票的时候,必定会有一个票数的计数器,每卖一张票,计数器就减1,放映厅的资源就少一个。当票数的计数器减到0,表示资源已经被申请完毕了。
这就可以类比计算机中,临界资源可以被划分为很多很多的临界资源单位,所以当一个执行流来访问临界资源的时候,我们就可以把一个临界资源单位分配给该执行流。这样就可以提高多执行流访问临界资源的并发度,只要保证它们不访问同一个临界资源单位,可以在一定程度上提高效率。
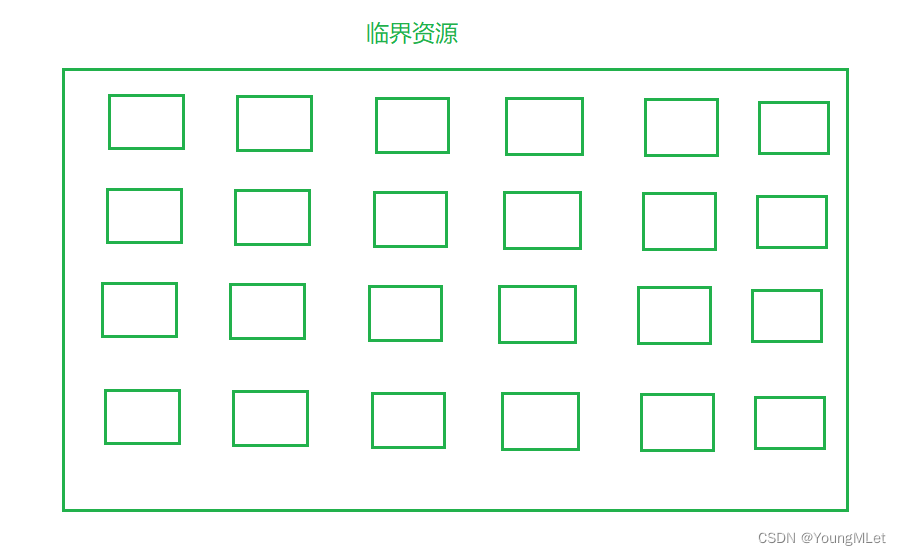
这种情况下,我们最怕的就是多个执行流访问同一个资源,或者执行流的数量大于临界资源单位的数量。所以为了避免这些情况,我们就需要引入一个计数器,计数器记录临界资源的数量,每当有一个执行流访问一个临界资源单位,计数器就减一。当计数器等于零的时候,表示资源被申请完了。
所以,申请计数器的过程等同于买票的过程;临界资源等同于放映厅;临界资源单位等同于放映厅内的座位;计数器的多少等同于座位的多少。所以,
- 当我们申请计数器成功了,就表示我具有访问资源的权限了
- 申请了计数器资源,本质就是对资源的预定机制
- 计数器可以有效保证进入共享资源的执行流的数量
- 所以每一个执行流,想访问共享资源中的一部分的时候,不是直接访问,而是先申请计数器,跟看电影的本质一样
所以我们把这个 “计数器” 叫做信号量!
我们把值只能为1或0两态的计数器,叫做二元信号量,本质就是一把锁!
所以我们要访问临界资源,先要申请信号量计数器资源,那么信号量计数器本质不也是共享资源吗?所以信号量计数器也要被加以保护!那么计数器本质就是对一个变量做减减操作,比如 cnt--,那么这个操作也是不安全的。因为它在 C/C++ 上是一条语句,但是它编译成汇编语言后,它会变成多条汇编语句,而进程在运行的时候,可以随时被切换,所以可能在某个汇编语句的时候,进程会被切换走,所以是不安全的!这个问题我们后面多线程再说。
所以现在我们只需要知道,申请信号量,本质就是对计数器减减,这个操作我们称为P操作;释放资源,释放信号量本质是对计数器加加,这个操作称为V操作;所以申请和释放称为PV操作,这种PV操作必须是原子的,也就是说要么就完成,要么就不完成,没有正在完成的概念。
所以总结一下,信号量本质是一把计数器,来进行PV操作,而这个操作是原子的。执行流申请资源,必须先申请信号量的资源,得到信号量之后,才能访问临界资源!信号量值为1、0两态的称为二元信号量,就是互斥功能;申请信号量的本质就是对临界资源的预定机制!
3. 了解系统调用接口
(1)申请信号量
int semget(key_t key, int nsems, int semflg);
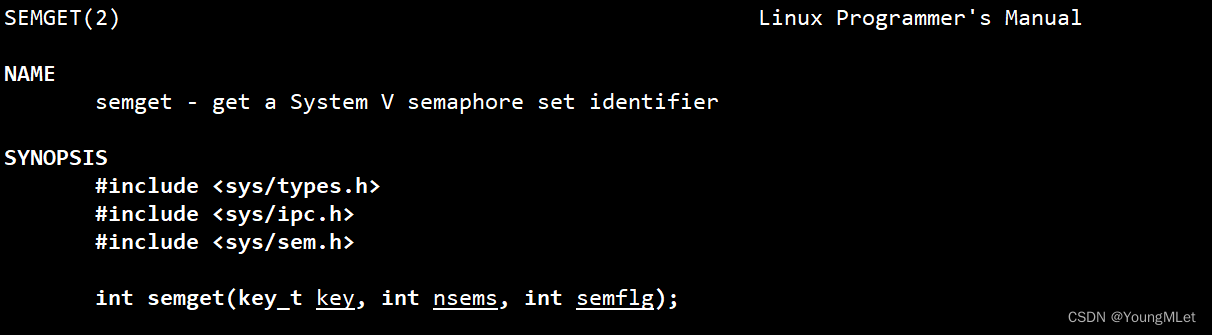
其中 nsems 是申请信号量的数量,但是多个信号量不等于信号量是几,我们一般设为1即可。
(2)释放信号量
int semctl(int semid, int semnum, int cmd, ...);
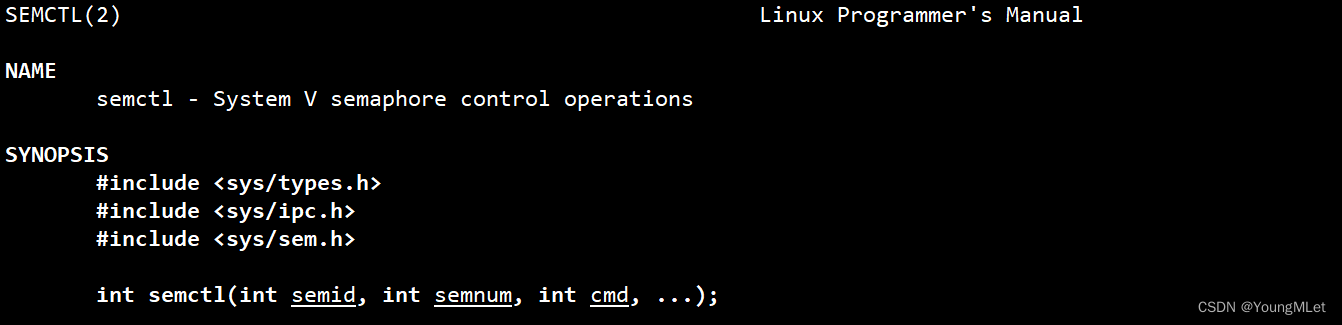
其中可变参数可以不用传。
(3)操作信号量
其中 PV 操作就是根据该函数来完成的:
int semop(int semid, struct sembuf *sops, unsigned nsops);
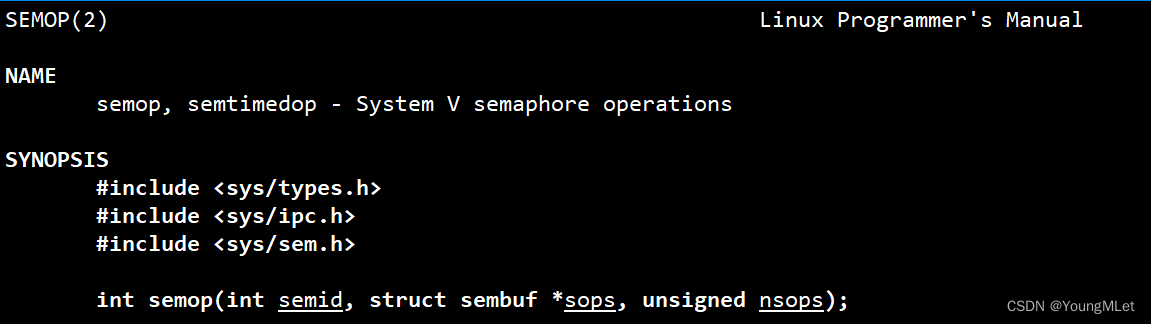

系统接口方面现在了解即可,后面多线程我们还会介绍。
最后,那么信号量为什么是进程间通信的一种呢?共享内存和消息队列都可以传数据,所以叫通信,那么信号量没有传数据为什么是进程间通信的一种呢?严格意义上讲,如果把通信定义成数据互相传送数据,那么信号量就不应该是通信的一种,但是通信不仅仅是进行传送数据,互相协同也是!那么要协同,本质也是通信,信号量首先要被所有的通信进程看到!那么信号量本质也是一种共享资源,所以它也算是进程间通信的一种!