《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
一、AI应用软件开发实战专栏【链接】
| 项目名称 | 项目名称 |
|---|---|
| 1.【人脸识别与管理系统开发】 | 2.【车牌识别与自动收费管理系统开发】 |
| 3.【手势识别系统开发】 | 4.【人脸面部活体检测系统开发】 |
| 5.【图片风格快速迁移软件开发】 | 6.【人脸表表情识别系统】 |
| 7.【YOLOv8多目标识别与自动标注软件开发】 | 8.【基于YOLOv8深度学习的行人跌倒检测系统】 |
| 9.【基于YOLOv8深度学习的PCB板缺陷检测系统】 | 10.【基于YOLOv8深度学习的生活垃圾分类目标检测系统】 |
| 11.【基于YOLOv8深度学习的安全帽目标检测系统】 | 12.【基于YOLOv8深度学习的120种犬类检测与识别系统】 |
| 13.【基于YOLOv8深度学习的路面坑洞检测系统】 | 14.【基于YOLOv8深度学习的火焰烟雾检测系统】 |
| 15.【基于YOLOv8深度学习的钢材表面缺陷检测系统】 | 16.【基于YOLOv8深度学习的舰船目标分类检测系统】 |
| 17.【基于YOLOv8深度学习的西红柿成熟度检测系统】 | 18.【基于YOLOv8深度学习的血细胞检测与计数系统】 |
| 19.【基于YOLOv8深度学习的吸烟/抽烟行为检测系统】 | 20.【基于YOLOv8深度学习的水稻害虫检测与识别系统】 |
| 21.【基于YOLOv8深度学习的高精度车辆行人检测与计数系统】 | 22.【基于YOLOv8深度学习的路面标志线检测与识别系统】 |
| 23.【基于YOLOv8深度学习的智能小麦害虫检测识别系统】 | 24.【基于YOLOv8深度学习的智能玉米害虫检测识别系统】 |
| 25.【基于YOLOv8深度学习的200种鸟类智能检测与识别系统】 | 26.【基于YOLOv8深度学习的45种交通标志智能检测与识别系统】 |
| 27.【基于YOLOv8深度学习的人脸面部表情识别系统】 | 28.【基于YOLOv8深度学习的苹果叶片病害智能诊断系统】 |
| 29.【基于YOLOv8深度学习的智能肺炎诊断系统】 | 30.【基于YOLOv8深度学习的葡萄簇目标检测系统】 |
| 31.【基于YOLOv8深度学习的100种中草药智能识别系统】 | 32.【基于YOLOv8深度学习的102种花卉智能识别系统】 |
| 33.【基于YOLOv8深度学习的100种蝴蝶智能识别系统】 | 34.【基于YOLOv8深度学习的水稻叶片病害智能诊断系统】 |
| 35.【基于YOLOv8与ByteTrack的车辆行人多目标检测与追踪系统】 |
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
《------正文------》
前言
论文发表时间:2023.02.03
paper地址:https://arxiv.org/pdf/2302.01791.pdf
github地址:https://github.com/JIAOJIAYUASD/dilateformer

文章提出了一种新的注意力机制——多尺度空洞注意力(MSDA)。MSDA 能够模拟小范围内的局部和稀疏的图像块交互,从而减少全局注意力模块中存在大量的冗余。因为作者发现在浅层次上,注意力矩阵具有局部性和稀疏性两个关键属性,这表明在浅层次的语义建模中,远离查询块的块大部分无关,全局注意力模块中存在大量的冗余。本文详细介绍了如何在yolov8中引入MSDA,有效地减少自注意力机制的冗余,无需复杂的操作和额外的计算成本,并且使用修改后的yolov8进行目标检测训练与推理。本文提供了所有源码免费供小伙伴们学习参考,需要的可以通过文末方式自行下载。
本文改进使用的ultralytics版本为:ultralytics == 8.0.227
目录
- 前言
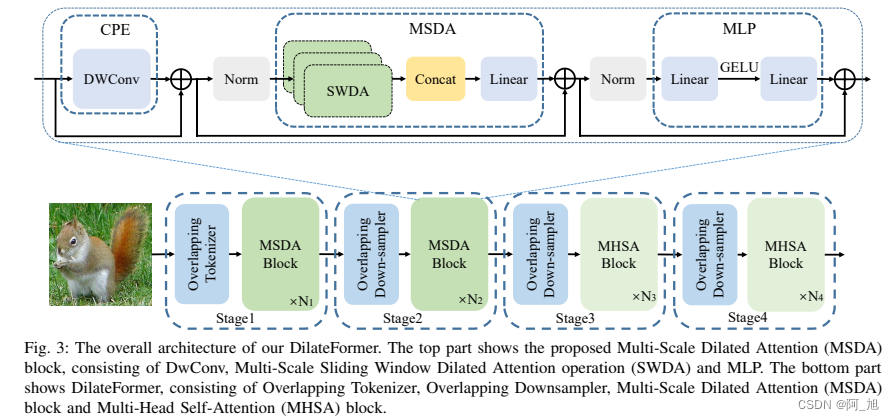
- 1.DilateFormer简介
- 1.1 网络结构
- 1.2 性能对比
- 2.YOLOv8添加MSDA
- YOLOv8网络结构前后对比
- 定义相关类
- 修改指定文件
- 3.加载配置文件并训练
- 4.模型推理
- 【源码免费获取】
- 结束语
1.DilateFormer简介
摘要:本文提出了一种新颖的
多尺度空洞 Transformer,简称DilateFormer,以用于视觉识别任务。原有的 ViT 模型在计算复杂性和感受野大小之间的权衡上存在矛盾。众所周知,ViT 模型使用全局注意力机制,能够在任意图像块之间建立长远距离上下文依赖关系,但是全局感受野带来的是平方级别的计算代价。同时,有些研究表明,在浅层特征上,直接进行全局依赖性建模可能存在冗余,因此是没必要的。为了克服这些问题,作者提出了一种新的注意力机制——多尺度空洞注意力(MSDA)。MSDA 能够模拟小范围内的局部和稀疏的图像块交互,这些发现源自于对 ViTs 在浅层次上全局注意力中图像块交互的分析。作者发现在浅层次上,注意力矩阵具有局部性和稀疏性两个关键属性,这表明在浅层次的语义建模中,远离查询块的块大部分无关,因此全局注意力模块中存在大量的冗余。
1.1 网络结构
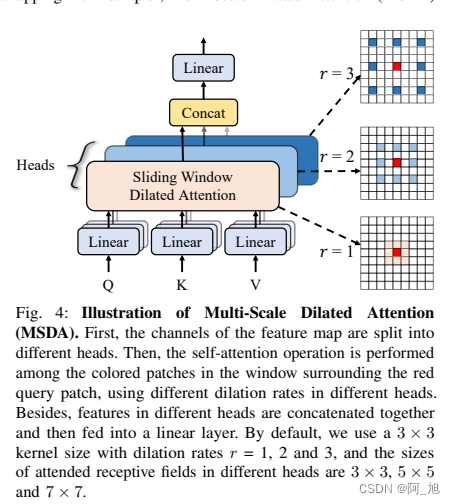
1.2 性能对比
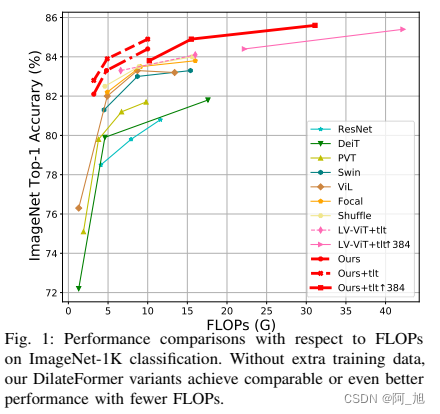
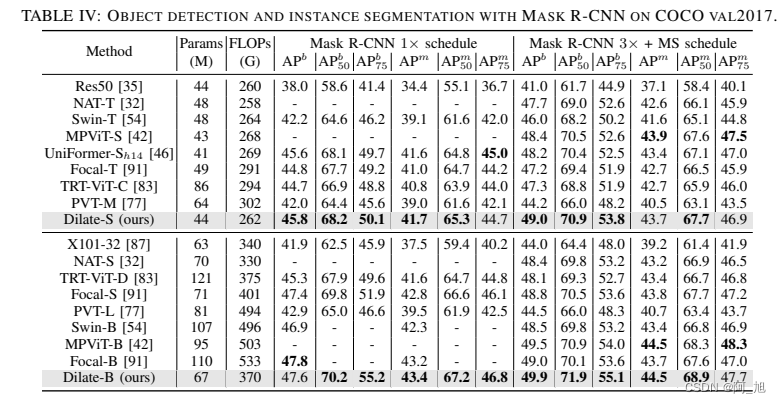
2.YOLOv8添加MSDA
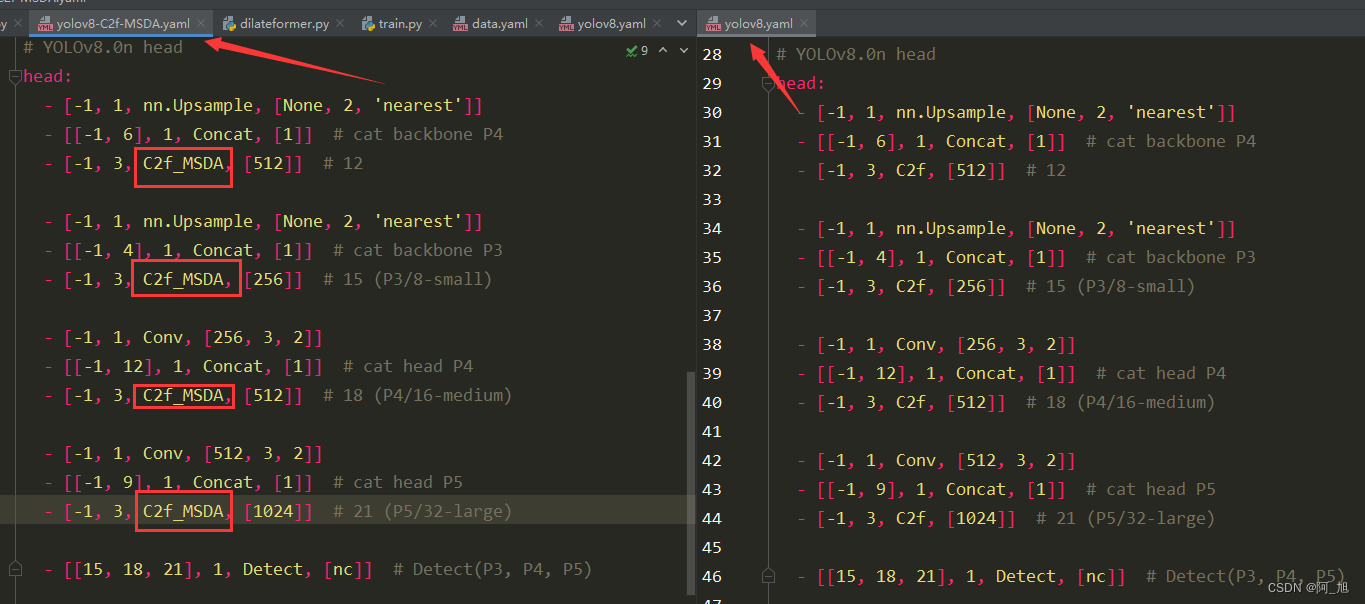
YOLOv8网络结构前后对比
定义相关类
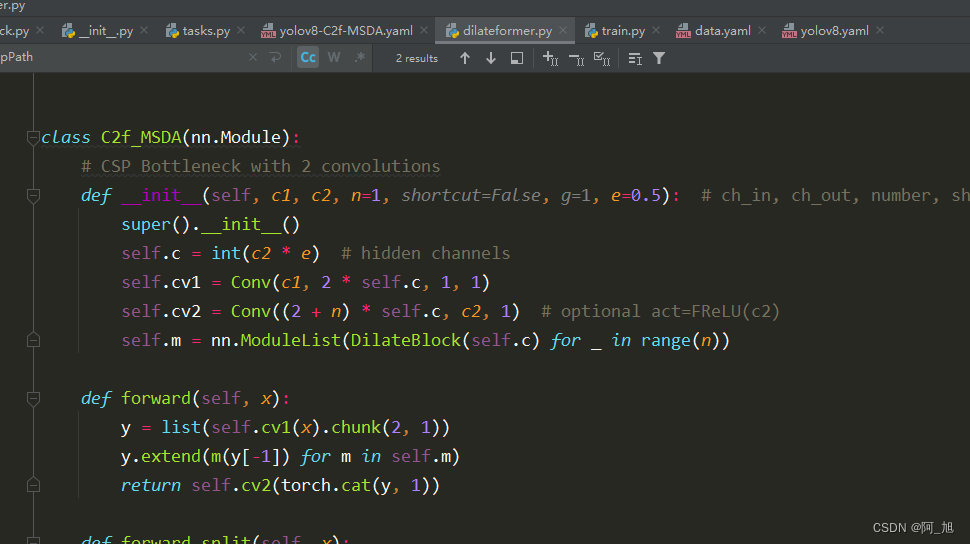
在ultralytics/nn/attention/中新建dilateformer.py,代码如下:
修改指定文件
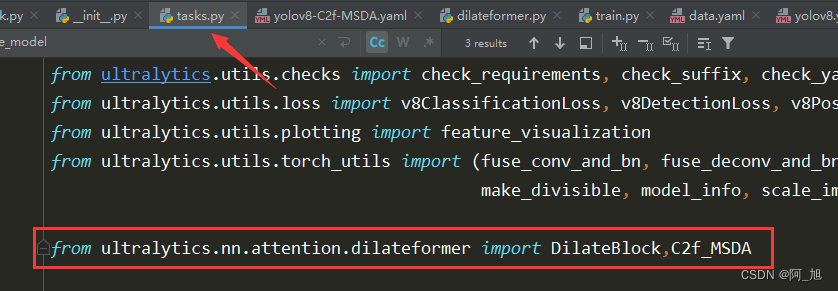
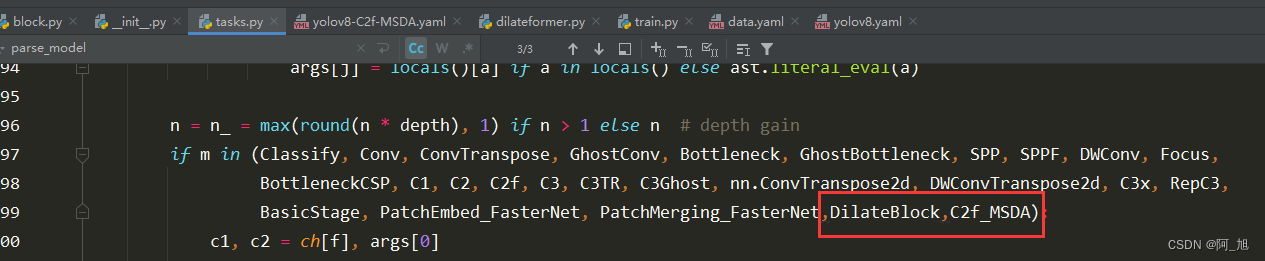
在 ultralytics/nn/tasks.py 上方导入相应类名,并在parse_model解析函数中添加如下代码:
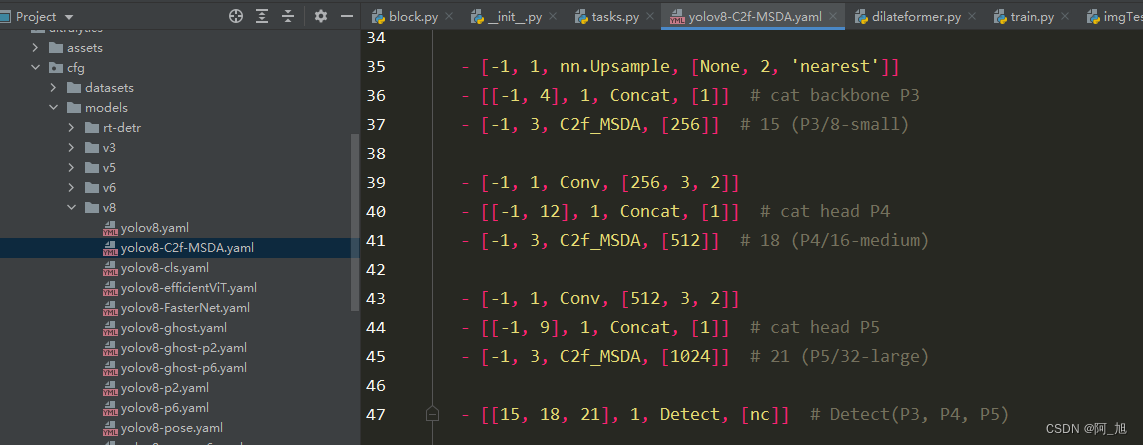
在ultralytics/cfg/models/v8文件夹下新建yolov8-C2f-MSDA.yaml文件,内容如下:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f_MSDA, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f_MSDA, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f_MSDA, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f_MSDA, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
3.加载配置文件并训练
加载yolov8-C2f-MSDA.yaml配置文件,并运行train.py训练代码:
#coding:utf-8
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/v8/yolov8-C2f-MSDA.yaml')
model.load('yolov8n.pt') # loading pretrain weights
model.train(data='datasets/TomatoData/data.yaml', epochs=50, batch=4)
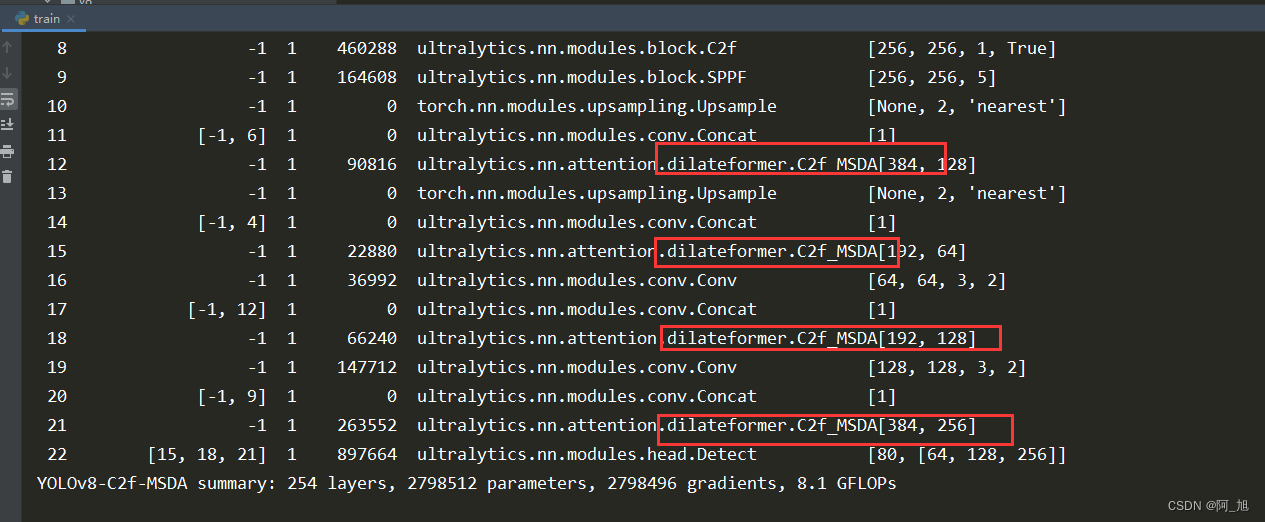
注意观察,打印出的网络结构是否正常修改,如下图所示:
4.模型推理
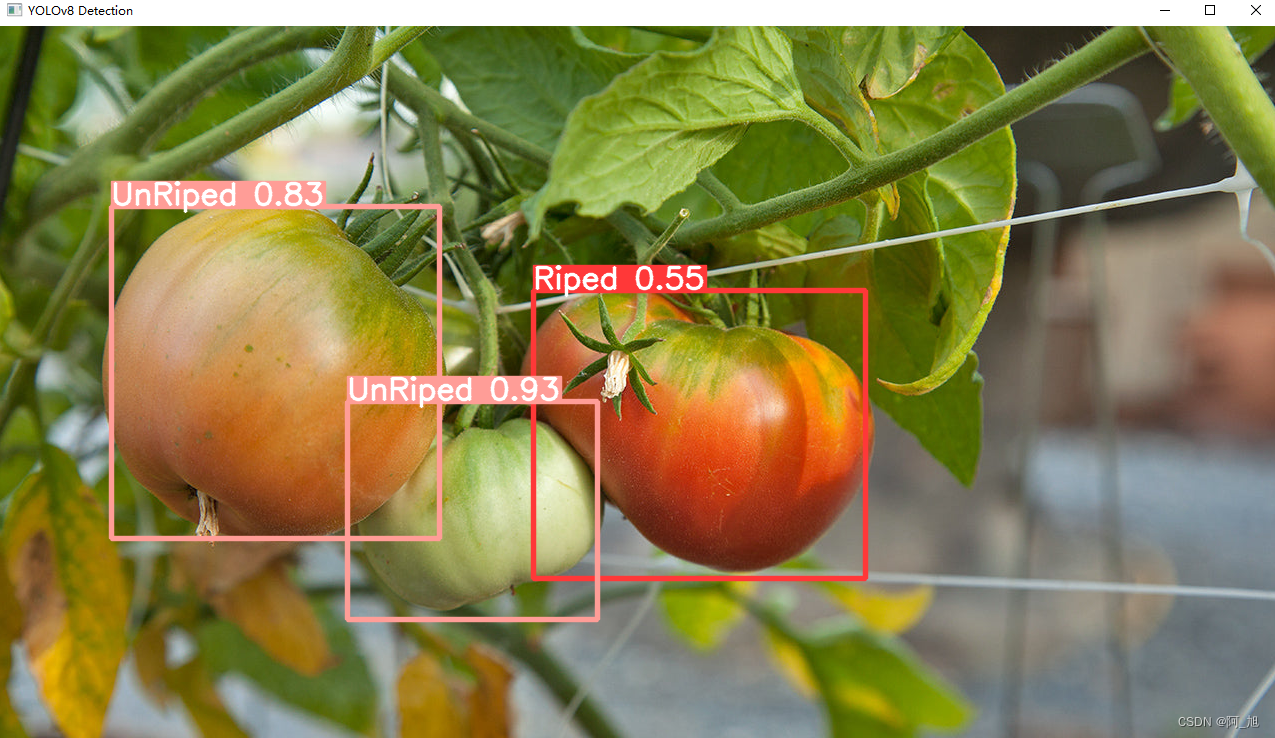
模型训练完成后,我们使用训练好的模型对图片进行检测:
#coding:utf-8
from ultralytics import YOLO
import cv2
# 所需加载的模型目录
# path = 'models/best2.pt'
path = 'runs/detect/train3/weights/best.pt'
# 需要检测的图片地址
img_path = "TestFiles/Riped tomato_8.jpeg"
# 加载预训练模型
# conf 0.25 object confidence threshold for detection
# iou 0.7 intersection over union (IoU) threshold for NMS
model = YOLO(path, task='detect')
# 检测图片
results = model(img_path)
res = results[0].plot()
# res = cv2.resize(res,dsize=None,fx=2,fy=2,interpolation=cv2.INTER_LINEAR)
cv2.imshow("YOLOv8 Detection", res)
cv2.waitKey(0)
【源码免费获取】
为了小伙伴们能够,更好的学习实践,本文已将所有代码、示例数据集、论文等相关内容打包上传,供小伙伴们学习。获取方式如下:
关注下方名片G-Z-H:【阿旭算法与机器学习】,发送【yolov8改进】即可免费获取
结束语
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!
觉得不错的小伙伴,感谢点赞、关注加收藏哦!