阅读数据是您处理数据的第一步,而数据是人工智能时代里机器学习的生产资料。

概述
在这个系列中,您将学习关于pandas的所有内容,它是最受欢迎的用于数据分析的Python库。 在学习过程中,你将完成几个实际数据的实践练习。建议您在阅读相应的文章时进行练习。当然,作者政安晨也会把演绎的图片贴出来,您也可以当作是您已经做过了。
Pandas具体是什么我这里就不多说了,直接干货。
开始
开始Pandas,您需要一个能工作的环境,如果您还没有准备好,参考我的这篇文章:
政安晨:机器学习快速入门(一){基于Python与Pandas}![]() https://blog.csdn.net/snowdenkeke/article/details/136046028
https://blog.csdn.net/snowdenkeke/article/details/136046028
要使用pandas,通常你会从下面这行代码开始。
import pandas as pd咱们启动一个Jupyter,并导入pandas库:

建立数据
在pandas中有两个核心对象:DataFrame 和 Series。
DataFrame
一个DataFrame是一个表格。它包含了一系列的个别条目,每个条目都有一个特定的值。每个条目对应一行(或记录)和一列。
例如,考虑以下简单的DataFrame:
pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]})
政安晨用Jupyter执行如下:
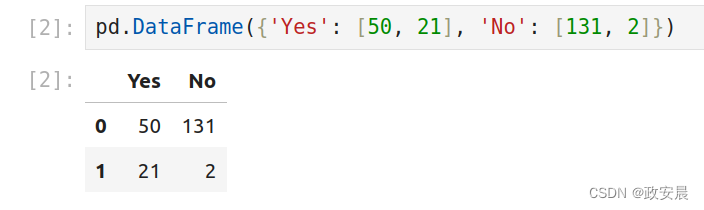
在这个例子中,
"0, No"的条目的值为131,"0, Yes"的条目的值为50,等等,DataFrame的条目不限于整数。
例如,这是一个值为字符串的DataFrame:

我们使用pd.DataFrame()构造函数生成这些DataFrame对象。声明一个新的DataFrame的语法是一个字典,其键是列名(在这个例子中是Bob和Sue),值是一个条目的列表。这是构建新的DataFrame的标准方式,也是您最有可能遇到的方式。
字典列表构造函数为列标签分配值,但对于行标签,它只使用从0开始的递增计数(0、1、2、3……)。有时这是可以接受的,但通常我们会希望自己指定这些标签。
在DataFrame中使用的行标签列表被称为索引。我们可以通过在构造函数中使用index参数来为其赋值。
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index=['Product A', 'Product B'])
Series
与之相比,Series是一系列的数据值。如果DataFrame是一张表格,那么Series就是一个列表。实际上,你可以仅仅用一个列表来创建一个Series。
pd.Series([1, 2, 3, 4, 5])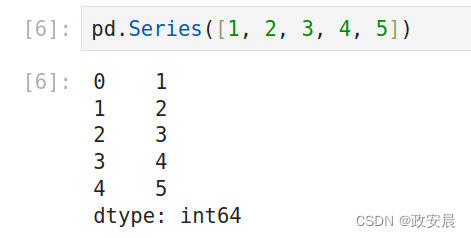
序列本质上是DataFrame的单列。因此,可以使用索引参数将行标签分配给序列,方式与之前相同。然而,序列没有列名,只有一个总体名称:
pd.Series([30, 35, 40], index=['2015 Sales', '2016 Sales', '2017 Sales'], name='Product A')
Series和DataFrame是密切相关的。把DataFrame想象成一堆"粘在一起的"Series会有助于我们理解。
读取数据文件
能够手动创建DataFrame或Series是非常方便的。但是,大多数情况下,我们实际上不会手动创建自己的数据,而是与已经存在的数据一起进行操作。
数据可以以多种不同的形式和格式存储。其中最基本的是简单的CSV文件。当你打开一个CSV文件时,你会看到类似下面的内容:
Product A,Product B,Product C, 30,21,9, 35,34,1, 41,11,11
CSV文件是由逗号分隔的值组成的表格。因此得名为“逗号分隔值”或CSV。
现在,让我们暂时将玩具数据集放在一边,看看在将真实数据集读入到DataFrame时它是什么样子的。我们将使用pd.read_csv()函数将数据读入到DataFrame中。用法如下:
(这里,咱们还是使用文章头部的csv数据集,大家下载解压使用,并把解压后的文件拷贝到您的虚拟环境目录中使用)
wine_reviews = pd.read_csv("./melb_data.csv")我们可以使用shape属性来检查生成的DataFrame有多大。
wine_reviews.shape老晨执行如下:
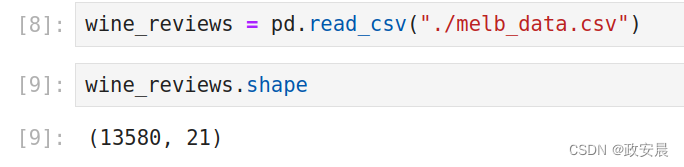
所以我们的新DataFrame有13580个记录,分布在21个不同的列中。总共有27万多个条目!
我们可以使用head()命令来检查结果DataFrame的内容,该命令会抓取前五行:
wine_reviews.head()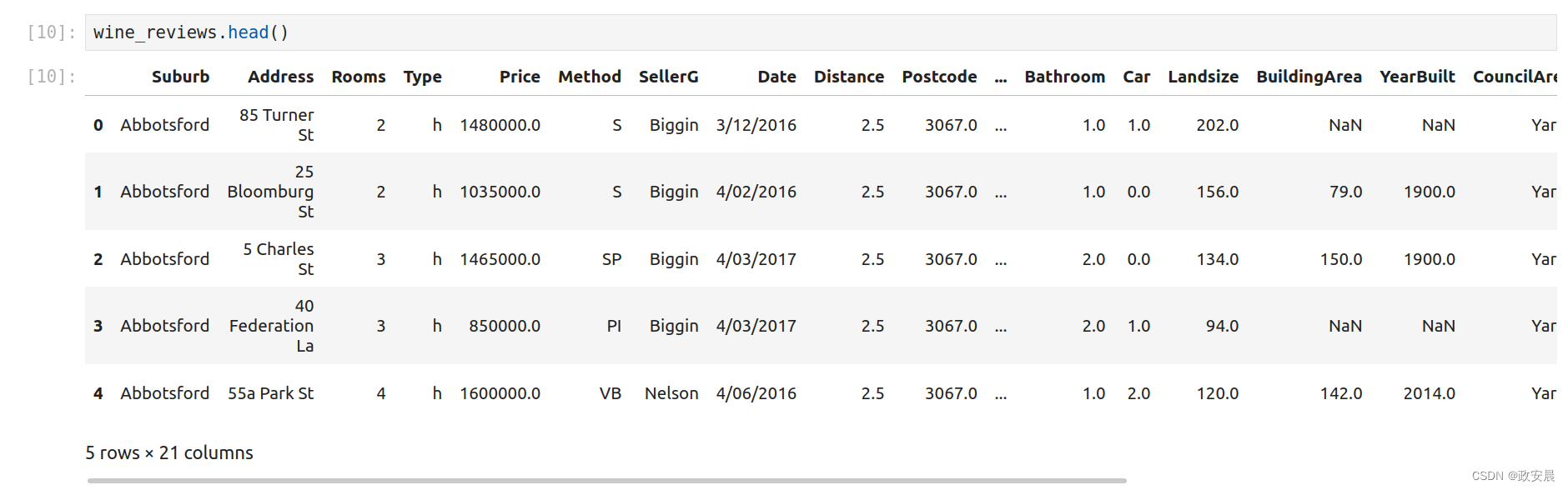
pd.read_csv()函数功能强大,有30多个可选参数可以指定。例如,您可以在此数据集中看到CSV文件具有内置索引,但pandas没有自动识别出来。为了让pandas使用该列作为索引(而不是从头开始创建一个新的索引),我们可以指定index_col参数。
# 我指定了从第5列开始
wine_reviews = pd.read_csv("./melb_data.csv", index_col=5)
wine_reviews.head()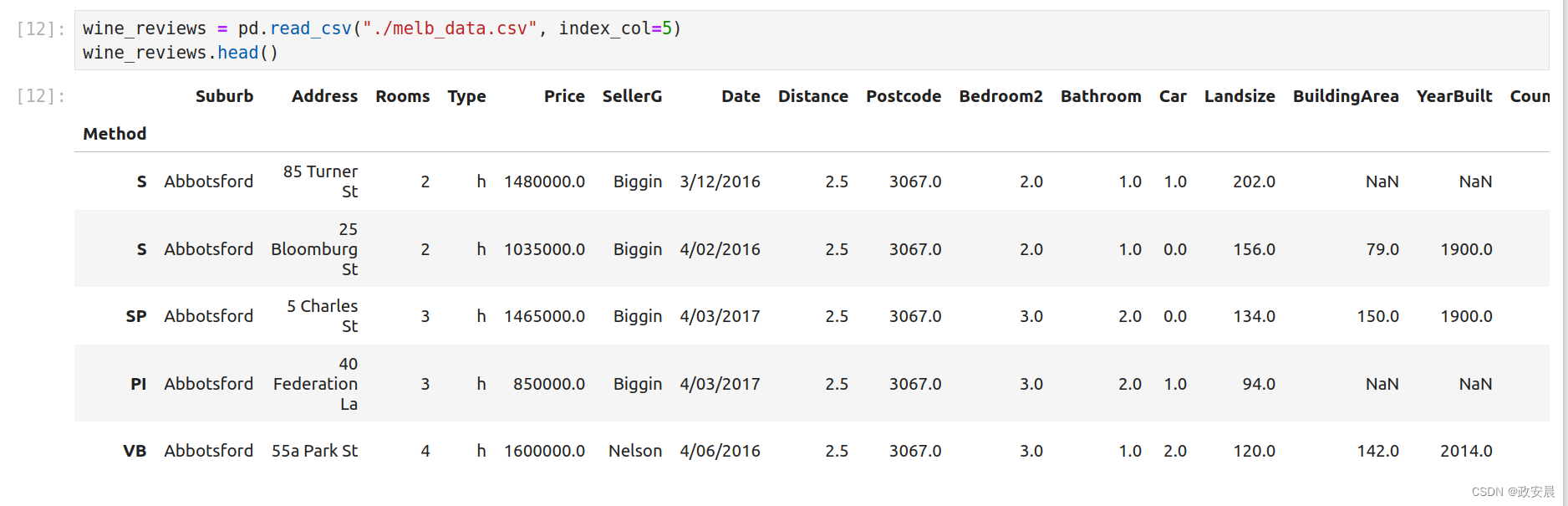
大家可以看到,输出就忽略了0-4列。
告一段落

其实在这篇文章中,大家去好好了解一下张量的概念,这是一个非常有意思的表述,数字世界中的任何数据都可以表达成张量。



![寒假提升(5)[利用位操作符的算法题]](https://img-blog.csdnimg.cn/direct/bdd25b1781b54466be792e463093571b.png)