文章目录
- 实验目的
- 实现
- 定义单词对应的种别码
- 定义输出形式:三元式
- python代码实现
- 运行结果
- 检错处理
- 总结
实验目的
输入一个C语言代码串,输出单词流,识别对象包含关键字、标识符、整型浮点型字符串型常数、科学计数法、操作符和标点、注释等等。
实现
定义单词对应的种别码
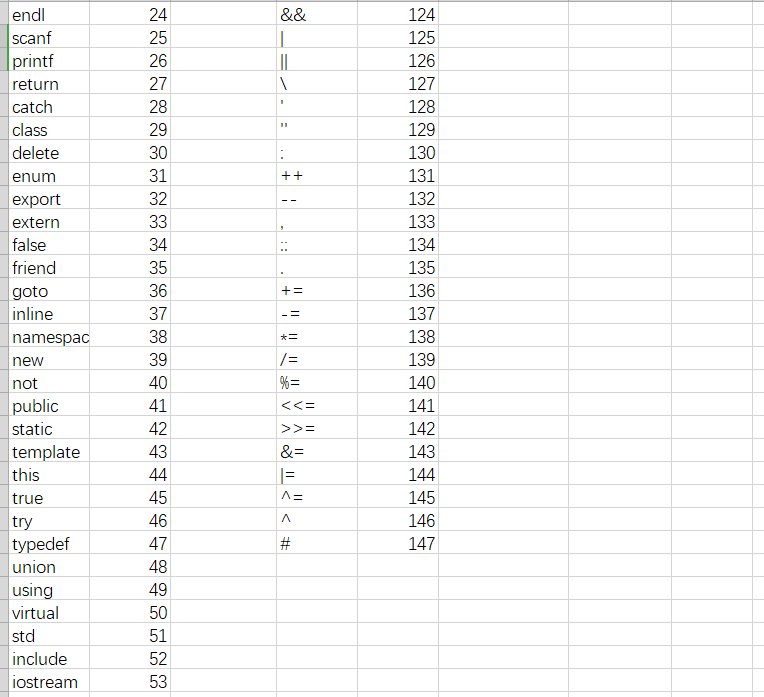
自行定义相关单词的种别码

定义输出形式:三元式
# 三元式
class ThreeFml: # 三元式
def __init__(self, syn, inPoint, value):
self.syn = syn # 种别码
self.inPoint = inPoint # 内码值
self.value = value # 自身值
def __eq__(self, other): # 重载 判别对象相等的依据
return self.syn == other.syn and self.value == other.value
def __lt__(self, other): # 重载 比较对象大小关系的依据
if self.syn == other.syn:
return self.inPoint < other.inPoint
else:
return self.syn < other.syn
每个三元组用一个自定义类表示:
类属性:种别码syn、内码值inPoint、自身值value
类方法:
- 方法1:判断两个三元组相等的方法:种别码syn和自身值value相等
- 方法2:确定展示时的先后顺序的方法:先比较种别码syn,再比较内码值inPoint
例如:
- 输入:double a; int a;
- 输出:
- 分析:有两个标识符a,根据类方法1,判断前后两个a为同一个三元组,因此不重复输a。参见种别码表,double为6,int为2,则根据类方法2,进行三元组的展示排序。

python代码实现
import re
# 三元式
class ThreeFml: # 三元式
def __init__(self, syn, inPoint, value):
self.syn = syn # 种别码
self.inPoint = inPoint # 内码值
self.value = value # 自身值
def __eq__(self, other): # 重载 判别对象相等的依据
return self.syn == other.syn and self.value == other.value
def __lt__(self, other): # 重载 比较对象大小关系的依据
if self.syn == other.syn:
return self.inPoint < other.inPoint
else:
return self.syn < other.syn
# 词法识别
class WordAnalysis:
def __init__(self, input_code_str):
self.input_code_str = input_code_str # 源程序字符串
self.code_char_list = [] # 源程序字符列表
self.code_len = 0 # 源程序字符列表长度
self.cp = 0 # 源程序字符列表指针,方便遍历字符串中的字符
self.cur = '' # 当前源程序字符列表的某个字符
self.val = [] # 单词自身的值
self.syn = 0 # 单词种别码
self.errInfo = "" # 错误信息
self.keyWords = ["main", "int", "short", "long", "float",
"double", "char", "string", "const", "void",
"struct", "if", "else", "switch", "case",
"default", "do", "while", "for", "continue",
"break", "cout", "cin", "endl", "scanf",
"printf", "return", 'catch', 'class', 'delete',
'enum', 'export', 'extern', 'false', 'friend',
'goto', 'inline', 'namespace', 'new', 'not',
'public', 'static', 'template', 'this', 'true',
'try', 'typedef', 'union', 'using', 'virtual',
'std', 'include', 'iostream'] # 关键字
self.TFs = [] # 存储三元式
def nextChar(self): # 封装cp++,简化函数scanWord中的代码
self.cp += 1
self.cur = self.code_char_list[self.cp]
def error(self, info): # errInfo错误信息
line = 1
for i in range(0, self.cp + 1):
if self.code_char_list[i] == '\n':
line += 1
self.errInfo = "第" + str(line) + "行报错:" + info
def bracket_match(self):
pattern = r'(\/\/.*?$|\/\*(.|\n)*?\*\/)' # 匹配单行或多行注释
comments = re.findall(pattern, self.input_code_str, flags=re.MULTILINE | re.DOTALL)
comments = [comment[0].strip() for comment in comments] # 处理结果,去除多余的空格
i = 0
code_sub_com = [] # 去除注释
print(f"comment: {comments}")
while i < len(self.input_code_str):
ch = self.input_code_str[i]
if ch == "/" and comments != []:
i += len(comments[0])
comments.pop(0)
continue
code_sub_com.append((i, ch))
i += 1
pattern2 = r'"([^"]*)"' # 匹配双引号包裹的字符串
strings = re.findall(pattern2, self.input_code_str)
code_sub_com_str = [] # 去除字符串变量
i = 0
while i < len(code_sub_com):
item = code_sub_com[i]
ch = item[1]
if ch == "\"" and comments != []:
i += len(strings[0]) + 2
strings.pop(0)
continue
code_sub_com_str.append(item)
i += 1
s = []
stack = []
mapping = {")": "(", "}": "{", "]": "["}
for idx, char in code_sub_com_str:
if char in mapping.keys() or char in mapping.values():
s.append((idx, char))
if not s:
return "ok"
for item in s:
idx = item[0]
char = item[1]
if char in mapping.values(): # 左括号
stack.append(item)
elif char in mapping.keys(): # 右括号
if not stack: # 栈为空,当前右括号匹配不到
return idx
topitem = stack[-1]
topidx = topitem[0]
topch = topitem[1]
if mapping[char] != topch: # 当前右括号匹配失败
return topidx
else:
stack.pop()
if not stack: # 栈为空,匹配完毕
return "ok"
else: # 栈不为空,只剩下左括号
item = stack[0]
idx = item[0]
return idx
def scanWord(self): # 词法分析
# 初始化value
self.val = []
self.syn = 0
# ******获取当前有效字符(去除空白,直至扫描到第一个有效字符)******
self.cur = self.code_char_list[self.cp]
# print(f"==={self.cp} {self.code_len-1}===")
while self.cur == ' ' or self.cur == '\n' or self.cur == '\t':
self.cp += 1
if self.cp >= self.code_len - 1:
print(f"越界{self.cp}")
return # 越界直接返回
self.cur = self.code_char_list[self.cp]
# ********************首字符为数字*****************
if self.cur.isdigit():
# ====首先默认为整数 ====
i_value = 0
while self.cur.isdigit(): # string数转int
i_value = i_value * 10 + int(self.cur)
self.nextChar()
six_flag = False
if (self.cur == 'x' or self.cur == 'X') \
and self.code_char_list[self.cp - 1] == '0': # 十六进制整数 0x?????
self.nextChar()
six_flag = True
s = ""
while self.cur.isdigit() or self.cur.isalpha():
if self.cur.isalpha():
if not (('a' <= self.cur <= 'f') or ('A' <= self.cur <= 'F')):
self.syn = -999
self.error("十六进制中的字母不为:a~f 或 A~F")
return
s += self.cur
self.nextChar()
i_value = int(s, 16) # 将16进制数转为整数
self.syn = 201
self.val = str(i_value) # int转str
if six_flag:
return
# ====有小数点或e,则为浮点数====
d_value = i_value * 1.0
if self.cur == '.':
fraction = 0.1
self.nextChar()
while self.cur.isdigit(): # 计算小数位上的数 形如 123.45
d_value += fraction * int(self.cur)
fraction = fraction * 0.1
self.nextChar()
if self.cur == 'E' or self.cur == 'e': # 形如 123.4E?? 或 123.E??
self.nextChar()
powNum = 0
if self.cur == '+': # 形如 123.4E+5
self.nextChar()
while self.cur.isdigit():
powNum = powNum * 10 + int(self.cur)
self.nextChar()
d_value *= 10 ** powNum
elif self.cur == '-': # 形如 123.4E-5
self.nextChar()
while self.cur.isdigit():
powNum = powNum * 10 + int(self.cur)
self.nextChar()
d_value /= 10 ** powNum
elif self.cur.isdigit(): # 形如 123.4E5
while self.cur.isdigit():
powNum = powNum * 10 + int(self.cur)
self.nextChar()
d_value *= 10 ** powNum
if self.cur.isalpha():
self.syn = -999
self.error(f"科学计数法后含有多余字母{self.cur}")
return
self.syn = 202
self.val = str(d_value) # double转str
elif self.cur == 'E' or self.cur == 'e': # 形如 123E??
self.nextChar()
powNum = 0
if self.cur == '+': # 形如 123E+4
self.nextChar()
while self.cur.isdigit():
powNum = powNum * 10 + int(self.cur)
self.nextChar()
d_value *= 10 ** powNum
elif self.cur == '-': # 形如 123E-4
self.nextChar()
while self.cur.isdigit():
powNum = powNum * 10 + int(self.cur)
self.nextChar()
d_value /= 10 ** powNum
elif self.cur.isdigit(): # 形如 123E4
while self.cur.isdigit():
powNum = powNum * 10 + int(self.cur)
self.nextChar()
d_value *= 10 ** powNum
if self.cur.isalpha():
self.syn = -999
self.error(f"科学计数法后含有多余字母{self.cur}")
return
self.syn = 202
self.val = str(d_value)
# ********************首字符为字母*****************
elif self.cur.isalpha():
# ====标识符====
while self.cur.isdigit() or self.cur.isalpha() or self.cur == '_':
self.val.append(self.cur)
self.nextChar()
self.syn = 222
# ====判断是否为关键字====
for i, keyword in enumerate(self.keyWords):
if ''.join(self.val) == keyword:
self.syn = i + 1
break
# ********************首字符为标点*****************
else:
if self.cur == '+':
self.syn = 101
self.val.append(self.cur)
self.nextChar()
if self.cur == '+':
self.syn = 131
self.val.append(self.cur)
self.nextChar()
elif self.cur == '=':
self.syn = 136
self.val.append(self.cur)
self.nextChar()
elif self.cur == '-':
self.syn = 102
self.val.append(self.cur)
self.nextChar()
if self.cur == '-':
self.syn = 132
self.val.append(self.cur)
self.nextChar()
elif self.cur == '=':
self.syn = 137
self.val.append(self.cur)
self.nextChar()
elif self.cur == '*':
self.syn = 103
self.val.append(self.cur)
self.nextChar()
if self.cur == '=':
self.syn = 138
self.val.append(self.cur)
self.nextChar()
elif self.cur == '/':
self.syn = 104
self.val.append(self.cur)
self.nextChar()
if self.cur == '=':
self.syn = 139
self.val.append(self.cur)
self.nextChar()
# 单行注释
elif self.cur == '/':
self.nextChar()
while self.cur != '\n':
self.nextChar()
self.syn = 0
# 多行注释
elif self.cur == '*':
self.cp += 1
haveEnd = False
flag = 0
for i in range(self.cp + 1, self.code_len):
# print(self.code_char_list[i])
if self.code_char_list[i - 1] == '*' and self.code_char_list[i] == '/':
haveEnd = True
flag = i
break
if haveEnd:
self.syn = 0
self.cp = flag + 1
else:
self.syn = -999
self.error(" 多行注释没有结尾*/ ")
elif self.cur == '%':
self.syn = 105
self.val.append(self.cur)
self.nextChar()
if self.cur == '=':
self.syn = 140
self.val.append(self.cur)
self.nextChar()
elif self.cur == '=':
self.syn = 106
self.val.append(self.cur)
self.nextChar()
if self.cur == '=':
self.syn = 118
self.val.append(self.cur)
self.nextChar()
elif self.cur == '(':
self.syn = 107
self.val.append(self.cur)
self.nextChar()
elif self.cur == ')':
self.syn = 108
self.val.append(self.cur)
self.nextChar()
elif self.cur == '[':
self.syn = 109
self.val.append(self.cur)
self.nextChar()
elif self.cur == ']':
self.syn = 110
self.val.append(self.cur)
self.nextChar()
elif self.cur == '{':
self.syn = 111
self.val.append(self.cur)
self.nextChar()
elif self.cur == '}':
self.syn = 112
self.val.append(self.cur)
self.nextChar()
elif self.cur == ';':
self.syn = 113
self.val.append(self.cur)
self.nextChar()
elif self.cur == '>':
self.syn = 114
self.val.append(self.cur)
self.nextChar()
if self.cur == '=':
self.syn = 116
self.val.append(self.cur)
self.nextChar()
elif self.cur == '>':
self.syn = 119
self.val.append(self.cur)
self.nextChar()
if self.cur == '=':
self.syn = 141
self.val.append(self.cur)
self.nextChar()
elif self.cur == '<':
self.syn = 115
self.val.append(self.cur)
self.nextChar()
if self.cur == '=':
self.syn = 117
self.val.append(self.cur)
self.nextChar()
elif self.cur == '<':
self.syn = 120
self.val.append(self.cur)
self.nextChar()
if self.cur == '=':
self.syn = 142
self.val.append(self.cur)
self.nextChar()
elif self.cur == '!':
self.syn = 121
self.val.append(self.cur)
self.nextChar()
if self.cur == '=':
self.syn = 122
self.val.append(self.cur)
self.nextChar()
elif self.cur == '&':
self.syn = 123
self.val.append(self.cur)
self.nextChar()
if self.cur == '&':
self.syn = 124
self.val.append(self.cur)
self.nextChar()
elif self.cur == '=':
self.syn = 143
self.val.append(self.cur)
self.nextChar()
elif self.cur == '|':
self.syn = 125
self.val.append(self.cur)
self.nextChar()
if self.cur == '|':
self.syn = 126
self.val.append(self.cur)
self.nextChar()
elif self.cur == '=':
self.syn = 144
self.val.append(self.cur)
self.nextChar()
elif self.cur == '\\': # \
self.syn = 127
self.val.append(self.cur)
self.nextChar()
elif self.cur == '\'': # ‘
self.syn = 128
self.val.append(self.cur)
self.nextChar()
elif self.cur == '\"': # ”
self.nextChar()
haveEnd = False
flag = 0
for i in range(self.cp, self.code_len):
if self.code_char_list[i] == '"':
haveEnd = True
flag = i
break
if haveEnd:
for j in range(self.cp, flag):
self.val.append(self.code_char_list[j])
self.cp = flag + 1
self.cur = self.code_char_list[self.cp]
self.syn = 203
else:
self.syn = -999
self.error(" string常量没有闭合的\" ")
elif self.cur == ':':
self.syn = 130
self.val.append(self.cur)
self.nextChar()
if self.cur == ':':
self.syn = 134
self.val.append(self.cur)
self.nextChar()
elif self.cur == ',':
self.syn = 133
self.val.append(self.cur)
self.nextChar()
elif self.cur == '^': # 按位异或
self.syn = 146
self.val.append(self.cur)
self.nextChar()
if self.cur == '=':
self.syn = 145
self.val.append(self.cur)
self.nextChar()
elif self.cur == '#':
self.syn = 147
self.val.append(self.cur)
self.nextChar()
else:
self.syn = -999
self.error(f" 无效字符: {self.cur}")
def solve(self):
print("\n================scan-main begin================")
self.code_char_list = list(self.input_code_str.strip()) # 去除头尾的空格
self.code_char_list.append('\n') # 末尾补充一个\n, 可在一些while判断中 防止越界
self.code_len = len(self.code_char_list)
if self.bracket_match() != "ok": # 检测括号匹配
self.cp = self.bracket_match()
self.error(f"{self.code_char_list[self.cp]}匹配缺失!")
intCnt, doubleCnt, stringCnt, idCnt = 0, 0, 0, 0 # 内码值
while True: # 至少执行一次,如同do while
self.scanWord() # 进入词法分析
value = ''.join(self.val) # char列表 ===> String
new_tf = ThreeFml(self.syn, -1, value) # 创建三元式对象
if self.syn == 201: # 整型常数
# print(f"整型常数: {value}")
if not any(tf == new_tf for tf in self.TFs): # append前先判断是否有重复
intCnt += 1
new_tf.inPoint = intCnt
self.TFs.append(new_tf)
elif self.syn == 202: # 浮点型常数
# print(f"浮点型常数: {value}")
if not any(tf == new_tf for tf in self.TFs):
doubleCnt += 1
new_tf.inPoint = doubleCnt
self.TFs.append(new_tf)
elif self.syn == 203: # 字符串常数
# print(f"字符串常数: {value}")
if not any(tf == new_tf for tf in self.TFs):
stringCnt += 1
new_tf.inPoint = stringCnt
self.TFs.append(new_tf)
elif self.syn == 222: # 标识符
# print(f"标识符: {value}")
if not any(tf == new_tf for tf in self.TFs):
idCnt += 1
new_tf.inPoint = idCnt
self.TFs.append(new_tf)
elif 1 <= self.syn <= 100: # 关键字
# print(f"关键字: {value}")
if not any(tf == new_tf for tf in self.TFs):
new_tf.inPoint = 1
self.TFs.append(new_tf)
elif self.syn == 0: # 注释内容、或者最后的\n
# print("注释 or 结束")
pass
elif self.syn == -999: # 报错
# print(f"error: {self.errInfo}")
break
else: # 符号:标点符、算符
# print(f"符号: {value}")
if not any(tf == new_tf for tf in self.TFs):
new_tf.inPoint = 1
self.TFs.append(new_tf)
if self.cp >= (self.code_len - 1): # 最后一个元素 为自主添加的\n,代表结束
# print(f"{cp} 跳出")
break
if self.errInfo: # 检查是否有报错
print(self.errInfo)
return
self.TFs.sort() # 给三元式列表TFs排序(按种别码、内码)
for tf in self.TFs: # 打印
print(f"({tf.syn}, {tf.inPoint}, {tf.value})")
print("================scan-main end================")
if __name__ == '__main__':
filepath = "./code.txt"
with open(filepath, "r") as file:
code = file.read()
word_analysis = WordAnalysis(code)
word_analysis.solve()
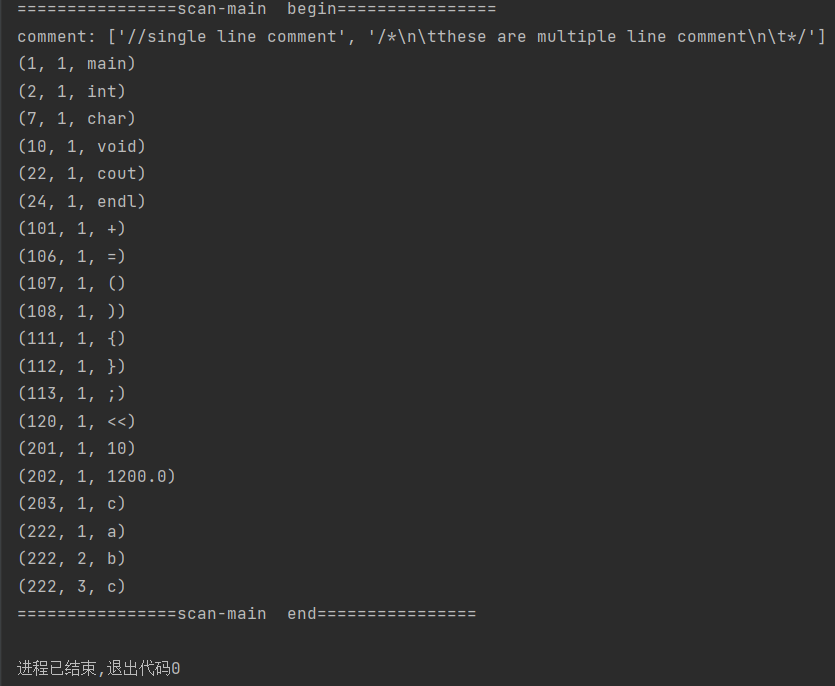
运行结果
输入:通过读取txt文件输入要分析的源程序串

输出:
第一行表示注释内容
后面为三元式(种别码,内码值,自身值)
从结果可以看到:
- 输入代码串中有两个int关键字,并没有重复输出,只保留1个
- 输入代码串中识别到多个标识符(我设定的种别码为222),由于它们的值不同,所以在种别码相同的情况下,给出不同的内码值。
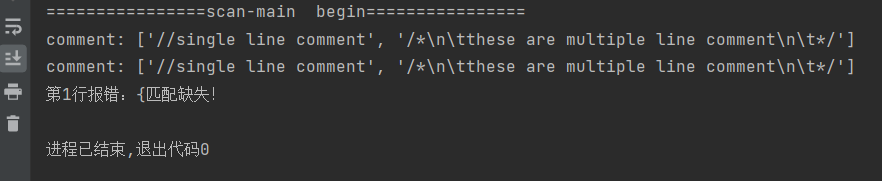
检错处理
括号匹配

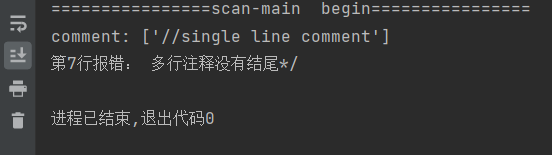
字符串常量未闭合


多行注释未闭合

十六进制数不规范


科学计数法不规范


总结
体会
在本次的实验中,通过对词法分析器的编写,在理论的基础上加深了对词法分析的理解和实践,所编写的词法分析器在多次的测试中均得到了正确的结果。
此外,我是先用c++编写的代码,确认大部分功能无误后,再改用python编写。在改语言的过程中,明显感受到python 的便利之处,就比如一个简单的判断字符是否为字母,在c++里需要自定义一个函数来判断(if ch>=’a’ and if ch<=’z’),而python则直接使用系统自带的isalpha函数即可,大大简化了代码量。
问题
编写的程序中,虽然已完成绝大部分单词分析功能,但对一些小细节就没有进行直接的编写。例如在识别用科学表示法表示的浮点型常量时,并没有考虑是否会溢出C++语言中的double类型,当然,这也可以认为是语义分析的任务,而非词法分析的任务,但这可以是程序改善的一处地方。
附思路流程图
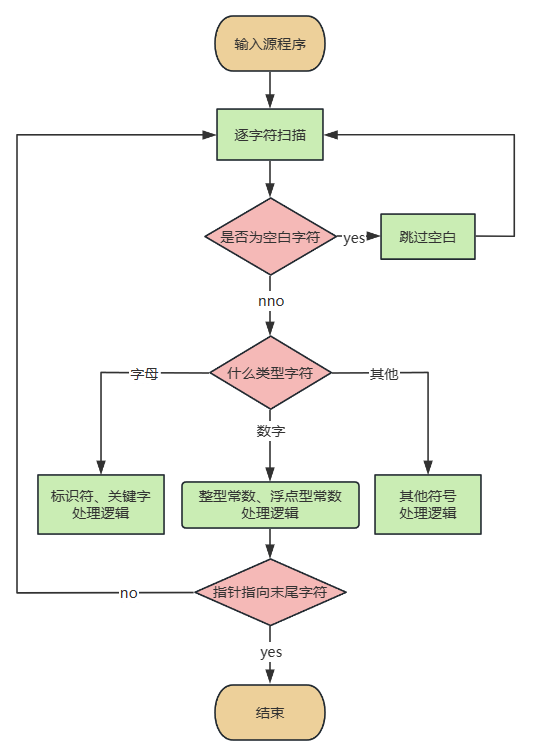
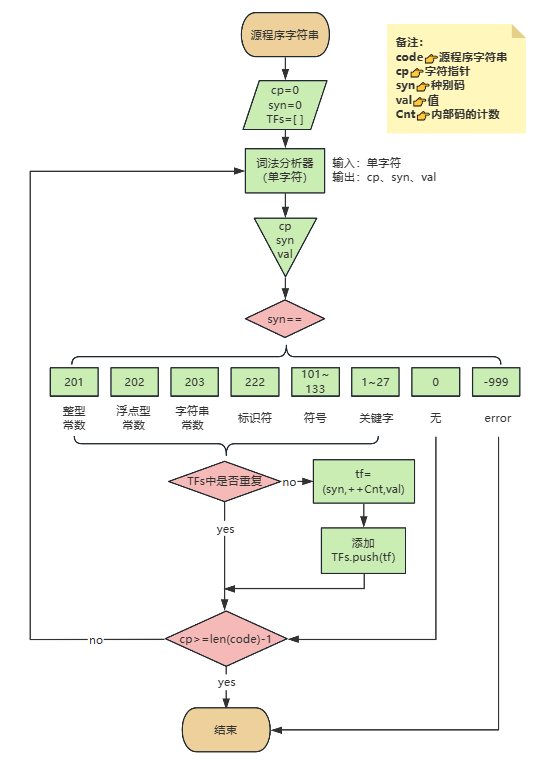
总体逻辑:
主函数逻辑

![[项目管理] 如何使用git客户端管理gitee的私有仓库](https://img-blog.csdnimg.cn/direct/9969af1ae6d240b688516649a688b024.png)
![K8S系列文章之 [使用 Alpine 搭建 k3s]](https://img-blog.csdnimg.cn/img_convert/3f682727b33bd7efffe905250ee3a569.png)