EVA-CLIP-18B: Scaling CLIP to 18 Billion Parameters
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
1. 简介
2. 弱到强视觉扩展
3. 实验
0. 摘要
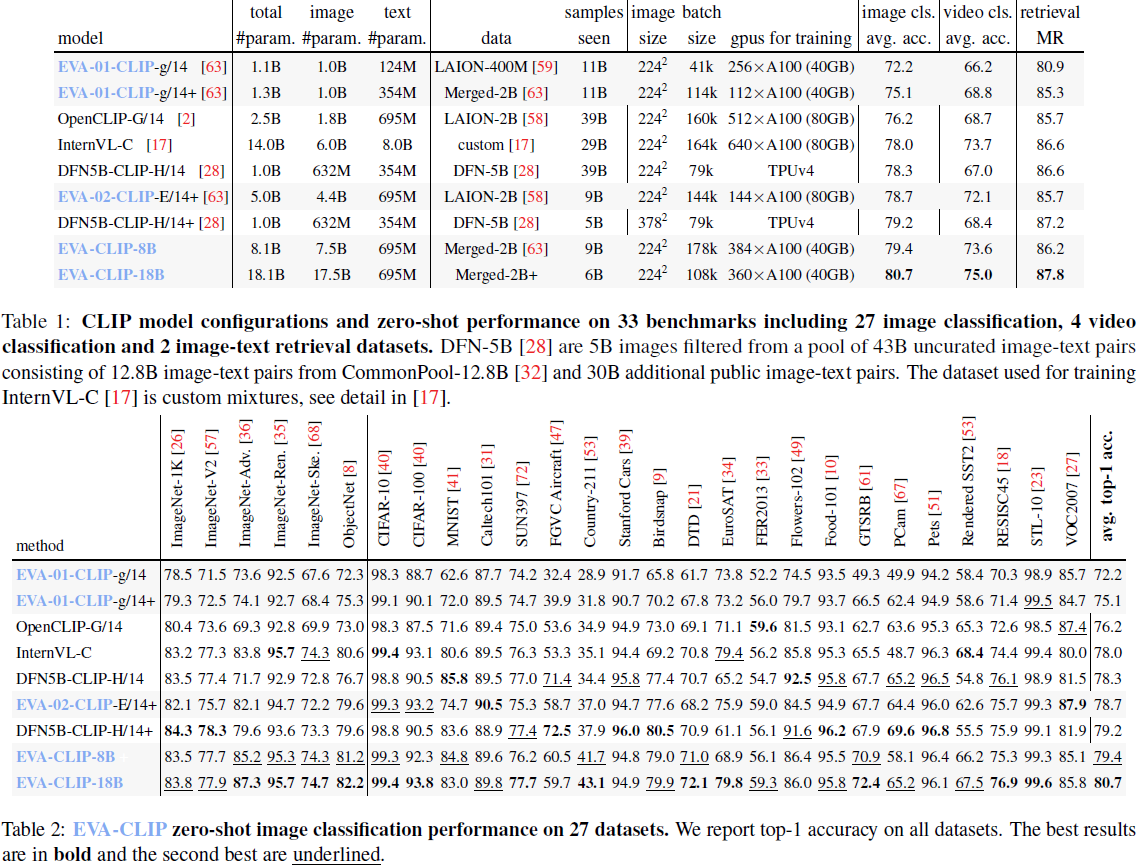
扩展对比语言-图像预训练(contrastive language-image pretraining,CLIP)对于强化视觉和多模态模型至关重要。我们介绍 EVA-CLIP-18B,迄今为止最大且最强大的开源 CLIP 模型,具有18B 参数。仅在看到 6B 训练样本的情况下,EVA-CLIP-18B 在 27 个广泛认可的图像分类基准测试中取得了卓越的 80.7% 零样本 top-1 准确性,优于其前身 EVA-CLIP(5B 参数)和其他开源CLIP 模型很大一部分。值得注意的是,尽管保持固定的来自 LAION-2B 和 COYO-700M 的 20B 图像文本对训练数据集,但我们观察到 EVA-CLIP 模型尺寸扩大时始终保持一致的性能改善。此数据集是公开可用的,比其他最先进的 CLIP 模型中使用的内部数据集(例如 DFN-5B,WebLI-10B)要小得多。EVA-CLIP-18B 展示了 EVA-style 弱到强(weak-to-strong)视觉模型扩展的潜力。通过公开提供我们的模型权重,我们希望促进未来在视觉和多模态基础模型领域的研究。
代码:baaivision/EVA/EVA-CLIP-18B
1. 简介
近年来,大型多模态模型(Large Multimodal Models,LMM)[3, 64, 62, 69, 5, 46] 迅速增长,CLIP 模型 [53, 19, 63, 43, 75, 28, 17] 作为基础视觉编码器,提供强大而可迁移的视觉表示,而大型语言模型(Large Language Models,LLM)[65, 54] 则作为在不同模态之间进行推理的通用接口。然而,随着 LLMs 的规模扩大到约 100B 参数或更高 [11, 20, 65],采用的视觉基础模型仍然在一个较小的尺度上运行,远远落后于 LLM。
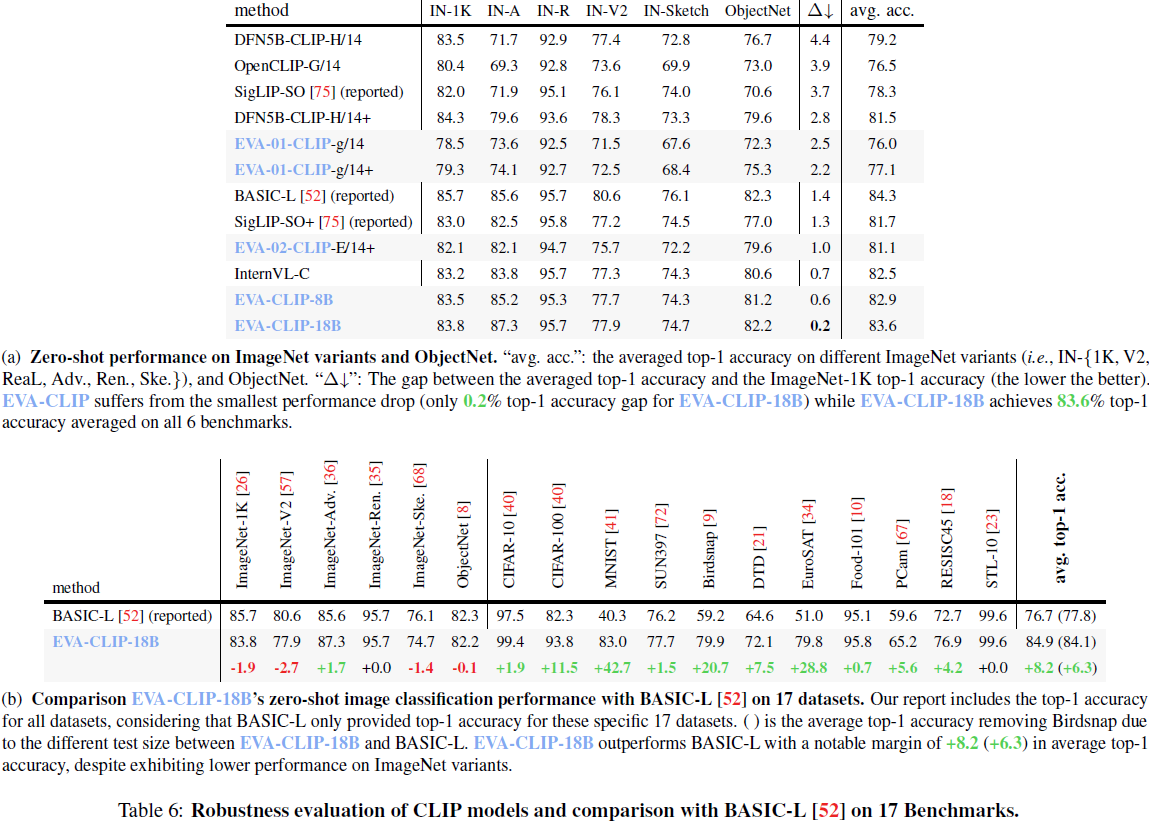
本文介绍了 EVA-CLIP-18B,这是具有 18B 参数的最大的开源 CLIP 模型,以缩小这一差距。EVA-CLIP [63] 开源了一系列有效且高效的 CLIP 模型,这些模型已被许多在 2D/3D 视觉和多模态建模领域有影响力的工作所采用 [42, 78, 77, 50, 69, 64]。基于 EVA [30, 29] 和 EVA-CLIP [63] 的扩展理念,我们进一步扩大了 EVA-CLIP 的规模。仅看到 6B 训练样本,并在公开可用的数据集上进行训练,EVA-CLIP-18B 在 27 个广泛认可的图像分类基准测试上取得了卓越的 80.7% 平均零样本 top-1 准确性,明显优于其前身 EVA-02-CLIP-E/14+ (5B 参数) 和其他开源 CLIP 模型。此外,这些模型没有显示出性能饱和的迹象,为进一步扩展视觉模型提供了启示。图 1 展示了一个直观的演示。
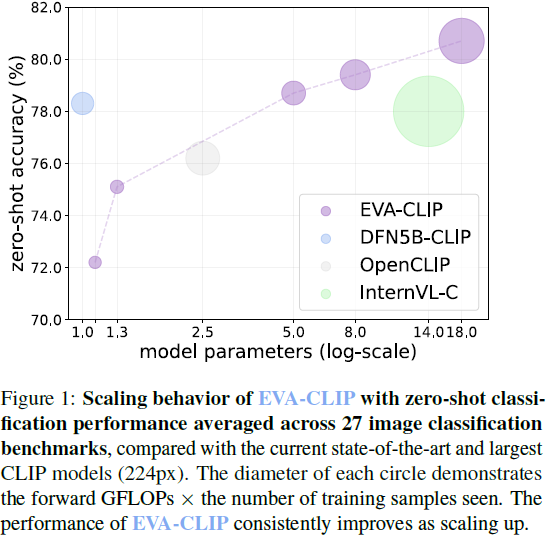
EVA-CLIP-18B 的成功训练体现了 EVA-style 视觉模型扩展理念的潜力。我们持续开源我们模型的训练代码和权重,以鼓励进一步研究并推动视觉和多模态基础模型的发展。
2. 弱到强视觉扩展
我们的扩展过程遵循 EVA [30] 和 EVA-CLIP [63] 的原则。EVA 对于扩展视觉模型的理念采用了弱到强(weak-to-strong)的范式,旨在通过策略性进展来改进视觉模型。这个过程始于从一个小 EVA-CLIP 模型中蒸馏知识的大 EVA 视觉模型,小模型还作为视觉编码器初始化,以稳定和加速大 EVA-CLIP 的训练。之后,这个封闭循环继续扩展,生成一个更大的 EVA。在整个模型扩展循环中,训练数据集基本保持不变,以展示我们模型规模特定的扩展理念的有效性,尽管扩大数据集可以进一步释放我们方法的扩展能力。
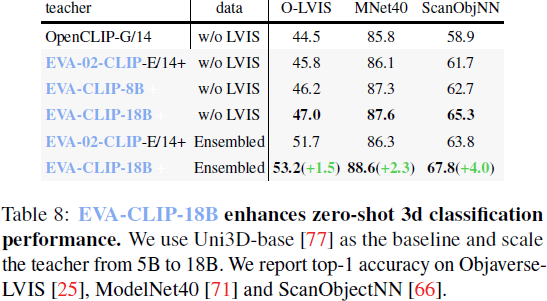
具体而言,在这项工作中,我们使用一个小的 EVA-CLIP(EVA-02-CLIP-E/14+)[63] 作为教师,对一个大型 EVA 模型进行预训练,命名为 EVA-18B。该教师模型被训练以从 EVA-02-CLIP-E/14+ 中重构被掩蔽的图像文本对齐的视觉特征。遵循 LLaMA [65],EVA-18B 省略了 QKV 投影的偏置项,使用 RMSNorm [76] 代替 LayerNorm [4]。随后,我们将 EVA 模型用作 EVA-CLIP 的视觉编码器初始化,进行图像文本对比学习目标的预训练。此外,我们还引入了一个较小的对应模型,EVA-CLIP-8B,它经历了类似的预训练方法。值得注意的是,我们的实验证明了通过逐渐弱教强扩展 EVA-CLIP,性能保持不断提升。
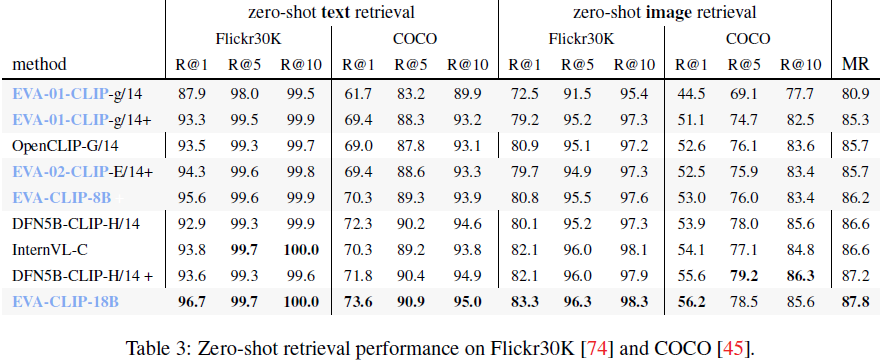
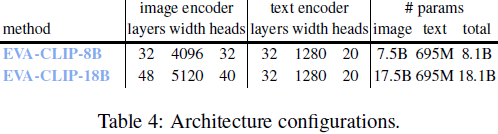
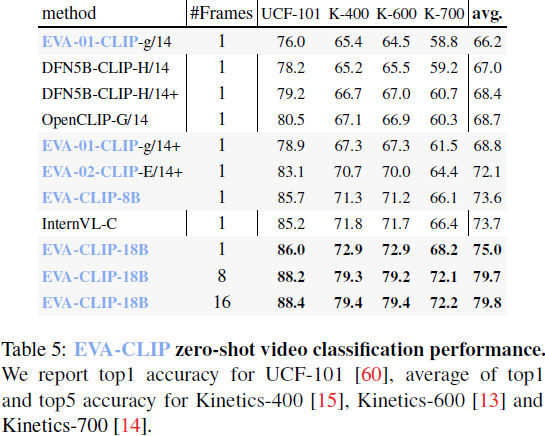
3. 实验






![洛谷:P1219 [USACO1.5] 八皇后 Checker Challenge(dfs深度优先遍历求解)](https://img-blog.csdnimg.cn/direct/da9470638b044323a6b8269975c72d5f.jpeg)