这篇咱们示例演绎Python的一个重要能力:导入、运算符重载和进入外部库世界的生存技巧。
在咱们这一篇中,你将学习Python中的导入,获取使用不熟悉的库(以及它们返回的对象)的一些技巧,并深入了解运算符重载。

导入
到目前为止,我们已经讨论了语言内置的类型和函数。
但是Python最好的地方之一(特别是对于数据科学家而言)是它所拥有的大量高质量的自定义库。
其中一些库是“标准库”,意味着你可以在任何运行Python的地方找到它们。其他库可以很容易地添加,即使它们并没有随Python一起发布。无论如何,我们将通过导入来访问这些代码。
我们将从标准库导入math模块来开始我们的示例。
import math
print("It's math! It has type {}".format(type(math)))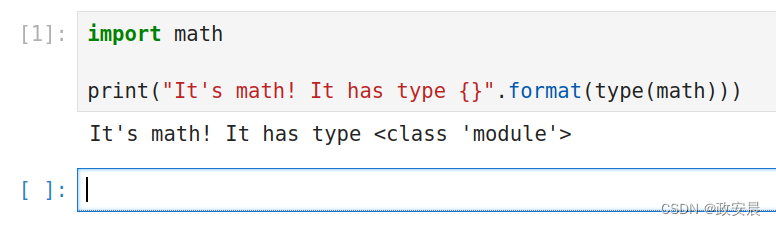
数学(math)是一个模块。
模块只是由别人定义的一组变量(如果你愿意,可以看作是一个命名空间)。我们可以使用内置函数dir()查看math中的所有名称。
print(dir(math))
我们可以使用点语法来访问这些变量。其中一些变量指的是简单的值,比如math.pi:
print("pi to 4 significant digits = {:.4}".format(math.pi))
但是,我们在模块中找到的大部分内容都是函数,比如math.log:
math.log(32, 2)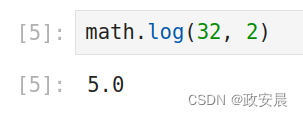
当然,如果我们不知道math.log函数的作用,我们可以对其调用help()命令:
help(math.log)
我们也可以在模块本身上调用help()函数。这将为我们提供模块中所有函数和值的组合文档(以及模块的高级描述)。
help(math)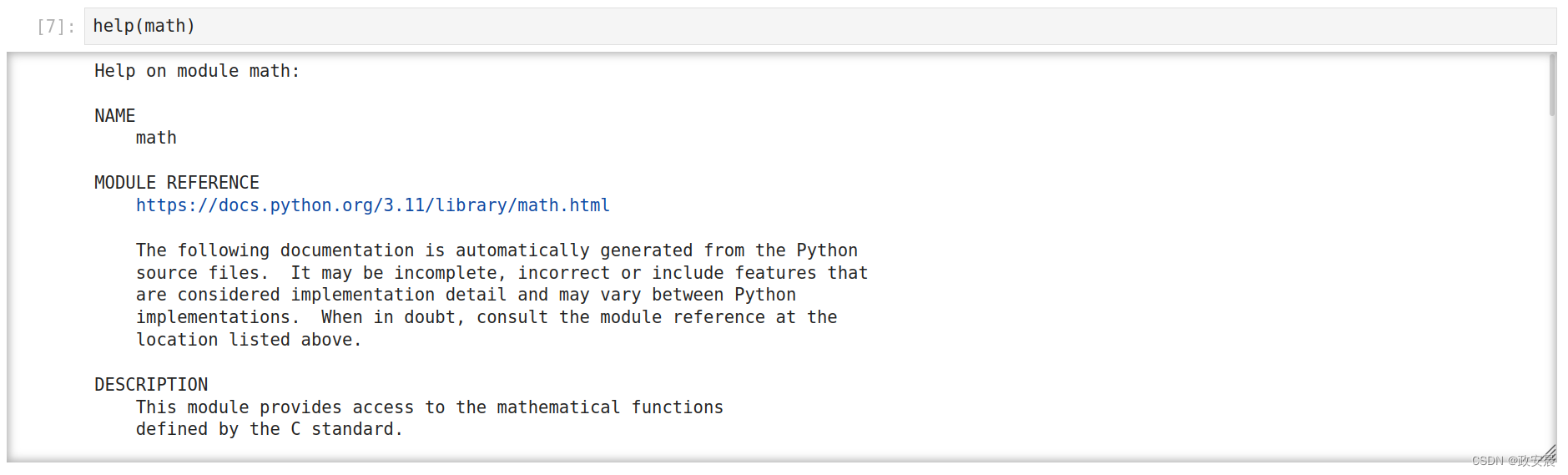
这里提供的帮助信息就特别多了,咱们这里不能详细列出,大家可以自行在Python环境中尝试。
其它导入的语法
如果我们预先知道将频繁使用数学函数的话,我们可以使用一个更短的别名来导入它,以节省一些打字(尽管在这种情况下,“math”已经相当短了),如下:
import math as mt
mt.pi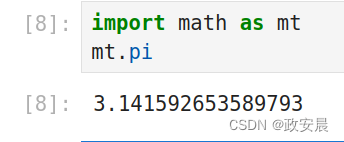
您可能已经看到过使用诸如Pandas、Numpy、Tensorflow或Matplotlib等流行库的代码来实现这一功能。例如,通常惯例是将numpy导入为np,将pandas导入为pd。
import math
mt = math如果我们可以单独使用数学模块中的所有变量,那岂不是太棒了?也就是说,我们可以直接使用pi而不是math.pi或者mt.pi。好消息是:我们可以做到这一点。
from math import *
print(pi, log(32, 2))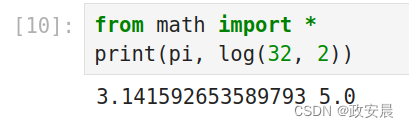
其实,使用import *可以直接访问模块的所有变量(无需任何前缀)。只是这样做,会失去很多优雅,并且让你的代码逐渐失序,这个真的有点道理。
from math import *
from numpy import *
print(pi, log(32, 2))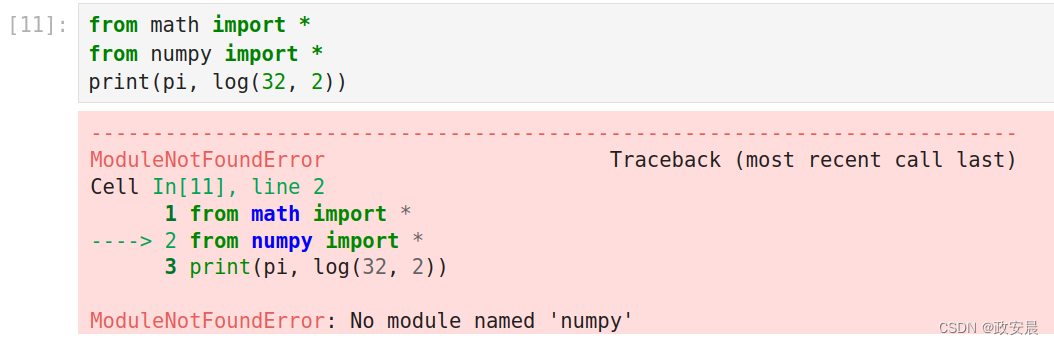
发生了什么事?之前不还是好好的吗!其实,这种“星号导入”有时会导致奇怪且难以调试的情况。
在这种情况下的问题是,math和numpy模块都有名为log的函数,但它们具有不同的语义。因为我们先从numpy导入,它的log覆盖(或“隐藏”)了我们从math导入的log变量。
一个好的折中办法是只从每个模块导入我们需要的特定内容:
from math import log, pi
from numpy import asarray子模块
我们已经看到,模块包含可以引用函数或值的变量。需要注意的是,它们还可以有引用其他模块的变量。
import numpy
print("numpy.random is a", type(numpy.random))
print("it contains names such as...",
dir(numpy.random)[-15:]
)当咱们导入numpy模块的时候,发现出现错误如下:
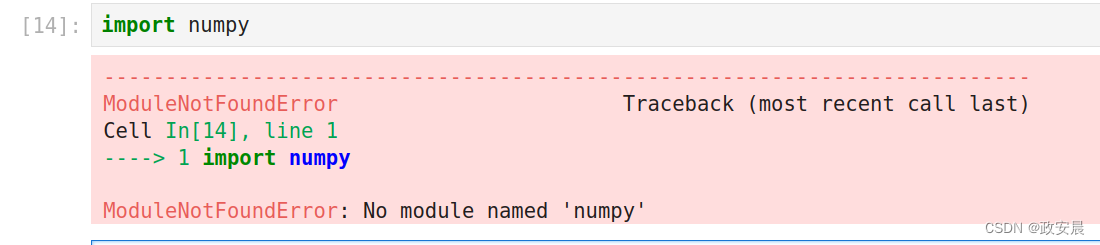
这是因为咱们在当前运行的虚拟环境中没有安装numpy,我们现在安装一下:
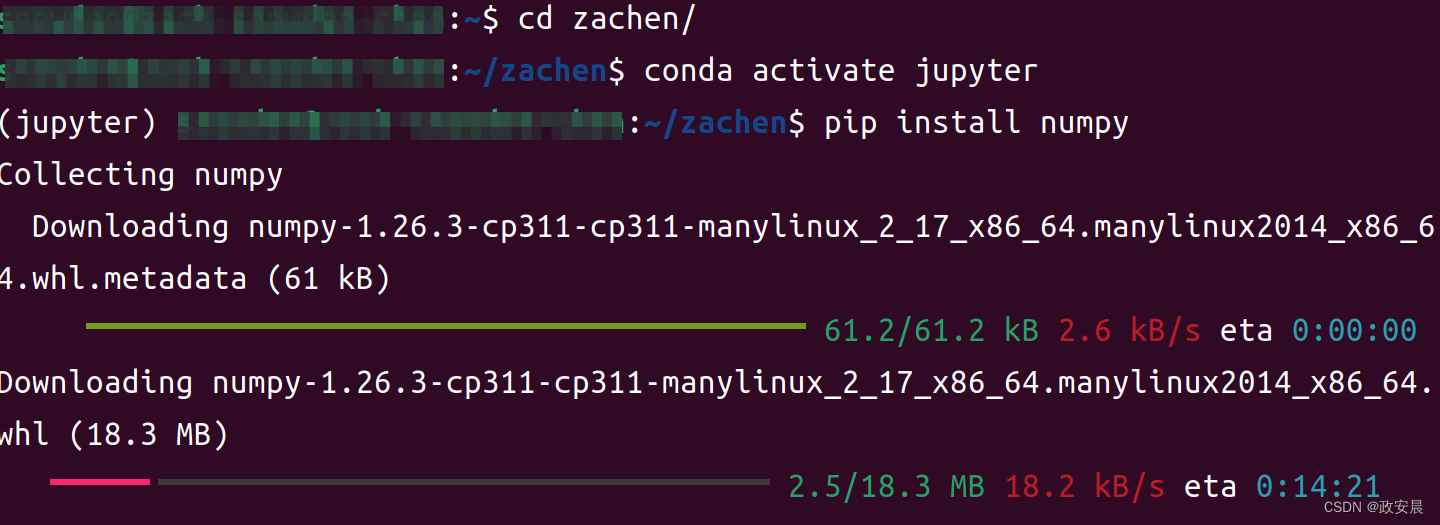

再一次执行上述代码:

这样,我们就熟悉了子模块。
另外,如果我们像上面那样导入numpy,那么调用random“子模块”中的函数将需要两个点(点操作两级):
# Roll 10 dice
rolls = numpy.random.randint(low=1, high=6, size=10)
rolls
经过前些篇的理解学习,你已经成为了int、float、bool、list、string和dict的专家了(对吧?)。
即使那是真的,也并不止于此。当你使用各种专门用于特定任务的库时,你会发现它们定义了自己的类型,你需要学会如何与其一起工作。例如,如果你使用绘图库matplotlib,你将接触到它定义的表示子图、图形、刻度线和注释的对象。pandas函数将给你提供DataFrames和Series。
接下来,我想与你分享一个快速应对陌生类型的生存指南。
理解陌生对象的三个工具
在上面的单元格(指 Jupyter Notebook单元格)中,我们看到调用一个numpy函数给了我们一个"array"。在之前我们从来没有看到过这样的东西(至少在本篇中没有)。但是不要惊慌:这里有三个我们熟悉的内置函数可以帮助我们。
1: type() (可以帮助咱们查看一切关于‘这是什么东东?’的方法)
type(rolls)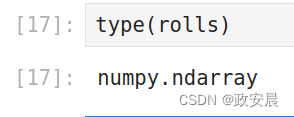
2: dir() (可以帮助咱们查看一切关于“我可以用它做什么?”的方法)
print(dir(rolls))
# the average roll
rolls.mean()如果我想要得到平均值,使用"mean"方法似乎是一个不错的选择...
(注:别走神啊,rolls这个对象咱们前面定义过)
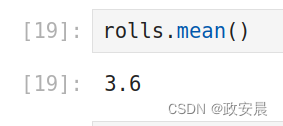
看看,咱们已经将前面numpy库工具随机产生的名为rolls的随机值列表数据计算了个平均值!
# Or maybe I just want to turn the array into a list, in which case I can use "tolist"
rolls.tolist()如果咱们只想要将数组转换成列表,这样我就可以使用"tolist"函数。

3: help() (当咱们想知道更多的时候,用它!)
# That "ravel" attribute sounds interesting. I'm a big classical music fan.
help(rolls.ravel)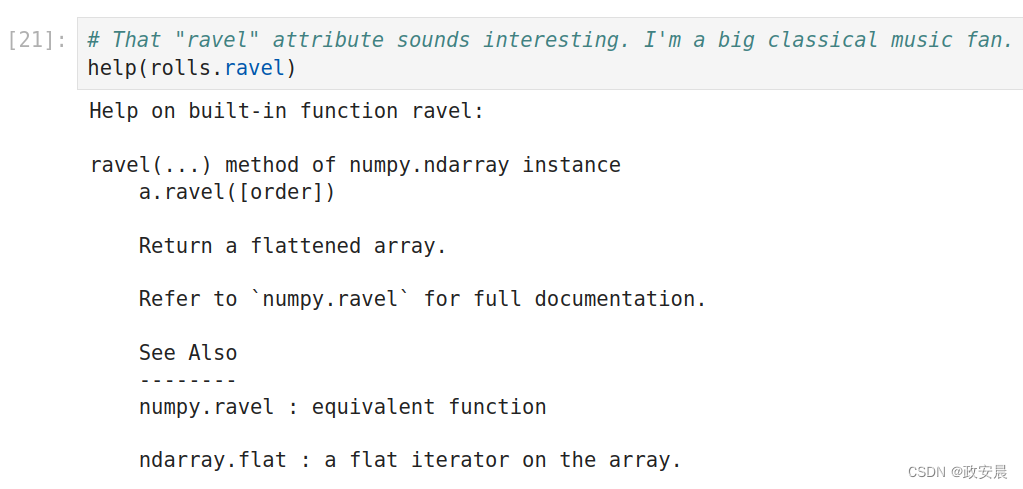
# Okay, just tell me everything there is to know about numpy.ndarray
help(rolls)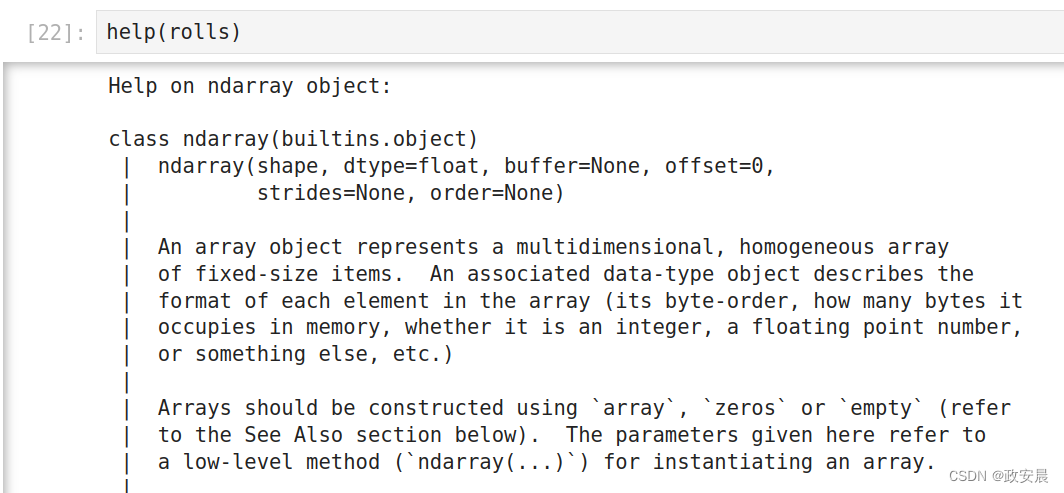
太多,咱们这里列不下,但我想,您估计更愿意去看这部分的在线文档:
numpy.ndarray — NumPy v1.14 Manual![]() https://docs.scipy.org/doc/numpy-1.14.0/reference/generated/numpy.ndarray.html
https://docs.scipy.org/doc/numpy-1.14.0/reference/generated/numpy.ndarray.html
运算符重载
以下表达式的值是多少?
[3, 4, 1, 2, 2, 1] + 10您试了一下,结果这样:
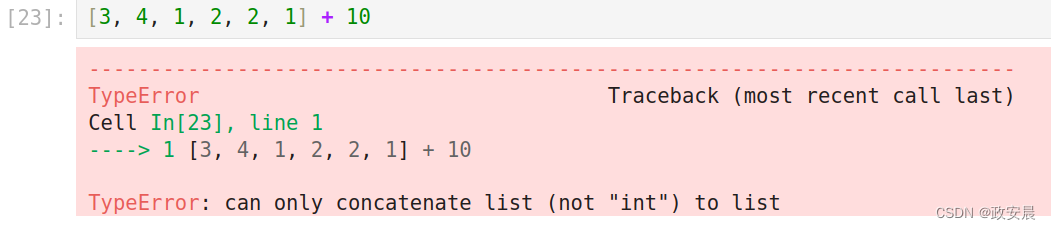
呵呵,这当然是个错误,但是……
rolls + 10
您会惊奇地发现,这样做就对了。
我们可能认为Python严格限制其核心语法的行为,如+、<、in、==或用于索引和切片的方括号。但实际上,Python采用了一种非常慎重的方法。当你定义一个新类型时,你可以选择它的加法运算方式,或者对于该类型的对象来说,它与其他对象相等意味着什么。
列表的设计者决定不允许将它们与数字相加。而NumPy数组的设计者则选择了不同的方法(将数字加到数组的每个元素上)。
下面是一些NumPy数组与Python运算符(或至少与列表不同)有差异的例子:
# At which indices are the dice less than or equal to 3?
rolls <= 3
xlist = [[1,2,3],[2,4,6],]
# Create a 2-dimensional array
x = numpy.asarray(xlist)
print("xlist = {}\nx =\n{}".format(xlist, x))
# Get the last element of the second row of our numpy array
x[1,-1]获取我们的numpy数组的第二行的最后一个元素:

# Get the last element of the second sublist of our nested list?
xlist[1,-1]获取我们嵌套列表中第二个子列表的最后一个元素?
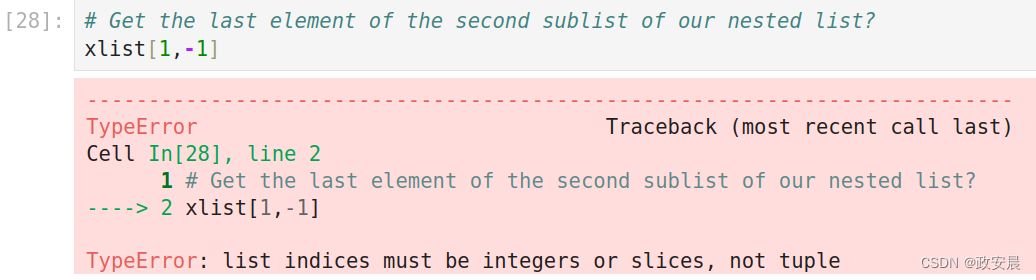
咦?出错啦?
numpy的ndarray类型专门用于处理多维数据,因此它定义了自己的索引逻辑,允许我们通过元组索引来指定每个维度的索引位置。
什么时候1+1不等于2?
事情可能会变得比这更奇怪。你可能听说过(甚至使用过)tensorflow,这是一个广泛用于深度学习的Python库。它大量使用了运算符重载技术。
(注意,下面咱们将引入TensorFlow库,我接下来切换成了已经安装有TensorFlow的虚拟环境,如果有小伙伴想知道如何安装TensorFLow,可以去看我机器学习笔记栏目里的文章。)
import tensorflow as tf
# Create two constants, each with value 1
a = tf.constant(1)
b = tf.constant(1)
# Add them together to get...
a + b
a + b 不是2,它是...(下面我引用了tensorflow的文档,把它翻译了一下)
"一个符号句柄,指向操作的其中一个输出。它不保存该操作输出的值,而是提供了一种在 TensorFlow 的 tf.Session 中计算这些值的方式。"
只要意识到这种情况是可能的,并且非常多的资料里通常会以非明显或看似神奇的方式使用操作符重载,这就很重要。
了解当应用于整数、字符串和列表时,Python的操作符如何工作并不能保证您能够立即理解它们应用于tensorflow Tensor、numpy ndarray或pandas DataFrame时的作用。
一旦您尝试了一点点DataFrame,例如下面的表达式开始看起来具有吸引力和直观性:
# Get the rows with population over 1m in South America
df[(df['population'] > 10**6) & (df['continent'] == 'South America')](作者政安晨提示:读者可以自己安装一下pandas的库,尝试一下下,咱们今后会有文章专门讲解pandas。)
但是为什么它起作用呢?上面的例子中有大约5种不同的重载运算符。每个操作符都在做什么?当事情开始出错时,了解答案可能会有所帮助。
好奇它是如何运作的吗?
你是否曾经在一个对象上调用过 help() 或者 dir() 函数,并且对那些带有双下划线的名字感到迷惑不解?
print(dir(list))
这实际上与运算符重载直接相关。
当Python程序员想要定义操作符在其类型上的行为时,他们通过实现以双下划线开始和结尾的特殊命名方法来实现,比如__lt__、setattr__或__contains。一般来说,遵循这种双下划线格式的命名在Python中具有特殊的含义。
例如,表达式 x in [1, 2, 3] 实际上是在幕后调用了列表方法 contains。它等同于(不太优雅的写法)[1, 2, 3].contains(x)。
如果你对此很好奇并想了解更多,你可以查阅Python的官方文档,其中描述了许多这种特殊的“下划线”方法。
3. Data model — Python 3.11.7 documentationObjects, values and types: Objects are Python’s abstraction for data. All data in a Python program is represented by objects or by relations between objects. (In a sense, and in conformance to Von ...![]() https://docs.python.org/3.11/reference/datamodel.html#special-method-names
https://docs.python.org/3.11/reference/datamodel.html#special-method-names
咱们在这篇文章中不会定义自己的类型(如果只有时间!),但我希望你能够在日后体验到定义自己独特、奇妙类型的乐趣。
轮到您啦
咱们用了7篇文章,带您了解一下Python语言,其实这7篇文章里已经囊括了Python语言的方方面面了,Python语言基础的讲解只要在这7篇文章上延展就可以啦。