一个不知名大学生,江湖人称菜狗
original author: jacky Li
Email : 3435673055@qq.com
Time of completion:2023.1.6
Last edited: 2023.1.6

YOLOv5 CPU实时的实例分割教程-它来了!
简介
前不久,ultralytics发布了一个yolov5 7.0版本,在这个版本中,隆重推出了yolov5的seg版本,也就是实例分割版本。
大佬酱也是奔着吃瓜要热乎的原则,立马上手尝试了一下,发现这个版本的mask回归头设计,还真的很高效。事实上在mask AP上的指标也不错!关键是速度快,可以在CPU下跑到realtime,还要啥自行车呢?
时至2023年,我们终于迎来了在CPU上实时跑实例分割的时代。

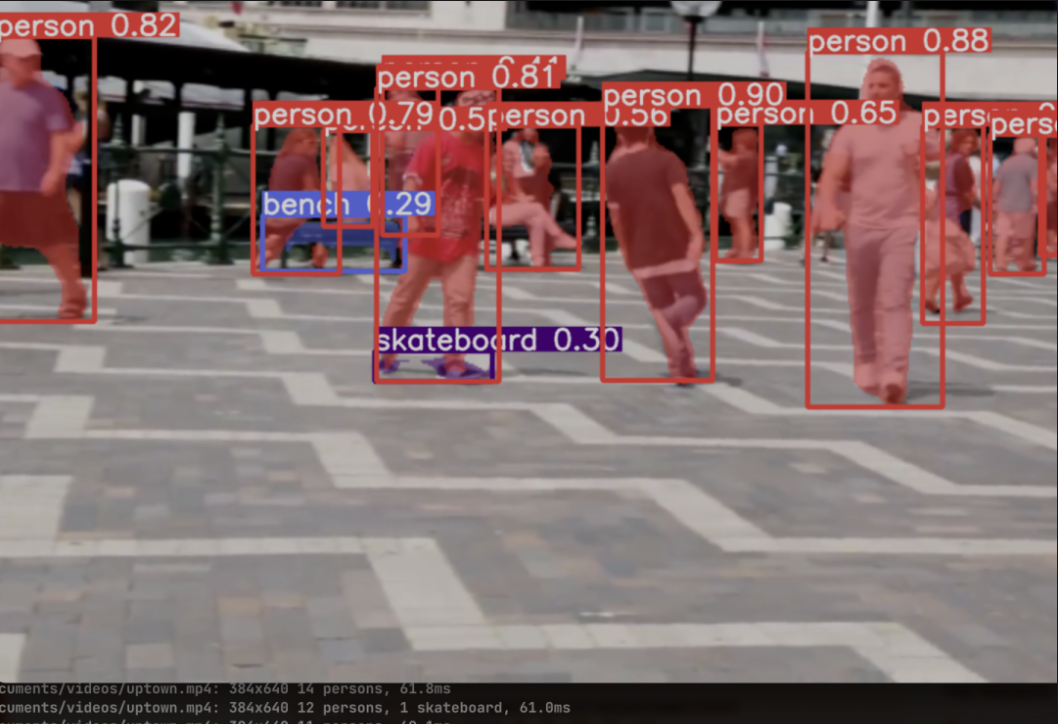
大佬酱实测了一下,在目标笔记多的时候,也可以以将近60ms的速度跑在CPU上,同时精度看起来也还不错。

单人场景下也可以跑的很快。
但是今天我们要做的事情不是就这样跑一下,而是要导出到ONNX,用ONNXRuntime来推理。
首先导出yolov5的实例分割模型:
python export.py --weights ~/Downloads/yolov5s-seg.pt --include onnx这一步比较简单,导出来的onnx如下:
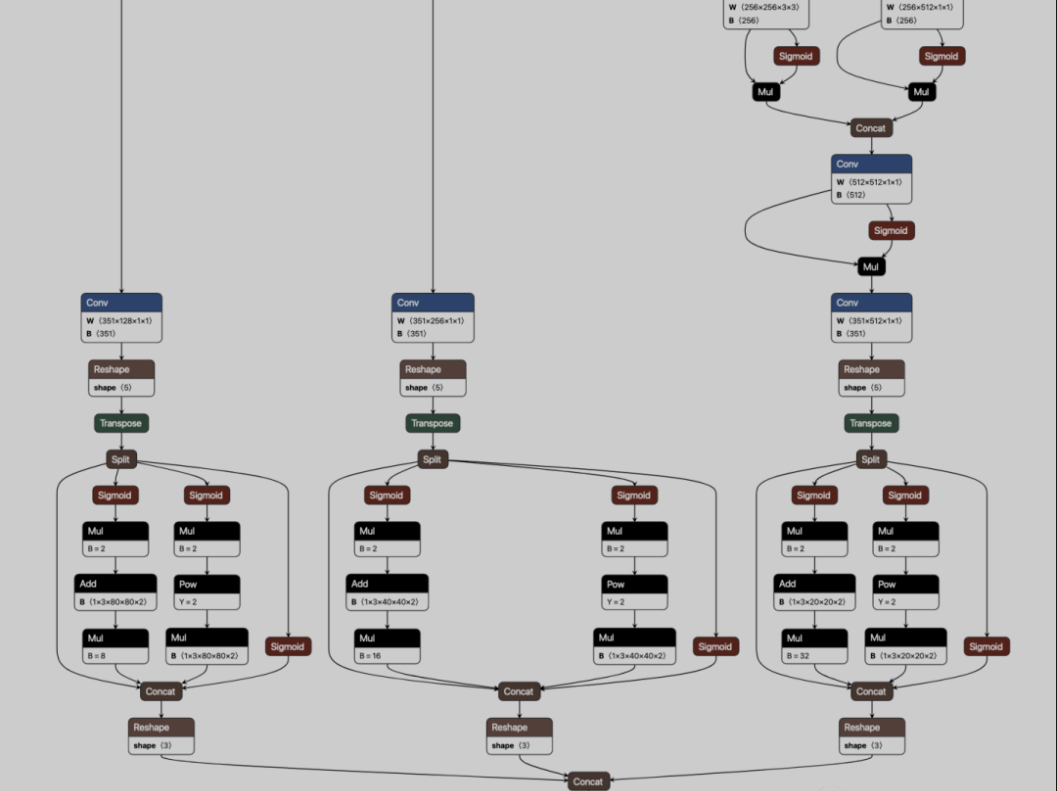
如果你嫌麻烦,也可以直接转到文末的代码专区,可以直接获取到onnx文件,并且推理脚本都有。
使用ONNXRuntime推理YOLOv5-seg
接下来就是拿到这个seg模型,用onnxruntime来推理。
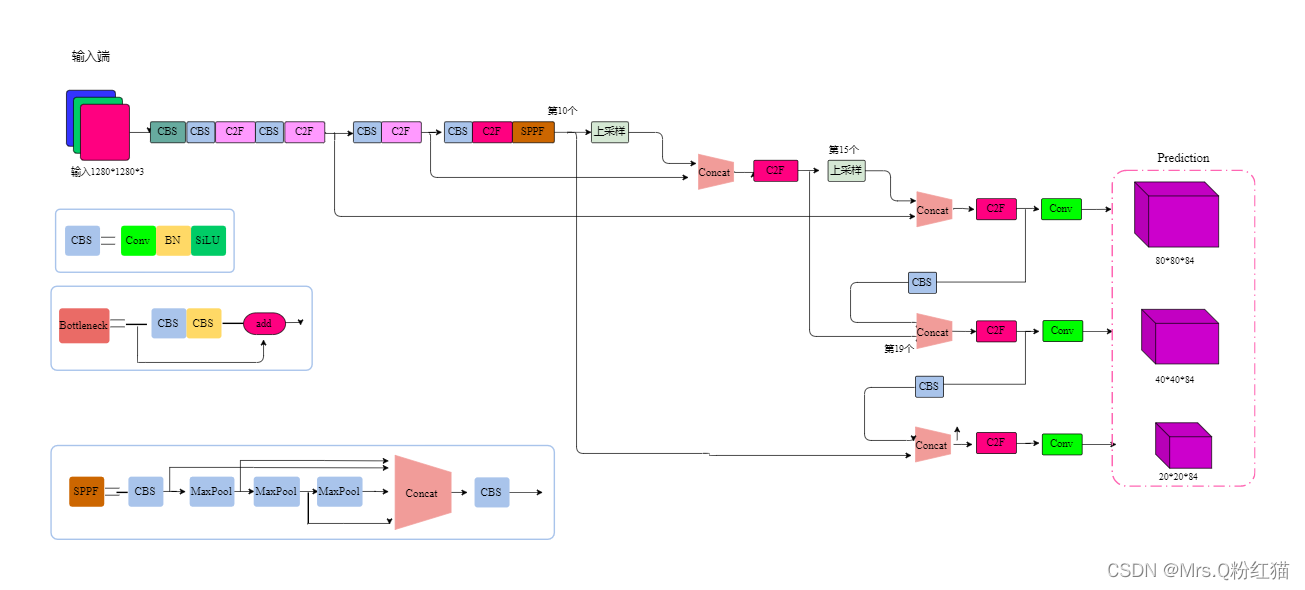
你需要知道的是,在yolov5-seg模型中,使用协方差与原型图来进行mask的预测,也就是说,在你的pred里面,输出的维度实际上是117. 它包括:
4 + 1 + 80 + 32
其中32就是mask的协方差系数。
与此同时,还有另外一个分支输出掩码,通过协方差与掩码的乘积,就可以知道mask的具体输出。
ONNXRuntime推理结果
接下里就是onnxruntime推理,直接上代码:
def detect(image):
im, ratio, (dw, dh) = letterbox(image, img_size, stride=32, auto=False)
im /= 255.0
print_shape(im)
inputs = {model.get_inputs()[0].name: im}
pred, proto = model.run(None, inputs)
pred = pred.reshape([1, -1, 4 + 1 + classes + 32])
pred = torch.as_tensor(pred)
proto = torch.as_tensor(proto)
print_shape(pred, proto)
pred = non_max_suppression(
pred, conf_thres, iou_thres, None, agnostic_nms, max_det=max_det, nm=32
)
# Process predictions
for i, det in enumerate(pred): # per image
if len(det):
masks = process_mask(
proto[i], det[:, 6:], det[:, :4], im.shape[2:], upsample=True
) # HWC
det[:, :4] = scale_boxes(
im.shape[2:], det[:, :4], image.shape
).round() # rescale boxes to im0 size
segments = reversed(masks2segments(masks))
segments = [
scale_segments(im.shape[2:], x, image.shape, normalize=False)
for x in segments
]
boxes = det[:, :4]
labels = det[:, 5]
scores = det[:, 4]
# print(boxes)
# print(scores)
image = visualize_det_cv2_part(image, scores, labels, boxes)
image = vis_segments_mask(image, segments)
return image输出结果:


作者有言
如果需要代码,请私聊博主,博主看见回。
如果感觉博主讲的对您有用,请点个关注支持一下吧,将会对此类问题持续更新……