文章目录
- bulk write
- addFields
- 增加field
- 嵌套增加field
- 覆盖显示
- 用变量替换
- 向数组中增加元素
- 分组 bucket
- 并行执行多个bucket
- $bucketAuto
- $count
- $document
- $facet
- 1.使用Aggregation对象实现
- 2.使用Aggregates实现
- $graphLookup 文档递归查询
- 跨多文档递归$graphLookup
bulk write
db.pizzas.insertMany( [
{ _id: 0, type: "pepperoni", size: "small", price: 4 },
{ _id: 1, type: "cheese", size: "medium", price: 7 },
{ _id: 2, type: "vegan", size: "large", price: 8 }
] )
try {
db.pizzas.bulkWrite( [
{ insertOne: { document: { _id: 3, type: "beef", size: "medium", price: 6 } } },
{ insertOne: { document: { _id: 4, type: "sausage", size: "large", price: 10 } } },
{ updateOne: {
filter: { type: "cheese" },
update: { $set: { price: 8 } }
} },
{ deleteOne: { filter: { type: "pepperoni"} } },
{ replaceOne: {
filter: { type: "vegan" },
replacement: { type: "tofu", size: "small", price: 4 }
} }
] )
} catch( error ) {
print( error )
}
输出
{
acknowledged: true,
insertedCount: 2,
insertedIds: { '0': 3, '1': 4 },
matchedCount: 2,
modifiedCount: 2,
deletedCount: 1,
upsertedCount: 0,
upsertedIds: {}
}
addFields
增加field
db.scores.insertMany([
{
_id: 1,
student: "Maya",
homework: [ 10, 5, 10 ],
quiz: [ 10, 8 ],
extraCredit: 0
},
{
_id: 2,
student: "Ryan",
homework: [ 5, 6, 5 ],
quiz: [ 8, 8 ],
extraCredit: 8
}])
db.scores.aggregate([
{
$addFields:{
totalHomework:{$sum:"$homework"},
totalQuiz:{$sum:"$quiz"}
}
},
{
$addFields:{
totalSocre:{$add:["$totalHomework","$totalQuiz","$extractCredit"]}
}
}
])
结果
{ _id: 1,
student: 'Maya',
homework: [ 10, 5, 10 ],
quiz: [ 10, 8 ],
extraCredit: 0,
totalHomework: 25,
totalQuiz: 18,
totalSocre: null }
{ _id: 2,
student: 'Ryan',
homework: [ 5, 6, 5 ],
quiz: [ 8, 8 ],
extraCredit: 8,
totalHomework: 16,
totalQuiz: 16,
totalSocre: null }
嵌套增加field
db.vehicles.insertMany(
[
{ _id: 1, type: "car", specs: { doors: 4, wheels: 4 } },
{ _id: 2, type: "motorcycle", specs: { doors: 0, wheels: 2 } },
{ _id: 3, type: "jet ski" }
]
)
db.vehicles.aggregate( [
{
$addFields: {
"specs.fuel_type": "unleaded"
}
}
] )
{ _id: 1, type: "car",
specs: { doors: 4, wheels: 4, fuel_type: "unleaded" } }
{ _id: 2, type: "motorcycle",
specs: { doors: 0, wheels: 2, fuel_type: "unleaded" } }
{ _id: 3, type: "jet ski",
specs: { fuel_type: "unleaded" } }
覆盖显示
db.scores.aggregate({
$addFields:{extraCredit:0}
})
{_id: 1,
student: 'Maya',
homework: [ 10, 5, 10 ],
quiz: [ 10, 8 ],
extraCredit: 0 }
{ _id: 2,
student: 'Ryan',
homework: [ 5, 6, 5 ],
quiz: [ 8, 8 ],
extraCredit: 0 }
用变量替换
db.scores.aggregate({
$addFields:{_id:"$item",item:"test"}
})
{ student: 'Maya',
homework: [ 10, 5, 10 ],
quiz: [ 10, 8 ],
extraCredit: 0,
item: 'test' }
{ student: 'Ryan',
homework: [ 5, 6, 5 ],
quiz: [ 8, 8 ],
extraCredit: 8,
item: 'test' }
向数组中增加元素
db.scores.insertMany([
{ _id: 1, student: "Maya", homework: [ 10, 5, 10 ], quiz: [ 10, 8 ], extraCredit: 0 },
{ _id: 2, student: "Ryan", homework: [ 5, 6, 5 ], quiz: [ 8, 8 ], extraCredit: 8 }
])
db.scores.aggregate([
{ $match: { _id: 1 } },
{ $addFields: { homework: { $concatArrays: [ "$homework", [ 7 ] ] } } }
])
{ "_id" : 1, "student" : "Maya", "homework" : [ 10, 5, 10, 7 ], "quiz" : [ 10, 8 ], "extraCredit" : 0 }
分组 bucket
$bucket and Memory Restrictions The $bucket stage has a limit of 100 megabytes of RAM. By default, if the stage exceeds this limit, $bucket returns an error. To allow more space for stage processing, use the allowDiskUse option to enable aggregation pipeline stages to write data to temporary files.
{
$bucket: {
groupBy: <expression>,
boundaries: [ <lowerbound1>, <lowerbound2>, ... ],
default: <literal>,
output: {
<output1>: { <$accumulator expression> },
...
<outputN>: { <$accumulator expression> }
}
}
}
db.artists.insertMany([
{ "_id" : 1, "last_name" : "Bernard", "first_name" : "Emil", "year_born" : 1868, "year_died" : 1941, "nationality" : "France" },
{ "_id" : 2, "last_name" : "Rippl-Ronai", "first_name" : "Joszef", "year_born" : 1861, "year_died" : 1927, "nationality" : "Hungary" },
{ "_id" : 3, "last_name" : "Ostroumova", "first_name" : "Anna", "year_born" : 1871, "year_died" : 1955, "nationality" : "Russia" },
{ "_id" : 4, "last_name" : "Van Gogh", "first_name" : "Vincent", "year_born" : 1853, "year_died" : 1890, "nationality" : "Holland" },
{ "_id" : 5, "last_name" : "Maurer", "first_name" : "Alfred", "year_born" : 1868, "year_died" : 1932, "nationality" : "USA" },
{ "_id" : 6, "last_name" : "Munch", "first_name" : "Edvard", "year_born" : 1863, "year_died" : 1944, "nationality" : "Norway" },
{ "_id" : 7, "last_name" : "Redon", "first_name" : "Odilon", "year_born" : 1840, "year_died" : 1916, "nationality" : "France" },
{ "_id" : 8, "last_name" : "Diriks", "first_name" : "Edvard", "year_born" : 1855, "year_died" : 1930, "nationality" : "Norway" }
])
db.artists.aggregate( [
// First Stage
{
$bucket: {
groupBy: "$year_born", // Field to group by
boundaries: [ 1840, 1850, 1860, 1870, 1880 ], // Boundaries for the buckets
default: "Other", // Bucket ID for documents which do not fall into a bucket
output: { // Output for each bucket
"count": { $sum: 1 },
"artists" :
{
$push: {
"name": { $concat: [ "$first_name", " ", "$last_name"] },
"year_born": "$year_born"
}
}
}
}
},
// Second Stage
{
$match: { count: {$gt: 3} }
}
] )
备注
The
$bucket
stage groups the documents into buckets by the year_born field. The buckets have the following
boundaries:
[1840, 1850)
[1850, 1860)
[1860, 1870)
[1870, 1880)
If a document did not contain the year_born field or its year_born field was outside the ranges above, it would be placed in the default bucket with the _id value "Other".
所以第一个stage产出的数据是
{ _id: 1840,
count: 1,
artists: [ { name: 'OdilonRedon', year_born: 1840 } ] }
{ _id: 1850,
count: 2,
artists:
[ { name: 'VincentVan Gogh', year_born: 1853 },
{ name: 'EdvardDiriks', year_born: 1855 } ] }
{ _id: 1860,
count: 4,
artists:
[ { name: 'EmilBernard', year_born: 1868 },
{ name: 'JoszefRippl-Ronai', year_born: 1861 },
{ name: 'AlfredMaurer', year_born: 1868 },
{ name: 'EdvardMunch', year_born: 1863 } ] }
{ _id: 1870,
count: 1,
artists: [ { name: 'AnnaOstroumova', year_born: 1871 } ] }
然后根据第二个stage 的$match进行过滤,得到
{ _id: 1860,
count: 4,
artists:
[ { name: 'EmilBernard', year_born: 1868 },
{ name: 'JoszefRippl-Ronai', year_born: 1861 },
{ name: 'AlfredMaurer', year_born: 1868 },
{ name: 'EdvardMunch', year_born: 1863 } ] }
并行执行多个bucket
db.artwork.insertMany([
{ "_id" : 1, "title" : "The Pillars of Society", "artist" : "Grosz", "year" : 1926,
"price" : NumberDecimal("199.99") },
{ "_id" : 2, "title" : "Melancholy III", "artist" : "Munch", "year" : 1902,
"price" : NumberDecimal("280.00") },
{ "_id" : 3, "title" : "Dancer", "artist" : "Miro", "year" : 1925,
"price" : NumberDecimal("76.04") },
{ "_id" : 4, "title" : "The Great Wave off Kanagawa", "artist" : "Hokusai",
"price" : NumberDecimal("167.30") },
{ "_id" : 5, "title" : "The Persistence of Memory", "artist" : "Dali", "year" : 1931,
"price" : NumberDecimal("483.00") },
{ "_id" : 6, "title" : "Composition VII", "artist" : "Kandinsky", "year" : 1913,
"price" : NumberDecimal("385.00") },
{ "_id" : 7, "title" : "The Scream", "artist" : "Munch", "year" : 1893
/* No price*/ },
{ "_id" : 8, "title" : "Blue Flower", "artist" : "O'Keefe", "year" : 1918,
"price" : NumberDecimal("118.42") }
])
db.artwork.aggregate( [
{
$facet: { // Top-level $facet stage
"price": [ // Output field 1
{
$bucket: {
groupBy: "$price", // Field to group by
boundaries: [ 0, 200, 400 ], // Boundaries for the buckets
default: "Other", // Bucket ID for documents which do not fall into a bucket
output: { // Output for each bucket
"count": { $sum: 1 },
"artwork" : { $push: { "title": "$title", "price": "$price" } },
"averagePrice": { $avg: "$price" }
}
}
}
],
"year": [ // Output field 2
{
$bucket: {
groupBy: "$year", // Field to group by
boundaries: [ 1890, 1910, 1920, 1940 ], // Boundaries for the buckets
default: "Unknown", // Bucket ID for documents which do not fall into a bucket
output: { // Output for each bucket
"count": { $sum: 1 },
"artwork": { $push: { "title": "$title", "year": "$year" } }
}
}
}
]
}
}
] )
产出
{ price:
[ { _id: 0,
count: 4,
artwork:
[ { title: 'The Pillars of Society', price: Decimal128("199.99") },
{ title: 'Dancer', price: Decimal128("76.04") },
{ title: 'The Great Wave off Kanagawa',
price: Decimal128("167.30") },
{ title: 'Blue Flower', price: Decimal128("118.42") } ],
averagePrice: Decimal128("140.4375") },
{ _id: 200,
count: 2,
artwork:
[ { title: 'Melancholy III', price: Decimal128("280.00") },
{ title: 'Composition VII', price: Decimal128("385.00") } ],
averagePrice: Decimal128("332.50") },
{ _id: 'Other',
count: 2,
artwork:
[ { title: 'The Persistence of Memory',
price: Decimal128("483.00") },
{ title: 'The Scream' } ],
averagePrice: Decimal128("483.00") } ],
year:
[ { _id: 1890,
count: 2,
artwork:
[ { title: 'Melancholy III', year: 1902 },
{ title: 'The Scream', year: 1893 } ] },
{ _id: 1910,
count: 2,
artwork:
[ { title: 'Composition VII', year: 1913 },
{ title: 'Blue Flower', year: 1918 } ] },
{ _id: 1920,
count: 3,
artwork:
[ { title: 'The Pillars of Society', year: 1926 },
{ title: 'Dancer', year: 1925 },
{ title: 'The Persistence of Memory', year: 1931 } ] },
{ _id: 'Unknown',
count: 1,
artwork: [ { title: 'The Great Wave off Kanagawa' } ] } ] }
$bucketAuto
db.artwork.insertMany([
{ "_id" : 1, "title" : "The Pillars of Society", "artist" : "Grosz", "year" : 1926,
"price" : NumberDecimal("199.99"),
"dimensions" : { "height" : 39, "width" : 21, "units" : "in" } },
{ "_id" : 2, "title" : "Melancholy III", "artist" : "Munch", "year" : 1902,
"price" : NumberDecimal("280.00"),
"dimensions" : { "height" : 49, "width" : 32, "units" : "in" } },
{ "_id" : 3, "title" : "Dancer", "artist" : "Miro", "year" : 1925,
"price" : NumberDecimal("76.04"),
"dimensions" : { "height" : 25, "width" : 20, "units" : "in" } },
{ "_id" : 4, "title" : "The Great Wave off Kanagawa", "artist" : "Hokusai",
"price" : NumberDecimal("167.30"),
"dimensions" : { "height" : 24, "width" : 36, "units" : "in" } },
{ "_id" : 5, "title" : "The Persistence of Memory", "artist" : "Dali", "year" : 1931,
"price" : NumberDecimal("483.00"),
"dimensions" : { "height" : 20, "width" : 24, "units" : "in" } },
{ "_id" : 6, "title" : "Composition VII", "artist" : "Kandinsky", "year" : 1913,
"price" : NumberDecimal("385.00"),
"dimensions" : { "height" : 30, "width" : 46, "units" : "in" } },
{ "_id" : 7, "title" : "The Scream", "artist" : "Munch",
"price" : NumberDecimal("159.00"),
"dimensions" : { "height" : 24, "width" : 18, "units" : "in" } },
{ "_id" : 8, "title" : "Blue Flower", "artist" : "O'Keefe", "year" : 1918,
"price" : NumberDecimal("118.42"),
"dimensions" : { "height" : 24, "width" : 20, "units" : "in" } }])
{ acknowledged: true,
insertedIds: { '0': 1, '1': 2, '2': 3, '3': 4, '4': 5, '5': 6, '6': 7, '7': 8 } }
db.artwork.aggregate([
{
$bucketAuto:{
groupBy:"$price",
buckets:4
}
}
])
{ _id: { min: Decimal128("76.04"), max: Decimal128("159.00") },
count: 2 }
{ _id: { min: Decimal128("159.00"), max: Decimal128("199.99") },
count: 2 }
{ _id: { min: Decimal128("199.99"), max: Decimal128("385.00") },
count: 2 }
{ _id: { min: Decimal128("385.00"), max: Decimal128("483.00") },
count: 2 }
db.artwork.aggregate( [
{
$facet: {
"price": [
{
$bucketAuto: {
groupBy: "$price",
buckets: 4
}
}
],
"year": [
{
$bucketAuto: {
groupBy: "$year",
buckets: 3,
output: {
"count": { $sum: 1 },
"years": { $push: "$year" }
}
}
}
],
"area": [
{
$bucketAuto: {
groupBy: {
$multiply: [ "$dimensions.height", "$dimensions.width" ]
},
buckets: 4,
output: {
"count": { $sum: 1 },
"titles": { $push: "$title" }
}
}
}
]
}
}
] )
输出
{
"area" : [
{
"_id" : { "min" : 432, "max" : 500 },
"count" : 3,
"titles" : [
"The Scream",
"The Persistence of Memory",
"Blue Flower"
]
},
{
"_id" : { "min" : 500, "max" : 864 },
"count" : 2,
"titles" : [
"Dancer",
"The Pillars of Society"
]
},
{
"_id" : { "min" : 864, "max" : 1568 },
"count" : 2,
"titles" : [
"The Great Wave off Kanagawa",
"Composition VII"
]
},
{
"_id" : { "min" : 1568, "max" : 1568 },
"count" : 1,
"titles" : [
"Melancholy III"
]
}
],
"price" : [
{
"_id" : { "min" : NumberDecimal("76.04"), "max" : NumberDecimal("159.00") },
"count" : 2
},
{
"_id" : { "min" : NumberDecimal("159.00"), "max" : NumberDecimal("199.99") },
"count" : 2
},
{
"_id" : { "min" : NumberDecimal("199.99"), "max" : NumberDecimal("385.00") },
"count" : 2 },
{
"_id" : { "min" : NumberDecimal("385.00"), "max" : NumberDecimal("483.00") },
"count" : 2
}
],
"year" : [
{ "_id" : { "min" : null, "max" : 1913 }, "count" : 3, "years" : [ 1902 ] },
{ "_id" : { "min" : 1913, "max" : 1926 }, "count" : 3, "years" : [ 1913, 1918, 1925 ] },
{ "_id" : { "min" : 1926, "max" : 1931 }, "count" : 2, "years" : [ 1926, 1931 ] }
]
}
$count
db.scores.insertMany([
{ "_id" : 1, "subject" : "History", "score" : 88 },
{ "_id" : 2, "subject" : "History", "score" : 92 },
{ "_id" : 3, "subject" : "History", "score" : 97 },
{ "_id" : 4, "subject" : "History", "score" : 71 },
{ "_id" : 5, "subject" : "History", "score" : 79 },
{ "_id" : 6, "subject" : "History", "score" : 83 }
])
{ acknowledged: true,
insertedIds: { '0': 1, '1': 2, '2': 3, '3': 4, '4': 5, '5': 6 } }
db.scores.aggregate([
{
$match:{
score:{$gt:80}
}
}
])
{ _id: 1, subject: 'History', score: 88 }
{ _id: 2, subject: 'History', score: 92 }
{ _id: 3, subject: 'History', score: 97 }
{ _id: 6, subject: 'History', score: 83 }
db.scores.aggregate([
{
$match:{
score:{$gt:80}
}
},{
$count:"passing_scores"
}
])
{ passing_scores: 4 }
$document
db.aggregate(
[
{ $documents: [ { x: 10 }, { x: 2 }, { x: 5 } ] },
{ $bucketAuto: { groupBy: "$x", buckets: 4 } }
]
)
{ _id: { min: 2, max: 5 }, count: 1 }
{ _id: { min: 5, max: 10 }, count: 1 }
{ _id: { min: 10, max: 10 }, count: 1 }
$facet
facet可以实现在facet管道操作完成多个stage管道操作。减少获取输入文档的次数。
分页查询文档数据的同时,把符合查询条件的总数也查询出来的场景下,如果使用$facet,同时获取分页数据和总数,不用做两次数据库查询(分别查询分页数据和总数)。
$unwind 学习
db.user.insertMany([
{
user_id:"A_id" ,
bonus:[
{ type:"a" ,amount:1000 },
{ type:"b" ,amount:2000 },
{ type:"b" ,amount:3000 }
]
}
])
{ acknowledged: true,
insertedIds: { '0': ObjectId("63b675e5e13faeb56183402e") } }
使用$unwind进行拆分
db.user.aggregate([
{$unwind:"$bonus"}
])
{ _id: ObjectId("63b675e5e13faeb56183402e"),
user_id: 'A_id',
bonus: { type: 'a', amount: 1000 } }
{ _id: ObjectId("63b675e5e13faeb56183402e"),
user_id: 'A_id',
bonus: { type: 'b', amount: 2000 } }
{ _id: ObjectId("63b675e5e13faeb56183402e"),
user_id: 'A_id',
bonus: { type: 'b', amount: 3000 } }
结合统计一起查询
db.user.aggregate([
{$match:{user_id:"A_id"}},
{$unwind:"$bonus"},
{$match:{"bonus.type":"b"}},
{$group:{_id:"$user_id",amount:{$sum:"$bonus.amount"}}}
])
{ _id: 'A_id', amount: 5000 }
db.artwork.insertMany([
{ "_id" : 1, "title" : "The Pillars of Society", "artist" : "Grosz", "year" : 1926,
"price" : NumberDecimal("199.99"),
"tags" : [ "painting", "satire", "Expressionism", "caricature" ] },
{ "_id" : 2, "title" : "Melancholy III", "artist" : "Munch", "year" : 1902,
"price" : NumberDecimal("280.00"),
"tags" : [ "woodcut", "Expressionism" ] },
{ "_id" : 3, "title" : "Dancer", "artist" : "Miro", "year" : 1925,
"price" : NumberDecimal("76.04"),
"tags" : [ "oil", "Surrealism", "painting" ] },
{ "_id" : 4, "title" : "The Great Wave off Kanagawa", "artist" : "Hokusai",
"price" : NumberDecimal("167.30"),
"tags" : [ "woodblock", "ukiyo-e" ] },
{ "_id" : 5, "title" : "The Persistence of Memory", "artist" : "Dali", "year" : 1931,
"price" : NumberDecimal("483.00"),
"tags" : [ "Surrealism", "painting", "oil" ] },
{ "_id" : 6, "title" : "Composition VII", "artist" : "Kandinsky", "year" : 1913,
"price" : NumberDecimal("385.00"),
"tags" : [ "oil", "painting", "abstract" ] },
{ "_id" : 7, "title" : "The Scream", "artist" : "Munch", "year" : 1893,
"tags" : [ "Expressionism", "painting", "oil" ] },
{ "_id" : 8, "title" : "Blue Flower", "artist" : "O'Keefe", "year" : 1918,
"price" : NumberDecimal("118.42"),
"tags" : [ "abstract", "painting" ] }
])
{ acknowledged: true,
insertedIds: { '0': 1, '1': 2, '2': 3, '3': 4, '4': 5, '5': 6, '6': 7, '7': 8 } }
按照tag分类:先用unwind拆分tags字段的数组值,交给下一个聚合 $sortByCount, 按照tags的个数排序
db.artwork.aggregate([
{$unwind:"$tags"},
{$sortByCount:"$tags"}
])
{ _id: 'painting', count: 6 }
{ _id: 'oil', count: 4 }
{ _id: 'Expressionism', count: 3 }
{ _id: 'Surrealism', count: 2 }
{ _id: 'abstract', count: 2 }
{ _id: 'ukiyo-e', count: 1 }
{ _id: 'woodblock', count: 1 }
{ _id: 'woodcut', count: 1 }
{ _id: 'satire', count: 1 }
{ _id: 'caricature', count: 1 }
按照price分类:先过滤数据(只处理存在price数据的文档),然后执行$bucket按照价格区间分组 0150,151200, 201~300, 301~400这样。
db.artwork.aggregate([
{$match:{price:{$exists:1}}},
{$bucket:{
groupBy:"$price",
boundaries:[0,150,200,300,400],
default:"Other"
}}
])
{ _id: 0, count: 2 }
{ _id: 150, count: 2 }
{ _id: 200, count: 1 }
{ _id: 300, count: 1 }
{ _id: 'Other', count: 1 }
进一步设置输出字段
db.artwork.aggregate([
{$match:{price:{$exists:1}}},
{$bucket:{
groupBy:"$price",
boundaries:[0,150,200,300,400],
default:"Other"
}}
])
{ _id: 0, count: 2 }
{ _id: 150, count: 2 }
{ _id: 200, count: 1 }
{ _id: 300, count: 1 }
{ _id: 'Other', count: 1 }
按照years分类。 分成4个区间。
db.artwork.aggregate([
{$bucketAuto:{
groupBy:"$year",
buckets:4
}}
])
{ _id: { min: null, max: 1902 }, count: 2 }
{ _id: { min: 1902, max: 1918 }, count: 2 }
{ _id: { min: 1918, max: 1926 }, count: 2 }
{ _id: { min: 1926, max: 1931 }, count: 2 }
整合到一起就是
db.artwork.aggregate([
{
$facet:{
"categorizedByTags":[
{$unwind:"$tags"},
{$sortByCount:"$tags"}
],
"categorizedByPrice":[
{$match:{price:{$exists:1}}},
{$bucket:{
groupBy:"$price",
boundaries:[0,150,200,300,400],
default:"Other",
output:{
"count":{$sum:1},
"titles":{$push:"$title"}
}
}}
] ,
"categorizedByYears(Auto)":[
{$bucketAuto:{
groupBy:"$year",
buckets:4
}}
]
}
}
])
{ categorizedByTags:
[ { _id: 'painting', count: 6 },
{ _id: 'oil', count: 4 },
{ _id: 'Expressionism', count: 3 },
{ _id: 'Surrealism', count: 2 },
{ _id: 'abstract', count: 2 },
{ _id: 'woodcut', count: 1 },
{ _id: 'woodblock', count: 1 },
{ _id: 'ukiyo-e', count: 1 },
{ _id: 'caricature', count: 1 },
{ _id: 'satire', count: 1 } ],
categorizedByPrice:
[ { _id: 0, count: 2, titles: [ 'Dancer', 'Blue Flower' ] },
{ _id: 150,
count: 2,
titles: [ 'The Pillars of Society', 'The Great Wave off Kanagawa' ] },
{ _id: 200, count: 1, titles: [ 'Melancholy III' ] },
{ _id: 300, count: 1, titles: [ 'Composition VII' ] },
{ _id: 'Other',
count: 1,
titles: [ 'The Persistence of Memory' ] } ],
'categorizedByYears(Auto)':
[ { _id: { min: null, max: 1902 }, count: 2 },
{ _id: { min: 1902, max: 1918 }, count: 2 },
{ _id: { min: 1918, max: 1926 }, count: 2 },
{ _id: { min: 1926, max: 1931 }, count: 2 } ] }
1.使用Aggregation对象实现
@Test
public void testFacetAggregations(){
String ARTWORK_COLLECTION = "artwork";
// Facet中第一组分类(categorizedByTags)的两个聚合操作unwind 和 sortByCount
UnwindOperation unwindForByTags = Aggregation.unwind("$tags");
SortByCountOperation sortByCountForByTags = Aggregation.sortByCount("$tags");
// Facet中第二组分类(categorizedByPrice)的聚合操作match 和 match
MatchOperation matchForByPrice = Aggregation.match(Criteria.where("price").exists(true));
// 分别传入bucket分组的字段price,设置区间值,并设置桶内条数统计和值(这里用titles接收title的值)
BucketOperation bucketForByPrice = Aggregation.bucket("$price")
.withBoundaries(0, 150, 200, 300, 400)
.withDefaultBucket("Other")
.andOutput("count").sum(1).as("count")
.andOutput("$title").push().as("titles");
// Facet中第三组分类 (categorizedByYears(Auto))的聚合操作,按年自动分成4个区间。
BucketAutoOperation bucketForByYears = Aggregation.bucketAuto("$year", 4);
// Aggregation调用facet方法,按照组别分类顺序,把每一组的聚合操作和输出的名称传进去。
FacetOperation facetOperation = Aggregation.facet(unwindForByTags, sortByCountForByTags).as("categorizedByTags")
.and(matchForByPrice, bucketForByPrice).as("categorizedByPrice")
.and(bucketForByYears).as("categorizedByYears(Auto)");
// 把facetOperation传入newAggregation得到Aggregation对象,调用mongoTemplate的Aggregate方法执行得到结果
Aggregation aggregation = Aggregation.newAggregation(facetOperation);
AggregationResults<Document> resultList = mongoTemplate.aggregate(aggregation, ARTWORK_COLLECTION, Document.class);
for (Document document : resultList) {
System.out.println("result is :" + document);
}
}
2.使用Aggregates实现
@Test
public void testFacetAggregates() {
String ARTWORK_COLLECTION = "artwork";
// Facet中第一组分类(categorizedByTags)的两个聚合操作unwind 和 sortByCount
Bson unwindBsonForByTags = Aggregates.unwind("$tags");
Bson sortByCountBsonForByTags = Aggregates.sortByCount("$tags");
// 新建Facet对象,传入第一组分类的接收名称,以及在第一组分类中要做的聚合操作。
Facet categorizedByTags = new Facet("categorizedByTags", unwindBsonForByTags, sortByCountBsonForByTags);
// Facet中第二组分类(categorizedByPrice)的聚合操作match 和 match
Bson matchBsonForPrice = Aggregates.match(Filters.exists("price"));
// 这里面要新建BsonField构建 {"count": { $sum: 1 } 和 "titles": { $push: "$title" }} 作为第二组分类中$Bucket聚合操作中output值
BsonField countOutput = new BsonField("count", new Document("$sum", 1));
BsonField titleOutput = new BsonField("titles", new Document("$push", "$price"));
// 上面2个操作传入到BucketOption对象,最后传到bucket操作
BucketOptions bucketOptions = new BucketOptions().defaultBucket("Other").output(countOutput).output(titleOutput);
Bson bucketBsonForByPrice = Aggregates.bucket("$price", Arrays.asList(0, 150, 200, 300, 400), bucketOptions);
Facet categorizedByPrice = new Facet("categorizedByPrice", matchBsonForPrice, bucketBsonForByPrice);
// Facet中第三组分类 (categorizedByYears(Auto))的聚合操作,按年自动分成4个区间。
Bson bucketAutoBsonForByYears = Aggregates.bucketAuto("$year", 4);
Facet categorizedByYears = new Facet("categorizedByYears", bucketAutoBsonForByYears);
// 新建一个List<Facet>把每组分类的Facet对象传进去。
List<Facet> facetList = new ArrayList<>();
facetList.add(categorizedByTags);
facetList.add(categorizedByPrice);
facetList.add(categorizedByYears);
// 调用Aggregates的facet方法,传入List<Facet>得到最终Bson对象,并添加到Bson集合中。
Bson facetBson = Aggregates.facet(facetList);
List<Bson> bsonList = new ArrayList<>();
bsonList.add(facetBson);
// 调用方法执行得到结果
MongoCollection<Document> collection = mongoTemplate.getCollection(ARTWORK_COLLECTION);
AggregateIterable<Document> resultList = collection.aggregate(bsonList);
for (Document document : resultList) {
System.out.println("result is :" + document);
}
}
$graphLookup 文档递归查询
格式
{
$graphLookup: {
from: <collection>,
startWith: <expression>,
connectFromField: <string>,
connectToField: <string>,
as: <string>,
maxDepth: <number>,
depthField: <string>,
restrictSearchWithMatch: <document>
}
}
注意事项
$graphLookup递归查询会用到内存占用
db.collection.aggregate([
{ $graphLookup: { from: "fromCollection", ... } }
])
The collection can be sharded.
The fromCollection cannot be sharded.
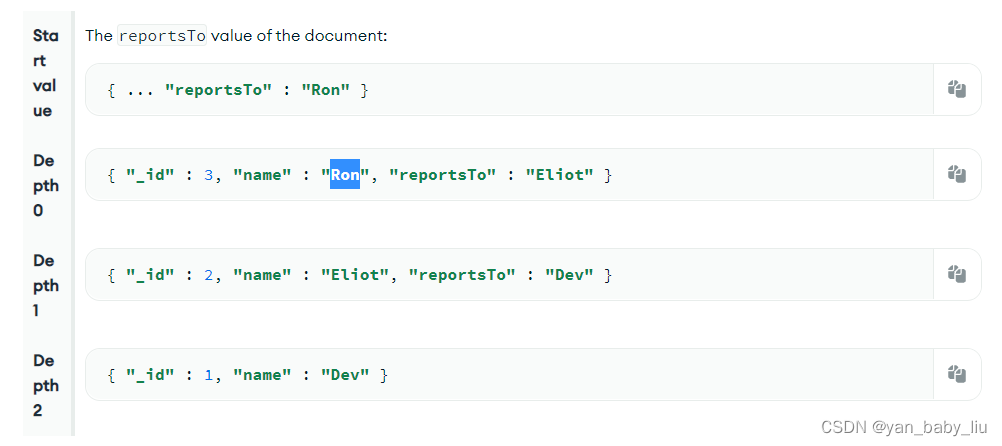
db.employees.insertMany([
{ "_id" : 1, "name" : "Dev" },
{ "_id" : 2, "name" : "Eliot", "reportsTo" : "Dev" },
{ "_id" : 3, "name" : "Ron", "reportsTo" : "Eliot" },
{ "_id" : 4, "name" : "Andrew", "reportsTo" : "Eliot" },
{ "_id" : 5, "name" : "Asya", "reportsTo" : "Ron" },
{ "_id" : 6, "name" : "Dan", "reportsTo" : "Andrew" }
])
db.employees.aggregate( [
{
$graphLookup: {
from: "employees",
startWith: "$reportsTo",
connectFromField: "reportsTo",
connectToField: "name",
as: "reportingHierarchy"
}
}
] )
{ _id: 1, name: 'Dev', reportingHierarchy: [] }
{ _id: 2,
name: 'Eliot',
reportsTo: 'Dev',
reportingHierarchy: [ { _id: 1, name: 'Dev' } ] }
{ _id: 3,
name: 'Ron',
reportsTo: 'Eliot',
reportingHierarchy:
[ { _id: 2, name: 'Eliot', reportsTo: 'Dev' },
{ _id: 1, name: 'Dev' } ] }
{ _id: 4,
name: 'Andrew',
reportsTo: 'Eliot',
reportingHierarchy:
[ { _id: 2, name: 'Eliot', reportsTo: 'Dev' },
{ _id: 1, name: 'Dev' } ] }
{ _id: 5,
name: 'Asya',
reportsTo: 'Ron',
reportingHierarchy:
[ { _id: 3, name: 'Ron', reportsTo: 'Eliot' },
{ _id: 2, name: 'Eliot', reportsTo: 'Dev' },
{ _id: 1, name: 'Dev' } ] }
{ _id: 6,
name: 'Dan',
reportsTo: 'Andrew',
reportingHierarchy:
[ { _id: 2, name: 'Eliot', reportsTo: 'Dev' },
{ _id: 4, name: 'Andrew', reportsTo: 'Eliot' },
{ _id: 1, name: 'Dev' } ] }
以下以Ron为例
跨多文档递归$graphLookup
db.airports.insertMany( [
{ "_id" : 0, "airport" : "JFK", "connects" : [ "BOS", "ORD" ] },
{ "_id" : 1, "airport" : "BOS", "connects" : [ "JFK", "PWM" ] },
{ "_id" : 2, "airport" : "ORD", "connects" : [ "JFK" ] },
{ "_id" : 3, "airport" : "PWM", "connects" : [ "BOS", "LHR" ] },
{ "_id" : 4, "airport" : "LHR", "connects" : [ "PWM" ] }
] )
db.travelers.insertMany( [
{ "_id" : 1, "name" : "Dev", "nearestAirport" : "JFK" },
{ "_id" : 2, "name" : "Eliot", "nearestAirport" : "JFK" },
{ "_id" : 3, "name" : "Jeff", "nearestAirport" : "BOS" }
] )
db.travelers.aggregate( [
{
$graphLookup: {
from: "airports",
startWith: "$nearestAirport",
connectFromField: "connects",
connectToField: "airport",
maxDepth: 2,
depthField: "numConnections",
as: "destinations"
}
}
] )
结果为
{
"_id" : 1,
"name" : "Dev",
"nearestAirport" : "JFK",
"destinations" : [
{ "_id" : 3,
"airport" : "PWM",
"connects" : [ "BOS", "LHR" ],
"numConnections" : NumberLong(2) },
{ "_id" : 2,
"airport" : "ORD",
"connects" : [ "JFK" ],
"numConnections" : NumberLong(1) },
{ "_id" : 1,
"airport" : "BOS",
"connects" : [ "JFK", "PWM" ],
"numConnections" : NumberLong(1) },
{ "_id" : 0,
"airport" : "JFK",
"connects" : [ "BOS", "ORD" ],
"numConnections" : NumberLong(0) }
]
}
{
"_id" : 2,
"name" : "Eliot",
"nearestAirport" : "JFK",
"destinations" : [
{ "_id" : 3,
"airport" : "PWM",
"connects" : [ "BOS", "LHR" ],
"numConnections" : NumberLong(2) },
{ "_id" : 2,
"airport" : "ORD",
"connects" : [ "JFK" ],
"numConnections" : NumberLong(1) },
{ "_id" : 1,
"airport" : "BOS",
"connects" : [ "JFK", "PWM" ],
"numConnections" : NumberLong(1) },
{ "_id" : 0,
"airport" : "JFK",
"connects" : [ "BOS", "ORD" ],
"numConnections" : NumberLong(0) } ]
}
{
"_id" : 3,
"name" : "Jeff",
"nearestAirport" : "BOS",
"destinations" : [
{ "_id" : 2,
"airport" : "ORD",
"connects" : [ "JFK" ],
"numConnections" : NumberLong(2) },
{ "_id" : 3,
"airport" : "PWM",
"connects" : [ "BOS", "LHR" ],
"numConnections" : NumberLong(1) },
{ "_id" : 4,
"airport" : "LHR",
"connects" : [ "PWM" ],
"numConnections" : NumberLong(2) },
{ "_id" : 0,
"airport" : "JFK",
"connects" : [ "BOS", "ORD" ],
"numConnections" : NumberLong(1) },
{ "_id" : 1,
"airport" : "BOS",
"connects" : [ "JFK", "PWM" ],
"numConnections" : NumberLong(0) }
]
}
递归匹配时候,增加过滤
{
"_id" : 1,
"name" : "Tanya Jordan",
"friends" : [ "Shirley Soto", "Terry Hawkins", "Carole Hale" ],
"hobbies" : [ "tennis", "unicycling", "golf" ]
},
{
"_id" : 2,
"name" : "Carole Hale",
"friends" : [ "Joseph Dennis", "Tanya Jordan", "Terry Hawkins" ],
"hobbies" : [ "archery", "golf", "woodworking" ]
},
{
"_id" : 3,
"name" : "Terry Hawkins",
"friends" : [ "Tanya Jordan", "Carole Hale", "Angelo Ward" ],
"hobbies" : [ "knitting", "frisbee" ]
},
{
"_id" : 4,
"name" : "Joseph Dennis",
"friends" : [ "Angelo Ward", "Carole Hale" ],
"hobbies" : [ "tennis", "golf", "topiary" ]
},
{
"_id" : 5,
"name" : "Angelo Ward",
"friends" : [ "Terry Hawkins", "Shirley Soto", "Joseph Dennis" ],
"hobbies" : [ "travel", "ceramics", "golf" ]
},
{
"_id" : 6,
"name" : "Shirley Soto",
"friends" : [ "Angelo Ward", "Tanya Jordan", "Carole Hale" ],
"hobbies" : [ "frisbee", "set theory" ]
}
])
1.查询
db.people.aggregate([
{$match:{name:"Tanya Jordan"}},
{$graphLookup:{
from:"people",
startWith:"$friends",
connectFromField:"friend",
connectToField:"name",
as:"golfers"
}}
])
{ _id: 1,
name: 'Tanya Jordan',
friends: [ 'Shirley Soto', 'Terry Hawkins', 'Carole Hale' ],
hobbies: [ 'tennis', 'unicycling', 'golf' ],
golfers:
[ { _id: 2,
name: 'Carole Hale',
friends: [ 'Joseph Dennis', 'Tanya Jordan', 'Terry Hawkins' ],
hobbies: [ 'archery', 'golf', 'woodworking' ] },
{ _id: 3,
name: 'Terry Hawkins',
friends: [ 'Tanya Jordan', 'Carole Hale', 'Angelo Ward' ],
hobbies: [ 'knitting', 'frisbee' ] },
{ _id: 6,
name: 'Shirley Soto',
friends: [ 'Angelo Ward', 'Tanya Jordan', 'Carole Hale' ],
hobbies: [ 'frisbee', 'set theory' ] } ] }
2.增加匹配限制
db.people.aggregate([
{$match:{name:"Tanya Jordan"}},
{$graphLookup:{
from:"people",
startWith:"$friends",
connectFromField:"friends",
connectToField:"name",
as:"golfers",
restrictSearchWithMatch: {"hobbies":"golf"},
depthField:"length"
}}
])
{ _id: 1,
name: 'Tanya Jordan',
friends: [ 'Shirley Soto', 'Terry Hawkins', 'Carole Hale' ],
hobbies: [ 'tennis', 'unicycling', 'golf' ],
golfers:
[ { _id: 4,
name: 'Joseph Dennis',
friends: [ 'Angelo Ward', 'Carole Hale' ],
hobbies: [ 'tennis', 'golf', 'topiary' ],
length: 1 },
{ _id: 1,
name: 'Tanya Jordan',
friends: [ 'Shirley Soto', 'Terry Hawkins', 'Carole Hale' ],
hobbies: [ 'tennis', 'unicycling', 'golf' ],
length: 1 },
{ _id: 5,
name: 'Angelo Ward',
friends: [ 'Terry Hawkins', 'Shirley Soto', 'Joseph Dennis' ],
hobbies: [ 'travel', 'ceramics', 'golf' ],
length: 2 },
{ _id: 2,
name: 'Carole Hale',
friends: [ 'Joseph Dennis', 'Tanya Jordan', 'Terry Hawkins' ],
hobbies: [ 'archery', 'golf', 'woodworking' ],
length: 0 } ] }
增加显示输出字段设置
db.people.aggregate([
{$match:{name:"Tanya Jordan"}},
{$graphLookup:{
from:"people",
startWith:"$friends",
connectFromField:"friends",
connectToField:"name",
as:"golfers",
restrictSearchWithMatch: {"hobbies":"golf"},
depthField:"length"
}},
{
$project:{
name:1,
friends:1,
"connections who play golf":"$golfers.name"
}
}
])
{ _id: 1,
name: 'Tanya Jordan',
friends: [ 'Shirley Soto', 'Terry Hawkins', 'Carole Hale' ],
'connections who play golf': [ 'Joseph Dennis', 'Tanya Jordan', 'Angelo Ward', 'Carole Hale' ] }