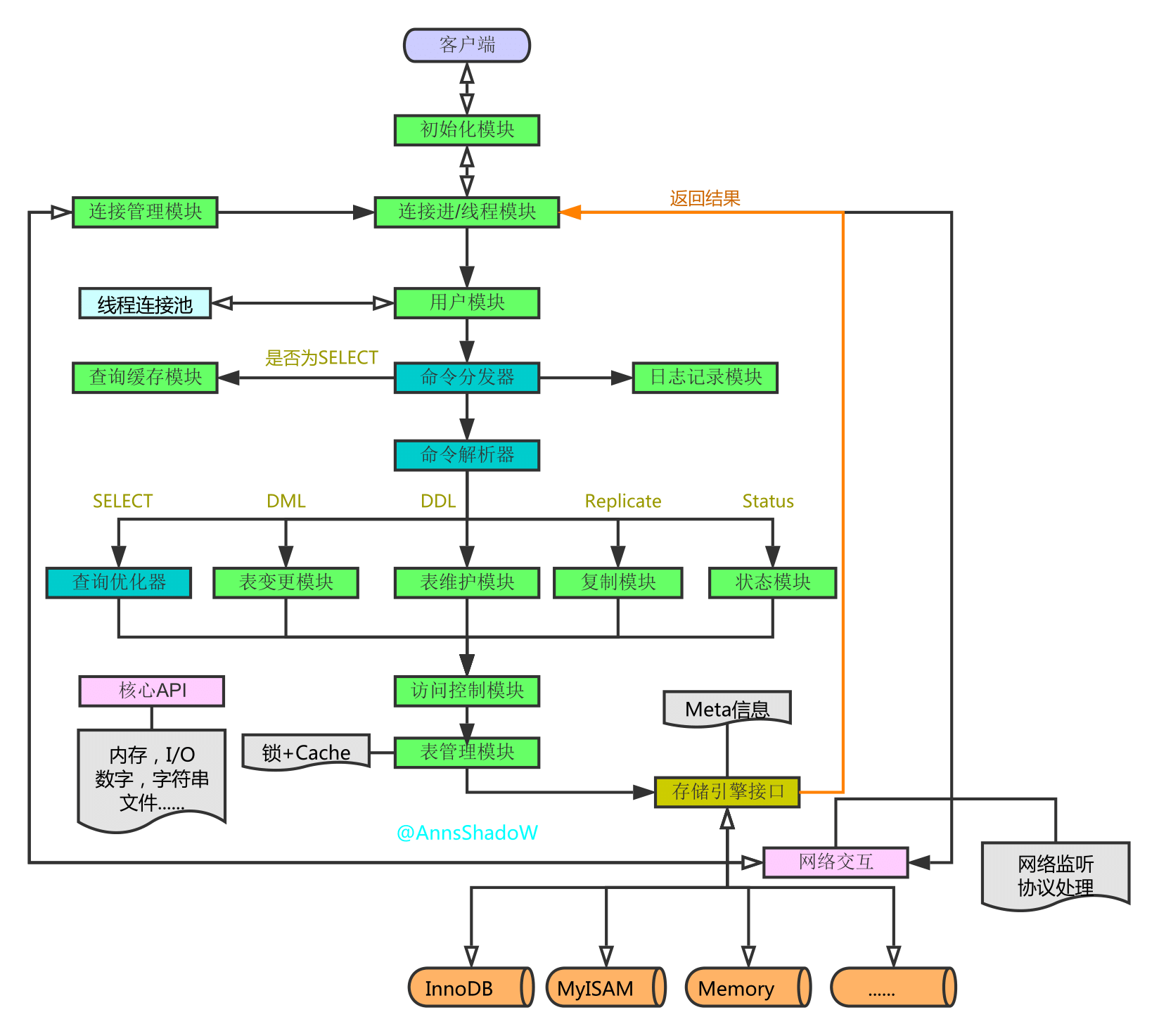
一、MySQL架构总览:
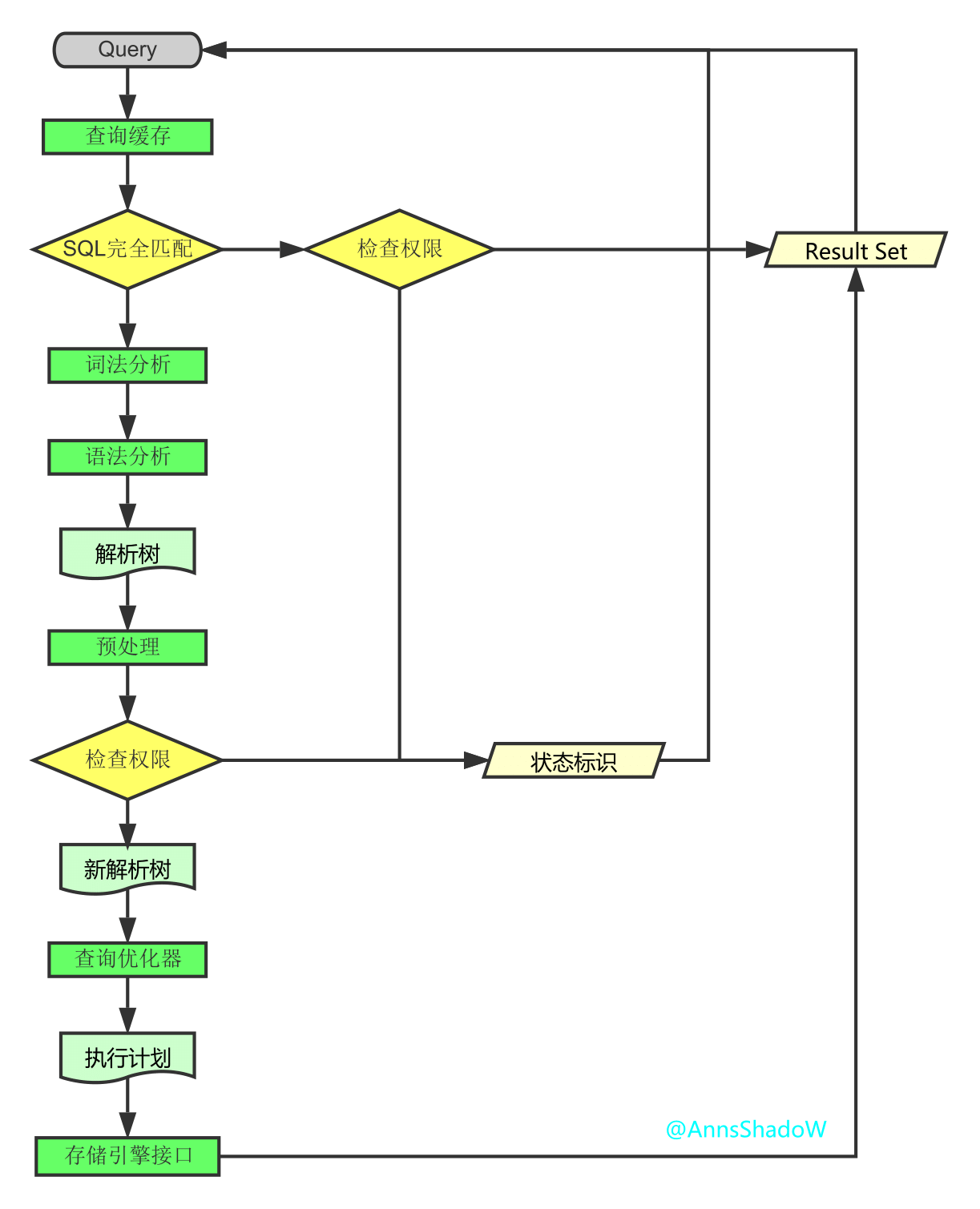
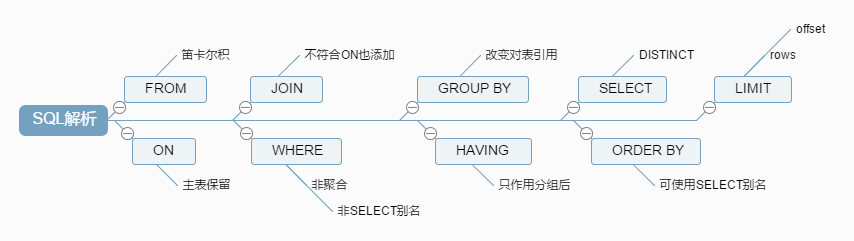
三、SQL解析顺序
SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number >
然而它的执行顺序是这样的
1 FROM <left_table>
2 ON <join_condition>
3 <join_type> JOIN <right_table>
4 WHERE <where_condition>
5 GROUP BY <group_by_list>
6 HAVING <having_condition>
7 SELECT
8 DISTINCT <select_list>
9 ORDER BY <order_by_condition>
10 LIMIT <limit_number>
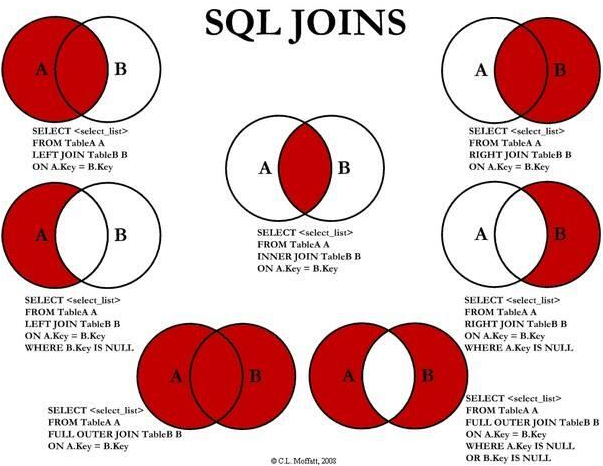
下面从网上找到一张很形象的关于‘SQL JOINS’的解释图,如若侵犯了你的权益,请劳烦告知删除,谢谢。

优化器会自动调整sname, s_code的顺序
s_code字段是一个范围查询,它之后的字段会停止匹配。
ref是找到匹配单独值的所有行 range是范围扫描
建立索引的时候不推荐建立在经常改变的字段
SELECT*,会进行回表扫描,这就多了一次b+树查询,速度必然会慢很多,减少使用select * 就是降低回表带来的损耗。如果不是select * 则是可能会直接在一次B+数的叶子结点中得到结果。
Select * 在一些情况下是会走索引的 如果不走索引就是 where 查询范围过大 导致MySQL 最优选择全表扫描了 并不是Select * 的问题
因为索引保存的是索引字段的原始值,而不是经过函数计算后的值,自然就没办法走索引了。
如果在使用like操作符时,后面的没有使用通用匹配符效果是和=一致的,
在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效 。 这个的优化方式就是 在Or的时候两边都加上索引
首先使用In 不是一定会造成全表扫描的 IN肯定会走索引,但是当IN的取值范围较大时会导致索引失效,走全表扫描
主键索引,其实就是聚簇索引(Clustered Index);
主键索引之外,其他的都称之为非主键索引,非主键索引也被称为二级索引(Secondary Index),或者叫作辅助索引。
覆盖索引是select的数据列只用从索引中就能够取得,不必读取数据行,
对于主键索引和非主键索引,使用的数据结构都是 B+Tree,的区别在于叶子结点中存储的内容不同:
-
主键索引的叶子结点存储的是一行完整的数据。
-
非主键索引的叶子结点存储的则是主键值。
如果是通过非主键索引来查询数据,例如 select * from user where username='javaboy',那么此时需要先搜索 username 这一列索引的 B+Tree,搜索完成后得到主键的值,然后再去搜索主键索引的 B+Tree,就可以获取到一行完整的数据。
对于第二种查询方式而言,一共搜索了两棵 B+Tree,次搜索 B+Tree 拿到主键值后再去搜索主键索引的 B+Tree,这个过程就是所谓的回表。
但是使用非主键索引不一定会导致回表
二级索引查出几条数据就回表几次

Like % 的解释
- %百分号通配符: 表示任何字符出现任意次数(可以是0次).
- _下划线通配符: 表示只能匹配单个字符,不能多也不能少,就是一个字符.
- like操作符: LIKE作用是指示mysql后面的搜索模式是利用通配符而不是直接相等匹配进行比较.
在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效 ,b 是主键,e 是普通列,是走了全表扫描。
优化
这个的优化方式就是 在Or的时候两边都加上索引
就会使用索引 避免全表扫描
首先使用In 不是一定会造成全表扫描的 IN肯定会走索引,但是当IN的取值范围较大时会导致索引失效,走全表扫描
in 在结果集 大于30%的时候索引失效
子查询会走索引吗
答案是会 但是使用不好就不会
覆盖索引:所查询的列出现在索引列中,叶子结点中有对应需要查询的列的数据,
所以不需要回表。 在Extra字段会输出Using index,这就表示当前sql使用了覆盖索引
EXPLAIN SELECT id,name FROM student
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i0wsW5ZE-1672939735408)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1672937852983.png)]
这是因为索引叶子节点存储了主键id,而name也是索引,所以查询为覆盖索引。
如何实现索引覆盖?
- 最常见的方法就是:将被查询的字段,建立到联合索引(如果只有一个字段,普通索引也可以)里去。
为什么在数据库中建议使用自增主键 ?
-
由于二级索引的叶子节点存储的就是主键,所以如果主键占用空间小,意味着二级索引的叶子节点将来占用的空间小
-
自增主键插入的时候比较快,直接插入即可,不会涉及到叶子节点分裂等问题(不需要挪动其他记录);
索引下推 :
select * from table1 where b like '3%' and c = 3
5.6 之前 和 5.6 之后 查询流程会有什么变化
5.6 之前 :
- 先通过 联合索引 查询到 开头为 3 的数据 然后拿到主键(上图中青色块为主键)
- 然后通过主键去主键索引里面去回表查询 二级索引里面查询出来几个 3 开头的就回表几次
5.6 之后
- 先通过 二级索引 查询到开头为 3 的数据 然后 再找到 c = 3 的数据进行过滤 之后拿到主键
- 通过主键进行回表查询
至此SQL的解析之旅就结束了,上图总结一下:
需要建立索引的情形:
-
主键自动建立主键索引(唯一 + 非空)
-
频繁作为查询条件的字段应该创建索引
-
查询中与其他表关联的字段,外键关系建立索引
-
查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
建的复合索引尽量与Order by 一致
- 查询中统计或者分组字段(group by也和索引有关)
不需要建立索引的情形:
-
记录太少的表。
-
经常增删改的表。
-
频繁更新的字段不适合创建索引。
-
Where条件里用不到的字段不创建索引。
-
假如一个表有10万行记录,有一个字段A只有true和false两种值,并且每个值的分布概率大约为50%,那么对A字段建索引一般不会提高数据库的查询速度。索引的选择性是指索引列中不同值的数目与表中记录数的比。如果一个表中有2000条记录,表索引列有1980个不同的值,那么这个索引的选择性就是1980/2000=0.99。一个索引的选择性越接近于1,这个索引的效率就越高。