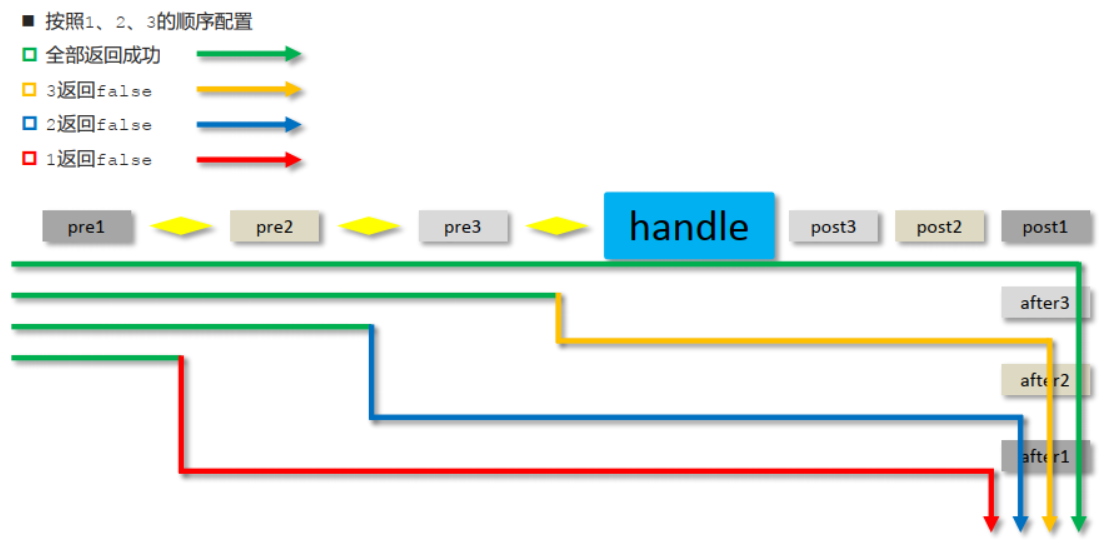
点击下载论文
代码地址
摘要
使用预训练的StyleGAN生成器进行图像编辑已成为面部编辑的强大范例,它提供了对年龄、表情、照明度等的解纠缠控制。然而,该方法不能直接用于视频操作。我们认为主要因素是缺乏对面部位置、面部姿势和局部面部表情的精细和清晰控制。在这项工作中,我们证明,通过跨多个(潜在)空间(即,位置空间、W+空间和S空间)工作并结合跨多个空间的优化结果,使用预训练的StyleGAN确实可以实现这种细粒度控制。基于这一启用组件,我们引入了Video2StyleGAN,它获取目标图像和驱动视频,在目标图像的身份特征上重现驱动视频中的局部和全局的位置和表情。我们在多个具有挑战性的场景中评估我们的方法的有效性,并论证了替代方法明显提高了实验结果。
1、引言
近年来,生成建模取得了巨大的进步。目前,在这一领域有多个强大的框架相互竞争,包括生成对抗网络(GAN)[Karras等人,2020a,2021a]、变分自动编码器(VAE)[Razavi等人,2019]、扩散网络[Ramesh等人,2022]和自回归模型(AR)[Esser等人,2021]。
在本文中,我们关注GAN,特别是StyleGAN架构。这种架构已经开始了一轮研究,探索语义图像编辑框架[Abdal等人,2021b;Patashnik等人,2021;Shen等人,2020年]。这些框架首先将给定的照片嵌入StyleGAN的潜空间,然后使用潜空间操作操作图像。人脸背景下的实例编辑操作是全局参数化图像编辑,以更改姿势、年龄、性别、亮度,或样式变换操作,将图像转换为特定样式的卡通。虽然这些编辑通常是成功的,但获得对给定人脸的精细控制仍然是一个挑战,例如,图像中的面部位置、头部姿势和面部表情。虽然这种细粒度控制对于编辑单个图像是有益的、可选的,但它们是从单个图像和其他视频编辑应用中创建视频的基本构建块。
在我们的工作中,我们着手解决以下研究问题:我们如何将给定的视频嵌入StyleGAN潜空间中,以获得潜空间中的视频上的有意义和解纠缠的表征?我们如何从单个图像创建视频,主要是通过从其他视频传输姿势和表情信息?

图1 精细控制。我们介绍了Video2StyleGAN,一种能够从单个图像生成视频的视频编辑框架。我们的框架可以通过驱动视频将其全局和局部信息传输到参考图像上。我们基于StyleGAN3架构独立编辑旋转、平移、姿势和局部表情,这样的信息也可以从多个视频中获得。
实际上,在StyleGAN中嵌入细粒度控制是多么困难,这有些令人惊讶。然而,所有直接的解决方案要么过正则化,要么欠正则化。过度正则化导致控件被忽略,使得给定的参考图像几乎不改变。欠正则化会导致非常不自然的面部变形和身份丢失。我们解决方案的主要思想是利用不同的潜空间来编码不同类型的信息:位置编码控制面部在图像中的位置(即平移和旋转);W空间控制全局编辑,例如姿势和某些类型的运动;S空间和生成器权重控制面部表情的局部和更详细的编辑。这种分层(代码)结构允许从给定的驱动视频中提取语义信息,并将其传输到给定的照片。见图1。
我们与不使用多分辨率潜空间的视频处理基线方法进行了比较,正如最近未发表的arXiv论文[Alaluf等人2022;Tzaban等人2022]中所做的那样。
这项工作的贡献如下:
- 我们提出了一种面部再现系统,该系统使用预训练的StyleGAN3来传递语音驱动头部的动作和局部动作,从而产生时间一致的视频编辑,而无需对视频进行额外训练。我们的方法可以将这些面部动作从源视频迁移到单个(目标)图像上。
- 我们对StyleGAN3的𝑊 以及𝑆 空间洞察使我们能够在视频中分清局部和全局的差异。特别是,我们可以分别控制眼睛、鼻子和嘴巴的运动。此外,我们可以修改视频中的姿势、旋转和平移参数,而不影响人的身份特征。
- 最后,与以前将单个视频作为输入来修改给定图像的面部属性的工作不同,我们直接从多个视频中提取局部和全局变化以重新生成给定图像。例如,我们能够修改一个视频中的眼睛、鼻子和嘴巴等局部特征,其他全局特征比如姿势、旋转和平移等来自其他视频。
2、相关工作
2.1、目前最好的GANs
最近随着对损失函数、架构和高质量数据集利用能力的提高【Karras等人2021b】提高了生成对抗性网络(GAN)的生成质量和多样性【Goodfellow等人2014;Radford等人2015】。由于这些发展,Karras等人发表了一系列架构[Karras等人,2017,2020a,2021a,b,2020b],从而在高质量数据集(如FFHQ[Karras et al.2021b]、AFHQ[Coi et al.2020]和LSUN对象[Yu et al.2015])上获得了最先进的结果。在这些GANs学习到的潜空间上已经探索了去执行各种任务。例如图像编辑[Abdal等人2019、2021b;Patashnik等人2021;Shen等人2020]或无监督的密集对应计算[Peebles等人2021]。虽然最近的3D GAN沿着3D几何方向在生成高分辨率、多视角、一致性图像方面表现出了良好的前景[Chan等人,2021;Deng等人,2021;Or-El等人,2021],但其质量仍落后于2D GAN,且最好方法的编码仍不可用。在这项工作中,我们基于目前最好的生成器StyleGAN3 [Karras et al. 2021a]。StylGAN3就生成的图像而言表现出良好的平移和旋转特性。这些特性吸引了对全局和局部视频编辑的研究。
2.2、使用GANs进行图像投影和编辑
基于GAN的图像和视频编辑需要两个构建块。首先,需要将真实图像投射到GAN的潜空间中。在StyleGAN领域中,Image2StyleGAN[Abdal等人2019]使用扩展的𝑊 + 潜空间使用优化方法将真实图像投影到StyleGAN潜空间中。着眼于改善重建编辑质量权衡,其他方法包括II2S[Zhu等人2020a]和PIE[Tewari等人2020b]提出了额外的正则化器,以确保优化收敛到潜空间中的高密度区域。而其他作品如IDInvert[Zhu et al.2020b]、pSp[Richardson et al.2020]、e4e[Tov et al.2021]和Restyle[Alaluf et al.2041a]则使用编码器和身份保持损失函数来维护嵌入的语义。最近的两项工作,PTI[Roich等人,2021]和HyperStyle[Alaluf等人,2021b]分别通过优化过程和超参数网络来修改生成器权重。这种方法提高了投影图像的重建质量。
其次,需要操纵潜码以实现所需的编辑。对于StyleGAN架构,InterFaceGAN[Shen et al.2020]、GANSpace[Härkönen et al.2022]、StyleFlow[Abdal et al.2021b]和StyleRig[Tewari et al.2020a]提出在𝑊 和𝑊 + 空间下进行线性和非线性编辑。基于CLIP [Radford et al. 2021]的图像编辑[Abdal et al. 2021a;Gal et al. 2021;Patashnik等人。2021]和域转移[Chong和Forsyth 2021;Zhu et al. 2022]还研究了StyleGAN和CLIP潜空间,将基于StyleGAN的编辑应用于不同的任务。
2.3、基于GAN的视频生成与编辑
基于GAN的视频生成和编辑方法[Menapace et al.2021;Munoz et al.2020;Tulyakov et al.2018;Wang et al.2021]在128×128、256×256和512×512空间分辨率上显示出显著的结果。由于StyleGAN具有较高的分辨率和分离的潜空间,该领域的多项工作要么使用预处理的StyleGAN生成器构建视频生成框架[Alaluf等人,2022年;Fox等人,2021;Tzaban等人,2022],要么通过在StyleGAN的顶部上训练其他模块并使用视频数据训练网络来重新定义问题[Sko rokhodov等人,2021;Tian等人,2021;Wang等人,2022]。其中包括基于 StyleGAN的𝑊 +空间操作的StyleVideoGAN[Fox等人,2021]。与预训练的基于潜空间的方法相关,Third Time’s the Charm [Alaluf et al. 2022] and Stitch it in Time [Tzaban et al. 2022] 使用StyleGAN的𝑊 和𝑆 空间来编辑嵌入式视频。请注意,这些方法与我们的方法是同时进行的,并且仅在本次提交时在arXiv上可用。此外,这些方法与我们的方法解决的任务不同,这些方法专注于在StyleGAN的不同空间编辑嵌入视频。另一组作品如StyleGAN-V[Skorokhodov等人,2021]和LIA[Wang等人,2022]在视频中重新训练修改后的StyleGAN架构。注意,我们的方法是基于StyleGAN3潜空间的方法,该方法在不需要额外视频训练的图像上训练。LIA也在与我们不同的数据集上进行训练,无法通过从不同的视频中获取信息来控制生成的图像的各个分量。也注意到StyleVideoGAN, Third Time’s the Charm, 和 Stitch it in Time使用W+或者修改生成器的权重将视频嵌入到潜空间中。为了与这些方法进行比较,我们在第4节中基于这些方法构建了一个基线,其中𝑊 + 空间用于编码视频的全局和局部分量。
3、方法
给定参考图像 𝐼 𝑟 𝑒 𝑓 𝐼_{𝑟𝑒𝑓} Iref 和驱动视频的帧𝐷, 我们的目标是生成最终的视频帧序列 𝑉 = : { 𝑉 𝑗 } 𝑉 =: \{𝑉_𝑗 \} V=:{Vj} 这个视频帧序列会产生一个从驱动视频的帧𝐷中包括局部和全局的身份 𝐼 𝑟 𝑒 𝑓 𝐼_{𝑟𝑒𝑓} Iref、姿势和表情。可选地,一个共同驱动视频 𝐶 𝐷 : = { 𝐶 𝐷 𝑗 } 𝐶𝐷 := \{𝐶𝐷_𝑗 \} CD:={CDj}可以作为输入提供。我们基于这些参数开发了一个框架,以产生一个驱动视频的解纠缠表征,这样我们就能够对其全局和局部属性进行编码,并分别控制它们以产生输出视频𝑉.
3.1、概述
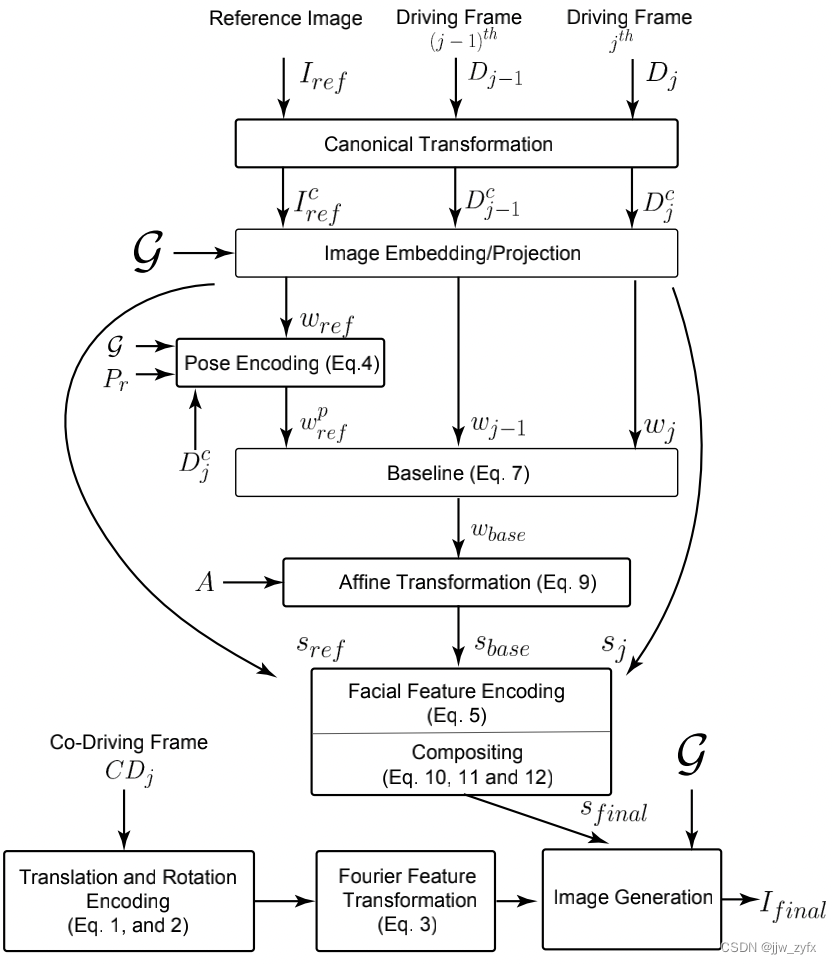
图2 Video2StyleGAN 流程。Video2StyleGAN方法的流程图。每个框表示使用我们的方法的局部或全局编码和编辑模块。详见第3节。
我们的框架(见图2)是基于对StyleGAN3相关的两个空间的分析,即𝑊 + 和𝑆 空间,使用单一(身份)的图像再现语音驱动头部动作生成。设𝑤+ ∈ 𝑊 + 和𝑠 ∈ 𝑆 是任何输入图像的相应空间中的变量。我们回顾S空间中的参数是源自𝑤+使用𝑠 := 𝐴(𝑤+)编码的。其中𝐴 是StyleGAN3中的仿射变换层[Karras等人2021a]。设
G
\mathcal G
G是预训练的StyleGAN3生成器。除了这两个潜空间之外,我们注意到StyleGAN3的第一层
G
\mathcal G
G产生了可解释的傅里叶特征,通过平移和旋转参数进行参数化。我们将此函数表示为
𝐹
𝑓
𝐹_𝑓
Ff .
先前的研究表明𝑊 + 空间[Abdal等人2021b]编码对象的全局属性和语义;而𝑆 空间[Wu等人2020]更适合于对StyleGAN生成的图像中的局部变化进行编码。基于这一观察,我们在我们的框架中使用了这两个空间。具体来说,为了分别控制生成的视频中的局部和全局变化,我们将这些组件分类为局部或全局编辑技术。注意,框架的一些组件包括这两个空间的组合,以实现渴望的属性再现(第3.5节)。
为了将给定的驱动视频编码到StyleGAN3的潜空间中,我们首先将视频的各个帧投影到StyleGAN3潜空间中。我们使用最先进的投影方法ReStyle[Alaluf等人2021a]将视频和参考图像的标准帧(即,在基于FFHQ的转换之后)投影到 StyleGAN3的𝑊 + 空间
(
𝑊
+
:
=
{
𝑤
+
∈
R
18
×
512
}
)
(𝑊 + := \{𝑤+ ∈ \Bbb R^{18×512}\})
(W+:={w+∈R18×512})。设
I
r
e
f
c
I^c_{ref}
Irefc代表参考图像、
w
r
e
f
w_{ref}
wref代表相应的w+编码。在下面的小节中,我们首先介绍了视频编辑框架的构建块,然后将它们结合起来生成Video2StyleGAN,这是一个可控的视频生成框架。
3.2、标准变换

图3 标准变换。给定带有旋转和平移的驱动帧的一个驱动视频(左),我们的框架可以将这些信息转换到新的参考图像上。顶行:参考图像。底行:变换后的图像。
给定一个视频来定义面部在帧内的位置,我们利用StyleGAN3架构的平移和旋转不变性特性来编码语音驱动头部动作生成的旋转和平移。我们记得StyleGAN3[Kar-ras等人2021a]的傅里叶特征可以被转换,以在输出图像上产生相同效果。我们定义一个元组
(
𝑡
𝑥
,
𝑡
𝑦
,
𝑟
)
,
其中
𝑡
𝑥
和
𝑡
𝑦
(𝑡_𝑥, 𝑡_𝑦, 𝑟), 其中𝑡_𝑥 和𝑡_𝑦
(tx,ty,r),其中tx和ty是水平和垂直平移参数,以及𝑟 是旋转角度。首先,为了确定FFHQ中存在的规范位置的平移和旋转变化[Karras等人2019],我们在视频的每个帧上使用最先进的标志检测器[ageitgey 2018]来确定特定帧
(
𝑡
𝑥
,
𝑡
𝑦
,
𝑟
)
(𝑡_𝑥, 𝑡_𝑦, 𝑟)
(tx,ty,r)的参数。对于每一帧,我们计算连接眼睛和嘴巴位置标志的平均值的向量。我们使用它们来计算标准垂直向量和当前面部方向之间的相对角度,我们使用它来编码头部的旋转。通常,让
𝑒
𝑙
和
𝑒
𝑟
𝑒_𝑙 和𝑒_𝑟
el和er是眼睛标志(分别为左和右),
𝑚
𝑙
𝑚_𝑙
ml是标志检测器
𝐿
𝑑
𝐿_𝑑
Ld预测的嘴部标志. 然后
𝑒
⃗
:
=
0.5
(
E
(
𝑒
𝑙
)
+
E
(
𝑒
𝑟
)
)
a
n
d
𝑣
⃗
:
=
E
(
𝑚
𝑙
)
−
𝑒
⃗
\vec{𝑒} := 0.5(\Bbb E(𝑒_𝑙) +\Bbb E(𝑒_𝑟)) \quad and\quad \vec{𝑣} := \Bbb E(𝑚_𝑙) − \vec{𝑒}
e:=0.5(E(el)+E(er))andv:=E(ml)−e和
𝑟
:
=
𝑑
𝑐
𝑜
𝑠
(
𝑢
⃗
,
𝑣
⃗
)
,
(
1
)
𝑟 := 𝑑_{𝑐𝑜𝑠}( \vec{𝑢},\vec{𝑣}), \quad\quad\quad\quad\quad\quad(1)
r:=dcos(u,v),(1)
其中
E
表示平均值,
𝑑
𝑐
𝑜
𝑠
其中\Bbb E表示平均值,𝑑_{𝑐𝑜𝑠}
其中E表示平均值,dcos是余弦相似度函数,
𝑢
⃗
\vec{𝑢}
u是向上向量。类似地,根据FFHQ变换,平移参数为:
t
⃗
:
=
𝑒
⃗
−
𝑒
⃗
′
,
(
2
)
\vec{t} := \vec{𝑒}− \vec{𝑒}^\prime, (2)
t:=e−e′,(2)其中
𝑒
⃗
′
\vec{𝑒}^\prime
e′是经过规范FFHQ变换的图像的中点,
t
⃗
是表示
𝑡
𝑥
和
𝑡
𝑦
\vec{t}是表示𝑡_𝑥和𝑡_𝑦
t是表示tx和ty的列向量。然后可以对傅里叶特征
𝐹
𝑓
𝐹_𝑓
Ff进行变换,以在给定图像上产生所需的旋转和平移效果,如下:
F
f
′
(
t
x
,
t
y
,
r
)
:
=
F
f
(
τ
(
𝑡
𝑥
,
𝑡
𝑦
,
𝑟
)
)
(
3
)
F^\prime_f(t_x, t_y, r) := F_f (\tau(𝑡_𝑥, 𝑡_𝑦, 𝑟))\quad\quad\quad\quad\quad(3)
Ff′(tx,ty,r):=Ff(τ(tx,ty,r))(3)其中
τ
\tau
τ表示变换,看图3
然而,这些变换[Alaluf等人,2022年]在整个帧中并不平滑。因此,为了平滑异常,我们将卷积操作应用于整个时域的参数序列。根据经验,我们找到了一个核大小为3或更大的均值滤波器,以在应用变换后产生平滑一致的视频。注意,这些参数也可以来自于另一个共同驱动的视频𝐶𝐷, 除了驱动视频𝐷, 并且应用于给定图像而不影响身份。例如,我们可以从第一个驱动视频中应用以下章节中提到的步骤,并从第二个共同驱动视频中使用旋转和平移效果。
3.3、全局位置编码
接下来,我们对驱动视频中的面部姿势进行编码。我们认为这也是视频编辑框架工作的一种全局变化。StyleGAN中的姿势变化在很大程度上与添加新的细节有关——拉伸、挤压,以及将眼睛和嘴的视图转换到目标位置。因此,我们使用StyleGAN3𝑊 +空间来编码这样的全局信息。给定StyleGAN3架构的分层结构和对潜空间的语义理解[Abdal等人2021b],我们限制StyleGAN3潜空间的前8层(共16层)对姿势信息进行编码。首先,我们观察到,当我们通过传输驱动帧 (𝑤+ ∈ 𝑊 +)的𝑤+编码的前两层来渲染给定图像。它拉伸了面部区域和眼睛,但是嘴和鼻子的位置保持不变,使得输出的面部不真实。然而转移前八层会以身份丢失为代价做出看似合理的姿势改变(参见补充视频)。
为了避免这种情况,我们设置了一个优化来匹配姿势信息。 具体来说,我们设置了一个目标,以优化给定图像的姿态(即,偏离、俯仰和侧倾),以匹配驱动视频的姿态。我们分别提出了两个损失函数来确保姿态匹配和身份保留。为了确保姿势保持,我们使用姿势回归模型[cunjian 2019],该模型在给定有效的视频帧的情况下,输出偏离、俯仰和横滚。为了确保身份保留,我们应用额外的损失来确保面部和身份的特征被保留。后一种损失确保来自前8层的优化潜空间保持尽可能接近给定图像的原始潜空间。请注意,为了编辑照片中的真实人脸,我们使用基于PTI的方法[Roich等人,2021]投影图像。在这种情况下,有多种方法可以优化代码,我们观察到,对于姿态,使用原始生成器优化代码,然后使用经过PTI训练的生成器填充细节效果最佳。优化如下:
𝑤
𝑟
𝑒
𝑓
𝑝
:
=
a
r
g
m
i
n
𝑤
𝑟
𝑒
𝑓
1
:
8
𝐿
𝑚
𝑠
𝑒
(
𝑃
𝑟
(
𝐺
(
𝑤
𝑟
𝑒
𝑓
)
)
,
𝑃
𝑟
(
𝐷
𝑗
)
)
⏟
p
o
s
e
p
r
e
s
e
r
v
a
t
i
o
n
+
𝐿
1
(
𝑤
𝑟
𝑒
𝑓
1
:
8
,
𝑤
𝑟
𝑒
𝑓
𝑝
1
:
8
)
⏟
i
d
e
n
t
i
t
y
p
r
e
s
e
r
v
a
t
i
o
n
,
(
4
)
𝑤^𝑝_{𝑟𝑒𝑓} := \underset{𝑤^{1:8}_{𝑟𝑒𝑓}}{arg\; min}\underbrace{𝐿_{𝑚𝑠𝑒}(𝑃_𝑟 (𝐺(𝑤_{𝑟𝑒𝑓} )), 𝑃_𝑟 (𝐷_𝑗))}_{pose \; preservation}+ \underbrace{𝐿_1(𝑤^{1:8}_{𝑟𝑒𝑓} ,𝑤^{𝑝1:8}_{𝑟𝑒𝑓})}_{identity \; preservation},\quad\quad\quad\quad\quad(4)
wrefp:=wref1:8argminposepreservation
Lmse(Pr(G(wref)),Pr(Dj))+identitypreservation
L1(wref1:8,wrefp1:8),(4)其中
𝑤
𝑟
𝑒
𝑓
1
:
8
𝑤^{1:8}_{𝑟𝑒𝑓}
wref1:8表示StyleGAN3前八层参考图像的𝑤+代码,
𝐿
𝑚
𝑠
𝑒
𝐿_{𝑚𝑠𝑒}
Lmse表示𝑀𝑆𝐸损失,
𝑃
𝑟
𝑃_𝑟
Pr是姿势回归模型[cunjian 2019]的输出。

图4 全局姿势编辑。给定一个参考图像和一个驱动帧,我们匹配姿态和局部信息。每行显示一个身份标识(参考图像),并对顶行(驱动帧)进行相应的编辑。
在图4中,我们显示了驱动视频中随机帧的姿态匹配结果。该图显示了在驱动视频中的给定姿势场景下对参考图像进行的姿势改变的不同结果。
3.4、局部面部特征编辑
在对视频中的全局信息(即旋转、平移和语音驱动头部姿势)进行编码之后,下一步是关注局部信息。我们确定了三个语义部分,即眼睛、嘴巴和鼻子,它们对语音驱动头部动作生成的驱动视频中的局部变化负责。注意,表情的变化通常会导致这些语义区域之间的耦合变化。为了捕捉面部这些语义部分的局部差异,我们求助于StyleGAN3架构的𝑆空间中的分析。为了欣赏StyleGAN3中𝑆空间的解纠缠特性,我们鼓励读者参考补充材料中显示𝑆空间的局部属性和相应的特征映射的UI应用程序的视频,该视频可以编辑。为了演示,我们手动更改StyleGAN3的给定层的给定通道的𝑆参数,以观察最终图像的预期效果。现在,我们将此观察结果用于操作𝑆空间中的参数的自动过程。
为了自动识别影响语义区域动作的特征映射和相应的𝑠∈𝑆参数,我们将这些层中的激活特征与使用分割网络获得的语义分割区域相匹配。我们使用语义部分分割网络BiSeNet [Yu等人。2018],在CELEBA-HQ [Karras等人。2017]数据集上进行训练,以确定这些层。首先,给定一组图像及其从StyleGAN3中提取的特征映射,我们首先使用BiSeNet计算图像的分割映射。其次,我们利用特征映射的每个特征通道的最小-最大归一化计算归一化映射。第三,为了匹配这些掩码的空间大小,我们使用双线性插值对这些掩码进行上采样以匹配目标掩码的空间大小。为了将这些归一化的特征转换为硬掩码,我们将这些映射阈值设置为二进制。最后,我们通过与这些二进制掩码进行比较,计算出源自图像集的三个语义组件的𝐼𝑂𝑈分数。

图5 提取局部脸部特征。一个给定的图像和一些由我们的框架的局部面部特征编码提取的归一化特征映射(见Eq 6)。上面一行显示的是关注眼睛的特征图,中间一行显示的是关注鼻子的特征图,下面一行显示的是关注嘴巴区域的图像。我们将潜空间优化限制到负责相应编辑的发现通道上。
设𝑆𝑒𝑔𝑁𝑒𝑡为语义部分分割网络(例如BiSeNet),
𝑀
𝑓
𝑔
𝑀_{𝑓𝑔}
Mfg为考虑的语义组件,
𝑀
𝑏
𝑔
𝑀_{𝑏𝑔}
Mbg为𝑆𝑒𝑔𝑁𝑒𝑡(
𝐼
𝑟
𝑒
𝑓
𝑐
𝐼^𝑐_{𝑟𝑒𝑓}
Irefc)给出的包括背景在内的其他语义组件。对特征图进行最小-最大归一化、上采样和二值化后,设
𝐶
𝑙
𝐶_𝑙
Cl为StyleGAN3 𝑙层的特征图,得到:
𝐼
𝑂
𝑈
+
:
=
𝐼
𝑂
𝑈
(
𝑀
𝑓
𝑔
,
𝑆
𝑒
𝑔
𝑁
𝑒
𝑡
(
𝐶
𝑙
)
)
a
n
d
𝐼𝑂𝑈^+ := 𝐼𝑂𝑈 (𝑀_{𝑓𝑔}, 𝑆𝑒𝑔𝑁𝑒𝑡(𝐶_𝑙)) \quad\quad and
IOU+:=IOU(Mfg,SegNet(Cl))and
𝐼
𝑂
𝑈
−
:
=
𝐼
𝑂
𝑈
(
𝑀
𝑏
𝑔
,
𝑆
𝑒
𝑔
𝑁
𝑒
𝑡
(
𝐶
𝑙
)
)
.
(
5
)
𝐼𝑂𝑈^-:= 𝐼𝑂𝑈 (𝑀_{𝑏𝑔}, 𝑆𝑒𝑔𝑁𝑒𝑡(𝐶_𝑙)). \quad\quad\quad\quad\quad\quad\quad (5)
IOU−:=IOU(Mbg,SegNet(Cl)).(5)基于正的
𝐼
𝑂
𝑈
+
𝐼𝑂𝑈^+
IOU+(眼睛、鼻子和嘴巴)和负的
𝐼
𝑂
𝑈
−
𝐼𝑂𝑈^-
IOU−(背景和不包含给定语义部分的组件)𝐼𝑂𝑈-s,我们选择这些映射的一个子集
(
X
𝑚
:
=
𝑥
∈
R
102
4
2
)
(X_𝑚:={𝑥∈\Bbb R 1024^2})
(Xm:=x∈R10242)和相应的𝑠参数
(
X
𝑠
:
=
𝑥
∈
R
)
(X_𝑠:={𝑥∈\Bbb R})
(Xs:=x∈R)作为我们的局部模型,用于操作语义部分。在形式上,
𝐶
𝑙
∈
X
𝑚
,
i
f
𝐼
𝑂
𝑈
+
≥
𝑡
𝑓
𝑔
a
n
d
𝐼
𝑂
𝑈
≥
𝑡
𝑏
𝑔
(
6
)
𝐶_𝑙 ∈ X_𝑚, \quad if \quad𝐼𝑂𝑈^+ ≥ 𝑡_{𝑓𝑔} \;and \; 𝐼𝑂𝑈 ≥ 𝑡_{𝑏𝑔}\quad\quad\quad\quad\quad (6)
Cl∈Xm,ifIOU+≥tfgandIOU≥tbg(6)其中
𝑡
𝑓
𝑔
和
𝑡
𝑏
𝑔
𝑡_{𝑓𝑔}和𝑡_{𝑏𝑔}
tfg和tbg为阈值。注意
X
𝑠
⊂
𝑆
X_𝑠\subset 𝑆
Xs⊂S。图5中,我们展示了
X
𝑚
X_𝑚
Xm中提取的特征映射的一些示例,仅关注面部的特定语义部分。
3.5、视频编辑基线

图6 与基线方法的比较。在每个子图中,第一列显示驱动帧,第二列显示共驱动帧,第三列显示基线方法的结果,最后一列显示我们的结果。请看补充视频。
在我们的实验中,我们发现只需对上述全局和局部组件进行编码,就可以使用StyleGAN3生成器执行真实的视频编辑。我们观察到,即使投影驱动视频的𝑤+代码可以编码不能直接用于视频编辑的非语义组件,但它携带的其他重要信息在转移到上述𝑆空间分析时丢失。具体来说,在图6中,我们简单地计算驱动视频的连续帧中的差分向量,并将这些变换应用于表示给定图像的给定潜表征上。在形式上,
𝑤
𝑏
𝑎
𝑠
𝑒
=
𝑤
𝑟
𝑒
𝑓
𝑝
+
(
𝑤
𝑗
−
1
−
𝑤
𝑗
)
(
7
)
𝑤_{𝑏𝑎𝑠𝑒} = 𝑤^𝑝_{𝑟𝑒𝑓} + (𝑤_{𝑗-1}-𝑤_𝑗)\quad\quad\quad\quad\quad (7)
wbase=wrefp+(wj−1−wj)(7)其中
𝑤
𝑗
−
1
𝑤_{𝑗-1}
wj−1为驱动视频
𝐷
𝑗
−
1
𝐷_{𝑗-1}
Dj−1对应的𝑤+代码,
𝑤
𝑗
𝑤_𝑗
wj为驱动视频
𝐷
𝑗
𝐷_𝑗
Dj对应的𝑤+代码。
注意使用这种幼稚的技术进行视频编辑的人的身份的伪影和损失(见补充视频)。我们将此作为我们方法的基线。尽管如此,我们观察到𝑤+代码,尽管有一些不受欢迎的效果,却捕获了一些额外的语义,使面部运动与驱动视频一致。例如,我们观察到非局部的影响,如在嘴巴、眼睛区域和下巴的运动中对脸颊的拉伸和挤压。(语义)部分之间的这种耦合不能仅通过局部分析来捕获。
3.6、Video2StyleGAN方法
现在我们将所有这些组件组合在一起来呈现我们的Video2StyleGAN(参见图2)。注意,在我们的框架中,组件可以由多个视频分别控制和驱动(参见第4节)。首先,我们通过使用the Translation and Rotation Encoding(第3.2节)计算驱动或共同驱动视频的旋转和平移参数来规范化输入视频,并在给定图像上使用提取的变换。或者,我们可以省略这些更改,以保持给定图像中的原始参数的真实性。
然后,我们使用Pose Encoding (章节3.3)通过驱动或共同驱动视频执行姿态变化。同样,我们可以省略这些变化,即使用给定图像的姿态,而不将其与驱动帧匹配。
最后,我们结合𝑊+空间(第3.4节)和𝑆空间分析(第3.5节)的组件来实现对视频生成的细粒度控制。其中,局部变化程度可以通过
𝑠
𝑟
𝑒
𝑓
𝑝
∈
X
𝑠
𝑠^𝑝_{𝑟𝑒𝑓}∈\mathcal X_𝑠
srefp∈Xs,结合基于𝑊+空间分析的方法进行修改。在实践中,我们认为𝑊+代码层的3-7层与𝑆空间结合时能产生最佳结果。设
X
𝑜
𝑟
𝑖
𝑔
:
=
{
𝑥
∈
R
512
}
\mathcal X_{𝑜𝑟𝑖𝑔}:=\{𝑥∈\Bbb R^{512}\}
Xorig:={x∈R512}是给定图像使用3-7层的原始𝑤+编码。类似地,我们将从Eq 7中获得的另一组𝑤+代码表示为
X
𝑤
:
=
{
𝑥
∈
R
512
}
\mathcal X_𝑤:=\{𝑥∈\Bbb R^{512}\}
Xw:={x∈R512}。设
𝐴
𝑙
𝐴_𝑙
Al为StyleGAN3生成器的𝑙层的仿射函数。然后,我们计算原始的𝑠参数为:
X
𝑜
𝑟
𝑖
𝑔
𝑠
:
=
⋃
𝑖
=
3
7
𝐴
𝑙
(
𝑤
𝑙
)
,
(
8
)
\mathcal X_{𝑜𝑟𝑖𝑔𝑠} := \bigcup^7_{𝑖=3}𝐴_𝑙 (𝑤_𝑙), \quad\quad\quad\quad\quad(8)
Xorigs:=i=3⋃7Al(wl),(8)其中
𝑤
𝑙
∈
X
𝑜
𝑟
𝑖
𝑔
𝑤_𝑙∈X_{𝑜𝑟𝑖𝑔}
wl∈Xorig。类似地,我们计算编辑帧的𝑠参数贡献值为:
X
𝑤
𝑠
:
=
⋃
𝑖
=
3
7
𝐴
𝑙
(
𝑤
𝑙
′
)
,
(
9
)
\mathcal X_{𝑤𝑠} := \bigcup^7_{𝑖=3}𝐴_𝑙 (𝑤^′_𝑙 ), \quad\quad\quad\quad\quad(9)
Xws:=i=3⋃7Al(wl′),(9)其中
𝑤
𝑙
′
∈
X
𝑤
𝑤^′_𝑙 ∈ \mathcal X_𝑤
wl′∈Xw
我们通过添加给定图像(
X
s
\mathcal X_s
Xs,见3.3节)的计算𝑠参数和驱动视频(
X
𝑠
𝑑
\mathcal X_{𝑠𝑑}
Xsd)的给定帧来编码局部变化。形式上,设
𝑠
𝑟
𝑒
𝑓
𝑝
∈
X
s
,设
𝑠
𝑗
𝑝
∈
X
s
d
𝑠^𝑝_{𝑟𝑒𝑓}∈\mathcal X_s,设𝑠^𝑝_𝑗∈\mathcal X_{sd}
srefp∈Xs,设sjp∈Xsd为给定集合中的𝑠参数,则运算为:
s
𝑙
𝑜
𝑐
𝑎
𝑙
=
α
s
r
e
f
p
+
β
𝑠
𝑗
𝑝
.
(
10
)
s_{𝑙𝑜𝑐𝑎𝑙} = \alpha s^p_{ref} + \beta𝑠^𝑝_𝑗. \quad\quad\quad\quad\quad(10)
slocal=αsrefp+βsjp.(10)两者结合我们定义操作
𝑠
𝑓
𝑖
𝑛
𝑎
𝑙
=
𝑠
𝑙
𝑜
𝑐
𝑎
𝑙
+
γ
𝑠
𝑏
𝑎
𝑠
𝑒
𝑝
,
(
11
)
𝑠_{𝑓𝑖𝑛𝑎𝑙} = 𝑠_{𝑙𝑜𝑐𝑎𝑙} + \gamma𝑠^𝑝 _{𝑏𝑎𝑠𝑒}, \quad\quad\quad\quad\quad(11)
sfinal=slocal+γsbasep,(11)其中
𝑠
𝑏
𝑎
𝑠
𝑒
𝑝
∈
X
𝑤
𝑠
𝑠^𝑝_{𝑏𝑎𝑠𝑒}∈\mathcal X_{𝑤𝑠}
sbasep∈Xws,使其与集合
X
𝑠
\mathcal X_𝑠
Xs中计算的𝑠参数位置相匹配。𝑠的其他参数:
𝑠
𝑓
𝑖
𝑛
𝑎
𝑙
=
ζ
𝑠
𝑟
𝑒
𝑓
𝑞
+
(
1
−
ζ
)
𝑠
𝑏
𝑎
𝑠
𝑒
𝑞
(
12
)
𝑠_{𝑓𝑖𝑛𝑎𝑙} = \zeta𝑠^𝑞_{𝑟𝑒𝑓} + (1- \zeta)𝑠^𝑞_{𝑏𝑎𝑠𝑒}\quad\quad\quad\quad\quad (12)
sfinal=ζsrefq+(1−ζ)sbaseq(12)在
𝑠
𝑟
𝑒
𝑓
𝑞
∈
X
𝑜
𝑟
𝑖
𝑔
𝑠
和
𝑠
𝑏
𝑎
𝑠
𝑒
𝑞
∈
X
𝑤
𝑠
𝑠^𝑞_{𝑟𝑒𝑓}∈\mathcal X_{𝑜𝑟𝑖𝑔𝑠}和𝑠^𝑞_{𝑏𝑎𝑠𝑒}∈\mathcal X_{𝑤𝑠}
srefq∈Xorigs和sbaseq∈Xws。请注意,𝛼,𝛽,𝛾,𝜁可以单独控制,以产生理想的动画。
4、结果(略)
5、结论
我们介绍了一个使用StyleGAN3生成器对单个图像进行细粒度控制的框架。特别是,该框架在编辑给定驱动视频的单个图像时非常有用。这个问题非常具有挑战性,因为现有的方法要么对驱动视频进行过拟合,要么对驱动视频进行欠拟合。我们的实验在附带的视频中产生了定性结果,并使用三种不同的指标产生了定量结果,以证明在目前的技术水平上有了明显的改进,包括最近的arXiv论文。我们的工作也有一些局限性。我们的方法是基于图像的,我们没有重建一个完整的3D模型。这意味着我们用3D和视点一致性来换取更高的视觉细节质量。此外,我们的算法目前只考虑人脸模型。要想处理完整的人体,还需要进一步的扩展。在未来的工作中,我们希望探索使用其他生成模型(如自回归transformer和扩散模型)进行视频编辑。我们还建议将文本驱动的视频编辑作为未来工作的可能方向。




![[Leetcode] 二叉树的遍历](https://img-blog.csdnimg.cn/img_convert/f793105ca0ebd6224c6f50d2dc3f981c.png)