一、理论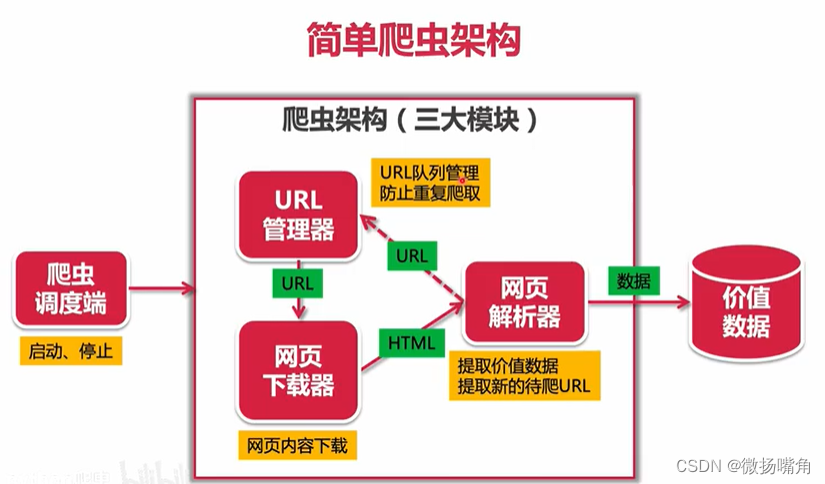
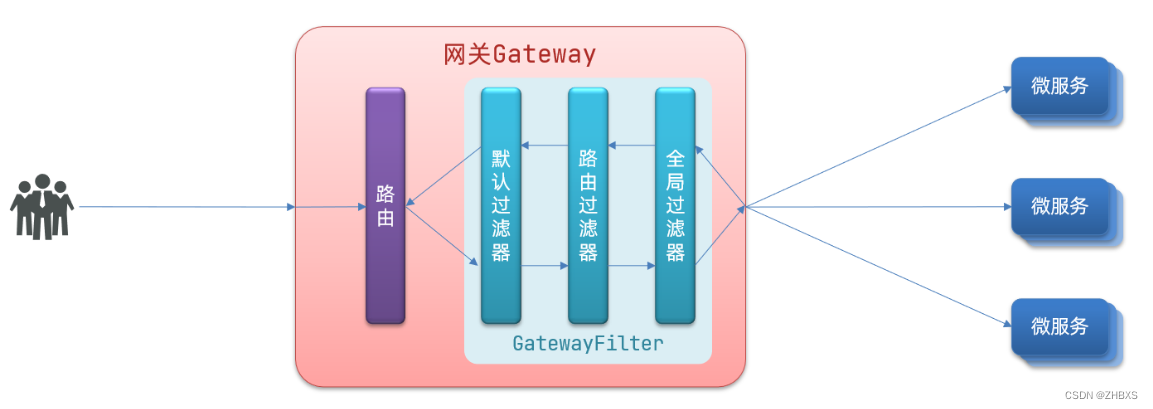
(1)URL管理器:网页之间的链接很复杂,a指向b,b指向a,如果不对其进行管理则可能导致重复爬取、循环爬取,因此单独用该模块进行管理。URL管理器有两个功能,分别是URL队列管理(url优先级,按先后顺序爬取,按网页权重爬取),防止重复、循环爬取。
(2)网页下载器:URL管理器输出的是URL,将其传给网页下载器,网页下载器使用python自动实现网页内容的下载,下载好后输出的是html,即网页的内容。注意:网页下载器还需解决网页登陆(有些网页是动态加载的)、拒绝下载的问题。
(3)网页解析器:网页下载器输出的内容传给网页解析器,网页解析器还可补充新的url(未爬取过的)给URL管理器。可对网页解析器 的数据存储步骤进行扩展,将其存到指定数据库中。
二、环境安装
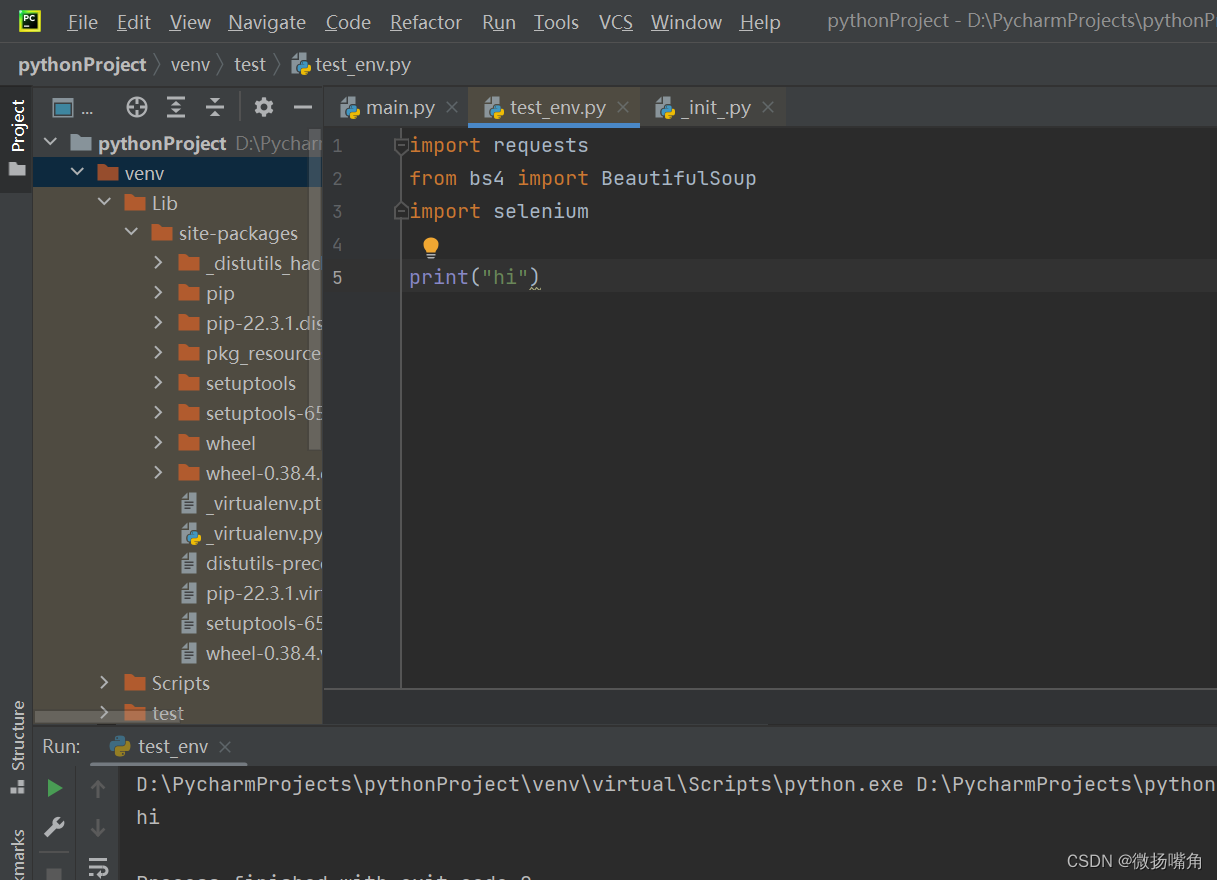
在pycharm中新建一个项目,在pycharm的终端(terminal)使用pip install 指令下载三个包:requests,beautifulsoup4,selenium.
用如下代码测试是否下载成功:
import requests
from bs4 import BeautifulSoup
import selenium
print("hi")
无报错则下载成功:
三、python中库的使用说明
request有两个方法,get和post。

补充:(1)params中的内容也可拼接到url后面。
(2)headers:如果hears为空,很容易被网站认为是爬虫程序而被禁止访问,这时可以设置一些虚假的header项。
(3)timeout:有些服务器有问题,不设置超时时间程序会卡住,设置时间自动中断。
(4)allow_redirects:有些网页访问url会自动进行跳转,requests会自动处理跳转,返回的是跳转之后的内容,而将allow_redirects设为false请求的则是跳转前的内容。

上图说明了如何获取requests得到的数据。
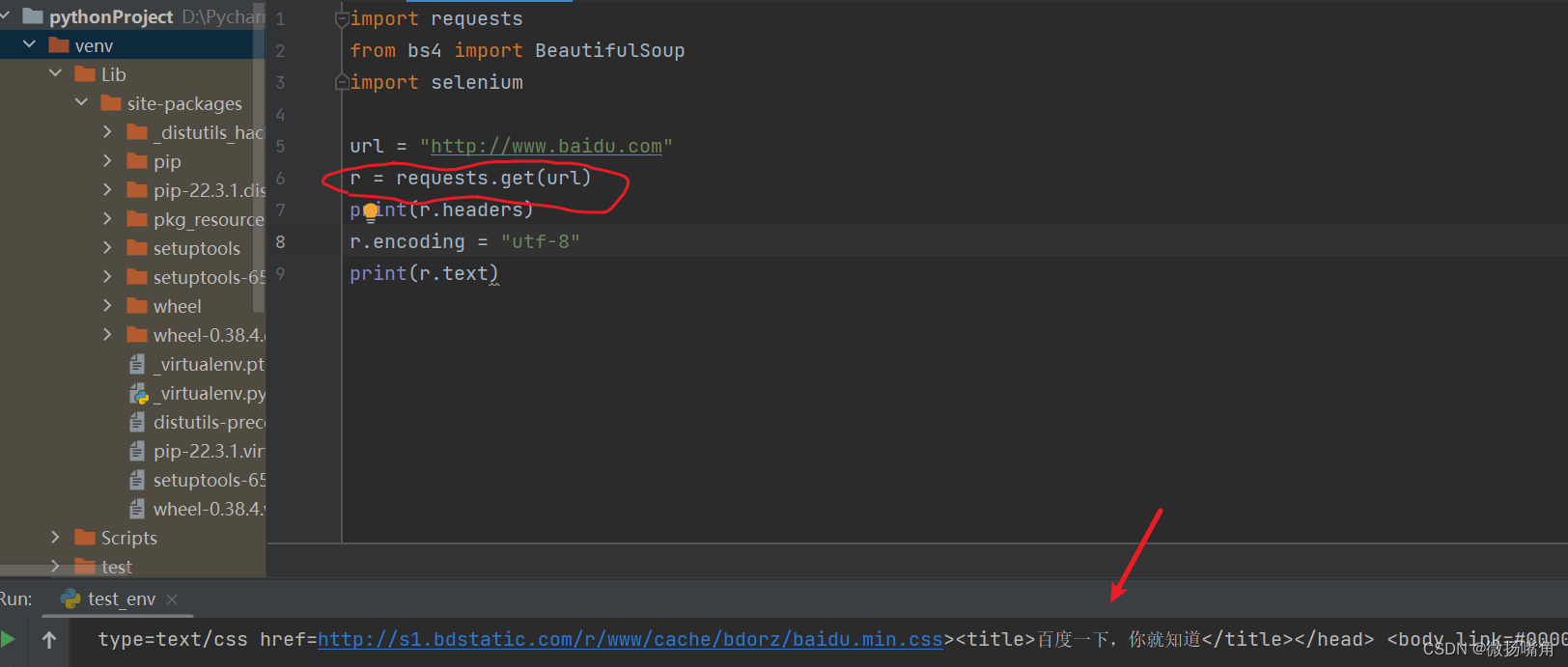
补充:(1)r.encoding很重要,有些网页返回的内容也许是乱码。
四、简单示例
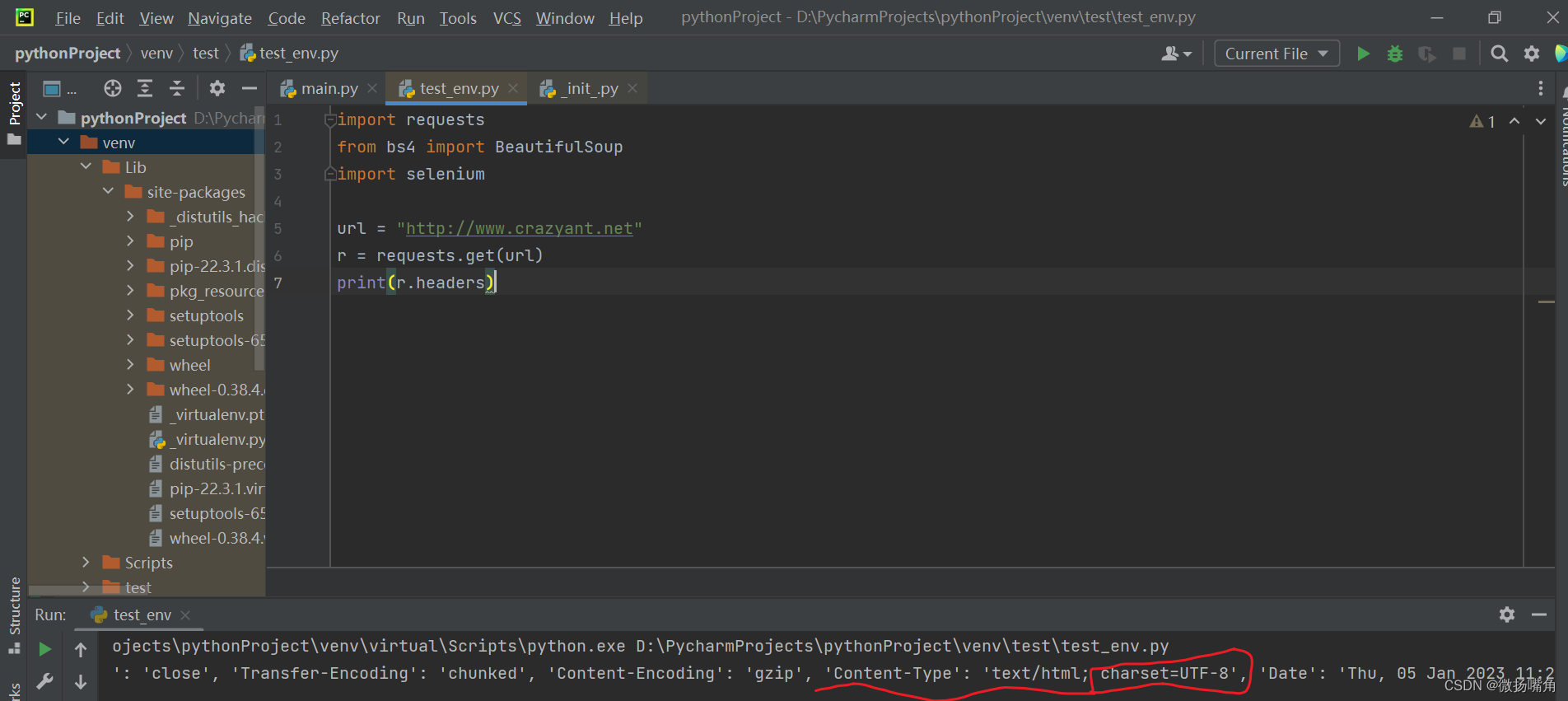
注意上面content-type字段的内容。
五、解决乱码问题
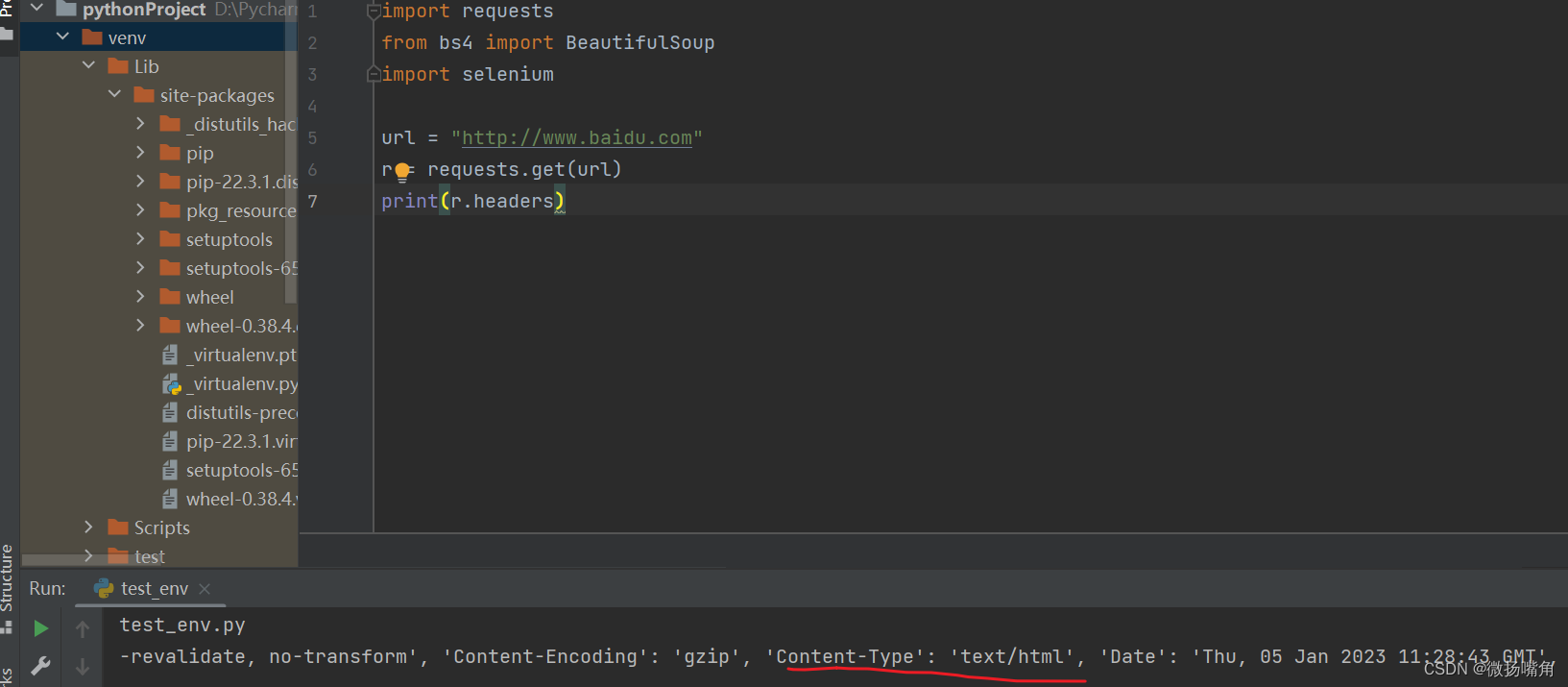
该网页的 headers中content-type中未设置utf-8导致中文显示不出(乱码):
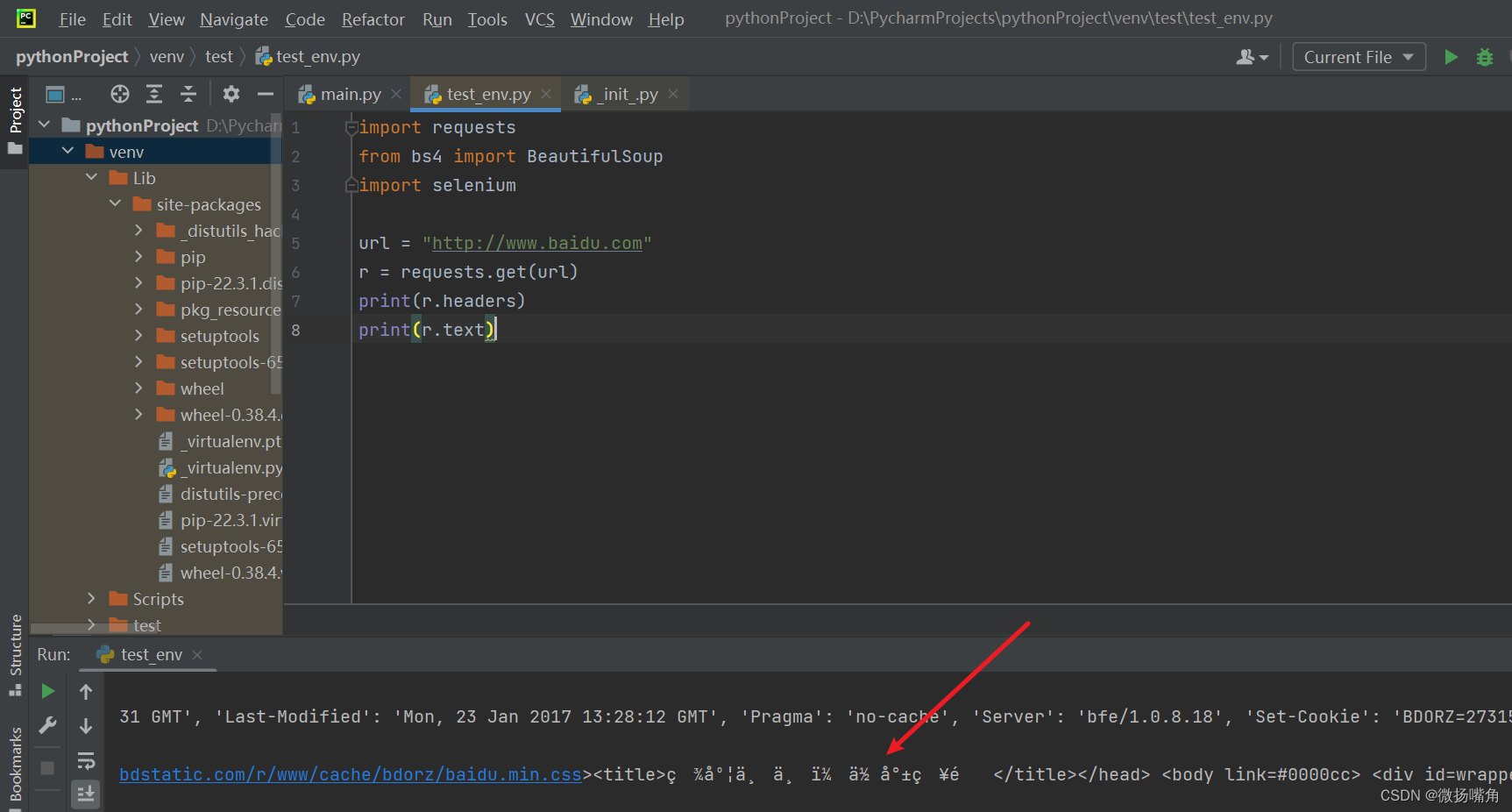
解决方法:添加下面一行代码



![[NOIP2017 提高组] 奶酪(C++,并查集)](https://img-blog.csdnimg.cn/img_convert/927c8f7cef70a66d2cfd9b3eeaf88ac1.png)