不可否认的是,LLM(例如 OpenAI 的 GPT 系列)将在不断发展的对话式 AI 领域发挥重要作用。 关于使用 ChatGPT 执行各种任务的帖子和文章不计其数。 GPT 有几个关键功能值得进一步探索,例如其摘要、分类和生成文本的能力。 其中,出现了一个问题——“我们能否使用LLM来有效取代为大多数基于意图的聊天机器人提供支持的传统机器学习模型”?
当我们想到LLM时,我们可能会想到一个没有明确定义的真正“意图”的未来。 它也许能够处理严格的、预先计划的结构之外的任何要求。 然而,截至今天,我们的重点是LLM可以适应并增强当前架构。 考虑到这一点,我们通过将LLM的分类能力与现实生活中的聊天机器人进行比较,采用了宽松的科学方法。
首先,我们需要接受没有一个聊天机器人可以完美地识别意图,因此已经存在错误分类的因素。 长篇大论、多重意图和许多其他事情都可能导致用户走上错误的道路。 我们投入了大量时间来识别和减少这些类型的对话。 也许LLM可以帮助完成这个过程?
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包
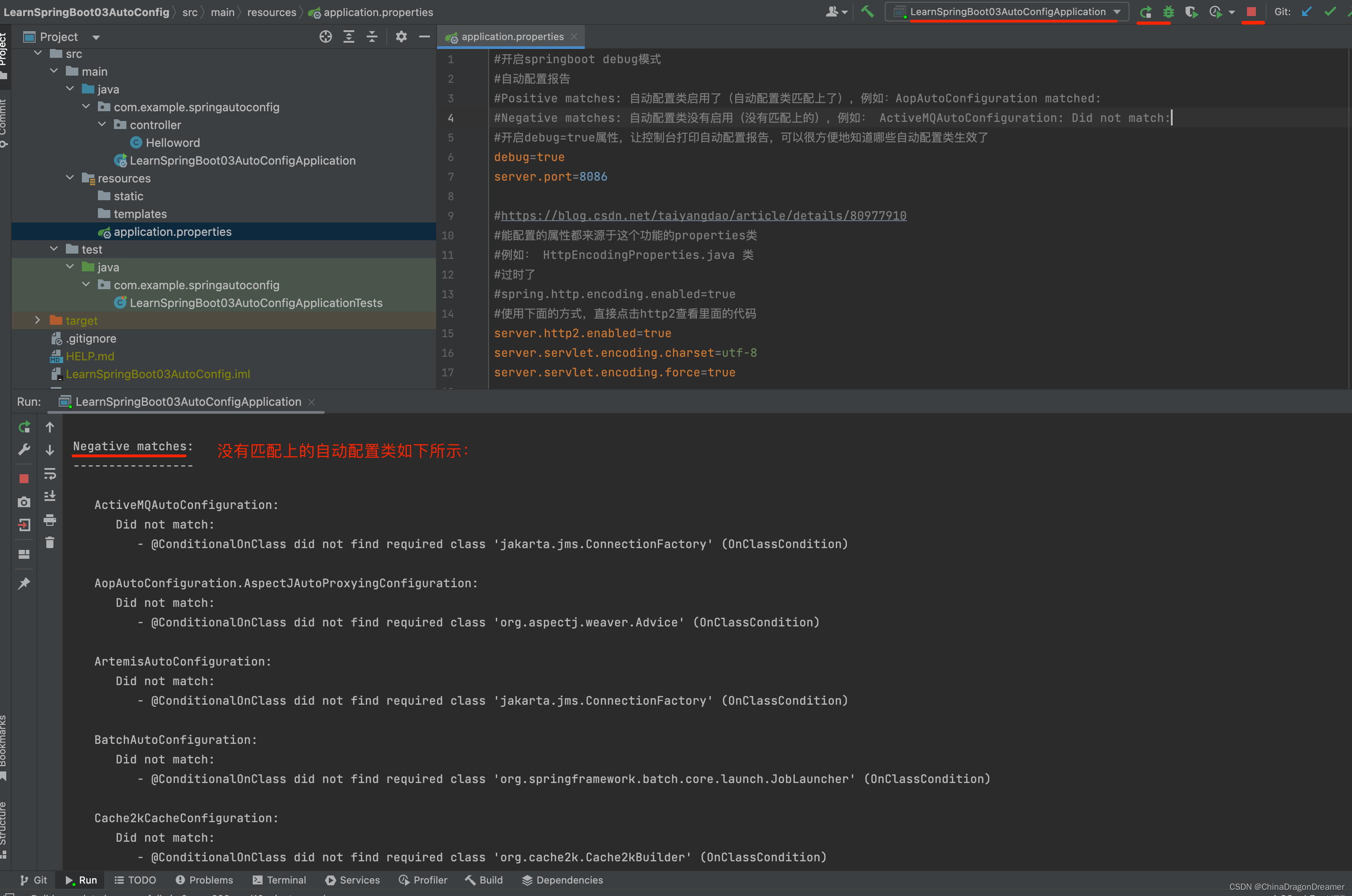
在我们的基准研究中,我们从生产客户服务聊天机器人中获取了数据,看看我们是否可以使用LLM来改进其意图识别。 为了实现基准比较,我们随机抽取了 400 个不同长度的真实用户输入,并用适当的意图手动标记这些输入。 接下来,我们针对机器人平台的机器学习模型运行了那些以前未见过的话语——准确率达到 60.5%。 虽然这可能看起来不太准确,但我们的聊天机器人解决方案也大量使用句法语言规则作为机器学习模型之上的额外层。 另一件需要考虑的事情是,人工标记也不是万无一失的,进行多次标记会减少那里的错误或偏差。 对于我们的小规模实验,我们只进行了一次标记。
常规 ML 模型的汇总结果:使用机器人平台的 ML 模型,涵盖 75 个意图的 9000 个训练问题返回 60.5% 的准确率
1、提示设计
我们写出了 75 个意图名称,并为每个意图添加了大约 5 - 7 个简洁的“主题”。 这些指令与用户话语一起在提示中传递以进行分类。 下面可以看到这些意图主题描述的示例。
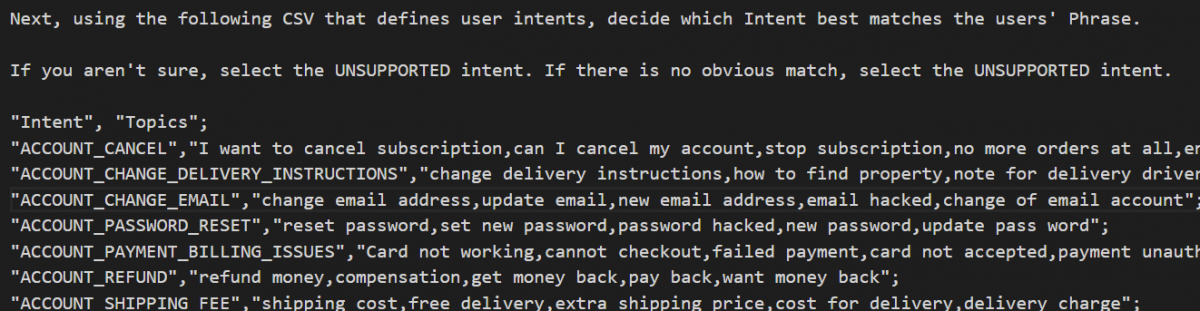
我们还添加了一些护栏提示,以确保它仅从给定列表中选择一个意图,如果不确定,则返回“UNSUPPORTED”。 还有一些关于选择某些意图作为优先于其他意图的规则。
初步结果令人印象深刻,它成功预测了 64.5% 的话语意图,击败了常规 ML 模型。
提示设计的总结结果:使用 GPT-3.5 的提示设计可达到 64.5% 的准确率,其中包含 375 个“主题”摘要,涵盖 75 个意图,每个意图定义 4-6 个主题。
分类提示设计的思考
这种方法似乎是识别用户意图的一种非常有效的方法,但也有一些缺点。 对于每个话语,我们每次都需要提供完整的意图列表及其主题描述。 每个 API 调用的成本可能只有几分之一美元,但如果乘以数千个对话,加起来就可能是一个非常大的数字。
我们还发现“审查和改进”结果具有挑战性。 例如,如果特定的用户话语失败,那么在主题描述中要更改的内容并不总是显而易见的。 虽然维护常规的 ML 训练短语也是如此,但提示方法似乎更像是猜测,而不是正常的。
此外,该模型也无法返回其预测的“置信度”或“概率”水平。 我们发现,任何询问置信度百分比或前 3 个建议列表的尝试都会大大降低其准确性。
2、微调
微调(fine tuning)是一种向预训练模型添加另一层额外信息的方法,以便它可以“记住”一些事实。 当我们使用微调层对用户输入进行分类时,我们准备了带有模式的数据来告诉模型返回(完成)我们的分类。 在撰写本文时,微调仅适用于基本 GPT-3 模型 - Davinci 是其中最有能力的。
最初,我们使用了在提示方法中效果很好的主题。 370 个主题中的每一个及其相应的意图名称都用于创建自定义的微调达芬奇模型。 我们可以在下面看到一些微调数据的示例。

该图显示了用于微调的 json 结构以及简短的主题示例
我们的基准测试结果是 44.25% 的准确率。 这并不奇怪,因为我们没有为模型提供太多可以“学习”的内容来对用户消息的意图进行分类。 我们还发现该模型会返回看似合理但虚构的意图名称,其格式与提供给它的名称类似。
微调主题的摘要结果:使用经过微调的 Ada 模型,准确率达到 44.25%,该模型包含 375 个“主题”摘要,涵盖 75 个意图,每个意图定义 4-6 个主题。
作为第二阶段测试,我们准备了用于 ML 模型的所有现有训练数据,并创建了另一个经过微调的 GPT-3 模型。 这相当于 9000 多个训练问题,因此为模型提供了更多现实生活中的示例。 现在,根据我们对 400 条以前未见过的话语进行的基准测试,它的预测正确率为 65%。 我们还发现它没有发明新的意图名称。 使用经过微调的达芬奇模型时,准确率提高到 70%。

微调训练短语的总结结果:使用经过微调的 Ada 模型(包含涵盖 55 个意图的 9000 个训练短语),准确率达到 65%;使用经过微调的达芬奇模型,包含涵盖 55 个意图的 9000 个训练短语,准确率达到 70%
关于分类微调的思考
这种方法需要将数据准备成“提示”和“完成”模式。 根据特定模型的代币使用情况,创建微调模型需要一次性付费。 与使用常规 GPT-3 基本模型相比,向该微调模型发送后续查询会产生更高的令牌费用。
我们发现的一个缺点是,我们无法在对用户的话语进行分类之前轻松添加这些额外的“规则”。 有一个相对较新的提示结构用于将指令与输入分开,称为 ChatML,但基本 GPT-3 模型似乎尚不支持此结构。
3、嵌入
最后一种方法称为嵌入(embedding), 它是一种将单词和句子转换为数字(向量)以比较相似度的方法。 嵌入向量通常用于语义搜索和从大型语料库中检索相关答案。 该过程涉及从文本块创建嵌入文件。 在大多数情况下,OpenAI 建议使用他们最快且最便宜的模型 Ada 来实现此目的。

创建嵌入时,它本质上是创建一个数字(向量)文本文件,可以在 OpenAI 基础设施之外下载和使用。 如果它非常大,可能需要将其集中托管在专用矢量数据库上。
我们选择嵌入大约 9000 个话语的训练数据。 因此,每个训练短语都会被嵌入,然后将 400 个测试话语中的每一个与这些嵌入进行比较以了解相似性。
结果是 60% 的准确率,实际上与常规 ML 模型本身相同。
嵌入的总结结果:使用 Ada 模型进行嵌入,具有涵盖 55 个意图的 9000 个训练短语,准确率达到 60%
关于分类嵌入的思考
一旦嵌入了自定义数据,拥有一个不会过期或产生使用费用的文件就很有吸引力。 然而,与嵌入数据进行比较的短语必须首先使用相同的模型嵌入。 嵌入似乎是一种基于语义相似性返回事实响应的可靠方法。 它不会“发明”新的意图,因为它会忠实地返回所提供的任何文本。 根据最可能的意图返回相似度分数。 然而,我们观察到的数字非常接近,有时在 0 到 1 的范围内仅相差 0.001。
在所有 3 种方法中,这种方法似乎是最复杂的,并且并没有比向提示本身添加简单主题产生更好的结果。
4、结束语
虽然我们的测试规模有限,但它们确实揭示了LLM如何适合意图分类。 为了更好地评估这些方法,让我们回到最初的问题“我们是否可以使用LLM来有效取代为大多数基于意图的聊天机器人提供支持的传统机器学习模型?”
微调提供了 70.5% 的最佳准确率,比常规 ML 模型高出 10%。 然而,这必须与维持训练短语和无法实施意图“优先”规则或“后备”响应的限制相平衡。 还值得注意的是,达芬奇模型的训练时间为 2 小时,成本为 21 美元。
嵌入方法提供的结果通常与传统机器学习模型的准确性一致,但它们仍然需要大量精选的训练短语。 从我们的测试来看,它们似乎不适合更好的意图识别或改进的工作流程。 事实上,对训练问题进行更改比在机器人平台本身上重新训练“内置”机器学习模型需要更长的时间。
然而,我们可以看到使用提示设计方法的用例。 创建意图列表相对较快,无需使用任何其他数据或 API。 它确实可以加速构建第一个迭代聊天机器人,或者可能是 PoC 或演示。 不需要预先拥有大量训练数据,任何人都可以填写“主题”来描述意图的目的。 对于这种情况,我们认为更少的意图很可能会带来更高的准确性,而低使用率将使其成为一种具有成本效益的选择。 通过护栏“规则”来“指导”分类的能力也是非常有益的。
还值得考虑的是,如果 API 在任意时间段内不可用,任何使用外部 LLM 作为意图分类“管理器”的聊天机器人都将遭受巨大损失。 在本文中,我们仅关注 OpenAI/GPT,但当然也可以使用其他 LLM,它们可能具有不同的可靠性因素,或者它们可能与我们测试过的那些不同,适合此任务。
我们还注意到,在所有测试的许多情况下,虽然意图被错误分类,但提出的意图却非常合理且合理。 例如,这些话语包含多种意图,或者它们在没有明确说明的情况下表明了特定的意图——这是人类(目前)更擅长的!
原文链接:LLM的意图识别能力 - BimAnt