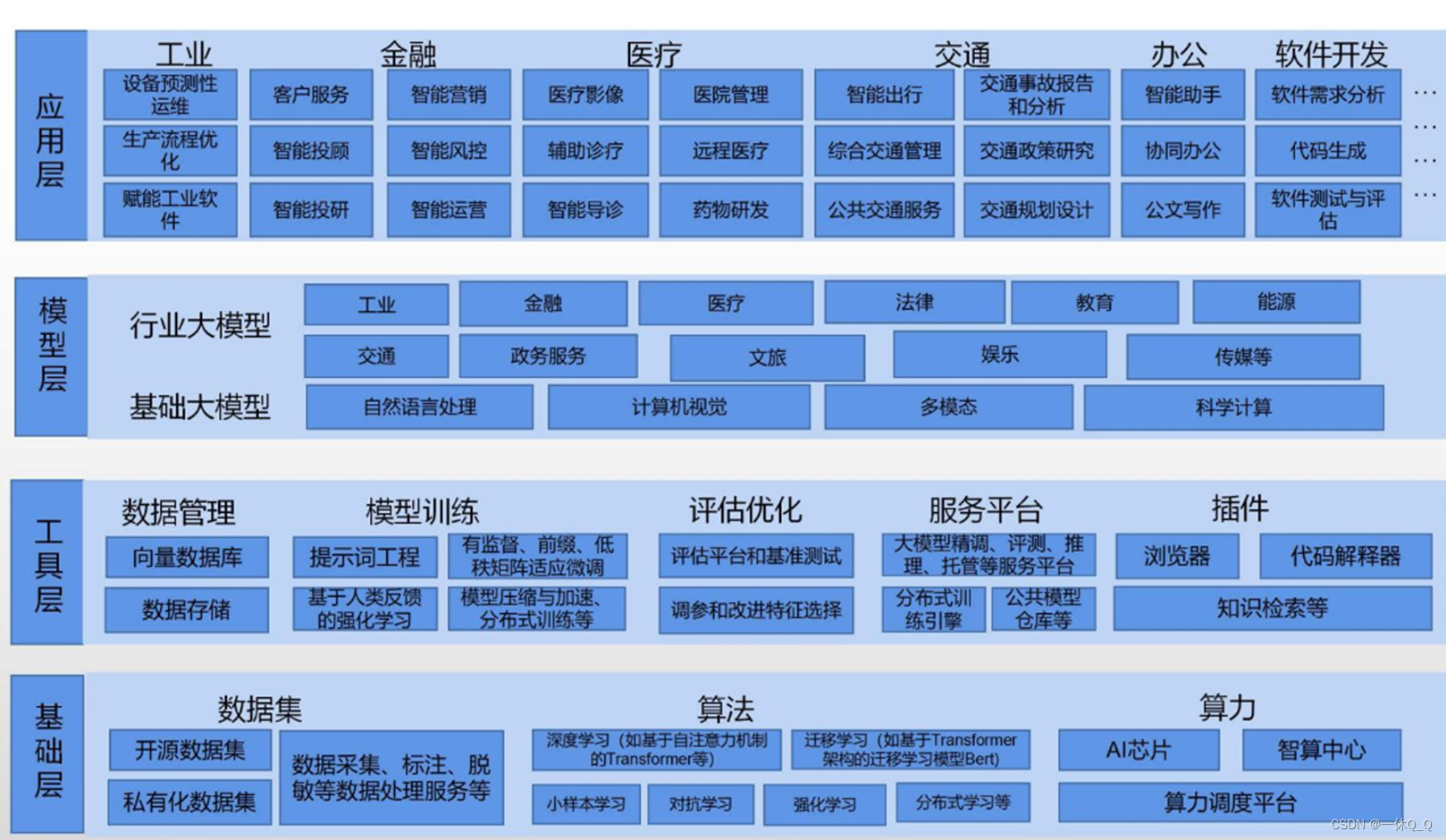
1.概念
大模型是指人工智能预训练大模型,具有海量参数和复杂架构,用于深度学习任务的模型,拥有强大的处理能力和表征能力,以数据+算力为支撑,借助数据管理、模型训练、评估优化、服务平台、插件等辅助工具,开发基础大模型或行业大模型,再延伸至工业、金融、医疗、交通等下游场景应用。
2.发展
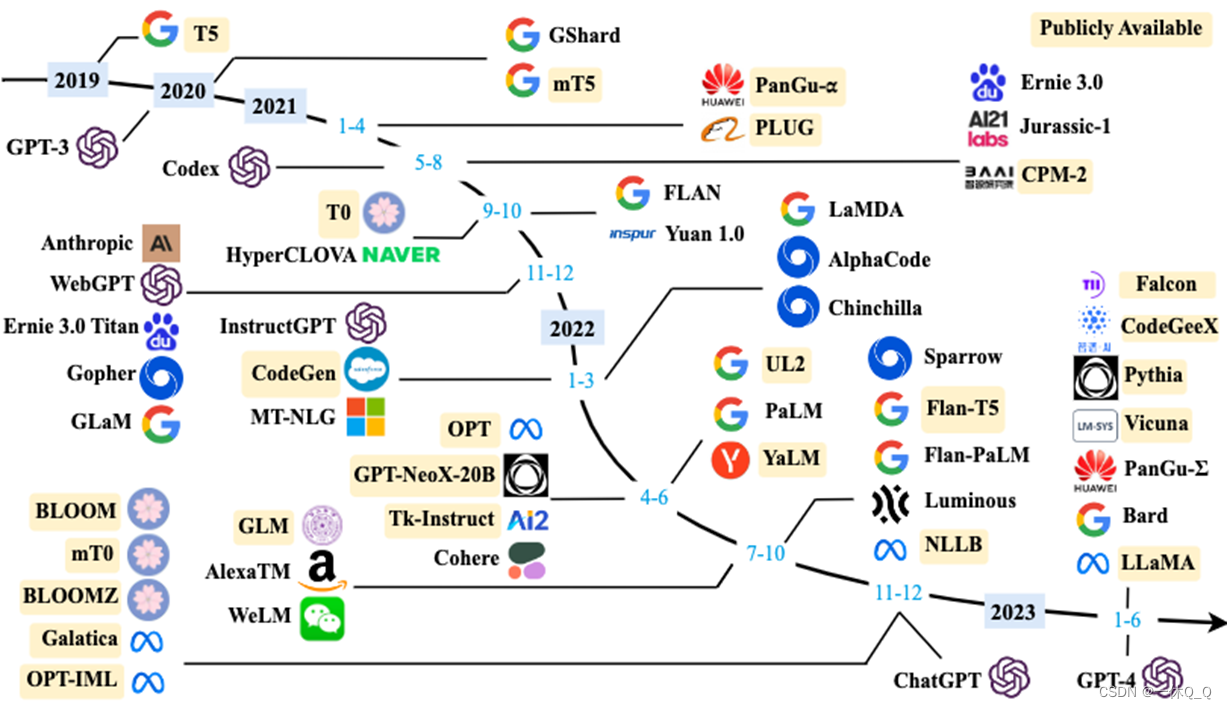
分为三个阶段:
3.GPT系列
GPT由OpenAI开发的一系列基于人工神经网络的自然语言处理模型,提出“生成式预训练(无监督)+判别式任务精调(有监督)”的范式来处理NLP任务。

模型由开源向闭源发展,构建技术壁垒。

4.LLaMa系列

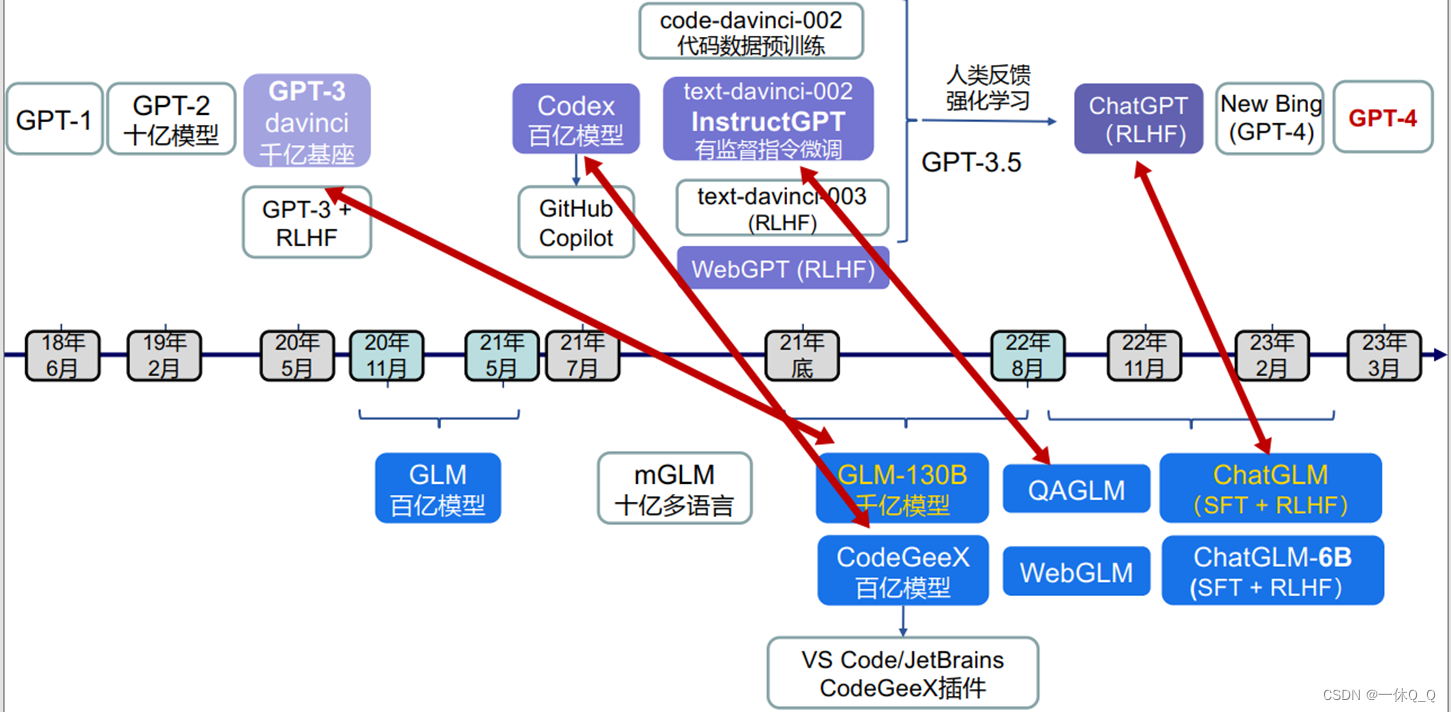
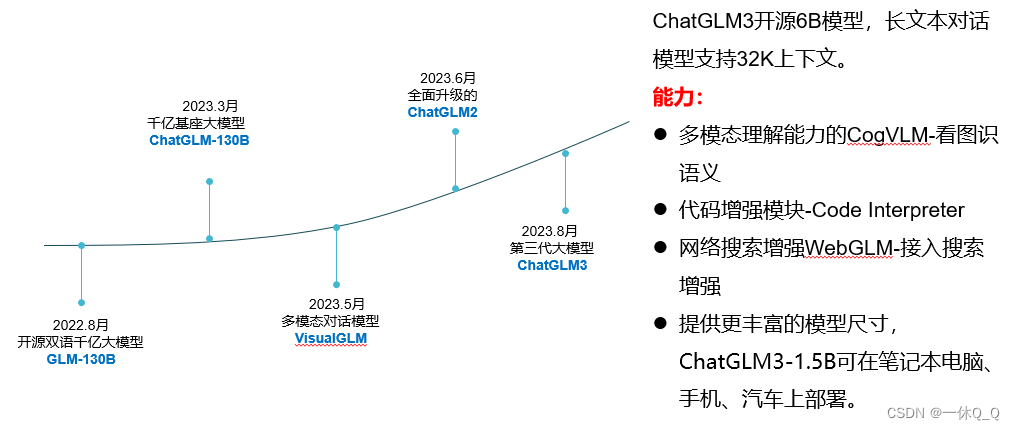
5.GLM系列
GLM是清华与智谱AI共同研制的一个开放的双语(英汉)双向密集预训练语言大模型,基于Transformer架构构建,具有强大的自然语言处理能力,能够实现对文本的理解、生成和生成式理解,被誉为“自然语言处理领域的黑科技”。
6.其它模型
Falcon:阿联酋阿布扎比的技术创新研究所(TII)开发,包含:Falcon-7B 、Falcon-40B和Falcon-180B,分别基于 1.5 万亿、 1 万亿、3.5 万亿 token数据训练而得,Falcon-180B是最大的开源预训练模型。
Vicuna:UC伯克利大学的研究人员联合其它几家研究机构共同推出的基于LLaMA微调的大语言模型, Vicuna 1.5系列包含Vicuna 7B、Vicuna 13B以及Vicuna 7B 16K和Vicuna 13B ,基于LLaMA2微调的,支持免费商用。
盘古:华为开发的一系列大规模自回归中文预训练语言模型,盘古3.0提供10B参数、38B参数、71B参数和 100B参数的基础大模型,提供NLP 大模型的知识问答、文案生成、代码生成,以及多模态大模型的图像生成、图像理解等能力。
文心一言:百度发布的人工智能大语言模型,文心大模型4.0拥有万亿级别参数,是国内首次用万卡集群训练的大预言模型,在语言理解和生成方面性能更优,具备更强的推理和创造能力,支持多语言处理,可以轻松应对不同国家和地区的语言需求。
星火认知大模型:科大讯飞发布的大预言模型,星火大模型V3.0版本,进一步升级了数学自动提炼规律、小样本学习、代码项目级理解能力、多模态指令跟随与细节表达等能力,进一步提升星火的落地应用能力。
百度-文心一言:是百度全新一代知识增强大语言模型,能够与人对话互动、回答问题、协助创作,高效便捷地帮助人们获取信息、知识和灵感。文心一言从数万亿数据和数千亿知识中融合学习,得到预训练大模型,在此基础上采用有监督精调、人类反馈强化学习、提示等技术,具备知识增强、检索增强和对话增强的技术优势。
科大讯飞-星火认知大模型:具有7大核心能力,即文本生成、语言理解、知识问答、逻辑推理、数学能力、代码能力、多模态能力。


![[UI5 常用控件] 06.Splitter,ResponsiveSplitter](https://img-blog.csdnimg.cn/direct/8812db63a2c64f6e96c42576fc6b6fae.png)