📝个人主页:五敷有你
🔥系列专栏:并发编程
⛺️稳重求进,晒太阳

JDK8之后有专门做累加的类,效率比自己做快数倍以上
累加器性能比较
参数是方法
- // supplier 提供者 无中生有 ()->结果
- // function 函数 一个参数一个结果 (参数)->结果 , BiFunction (参数1,参数2)->结果
- // consumer 消费者 一个参数没结果 (参数)->void, BiConsumer (参数1,参数2)->void
private static<T> void demo(Supplier<T> adderSupplier,Consumer<T> action){
T adder=adderSupplier.get();
long start=System.nanoTime();
List<Thread> ts=new ArrayList<>();
// 4 个线程,每人累加 50 万
for(int i=0;i< 40;i++){
ts.add(new Thread(()->{
for(int j=0;j< 500000;j++){
action.accept(adder);
}
}));
}
ts.forEach(t->t.start());
ts.forEach(t->{
try{
t.join();
}catch(InterruptedException e){
e.printStackTrace();
}
});
long end=System.nanoTime();
System.out.println(adder+" cost:"+(end-start)/1000_000);
}比较 AtomicLong 与 LongAdder
for (int i = 0; i < 5; i++) {
demo(() -> new LongAdder(), adder -> adder.increment());
}
for (int i = 0; i < 5; i++) {
demo(() -> new AtomicLong(), adder -> adder.getAndIncrement());
}原子累加器 花费116ms, 自己写花费 938ms
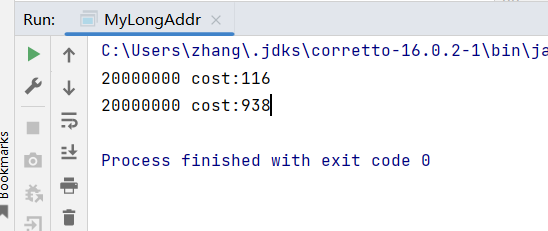
性能提升的原因很简单,就是在有竞争时,设置多个累加单元,Therad-0 累加 Cell[0],而 Thread-1 累加Cell[1]... 最后将结果汇总。这样它们在累加时操作的不同的 Cell 变量,因此减少了 CAS 重试失败,从而提高性能。
源码之LongAdder
LongAdder 是并发大师 @author Doug Lea 的作品,设计精巧
LongAdder类有几个关键域
// 累加单元数组, 懒惰初始化
transient volatile Cell[] cells;
// 基础值, 如果没有竞争, 则用 cas 累加这个域
transient volatile long base;
// 在 cells 创建或扩容时, 置为 1, 表示加锁
transient volatile int cellsBusy;CAS锁
// 不要用于实践!!!
public class LockCas {
private AtomicInteger state = new AtomicInteger(0);
public void lock() {
while (true) {
if (state.compareAndSet(0, 1)) {
break;
}
}
}
public void unlock() {
log.debug("unlock...");
state.set(0);
}
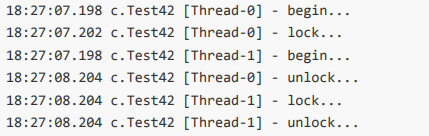
}测试
LockCas lock = new LockCas();
new Thread(() -> {
System.out.println("begin...");
lock.lock();
try {
System.out.println("lock...");
sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}).start();
new Thread(() -> {
System.out.println("begin...");
lock.lock();
try {
System.out.println("lock...");
} finally {
lock.unlock();
}
}).start();输出
原理之伪共享
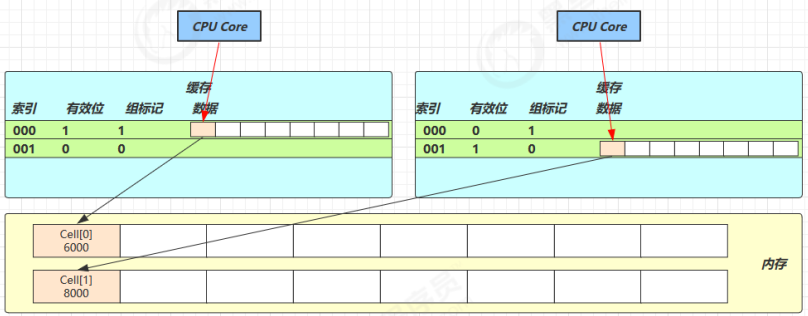
其中 Cell 即为累加单元
得从缓存说起
缓存与内存的速度比较
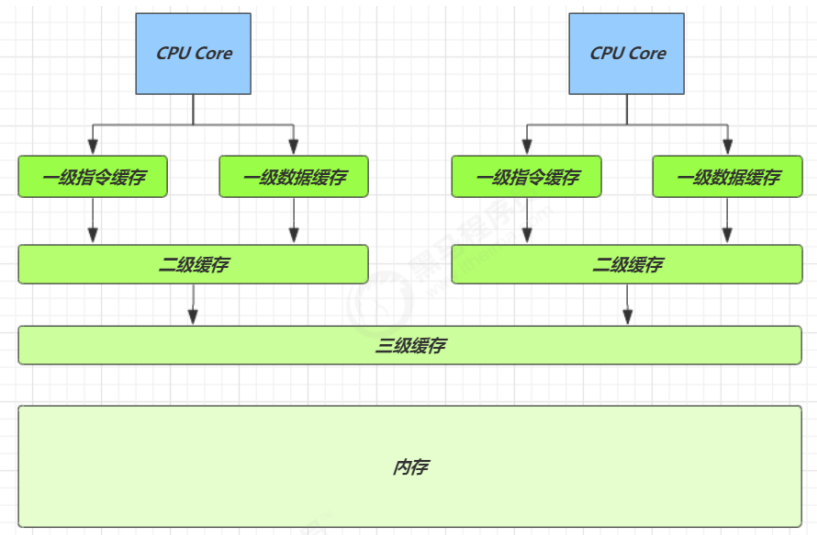
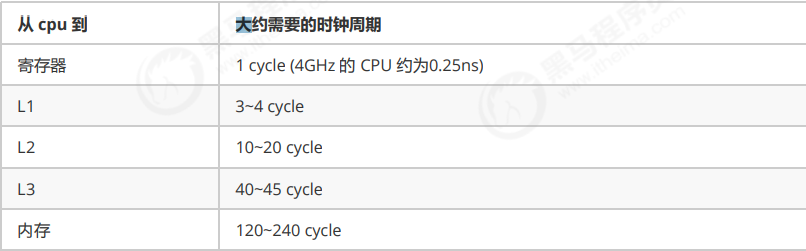
因为 CPU 与 内存的速度差异很大,需要靠预读数据至缓存来提升效率。
而缓存以缓存行为单位,每个缓存行对应着一块内存,一般是 64 byte(8 个 long)
缓存的加入会造成数据副本的产生,即同一份数据会缓存在不同核心的缓存行中
CPU 要保证数据的一致性,如果某个 CPU 核心更改了数据,其它 CPU 核心对应的整个缓存行必须失效
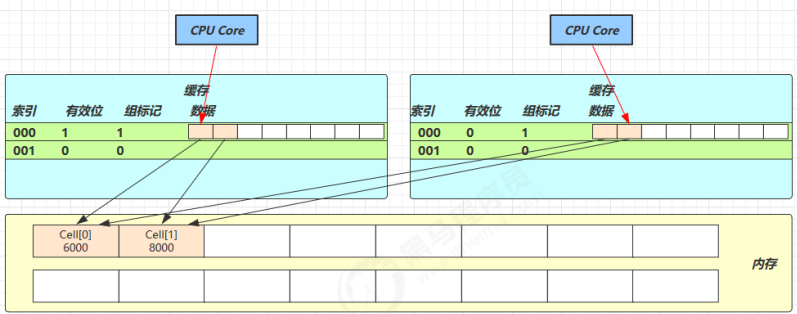
因为 Cell 是数组形式,在内存中是连续存储的,一个 Cell 为 24 字节(16 字节的对象头和 8 字节的 value),因此缓存行可以存下 2 个的 Cell 对象。这样问题来了:
- Core-0 要修改 Cell[0]
- Core-1 要修改 Cell[1]
无论谁修改成功,都会导致对方 Core 的缓存行失效,比如 Core-0 中 Cell[0]=6000, Cell[1]=8000 要累加Cell[0]=6001, Cell[1]=8000 ,这时会让 Core-1 的缓存行失效
@sun.misc.Contended 用来解决这个问题,它的原理是在使用此注解的对象或字段的前后各增加 128 字节大小的padding(填充),从而让 CPU 将对象预读至缓存时占用不同的缓存行,这样,不会造成对方缓存行的失效
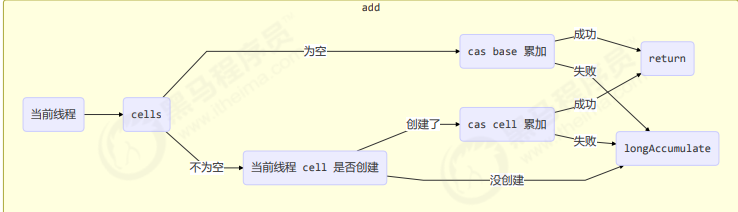
累加主要调用下面的方法
public void add(long x) {
// as 为累加单元数组
// b 为基础值
// x 为累加值
Cell[] as; long b, v; int m; Cell a;
// 进入 if 的两个条件
// 1. as 有值, 表示已经发生过竞争, 进入 if
// 2. cas 给 base 累加时失败了, 表示 base 发生了竞争, 进入 if
if ((as = cells) != null || !casBase(b = base, b + x)) {
// uncontended 表示 cell 没有竞争
boolean uncontended = true;
if (
// as 还没有创建
as == null || (m = as.length - 1) < 0 ||
// 当前线程对应的 cell 还没有
(a = as[getProbe() & m]) == null ||
// cas 给当前线程的 cell 累加失败 uncontended=false ( a 为当前线程的 cell )
!(uncontended = a.cas(v = a.value, v + x))
) {
// 进入 cell 数组创建、cell 创建的流程
longAccumulate(x, null, uncontended);
}
}
}add 流程图
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
// 当前线程还没有对应的 cell, 需要随机生成一个 h 值用来将当前线程绑定到 cell
if ((h = getProbe()) == 0) {
// 初始化 probe
ThreadLocalRandom.current();
// h 对应新的 probe 值, 用来对应 cell
h = getProbe();
wasUncontended = true;
}
// collide 为 true 表示需要扩容
boolean collide = false;
for (;;) {
Cell[] as; Cell a; int n; long v;
// 已经有了 cells
if ((as = cells) != null && (n = as.length) > 0) {
// 还没有 cell
if ((a = as[(n - 1) & h]) == null) {
// 为 cellsBusy 加锁, 创建 cell, cell 的初始累加值为 x
// 成功则 break, 否则继续 continue 循环
}
// 有竞争, 改变线程对应的 cell 来重试 cas
else if (!wasUncontended)
wasUncontended = true;
// cas 尝试累加, fn 配合 LongAccumulator 不为 null, 配合 LongAdder 为 null
else if (a.cas(v = a.value, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
break;
// 如果 cells 长度已经超过了最大长度, 或者已经扩容, 改变线程对应的 cell 来重试 cas
else if (n >= NCPU || cells != as)
collide = false;
// 确保 collide 为 false 进入此分支, 就不会进入下面的 else if 进行扩容了
else if (!collide)
collide = true;
// 加锁
else if (cellsBusy == 0 && casCellsBusy()) {
// 加锁成功, 扩容
continue;
}
// 改变线程对应的 cell
h = advanceProbe(h);
}
// 还没有 cells, 尝试给 cellsBusy 加锁
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
// 加锁成功, 初始化 cells, 最开始长度为 2, 并填充一个 cell
// 成功则 break;
}
// 上两种情况失败, 尝试给 base 累加
else if (casBase(v = base, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
break;
}longAccumulate 流程图
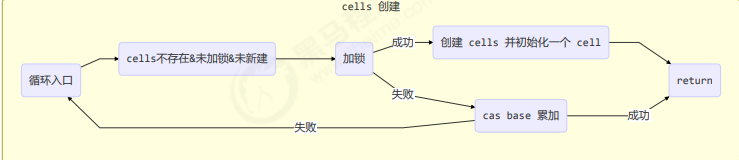
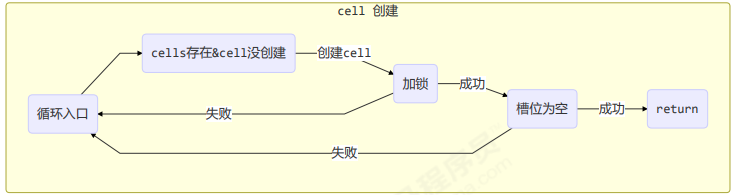
每个线程刚进入 longAccumulate 时,会尝试对应一个 cell 对象(找到一个坑位)
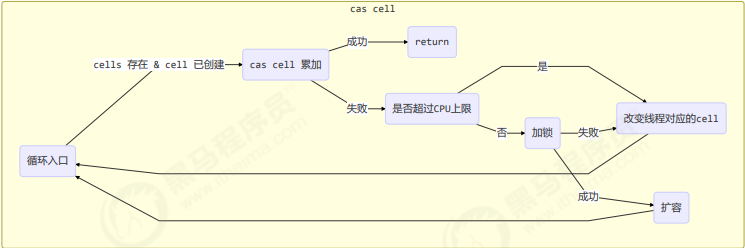
获取最终结果通过 sum 方法
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}