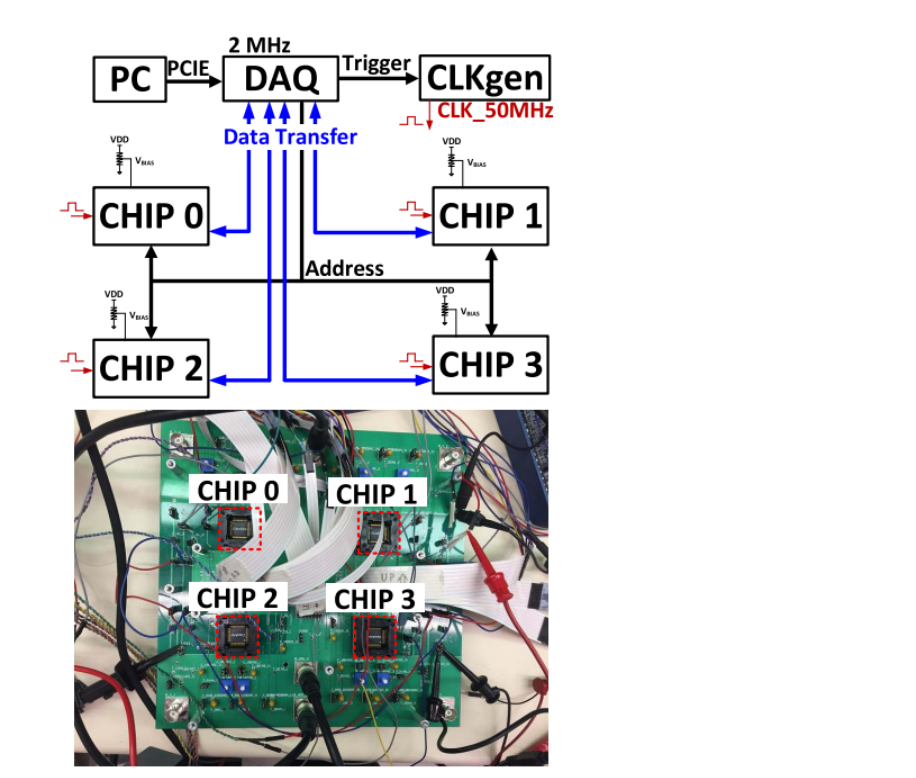
简单函数
函数:就是封装了一段可被重复调用执行的代码块。通过此代码块可以实现大量代码的重复使用。
函数的使用包含两个步骤:
-
定义函数 —— 封装 独立的功能
-
调用函数 —— 享受 封装 的成果
函数的作用,在开发程序时,使用函数可以提高编写的效率以及代码的重用
函数的定义
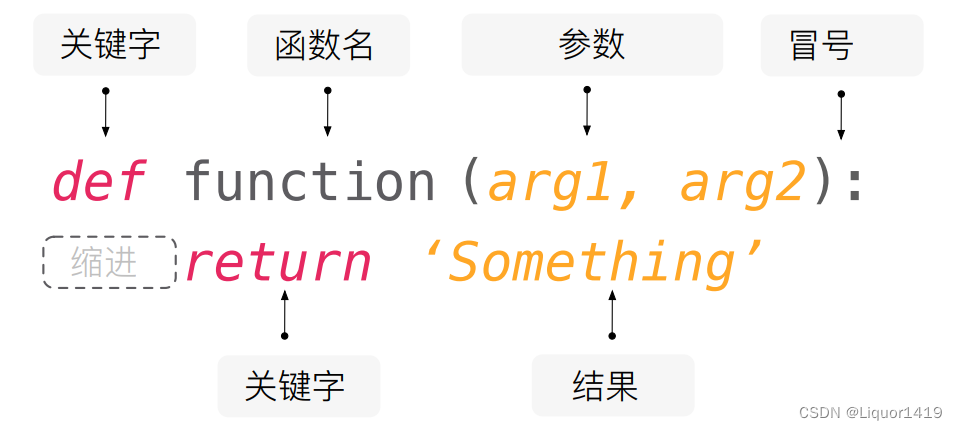
声明函数
-
def:表示函数的关键字,是英文define的缩写 -
函数名:函数的名称,后续根据函数名调用函数,函数名称应该能够表达函数封装代码的功能
-
arg: 即 argument 参数 -
函数体:函数中进行一系列的逻辑计算,如:发送邮件、计算出 [11,22,38,888,2]中的最大数等...
-
函数名称的命名应该符合标识符的命名规则
-
可以由 字母、下划线和数字组成
-
不能以数字开头
-
不能与关键字重名
-
# 声明函数
def func():
# 函数体代码
# 函数体代码
# 函数体代码
# 函数体代码
print()def 是声明函数的关键字,必须小写
由于函数一般是为了实现某个功能才定义的, 所以通常我们将函数名命名为动词,比如 get_sum
调用函数
# 调用函数
函数名(); # 通过调用函数名来执行函数体代码调用的时候千万不要忘记添加小括号
口诀:函数不调用,自己不执行
注意:声明函数本身并不会执行代码,只有调用函数时才会执行函数体代码。
函数的封装
函数的封装是把一个或者多个功能通过函数的方式封装起来,对外只提供一个简单的函数接口
简单理解:封装类似于将电脑配件整合组装到机箱中 ( 类似快递打包)
例子:封装计算1-100累加和
"""
计算1-100之间值的函数
"""
# 声明函数
def get_sum():
total = 0
for i in range(100):
total += i
print(total)
# 调用函数
get_sum()例子:利用函数 求两个数的最大值
# 利用函数 求两个数的最大值
def get_max(num1, num2):
if num1 > num2:
print(num1)
else:
print(num2)
get_max(1, 3)
get_max(11, 3)调用函数很简单的,通过 函数名() 即可完成对函数的调用
细节问题
能否将函数调用放在函数定义的上方?
-
不能
-
因为在使用函数名调用函数之前,必须要保证
Python已经知道函数的存在 -
否则控制台会提示
NameError: name 'f' is not defined(名称错误:f这个名字没有被定义)
函数的功能
有两个变量 x 和 y ,当 x 取其变化范围中的每一个特定值时,相应地有唯一的 y 与它对应,则称 y 是 x 的函数。记为 y = f ( x ),其中 x 为自变量, y 为因变量。
-
将
y = kx + b封装成一个函数,其中k=5,b=6, 假设x=5 -
在函数下方调用线性方程函数,打印结果
"""
# 函数在数学组的表达形式
y = f(x)
y = kx + b
"""k = 5
b = 6
# define 定义
# f 为函数名
def f(x):
# 里面的内容是函数体,函数执行的代码
y = k * x + b
# return 函数的返回值
return y参数可变
我们定义和调用一个没有参数的函数。假设需要求当 x 分别为 5 与 6 时,f(x) 的结果相加:
x = 5
def f(x):
y = 5 * x + 6
return y
print(f(5) + f(6))多次调用产生不同的结果
带参数的函数有一个非常大的好处,通过修改调用函数传入的参数,从而得到不同的值。
def f(x):
y = 5 * x + 6
return y
f(5)
f(6)
f(7)函数的返回值
建立在之前的函数之上,如果想得到函数的计算结果,然后相加在进行输出改如何处理?例如在函数外部将函数 f 的结果加 10 再进行输出。
函数的返回值
函数是一个功能块,该功能到底执行成功与否,需要通过返回值来告知调用者。
x = 5
def f():
y = 5 * x + 6
# return 关键字 返回一个内容
return y
print(f() +y)程序运行到所遇到的第一个return即返回(退出def块),实现函数值的返回,不会再运行第二个return。返回时可附带一个返回值,由return后面的参数指定。
return 之后函数就结束了,不会再执行后续代码
案例:
编写一个函数,求1+2+3+...+n
-
定义一个函数
-
函数接收一个参数 n
-
对1到n的数求和
-
打印和
def sum_test(n):
sum = 0
for x in range(1,n+1):
sum += x
return sum
print(sum_test(10))
'''
55
'''函数的其他形式
函数根据 有没有参数 以及 有没有返回值,可以 相互组合,一共有 4 种 组合形式
-
无参数,无返回值
-
无参数,有返回值
-
有参数,无返回值
-
有参数,有返回值
案例:函数复用
"""
复利公式:s = p(1 + i)^n
余额宝 兴全添利宝 年化 2.5610%
假设本金(principal)10000
1、请问分别存 5年 10年 15年 20年后 本金利息共多少
2、如果利率(interest)变成 6% 分别存 5年 10年 15年 20年后 本金利息共多少
3、如果本金变成 20000,利率不变 分别存 5年 10年 15年 20年后 本金利息共多少
"""
def func(p, i, n):
s = p * (1 + i) ** n
return s函数的参数
位置参数
Python 处理参数的方式要比其他语言更加灵活。其中,最熟悉的参数类型是位置参数,传入参数的值是按照顺序依次复制过去的。下面创建一个带有位置参数的函数:
需求:
y = k * x +b 中 k 与 b 也不固定。
def f(x, k, b):
y = k * x + b
print(y)
f(5, 5, 6)尽管这种方式很常见,但是位置参数的一个弊端是必须熟记每个位置的参数的含义。在调用函数 f() 时误把最后一个参数当作第一个参数,会得到完全不同的结果:
def f(x, k, b):
print("x:{} k:{} b:{}".format(x, k, b))
y = k * x + b
return(y)
f(5, 5, 6)关键字参数
为了避免位置参数带来的混乱,调用参数时可以指定对应参数的名字,甚至可以采用与函数定义不同的顺序调用:
def f(x, k, b):
print("x:{} k:{} b:{}".format(x, k, b))
y = k * x + b
return(y)
f(x=5, k=5, b=6)你也可以把位置参数和关键字参数混合起来。首先,实例化参数 ,然后对参数使用关键字参数的方式:
def f(x, k, b):
print("x:{} k:{} b:{}".format(x, k, b))
y = k * x + b
return(y)
f(5, k=5, b=6)
如果同时出现两种参数形式,首先应该考虑的是位置参数。
默认参数
当调用方没有提供对应的参数值时,你可以指定默认参数值。这个听起来很普通的特性实际上特别有用,以之前的例子为例:
def f(x, k=5, b=6):
print("x:{} k:{} b:{}".format(x, k, b))
y = k * x + b
return y
f(x=5, k=5, b=6)不确定长度的参数
*args
收集位置参数(了解)
在不清楚传入参数是多少个
# 用 * 收集位置参数
# int * 特殊符号 有特殊的作用, 在定义函数的括号里面,用于收集所有的位置参数
# 在输出 或者是运行代码的过程中 是解包 包:元组、列表、迭代器、生成器
def print_args(*args):
# * 解包的标志
print('位置参数的类型:', type(args))
print('位置参数的内容:', args)无参数调用函数,则什么也不会返回:
>>> print_args()
print_args ()给函数传入的所有参数都会以元组的形式返回输出:
>>> print_args(3, 2, 1, 'wait!', 'uh...')
(3, 2, 1, 'wait!', 'uh...')这样的技巧对于编写像 print() 一样接受可变数量的参数的函数是非常有用的。如果你函数同时有限定的位置参数,那么 *args 会收集剩下的参数:
>>> def print_args1(arg1, arg2, *args):
... print('arg1:', arg1)
... print('arg2:', arg2)
... print('args:', args)
...
>>> print_args1(1,2,3,4,5,6)
arg1: 1
arg2: 2
args: (3, 4, 5, 6)当使用 * 时不需要调用元组参数 args,不过这也是 Python 的一个常见做法。
**kwargs
收集关键字参数
使用两个星号可以将参数收集到一个字典中,参数的名字是字典的键,对应参数的值是字典的值。下面的例子定义了函数 print_kwargs(),然后打印输出它的关键字参数:
def print_kwargs(*arg, **kwargs):
""" args为关键字元组 kwargs为双元关键字元组 """
print('位置参数:', arg)
print('关键字参数:', kwargs)例子
案例:假设 python 中的 print 不能一次性传入多个参数使用了,让我们自己实现 print 可以传递多个参数的功能。
# 假设 print 函数突然变成了一下这个样子
def print_(arg):
print(arg, sep="", end="")要求:自己编写一个 changed_print 函数实现原本 print 的功能。
例:原本函数的功能
In [1]: print(1)
1
In [2]: print(1, 2, 3, 4)
1 2 3 4
In [3]: print(1, 2, 3,4, sep=',')
1,2,3,4
In [4]: print(1, 2, 3,4, sep=',', end='我是结尾')
1,2,3,4我是结尾def changed_print(*args, sep=' ', end='\n'):
# print_ 只能接受一个参数
for arg in args[:-1]:
print_1(arg)
# , 空格 #
print_1(sep)
print(args[-1])
print_1('\n')
一等公民函数
在 Python 中,函数是一等对象。编程语言理论家把“一等对象”定义为满足下述条件的程序实体:
-
在运行时创建
-
能赋值给变量或数据结构中的元素
-
能作为参数传给函数
-
能作为函数的返回结果
在 Python 中,整数、字符串和字典都是一等对象——没什么特别的。接下来的内容将重点讨论把函数作为对象的影响和实际应用。
比如说我要将之前函数修改一个名字,使用新的函数名去调用旧的函数
def f(x):
y = 5 * x + 6
# return 关键字 返回一个内容
return y
d = f
print(d(x) +d(y))把函数当参数传递
案例需求 f(1) + f(2) + f(3) + f(4) + f(5)
print(f(1) + f(2) + f(3) + f(4) + f(5))
# 把函数当参数传递
print(f(f(1)))设:求 f(1) + f(2) + f(3) + f(4) + f(5) + ...+f(N)
def sum_(N):
total = 0
for i in range(1, N + 1):
total += f(N)
return total
print_(sum_(5))全局变量作用域是整个程序,局部变量作用域是定义该变量的子程序。
交换变量值
需求:有变量a = 10和b = 20,交换两个变量的值。
-
方法一
借助第三变量存储数据。
# 1. 定义中间变量
c = 0
# 2. 将a的数据存储到c
c = a
# 3. 将b的数据20赋值到a,此时a = 20
a = b
# 4. 将之前c的数据10赋值到b,此时b = 10
b = c
print(a) # 20
print(b) # 10- 方法二
a, b = 1, 2
a, b = b, a
print(a) # 2
print(b) # 1例子
冒泡排序(冒泡排序)也是一种简单的简单列访问排序。它重复地走过去要排序的数,一次比较两个元素,如果他们的顺序错误让他们交换过来。走访数工作列的是重复地进行到那时已经没有再需要交换了,该算法的名字会因为越过元素会来交换慢慢地“浮”到数列的排序。
需求: 任意给定一组序列数字, 比如 [3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48], 将序列从小到大排列。(不能使用python函数解决)
"""
需求: 任意给定一组序列数字,
比如 [3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48],
将序列从小到大排列。(不能使用python函数解决)
"""
def bubbleSort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
return arr
print(bubbleSort([3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48]))
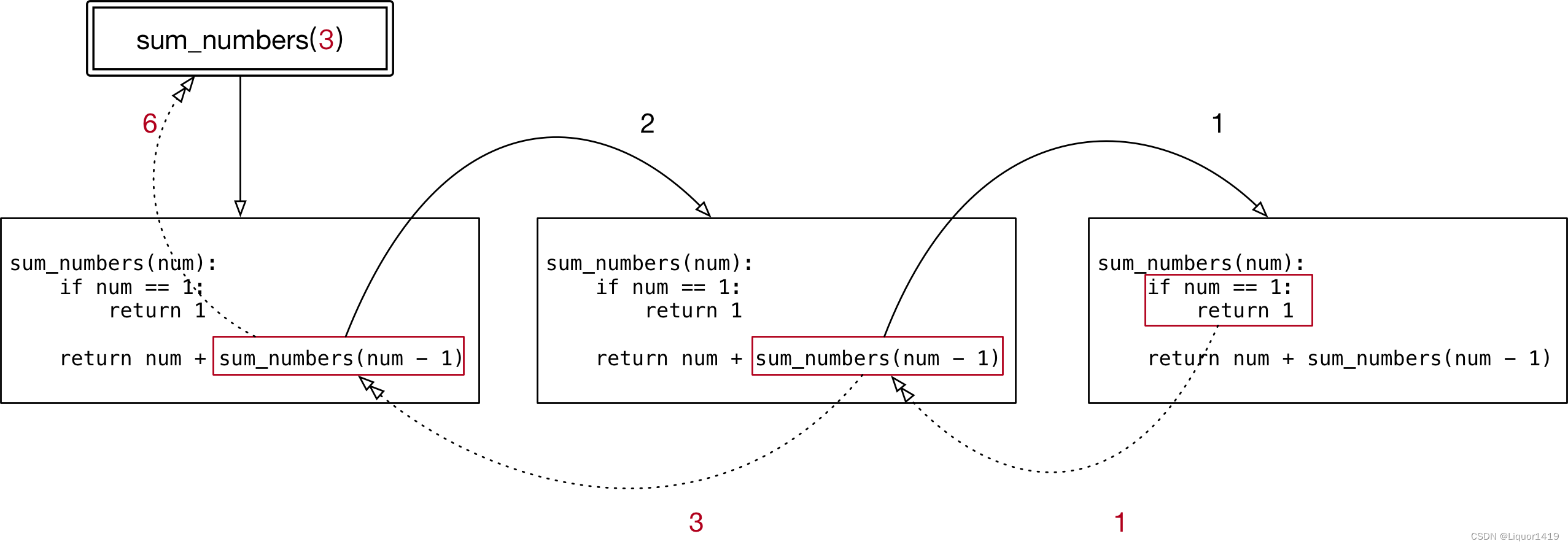
# 结果:[2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]递归
递归的应用场景
递归是一种编程思想,应用场景:
-
在我们日常开发中,如果要遍历一个文件夹下面所有的文件,通常会使用递归来实现;
-
在后续的算法课程中,很多算法都离不开递归,例如:快速排序。
递归的特点
-
函数内部自己调用自己
-
必须有出口
应用:数字累加求和
-
代码
# 3 + 2 + 1
def sum_numbers(num):
if num == 1:
return 1
return num + sum_numbers(num-1)
sum_result = sum_numbers(3)
# 输出结果为6
print(sum_result)- 执行结果
lambda 表达式
lambda 的应用场景
如果一个函数有一个返回值,并且只有一句代码,可以使用 lambda 简化。
lambda语法
lambda 参数列表 : 表达式注意
-
lambda表达式的参数可有可无,函数的参数在lambda表达式中完全适用。
-
lambda表达式能接收任何数量的参数但只能返回一个表达式的值。
快速入门
# 函数
def fn1():
return 200
print(fn1)
print(fn1())
# lambda表达式
fn2 = lambda: 100
print(fn2)
print(fn2())注意:直接打印lambda表达式,输出的是此lambda的内存地址
示例:计算a + b
函数实现
def add(a, b):
return a + b
result = add(1, 2)
print(result)思考:需求简单,是否代码多?
lambda实现
fn1 = lambda a, b: a + b
print(fn1(1, 2))lambda的参数形式
无参数
fn1 = lambda: 100
print(fn1())一个参数
fn1 = lambda a: a
print(fn1('hello world'))默认参数
fn1 = lambda a, b, c=100: a + b + c
print(fn1(10, 20))可变参数:*args
fn1 = lambda *args: args
print(fn1(10, 20, 30))注意:这里的可变参数传入到lambda之后,返回值为元组。
可变参数:**kwargs
fn1 = lambda **kwargs: kwargs
print(fn1(name='python', age=20))lambda的应用
带判断的lambda
fn1 = lambda a, b: a if a > b else b
print(fn1(1000, 500))列表数据按字典key的值排序
students = [
{'name': 'TOM', 'age': 20},
{'name': 'ROSE', 'age': 19},
{'name': 'Jack', 'age': 22}
]
# 按name值升序排列
students.sort(key=lambda x: x['name'])
print(students)
# 按name值降序排列
students.sort(key=lambda x: x['name'], reverse=True)
print(students)
# 按age值升序排列
students.sort(key=lambda x: x['age'])
print(students)高阶函数
把函数作为参数传入,这样的函数称为高阶函数,高阶函数是函数式编程的体现。函数式编程就是指这种高度抽象的编程范式。
体验高阶函数
在Python中,abs()函数可以完成对数字求绝对值计算。
abs(-10) # 10round()函数可以完成对数字的四舍五入计算。
round(1.2) # 1
round(1.9) # 2需求:任意两个数字,按照指定要求整理数字后再进行求和计算。
-
方法1
def add_num(a, b):
return abs(a) + abs(b)
result = add_num(-1, 2)
print(result) # 3- 方法2
def sum_num(a, b, f):
return f(a) + f(b)
result = sum_num(-1, 2, abs)
print(result) # 3注意:两种方法对比之后,发现,方法2的代码会更加简洁,函数灵活性更高。
函数式编程大量使用函数,减少了代码的重复,因此程序比较短,开发速度较快。
内置高阶函数
map()
map(func, lst),将传入的函数变量func作用到lst变量的每个元素中,并将结果组成新的列表(Python2)/迭代器(Python3)返回。
需求:计算list1序列中各个数字的2次方。
list1 = [1, 2, 3, 4, 5]
def func(x):
return x ** 2
result = map(func, list1)
print(result) # <map object at 0x0000013769653198>
print(list(result)) # [1, 4, 9, 16, 25]zip()
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同
a = [1,2,3]
b = [4,5,6]
c = [4,5,6,7,8]
result = zip(a,b) # 打包为元组的列表
# 结果:[(1, 4), (2, 5), (3, 6)]
result = zip(a,c) # 元素个数与最短的列表一致
# 结果:[(1, 4), (2, 5), (3, 6)]reduce()
reduce() 函数会对参数序列中元素进行累积。
reduce(func,lst),其中func必须有两个参数。每次func计算的结果继续和序列的下一个元素做累积计算。
注意:reduce()传入的参数func必须接收2个参数。
需求:计算list1序列中各个数字的累加和。
import functools
list1 = [1, 2, 3, 4, 5]
def func(a, b):
return a + b
result = functools.reduce(func, list1)
print(result) # 15filter()
filter(func, lst)函数用于过滤序列, 过滤掉不符合条件的元素, 返回一个 filter 对象。如果要转换为列表, 可以使用 list() 来转换。
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
def func(x):
return x % 2 == 0
result = filter(func, list1)
print(result) # <filter object at 0x0000017AF9DC3198>
print(list(result)) # [2, 4, 6, 8, 10]