前言

前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家:https://www.captainbed.cn/z

ChatGPT体验地址
文章目录
- 前言
- 引言
- 内存计算体系结构
- 深度神经网络(DNN)
- 随机梯度的优化算法
- 二值化神经网络(BNN)
- BNN架构
- 基于 sram 的内存计算系统中各列偏移的硬件补偿,
- 归一化
- 系统演示
- 总结
引言
深度神经网络(DNN)在机器学习领域越来越受欢迎,其在一系列任务中展现出最先进的性能。为了达到最佳结果,通常需要大量的训练数据和大型模型,从而使得训练和推理过程变得复杂。尽管图形处理单元(GPU)在许多应用中被用于提供并行计算能力,但较低能耗的平台有可能实现一系列新的应用。目前,一个趋势是降低权重和激活精度的能力,以前的研究表明,在某些情况下,权重和激活可以二值化(即二值化神经网络,BNN),从而显著减小模型尺寸。利用这一特点可以减少计算能量和数据传输能量。
内存计算体系结构
内存访问在能量和吞吐量方面是一个关键的瓶颈,无法通过传统的数字加速方法来解决。深度神经网络受到严重影响,因为其涉及到大模型尺寸,需要在内存中存储权重。这促使了内存计算方法的发展。尽管已经提出了各种方法,但它们的原理通常是通过对许多存储位访问来计算结果,从而逐个分摊访问原始数据的成本。
例如,传统内存一次只访问一行,而内存计算一次可以访问许多行(可能是所有行)。然而,这种平衡需要在许多位上进行计算,这通常会增加所需的动态范围。在现有的内存受限结构中,拟合计算通常需要模拟操作,从而降低计算的信噪比(SNR)。
下图,我们保留了一个标准的6T SRAM位单元,以最大限度地提高归一化效率和吞吐量,同时探索如何通过训练方法解决深度神经网络的计算SNR问题。通过修改存储位单元并采用电荷域运算,我们大幅提高了模拟计算的SNR,从而实现了最先进的规模和能源效率。
目前挑战主要有两个方向:(1)将权重值重置为1-b值;(2)针对位元变化和BL/BLB放电非线性的模拟MAC操作,产生各种非理想的因素。使用了增强的线性分类器,并在训练过程中采用约束分辨率回归(CRR)算法来适应1-b权重值。同时,他们利用错误自适应分类器增强(EACB)算法来克服模拟非理想。进一步发展到深度神经网络推理模型,以实现更高的精度。以上所采用的训练方法能够容忍有限的精度和模拟非理想。最近的内存计算架构进一步实现了1-8位的值和激活精度的可扩展性。
深度神经网络(DNN)
深度神经网络的训练过程与其它机器学习算法类似,通常采用一种称为随机梯度的优化算法。
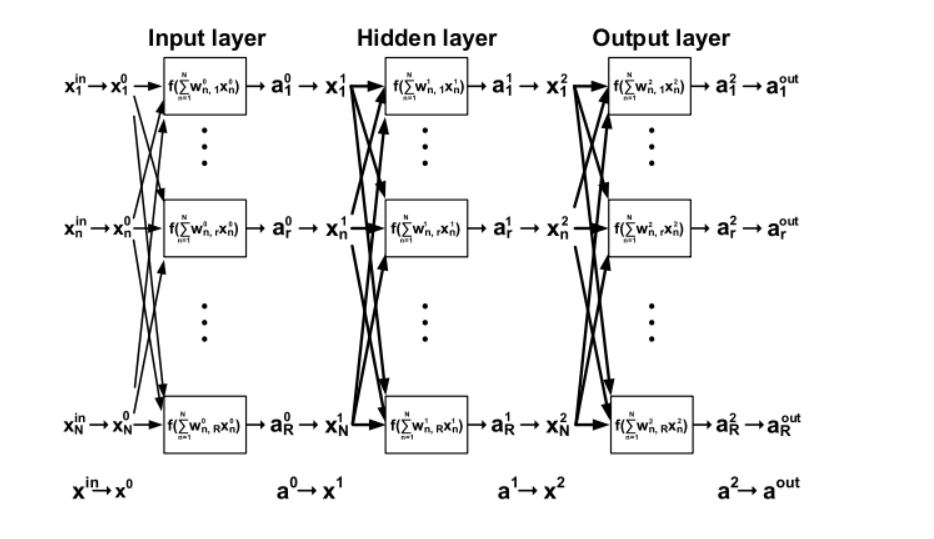
深度神经网络的结构如图2所示,每个“神经元”都是一个计算单元,接收N个输入x/n并在输入和可调权重w之间执行MAC操作。在这里,nr,re1,…R,其中R代表第1层的神经元总数,因此该层的输出维数也是R。值得注意的是,每一层的N必须等于前一层的N。在每个神经元中求和后,应用非线性函数·)产生输出激活al。对于下一层,激活作为输入,因此a→xn=r)。尽管图示了三层,但最终的输出层生成的激活.1通常对应于输出分类决策,例如,基于最高值的输出实现多类推理。
随机梯度的优化算法
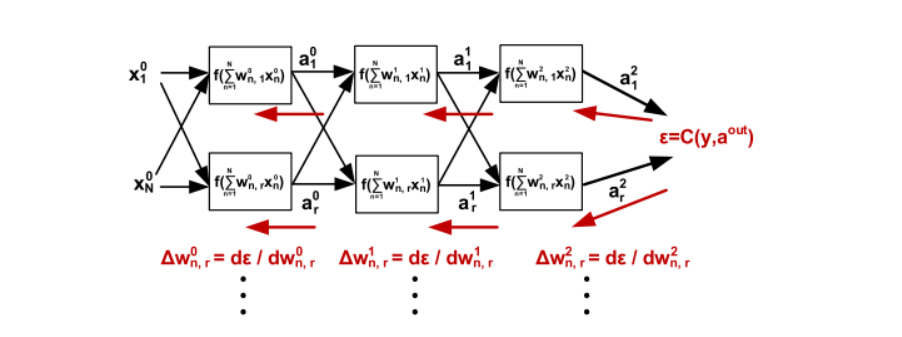
随机梯度下降(SGD)是一种用于训练深度学习和机器学习模型的优化算法。其核心思想是通过计算模型参数的梯度,并乘以一个学习率来更新参数。SGD包括以下步骤:
- 向前传播:将训练数据输入到模型中,计算输出。
- 计算误差:通过代价函数表示输出与真实标签之间的差距。
- 向后传播:计算误差的梯度,以调整模型参数。
- 权重更新:根据梯度值更新模型参数。
SGD通常在处理大量训练样本(称为“批处理”)之前进行权重更新,以避免由于随机噪声导致的稳定性问题。可以通过控制批处理的大小来调整更新策略。此外,SGD可以采用多种随机方式进行更新,称为“epoch”,以实现增量权重更新。在推理阶段,只需执行前向传播以获得决策结果。
二值化神经网络(BNN)
二值化神经网络(BNN)是一种在深度学习模型中使用二进制权重和激活值的网络。在BNN的训练过程中,权重和激活值都是在正向传播过程中进行二值化的。然而,如果将梯度存储为二进制值,更新过程将变得困难,因此我们存储全精度的梯度。
在BNN中,由于激活函数的不连续性,需要使用新的导数函数。常用的成本函数有铰链损失等。为了进一步提高稳定性,提高收敛速度,并减少由于精度降低而导致的协方差偏移,建议在MLP训练过程中加入批归一化(batchnorm)。
BNN架构
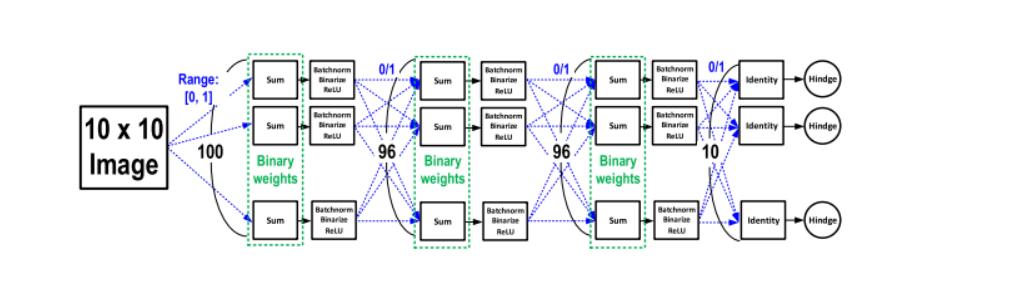
我们考虑了一个二值化神经网络(BNN),其中每个神经元被视为一个函数,计算隐藏层的激活值。虽然重和激活值在隐藏层和输入层都是二值化的,但输入层并未二值化,而是使用5-b表示。
这个BNN架构使用MATLAB将MNIST图像从28x28缩小到10x10,并量化到5b,然后将其馈送到DNN的第一层。DNN包括两个隐藏层,每个隐藏层由96个神经元组成。每个神经元都是由一个SRAM列实现的,用于内存计算。
在BNN中,使用ReLU激活函数,并通过Theano库进行反向传播和重更新。使用基于平方铰链函数的损失函数,并使用ADAM自适应学习进行最小化。
在训练过程中,利用片上前向传播来获得一组可用于内存计算系推理的模型重。这不仅允许表示由于精度降低而导致的误差,还允许表示和通过重调优来解决由于模拟非理想而导致的误差。
基于 sram 的内存计算系统中各列偏移的硬件补偿,
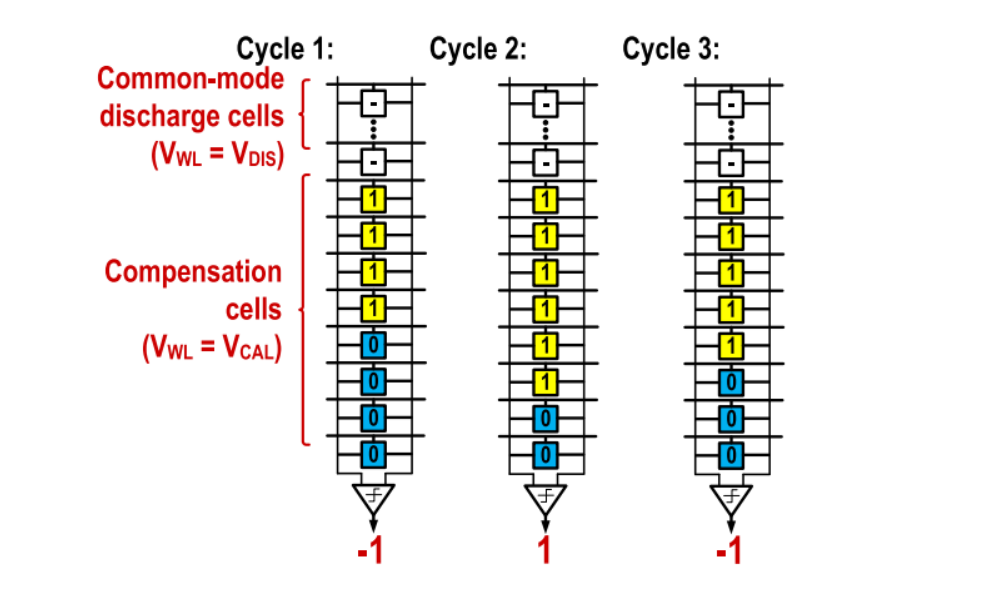
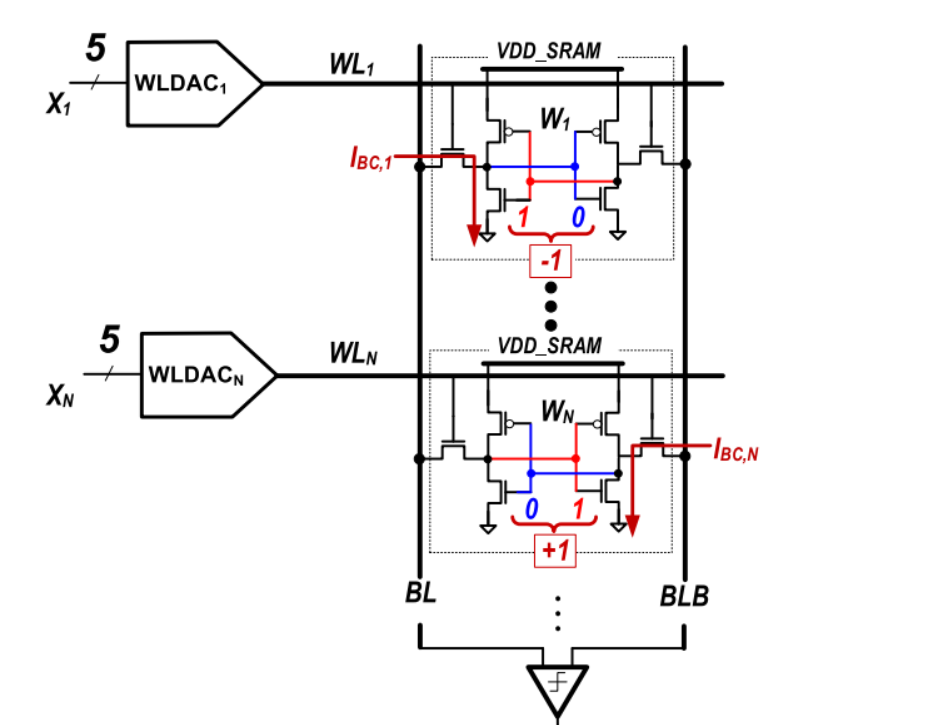
首先,我们提出了一种基于硬件的补偿方法,用于减轻由比较器失配引起的每列偏移。这种方法已经在文献[6]中使用。如上图,我们使用8行SRAM进行补偿,尽管实际使用的系统具有32行。通过存储在这些行中的数据来对BIBLB放电进行偏置,其中偏置可以通过为该列存储的位单元值对每列进行完成。所有列的最优值可以使用二叉搜索算法高效且并行地确定。
在算法的开始,每列中的补偿位单元格的一半被设置为1,另一半被设置为0。当断言单词行时,补偿行名义上导致相等的BL/BL放电,因此比较器可以决定每列中的偏移量。补偿位单元的值被相应地调整,以抵消如图所示的偏移量,并重复此过程,调整存储值的数量是以前的一半,直到仅调整一行中的值。
最后,最终的偏移量对应于一个补偿行引入的放电偏置量。通过选择补偿行数和用于补偿行的字线电压,可以在补偿范围和补偿粒度之间实现平衡。因此,补偿字线电压与其他字线电压有选择地不同。
归一化
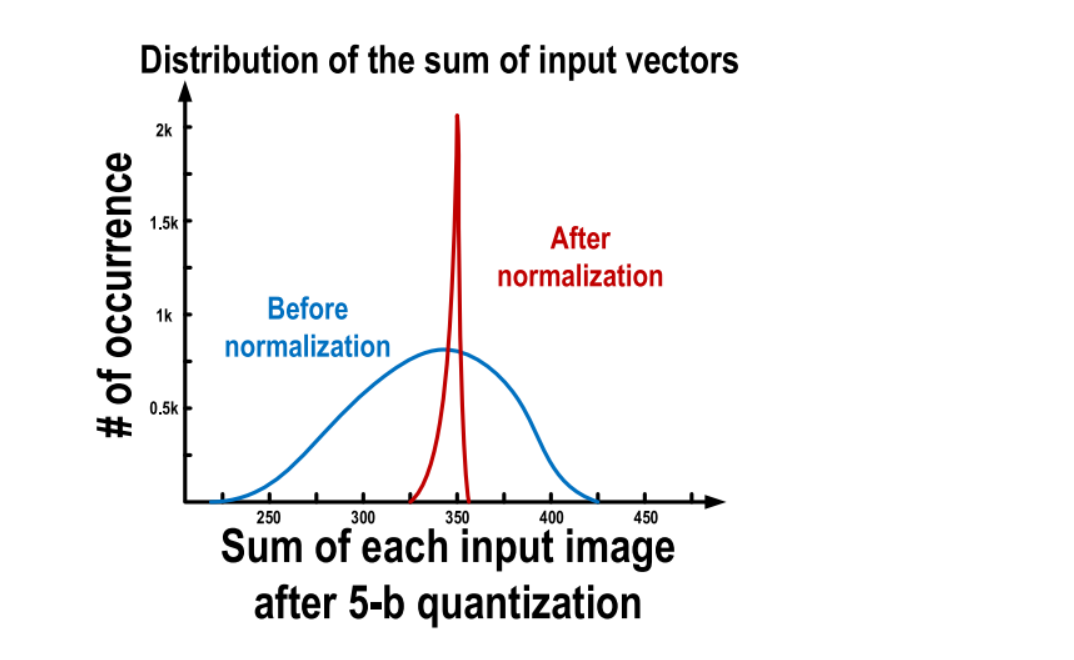
第二种方法涉及对 5-b输入图像数据进行归一化,以确保模拟偏置的某些一致性,从而减轻非线性的影响。例如,位单元电流和比较器偏置电压都是 BL/BLB 值的强函数。
系统演示
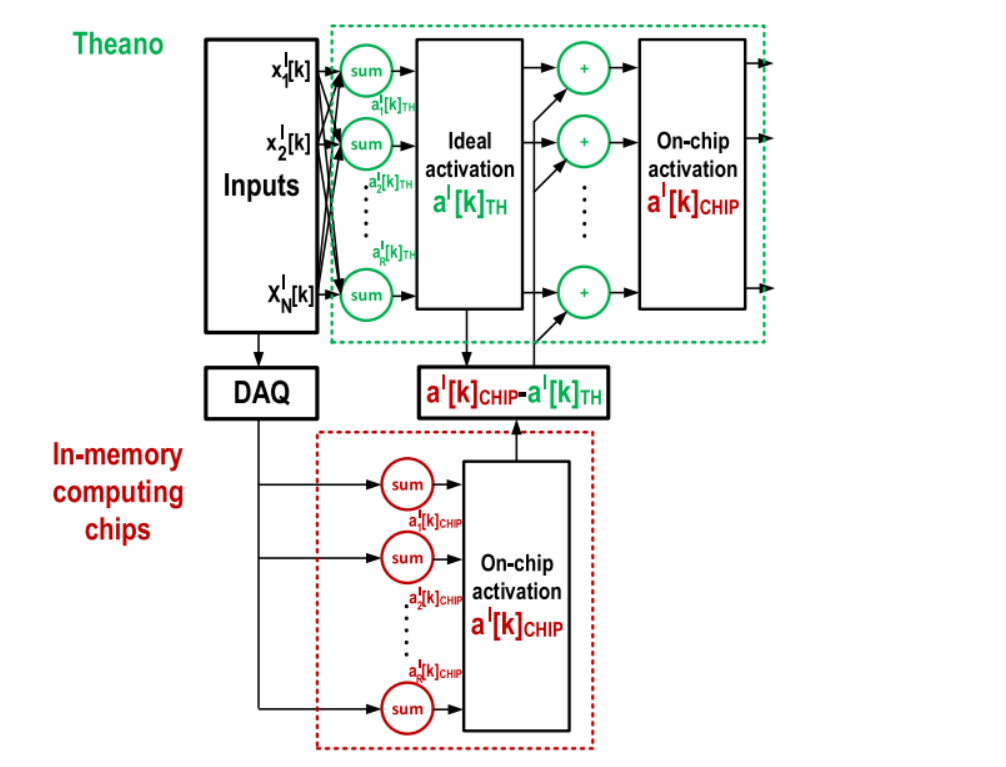
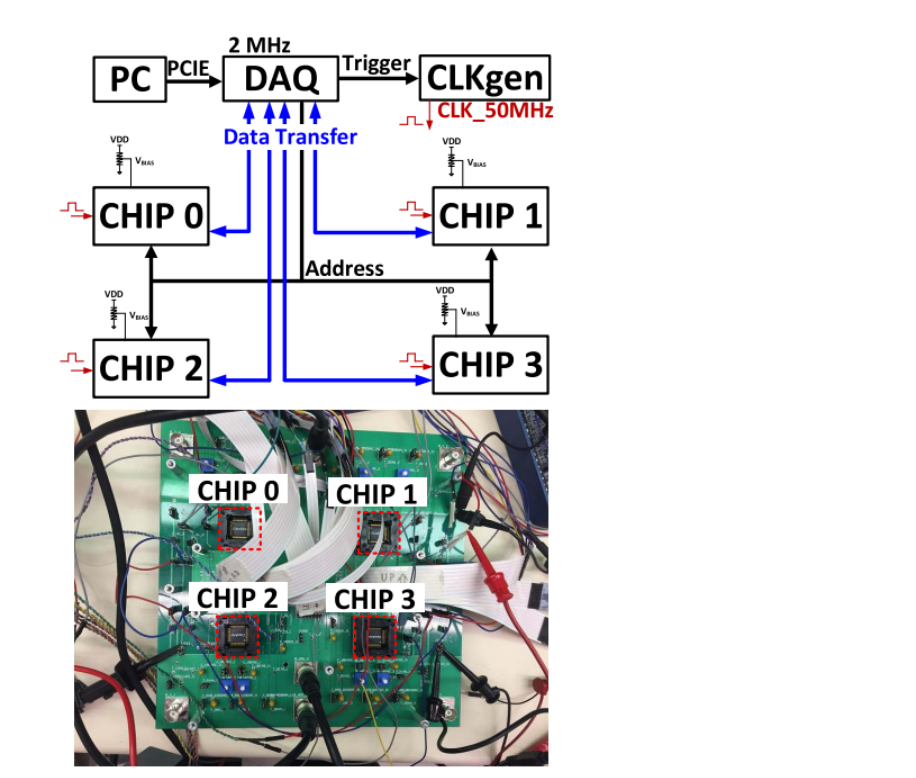
为进行系统演示,构建下图所示的4芯片系统。该系统与[27]中使用的系统类似,但设置和配置不同。在这个应用中,三层只需要四个芯片中的三个。在片上BNN 系统中,硬件只用于前向传播,无论是在训练还是测试中。如第三节所述,反向传播和权重更新由 Theano 处理。芯片和Theano之间的数据通过 matlab 控制的 DAO 交换。在此过程中,计算第 III-D 节中提到的批量归一化,从芯片获得的激活值a在发送到后续芯片之前被归一化并转换为5位数字。
总结
基于二值化值和激活的MNIST分类的BNN实现,利用标准6T SRAM位单元进行内存计算。通过使用这种方法,将神经网络中通常需要的MAC操作减少为逐位操作,从而大大减小了模型的大小,节约了能量,同时保持了存储在内存中的重量不变
随着人工智能和大数据时代的到来,深度神经网络(DNN)在计算机领域中得到了广泛应用。DNN具有较高的准确度和广泛的应用领域,如语音识别、图像识别等。然而,DNN的计算成本较高,需要大量的标记样本和计算时间。为了解决这一问题,随机梯度优化算法被提出,用于加快DNN的训练速度。同时,二值化神经网络(BNN)也被提出,通过减少神经网络中的权重和激活值的数量,降低计算和存储成本。在内存计算体系结构中,基于SRAM的内存计算系统可以提供高效的计算和存储能力,但需要对各列偏移进行硬件补偿。归一化操作也是DNN中不可或缺的一部分,能够有效提高模型的收敛速度和准确度。
![Android 数据恢复电脑版免费下载使用方法 [2024 更新]](https://img-blog.csdnimg.cn/direct/52ea438f49bc44bfbe9a4e280b4fc9ff.png)