文章目录
- @[TOC]
- 基于Kaggle电信用户流失案例数据(可在官网进行下载)
- 逻辑回归模型训练
- 逻辑回归的超参数调优
文章目录
- @[TOC]
- 基于Kaggle电信用户流失案例数据(可在官网进行下载)
- 逻辑回归模型训练
- 逻辑回归的超参数调优
基于Kaggle电信用户流失案例数据(可在官网进行下载)
数据预处理部分可见:
机器学习数据预处理方法(数据重编码)
逻辑回归模型训练
from sklearn.metrics import accuracy_score, recall_score, precision_score, f1_score, roc_auc_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
# 其中train就是训练数据集,同时包含训练集的特征和标签
train, test = train_test_split(tcc, test_size=0.3, random_state=21)
# 划分特征和标签
X_train = train.drop(columns=[ID_col, target]).copy()
y_train = train['Churn'].copy()
X_test = test.drop(columns=[ID_col, target]).copy()
y_test = test['Churn'].copy()
# 检验列是否划分完全
assert len(category_cols) + len(numeric_cols) == X_train.shape[1]
# 设置转化器流
logistic_pre = ColumnTransformer([
('cat', preprocessing.OneHotEncoder(drop='if_binary'), category_cols),
('num', 'passthrough', numeric_cols)
])
# 实例化逻辑回归评估器
logistic_model = LogisticRegression(max_iter=int(1e8))
# 设置机器学习流
logistic_pipe = make_pipeline(logistic_pre, logistic_model)
logistic_pipe.fit(X_train, y_train)
运行得到模型整体结构
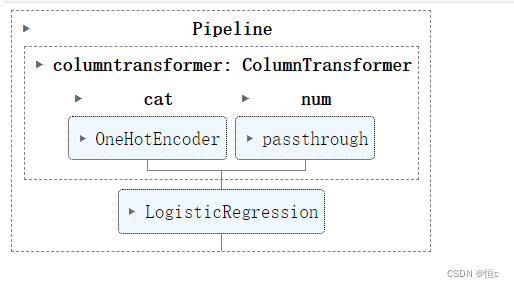
- 查看模型结果(最初结果)
# 定义模型评估指标函数
def result_df(model, X_train, y_train, X_test, y_test, metrics=
[accuracy_score, recall_score, precision_score, f1_score, roc_auc_score]):
res_train = []
res_test = []
col_name = []
for fun in metrics:
res_train.append(fun(model.predict(X_train), y_train))
res_test.append(fun(model.predict(X_test), y_test))
col_name.append(fun.__name__)
idx_name = ['train_eval', 'test_eval', ]
res = pd.DataFrame([res_train, res_test],columns=col_name,index=idx_name)
return res
result_df(logistic_pipe,X_train,y_train,X_test,y_test)

逻辑回归的超参数调优
逻辑回归评估器损失函数方程如下:

而逻辑回归评估器的所有参数解释如下:
| 参数 | 解释 |
|---|---|
| penalty | 正则化项 |
| dual | 是否求解对偶问题* |
| tol | 迭代停止条件:两轮迭代损失值差值小于tol时,停止迭代 |
| C | 经验风险和结构风险在损失函数中的权重 |
| fit_intercept | 线性方程中是否包含截距项 |
| intercept_scaling | 相当于此前讨论的特征最后一列全为1的列,当使用liblinear求解参数时用于捕获截距 |
| class_weight | 各类样本权重* |
| random_state | 随机数种子 |
| solver | 损失函数求解方法* |
| max_iter | 求解参数时最大迭代次数,迭代过程满足max_iter或tol其一即停止迭代 |
| multi_class | 多分类问题时求解方法* |
| verbose | 是否输出任务进程 |
| warm_start | 是否使用上次训练结果作为本次运行初始参数 |
| l1_ratio | 当采用弹性网正则化时, l 1 l1 l1正则项权重,就是损失函数中的 ρ \rho ρ |
而在这些所有超参数中,对模型结果影响较大的参数主要有两类,其一是正则化项的选择,同时也包括经验风险项的系数与损失求解方法选择,第二类则是迭代限制条件,主要是max_iter和tol两个参数,当然,在数据量较小、算力允许的情况下,我们也可以直接设置较大max_iter、同时设置较小tol数值。由于我们并未考虑带入数据本身的膨胀系数(共线性),因此此处我们优先考虑围绕经验风险系数与正则化选择类参数进行搜索与优化。
而整个网格搜索过程其实就是一个将所有参数可能的取值一一组合,然后计算每一种组合下模型在给定评估指标下的交叉验证的结果(验证集上的平均值),作为该参数组合的得分,然后通过横向比较(比较不同参数组合的得分),来选定最优参数组合。要使用网格搜索,首先我们需要设置参数空间,也就是带入哪些参数的哪些取值进行搜索。需要注意的是,由于我们现在是直接选用机器学习流进行训练,此时逻辑回归的超参数的名称会发生变化,我们可以通过机器学习流的.get_param来获取集成在机器学习流中的逻辑回归参数名称:
然后,我们选取正则化项、经验风险权重项C、弹性网正则化中l1正则化的比例项l1_ratio、以及求解器solver作为搜索超参数,来构建超参数空间:
from sklearn.model_selection import GridSearchCV
logistic_param = [
{'logisticregression__penalty': ['l1'], 'logisticregression__C': np.arange(0.1, 2.1, 0.1).tolist(), 'logisticregression__solver': ['saga']},
{'logisticregression__penalty': ['l2'], 'logisticregression__C': np.arange(0.1, 2.1, 0.1).tolist(), 'logisticregression__solver': ['lbfgs', 'newton-cg', 'sag', 'saga']},
{'logisticregression__penalty': ['elasticnet'], 'logisticregression__C': np.arange(0.1, 2.1, 0.1).tolist(), 'logisticregression__l1_ratio': np.arange(0.1, 1.1, 0.1).tolist(), 'logisticregression__solver': ['saga']}
]
接下来执行网格搜索,在网格搜索评估器的使用过程中,只需要输入搜索的评估器(也就是机器学习流)和评估器的参数空间即可,当然若想提高运行速度,可以在n_jobs中输入调用进程数,一般保守情况数值可以设置为当前电脑核数。此外,由于我们目前是以准确率作为评估指标,因此在实例化评估器时无需设置评估指标参数。
# 实例化网格搜索评估器
logistic_search = GridSearchCV(estimator = logistic_pipe,
param_grid = logistic_param,
n_jobs = 4)
import time
# 在训练集上进行训练
s = time.time()
logistic_search.fit(X_train, y_train)
print(time.time()-s, "s")
运行时间:
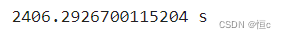
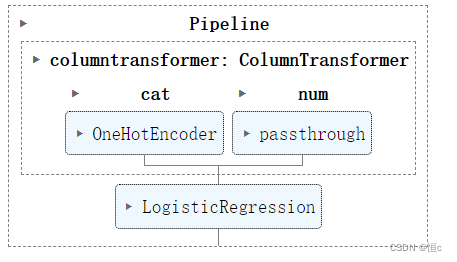
# 调用最佳参数的机器学习流评估器
logistic_search.best_estimator_
# 计算预测结果
result_df(logistic_search.best_estimator_, X_train, y_train, X_test, y_test)