阶段性测试和阶段性代码合集
- 一.编写测试程序-server.cc
- 二.一些问题
- 三.完整源代码
在这里添加了一些打印信息,方便我们观察,由于比较分散就不一一列举,可以看下面的完整源代码。
一.编写测试程序-server.cc
1.原版
只是简单的测试,就不写过程了。
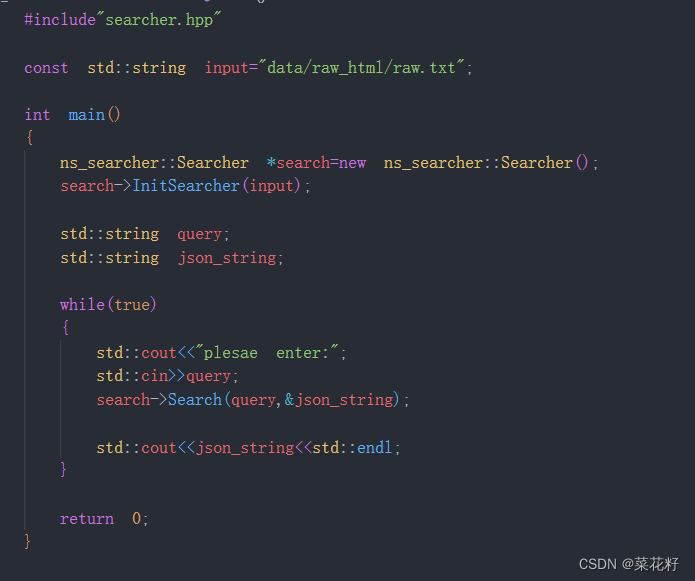


可以看到它把所有包含filename的文档直接打印出来了,很明显并不方便我们进行查阅,所以进行修改,让content只显示一部分即可。
2.修改版本
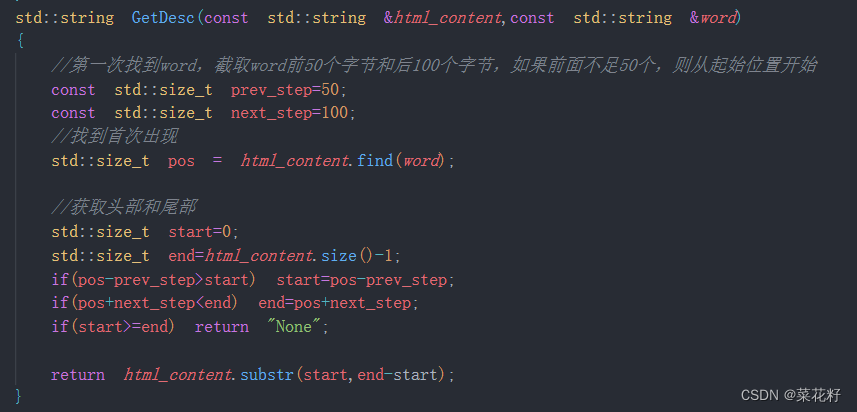
在searcher里建立获取摘要的过程。


二.一些问题
1.坑一:读取
这里我们直接使用cin读取是会出现问题的,因为当cin遇到空格时就会停止,所以如果一句话里有空格的话就会多次读取。下面进行修改,使用getline进行读取。

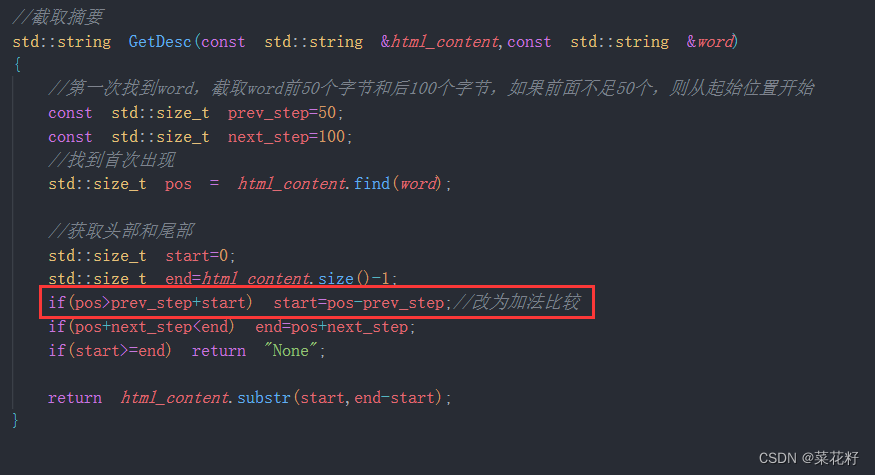
2.坑二:size_t是无符号整型
我们在取摘要时,用的是size_t,如果减数大于被减数它就会得出一个很大的数,所以我们把它改为加法比较。
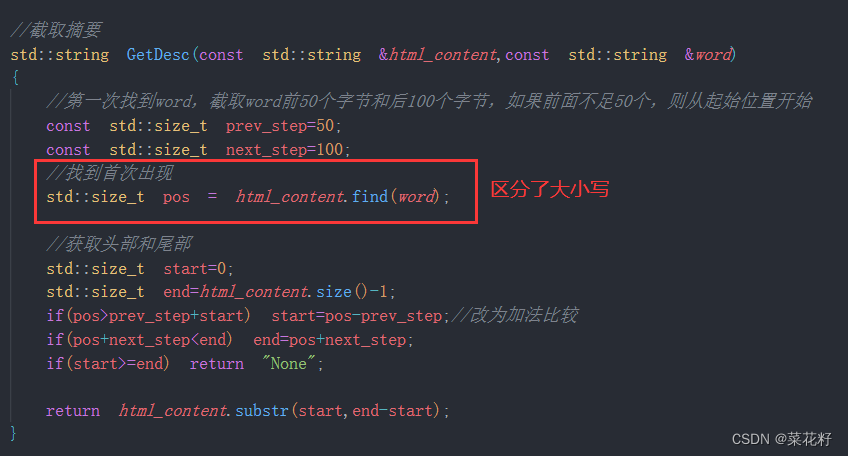
3.坑三:大小写
我们在建立倒排索引时是忽略了大小写的,但是我们使用string.find()查找词时又是区分了大小写的,所以会导致查找错误。

进行改正,可以使用Boost库里提供的方法,这里我使用search。

三.完整源代码

index.hpp
#include <vector>
#include <iostream>
#include <string>
#include <unordered_map>
#include <fstream>
#include <mutex>
#include "util.hpp"
namespace ns_index
{
// 正排索引
struct DocInfo
{
std::string title;
std::string content;
std::string url;
uint64_t id;
};
// 倒排索引
struct InvertedElem
{
uint64_t id;
std::string word; // 关键词
int weight; // 权重
};
typedef std::vector<InvertedElem> InvertedList;
class Index
{
private:
// 正排索引用数组,数组下标天然就是文档ID
std::vector<DocInfo> forward_index; // 正排索引
// 倒排索引是映射关系,一个关键字和一个(组)InvertedElem对应
std::unordered_map<std::string, std::vector<InvertedElem>> inverted_index; // 倒排索引
private:
Index() {}
Index(const Index &) = delete;
Index &operator=(const Index &) = delete;
static std::mutex mtx; // 锁
static Index *instance; // 单例指针
public:
static Index *GetInstance() // 获取单例接口
{
if (nullptr == instance) // 该判段是为了加速,防止堵塞
{
mtx.lock(); // 上锁
if (nullptr == instance)
{
instance = new Index();
}
mtx.unlock(); // 解锁
}
return instance;
}
~Index()
{
}
public:
// 根据doc_id找到文档内容
DocInfo *GetForwardIndex(uint64_t doc_id)
{
if (doc_id >= forward_index.size())
{
std::cerr << "doc_id is not range!" << std::endl;
return nullptr;
}
return &forward_index[doc_id];
}
// 根据关键字string,获得倒排拉链
std::vector<InvertedElem> *GetInvertedList(const std::string &word)
{
auto iter = inverted_index.find(word);
if (iter == inverted_index.end())
{
std::cerr << word << "have no Inverted" << std::endl;
return nullptr;
}
return &(iter->second);
}
// 根据文档构建索引
bool BuildIndex(const std::string &input)
{
// 构建读取文件对象
std::ifstream in(input);
if (!in.is_open())
{
std::cerr << input << " open err!!!!!" << std::endl;
return false;
}
std::string line;
int count = 0;
while (getline(in, line))
{
DocInfo *doc = BuildForwardIndex(line); // 构建正排索引
if (nullptr == doc)
{
std::cerr << "build:" << line << "error!" << std::endl;
continue;
}
BuildInvertedIndex(*doc);
count++;
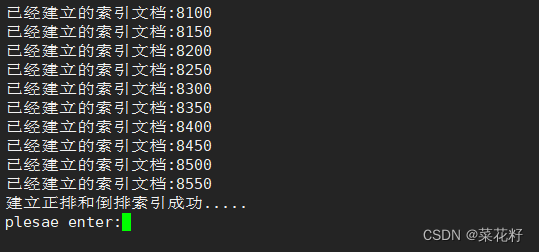
if (count % 50 == 0)
{
std::cout << "已经建立的索引文档:" << count << std::endl;
}
}
return true;
}
private:
// 建立正排索引
DocInfo *BuildForwardIndex(const std::string &line)
{
std::vector<std::string> results;
std::string sep = "\3";
ns_util::StringUtil::Split(line, &results, sep); // 分割字符串
if (results.size() != 3)
return nullptr;
// 进行填充
DocInfo doc;
doc.title = results[0];
doc.content = results[1];
doc.url = results[2];
doc.id = forward_index.size(); // 用数组下标代表id
forward_index.push_back(std::move(doc)); // 细节:加move避免拷贝
return &(forward_index.back());
}
// 建立倒排索引
bool BuildInvertedIndex(DocInfo &doc)
{
// 分词
std::unordered_map<std::string, int> word_map; // 进行权重统计
// 1.分title
std::vector<std::string> title;
ns_util::JiebaUtil::CutString(doc.title, &title);
for (auto &s : title) // 标题为10
{
boost::to_lower(s); // 忽略大小写
word_map[s] += 10;
}
// 2.分content
std::vector<std::string> content;
ns_util::JiebaUtil::CutString(doc.content, &content);
for (auto &s : content) // 内容为1
{
boost::to_lower(s); // 忽略大小写
word_map[s]++;
}
// 3.放入hash表中
for (auto &word_pair : word_map)
{
InvertedElem item;
item.id = doc.id;
item.word = word_pair.first;
item.weight = word_pair.second;
inverted_index[word_pair.first].push_back(std::move(item)); // 细节避免拷贝
}
}
};
Index *Index::instance = nullptr; // 在类外初始化
std::mutex Index::mtx;
}
makefile
.PHONY:all
all:parser search
search:server.cc
g++ -o $@ $^ -ljsoncpp -std=c++11
parser:parser.cc
g++ -o $@ $^ -lboost_system -lboost_filesystem -std=c++11
.PHONY:clean
clean:
rm -f parser search
parser.cc
include <iostream>
#include <vector>
#include <string>
#include <boost/filesystem.hpp>
#include "util.hpp"
const std::string src_path = "data/input/"; // 要读取的文件路径
const std::string output = "data/raw_html/raw.txt"; // 存放处理后文件路径
typedef struct DocInfo
{
std::string title; // 文档标题
std::string content; // 文档内容
std::string url; // 文档路径
} DocInfo_t;
// const &:表示输入
//&:输入输出
//*:输出
bool EnumFile(const std::string &src_path, std::vector<std::string> *files_lists);
bool ParseHtml(const std::vector<std::string> &files_lists, std::vector<DocInfo_t> *results);
bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output);
int main()
{
// 第一步:读取目标文件的路径和文件名
std::vector<std::string> files_lists;
if (!EnumFile(src_path, &files_lists))
{
std::cerr << "enum file error" << std::endl;
return 1;
}
// 第二步:把读取的文件按照格式进行解析
std::vector<DocInfo_t> results;
if (!ParseHtml(files_lists, &results))
{
std::cerr << "parse html error" << std::endl;
return 2;
}
// 第三步:把解析后的文件输出到output路径里
if (!SaveHtml(results, output))
{
std::cerr << "save html error" << std::endl;
return 3;
}
return 0;
}
bool EnumFile(const std::string &src_path, std::vector<std::string> *files_lists)
{
// 定义一个path对象,从当前路径开始查找
boost::filesystem::path root_path(src_path);
if (!boost::filesystem::exists(root_path)) // 如果当前路径不存在就返回false
{
std::cerr << src_path << "not exists" << std::endl;
return false;
}
// 定义一个空的迭代器,判断是否结束
boost::filesystem::recursive_directory_iterator end;
// 开始递归搜索
for (boost::filesystem::recursive_directory_iterator iter(root_path); iter != end; iter++)
{
// 如果不是普通文件,跳过
if (!boost::filesystem::is_regular_file(*iter))
{
continue;
}
// 如果不是以html结尾,跳过
if (iter->path().extension() != ".html")
{
continue;
}
// 测试代码,之后删除
// std::cout<<"debug"<<iter->path().string()<<std::endl;
// 将满足条件的网页的路径存入
files_lists->push_back(iter->path().string());
}
return true;
}
static bool ParaseTitle(const std::string &file, std::string *title)
{
std::size_t begin = file.find("<title>");
if (begin == std::string::npos)
return false;
begin += 7;
std::size_t end = file.find("</title>");
if (end == std::string::npos)
return false;
if (begin > end)
return false;
*title = file.substr(begin, end - begin);
return true;
}
static bool ParseContent(const std::string &file, std::string *content)
{
// 一个简易的状态机
enum state
{
LABEL,
CONTENT
};
// 初始化为LABEL
enum state s = LABEL;
for (char c : file)
{
switch (s)
{
case LABEL:
if (c == '>')
s = CONTENT;
break;
case CONTENT:
if (c == '<')
s = LABEL;
else
{
// 我们不想要原始文档里的换行符,因为我们想用\n作为之后文档分隔符
if (c == '\n')
c = ' ';
content->push_back(c);
}
break;
default:
break;
}
}
return true;
}
static bool ParseUrl(const std::string &file, std::string *url)
{
std::string head = "https://www.boost.org/doc/libs/1_84_0/doc/html/";
std::string tail = file.substr(src_path.size());
*url = head + tail;
return true;
}
bool ParseHtml(const std::vector<std::string> &files_lists, std::vector<DocInfo_t> *results)
{
for (const std::string &file : files_lists)
{
// 1.读取文件
std::string result;
if (!ns_util::FillUtil::ReadFile(file, &result))
{
continue;
}
DocInfo_t doc;
// 提取title
if (!ParaseTitle(result, &doc.title))
{
continue;
}
// 提取content
if (!ParseContent(result, &doc.content))
{
continue;
}
// 提取URL
if (!ParseUrl(file, &doc.url))
{
continue;
}
// 放入结果
results->push_back(std::move(doc));//细节;因为直接使用push_back会发生拷贝,为了提高效率使用move
// 测试代码
// std::cout<<"title:"<<doc.title<<std::endl;
// std::cout<<"content:"<<doc.content<<std::endl;
// std::cout<<"url:"<<doc.url<<std::endl;
// break;
}
return true;
}
bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output)
{
// 创建输出对象
std::ofstream out(output);
if (!out.is_open())
{
std::cerr << "open:" << output << "failed!" << std::endl;
return false;
}
// 将其格式化
for (auto &item : results)
{
std::string result;
result += item.title;
result += '\3';
result += item.content;
result += '\3';
result += item.url;
result += '\n';
out.write(result.c_str(), result.size());
}
out.close();
return true;
}
searcher.hpp
#include "index.hpp"
#include <algorithm>
#include <jsoncpp/json/json.h>
namespace ns_searcher
{
class Searcher
{
private:
ns_index::Index *index; // 供系统查找的接口
public:
Searcher()
{
}
~Searcher()
{
}
public:
// 初始化
void InitSearcher(const std::string &input)
{
// 1.创建Index对象
index = ns_index::Index::GetInstance();
std::cout << "获取index单例成功....." << std::endl;
// 2.创建索引
index->BuildIndex(input);
std::cout << "建立正排和倒排索引成功....." << std::endl;
}
// 查找
void Search(const std::string &query, std::string *json_string)
{
// 1.分词
std::vector<std::string> words; // 存放词
ns_util::JiebaUtil::CutString(query, &words);
// 2.触发:根据分词找到对应倒排拉链(注意:要忽略大小写)
// 为了方便,这里经过了typedef,把倒排hash的second(vector<InvertedElem>)重命名成了InvertedList
ns_index::InvertedList inverted_list_all; // 存放所有找到的文档的倒排拉链
for (auto &s : words)
{
boost::to_lower(s); // 忽略大小写
ns_index::InvertedList *inverted_list = index->GetInvertedList(s); // 根据string获取倒排拉链
if (nullptr == inverted_list)
continue;
inverted_list_all.insert(inverted_list_all.end(), inverted_list->begin(), inverted_list->end());
}
// 3.进行汇总排序
class Less
{
public:
bool operator()(const ns_index::InvertedElem &e1, const ns_index::InvertedElem &e2)
{
return e1.weight > e2.weight;
}
};
std::sort(inverted_list_all.begin(), inverted_list_all.end(), Less());
// std::sort(inverted_list_all.begin(), inverted_list_all.end(), [](const ns_index::InvertedElem &e1, const ns_index::InvertedElem &e2)
// { e1.weight > e2.weight; });
// 4.构建jsoncpp串
Json::Value root;
for (auto &item : inverted_list_all)
{
ns_index::DocInfo *doc = index->GetForwardIndex(item.id); // 通过正排索引获取文档
if (nullptr == doc)
continue;
Json::Value elem;
elem["title"] = doc->title;
elem["desc"] = GetDesc(doc->content, item.word); // 我们只需要展示一部分内容即可,这里以后会改
elem["url"] = doc->url;
//for DeBUG 测试权重,这里由于分词原因,所以权重可能不如我们预期
//elem["id"]=(int)item.id;
//elem["weight"]=item.weight;
root.append(elem);
}
Json::StyledWriter writer;
*json_string = writer.write(root); // 写入目标文件
}
// 截取摘要
std::string GetDesc(const std::string &html_content, const std::string &word)
{
// 第一次找到word,截取word前50个字节和后100个字节,如果前面不足50个,则从起始位置开始
const std::size_t prev_step = 50;
const std::size_t next_step = 100;
// 找到首次出现
// 忽略大小写
auto iter = std::search(html_content.begin(), html_content.end(), word.begin(), word.end(), [](int x, int y)
{ return std::tolower(x) == std::tolower(y); });
if (iter == html_content.end())
return "None1";
std::size_t pos = std::distance(html_content.begin(), iter);
// 获取头部和尾部
std::size_t start = 0;
std::size_t end = html_content.size() - 1;
if (pos > prev_step + start)
start = pos - prev_step; // 改为加法比较
if (pos + next_step < end)
end = pos + next_step;
if (start >= end)
return "None2";
return html_content.substr(start, end - start);
}
};
}
server.cc
#include"searcher.hpp"
const std::string input="data/raw_html/raw.txt";
int main()
{
ns_searcher::Searcher *search=new ns_searcher::Searcher();
search->InitSearcher(input);
std::string query;
std::string json_string;
while(true)
{
std::cout<<"Plesae Enter Your Search Query:";
getline(std::cin,query);
search->Search(query,&json_string);
std::cout<<json_string<<std::endl;
}
return 0;
}
util.hpp
#include <iostream>
#include <string>
#include <fstream>
#include <boost/algorithm/string.hpp>
#include "cppjieba/Jieba.hpp"
namespace ns_util
{
class FillUtil
{
public:
static bool ReadFile(const std::string &file_path, std::string *out)
{
std::ifstream in(file_path); // 创建对象,这种创建模式,默认打开文件
// 判断文件是否打开
if (!in.is_open())
{
std::cerr << "open file" << file_path << "error" << std::endl;
return false;
}
// 读取文件,按行读取
std::string line;
while (std::getline(in, line)) // getline的返回值是istream类型,但该类内部进行了重载,所以可以直接判断
{
*out += line;
}
// 关闭文件
in.close();
return true;
}
};
class StringUtil
{
public:
static void Split(const std::string &target, std::vector<std::string> *out, const std::string &sep)
{
boost::split(*out, target, boost::is_any_of(sep), boost::token_compress_on);
}
};
const char *const DICT_PATH = "./dict/jieba.dict.utf8";
const char *const HMM_PATH = "./dict/hmm_model.utf8";
const char *const USER_DICT_PATH = "./dict/user.dict.utf8";
const char *const IDF_PATH = "./dict/idf.utf8";
const char *const STOP_WORD_PATH = "./dict/stop_words.utf8";
class JiebaUtil
{
public:
// 构建jieba对象
static cppjieba::Jieba jieba;
public:
static void CutString(const std::string &src, std::vector<std::string> *out)
{
jieba.CutForSearch(src, *out);
}
};
cppjieba::Jieba JiebaUtil::jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH);
}