LLaVA:GPT-4V(ision) 的新开源替代品。

LLaVA (https://llava-vl.github.io/,是 Large Language 和Visual A ssistant的缩写)。它是一种很有前景的开源生成式 AI 模型,它复制了 OpenAI GPT-4 在与图像对话方面的一些功能。
用户可以将图像添加到 LLaVA 聊天对话中,可以以聊天方式讨论这些图像的内容,还可以将它们用作以视觉方式描述想法、上下文或情况等方式。
LLaVA 最引人注目的功能是它能够改进其他开源解决方案,同时使用更简单的模型架构和更少的训练数据。这些特性使得 LLaVA 不仅训练速度更快、成本更低,而且更适合在消费类的硬件上进行推理。

本篇文章将概述 LLaVA,其目标如下:
展示如何从网页界面进行试验,以及如何将其安装在您的计算机或笔记本电脑上
详细解释其主要技术特性
说明如何使用它进行编程,以使用 Google Colab 上的 HuggingFace 库( Transformers和Gradio )构建的简单聊天机器人应用程序为例。
在线使用 LLaVA
如果你还没有尝试过它,使用 LLaVA 最简单的方法是访问其作者提供的Web 界面。
下面的屏幕截图说明了其界面的运行方式,用户根据冰箱内容的图片询问要做什么饭菜。可以使用左侧的小部件加载图像,其聊天界面允许用户以文本形式提出问题并获得答案。
访问地址:https://llava.hliu.cc/
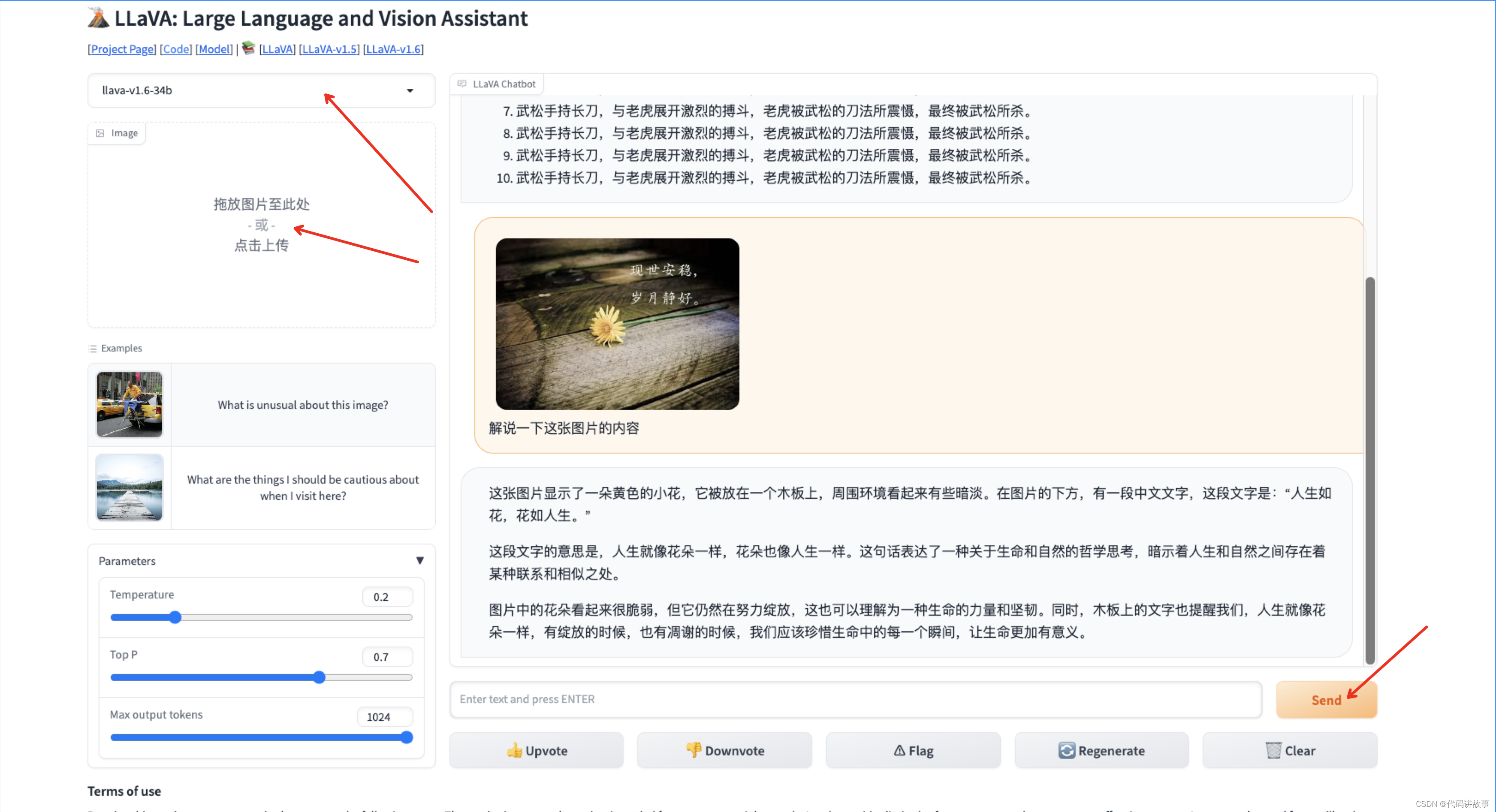
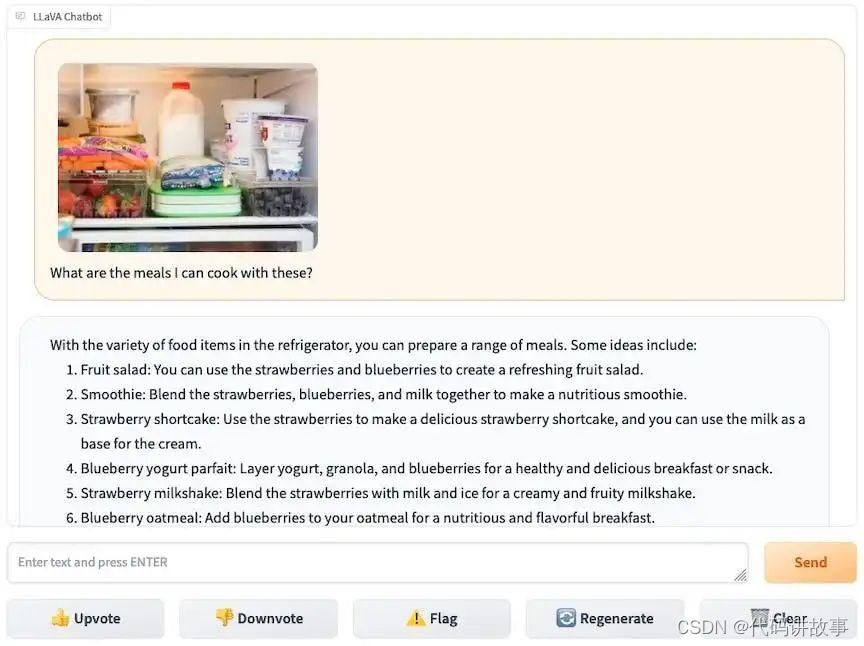
LLaVA 网页界面:https://llava.hliu.cc/
在上面的对话示例中,LLaVA 已经正确识别了冰箱中存在的成分,例如蓝莓、草莓、胡萝卜、酸奶或牛奶,并提出相关建议,例如水果沙拉、冰沙或蛋糕。
该项目网站(
https://llava-vl.github.io/)上还给出了与 LLaVA 对话的其他示例,这说明了 LLaVA 不仅能够描述图像,还能够根据图像中的元素进行推理和推理(使用图片中的线索识别电影或人,从绘图中编写一个网站,解释段子文案等)。
如何本地运行 LLaVA
LLaVA 还可以使用Ollama(https://ollama.ai/)或 Mozilla ’ llamafile’ (
https://github.com/Mozilla-Ocho/llamafile)安装在本地计算机上。
这些工具可以在大多数仅使用 CPU 的消费级机器上运行,因为该模型仅需要 8GB RAM 和 4GB 可用磁盘空间,甚至被证明可以在 Raspberry PI (相关链接:
https://towardsdatascience.com/running-local-llms-and-vlms-on-the-raspberry-pi-57bd0059c41a)上成功运行。
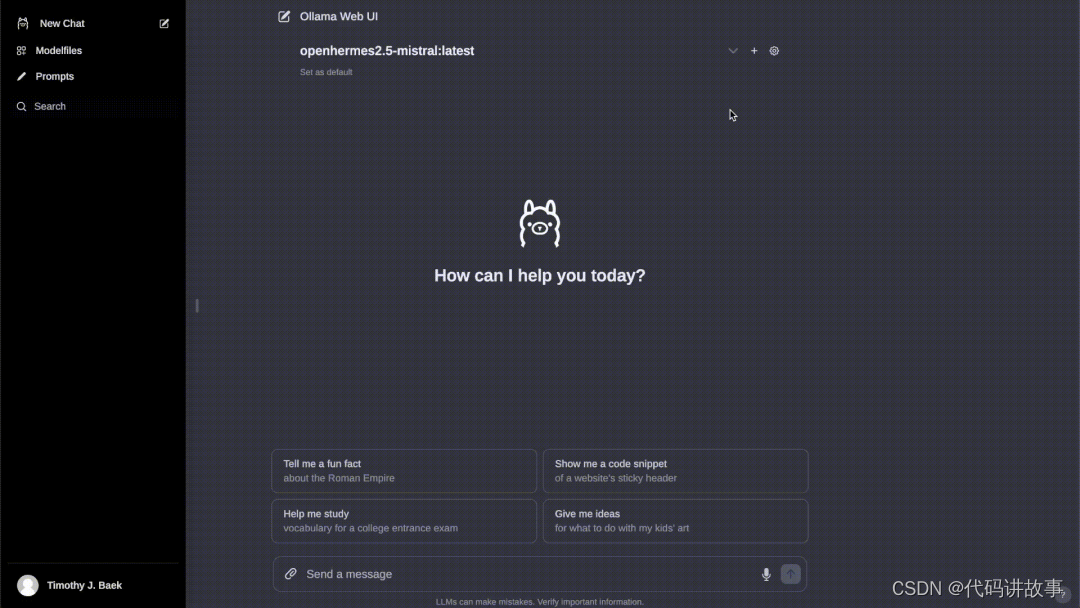
在围绕 Ollama 项目开发的工具和界面中,一个值得注意的举措是Ollama-WebUI(如下所示),它再现了 OpenAI ChatGPT 用户界面的外观和感觉。
LLaVA 主要功能简介
LLaVA 由威斯康星大学麦迪逊分校、微软研究院和哥伦比亚大学的研究人员设计,最近在 NeurIPS 2023 上进行了展示。该项目的代码和技术规范可以在其Github 存储库上访问。该存储库地址如下:
https://github.com/haotian-liu/LLaVA
作者在论文摘要中总结道:
[LLava] 在 11 项基准测试中达到了最先进的水平。我们的最终 13B 检查点仅使用 120 万个公开可用数据,并在单个 8-A100 节点上约 1 天完成完整训练。我们希望这能让最先进的 LMM 研究变得更容易实现。代码和模型将公开。
详细地址:
https://arxiv.org/pdf/2310.03744.pdf
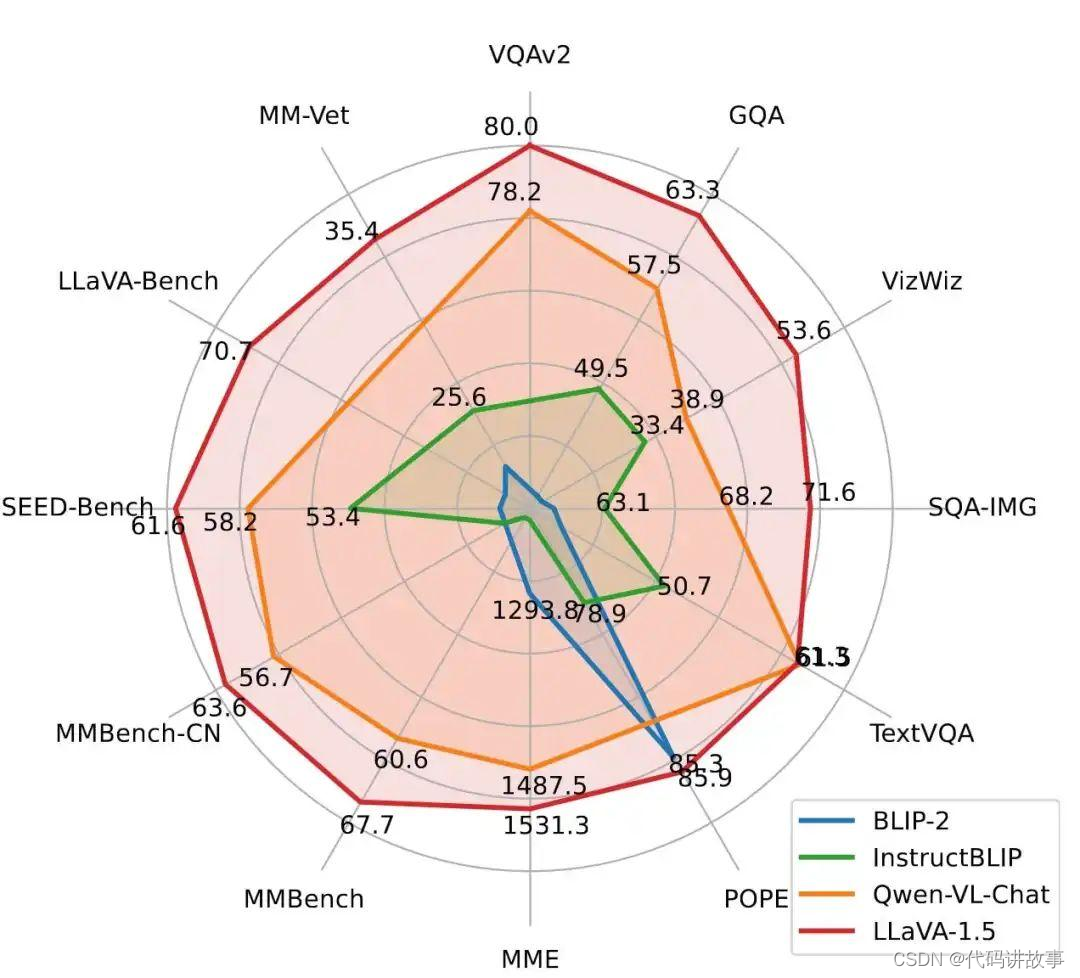
本文中以雷达图形式报告的基准测试结果说明了与其他最先进模型相对比的改进。
LLaVA内部运作流程
LLaVA 的数据处理工作流程在概念上很简单。
该模型本质上作为标准因果语言模型工作,将语言指令(用户文本提示)作为输入,并返回语言响应。语言模型处理图像的能力是由单独的视觉编码器模型实现的,该模型将图像转换为语言标记,这些标记被悄悄地添加到用户文本提示中(充当一种软提示)。
LLaVA 执行过程,来看下图所示。
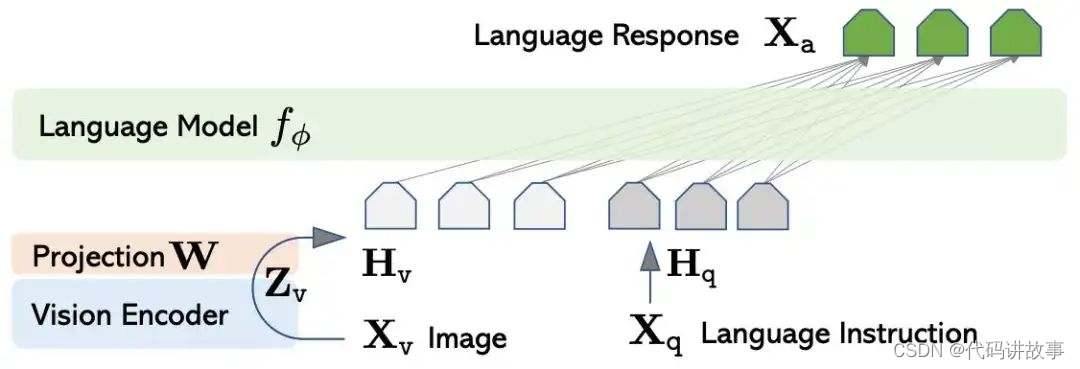
LLaVA 的语言模型和视觉编码器分别依赖于两个参考模型:Vicuna 和 CLIP。
Vicuna基于 LLaMA-2(由 Meta 设计)的预训练大型语言模型,其性能与中型 LLM 具有竞争力。
CLIP (https://openai.com/research/clip)是 OpenAI 设计的图像编码器,经过预训练,可使用对比语言图像预训练(因此称为“CLIP”)在类似的嵌入空间中对图像和文本进行编码。
LLaVA 中使用的模型是视觉变换器变体 CLIP-ViT-L/14(请参阅HuggingFace 上的模型卡)。
为了将视觉编码器的维度与语言模型的维度相匹配,应用了投影模块(上图中的W )。它是原始LLaVA中的简单线性投影,以及LLaVA 1.5中的两层感知器。
训练流程
LLaVA 的训练过程由两个相对简单的阶段组成。
第一阶段目标在调整投影模块W,并且视觉编码器和LLM的权重保持冻结。使用来自CC3M 概念字幕数据集的大约 600k 图像/字幕对的子集来执行训练,并且可以在该存储库的HuggingFace 上找到。
在第二阶段,使用 158K 语言图像指令跟踪数据的数据集,对投影模块权重W与 LLM 权重一起进行微调(同时保持视觉编码器的权重冻结)。数据是使用 GPT4 生成的,具有对话示例、详细描述和复杂推理,也可在 HuggingFace 上的存储库中获取。
整个训练大约需要一天时间,使用 8 个 A100 GPU。
使用 LLaVA 编程:如何开始
LLaVA 模型集成在 Transformers 库中,可以使用标准管道对象加载。模型的 7B 和 13B 变体可在LLaVA GitHub 空间上使用,并且可以以 4 和 8 位加载以节省 GPU 内存。下面我们将说明如何使用可在具有 T4 TPU(15GB RAM GPU)的 Colab 上执行的代码来加载和运行模型。
下面是以 4 位加载 LLaVA 1.5 的 7B 变体的代码片段:
from transformers import pipeline, BitsAndBytesConfig
import torch
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
model_id = "llava-hf/llava-1.5-7b-hf"
pipe = pipeline("image-to-text", model=model_id, model_kwargs={"quantization_config": quantization_config})
使用标准的PIL库来加载图片:
import requests
from PIL import Image
image_url = "https://cdn.pixabay.com/photo/2018/01/29/14/13/italy-3116211_960_720.jpg"
image = Image.open(requests.get(image_url, stream=True).raw)
image
最后让我们用图像查询 LLaVA 模型,并提示要求描述图片。提示格式如下
“USER: \n\nASSISTANT:”
prompt = "USER: <image>\nDescribe this picture\nASSISTANT:"
outputs = pipe(image, prompt=prompt, generate_kwargs={"max_new_tokens": 200})
print(outputs[0]['generated_text'])
它将返回以下答案:
用户:请描述一下这张图片
助理:图片上有一个巨大的、空荡荡的圆形剧场,背景是令人惊叹的海洋景色。圆形剧场周围是郁郁葱葱的绿色山坡,远处可以看到雄伟的山峰。景色宁静而美丽,阳光照耀着大地。
LLaVA 聊天机器人
我们最终创建一个依赖于 LLaVA 模型的简单聊天机器人。我们将使用Gradio 库,它提供了一种快速、简单的方法来创建机器学习 Web 界面。
该界面的核心由一行图像上传器(一个 Gradio Image 对象)和一个聊天界面(一个 Gradio ChatInterface对象)组成。
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
image = gr.Image(type='pil', interactive=True)
gr.ChatInterface(
update_conversation, additional_inputs=[image]
)
聊天界面连接到一个函数update_conversation,该函数负责保存对话历史记录,并在用户发送消息时调用 LLaVA 模型进行响应。
def update_conversation(new_message, history, image):
if image is None:
return "Please upload an image first using the widget on the left"
conversation_starting_from_image = [[user, assistant] for [user, assistant] in history if not assistant.startswith('Please')]
prompt = "USER: <image>\n"
for i in range(len(history)):
prompt+=history[i][0]+'ASSISTANT: '+history[i][1]+"USER: "
prompt = prompt+new_message+'ASSISTANT: '
outputs = pipe(image, prompt=prompt, generate_kwargs={"max_new_tokens": 200, "do_sample" : True, "temperature" : 0.7})[0]['generated_text']
return outputs[len(prompt)-6:]
调用launch方法启动界面。
demo.launch(debug=True)
几秒钟后,将出现聊天机器人 Web 界面:
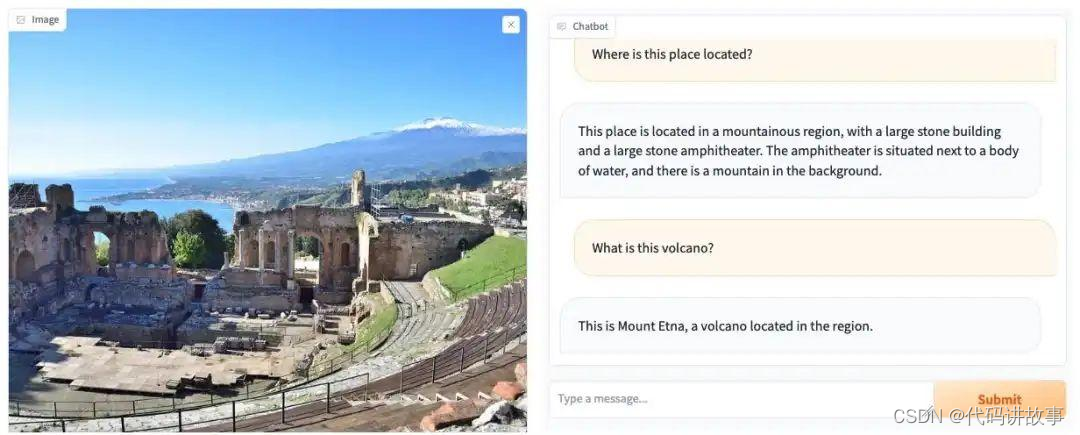
恭喜,您的 LLaVA 聊天机器人现在已经启动,并成功运行!
相关参考链接:
HuggingFace LLaVA 模型文档:
https://huggingface.co/docs/transformers/model_doc/llava
Llava 抱脸组织
https://huggingface.co/llava-hf
使用 AutoPrecessor 和 LLaVAForConditionalGeneration 加载并运行 LLaVA:Colab 笔记本
https://colab.research.google.com/drive/1_q7cOB-jCu3RExrkhrgewBR0qKjZr-Sx
GPT-4V(ision)系统卡
https://cdn.openai.com/papers/GPTV_System_Card.pdf
视觉指令调整
https://newsletter.artofsaience.com/p/understanding-visual-instruction