原文:Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
译者:飞龙
协议:CC BY-NC-SA 4.0
第三章:分类
在第一章中,我提到最常见的监督学习任务是回归(预测值)和分类(预测类)。在第二章中,我们探讨了一个回归任务,使用各种算法(如线性回归、决策树和随机森林)来预测房屋价值(这将在后面的章节中进一步详细解释)。现在我们将把注意力转向分类系统。
MNIST
在本章中,我们将使用 MNIST 数据集,这是由美国人口普查局的高中学生和员工手写的 70,000 张小数字图像集。每个图像都带有它代表的数字标签。这个数据集已经被研究了很多次,通常被称为机器学习的“hello world”:每当人们提出一个新的分类算法时,他们都很好奇它在 MNIST 上的表现如何,任何学习机器学习的人迟早都会处理这个数据集。
Scikit-Learn 提供许多辅助函数来下载流行的数据集。MNIST 就是其中之一。以下代码从 OpenML.org 获取 MNIST 数据集:¹
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', as_frame=False)
sklearn.datasets包主要包含三种类型的函数:fetch_*函数,如fetch_openml()用于下载真实数据集,load_*函数用于加载与 Scikit-Learn 捆绑的小型玩具数据集(因此不需要通过互联网下载),以及make_*函数用于生成虚假数据集,对测试很有用。生成的数据集通常作为包含输入数据和目标的(X, y)元组返回,都作为 NumPy 数组。其他数据集作为sklearn.utils.Bunch对象返回,这些对象是字典,其条目也可以作为属性访问。它们通常包含以下条目:
"DESCR"
数据集描述
“数据”
输入数据,通常作为 2D NumPy 数组
“目标”
标签,通常作为 1D NumPy 数组
fetch_openml()函数有点不同,因为默认情况下它将输入返回为 Pandas DataFrame,将标签返回为 Pandas Series(除非数据集是稀疏的)。但是 MNIST 数据集包含图像,而 DataFrame 并不理想,因此最好设置as_frame=False以将数据作为 NumPy 数组获取。让我们看看这些数组:
>>> X, y = mnist.data, mnist.target
>>> X
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
>>> X.shape
(70000, 784)
>>> y
array(['5', '0', '4', ..., '4', '5', '6'], dtype=object)
>>> y.shape
(70000,)
共有 70,000 张图像,每张图像有 784 个特征。这是因为每个图像是 28×28 像素,每个特征只是表示一个像素的强度,从 0(白色)到 255(黑色)。让我们看一下数据集中的一个数字(图 3-1)。我们只需要获取一个实例的特征向量,将其重塑为 28×28 数组,并使用 Matplotlib 的imshow()函数显示它。我们使用cmap="binary"来获取一个灰度色图,其中 0 是白色,255 是黑色:
import matplotlib.pyplot as plt
def plot_digit(image_data):
image = image_data.reshape(28, 28)
plt.imshow(image, cmap="binary")
plt.axis("off")
some_digit = X[0]
plot_digit(some_digit)
plt.show()

图 3-1。MNIST 图像示例
这看起来像一个 5,事实上标签告诉我们是这样的:
>>> y[0]
'5'
为了让您感受分类任务的复杂性,图 3-2 显示了 MNIST 数据集中的更多图像。
但是!在仔细检查数据之前,您应该始终创建一个测试集并将其放在一边。fetch_openml()返回的 MNIST 数据集实际上已经分为训练集(前 60,000 张图像)和测试集(最后 10,000 张图像):²
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
训练集已经为我们洗牌,这很好,因为这保证了所有交叉验证折叠将是相似的(我们不希望一个折叠缺少一些数字)。此外,一些学习算法对训练实例的顺序敏感,如果它们连续获得许多相似实例,则表现会很差。洗牌数据集确保这种情况不会发生。³
图 3-2。来自 MNIST 数据集的数字
训练二元分类器
现在,让我们简化问题,只尝试识别一个数字,例如数字 5。这个“5 检测器”将是一个二元分类器的示例,能够区分只有两个类别的 5 和非 5。首先,我们将为这个分类任务创建目标向量:
y_train_5 = (y_train == '5') # True for all 5s, False for all other digits
y_test_5 = (y_test == '5')
现在让我们选择一个分类器并对其进行训练。一个很好的开始地方是使用随机梯度下降(SGD,或随机 GD)分类器,使用 Scikit-Learn 的SGDClassifier类。这个分类器能够高效处理非常大的数据集。部分原因是因为 SGD 独立处理训练实例,一次一个,这也使得 SGD 非常适合在线学习,稍后您将看到。让我们创建一个SGDClassifier并在整个训练集上对其进行训练:
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_5)
现在我们可以使用它来检测数字 5 的图像:
>>> sgd_clf.predict([some_digit])
array([ True])
分类器猜测这幅图像代表数字 5(True)。在这种特殊情况下,看起来它猜对了!现在,让我们评估这个模型的性能。
性能指标
评估分类器通常比评估回归器要困难得多,因此我们将在本章的大部分时间中讨论这个主题。有许多性能指标可用,所以抓杯咖啡,准备学习一堆新概念和首字母缩略词!
使用交叉验证测量准确率
评估模型的一个好方法是使用交叉验证,就像您在第二章中所做的那样。让我们使用cross_val_score()函数来评估我们的SGDClassifier模型,使用三折交叉验证。请记住,k-fold 交叉验证意味着将训练集分成k折(在本例中为三折),然后训练模型k次,每次保留一个不同的折叠用于评估(参见第二章):
>>> from sklearn.model_selection import cross_val_score
>>> cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy")
array([0.95035, 0.96035, 0.9604 ])
哇!在所有交叉验证折叠中超过 95%的准确率(正确预测的比例)?看起来很惊人,不是吗?好吧,在你太兴奋之前,让我们看一个只将每个图像分类为最频繁类别的虚拟分类器,这种情况下是负类别(即非 5):
from sklearn.dummy import DummyClassifier
dummy_clf = DummyClassifier()
dummy_clf.fit(X_train, y_train_5)
print(any(dummy_clf.predict(X_train))) # prints False: no 5s detected
您能猜到这个模型的准确率吗?让我们找出来:
>>> cross_val_score(dummy_clf, X_train, y_train_5, cv=3, scoring="accuracy")
array([0.90965, 0.90965, 0.90965])
没错,它的准确率超过 90%!这仅仅是因为大约 10%的图像是 5,所以如果您总是猜测一幅图像不是 5,您将有 90%的准确率。胜过诺斯特拉达姆。
这说明为什么准确率通常不是分类器的首选性能指标,特别是当您处理倾斜数据集(即某些类别比其他类别更频繁时)。评估分类器性能的一个更好方法是查看混淆矩阵(CM)。
混淆矩阵
混淆矩阵的一般思想是计算类 A 的实例被分类为类 B 的次数,对于所有 A/B 对。例如,要知道分类器将 8 的图像误判为 0 的次数,您将查看混淆矩阵的第 8 行,第 0 列。
计算混淆矩阵,首先需要一组预测结果,以便与实际目标进行比较。您可以对测试集进行预测,但最好现在保持不变(记住,您只想在项目的最后阶段使用测试集,一旦您准备启动分类器)。相反,您可以使用cross_val_predict()函数:
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)
就像cross_val_score()函数一样,cross_val_predict()执行k-fold 交叉验证,但不返回评估分数,而是返回在每个测试折叠上做出的预测。这意味着您可以获得训练集中每个实例的干净预测(“干净”是指“样本外”:模型对训练期间从未见过的数据进行预测)。
现在您已经准备好使用confusion_matrix()函数获取混淆矩阵。只需将目标类(y_train_5)和预测类(y_train_pred)传递给它:
>>> from sklearn.metrics import confusion_matrix
>>> cm = confusion_matrix(y_train_5, y_train_pred)
>>> cm
array([[53892, 687],
[ 1891, 3530]])
混淆矩阵中的每一行代表一个实际类别,而每一列代表一个预测类别。该矩阵的第一行考虑了非 5 的图像(负类):其中 53,892 个被正确分类为非 5(称为真负例),而剩下的 687 个被错误分类为 5(假正例,也称为类型 I 错误)。第二行考虑了 5 的图像(正类):其中 1,891 个被错误分类为非 5(假阴性,也称为类型 II 错误),而剩下的 3,530 个被正确分类为 5(真正例)。一个完美的分类器只会有真正例和真负例,因此其混淆矩阵只会在其主对角线上有非零值(从左上到右下):
>>> y_train_perfect_predictions = y_train_5 # pretend we reached perfection
>>> confusion_matrix(y_train_5, y_train_perfect_predictions)
array([[54579, 0],
[ 0, 5421]])
混淆矩阵提供了很多信息,但有时您可能更喜欢一个更简洁的指标。一个有趣的指标是正预测的准确率;这被称为分类器的精度(方程 3-1)。
方程 3-1。精度
精度 = TP TP+FP
TP是真正例的数量,FP是假正例的数量。
实现完美精度的一个微不足道的方法是创建一个分类器,总是做出负预测,除了在它最有信心的实例上做出一个单一的正预测。如果这一个预测是正确的,那么分类器的精度就是 100%(精度=1/1=100%)。显然,这样的分类器不会很有用,因为它会忽略除了一个正实例之外的所有实例。因此,精度通常与另一个指标一起使用,该指标称为召回率,也称为敏感度或真正例率(TPR):这是分类器正确检测到的正实例的比率(方程 3-2)。
方程 3-2。回想一下
召回率 = TP TP+FN
FN,当然,是假阴性的数量。
如果您对混淆矩阵感到困惑,图 3-3 可能会有所帮助。
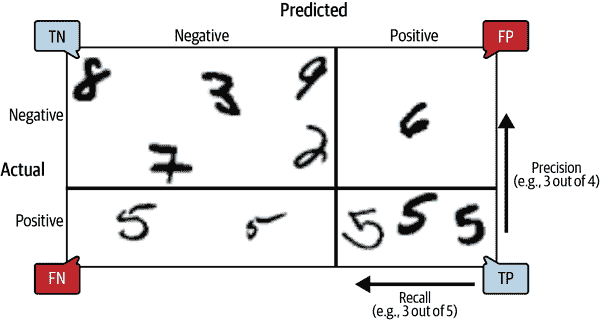
图 3-3。一个说明混淆矩阵的示例,显示真负例(左上)、假正例(右上)、假阴性(左下)和真正例(右下)
精度和召回率
Scikit-Learn 提供了几个函数来计算分类器的指标,包括精度和召回率:
>>> from sklearn.metrics import precision_score, recall_score
>>> precision_score(y_train_5, y_train_pred) # == 3530 / (687 + 3530)
0.8370879772350012
>>> recall_score(y_train_5, y_train_pred) # == 3530 / (1891 + 3530)
0.6511713705958311
现在我们的 5 检测器看起来并不像我们在查看其准确性时那么出色。当它声称一幅图像代表 5 时,它只有 83.7%的时间是正确的。此外,它只能检测到 65.1%的 5。
通常方便将精度和召回率结合成一个称为F[1]分数的单一指标,特别是当您需要一个单一指标来比较两个分类器时。 F[1]分数是精度和召回率的调和平均(方程 3-3)。而普通平均值对所有值都一视同仁,调和平均值更加重视低值。因此,只有当召回率和精度都很高时,分类器才会获得高的 F[1]分数。
方程 3-3。F[1]分数
F 1 = 2 1 精度+1 召回率 = 2 × 精度×召回率 精度+召回率 = TP TP+FN+FP 2
要计算 F[1]分数,只需调用f1_score()函数:
>>> from sklearn.metrics import f1_score
>>> f1_score(y_train_5, y_train_pred)
0.7325171197343846
F[1]分数偏向于具有类似精度和召回率的分类器。这并不总是你想要的:在某些情境下,你更关心精度,而在其他情境下,你真的很在意召回率。例如,如果你训练一个用于检测适合儿童观看的视频的分类器,你可能更喜欢一个拒绝许多好视频(低召回率)但仅保留安全视频(高精度)的分类器,而不是一个召回率更高但让一些非常糟糕的视频出现在你的产品中的分类器(在这种情况下,你甚至可能想添加一个人工流水线来检查分类器的视频选择)。另一方面,假设你训练一个用于在监控图像中检测扒手的分类器:如果你的分类器只有 30%的精度,只要召回率达到 99%就可以了(当然,保安人员会收到一些错误警报,但几乎所有扒手都会被抓住)。
不幸的是,你不能两全其美:提高精度会降低召回率,反之亦然。这被称为精度/召回率权衡。
精度/召回率权衡
为了理解这种权衡,让我们看看SGDClassifier是如何做出分类决策的。对于每个实例,它根据决策函数计算得分。如果该得分大于阈值,则将实例分配给正类;否则将其分配给负类。图 3-4 显示了一些数字,从最低得分的左侧到最高得分的右侧。假设决策阈值位于中间箭头处(两个 5 之间):你会发现在该阈值右侧有 4 个真正例(实际为 5),以及 1 个假正例(实际上是 6)。因此,使用该阈值,精度为 80%(5 个中的 4 个)。但在 6 个实际为 5 的情况下,分类器只检测到 4 个,因此召回率为 67%(6 个中的 4 个)。如果提高阈值(将其移动到右侧的箭头处),假正例(6)变为真负例,从而增加精度(在这种情况下最高可达 100%),但一个真正例变为假负例,将召回率降低到 50%。相反,降低阈值会增加召回率并降低精度。
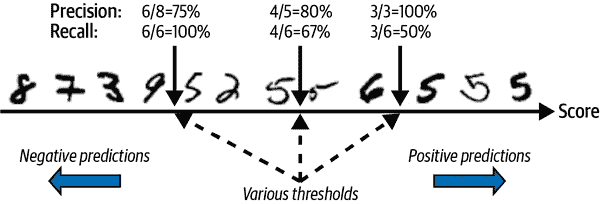
图 3-4。精度/召回率权衡:图像按其分类器得分排名,高于所选决策阈值的图像被视为正例;阈值越高,召回率越低,但(一般而言)精度越高
Scikit-Learn 不允许直接设置阈值,但它确实让您访问它用于做出预测的决策得分。您可以调用分类器的decision_function()方法,而不是调用predict()方法,该方法返回每个实例的得分,然后根据这些得分使用任何阈值进行预测:
>>> y_scores = sgd_clf.decision_function([some_digit])
>>> y_scores
array([2164.22030239])
>>> threshold = 0
>>> y_some_digit_pred = (y_scores > threshold)
array([ True])
SGDClassifier使用阈值等于 0,因此前面的代码返回与predict()方法相同的结果(即True)。让我们提高阈值:
>>> threshold = 3000
>>> y_some_digit_pred = (y_scores > threshold)
>>> y_some_digit_pred
array([False])
这证实了提高阈值会降低召回率。图像实际上代表一个 5,当阈值为 0 时分类器检测到它,但当阈值增加到 3,000 时却错过了它。
如何决定使用哪个阈值?首先,使用cross_val_predict()函数获取训练集中所有实例的分数,但是这次指定要返回决策分数而不是预测:
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,
method="decision_function")
使用这些分数,使用precision_recall_curve()函数计算所有可能阈值的精度和召回率(该函数添加最后一个精度为 0 和最后一个召回率为 1,对应于无限阈值):
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
最后,使用 Matplotlib 绘制精度和召回率作为阈值值的函数(图 3-5)。让我们展示我们选择的 3,000 的阈值:
plt.plot(thresholds, precisions[:-1], "b--", label="Precision", linewidth=2)
plt.plot(thresholds, recalls[:-1], "g-", label="Recall", linewidth=2)
plt.vlines(threshold, 0, 1.0, "k", "dotted", label="threshold")
[...] # beautify the figure: add grid, legend, axis, labels, and circles
plt.show()
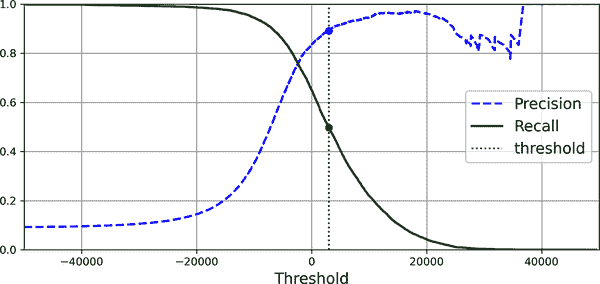
图 3-5. 精度和召回率与决策阈值
注意
你可能会想知道为什么图 3-5 中的精度曲线比召回率曲线更加崎岖。原因是当你提高阈值时,精度有时会下降(尽管通常会上升)。要理解原因,请回顾图 3-4,注意当你从中心阈值开始,将其向右移动一个数字时会发生什么:精度从 4/5(80%)下降到 3/4(75%)。另一方面,当增加阈值时,召回率只能下降,这解释了为什么其曲线看起来平滑。
在这个阈值下,精度接近 90%,召回率约为 50%。选择一个良好的精度/召回率折衷的另一种方法是直接绘制精度与召回率的图表,如图 3-6 所示(显示相同的阈值):
plt.plot(recalls, precisions, linewidth=2, label="Precision/Recall curve")
[...] # beautify the figure: add labels, grid, legend, arrow, and text
plt.show()
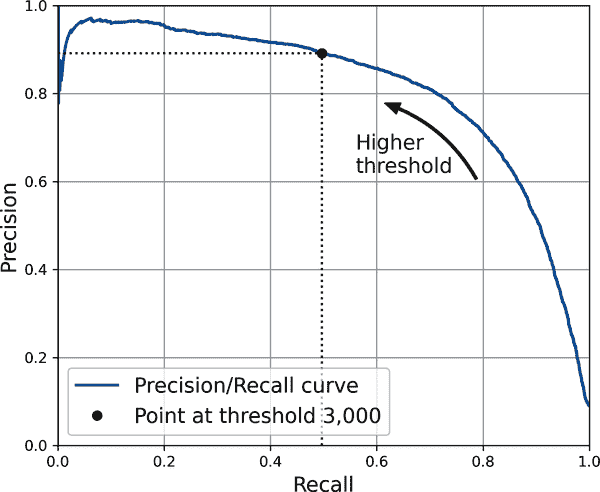
图 3-6. 精度与召回率
你可以看到精度在约 80%的召回率处开始急剧下降。你可能希望在该下降之前选择一个精度/召回率折衷,例如在约 60%的召回率处。但是,选择取决于你的项目。
假设你决定追求 90%的精度。你可以使用第一个图表找到需要使用的阈值,但这不太精确。或者,你可以搜索给出至少 90%精度的最低阈值。为此,你可以使用 NumPy 数组的argmax()方法。这将返回最大值的第一个索引,这在这种情况下意味着第一个True值:
>>> idx_for_90_precision = (precisions >= 0.90).argmax()
>>> threshold_for_90_precision = thresholds[idx_for_90_precision]
>>> threshold_for_90_precision
3370.0194991439557
要进行预测(目前只是在训练集上),而不是调用分类器的predict()方法,你可以运行这段代码:
y_train_pred_90 = (y_scores >= threshold_for_90_precision)
让我们检查这些预测的精度和召回率:
>>> precision_score(y_train_5, y_train_pred_90)
0.9000345901072293
>>> recall_at_90_precision = recall_score(y_train_5, y_train_pred_90)
>>> recall_at_90_precision
0.4799852425751706
太棒了,你有一个 90%的精度分类器!正如你所看到的,几乎可以轻松地创建一个任意精度的分类器:只需设置足够高的阈值,就可以了。但是等等,不要那么快——如果召回率太低,高精度的分类器就不太有用!对于许多应用程序来说,48%的召回率根本不好。
提示
如果有人说:“让我们达到 99%的精度”,你应该问:“召回率是多少?”
ROC 曲线
接收者操作特征(ROC)曲线是与二元分类器一起使用的另一个常见工具。它与精度/召回率曲线非常相似,但是 ROC 曲线不是绘制精度与召回率,而是绘制真正例率(召回率的另一个名称)与假正例率(FPR)。FPR(也称为误报率)是被错误分类为正例的负实例的比率。它等于 1 减去真负例率(TNR),即被正确分类为负例的负实例的比率。TNR 也称为特异性。因此,ROC 曲线绘制灵敏度(召回率)与 1-特异性。
要绘制 ROC 曲线,首先使用roc_curve()函数计算各种阈值的 TPR 和 FPR:
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)
然后,您可以使用 Matplotlib 绘制 FPR 与 TPR。以下代码生成图 3-7 中的图。要找到对应于 90%精确度的点,我们需要查找所需阈值的索引。由于在这种情况下,阈值按降序列出,因此我们在第一行上使用<=而不是>=:
idx_for_threshold_at_90 = (thresholds <= threshold_for_90_precision).argmax()
tpr_90, fpr_90 = tpr[idx_for_threshold_at_90], fpr[idx_for_threshold_at_90]
plt.plot(fpr, tpr, linewidth=2, label="ROC curve")
plt.plot([0, 1], [0, 1], 'k:', label="Random classifier's ROC curve")
plt.plot([fpr_90], [tpr_90], "ko", label="Threshold for 90% precision")
[...] # beautify the figure: add labels, grid, legend, arrow, and text
plt.show()
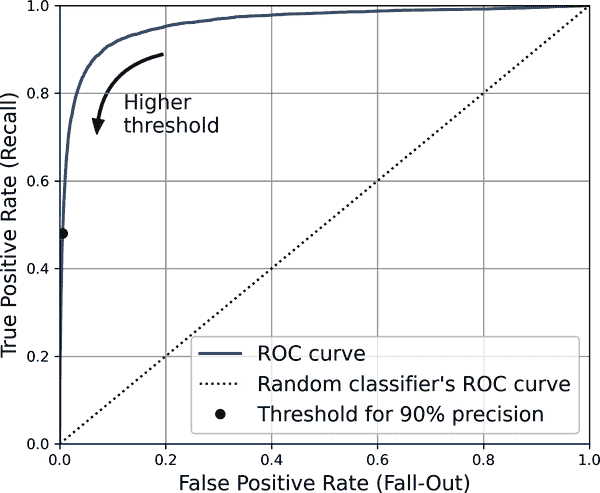
图 3-7。ROC 曲线绘制了所有可能阈值的假阳性率与真阳性率之间的关系;黑色圆圈突出显示了选择的比率(在 90%精确度和 48%召回率处)
再次存在权衡:召回率(TPR)越高,分类器产生的假阳性(FPR)就越多。虚线代表纯随机分类器的 ROC 曲线;一个好的分类器尽可能远离该线(朝向左上角)。
比较分类器的一种方法是测量曲线下面积(AUC)。完美的分类器的 ROC AUC 等于 1,而纯随机分类器的 ROC AUC 等于 0.5。Scikit-Learn 提供了一个估计 ROC AUC 的函数:
>>> from sklearn.metrics import roc_auc_score
>>> roc_auc_score(y_train_5, y_scores)
0.9604938554008616
提示
由于 ROC 曲线与精确率/召回率(PR)曲线非常相似,您可能想知道如何决定使用哪个。作为经验法则,当正类别很少或您更关心假阳性而不是假阴性时,应优先选择 PR 曲线。否则,请使用 ROC 曲线。例如,查看先前的 ROC 曲线(以及 ROC AUC 分数),您可能会认为分类器非常好。但这主要是因为与负例(非 5)相比,正例(5)很少。相比之下,PR 曲线清楚地表明分类器有改进的空间:曲线实际上可以更接近右上角(再次参见图 3-6)。
现在让我们创建一个RandomForestClassifier,我们可以将其 PR 曲线和 F[1]分数与SGDClassifier的进行比较:
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(random_state=42)
precision_recall_curve()函数期望每个实例的标签和分数,因此我们需要训练随机森林分类器并使其为每个实例分配一个分数。但是,由于RandomForestClassifier类的工作方式(我们将在第七章中介绍),它没有decision_function()方法。幸运的是,它有一个predict_proba()方法,为每个实例返回类概率,并且我们可以将正类别的概率作为分数,因此它将正常工作。⁴我们可以调用cross_val_predict()函数,使用交叉验证训练RandomForestClassifier,并使其为每个图像预测类概率,如下所示:
y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3,
method="predict_proba")
让我们看看训练集中前两个图像的类概率:
>>> y_probas_forest[:2]
array([[0.11, 0.89],
[0.99, 0.01]])
模型预测第一幅图像为正面的概率为 89%,并且预测第二幅图像为负面的概率为 99%。由于每幅图像要么是正面要么是负面,因此每行中的概率总和为 100%。
警告
这些是估计概率,而不是实际概率。例如,如果您查看模型将其分类为正面的所有图像,其估计概率在 50%到 60%之间,大约 94%实际上是正面的。因此,在这种情况下,模型的估计概率要低得多,但模型也可能过于自信。sklearn.calibration包含工具,可以校准估计的概率,使其更接近实际概率。有关更多详细信息,请参阅本章笔记本中的额外材料部分。
第二列包含正类别的估计概率,因此让我们将它们传递给precision_recall_curve()函数:
y_scores_forest = y_probas_forest[:, 1]
precisions_forest, recalls_forest, thresholds_forest = precision_recall_curve(
y_train_5, y_scores_forest)
现在我们准备绘制 PR 曲线。为了查看它们的比较,也有必要绘制第一个 PR 曲线(图 3-8):
plt.plot(recalls_forest, precisions_forest, "b-", linewidth=2,
label="Random Forest")
plt.plot(recalls, precisions, "--", linewidth=2, label="SGD")
[...] # beautify the figure: add labels, grid, and legend
plt.show()
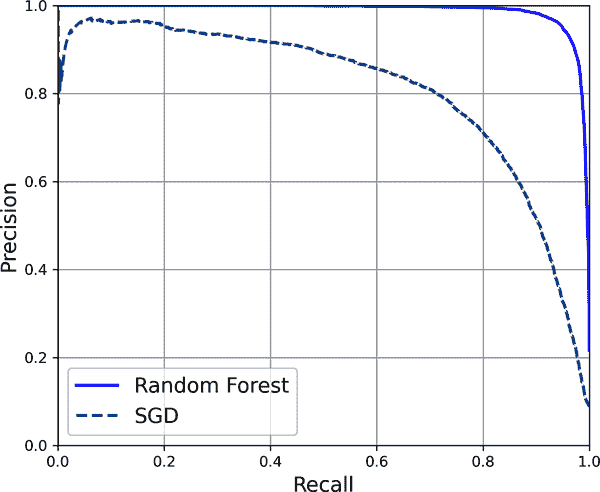
图 3-8。比较 PR 曲线:随机森林分类器优于 SGD 分类器,因为其 PR 曲线更接近右上角,并且具有更大的 AUC
正如您在图 3-8 中所看到的,RandomForestClassifier的 PR 曲线看起来比SGDClassifier的要好得多:它更接近右上角。它的 F[1]分数和 ROC AUC 分数也显著更好:
>>> y_train_pred_forest = y_probas_forest[:, 1] >= 0.5 # positive proba ≥ 50%
>>> f1_score(y_train_5, y_pred_forest)
0.9242275142688446
>>> roc_auc_score(y_train_5, y_scores_forest)
0.9983436731328145
尝试测量精确度和召回率得分:您应该会发现大约 99.1%的精确度和 86.6%的召回率。还不错!
您现在知道如何训练二元分类器,选择适合您任务的适当度量标准,使用交叉验证评估您的分类器,选择适合您需求的精确度/召回率折衷,并使用多种指标和曲线比较各种模型。您已经准备好尝试检测不仅仅是数字 5 了。
多类分类
而二元分类器区分两个类别,多类分类器(也称为多项分类器)可以区分两个以上的类别。
一些 Scikit-Learn 分类器(例如LogisticRegression、RandomForestClassifier和GaussianNB)能够本地处理多个类别。其他严格的二元分类器(例如SGDClassifier和SVC)。然而,有各种策略可用于使用多个二元分类器执行多类分类。
创建一个能够将数字图像分类为 10 个类别(从 0 到 9)的系统的一种方法是训练 10 个二元分类器,每个数字一个(一个 0 检测器,一个 1 检测器,一个 2 检测器,依此类推)。然后,当您想要对一幅图像进行分类时,您会从每个分类器中获取该图像的决策分数,并选择输出最高分数的类别。这被称为一对剩余(OvR)策略,有时也称为一对所有(OvA)。
另一种策略是为每对数字训练一个二元分类器:一个用于区分 0 和 1,另一个用于区分 0 和 2,另一个用于 1 和 2,依此类推。这被称为一对一(OvO)策略。如果有N个类别,您需要训练N×(N - 1)/ 2 个分类器。对于 MNIST 问题,这意味着训练 45 个二元分类器!当您想要对一幅图像进行分类时,您必须通过所有 45 个分类器并查看哪个类别赢得了最多的决斗。OvO 的主要优势在于每个分类器只需要在包含它必须区分的两个类别的训练集部分上进行训练。
一些算法(如支持向量机分类器)随着训练集的大小而扩展得很差。对于这些算法,OvO 更受青睐,因为在小训练集上训练许多分类器比在大训练集上训练少数分类器要快。然而,对于大多数二元分类算法,OvR 更受青睐。
Scikit-Learn 会检测到您尝试将二元分类算法用于多类分类任务时,并根据算法自动运行 OvR 或 OvO。让我们尝试使用sklearn.svm.SVC类中的支持向量机分类器(参见第五章)。我们只会在前 2,000 幅图像上进行训练,否则会花费很长时间:
from sklearn.svm import SVC
svm_clf = SVC(random_state=42)
svm_clf.fit(X_train[:2000], y_train[:2000]) # y_train, not y_train_5
这很容易!我们使用原始目标类别从 0 到 9(y_train)来训练SVC,而不是使用 5 对剩余目标类别(y_train_5)。由于有 10 个类别(即超过 2 个),Scikit-Learn 使用了 OvO 策略并训练了 45 个二元分类器。现在让我们对一幅图像进行预测:
>>> svm_clf.predict([some_digit])
array(['5'], dtype=object)
这是正确的!这段代码实际上进行了 45 次预测——每对类别一次——并选择了赢得最多决斗的类别。如果调用decision_function()方法,您会看到它为每个实例返回 10 个分数:每个类别一个。每个类别得分等于赢得的决斗数加上或减去一个小调整(最大±0.33)以打破平局,基于分类器的分数:
>>> some_digit_scores = svm_clf.decision_function([some_digit])
>>> some_digit_scores.round(2)
array([[ 3.79, 0.73, 6.06, 8.3 , -0.29, 9.3 , 1.75, 2.77, 7.21,
4.82]])
最高分是 9.3,确实对应于类别 5:
>>> class_id = some_digit_scores.argmax()
>>> class_id
5
当分类器训练完成时,它会将目标类别列表存储在其classes_属性中,按值排序。在 MNIST 的情况下,classes_数组中每个类别的索引恰好与类别本身匹配(例如,索引为 5 的类在数组中是类'5'),但通常您不会那么幸运;您需要像这样查找类标签:
>>> svm_clf.classes_
array(['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'], dtype=object)
>>> svm_clf.classes_[class_id]
'5'
如果您想强制 Scikit-Learn 使用一对一或一对多,您可以使用OneVsOneClassifier或OneVsRestClassifier类。只需创建一个实例并将分类器传递给其构造函数(甚至不必是二元分类器)。例如,此代码使用 OvR 策略基于SVC创建一个多类分类器:
from sklearn.multiclass import OneVsRestClassifier
ovr_clf = OneVsRestClassifier(SVC(random_state=42))
ovr_clf.fit(X_train[:2000], y_train[:2000])
让我们进行预测,并检查训练过的分类器数量:
>>> ovr_clf.predict([some_digit])
array(['5'], dtype='<U1')
>>> len(ovr_clf.estimators_)
10
在多类数据集上训练SGDClassifier并使用它进行预测同样简单:
>>> sgd_clf = SGDClassifier(random_state=42)
>>> sgd_clf.fit(X_train, y_train)
>>> sgd_clf.predict([some_digit])
array(['3'], dtype='<U1')
哎呀,那是错误的。预测错误确实会发生!这次 Scikit-Learn 在幕后使用了 OvR 策略:由于有 10 个类别,它训练了 10 个二元分类器。decision_function()方法现在返回每个类别的一个值。让我们看看 SGD 分类器为每个类别分配的分数:
>>> sgd_clf.decision_function([some_digit]).round()
array([[-31893., -34420., -9531., 1824., -22320., -1386., -26189.,
-16148., -4604., -12051.]])
您可以看到分类器对其预测并不是很自信:几乎所有分数都非常负面,而类别 3 的分数为+1,824,类别 5 也不远处为-1,386。当然,您会希望对这个分类器进行多个图像的评估。由于每个类别中的图像数量大致相同,准确度指标是可以接受的。通常情况下,您可以使用cross_val_score()函数来评估模型:
>>> cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy")
array([0.87365, 0.85835, 0.8689 ])
它在所有测试折叠上都超过了 85.8%。如果使用随机分类器,您将获得 10%的准确率,因此这并不是一个很差的分数,但您仍然可以做得更好。简单地缩放输入(如第二章中讨论的)可以将准确率提高到 89.1%以上:
>>> from sklearn.preprocessing import StandardScaler
>>> scaler = StandardScaler()
>>> X_train_scaled = scaler.fit_transform(X_train.astype("float64"))
>>> cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring="accuracy")
array([0.8983, 0.891 , 0.9018])
错误分析
如果这是一个真实的项目,您现在将按照机器学习项目清单中的步骤进行操作(请参阅附录 A)。您将探索数据准备选项,尝试多个模型,列出最佳模型,使用GridSearchCV微调其超参数,并尽可能自动化。在这里,我们假设您已经找到了一个有希望的模型,并且想要找到改进它的方法。其中一种方法是分析它所犯的错误类型。
首先,看一下混淆矩阵。为此,您首先需要使用cross_val_predict()函数进行预测;然后您可以将标签和预测传递给confusion_matrix()函数,就像您之前所做的那样。然而,由于现在有 10 个类别而不是 2 个,混淆矩阵将包含相当多的数字,可能很难阅读。
彩色混淆矩阵图表更容易分析。要绘制这样的图表,请使用ConfusionMatrixDisplay.from_predictions()函数,如下所示:
from sklearn.metrics import ConfusionMatrixDisplay
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred)
plt.show()
这将生成图 3-9 中的左侧图。这个混淆矩阵看起来相当不错:大多数图像都在主对角线上,这意味着它们被正确分类了。请注意,对角线上的第 5 行和第 5 列的单元格看起来比其他数字稍暗。这可能是因为模型在 5 上犯了更多错误,或者因为数据集中的 5 比其他数字少。这就是通过将每个值除以相应(真实)类别中图像的总数(即除以行的总和)来对混淆矩阵进行归一化的重要性。这可以通过简单地设置normalize="true"来完成。我们还可以指定values_format=".0%"参数以显示没有小数的百分比。以下代码生成图 3-9 中右侧的图表:
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred,
normalize="true", values_format=".0%")
plt.show()
现在我们可以很容易地看到,只有 82%的 5 的图像被正确分类。模型在 5 的图像中最常见的错误是将它们错误分类为 8:这发生在所有 5 的 10%中。但只有 2%的 8 被错误分类为 5;混淆矩阵通常不是对称的!如果你仔细观察,你会注意到许多数字被错误分类为 8,但从这个图表中并不立即明显。如果你想让错误更加突出,你可以尝试在正确预测上设置零权重。以下代码就是这样做的,并生成了图 3-10 中左边的图表:
sample_weight = (y_train_pred != y_train)
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred,
sample_weight=sample_weight,
normalize="true", values_format=".0%")
plt.show()
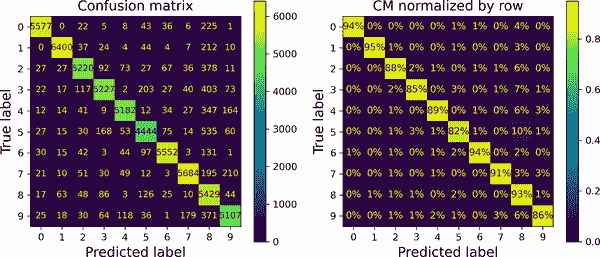
图 3-9。混淆矩阵(左)和相同的通过行归一化的 CM(右)
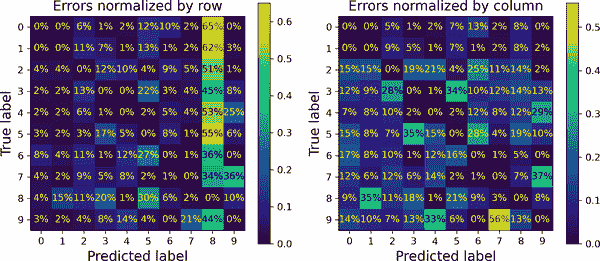
图 3-10。仅显示错误的混淆矩阵,通过行归一化(左)和通过列归一化(右)
现在你可以更清楚地看到分类器所犯的错误类型。类别 8 的列现在非常亮,这证实了许多图像被错误分类为 8。事实上,这是几乎所有类别中最常见的错误分类。但要注意如何解释这个图表中的百分比:记住我们已经排除了正确的预测。例如,第 7 行第 9 列的 36% 不意味着 36%的所有 7 的图像被错误分类为 9。它意味着 36%的模型在 7 的图像上犯的错误被错误分类为 9。实际上,只有 3%的 7 的图像被错误分类为 9,你可以在右边的图表中看到图 3-9。
也可以通过列而不是通过行对混淆矩阵进行归一化:如果设置normalize="pred",你会得到图 3-10 中右边的图表。例如,你可以看到 56%的错误分类的 7 实际上是 9。
分析混淆矩阵通常可以让你了解如何改进你的分类器。从这些图表中看,你的努力应该花在减少错误的 8 上。例如,你可以尝试收集更多看起来像 8 的(但实际上不是)数字的训练数据,这样分类器就可以学会区分它们和真正的 8。或者你可以设计新的特征来帮助分类器,例如,编写一个算法来计算闭环的数量(例如,8 有两个,6 有一个,5 没有)。或者你可以预处理图像(例如,使用 Scikit-Image、Pillow 或 OpenCV)使一些模式,如闭环,更加突出。
分析单个错误也是了解你的分类器在做什么以及为什么失败的好方法。例如,让我们以混淆矩阵样式绘制 3 和 5 的示例(图 3-11):
cl_a, cl_b = '3', '5'
X_aa = X_train[(y_train == cl_a) & (y_train_pred == cl_a)]
X_ab = X_train[(y_train == cl_a) & (y_train_pred == cl_b)]
X_ba = X_train[(y_train == cl_b) & (y_train_pred == cl_a)]
X_bb = X_train[(y_train == cl_b) & (y_train_pred == cl_b)]
[...] # plot all images in X_aa, X_ab, X_ba, X_bb in a confusion matrix style
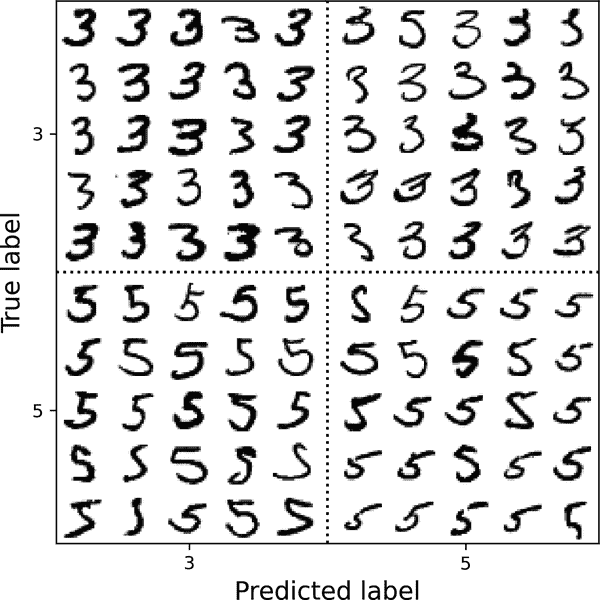
图 3-11。一些 3 和 5 的图像以混淆矩阵的方式组织
正如你所看到的,分类器错误分类的一些数字(即,左下角和右上角的块)写得非常糟糕,即使是人类也会难以分类。然而,大多数错误分类的图像对我们来说似乎是明显的错误。理解分类器为什么犯错可能很困难,但请记住,人类大脑是一个出色的模式识别系统,我们的视觉系统在任何信息到达我们的意识之前都进行了大量复杂的预处理。因此,这个任务看起来简单并不意味着它是简单的。回想一下,我们使用了一个简单的SGDClassifier,它只是一个线性模型:它只是为每个像素分配一个类别权重,当它看到一个新的图像时,它只是将加权像素强度相加以获得每个类别的得分。由于 3 和 5 之间只相差几个像素,这个模型很容易混淆它们。
3s 和 5s 之间的主要区别是连接顶线和底部弧线的小线的位置。如果你画一个 3,连接处稍微向左移动,分类器可能会将其分类为 5,反之亦然。换句话说,这个分类器对图像的移动和旋转非常敏感。减少 3/5 混淆的一种方法是预处理图像,确保它们居中且旋转不太多。然而,这可能并不容易,因为它需要预测每个图像的正确旋转。一个更简单的方法是通过增加训练集中略微移动和旋转的变体来增强训练集。这将迫使模型学会更容忍这些变化。这被称为数据增强(我们将在第十四章中介绍;也请参见本章末尾的练习 2)。
多标签分类
到目前为止,每个实例总是被分配到一个类。但在某些情况下,您可能希望您的分类器为每个实例输出多个类。考虑一个人脸识别分类器:如果它在同一张图片中识别出几个人,它应该做什么?它应该为它识别出的每个人附上一个标签。假设分类器已经训练好了识别三张脸:Alice、Bob 和 Charlie。那么当分类器看到 Alice 和 Charlie 的图片时,它应该输出[True, False, True](意思是“Alice 是,Bob 不是,Charlie 是”)。这样一个输出多个二进制标签的分类系统被称为多标签分类系统。
我们暂时不会讨论人脸识别,但让我们看一个更简单的例子,仅供说明目的:
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
y_train_large = (y_train >= '7')
y_train_odd = (y_train.astype('int8') % 2 == 1)
y_multilabel = np.c_[y_train_large, y_train_odd]
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_multilabel)
这段代码创建一个包含每个数字图像两个目标标签的y_multilabel数组:第一个指示数字是否大(7、8 或 9),第二个指示数字是否奇数。然后代码创建一个KNeighborsClassifier实例,支持多标签分类(并非所有分类器都支持),并使用多目标数组训练这个模型。现在您可以进行预测,并注意到它输出了两个标签:
>>> knn_clf.predict([some_digit])
array([[False, True]])
而且它预测正确了!数字 5 确实不是大的(False)且是奇数(True)。
有许多方法可以评估多标签分类器,选择正确的度量标准取决于您的项目。一种方法是测量每个单独标签的 F[1]分数(或之前讨论过的任何其他二元分类器度量标准),然后简单地计算平均分数。以下代码计算所有标签的平均 F[1]分数:
>>> y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_multilabel, cv=3)
>>> f1_score(y_multilabel, y_train_knn_pred, average="macro")
0.976410265560605
这种方法假设所有标签都同等重要,但这可能并非总是如此。特别是,如果您有比 Bob 或 Charlie 更多的 Alice 图片,您可能希望在 Alice 图片上给分类器的分数更多的权重。一个简单的选择是为每个标签赋予一个权重,等于其支持(即具有该目标标签的实例数)。要做到这一点,只需在调用f1_score()函数时设置average="weighted"。⁵
如果您希望使用不原生支持多标签分类的分类器,比如SVC,一种可能的策略是为每个标签训练一个模型。然而,这种策略可能难以捕捉标签之间的依赖关系。例如,一个大数字(7、8 或 9)是奇数的可能性是偶数的两倍,但“奇数”标签的分类器不知道“大”标签的分类器预测了什么。为了解决这个问题,模型可以被组织成一个链:当一个模型做出预测时,它使用输入特征加上链中之前所有模型的预测。
好消息是,Scikit-Learn 有一个名为ChainClassifier的类,它就是做这个的!默认情况下,它将使用真实标签进行训练,根据它们在链中的位置为每个模型提供适当的标签。但是,如果设置cv超参数,它将使用交叉验证为训练集中的每个实例获取“干净”(样本外)预测,并且这些预测将用于以后在链中训练所有模型。以下是一个示例,展示如何使用交叉验证策略创建和训练ChainClassifier。与之前一样,我们将只使用训练集中的前 2,000 幅图像以加快速度:
from sklearn.multioutput import ClassifierChain
chain_clf = ClassifierChain(SVC(), cv=3, random_state=42)
chain_clf.fit(X_train[:2000], y_multilabel[:2000])
现在我们可以使用这个ChainClassifier进行预测:
>>> chain_clf.predict([some_digit])
array([[0., 1.]])
多输出分类
我们将在这里讨论的最后一种分类任务类型称为多输出-多类别分类(或多输出分类)。这是多标签分类的一种泛化,其中每个标签可以是多类别的(即,它可以有两个以上的可能值)。
为了说明这一点,让我们构建一个从图像中去除噪声的系统。它将以嘈杂的数字图像作为输入,然后(希望)输出一个干净的数字图像,表示为像 MNIST 图像一样的像素强度数组。请注意,分类器的输出是多标签的(每个像素一个标签),每个标签可以有多个值(像素强度范围从 0 到 255)。因此,这是一个多输出分类系统的示例。
注意
分类和回归之间的界限有时是模糊的,比如在这个例子中。可以说,预测像素强度更类似于回归而不是分类。此外,多输出系统不仅限于分类任务;您甚至可以拥有一个系统,它为每个实例输出多个标签,包括类标签和值标签。
让我们从使用 NumPy 的randint()函数向 MNIST 图像添加噪声来创建训练集和测试集。目标图像将是原始图像:
np.random.seed(42) # to make this code example reproducible
noise = np.random.randint(0, 100, (len(X_train), 784))
X_train_mod = X_train + noise
noise = np.random.randint(0, 100, (len(X_test), 784))
X_test_mod = X_test + noise
y_train_mod = X_train
y_test_mod = X_test
让我们看一下测试集中的第一幅图像(图 3-12)。是的,我们正在窥探测试数据,所以您现在应该皱起眉头。
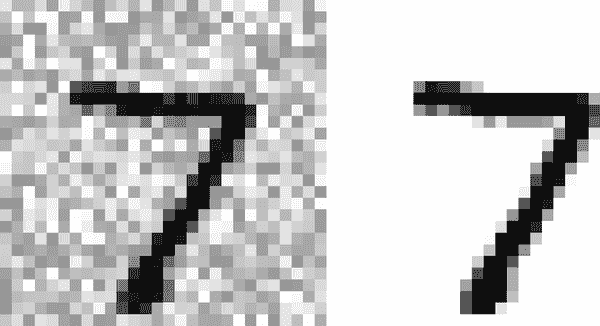
图 3-12. 一幅嘈杂的图像(左)和目标干净图像(右)
左边是嘈杂的输入图像,右边是干净的目标图像。现在让我们训练分类器,让它清理这幅图像(图 3-13):
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train_mod, y_train_mod)
clean_digit = knn_clf.predict([X_test_mod[0]])
plot_digit(clean_digit)
plt.show()
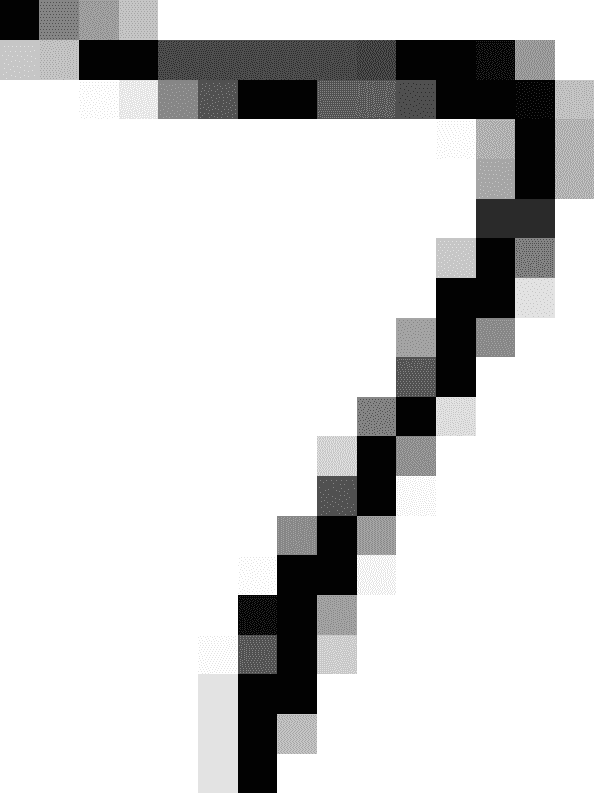
图 3-13. 清理后的图像
看起来接近目标了!这结束了我们的分类之旅。您现在知道如何为分类任务选择良好的度量标准,选择适当的精确度/召回率折衷,比较分类器,以及更一般地构建各种任务的良好分类系统。在接下来的章节中,您将了解您一直在使用的所有这些机器学习模型实际上是如何工作的。
练习
-
尝试为 MNIST 数据集构建一个分类器,在测试集上实现超过 97%的准确率。提示:
KNeighborsClassifier对这个任务效果很好;您只需要找到好的超参数值(尝试在weights和n_neighbors超参数上进行网格搜索)。 -
编写一个函数,可以将 MNIST 图像向任何方向(左、右、上或下)移动一个像素。然后,对于训练集中的每个图像,创建四个移位副本(每个方向一个)并将它们添加到训练集中。最后,在这个扩展的训练集上训练您最好的模型,并在测试集上测量其准确率。您应该观察到您的模型现在表现得更好了!这种人为扩展训练集的技术称为数据增强或训练集扩展。
-
解决泰坦尼克号数据集。一个很好的开始地方是Kaggle。或者,您可以从https://homl.info/titanic.tgz下载数据并解压缩这个 tarball,就像您在第二章中为房屋数据所做的那样。这将给您两个 CSV 文件,train.csv和test.csv,您可以使用
pandas.read_csv()加载。目标是训练一个分类器,可以根据其他列预测Survived列。 -
构建一个垃圾邮件分类器(一个更具挑战性的练习):
-
从Apache SpamAssassin 的公共数据集下载垃圾邮件和正常邮件的示例。
-
解压数据集并熟悉数据格式。
-
将数据分割为训练集和测试集。
-
编写一个数据准备流水线,将每封电子邮件转换为特征向量。您的准备流水线应该将一封电子邮件转换为一个(稀疏)向量,指示每个可能单词的存在或不存在。例如,如果所有电子邮件只包含四个单词,“Hello”、“how”、“are”、“you”,那么电子邮件“Hello you Hello Hello you”将被转换为向量[1, 0, 0, 1](表示[“Hello”存在,“how”不存在,“are”不存在,“you”存在]),或者如果您更喜欢计算每个单词出现的次数,则为[3, 0, 0, 2]。
您可能希望在准备流水线中添加超参数,以控制是否剥离电子邮件头部,将每封电子邮件转换为小写,删除标点符号,用“URL”替换所有 URL,用“NUMBER”替换所有数字,甚至执行词干提取(即修剪单词结尾;有 Python 库可用于执行此操作)。
-
最后,尝试几种分类器,看看是否可以构建一个既具有高召回率又具有高精度的垃圾邮件分类器。
-
这些练习的解决方案可以在本章笔记本的末尾找到,网址为https://homl.info/colab3。
¹ 默认情况下,Scikit-Learn 会将下载的数据集缓存到名为scikit_learn_data的目录中,该目录位于您的主目录中。
² fetch_openml()返回的数据集并不总是被洗牌或分割。
³ 在某些情况下,洗牌可能不是一个好主意——例如,如果您正在处理时间序列数据(如股票市场价格或天气状况)。我们将在第十五章中探讨这个问题。
⁴ Scikit-Learn 分类器总是具有decision_function()方法或predict_proba()方法,有时两者都有。
⁵ Scikit-Learn 提供了一些其他平均选项和多标签分类器指标;更多细节请参阅文档。
⁶ 您可以使用scipy.ndimage.interpolation模块中的shift()函数。例如,shift(image, [2, 1], cval=0)将图像向下移动两个像素,向右移动一个像素。
第四章:训练模型
到目前为止,我们大多将机器学习模型及其训练算法视为黑匣子。如果您在之前章节的一些练习中有所了解,您可能会对不知道底层原理的情况下能做多少事情感到惊讶:您优化了一个回归系统,改进了一个数字图像分类器,甚至从头开始构建了一个垃圾邮件分类器,所有这些都是在不知道它们实际如何工作的情况下完成的。实际上,在许多情况下,您并不真正需要知道实现细节。
然而,对事物如何运作有一个良好的理解可以帮助您快速找到适当的模型、正确的训练算法以及适合您任务的一组良好的超参数。了解底层原理还将帮助您更有效地调试问题并执行错误分析。最后,本章讨论的大多数主题将对理解、构建和训练神经网络(本书的第二部分中讨论)至关重要。
在本章中,我们将首先看一下线性回归模型,这是最简单的模型之一。我们将讨论两种非常不同的训练方法:
-
使用一个“封闭形式”方程¹直接计算最适合训练集的模型参数(即最小化训练集上成本函数的模型参数)。
-
使用一种称为梯度下降(GD)的迭代优化方法,逐渐调整模型参数以最小化训练集上的成本函数,最终收敛到与第一种方法相同的参数集。我们将看一下几种梯度下降的变体,当我们研究神经网络时会一再使用:批量 GD、小批量 GD 和随机 GD。
接下来我们将看一下多项式回归,这是一个可以拟合非线性数据集的更复杂模型。由于这个模型比线性回归有更多的参数,所以更容易过拟合训练数据。我们将探讨如何通过学习曲线检测是否存在这种情况,然后我们将看一下几种正则化技术,可以减少过拟合训练集的风险。
最后,我们将研究另外两种常用于分类任务的模型:逻辑回归和 softmax 回归。
警告
本章将包含相当多的数学方程,使用线性代数和微积分的基本概念。要理解这些方程,您需要知道向量和矩阵是什么;如何转置、相乘和求逆;以及什么是偏导数。如果您对这些概念不熟悉,请查看在线补充材料中作为 Jupyter 笔记本提供的线性代数和微积分入门教程。对于那些真正对数学过敏的人,您仍然应该阅读本章,并简单跳过方程;希望文本足以帮助您理解大部分概念。
线性回归
在第一章中,我们看了一个关于生活满意度的简单回归模型:
life_satisfaction = θ[0] + θ[1] × GDP_per_capita
该模型只是输入特征GDP_per_capita的线性函数。θ[0]和θ[1]是模型的参数。
更一般地,线性模型通过简单地计算输入特征的加权和加上一个称为偏置项(也称为截距项)的常数来进行预测,如方程 4-1 所示。
方程 4-1。线性回归模型预测
y ^ = θ 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ n x n
在这个方程中:
-
ŷ是预测值。
-
n是特征数量。
-
x[i]是第i个特征值。
-
θ[j]是第j个模型参数,包括偏置项θ[0]和特征权重θ[1]、θ[2]、⋯、θ[n]。
这可以用矢量化形式更简洁地表示,如方程 4-2 所示。
方程 4-2. 线性回归模型预测(矢量化形式)
y^=hθ(x)=θ·x
在这个方程中:
-
h[θ]是假设函数,使用模型参数θ。
-
θ是模型的参数向量,包括偏置项θ[0]和特征权重θ[1]到θ[n]。
-
x是实例的特征向量,包含x[0]到x[n],其中x[0]始终等于 1。
-
θ · x是向量θ和x的点积,等于θ[0]x[0] + θ[1]x[1] + θ[2]x[2] + … + θ[n]x[n]。
注意
在机器学习中,向量通常表示为列向量,这是具有单列的二维数组。如果θ和x是列向量,那么预测值为y^=θ⊺x,其中θ⊺是θ的转置(行向量而不是列向量),θ⊺x是θ⊺和x的矩阵乘法。当然,这是相同的预测,只是现在表示为单元格矩阵而不是标量值。在本书中,我将使用这种表示法,以避免在点积和矩阵乘法之间切换。
好的,这就是线性回归模型,但我们如何训练它呢?嗯,回想一下,训练模型意味着设置其参数,使模型最好地适应训练集。为此,我们首先需要一个衡量模型与训练数据拟合程度的指标。在第二章中,我们看到回归模型最常见的性能指标是均方根误差(方程 2-1)。因此,要训练线性回归模型,我们需要找到最小化 RMSE 的θ的值。在实践中,最小化均方误差(MSE)比最小化 RMSE 更简单,并且会导致相同的结果(因为最小化正函数的值也会最小化其平方根)。
警告
在训练期间,学习算法通常会优化不同的损失函数,而不是用于评估最终模型的性能指标。这通常是因为该函数更容易优化和/或因为在训练期间仅需要额外的项(例如,用于正则化)。一个好的性能指标应尽可能接近最终的业务目标。一个好的训练损失易于优化,并且与指标强相关。例如,分类器通常使用成本函数进行训练,如对数损失(稍后在本章中将看到),但使用精度/召回率进行评估。对数损失易于最小化,这样做通常会提高精度/召回率。
线性回归假设h[θ]在训练集X上的 MSE 是使用方程 4-3 计算的。
方程 4-3. 线性回归模型的 MSE 成本函数
MSE ( X , h θ ) = 1 m ∑ i=1 m (θ ⊺ x (i) -y (i) ) 2
大多数这些符号在第二章中已经介绍过(参见“符号”)。唯一的区别是我们写h[θ]而不是只写h,以明确模型是由向量θ参数化的。为了简化符号,我们将只写 MSE(θ)而不是 MSE(X, h[θ])。
正规方程
为了找到最小化 MSE 的θ的值,存在一个闭式解——换句话说,一个直接给出结果的数学方程。这被称为正规方程(方程 4-4)。
方程 4-4. 正规方程
θ ^ = (X ⊺ X) -1 X ⊺ y
在这个方程中:
-
θ^是最小化成本函数的θ的值。
-
y是包含y((1))到*y*((m))的目标值向量。
让我们生成一些看起来线性的数据来测试这个方程(图 4-1):
import numpy as np
np.random.seed(42) # to make this code example reproducible
m = 100 # number of instances
X = 2 * np.random.rand(m, 1) # column vector
y = 4 + 3 * X + np.random.randn(m, 1) # column vector
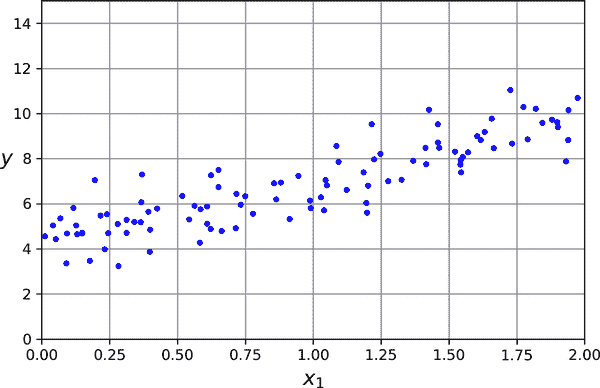
图 4-1. 随机生成的线性数据集
现在让我们使用正规方程计算θ^。我们将使用 NumPy 的线性代数模块(np.linalg)中的inv()函数计算矩阵的逆,以及矩阵乘法的dot()方法:
from sklearn.preprocessing import add_dummy_feature
X_b = add_dummy_feature(X) # add x0 = 1 to each instance
theta_best = np.linalg.inv(X_b.T @ X_b) @ X_b.T @ y
注意
@运算符执行矩阵乘法。如果A和B是 NumPy 数组,则A @ B等同于np.matmul(A, B)。许多其他库,如 TensorFlow、PyTorch 和 JAX,也支持@运算符。但是,不能在纯 Python 数组(即列表的列表)上使用@。
我们用来生成数据的函数是y = 4 + 3x[1] + 高斯噪声。让我们看看方程找到了什么:
>>> theta_best
array([[4.21509616],
[2.77011339]])
我们希望θ[0] = 4 和θ[1] = 3,而不是θ[0] = 4.215 和θ[1] = 2.770。足够接近,但噪声使得无法恢复原始函数的确切参数。数据集越小且噪声越大,问题就越困难。
现在我们可以使用θ^进行预测:
>>> X_new = np.array([[0], [2]])
>>> X_new_b = add_dummy_feature(X_new) # add x0 = 1 to each instance
>>> y_predict = X_new_b @ theta_best
>>> y_predict
array([[4.21509616],
[9.75532293]])
让我们绘制这个模型的预测(图 4-2):
import matplotlib.pyplot as plt
plt.plot(X_new, y_predict, "r-", label="Predictions")
plt.plot(X, y, "b.")
[...] # beautify the figure: add labels, axis, grid, and legend
plt.show()
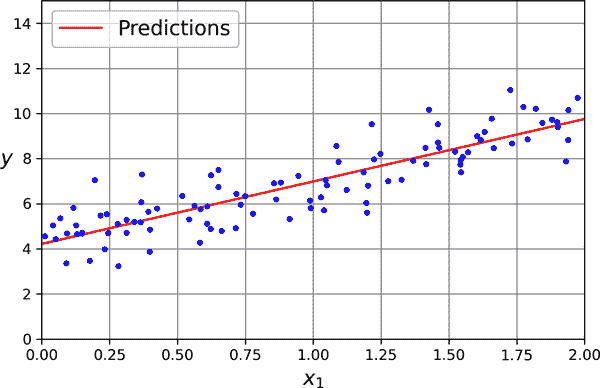
图 4-2. 线性回归模型预测
使用 Scikit-Learn 执行线性回归相对简单:
>>> from sklearn.linear_model import LinearRegression
>>> lin_reg = LinearRegression()
>>> lin_reg.fit(X, y)
>>> lin_reg.intercept_, lin_reg.coef_
(array([4.21509616]), array([[2.77011339]]))
>>> lin_reg.predict(X_new)
array([[4.21509616],
[9.75532293]])
请注意,Scikit-Learn 将偏置项(intercept_)与特征权重(coef_)分开。LinearRegression类基于scipy.linalg.lstsq()函数(名称代表“最小二乘法”),您可以直接调用该函数:
>>> theta_best_svd, residuals, rank, s = np.linalg.lstsq(X_b, y, rcond=1e-6)
>>> theta_best_svd
array([[4.21509616],
[2.77011339]])
这个函数计算θ^=X+y,其中X+是X的伪逆(具体来说,是 Moore-Penrose 逆)。您可以使用np.linalg.pinv()直接计算伪逆:
>>> np.linalg.pinv(X_b) @ y
array([[4.21509616],
[2.77011339]])
伪逆本身是使用称为奇异值分解(SVD)的标准矩阵分解技术计算的,可以将训练集矩阵X分解为三个矩阵U Σ V^⊺的矩阵乘法(参见numpy.linalg.svd())。伪逆计算为X+=VΣ+U⊺。为了计算矩阵Σ+,算法取Σ并将小于一个微小阈值的所有值设为零,然后用它们的倒数替换所有非零值,最后转置结果矩阵。这种方法比计算正规方程更有效,而且可以很好地处理边缘情况:实际上,如果矩阵X^⊺X不可逆(即奇异),例如如果m<n或者某些特征是冗余的,那么正规方程可能无法工作,但伪逆总是被定义的。
计算复杂度
正规方程计算X⊺**X**的逆,这是一个(*n*+1)×(*n*+1)矩阵(其中*n*是特征数)。求解这样一个矩阵的*计算复杂度*通常约为*O*(*n*(2.4))到O(n³),取决于实现。换句话说,如果特征数翻倍,计算时间大约会乘以 2^(2.4)=5.3 到 2³=8。
Scikit-Learn 的LinearRegression类使用的 SVD 方法大约是O(n²)。如果特征数量翻倍,计算时间大约会乘以 4。
警告
当特征数量增多时(例如 100,000),正规方程和 SVD 方法都变得非常慢。积极的一面是,它们都与训练集中实例数量线性相关(它们是O(m)),因此它们可以有效地处理大型训练集,只要它们可以放入内存。
此外,一旦训练好线性回归模型(使用正规方程或任何其他算法),预测速度非常快:计算复杂度与您要进行预测的实例数量和特征数量成正比。换句话说,对两倍实例(或两倍特征)进行预测将花费大约两倍的时间。
现在我们将看一种非常不同的训练线性回归模型的方法,这种方法更适用于特征数量较多或训练实例太多无法放入内存的情况。
梯度下降
梯度下降是一种通用的优化算法,能够找到各种问题的最优解。梯度下降的一般思想是迭代地调整参数,以最小化成本函数。
假设你在浓雾中的山中迷失了方向,只能感受到脚下的坡度。快速到达山谷底部的一个好策略是沿着最陡的坡度方向下坡。这正是梯度下降所做的:它测量了关于参数向量θ的误差函数的局部梯度,并沿着下降梯度的方向前进。一旦梯度为零,你就到达了一个最小值!
在实践中,您首先用随机值填充θ(这称为随机初始化)。然后逐渐改进它,每次尝试减少成本函数(例如 MSE)一点点,直到算法收敛到最小值(参见图 4-3)。
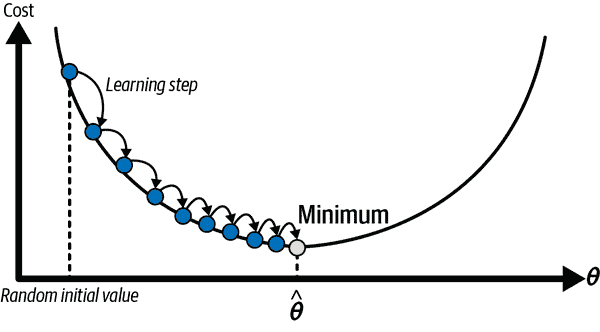
图 4-3。在这个梯度下降的描述中,模型参数被随机初始化,并不断调整以最小化成本函数;学习步长大小与成本函数的斜率成比例,因此随着成本接近最小值,步长逐渐变小
梯度下降中的一个重要参数是步长的大小,由学习率超参数确定。如果学习率太小,那么算法将需要经过许多迭代才能收敛,这将花费很长时间(参见图 4-4)。
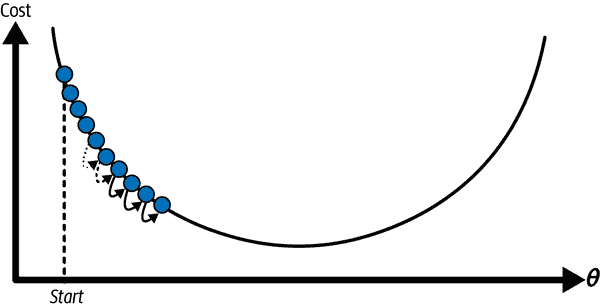
图 4-4。学习率太小
另一方面,如果学习率太高,您可能会跳过山谷,最终停在另一侧,甚至可能比之前更高。这可能导致算法发散,产生越来越大的值,无法找到一个好的解决方案(参见图 4-5)。
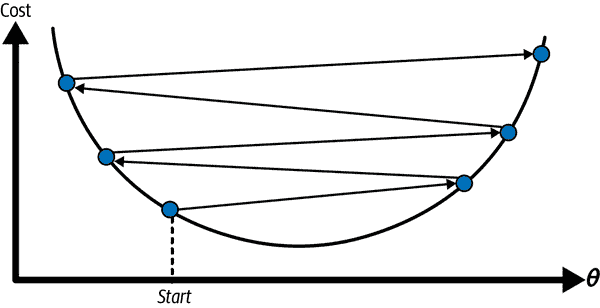
图 4-5。学习率太高
此外,并非所有成本函数都像漂亮的、规则的碗一样。可能会有洞、脊、高原和各种不规则的地形,使得收敛到最小值变得困难。图 4-6 展示了梯度下降的两个主要挑战。如果随机初始化将算法开始于左侧,则它将收敛到局部最小值,这不如全局最小值好。如果它从右侧开始,则穿过高原将需要很长时间。如果您停得太早,您将永远无法达到全局最小值。
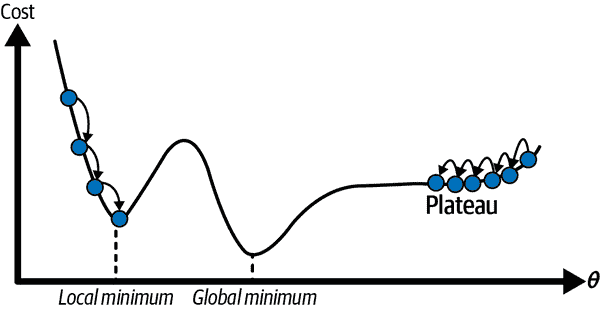
图 4-6。梯度下降的陷阱
幸运的是,线性回归模型的 MSE 成本函数恰好是一个凸函数,这意味着如果您选择曲线上的任意两点,连接它们的线段永远不会低于曲线。这意味着没有局部最小值,只有一个全局最小值。它还是一个连续函数,斜率永远不会突然改变。这两个事实有一个重要的结果:梯度下降保证可以无限接近全局最小值(如果等待足够长的时间且学习率不太高)。
虽然成本函数的形状像一个碗,但如果特征具有非常不同的比例,它可能是一个延长的碗。图 4-7 展示了在特征 1 和 2 具有相同比例的训练集上的梯度下降(左侧),以及在特征 1 的值远小于特征 2 的训练集上的梯度下降(右侧)。
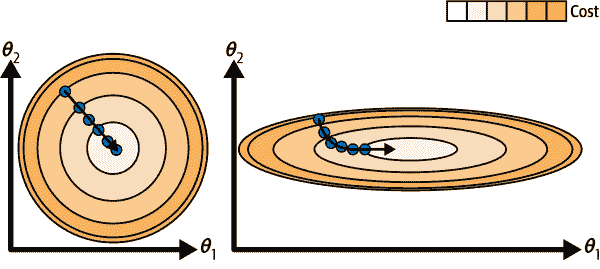
图 4-7。特征缩放的梯度下降(左)和不缩放的梯度下降(右)
正如您所看到的,左侧的梯度下降算法直接朝向最小值,因此快速到达,而右侧首先朝向几乎与全局最小值方向正交的方向,最终沿着几乎平坦的山谷长途跋涉。它最终会到达最小值,但需要很长时间。
警告
在使用梯度下降时,您应确保所有特征具有相似的比例(例如,使用 Scikit-Learn 的StandardScaler类),否则收敛所需的时间将更长。
这个图表还说明了训练模型意味着寻找一组模型参数的组合,使得成本函数(在训练集上)最小化。这是在模型的参数空间中进行的搜索。模型的参数越多,空间的维度就越多,搜索就越困难:在一个 300 维的草堆中搜索一根针比在 3 维空间中要困难得多。幸运的是,由于线性回归的情况下成本函数是凸的,所以这根针就在碗底。
批量梯度下降
要实现梯度下降,您需要计算成本函数相对于每个模型参数θ[j]的梯度。换句话说,您需要计算如果您稍微改变θ[j],成本函数将如何变化。这被称为偏导数。这就像问,“如果我面向东,脚下的山坡有多陡?”然后面向北问同样的问题(如果您可以想象一个超过三维的宇宙,那么其他维度也是如此)。方程 4-5 计算了关于参数θ[j]的 MSE 的偏导数,表示为∂ MSE(θ) / ∂θ[j]。
方程 4-5. 成本函数的偏导数
∂ ∂θ j MSE ( θ ) = 2 m ∑ i=1 m ( θ ⊺ x (i) - y (i) ) x j (i)
与单独计算这些偏导数不同,您可以使用方程 4-6 一次性计算它们。梯度向量,表示为∇[θ]MSE(θ),包含成本函数的所有偏导数(每个模型参数一个)。
方程 4-6. 成本函数的梯度向量
∇ θ MSE ( θ ) = ∂ ∂θ 0 MSE ( θ ) ∂ ∂θ 1 MSE ( θ ) ⋮ ∂ ∂θ n MSE ( θ ) = 2 m X ⊺ ( X θ - y )
警告
请注意,这个公式涉及对整个训练集X进行计算,每次梯度下降步骤都要进行!这就是为什么该算法被称为批量梯度下降:它在每一步使用整个批量的训练数据(实际上,全梯度下降可能是一个更好的名称)。因此,在非常大的训练集上,它非常慢(我们很快将看到一些更快的梯度下降算法)。然而,梯度下降随着特征数量的增加而扩展得很好;当特征数量达到数十万时,使用梯度下降训练线性回归模型比使用正规方程或 SVD 分解要快得多。
一旦有了指向上坡的梯度向量,只需朝相反方向前进以下坡。这意味着从θ中减去∇[θ]MSE(θ)。这就是学习率η发挥作用的地方:⁴将梯度向量乘以η来确定下坡步长的大小(方程 4-7)。
方程 4-7. 梯度下降步骤
θ(下一步)=θ-η∇θMSE(θ)
让我们快速实现这个算法:
eta = 0.1 # learning rate
n_epochs = 1000
m = len(X_b) # number of instances
np.random.seed(42)
theta = np.random.randn(2, 1) # randomly initialized model parameters
for epoch in range(n_epochs):
gradients = 2 / m * X_b.T @ (X_b @ theta - y)
theta = theta - eta * gradients
这并不难!每次对训练集的迭代称为epoch。让我们看看得到的theta:
>>> theta
array([[4.21509616],
[2.77011339]])
嘿,这正是正规方程找到的!梯度下降完美地工作了。但是如果您使用了不同的学习率(eta)会怎样呢?图 4-8 显示了使用三种不同学习率的梯度下降的前 20 步。每个图中底部的线代表随机起始点,然后每个迭代由越来越深的线表示。
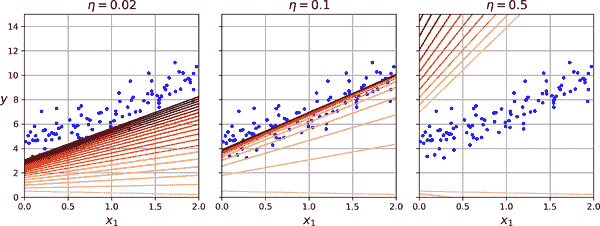
图 4-8. 不同学习率的梯度下降
在左侧,学习率太低:算法最终会达到解,但需要很长时间。在中间,学习率看起来相当不错:在几个迭代中,它已经收敛到解。在右侧,学习率太高:算法发散,跳来跳去,实际上每一步都离解越来越远。
要找到一个好的学习率,可以使用网格搜索(参见第二章)。然而,您可能希望限制迭代次数,以便网格搜索可以消除收敛时间过长的模型。
您可能想知道如何设置迭代次数。如果太低,当算法停止时,您仍然离最优解很远;但如果太高,您将浪费时间,因为模型参数不再改变。一个简单的解决方案是设置一个非常大的迭代次数,但在梯度向量变得微小时中断算法——也就是说,当其范数小于一个微小数ϵ(称为容差)时——因为这表示梯度下降已经(几乎)达到了最小值。
随机梯度下降
批量梯度下降的主要问题在于,它在每一步使用整个训练集来计算梯度,这使得在训练集很大时非常缓慢。相反,随机梯度下降 在每一步选择训练集中的一个随机实例,并仅基于该单个实例计算梯度。显然,一次只处理一个实例使得算法更快,因为每次迭代时需要操作的数据量很少。这也使得在庞大的训练集上进行训练成为可能,因为每次迭代只需要一个实例在内存中(随机梯度下降可以作为一种离线算法实现;参见第一章)。
另一方面,由于其随机(即随机)性质,这种算法比批量梯度下降不规则得多:成本函数不会温和地减少直到达到最小值,而是会上下波动,仅平均减少。随着时间的推移,它最终会非常接近最小值,但一旦到达那里,它将继续上下波动,永远不会稳定下来(参见图 4-9)。一旦算法停止,最终的参数值将是不错的,但不是最优的。
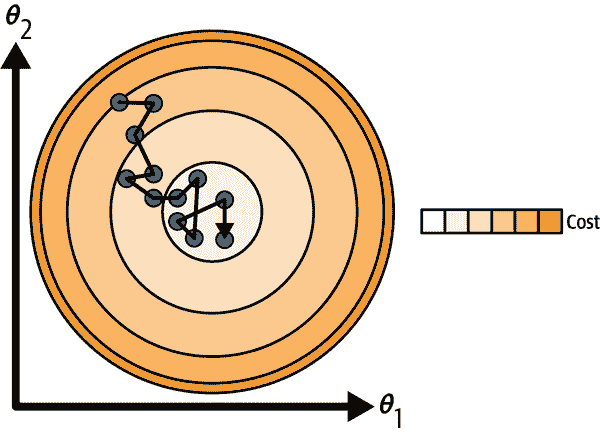
图 4-9。使用随机梯度下降,每个训练步骤比使用批量梯度下降快得多,但也更不规则。
当成本函数非常不规则时(如图 4-6 中所示),这实际上可以帮助算法跳出局部最小值,因此随机梯度下降比批量梯度下降更有可能找到全局最小值。
因此,随机性有助于摆脱局部最优解,但也不好,因为这意味着算法永远无法稳定在最小值处。解决这一困境的一个方法是逐渐降低学习率。步骤开始很大(有助于快速取得进展并摆脱局部最小值),然后变得越来越小,允许算法在全局最小值处稳定下来。这个过程类似于模拟退火,这是一种受金属冶炼过程启发的算法,其中熔化的金属被慢慢冷却。确定每次迭代学习率的函数称为学习计划。如果学习率降低得太快,您可能会陷入局部最小值,甚至最终冻结在最小值的一半。如果学习率降低得太慢,您可能会在最小值周围跳来跳去很长时间,并且如果您在训练过早停止,最终会得到一个次优解。
此代码使用简单的学习计划实现随机梯度下降:
n_epochs = 50
t0, t1 = 5, 50 # learning schedule hyperparameters
def learning_schedule(t):
return t0 / (t + t1)
np.random.seed(42)
theta = np.random.randn(2, 1) # random initialization
for epoch in range(n_epochs):
for iteration in range(m):
random_index = np.random.randint(m)
xi = X_b[random_index : random_index + 1]
yi = y[random_index : random_index + 1]
gradients = 2 * xi.T @ (xi @ theta - yi) # for SGD, do not divide by m
eta = learning_schedule(epoch * m + iteration)
theta = theta - eta * gradients
按照惯例,我们按照m次迭代的轮次进行迭代;每一轮称为epoch,如前所述。虽然批量梯度下降代码通过整个训练集迭代了 1,000 次,但这段代码只通过训练集迭代了 50 次,并达到了一个相当不错的解决方案:
>>> theta
array([[4.21076011],
[2.74856079]])
图 4-10 显示了训练的前 20 步(请注意步骤的不规则性)。
请注意,由于实例是随机选择的,一些实例可能在每个 epoch 中被多次选择,而其他实例可能根本不被选择。如果您想确保算法在每个 epoch 中通过每个实例,另一种方法是对训练集进行洗牌(确保同时洗牌输入特征和标签),然后逐个实例地进行,然后再次洗牌,依此类推。然而,这种方法更复杂,通常不会改善结果。
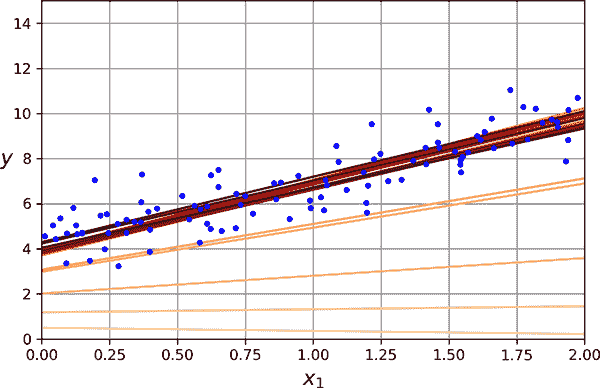
图 4-10。随机梯度下降的前 20 步
警告
在使用随机梯度下降时,训练实例必须是独立同分布的(IID),以确保参数平均被拉向全局最优解。确保这一点的一个简单方法是在训练期间对实例进行洗牌(例如,随机选择每个实例,或在每个 epoch 开始时对训练集进行洗牌)。如果不对实例进行洗牌,例如,如果实例按标签排序,则 SGD 将从优化一个标签开始,然后是下一个标签,依此类推,并且不会接近全局最小值。
要使用 Scikit-Learn 进行随机梯度下降线性回归,您可以使用SGDRegressor类,默认情况下优化 MSE 成本函数。以下代码最多运行 1,000 个时代(max_iter)或在 100 个时代内损失下降不到 10^(–5)(tol)时停止(n_iter_no_change)。它以学习率 0.01(eta0)开始,使用默认学习计划(与我们使用的不同)。最后,它不使用任何正则化(penalty=None;稍后会详细介绍):
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(max_iter=1000, tol=1e-5, penalty=None, eta0=0.01,
n_iter_no_change=100, random_state=42)
sgd_reg.fit(X, y.ravel()) # y.ravel() because fit() expects 1D targets
再次,您会发现解决方案与正规方程返回的解非常接近:
>>> sgd_reg.intercept_, sgd_reg.coef_
(array([4.21278812]), array([2.77270267]))
提示
所有 Scikit-Learn 估计器都可以使用fit()方法进行训练,但有些估计器还有一个partial_fit()方法,您可以调用它来对一个或多个实例运行一轮训练(它会忽略max_iter或tol等超参数)。反复调用partial_fit()会逐渐训练模型。当您需要更多控制训练过程时,这是很有用的。其他模型则有一个warm_start超参数(有些模型两者都有):如果您设置warm_start=True,在已训练的模型上调用fit()方法不会重置模型;它将继续训练在哪里停止,遵守max_iter和tol等超参数。请注意,fit()会重置学习计划使用的迭代计数器,而partial_fit()不会。
小批量梯度下降
我们将要看的最后一个梯度下降算法称为小批量梯度下降。一旦您了解了批量梯度下降和随机梯度下降,这就很简单了:在每一步中,小批量梯度下降不是基于完整训练集(批量梯度下降)或仅基于一个实例(随机梯度下降)计算梯度,而是在称为小批量的小随机实例集上计算梯度。小批量梯度下降相对于随机梯度下降的主要优势在于,您可以通过硬件优化矩阵运算获得性能提升,尤其是在使用 GPU 时。
该算法在参数空间中的进展比随机梯度下降更加稳定,尤其是在使用相当大的小批量时。因此,小批量梯度下降最终会比随机梯度下降更接近最小值,但它可能更难逃离局部最小值(在存在局部最小值的问题中,不同于具有 MSE 成本函数的线性回归)。图 4-11 显示了训练过程中三种梯度下降算法在参数空间中的路径。它们最终都接近最小值,但批量梯度下降的路径实际上停在最小值处,而随机梯度下降和小批量梯度下降则继续移动。但是,请不要忘记,批量梯度下降需要很长时间才能完成每一步,如果您使用良好的学习计划,随机梯度下降和小批量梯度下降也会达到最小值。
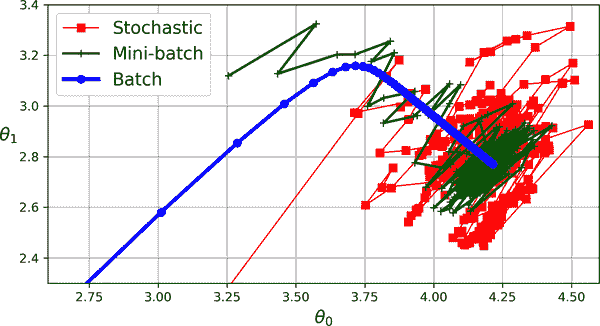
图 4-11. 参数空间中的梯度下降路径
表 4-1 比较了迄今为止我们讨论过的线性回归算法(请回忆m是训练实例的数量,n是特征的数量)。
表 4-1. 线性回归算法比较
| 算法 | 大 m | 支持离线 | 大 n | 超参数 | 需要缩放 | Scikit-Learn |
|---|---|---|---|---|---|---|
| 正规方程 | 快 | 否 | 慢 | 0 | 否 | N/A |
| SVD | 快 | 否 | 慢 | 0 | 否 | LinearRegression |
| 批量梯度下降 | 慢 | 否 | 快 | 2 | 是 | N/A |
| 随机梯度下降 | 快 | 是 | 快 | ≥2 | 是 | SGDRegressor |
| 小批量梯度下降 | 快 | 是 | 快 | ≥2 | 是 | N/A |
训练后几乎没有区别:所有这些算法最终得到非常相似的模型,并以完全相同的方式进行预测。
多项式回归
如果你的数据比一条直线更复杂怎么办?令人惊讶的是,你可以使用线性模型来拟合非线性数据。一个简单的方法是将每个特征的幂作为新特征添加,然后在这个扩展的特征集上训练线性模型。这种技术称为多项式回归。
让我们看一个例子。首先,我们将生成一些非线性数据(参见图 4-12),基于一个简单的二次方程——即形式为y = ax² + bx + c的方程——再加上一些噪声:
np.random.seed(42)
m = 100
X = 6 * np.random.rand(m, 1) - 3
y = 0.5 * X ** 2 + X + 2 + np.random.randn(m, 1)
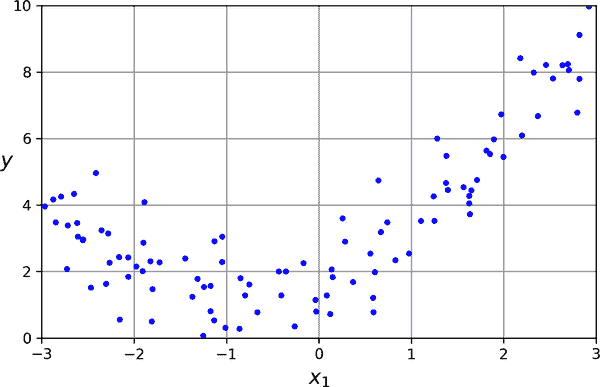
图 4-12。生成的非线性和嘈杂数据集
显然,一条直线永远无法正确拟合这些数据。因此,让我们使用 Scikit-Learn 的PolynomialFeatures类来转换我们的训练数据,将训练集中每个特征的平方(二次多项式)作为新特征添加到训练数据中(在这种情况下只有一个特征):
>>> from sklearn.preprocessing import PolynomialFeatures
>>> poly_features = PolynomialFeatures(degree=2, include_bias=False)
>>> X_poly = poly_features.fit_transform(X)
>>> X[0]
array([-0.75275929])
>>> X_poly[0]
array([-0.75275929, 0.56664654])
X_poly现在包含了X的原始特征以及该特征的平方。现在我们可以将LinearRegression模型拟合到这个扩展的训练数据上(图 4-13):
>>> lin_reg = LinearRegression()
>>> lin_reg.fit(X_poly, y)
>>> lin_reg.intercept_, lin_reg.coef_
(array([1.78134581]), array([[0.93366893, 0.56456263]]))
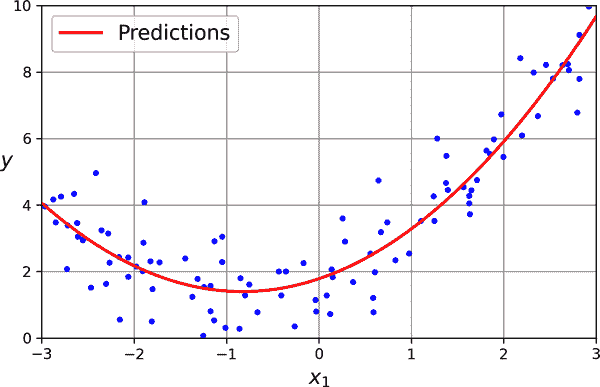
图 4-13。多项式回归模型预测
不错:模型估计y ^ = 0.56 x 1 2 + 0.93 x 1 + 1.78,而实际上原始函数是y = 0.5 x 1 2 + 1.0 x 1 + 2.0 + 高斯噪声。
请注意,当存在多个特征时,多项式回归能够找到特征之间的关系,这是普通线性回归模型无法做到的。这是因为PolynomialFeatures还会添加给定次数的所有特征组合。例如,如果有两个特征a和b,PolynomialFeatures的degree=3不仅会添加特征a²、a³、b²和b³,还会添加组合ab、a²b和ab²。
警告
PolynomialFeatures(degree=*d*)将包含n个特征的数组转换为包含(n + d)! / d!n!个特征的数组,其中n!是n的阶乘,等于 1 × 2 × 3 × ⋯ × n。注意特征数量的组合爆炸!
学习曲线
如果进行高次多项式回归,你很可能会比普通线性回归更好地拟合训练数据。例如,图 4-14 将一个 300 次多项式模型应用于前面的训练数据,并将结果与纯线性模型和二次模型(二次多项式)进行比较。请注意,300 次多项式模型在训练实例周围摆动以尽可能接近训练实例。
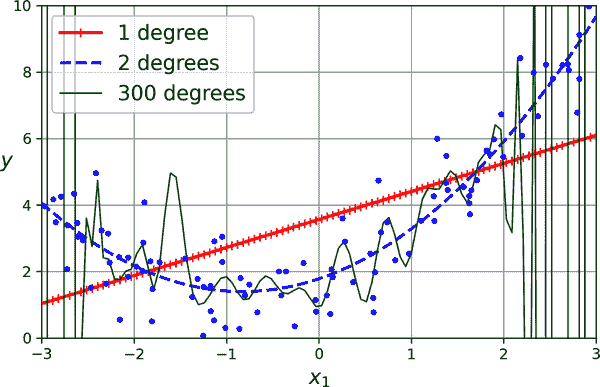
图 4-14。高次多项式回归
这个高次多项式回归模型严重过拟合了训练数据,而线性模型则欠拟合了。在这种情况下,最能泛化的模型是二次模型,这是有道理的,因为数据是使用二次模型生成的。但通常你不会知道是什么函数生成了数据,那么你如何决定模型应该有多复杂呢?你如何判断你的模型是过拟合还是欠拟合了数据?
在第二章中,您使用交叉验证来估计模型的泛化性能。如果模型在训练数据上表现良好,但根据交叉验证指标泛化能力差,那么您的模型是过拟合的。如果两者表现都不好,那么它是拟合不足的。这是判断模型过于简单或过于复杂的一种方法。
另一种方法是查看学习曲线,这是模型的训练误差和验证误差作为训练迭代的函数的图表:只需在训练集和验证集上定期评估模型,并绘制结果。如果模型无法进行增量训练(即,如果它不支持partial_fit()或warm_start),那么您必须在逐渐扩大的训练集子集上多次训练它。
Scikit-Learn 有一个有用的learning_curve()函数来帮助解决这个问题:它使用交叉验证来训练和评估模型。默认情况下,它会在不断增长的训练集子集上重新训练模型,但如果模型支持增量学习,您可以在调用learning_curve()时设置exploit_incremental_learning=True,它将逐步训练模型。该函数返回评估模型的训练集大小,以及每个大小和每个交叉验证折叠的训练和验证分数。让我们使用这个函数来查看普通线性回归模型的学习曲线(参见图 4-15):
from sklearn.model_selection import learning_curve
train_sizes, train_scores, valid_scores = learning_curve(
LinearRegression(), X, y, train_sizes=np.linspace(0.01, 1.0, 40), cv=5,
scoring="neg_root_mean_squared_error")
train_errors = -train_scores.mean(axis=1)
valid_errors = -valid_scores.mean(axis=1)
plt.plot(train_sizes, train_errors, "r-+", linewidth=2, label="train")
plt.plot(train_sizes, valid_errors, "b-", linewidth=3, label="valid")
[...] # beautify the figure: add labels, axis, grid, and legend
plt.show()
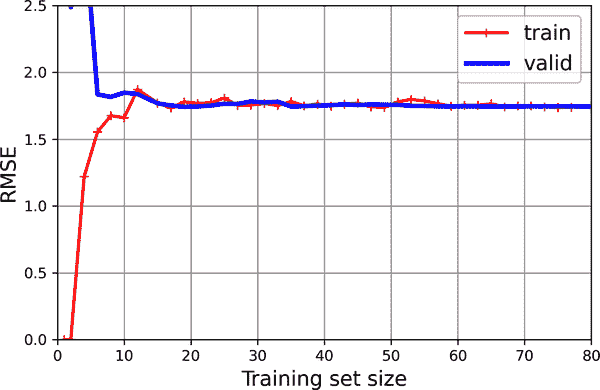
图 4-15. 学习曲线
这个模型拟合不足。为了了解原因,首先让我们看看训练误差。当训练集中只有一个或两个实例时,模型可以完美拟合它们,这就是曲线从零开始的原因。但随着新实例被添加到训练集中,模型无法完美拟合训练数据,因为数据存在噪声,而且根本不是线性的。因此,训练数据的误差会上升,直到达到一个平台,在这一点上,向训练集添加新实例不会使平均误差变得更好或更糟。现在让我们看看验证误差。当模型在非常少的训练实例上训练时,它无法正确泛化,这就是为什么验证误差最初相当大的原因。然后,随着模型展示更多的训练示例,它学习,因此验证误差慢慢下降。然而,再次,一条直线无法很好地对数据建模,因此误差最终会达到一个接近另一条曲线的平台。
这些学习曲线是典型的拟合不足模型。两条曲线都达到了一个平台;它们接近且相当高。
提示
如果您的模型对训练数据拟合不足,增加更多的训练样本将无济于事。您需要使用更好的模型或提出更好的特征。
现在让我们看看相同数据上 10 次多项式模型的学习曲线(参见图 4-16):
from sklearn.pipeline import make_pipeline
polynomial_regression = make_pipeline(
PolynomialFeatures(degree=10, include_bias=False),
LinearRegression())
train_sizes, train_scores, valid_scores = learning_curve(
polynomial_regression, X, y, train_sizes=np.linspace(0.01, 1.0, 40), cv=5,
scoring="neg_root_mean_squared_error")
[...] # same as earlier
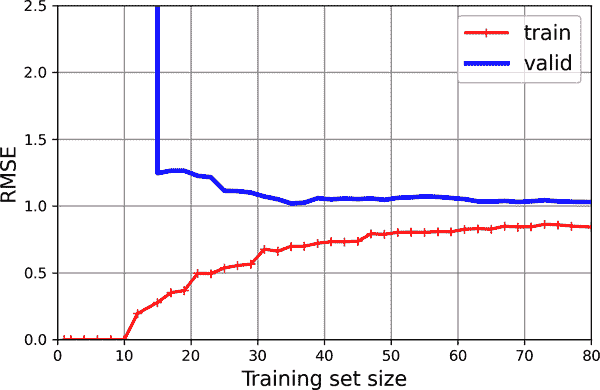
图 4-16. 10 次多项式模型的学习曲线
这些学习曲线看起来有点像之前的曲线,但有两个非常重要的区别:
-
训练数据上的误差比以前低得多。
-
曲线之间存在差距。这意味着模型在训练数据上的表现明显优于验证数据,这是过拟合模型的标志。然而,如果您使用更大的训练集,这两条曲线将继续接近。
提示
改进过拟合模型的一种方法是提供更多的训练数据,直到验证误差达到训练误差。
正则化线性模型
正如您在第一章和第二章中看到的,减少过拟合的一个好方法是对模型进行正则化(即,约束它):它的自由度越少,过拟合数据的难度就越大。对多项式模型进行正则化的一种简单方法是减少多项式次数。
对于线性模型,通常通过约束模型的权重来实现正则化。我们现在将看一下岭回归、套索回归和弹性网络回归,它们实现了三种不同的约束权重的方式。
岭回归
岭回归(也称为Tikhonov 正则化)是线性回归的正则化版本:一个等于αm∑i=1nθi2的正则化项被添加到 MSE 中。这迫使学习算法不仅拟合数据,还要尽量保持模型权重尽可能小。请注意,正则化项应该只在训练期间添加到成本函数中。一旦模型训练完成,您希望使用未经正则化的 MSE(或 RMSE)来评估模型的性能。
超参数α控制着您希望对模型进行多少正则化。如果α=0,则岭回归就是线性回归。如果α非常大,则所有权重最终都非常接近零,结果是一条通过数据均值的平坦线。方程 4-8 呈现了岭回归成本函数。⁷
方程 4-8。岭回归成本函数
J(θ)=MSE(θ)+αm∑i=1nθi2
请注意,偏置项θ[0]不被正则化(总和从i=1 开始,而不是 0)。如果我们将w定义为特征权重的向量(θ[1]到θ[n]),则正则化项等于α(∥ w ∥[2])² / m,其中∥ w ∥[2]表示权重向量的ℓ[2]范数。⁸ 对于批量梯度下降,只需将 2αw / m添加到对应于特征权重的 MSE 梯度向量的部分,而不要将任何内容添加到偏置项的梯度(参见方程 4-6)。
警告
在执行岭回归之前,重要的是对数据进行缩放(例如,使用StandardScaler),因为它对输入特征的规模敏感。这对大多数正则化模型都是正确的。
图 4-17 显示了在一些非常嘈杂的线性数据上使用不同α值训练的几个岭模型。在左侧,使用普通的岭模型,导致线性预测。在右侧,首先使用PolynomialFeatures(degree=10)扩展数据,然后使用StandardScaler进行缩放,最后将岭模型应用于生成的特征:这是带有岭正则化的多项式回归。请注意,增加α会导致更平缓(即,更不极端,更合理)的预测,从而减少模型的方差但增加其偏差。
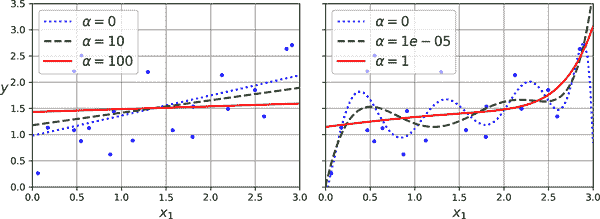
图 4-17。线性(左)和多项式(右)模型,都具有不同级别的岭正则化
与线性回归一样,我们可以通过计算闭式方程或执行梯度下降来执行岭回归。优缺点是相同的。方程 4-9 显示了闭式解,其中A是(n + 1) × (n + 1) 单位矩阵,⁹除了左上角的单元格为 0,对应于偏置项。
方程 4-9. 岭回归闭式解
θ ^ = (X ⊺ X+αA) -1 X ⊺ y
以下是如何使用 Scikit-Learn 执行岭回归的闭式解(一种方程 4-9 的变体,使用 André-Louis Cholesky 的矩阵分解技术):
>>> from sklearn.linear_model import Ridge
>>> ridge_reg = Ridge(alpha=0.1, solver="cholesky")
>>> ridge_reg.fit(X, y)
>>> ridge_reg.predict([[1.5]])
array([[1.55325833]])
使用随机梯度下降:¹⁰
>>> sgd_reg = SGDRegressor(penalty="l2", alpha=0.1 / m, tol=None,
... max_iter=1000, eta0=0.01, random_state=42)
...
>>> sgd_reg.fit(X, y.ravel()) # y.ravel() because fit() expects 1D targets
>>> sgd_reg.predict([[1.5]])
array([1.55302613])
penalty超参数设置要使用的正则化项的类型。指定"l2"表示您希望 SGD 将正则化项添加到 MSE 成本函数中,等于alpha乘以权重向量的ℓ[2]范数的平方。这就像岭回归一样,只是在这种情况下没有除以m;这就是为什么我们传递alpha=0.1 / m,以获得与Ridge(alpha=0.1)相同的结果。
提示
RidgeCV类也执行岭回归,但它会自动使用交叉验证调整超参数。它大致相当于使用GridSearchCV,但它针对岭回归进行了优化,并且运行快得多。其他几个估计器(主要是线性的)也有高效的 CV 变体,如LassoCV和ElasticNetCV。
Lasso 回归
最小绝对值收缩和选择算子回归(通常简称为Lasso 回归)是线性回归的另一个正则化版本:就像岭回归一样,它向成本函数添加一个正则化项,但是它使用权重向量的ℓ[1]范数,而不是ℓ[2]范数的平方(参见方程 4-10)。请注意,ℓ[1]范数乘以 2α,而ℓ[2]范数在岭回归中乘以α / m。选择这些因子是为了确保最佳α值与训练集大小无关:不同的范数导致不同的因子(有关更多细节,请参阅Scikit-Learn 问题#15657)。
方程 4-10. Lasso 回归成本函数
J(θ)=MSE(θ)+2α∑i=1nθi
图 4-18 显示了与图 4-17 相同的内容,但用 Lasso 模型替换了岭模型,并使用不同的α值。
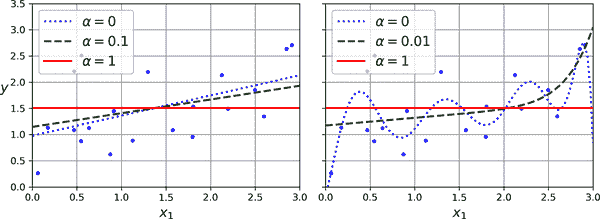
图 4-18. 线性(左)和多项式(右)模型,都使用不同级别的 Lasso 正则化
Lasso 回归的一个重要特征是它倾向于消除最不重要特征的权重(即将它们设置为零)。例如,图 4-18 中右侧图中的虚线看起来大致是立方形:高次多项式特征的所有权重都等于零。换句话说,Lasso 回归自动执行特征选择,并输出具有少量非零特征权重的稀疏模型。
你可以通过查看图 4-19 来了解这种情况:坐标轴代表两个模型参数,背景轮廓代表不同的损失函数。在左上角的图中,轮廓代表ℓ[1]损失(|θ[1]| + |θ[2]|),随着你靠近任何轴,损失会线性下降。例如,如果你将模型参数初始化为θ[1] = 2 和θ[2] = 0.5,运行梯度下降将等量减少两个参数(如虚线黄线所示);因此θ[2]会先达到 0(因为它最初更接近 0)。之后,梯度下降将沿着槽滚动,直到达到θ[1] = 0(稍微反弹一下,因为ℓ[1]的梯度从不接近 0:对于每个参数,它们要么是-1 要么是 1)。在右上角的图中,轮廓代表套索回归的成本函数(即,MSE 成本函数加上ℓ[1]损失)。小白色圆圈显示了梯度下降优化某些模型参数的路径,这些参数最初设定为θ[1] = 0.25 和θ[2] = -1:再次注意路径如何迅速到达θ[2] = 0,然后沿着槽滚动并最终在全局最优解周围反弹(由红色方块表示)。如果增加α,全局最优解将沿着虚线黄线向左移动,而如果减小α,全局最优解将向右移动(在这个例子中,未正则化 MSE 的最佳参数为θ[1] = 2 和θ[2] = 0.5)。
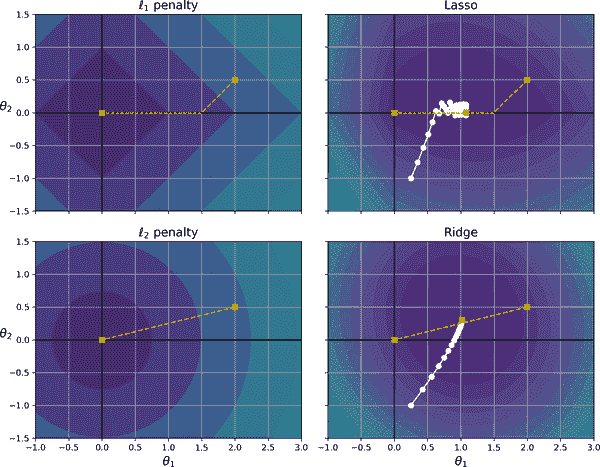
图 4-19。套索与岭正则化
两个底部图表展示了相同的情况,但使用了ℓ[2]惩罚。在左下角的图中,你可以看到随着我们靠近原点,ℓ[2]损失减少,因此梯度下降直接朝着那个点前进。在右下角的图中,轮廓代表岭回归的成本函数(即,MSE 成本函数加上ℓ[2]损失)。正如你所看到的,随着参数接近全局最优解,梯度变小,因此梯度下降自然减慢。这限制了反弹,有助于岭回归比套索收敛更快。还要注意,当增加α时,最佳参数(由红色方块表示)越来越接近原点,但它们永远不会完全消失。
提示
为了防止在使用套索回归时梯度下降在最后反弹到最优解周围,你需要在训练过程中逐渐减小学习率。它仍然会在最优解周围反弹,但步长会变得越来越小,因此会收敛。
套索成本函数在θ[i] = 0(对于 i = 1, 2, ⋯, n)处不可微,但如果在任何θ[i] = 0 时使用子梯度向量 g¹¹,梯度下降仍然有效。方程 4-11 展示了一个你可以用于套索成本函数的梯度下降的子梯度向量方程。
方程 4-11。套索回归子梯度向量
g(θ,J)=∇θMSE(θ)+2αsign(θ1)sign(θ2)⋮sign(θn)where sign(θi)=-1if θi<00if θi=0+1if θi>0
这里有一个使用Lasso类的小型 Scikit-Learn 示例:
>>> from sklearn.linear_model import Lasso
>>> lasso_reg = Lasso(alpha=0.1)
>>> lasso_reg.fit(X, y)
>>> lasso_reg.predict([[1.5]])
array([1.53788174])
请注意,您也可以使用SGDRegressor(penalty="l1", alpha=0.1)。
弹性网回归
弹性网回归是岭回归和套索回归之间的中间地带。正则化项是岭回归和套索回归正则化项的加权和,您可以控制混合比例r。当r=0 时,弹性网等同于岭回归,当r=1 时,它等同于套索回归(方程 4-12)。
方程 4-12。弹性网成本函数
J(θ)=MSE(θ)+r2α∑i=1nθi+(1-r)αm∑i=1nθi2
那么何时使用弹性网回归,或者岭回归、套索回归,或者普通线性回归(即没有任何正则化)?通常最好至少有一点点正则化,因此通常应避免普通线性回归。岭回归是一个很好的默认选择,但如果您怀疑只有少数特征是有用的,您应该更喜欢套索或弹性网,因为它们倾向于将无用特征的权重降至零,正如前面讨论的那样。总的来说,相对于套索,弹性网更受青睐,因为当特征数量大于训练实例数量或者多个特征强相关时,套索可能表现不稳定。
这里有一个使用 Scikit-Learn 的ElasticNet的简短示例(l1_ratio对应混合比例r):
>>> from sklearn.linear_model import ElasticNet
>>> elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5)
>>> elastic_net.fit(X, y)
>>> elastic_net.predict([[1.5]])
array([1.54333232])
早停
一种非常不同的正则化迭代学习算法(如梯度下降)的方法是在验证错误达到最小值时停止训练。这被称为早停止。图 4-20 显示了一个复杂模型(在本例中,是一个高次多项式回归模型)在我们之前使用的二次数据集上使用批量梯度下降进行训练。随着时代的变迁,算法学习,其在训练集上的预测误差(RMSE)下降,以及在验证集上的预测误差也下降。然而,一段时间后,验证错误停止下降并开始上升。这表明模型已经开始过拟合训练数据。通过早停止,您只需在验证错误达到最小值时停止训练。这是一种简单而高效的正则化技术,Geoffrey Hinton 称之为“美丽的免费午餐”。
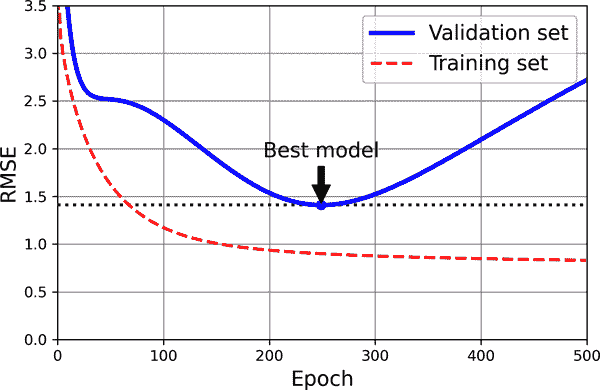
图 4-20。早停止正则化
提示
对于随机梯度下降和小批量梯度下降,曲线不那么平滑,可能很难知道是否已经达到最小值。一个解决方案是只有在验证错误超过最小值一段时间后(当您确信模型不会再有更好的表现时),然后将模型参数回滚到验证错误最小值的点。
这是早停止的基本实现:
from copy import deepcopy
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
X_train, y_train, X_valid, y_valid = [...] # split the quadratic dataset
preprocessing = make_pipeline(PolynomialFeatures(degree=90, include_bias=False),
StandardScaler())
X_train_prep = preprocessing.fit_transform(X_train)
X_valid_prep = preprocessing.transform(X_valid)
sgd_reg = SGDRegressor(penalty=None, eta0=0.002, random_state=42)
n_epochs = 500
best_valid_rmse = float('inf')
for epoch in range(n_epochs):
sgd_reg.partial_fit(X_train_prep, y_train)
y_valid_predict = sgd_reg.predict(X_valid_prep)
val_error = mean_squared_error(y_valid, y_valid_predict, squared=False)
if val_error < best_valid_rmse:
best_valid_rmse = val_error
best_model = deepcopy(sgd_reg)
这段代码首先添加多项式特征并缩放所有输入特征,对于训练集和验证集都是如此(代码假定您已将原始训练集分成较小的训练集和验证集)。然后它创建一个没有正则化和较小学习率的SGDRegressor模型。在训练循环中,它调用partial_fit()而不是fit(),以执行增量学习。在每个时代,它测量验证集上的 RMSE。如果低于迄今为止看到的最低 RMSE,则将模型的副本保存在best_model变量中。这个实现实际上并没有停止训练,但它允许您在训练后返回到最佳模型。请注意,使用copy.deepcopy()复制模型,因为它同时复制了模型的超参数和学习参数。相比之下,sklearn.base.clone()只复制模型的超参数。
逻辑回归
正如在第一章中讨论的那样,一些回归算法可以用于分类(反之亦然)。逻辑回归(也称为logit 回归)通常用于估计一个实例属于特定类别的概率(例如,这封电子邮件是垃圾邮件的概率是多少?)。如果估计的概率大于给定阈值(通常为 50%),则模型预测该实例属于该类别(称为正类,标记为“1”),否则预测它不属于该类别(即属于负类,标记为“0”)。这使其成为一个二元分类器。
估计概率
那么逻辑回归是如何工作的呢?就像线性回归模型一样,逻辑回归模型计算输入特征的加权和(加上偏置项),但是不像线性回归模型直接输出结果,它输出这个结果的逻辑(参见方程 4-13)。
方程 4-13。逻辑回归模型估计概率(向量化形式)
p ^ = h θ ( x ) = σ ( θ ⊺ x )
逻辑函数 σ(·) 是一个 S 形函数,输出介于 0 和 1 之间的数字。它的定义如 方程式 4-14 和 图 4-21 所示。
方程式 4-14. 逻辑函数
σ ( t ) = 1 1+exp(-t)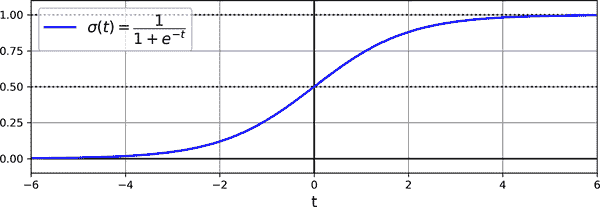
图 4-21. 逻辑函数
逻辑回归模型一旦估计出概率 p^ = hθ,即实例 x 属于正类的概率,它可以轻松地进行预测 ŷ(见 方程式 4-15)。
方程式 4-15. 使用 50% 阈值概率的逻辑回归模型预测
y ^ = 0 if p ^ < 0.5 1 if p ^ ≥ 0.5
注意到当 t < 0 时,σ(t) < 0.5,当 t ≥ 0 时,σ(t) ≥ 0.5,因此使用默认的 50% 概率阈值的逻辑回归模型会在 θ^⊺ x 为正时预测为 1,为负时预测为 0。
注意
得分 t 通常被称为 对数几率。这个名字来自于对数几率函数的定义,即 logit(p) = log(p / (1 – p)),它是逻辑函数的反函数。实际上,如果计算估计概率 p 的对数几率,你会发现结果是 t。对数几率也被称为 对数几率比,因为它是正类估计概率与负类估计概率之间的比值的对数。
训练和成本函数
现在你知道逻辑回归模型如何估计概率并进行预测了。但是它是如何训练的呢?训练的目标是设置参数向量 θ,使模型为正实例(y = 1)估计出高概率,为负实例(y = 0)估计出低概率。这个想法被 方程式 4-16 中的成本函数所捕捉,针对单个训练实例 x。
方程式 4-16. 单个训练实例的成本函数
c(θ)=-log(p^)if y=1-log(1-p^)if y=0
这个成本函数是有意义的,因为当 t 接近 0 时,–log(t) 会变得非常大,所以如果模型为正实例估计出接近 0 的概率,成本会很大,如果模型为负实例估计出接近 1 的概率,成本也会很大。另一方面,当 t 接近 1 时,–log(t) 接近 0,所以如果负实例的估计概率接近 0,或者正实例的估计概率接近 1,成本会接近 0,这正是我们想要的。
整个训练集上的成本函数是所有训练实例的平均成本。它可以用一个称为对数损失的单个表达式来表示,如方程 4-17 所示。
方程 4-17。逻辑回归成本函数(对数损失)
J(θ)=-1m∑i=1my(i)logp^(i)+(1-y(i))log1-p^(i)
警告
对数损失不是凭空想出来的。可以用数学方法(使用贝叶斯推断)证明,最小化这种损失将导致具有最大可能性的模型是最优的,假设实例围绕其类的平均值遵循高斯分布。当您使用对数损失时,这是您所做的隐含假设。这种假设错误越大,模型就会越有偏见。同样,当我们使用 MSE 来训练线性回归模型时,我们隐含地假设数据是纯线性的,再加上一些高斯噪声。因此,如果数据不是线性的(例如,如果是二次的),或者噪声不是高斯的(例如,如果异常值不是指数稀有的),那么模型就会有偏见。
坏消息是,没有已知的闭式方程可以计算最小化这个成本函数的θ的值(没有等价于正规方程)。但好消息是,这个成本函数是凸的,因此梯度下降(或任何其他优化算法)保证会找到全局最小值(如果学习率不是太大,并且等待足够长的时间)。成本函数对于j^(th)模型参数θ[j]的偏导数由方程 4-18 给出。
方程 4-18。逻辑成本函数偏导数
数学显示=“block”>∂ ∂θ j J ( θ ) = 1 m ∑ i=1 m σ ( θ ⊺ x (i) ) - y (i) x j (i)
这个方程看起来非常像方程 4-5:对于每个实例,它计算预测误差并将其乘以j^(th)特征值,然后计算所有训练实例的平均值。一旦有包含所有偏导数的梯度向量,您就可以在批量梯度下降算法中使用它。就是这样:您现在知道如何训练逻辑回归模型了。对于随机梯度下降,您将一次处理一个实例,对于小批量梯度下降,您将一次处理一个小批量。
决策边界
我们可以使用鸢尾花数据集来说明逻辑回归。这是一个包含 150 朵三种不同物种鸢尾花(Iris setosa、Iris versicolor和Iris virginica)的萼片和花瓣长度和宽度的著名数据集(参见图 4-22)。

图 4-22。三种鸢尾植物物种的花朵¹²
让我们尝试构建一个基于花瓣宽度特征的分类器来检测Iris virginica类型。第一步是加载数据并快速查看:
>>> from sklearn.datasets import load_iris
>>> iris = load_iris(as_frame=True)
>>> list(iris)
['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names',
'filename', 'data_module']
>>> iris.data.head(3)
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
>>> iris.target.head(3) # note that the instances are not shuffled
0 0
1 0
2 0
Name: target, dtype: int64
>>> iris.target_names
array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
接下来我们将拆分数据并在训练集上训练逻辑回归模型:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
X = iris.data[["petal width (cm)"]].values
y = iris.target_names[iris.target] == 'virginica'
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
log_reg = LogisticRegression(random_state=42)
log_reg.fit(X_train, y_train)
让我们看看模型对花朵的估计概率,这些花朵的花瓣宽度从 0 厘米到 3 厘米不等(参见图 4-23):¹³
X_new = np.linspace(0, 3, 1000).reshape(-1, 1) # reshape to get a column vector
y_proba = log_reg.predict_proba(X_new)
decision_boundary = X_new[y_proba[:, 1] >= 0.5][0, 0]
plt.plot(X_new, y_proba[:, 0], "b--", linewidth=2,
label="Not Iris virginica proba")
plt.plot(X_new, y_proba[:, 1], "g-", linewidth=2, label="Iris virginica proba")
plt.plot([decision_boundary, decision_boundary], [0, 1], "k:", linewidth=2,
label="Decision boundary")
[...] # beautify the figure: add grid, labels, axis, legend, arrows, and samples
plt.show()
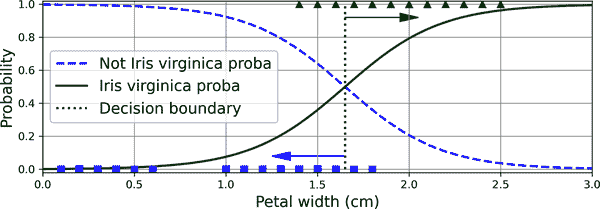
图 4-23。估计的概率和决策边界
Iris virginica花朵的花瓣宽度(表示为三角形)范围从 1.4 厘米到 2.5 厘米,而其他鸢尾花(用方块表示)通常具有较小的花瓣宽度,范围从 0.1 厘米到 1.8 厘米。请注意,存在一些重叠。大约在 2 厘米以上,分类器非常确信花朵是Iris virginica(输出该类的高概率),而在 1 厘米以下,它非常确信它不是Iris virginica(“非 Iris virginica”类的高概率)。在这两个极端之间,分类器不确定。但是,如果要求它预测类别(使用predict()方法而不是predict_proba()方法),它将返回最有可能的类别。因此,在大约 1.6 厘米处有一个决策边界,两个概率都等于 50%:如果花瓣宽度大于 1.6 厘米,分类器将预测花朵是Iris virginica,否则它将预测它不是(即使它不太自信):
>>> decision_boundary
1.6516516516516517
>>> log_reg.predict([[1.7], [1.5]])
array([ True, False])
图 4-24 显示了相同的数据集,但这次显示了两个特征:花瓣宽度和长度。一旦训练完成,逻辑回归分类器可以根据这两个特征估计新花朵是Iris virginica的概率。虚线代表模型估计 50%概率的点:这是模型的决策边界。请注意,这是一个线性边界。¹⁴ 每条平行线代表模型输出特定概率的点,从 15%(左下角)到 90%(右上角)。所有超过右上线的花朵根据模型有超过 90%的概率是Iris virginica。
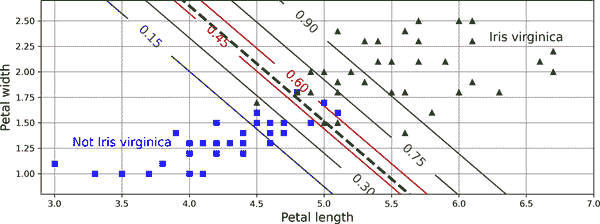
图 4-24。线性决策边界
注意
控制 Scikit-Learn LogisticRegression模型正则化强度的超参数不是alpha(像其他线性模型一样),而是它的倒数:C。C值越高,模型的正则化就越少。
与其他线性模型一样,逻辑回归模型可以使用ℓ[1]或ℓ[2]惩罚进行正则化。Scikit-Learn 实际上默认添加了ℓ[2]惩罚。
Softmax 回归
逻辑回归模型可以直接泛化为支持多类别,而无需训练和组合多个二元分类器(如第三章中讨论的)。这称为softmax 回归或多项式逻辑回归。
这个想法很简单:给定一个实例x,Softmax 回归模型首先为每个类别k计算一个分数s**k,然后通过应用softmax 函数(也称为归一化指数函数)来估计每个类别的概率。计算s**k的方程应该看起来很熟悉,因为它就像线性回归预测的方程(参见方程 4-19)。
方程 4-19。类别 k 的 Softmax 分数
s k ( x ) = (θ (k) ) ⊺ x
注意每个类别都有自己专用的参数向量θ^((k))。所有这些向量通常被存储为参数矩阵 Θ 的行。
一旦你计算出每个类别对于实例x的得分,你可以通过将得分通过 softmax 函数(方程 4-20)来估计实例属于类别k的概率p^k。该函数计算每个得分的指数,然后对它们进行归一化(除以所有指数的和)。这些得分通常被称为对数几率或对数几率(尽管它们实际上是未归一化的对数几率)。
方程 4-20. Softmax 函数
p ^ k = σ s(x) k = exps k (x) ∑ j=1 K exps j (x)
在这个方程中:
-
K 是类别的数量。
-
s(x)是包含实例x每个类别得分的向量。
-
σ(s(x))[k]是实例x属于类别k的估计概率,给定该实例每个类别的得分。
就像逻辑回归分类器一样,默认情况下,softmax 回归分类器预测具有最高估计概率的类别(即具有最高得分的类别),如方程 4-21 所示。
方程 4-21. Softmax 回归分类器预测
y ^ = argmax k σ s(x) k = argmax k s <mi k ( x ) = argmax k (θ (k) ) ⊺ x
argmax运算符返回最大化函数的变量值。在这个方程中,它返回最大化估计概率σ(s(x))[k]的k值。
提示
softmax 回归分类器一次只预测一个类别(即它是多类别的,而不是多输出的),因此它只能用于具有互斥类别的情况,例如不同种类的植物。你不能用它来识别一张图片中的多个人。
现在你知道模型如何估计概率并进行预测了,让我们来看看训练。目标是让模型估计目标类的概率很高(因此其他类的概率很低)。最小化方程 4-22 中显示的成本函数,称为交叉熵,应该能够实现这个目标,因为当模型估计目标类的概率很低时,它会受到惩罚。交叉熵经常用来衡量一组估计的类别概率与目标类别的匹配程度。
方程 4-22. 交叉熵成本函数
J(Θ)=-1m∑i=1m∑k=1Kyk(i)logp^k(i)
在这个方程中,yk(i)是第i个实例属于第k类的目标概率。一般来说,它要么等于 1,要么等于 0,取决于实例是否属于该类。
注意,当只有两类(K = 2)时,这个成本函数等同于逻辑回归成本函数(对数损失;参见方程 4-17)。
这个成本函数关于θ^((k))的梯度向量由方程 4-23 给出。
方程 4-23. 类别 k 的交叉熵梯度向量
∇ θ (k) J ( Θ ) = 1 m ∑ i=1 m p ^ k (i) - y k (i) x (i)
现在你可以计算每个类别的梯度向量,然后使用梯度下降(或任何其他优化算法)来找到最小化成本函数的参数矩阵Θ。
让我们使用 softmax 回归将鸢尾花分类为所有三类。当你在多于两类上训练 Scikit-Learn 的LogisticRegression分类器时,它会自动使用 softmax 回归(假设你使用solver="lbfgs",这是默认值)。它还默认应用ℓ[2]正则化,你可以使用之前提到的超参数C来控制:
X = iris.data[["petal length (cm)", "petal width (cm)"]].values
y = iris["target"]
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
softmax_reg = LogisticRegression(C=30, random_state=42)
softmax_reg.fit(X_train, y_train)
所以下次当你发现一朵花瓣长 5 厘米,宽 2 厘米的鸢尾花时,你可以让你的模型告诉你它是什么类型的鸢尾花,它会以 96%的概率回答Iris virginica(第 2 类)(或以 4%的概率回答Iris versicolor):
>>> softmax_reg.predict([[5, 2]])
array([2])
>>> softmax_reg.predict_proba([[5, 2]]).round(2)
array([[0\. , 0.04, 0.96]])
图 4-25 显示了由背景颜色表示的决策边界。请注意,任意两个类之间的决策边界是线性的。图中还显示了Iris versicolor类的概率,由曲线表示(例如,标有 0.30 的线表示 30% 概率边界)。请注意,模型可以预测估计概率低于 50% 的类。例如,在所有决策边界相交的点,所有类的估计概率均为 33%。
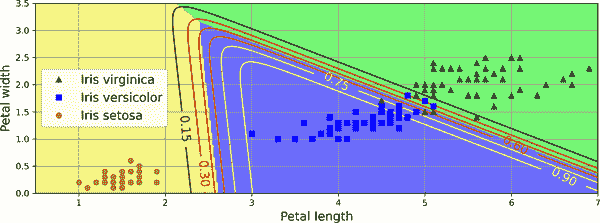
图 4-25. Softmax 回归决策边界
在本章中,你学习了训练线性模型的各种方法,包括回归和分类。你使用闭式方程解决线性回归问题,以及梯度下降,并学习了在训练过程中如何向成本函数添加各种惩罚以对模型进行正则化。在此过程中,你还学习了如何绘制学习曲线并分析它们,以及如何实现早期停止。最后,你学习了逻辑回归和 softmax 回归的工作原理。我们已经打开了第一个机器学习黑匣子!在接下来的章节中,我们将打开更多黑匣子,从支持向量机开始。
练习
-
如果你有一个拥有数百万个特征的训练集,你可以使用哪种线性回归训练算法?
-
假设你的训练集中的特征具有非常不同的尺度。哪些算法可能会受到影响,以及如何受影响?你可以采取什么措施?
-
在训练逻辑回归模型时,梯度下降是否会陷入局部最小值?
-
如果让所有梯度下降算法运行足够长的时间,它们会导致相同的模型吗?
-
假设你使用批量梯度下降,并在每个时期绘制验证误差。如果你注意到验证误差持续上升,可能出现了什么问题?如何解决?
-
当验证误差上升时,立即停止小批量梯度下降是一个好主意吗?
-
在我们讨论的梯度下降算法中,哪种算法会最快接近最优解?哪种实际上会收敛?如何使其他算法也收敛?
-
假设你正在使用多项式回归。你绘制学习曲线并注意到训练误差和验证误差之间存在很大差距。发生了什么?有哪三种方法可以解决这个问题?
-
假设你正在使用岭回归,并且注意到训练误差和验证误差几乎相等且相当高。你会说模型存在高偏差还是高方差?你应该增加正则化超参数α还是减少它?
-
为什么要使用:
-
是否可以使用岭回归代替普通线性回归(即,没有任何正则化)?
-
是否可以使用 Lasso 代替岭回归?
-
是否可以使用弹性网络代替 Lasso 回归?
-
-
假设你想要将图片分类为室内/室外和白天/黑夜。你应该实现两个逻辑回归分类器还是一个 softmax 回归分类器?
-
使用 NumPy 实现批量梯度下降并进行早期停止以进行 softmax 回归,而不使用 Scikit-Learn。将其应用于鸢尾花数据集等分类任务。
这些练习的解决方案可在本章笔记本的末尾找到,网址为https://homl.info/colab3。
¹ 闭式方程仅由有限数量的常数、变量和标准操作组成:例如,a = sin(b – c)。没有无限求和、极限、积分等。
² 从技术上讲,它的导数是Lipschitz 连续的。
³ 由于特征 1 较小,改变θ[1]以影响成本函数需要更大的变化,这就是为什么碗沿着θ[1]轴被拉长的原因。
⁴ Eta(η)是希腊字母表的第七个字母。
⁵ 而正规方程只能执行线性回归,梯度下降算法可以用来训练许多其他模型,您将会看到。
⁶ 这种偏差的概念不应与线性模型的偏差项混淆。
⁷ 通常使用符号J(θ)表示没有简短名称的代价函数;在本书的其余部分中,我经常会使用这种符号。上下文将清楚地表明正在讨论哪个代价函数。
⁸ 范数在第二章中讨论。
⁹ 一个全是 0 的方阵,除了主对角线(从左上到右下)上的 1。
¹⁰ 或者,您可以使用Ridge类与"sag"求解器。随机平均梯度下降是随机梯度下降的一种变体。有关更多详细信息,请参阅由不列颠哥伦比亚大学的 Mark Schmidt 等人提出的演示“使用随机平均梯度算法最小化有限和”。
¹¹ 您可以将非可微点处的次梯度向量视为该点周围梯度向量之间的中间向量。
¹² 照片来源于相应的维基百科页面。Iris virginica照片由 Frank Mayfield 拍摄(知识共享署名-相同方式共享 2.0),Iris versicolor照片由 D. Gordon E. Robertson 拍摄(知识共享署名-相同方式共享 3.0),Iris setosa照片为公共领域。
¹³ NumPy 的reshape()函数允许一个维度为-1,表示“自动”:该值是从数组的长度和剩余维度推断出来的。
¹⁴ 它是一组点x,使得θ[0] + θ[1]x[1] + θ[2]x[2] = 0,这定义了一条直线。
第五章:支持向量机
支持向量机(SVM)是一个强大且多功能的机器学习模型,能够执行线性或非线性分类、回归,甚至新颖性检测。SVM 在小到中等大小的非线性数据集(即,数百到数千个实例)上表现出色,尤其适用于分类任务。然而,它们在处理非常大的数据集时并不很好,您将看到。
本章将解释 SVM 的核心概念,如何使用它们以及它们的工作原理。让我们开始吧!
线性 SVM 分类
支持向量机背后的基本思想最好通过一些可视化来解释。图 5-1 展示了在第四章末尾介绍的鸢尾花数据集的一部分。这两个类可以很容易地用一条直线分开(它们是线性可分的)。左图显示了三种可能线性分类器的决策边界。决策边界由虚线表示的模型非常糟糕,甚至不能正确地分开这两个类。其他两个模型在这个训练集上表现完美,但它们的决策边界与实例非常接近,因此这些模型在新实例上可能表现不佳。相比之下,右图中的实线代表 SVM 分类器的决策边界;这条线不仅分开了两个类,而且尽可能远离最接近的训练实例。您可以将 SVM 分类器视为在类之间拟合最宽可能的街道(由平行虚线表示)。这被称为大边距分类。
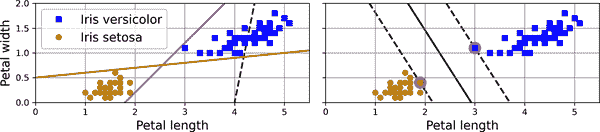
图 5-1. 大边距分类
请注意,添加更多训练实例“离开街道”不会对决策边界产生任何影响:它完全由位于街道边缘的实例决定(或“支持”)。这些实例被称为支持向量(它们在图 5-1 中被圈出)。
警告
支持向量机对特征的尺度敏感,如您可以在图 5-2 中看到。在左图中,垂直尺度远大于水平尺度,因此最宽可能的街道接近水平。经过特征缩放(例如,使用 Scikit-Learn 的StandardScaler),右图中的决策边界看起来好多了。
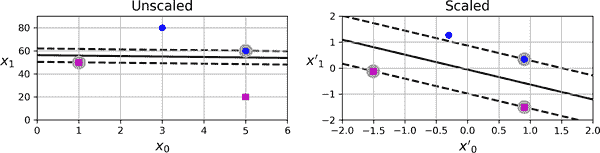
图 5-2. 特征尺度的敏感性
软边距分类
如果我们严格要求所有实例必须远离街道并位于正确的一侧,这被称为硬边距分类。硬边距分类存在两个主要问题。首先,它仅在数据线性可分时有效。其次,它对异常值敏感。图 5-3 展示了鸢尾花数据集中仅有一个额外异常值的情况:在左侧,找到硬边距是不可能的;在右侧,决策边界与图 5-1 中看到的没有异常值的情决策边界非常不同,模型可能不会很好地泛化。
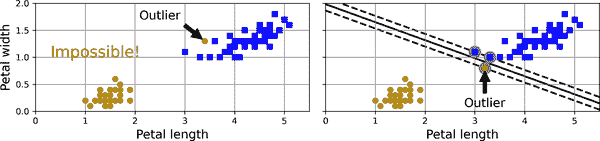
图 5-3. 硬边距对异常值的敏感性
为了避免这些问题,我们需要使用一个更灵活的模型。目标是在尽可能保持街道尽可能宽阔和限制边距违规(即,最终位于街道中间甚至错误一侧的实例)之间找到一个良好的平衡。这被称为软边距分类。
在使用 Scikit-Learn 创建 SVM 模型时,您可以指定几个超参数,包括正则化超参数C。如果将其设置为较低的值,则会得到左侧图 5-4 中的模型。如果设置为较高的值,则会得到右侧的模型。正如您所看到的,减少C会使街道变宽,但也会导致更多的间隔违规。换句话说,减少C会导致更多的实例支持街道,因此过拟合的风险较小。但是,如果减少得太多,那么模型最终会欠拟合,就像这里的情况一样:C=100的模型看起来比C=1的模型更容易泛化。
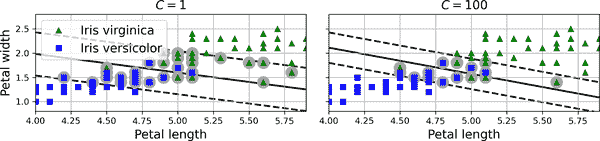
图 5-4. 大间隔(左)与较少间隔违规(右)
提示
如果您的 SVM 模型过拟合,可以尝试通过减少C来对其进行正则化。
以下 Scikit-Learn 代码加载了鸢尾花数据集,并训练了一个线性 SVM 分类器来检测Iris virginica花。该流水线首先对特征进行缩放,然后使用LinearSVC和C=1进行训练:
from sklearn.datasets import load_iris
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris = load_iris(as_frame=True)
X = iris.data[["petal length (cm)", "petal width (cm)"]].values
y = (iris.target == 2) # Iris virginica
svm_clf = make_pipeline(StandardScaler(),
LinearSVC(C=1, random_state=42))
svm_clf.fit(X, y)
生成的模型在图 5-4 的左侧表示。
然后,像往常一样,您可以使用模型进行预测:
>>> X_new = [[5.5, 1.7], [5.0, 1.5]]
>>> svm_clf.predict(X_new)
array([ True, False])
第一个植物被分类为Iris virginica,而第二个没有。让我们看看 SVM 用于做出这些预测的分数。这些分数衡量了每个实例与决策边界之间的有符号距离:
>>> svm_clf.decision_function(X_new)
array([ 0.66163411, -0.22036063])
与LogisticRegression不同,LinearSVC没有predict_proba()方法来估计类概率。也就是说,如果您使用SVC类(稍后讨论)而不是LinearSVC,并将其probability超参数设置为True,那么模型将在训练结束时拟合一个额外的模型,将 SVM 决策函数分数映射到估计概率。在幕后,这需要使用 5 倍交叉验证为训练集中的每个实例生成样本外预测,然后训练一个LogisticRegression模型,因此会显著减慢训练速度。之后,predict_proba()和predict_log_proba()方法将可用。
非线性 SVM 分类
尽管线性 SVM 分类器高效且通常表现出色,但许多数据集甚至远非线性可分。处理非线性数据集的一种方法是添加更多特征,例如多项式特征(就像我们在第四章中所做的那样);在某些情况下,这可能会导致一个线性可分的数据集。考虑图 5-5 中的左侧图:它代表一个只有一个特征x[1]的简单数据集。正如您所看到的,这个数据集是线性不可分的。但是,如果添加第二个特征x[2] = (x[1])²,那么得到的 2D 数据集就是完全线性可分的。
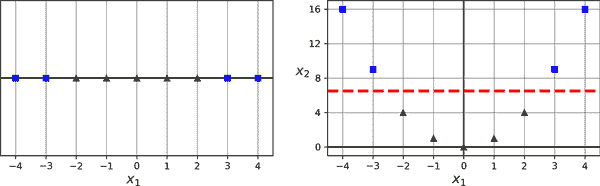
图 5-5. 添加特征使数据集线性可分
要使用 Scikit-Learn 实现这个想法,您可以创建一个包含PolynomialFeatures转换器(在“多项式回归”中讨论)、StandardScaler和LinearSVC分类器的流水线。让我们在 moons 数据集上测试这个流水线,这是一个用于二元分类的玩具数据集,其中数据点呈两个交错新月形状(参见图 5-6)。您可以使用make_moons()函数生成这个数据集:
from sklearn.datasets import make_moons
from sklearn.preprocessing import PolynomialFeatures
X, y = make_moons(n_samples=100, noise=0.15, random_state=42)
polynomial_svm_clf = make_pipeline(
PolynomialFeatures(degree=3),
StandardScaler(),
LinearSVC(C=10, max_iter=10_000, random_state=42)
)
polynomial_svm_clf.fit(X, y)
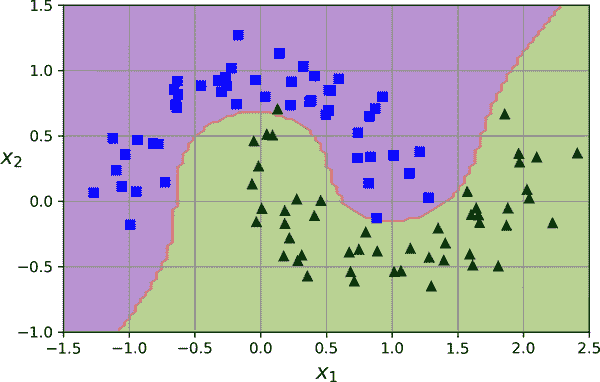
图 5-6. 使用多项式特征的线性 SVM 分类器
多项式核
添加多项式特征很容易实现,并且可以与各种机器学习算法(不仅仅是 SVM)很好地配合。也就是说,在低多项式度数下,这种方法无法处理非常复杂的数据集,而在高多项式度数下,它会创建大量特征,使模型变得过于缓慢。
幸运的是,在使用 SVM 时,你可以应用一种几乎神奇的数学技术,称为核技巧(稍后在本章中解释)。核技巧使得可以获得与添加许多多项式特征相同的结果,即使是非常高次的,而无需实际添加它们。这意味着特征数量不会组合爆炸。这个技巧由SVC类实现。让我们在 moons 数据集上测试一下:
from sklearn.svm import SVC
poly_kernel_svm_clf = make_pipeline(StandardScaler(),
SVC(kernel="poly", degree=3, coef0=1, C=5))
poly_kernel_svm_clf.fit(X, y)
这段代码使用三次多项式核训练了一个 SVM 分类器,左侧在图 5-7 中表示。右侧是另一个使用十次多项式核的 SVM 分类器。显然,如果你的模型出现过拟合,你可能需要降低多项式次数。相反,如果出现欠拟合,你可以尝试增加它。超参数coef0控制模型受高次项和低次项影响的程度。
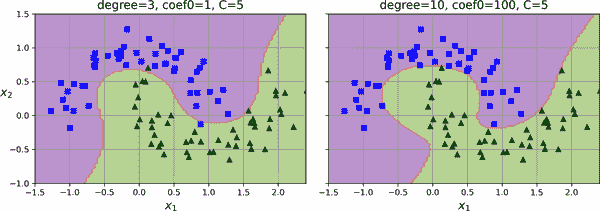
图 5-7. 使用多项式核的 SVM 分类器
提示
虽然超参数通常会自动调整(例如使用随机搜索),但了解每个超参数实际上是做什么以及它如何与其他超参数交互是很有帮助的:这样,你可以将搜索范围缩小到一个更小的空间。
相似性特征
解决非线性问题的另一种技术是添加使用相似性函数计算的特征,该函数衡量每个实例与特定“地标”的相似程度,就像我们在第二章中添加地理相似性特征时所做的那样。例如,让我们取之前的一维数据集,在x[1] = -2 和x[1] = 1 处添加两个地标(参见图 5-8 中的左图)。接下来,我们将定义相似性函数为带有γ = 0.3 的高斯 RBF。这是一个钟形函数,从 0(远离地标)变化到 1(在地标处)。
现在我们准备计算新特征。例如,让我们看一下实例x[1] = -1:它距离第一个地标 1,距离第二个地标 2。因此,它的新特征是x[2] = exp(–0.3 × 1²) ≈ 0.74 和x[3] = exp(–0.3 × 2²) ≈ 0.30。图 5-8 中右侧的图显示了转换后的数据集(放弃了原始特征)。如你所见,现在它是线性可分的。
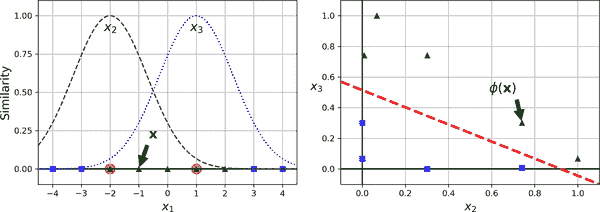
图 5-8. 使用高斯 RBF 的相似性特征
你可能想知道如何选择地标。最简单的方法是在数据集中的每个实例位置创建一个地标。这样做会创建许多维度,从而增加转换后的训练集线性可分的机会。缺点是,一个包含m个实例和n个特征的训练集会转换为一个包含m个实例和m个特征的训练集(假设你放弃了原始特征)。如果你的训练集非常大,最终会得到同样数量的特征。
高斯 RBF 核
与多项式特征方法一样,相似性特征方法可以与任何机器学习算法一起使用,但计算所有额外特征可能会很昂贵(尤其是在大型训练集上)。再次,核技巧发挥了 SVM 的魔力,使得可以获得与添加许多相似性特征相同的结果,但实际上并没有这样做。让我们尝试使用高斯 RBF 核的SVC类:
rbf_kernel_svm_clf = make_pipeline(StandardScaler(),
SVC(kernel="rbf", gamma=5, C=0.001))
rbf_kernel_svm_clf.fit(X, y)
这个模型在图 5-9 的左下角表示。其他图显示了使用不同超参数gamma(γ)和C训练的模型。增加gamma会使钟形曲线变窄(参见图 5-8 中的左侧图)。因此,每个实例的影响范围更小:决策边界最终变得更加不规则,围绕个别实例摆动。相反,较小的gamma值会使钟形曲线变宽:实例的影响范围更大,决策边界变得更加平滑。因此,γ就像一个正则化超参数:如果你的模型过拟合,应该减小γ;如果欠拟合,应该增加γ(类似于C超参数)。
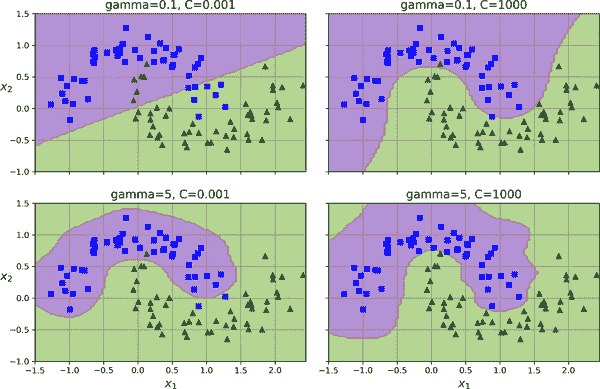
图 5-9。使用 RBF 核的 SVM 分类器
其他核存在,但使用得更少。一些核专门用于特定的数据结构。字符串核有时用于对文本文档或 DNA 序列进行分类(例如,使用字符串子序列核或基于 Levenshtein 距离的核)。
提示
有这么多核可供选择,你如何决定使用哪一个?作为一个经验法则,你应该始终首先尝试线性核。LinearSVC类比SVC(kernel="linear")快得多,特别是当训练集非常大时。如果不太大,你也应该尝试核化的 SVM,首先使用高斯 RBF 核;它通常效果很好。然后,如果你有多余的时间和计算能力,你可以尝试使用一些其他核进行超参数搜索。如果有专门针对你的训练集数据结构的核,也要试一试。
SVM 类和计算复杂度
LinearSVC类基于liblinear库,该库实现了线性 SVM 的优化算法。¹ 它不支持核技巧,但随着训练实例数量和特征数量的增加,它的缩放几乎是线性的。其训练时间复杂度大约为O(m × n)。如果需要非常高的精度,算法会花费更长的时间。这由容差超参数ϵ(在 Scikit-Learn 中称为tol)控制。在大多数分类任务中,默认容差是可以接受的。
SVC类基于libsvm库,该库实现了一个支持核技巧的算法。² 训练时间复杂度通常在O(m² × n)和O(m³ × n)之间。不幸的是,这意味着当训练实例数量变大时(例如,数十万个实例),算法会变得非常慢,因此这个算法最适合小型或中等大小的非线性训练集。它对特征数量的缩放效果很好,特别是对于稀疏特征(即每个实例具有很少的非零特征)。在这种情况下,算法的缩放大致与每个实例的平均非零特征数量成比例。
SGDClassifier类默认也执行大边距分类,其超参数,特别是正则化超参数(alpha和penalty)和learning_rate,可以调整以产生与线性 SVM 类似的结果。它使用随机梯度下降进行训练(参见第四章),允许增量学习并且使用很少的内存,因此可以用于在 RAM 中无法容纳的大型数据集上训练模型(即用于外存学习)。此外,它的缩放非常好,因为其计算复杂度为O(m × n)。表 5-1 比较了 Scikit-Learn 的 SVM 分类类。
表 5-1。Scikit-Learn 用于 SVM 分类的类比较
| 类别 | 时间复杂度 | 外存支持 | 需要缩放 | 核技巧 |
|---|---|---|---|---|
LinearSVC | O(m × n) | 否 | 是 | 否 |
SVC | O(m² × n) 到 O(m³ × n) | 否 | 是 | 是 |
SGDClassifier | O(m × n) | 是 | 是 | 否 |
现在让我们看看 SVM 算法如何用于线性和非线性回归。
SVM 回归
要将 SVM 用于回归而不是分类,关键是调整目标:不再试图在两个类之间拟合尽可能大的间隔同时限制间隔违规,SVM 回归试图在尽可能多的实例在间隔上拟合,同时限制间隔违规(即实例在间隔之外)。间隔的宽度由超参数ϵ控制。图 5-10 显示了在一些线性数据上训练的两个线性 SVM 回归模型,一个具有较小的间隔(ϵ = 0.5),另一个具有较大的间隔(ϵ = 1.2)。
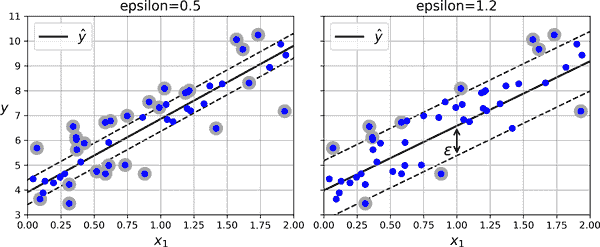
图 5-10。SVM 回归
减小ϵ会增加支持向量的数量,从而对模型进行正则化。此外,如果在间隔内添加更多训练实例,不会影响模型的预测;因此,该模型被称为ϵ-不敏感。
您可以使用 Scikit-Learn 的LinearSVR类执行线性 SVM 回归。以下代码生成了左侧图中表示的模型图 5-10:
from sklearn.svm import LinearSVR
X, y = [...] # a linear dataset
svm_reg = make_pipeline(StandardScaler(),
LinearSVR(epsilon=0.5, random_state=42))
svm_reg.fit(X, y)
为了处理非线性回归任务,您可以使用核化的 SVM 模型。图 5-11 显示了在随机二次训练集上使用二次多项式核进行 SVM 回归。左图中有一些正则化(即较小的C值),右图中的正则化要少得多(即较大的C值)。
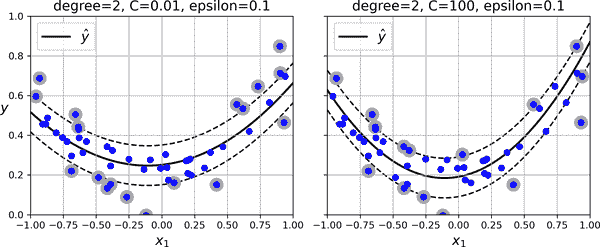
图 5-11。使用二次多项式核的 SVM 回归
以下代码使用 Scikit-Learn 的SVR类(支持核技巧)生成了左侧图中表示的模型图 5-11:
from sklearn.svm import SVR
X, y = [...] # a quadratic dataset
svm_poly_reg = make_pipeline(StandardScaler(),
SVR(kernel="poly", degree=2, C=0.01, epsilon=0.1))
svm_poly_reg.fit(X, y)
SVR类是SVC类的回归等价物,LinearSVR类是LinearSVC类的回归等价物。LinearSVR类与训练集的大小呈线性比例(就像LinearSVC类一样),而SVR类在训练集增长非常大时变得非常慢(就像SVC类一样)。
注意
支持向量机也可以用于新颖性检测,正如您将在第九章中看到的那样。
本章的其余部分将解释 SVM 如何进行预测以及它们的训练算法是如何工作的,从线性 SVM 分类器开始。如果您刚开始学习机器学习,可以安全地跳过这部分,直接转到本章末尾的练习,并在以后想要更深入地了解 SVM 时再回来。
线性 SVM 分类器的内部工作原理
线性 SVM 分类器通过首先计算决策函数θ^⊺ x = θ[0] x[0] + ⋯ + θ[n] x[n]来预测新实例x的类别,其中x[0]是偏置特征(始终等于 1)。如果结果为正,则预测的类别ŷ为正类(1);否则为负类(0)。这与LogisticRegression(在第四章中讨论)完全相同。
注意
到目前为止,我一直使用将所有模型参数放在一个向量θ中的约定,包括偏置项θ[0]和输入特征权重θ[1]到θ[n]。这需要向所有实例添加一个偏置输入x[0] = 1。另一个非常常见的约定是将偏置项b(等于θ[0])和特征权重向量w(包含θ[1]到θ[n])分开。在这种情况下,不需要向输入特征向量添加偏置特征,线性 SVM 的决策函数等于w^⊺ x + b = w[1] x[1] + ⋯ + w[n] x[n] + b。我将在本书的其余部分中使用这种约定。
因此,使用线性 SVM 分类器进行预测非常简单。那么训练呢?这需要找到使街道或边界尽可能宽阔的权重向量w和偏置项b,同时限制边界违规的数量。让我们从街道的宽度开始:为了使其更宽,我们需要使w更小。这在 2D 中可能更容易可视化,如图 5-12 所示。让我们将街道的边界定义为决策函数等于-1 或+1 的点。在左图中,权重w[1]为 1,因此w[1] x[1] = -1 或+1 的点是x[1] = -1 和+1:因此边界的大小为 2。在右图中,权重为 0.5,因此w[1] x[1] = -1 或+1 的点是x[1] = -2 和+2:边界的大小为 4。因此,我们需要尽可能保持w较小。请注意,偏置项b对边界的大小没有影响:调整它只是移动边界,而不影响其大小。
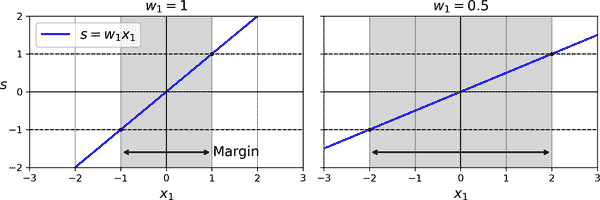
图 5-12. 较小的权重向量导致较大的边界
我们还希望避免边界违规,因此我们需要决策函数对所有正训练实例大于 1,对负训练实例小于-1。如果我们定义t^((i)) = -1 为负实例(当y^((i)) = 0 时),t^((i)) = 1 为正实例(当y^((i)) = 1 时),那么我们可以将这个约束写为t((*i*))(**w**⊺ x^((i)) + b) ≥ 1 对所有实例成立。
因此,我们可以将硬间隔线性 SVM 分类器的目标表达为方程 5-1 中的约束优化问题。
方程 5-1. 硬间隔线性 SVM 分类器目标
minimize w,b 1 2 w ⊺ w subject to t (i) ( w ⊺ x (i) + b ) ≥ 1 for i = 1 , 2 , ⋯ , m
注意
我们最小化的是½ w^⊺ w,它等于½∥ w ∥²,而不是最小化∥ w ∥(w的范数)。实际上,½∥ w ∥²具有一个简单的导数(就是w),而∥ w ∥在w = 0 处不可微。优化算法在可微函数上通常效果更好。
为了得到软间隔目标,我们需要为每个实例引入一个松弛变量 ζ^((i)) ≥ 0:³ ζ^((i))衡量第i个实例允许违反边界的程度。现在我们有两个相互冲突的目标:尽量减小松弛变量以减少边界违规,同时尽量减小½ w^⊺ w以增加边界。这就是C超参数的作用:它允许我们定义这两个目标之间的权衡。这给我们带来了方程 5-2 中的约束优化问题。
方程 5-2. 软间隔线性 SVM 分类器目标
最小化 w,b,ζ 1 2 w ⊺ w + C ∑ i=1 m ζ (i) 受限于 满足 t (i) ( w ⊺ x (i) + b ) ≥ 1 - ζ (i) 且 ζ (i) ≥ 0 对于 i = 1 , 2 , ⋯ , m
硬间隔和软间隔问题都是具有线性约束的凸二次优化问题。这些问题被称为二次规划(QP)问题。许多现成的求解器可用于通过使用本书范围之外的各种技术来解决 QP 问题。⁴
使用 QP 求解器是训练 SVM 的一种方法。另一种方法是使用梯度下降来最小化铰链损失或平方铰链损失(见图 5-13)。给定正类别(即,t=1)的实例x,如果决策函数的输出s(s = w^⊺ x + b)大于或等于 1,则损失为 0。这发生在实例偏离街道并位于正侧时。给定负类别(即,t=-1)的实例,如果s ≤ -1,则损失为 0。这发生在实例偏离街道并位于负侧时。实例距离正确边界越远,损失越高:对于铰链损失,它线性增长,对于平方铰链损失,它二次增长。这使得平方铰链损失对异常值更敏感。但是,如果数据集干净,它往往会更快地收敛。默认情况下,LinearSVC使用平方铰链损失,而SGDClassifier使用铰链损失。这两个类允许您通过将loss超参数设置为"hinge"或"squared_hinge"来选择损失。SVC类的优化算法找到了与最小化铰链损失类似的解。
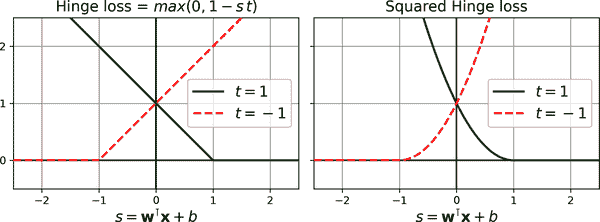
图 5-13. 铰链损失(左)和平方铰链损失(右)
接下来,我们将看另一种训练线性 SVM 分类器的方法:解决对偶问题。
对偶问题
给定一个约束优化问题,称为原始问题,可以表达一个不同但密切相关的问题,称为对偶问题。对于对偶问题的解通常给出原始问题解的下界,但在某些条件下,它可以与原始问题具有相同的解。幸运的是,SVM 问题恰好符合这些条件,⁵,因此您可以选择解决原始问题或对偶问题;两者都将有相同的解。方程 5-3 显示了线性 SVM 目标的对偶形式。如果您想了解如何从原始问题推导出对偶问题,请参阅本章笔记本中的额外材料部分。
方程 5-3. 线性 SVM 目标的对偶形式
最小化 α12∑i=1m∑j=1mα(i)α(j)t(i)t(j)x(i)⊺x(j)-∑i=1mα(i)受限于 α(i)≥0 对于所有 i=1,2,…,m 和 ∑i=1mα(i)t(i)=0
一旦找到最小化这个方程的向量α ^(使用 QP 求解器),使用方程 5-4 来计算最小化原始问题的w ^和b^。在这个方程中,n[s]代表支持向量的数量。
方程 5-4. 从对偶解到原始解
w ^ = ∑ i=1 m α ^ (i) t (i) x (i) b ^ = 1 n s ∑ i=1 α ^ (i) >0 m t (i) - w ^ ⊺ x (i)
当训练实例的数量小于特征数量时,对偶问题比原始问题更快解决。更重要的是,对偶问题使核技巧成为可能,而原始问题则不行。那么这个核技巧到底是什么呢?
核化支持向量机
假设你想对一个二维训练集(比如 moons 训练集)应用二次多项式转换,然后在转换后的训练集上训练一个线性 SVM 分类器。方程 5-5 展示了你想应用的二次多项式映射函数ϕ。
方程 5-5. 二次多项式映射
ϕ x = ϕ x 1 x 2 = x 1 2 2 x 1 x 2 x 2 2
请注意,转换后的向量是 3D 而不是 2D。现在让我们看看如果我们应用这个二次多项式映射,然后计算转换后向量的点积,2D 向量a和b会发生什么(参见方程 5-6)。
方程 5-6. 二次多项式映射的核技巧
ϕ (a) ⊺ ϕ ( b ) = a 1 2 2a 1 a 2 a 2 2 ⊺ b 1 2 2 b 1 b 2 b 2 2 = a 1 2 b 1 2 + 2 a 1 b 1 a 2 b 2 + a 2 2 b 2 2 = a 1 b 1 +a 2 b 2 2 = a 1 a 2 ⊺ b 1 b 2 2 = (a ⊺ b) 2
如何?转换后的向量的点积等于原始向量的点积的平方:ϕ(a)^⊺ ϕ(b) = (a^⊺ b)²。
这里的关键见解是:如果将转换 ϕ 应用于所有训练实例,那么对偶问题(参见方程 5-3)将包含点积 ϕ(x((*i*)))⊺ ϕ(x^((j)))。但如果 ϕ 是在方程 5-5 中定义的二次多项式变换,那么你可以简单地用(x (i) ⊺ x (j) ) 2来替换这些转换后向量的点积。因此,你根本不需要转换训练实例;只需在方程 5-3 中用其平方替换点积。结果将严格与你经历转换训练集然后拟合线性 SVM 算法的麻烦完全相同,但这个技巧使整个过程更加高效。
函数K(a,b)=(a^⊺ b)²是一个二次多项式核。在机器学习中,核是一个能够基于原始向量a和b计算点积ϕ(a)^⊺ ϕ(b)的函数,而无需计算(甚至了解)变换ϕ。方程 5-7 列出了一些最常用的核。
方程 5-7。常见核
线性: K ( a , b ) = a ⊺ b 多项式: K ( a , b ) = γa ⊺ b+r d 高斯 RBF: K ( a , b ) = exp ( - γ a-b 2 ) 双曲正切: K ( a , b ) = tanh γ a ⊺ b + r
我们还有一个问题要解决。方程 5-4 展示了如何在线性 SVM 分类器的情况下从对偶解到原始解的转换。但是如果应用核技巧,你会得到包含ϕ(x^((i)))的方程。事实上,w </mo></mover></math>必须具有与*ϕ*(*x*((i)))相同数量的维度,这可能非常庞大甚至无限,因此无法计算。但是,如何在不知道w ^的情况下进行预测呢?好消息是,你可以将方程 5-4 中的w </mo></mover></math>公式代入新实例**x**((n))的决策函数中,得到一个只涉及输入向量点积的方程。这使得可以使用核技巧(方程 5-8)。
方程 5-8。使用核化 SVM 进行预测
h w ^,b ^ ϕ ( x (n) ) = w ^ ⊺ ϕ ( x (n) ) + b ^ = ∑ i=1 m α ^ (i) t (i) ϕ(x (i) ) ⊺ ϕ ( x (n) ) + b ^ = ∑ i=1 m α ^ (i) t (i) ϕ (x (i) ) ⊺ ϕ ( x (n) ) + b ^ = ∑ i=1 α ^ (i) >0 m α ^ (i) t (i) K ( x (i) , x (n) ) + b ^
请注意,由于α^((i)) ≠ 0 仅对支持向量有效,因此进行预测涉及计算新输入向量 x^((n)) 与仅支持向量的点积,而不是所有训练实例。当然,您需要使用相同的技巧来计算偏置项 b^(方程 5-9)。
方程 5-9。使用核技巧计算偏置项
b ^ = 1 n s ∑ i=1 α ^ (i) >0 m t (i) - w ^ ⊺ ϕ ( x (i) ) = 1 n s ∑ i=1 α ^ (i) >0 m t (i) - ∑ j=1 m α ^ (j) t (j) ϕ(x (j) ) ⊺ ϕ ( x (i) ) = 1 n s ∑ i=1 α ^ (i) >0 m t (i) - ∑ j=1 α ^ (j) >0 m α ^ (j) t (j) K ( x (i) , x (j) )
如果您开始头痛,那是完全正常的:这是核技巧的一个不幸的副作用。
注意
还可以实现在线核化 SVM,能够进行增量学习,如论文“增量和减量支持向量机学习”⁷和“具有在线和主动学习的快速核分类器”中所述。⁸这些核化 SVM 是用 Matlab 和 C++实现的。但对于大规模非线性问题,您可能需要考虑使用随机森林(参见第七章)或神经网络(参见第 II 部分)。
练习
-
支持向量机背后的基本思想是什么?
-
支持向量是什么?
-
在使用 SVM 时为什么重要对输入进行缩放?
-
SVM 分类器在对一个实例进行分类时能输出置信度分数吗?概率呢?
-
您如何在
LinearSVC、SVC和SGDClassifier之间进行选择? -
假设您使用 RBF 核训练了一个 SVM 分类器,但似乎对训练集欠拟合。您应该增加还是减少γ(
gamma)?C呢? -
模型是ϵ-insensitive是什么意思?
-
使用核技巧的目的是什么?
-
在一个线性可分数据集上训练一个
LinearSVC。然后在相同数据集上训练一个SVC和一个SGDClassifier。看看是否可以让它们产生大致相同的模型。 -
在葡萄酒数据集上训练一个 SVM 分类器,您可以使用
sklearn.datasets.load_wine()加载该数据集。该数据集包含了由 3 个不同的种植者生产的 178 个葡萄酒样本的化学分析:目标是训练一个能够根据葡萄酒的化学分析预测种植者的分类模型。由于 SVM 分类器是二元分类器,您需要使用一对所有来对所有三个类进行分类。您能达到什么准确度? -
在加利福尼亚住房数据集上训练和微调一个 SVM 回归器。您可以使用原始数据集,而不是我们在第二章中使用的调整版本,您可以使用
sklearn.datasets.fetch_california_housing()加载该数据集。目标代表数十万美元。由于有超过 20,000 个实例,SVM 可能会很慢,因此在超参数调整中,您应该使用更少的实例(例如 2,000)来测试更多的超参数组合。您最佳模型的 RMSE 是多少?
这些练习的解决方案可以在本章笔记本的末尾找到,网址为https://homl.info/colab3。
¹ Chih-Jen Lin 等人,“用于大规模线性 SVM 的双坐标下降方法”,第 25 届国际机器学习会议论文集(2008 年):408–415。
² John Platt,“顺序最小优化:用于训练支持向量机的快速算法”(微软研究技术报告,1998 年 4 月 21 日)。
³ Zeta(ζ)是希腊字母表的第六个字母。
⁴ 要了解更多关于二次规划的知识,您可以开始阅读 Stephen Boyd 和 Lieven Vandenberghe 的书籍凸优化(剑桥大学出版社)或观看 Richard Brown 的系列视频讲座。
⁵ 目标函数是凸函数,不等式约束是连续可微的凸函数。
⁶ 如第四章中所解释的,两个向量a和b的点积通常表示为a·b。然而,在机器学习中,向量经常被表示为列向量(即单列矩阵),因此点积通过计算a^⊺b来实现。为了与本书的其余部分保持一致,我们将在这里使用这种表示法,忽略了这实际上导致了一个单元格矩阵而不是标量值的事实。
⁷ Gert Cauwenberghs 和 Tomaso Poggio,“增量和减量支持向量机学习”,《第 13 届国际神经信息处理系统会议论文集》(2000 年):388–394。
⁸ Antoine Bordes 等人,“具有在线和主动学习的快速核分类器”,《机器学习研究杂志》6(2005 年):1579–1619。
![[技术杂谈]如何下载vscode历史版本](https://img-blog.csdnimg.cn/direct/18e927e78e82496e80649940eb70a716.png)




![[嵌入式AI从0开始到入土]5_炼丹炉的搭建(基于wsl2_Ubuntu22.04)](https://img-blog.csdnimg.cn/direct/971108e55b2f48f0b2802e72653b00e5.png)