一、背景
支持向量机(Support Vector Machine,SVM)是一种用于分类、回归和离群点检测等领域的监督学习方法。它最初由Vapnik和Cortes在1995年提出,被认为是机器学习领域中最成功的算法之一。

二、原理
2.1 线性SVM
我们先从最简单的线性支持向量机(Linear SVM)开始。对于一个二分类问题,假设训练数据集为D={(x1,y1),(x2,y2),...,(xn,yn)},其中xi∈Rd表示第i个样本的d个特征值,yi∈{−1,1}表示第i个样本的类别标签。我们的目标是构建一个分类器f(x),将样本x划分为正类或负类。线性支持向量机的基本思想是在特征空间中找到一个超平面,将不同类别的样本分开,并且使得超平面与离其最近的样本点之间的距离最大。这个距离也称为“间隔”(Margin)。
其中,w是超平面的法向量,b是截距,x+和x−分别表示正类和负类样本离超平面最近的点。它们满足以下条件:
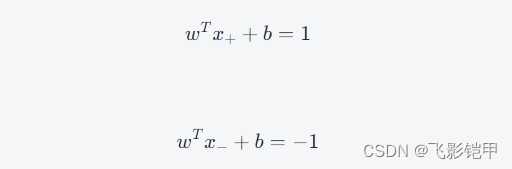
将两式相减可得:

因此,超平面到离其最近的两个点的距离为:

SVM的目标就是最大化这个距离。同时,我们希望超平面能够将不同类别的样本分开,即对于所有i∈[1,n],有:
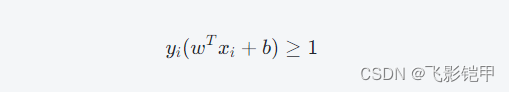
这个条件可以理解为对于任意一个样本,如果它被正确分类,则它在超平面两侧的距离之和必须大于等于22。这个条件也称为“硬间隔”(Hard Margin)。
但是,在实际问题中,有些样本可能无法被线性分开。
这种情况下,我们可以通过引入松弛变量(Slack Variable)ξi≥0来允许部分样本分类错误,同时惩罚这些错误分类的样本。具体地,对于样本i,我们希望:
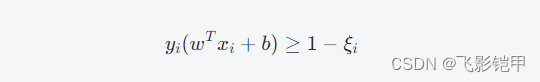
同时,我们最小化所有ξi的和,即∑i=1nξi。这个条件也称为“软间隔”(Soft Margin)。
综上所述,线性支持向量机的目标就是最小化以下函数:

其中,C是一个超参数,用于平衡较大的间隔和较小的误分类损失。
2.2 非线性SVM
上面介绍了如何使用线性超平面将不同类别的样本分开。但是,如果样本在特征空间中的分布非线性,则无法通过简单的线性超平面进行分割。
这个时候,我们可以使用核函数(Kernel Function)将样本从原始特征空间映射到高维特征空间,然后在高维特征空间中找到一个线性超平面,将不同类别的样本分开。常用的核函数包括线性核、多项式核、径向基函数(Radial Basis Function,RBF)核等。以RBF核为例,它的定义如下:
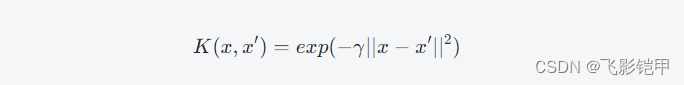
其中,γ是一个超参数,控制了映射到高维空间后的数据分布。使用核函数的非线性支持向量机的目标可以表示为:

其中,ϕ(x)表示将样本x映射到高维特征空间后的结果。
2.3 求解
上面介绍了支持向量机的基本原理,但是如何求解最优超平面呢?这个问题可以通过拉格朗日对偶性(Lagrange Duality)来解决。具体地,我们可以将优化问题转化为对偶问题,然后通过对偶问题的求解来得到最优超平面的参数。
以线性支持向量机为例,它的对偶问题可以表示为:

其中,α=[α1,α2,...,αn]是拉格朗日乘子向量。通过求解上述对偶问题,我们可以得到最优的α,然后利用以下公式计算权重向量w和截距b:
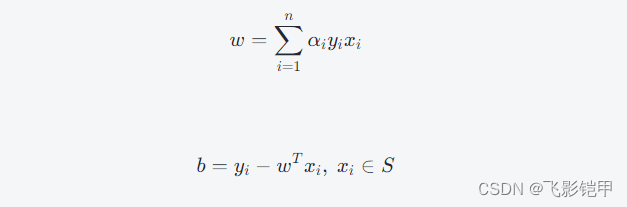
其中,S表示支持向量的集合。
2.4 核方法
当使用核函数进行非线性分类时,我们需要在高维空间中计算数据点之间的内积,这个计算量很大,不利于模型的实际应用。但是,由于核函数的形式比较简单,我们可以使用核技巧(Kernel Trick)来避免直接计算内积,而是通过计算核函数的值来间接计算内积。具体地,我们将样本集中的每个样本映射到高维特征空间中,并计算它们之间的内积,这样就可以得到核矩阵(Kernel Matrix),然后在求解对偶问题时使用核矩阵代替内积即可,从而避免了直接进行昂贵的高维计算。
三、应用
支持向量机在分类、回归和离群点检测等领域中有着广泛的应用。在分类问题中,SVM被广泛应用于图像分类、文本分类、生物信息学等领域。在回归问题中,SVM可以用于预测连续值的变量,例如房价预测、股票价格预测等。此外,由于支持向量机具有好的泛化性能和鲁棒性,在离群点检测等场景中也经常被使用。
四、总结
支持向量机是一种优秀的监督学习方法,其基本思想是在特征空间中找到一个超平面,将不同类别的样本分开,并且使得超平面与离其最近的样本点之间的距离最大。通过引入松弛变量和核函数等技巧,SVM可以处理线性和非线性分类问题。由于支持向量机具有好的泛化性能和鲁棒性,在实际应用中得到了广泛的应用。

![【蓝桥杯冲冲冲】动态规划学习 [NOIP2003 提高组] 加分二叉树](https://img-blog.csdnimg.cn/direct/b6b94f5a2cb6467983fe630443d31209.jpeg#pic_center)