原文:Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
译者:飞龙
协议:CC BY-NC-SA 4.0
第六章:决策树
决策树是多功能的机器学习算法,可以执行分类和回归任务,甚至多输出任务。它们是强大的算法,能够拟合复杂的数据集。例如,在第二章中,你在加利福尼亚住房数据集上训练了一个DecisionTreeRegressor模型,完美拟合了它(实际上,过度拟合了)。
决策树也是随机森林(参见第七章)的基本组件之一,随机森林是当今最强大的机器学习算法之一。
在本章中,我们将首先讨论如何训练、可视化和使用决策树进行预测。然后我们将介绍 Scikit-Learn 使用的 CART 训练算法,并探讨如何正则化树并将其用于回归任务。最后,我们将讨论决策树的一些局限性。
训练和可视化决策树
为了理解决策树,让我们构建一个并看看它如何进行预测。以下代码在鸢尾数据集上训练了一个DecisionTreeClassifier(参见第四章):
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris(as_frame=True)
X_iris = iris.data[["petal length (cm)", "petal width (cm)"]].values
y_iris = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2, random_state=42)
tree_clf.fit(X_iris, y_iris)
你可以通过首先使用export_graphviz()函数输出一个名为iris_tree.dot的图形定义文件来可视化训练好的决策树:
from sklearn.tree import export_graphviz
export_graphviz(
tree_clf,
out_file="iris_tree.dot",
feature_names=["petal length (cm)", "petal width (cm)"],
class_names=iris.target_names,
rounded=True,
filled=True
)
然后你可以使用graphviz.Source.from_file()来加载并在 Jupyter 笔记本中显示文件:
from graphviz import Source
Source.from_file("iris_tree.dot")
Graphviz是一个开源图形可视化软件包。它还包括一个dot命令行工具,可以将*.dot*文件转换为各种格式,如 PDF 或 PNG。
你的第一个决策树看起来像图 6-1。

图 6-1. 鸢尾决策树
进行预测
让我们看看图 6-1 中表示的树如何进行预测。假设你找到一朵鸢尾花,想根据其花瓣对其进行分类。你从根节点(深度 0,顶部)开始:这个节点询问花瓣长度是否小于 2.45 厘米。如果是,那么你向下移动到根节点的左子节点(深度 1,左侧)。在这种情况下,它是一个叶节点(即,它没有任何子节点),所以它不会提出任何问题:只需查看该节点的预测类别,决策树预测你的花是鸢尾山鸢尾(class=setosa)。
现在假设你找到另一朵花,这次花瓣长度大于 2.45 厘米。你再次从根节点开始,但现在向下移动到右侧子节点(深度 1,右侧)。这不是一个叶节点,它是一个分裂节点,所以它提出另一个问题:花瓣宽度是否小于 1.75 厘米?如果是,那么你的花很可能是鸢尾杂色(深度 2,左侧)。如果不是,它很可能是鸢尾维吉尼亚(深度 2,右侧)。就是这么简单。
注意
决策树的许多优点之一是它们几乎不需要数据准备。事实上,它们根本不需要特征缩放或居中。
节点的samples属性计算它适用于多少训练实例。例如,有 100 个训练实例的花瓣长度大于 2.45 厘米(深度 1,右侧),其中有 100 个训练实例的花瓣宽度小于 1.75 厘米(深度 2,左侧)。节点的value属性告诉您此节点适用于每个类别的训练实例数量:例如,右下节点适用于 0 个Iris setosa,1 个Iris versicolor和 45 个Iris virginica的训练实例。最后,节点的gini属性测量其基尼不纯度:如果所有适用于该节点的训练实例属于同一类,则节点是“纯净的”(gini=0)。例如,由于深度为 1 的左节点仅适用于Iris setosa训练实例,因此它是纯净的,其基尼不纯度为 0。方程 6-1 显示了训练算法如何计算第i个节点的基尼不纯度G[i]。深度为 2 的左节点的基尼不纯度等于 1 - (0/54)² - (49/54)² - (5/54)² ≈ 0.168。
方程 6-1. 基尼不纯度
G i = 1 - ∑ k=1 n p i,k 2
在这个方程中:
-
G[i]是第i个节点的基尼不纯度。
-
p[i,k]是第i个节点中训练实例中类k实例的比率。
注意
Scikit-Learn 使用 CART 算法,该算法仅生成二叉树,即分裂节点始终具有两个子节点(即问题只有是/否答案)。但是,其他算法(如 ID3)可以生成具有多于两个子节点的决策树。
图 6-2 显示了此决策树的决策边界。粗垂直线代表根节点(深度 0)的决策边界:花瓣长度=2.45 厘米。由于左侧区域是纯净的(仅Iris setosa),因此无法进一步分裂。但是,右侧区域是不纯的,因此深度为 1 的右节点在花瓣宽度=1.75 厘米处分裂(由虚线表示)。由于max_depth设置为 2,决策树在那里停止。如果将max_depth设置为 3,则两个深度为 2 的节点将分别添加另一个决策边界(由两个垂直虚线表示)。

图 6-2. 决策树决策边界
提示
决策树结构,包括图 6-1 中显示的所有信息,可以通过分类器的tree_属性获得。输入**help(tree_clf.tree_)**以获取详细信息,并查看本章笔记本中的示例。
估计类别概率
决策树还可以估计一个实例属于特定类k的概率。首先,它遍历树以找到此实例的叶节点,然后返回该节点中类k的训练实例的比率。例如,假设您找到了一朵花,其花瓣长 5 厘米,宽 1.5 厘米。相应的叶节点是深度为 2 的左节点,因此决策树输出以下概率:Iris setosa为 0%(0/54),Iris versicolor为 90.7%(49/54),Iris virginica为 9.3%(5/54)。如果要求它预测类别,则输出Iris versicolor(类别 1),因为它具有最高概率。让我们来检查一下:
>>> tree_clf.predict_proba([[5, 1.5]]).round(3)
array([[0\. , 0.907, 0.093]])
>>> tree_clf.predict([[5, 1.5]])
array([1])
完美!请注意,在图 6-2 的右下矩形中的任何其他位置,估计的概率将是相同的——例如,如果花瓣长 6 厘米,宽 1.5 厘米(即使在这种情况下,很明显它很可能是Iris virginica)。
CART 训练算法
Scikit-Learn 使用分类和回归树(CART)算法来训练决策树(也称为“生长”树)。该算法首先通过使用单个特征k和阈值t[k](例如,“花瓣长度≤2.45 厘米”)将训练集分成两个子集。它如何选择k和t[k]?它搜索产生最纯净子集的配对(k,t[k]),并根据它们的大小加权。方程 6-2 给出了算法试图最小化的成本函数。
方程 6-2. 用于分类的 CART 成本函数
J ( k , t k ) = m left m G left + m right m G right 其中 G left/right 衡量 左/右 子集的不纯度 m left/right 是 左/右 子集中实例的数量
一旦 CART 算法成功将训练集分成两部分,它会使用相同的逻辑分割子集,然后是子子集,依此类推,递归地进行。一旦达到最大深度(由max_depth超参数定义),或者无法找到能够减少不纯度的分割时,递归停止。另外几个超参数(稍后描述)控制额外的停止条件:min_samples_split,min_samples_leaf,min_weight_fraction_leaf和max_leaf_nodes。
警告
正如您所看到的,CART 算法是一种贪婪算法:它贪婪地在顶层搜索最佳分割,然后在每个后续级别重复该过程。它不检查分割是否会导致几个级别下可能的最低不纯度。贪婪算法通常会产生一个相当好但不能保证是最佳的解决方案。
不幸的是,找到最佳树被认为是一个NP 完全问题。¹ 它需要O(exp(m))的时间,使得即使对于小型训练集,问题也难以解决。这就是为什么在训练决策树时我们必须接受“相当好”的解决方案。
计算复杂度
进行预测需要从根节点到叶节点遍历决策树。决策树通常大致平衡,因此遍历决策树需要经过大约O(log2)个节点,其中 log2 是m的二进制对数,等于 log(m) / log(2)。由于每个节点只需要检查一个特征的值,因此整体预测复杂度为O(log2),与特征数量无关。因此,即使处理大型训练集,预测也非常快速。
训练算法在每个节点上比较所有特征(或少于max_features设置的特征)的所有样本。在每个节点上比较所有特征的所有样本会导致训练复杂度为O(n × m log2)。
基尼不纯度还是熵?
默认情况下,DecisionTreeClassifier类使用基尼不纯度度量,但您可以通过将criterion超参数设置为"entropy"来选择熵不纯度度量。熵的概念起源于热力学,作为分子无序性的度量:当分子静止且有序时,熵接近零。熵后来传播到各种领域,包括香农的信息论,在那里它衡量消息的平均信息内容,正如我们在第四章中看到的那样。当所有消息相同时,熵为零。在机器学习中,熵经常用作不纯度度量:当集合中只包含一个类的实例时,其熵为零。方程 6-3 显示了i^(th)节点熵的定义。例如,图 6-1 中深度为 2 的左节点的熵等于-(49/54) log[2] (49/54) - (5/54) log[2] (5/54) ≈ 0.445。
方程 6-3. 熵
H i = - ∑ k=1 p i,k ≠0 n p i,k log 2 ( p i,k )
那么,您应该使用基尼不纯度还是熵?事实是,大多数情况下并没有太大的区别:它们导致类似的树。基尼不纯度计算速度稍快,因此是一个很好的默认选择。然而,当它们不同时,基尼不纯度倾向于将最频繁的类隔离在树的自己分支中,而熵倾向于产生稍微更平衡的树。
正则化超参数
决策树对训练数据做出很少的假设(与线性模型相反,线性模型假设数据是线性的,例如)。如果不加约束,树结构将自适应于训练数据,非常紧密地拟合它——事实上,很可能过度拟合。这样的模型通常被称为非参数模型,不是因为它没有任何参数(通常有很多),而是因为参数的数量在训练之前不确定,因此模型结构可以自由地紧密地贴近数据。相比之下,参数模型,如线性模型,具有预先确定的参数数量,因此其自由度受限,减少了过度拟合的风险(但增加了欠拟合的风险)。
为了避免过度拟合训练数据,您需要在训练期间限制决策树的自由度。正如您现在所知,这被称为正则化。正则化超参数取决于所使用的算法,但通常您至少可以限制决策树的最大深度。在 Scikit-Learn 中,这由max_depth超参数控制。默认值为None,表示无限制。减少max_depth将使模型正则化,从而减少过度拟合的风险。
DecisionTreeClassifier类还有一些其他参数,类似地限制了决策树的形状:
max_features
在每个节点评估用于分裂的最大特征数
max_leaf_nodes
叶节点的最大数量
min_samples_split
节点在可以分裂之前必须具有的最小样本数
min_samples_leaf
叶节点必须具有的最小样本数
min_weight_fraction_leaf
与min_samples_leaf相同,但表示为加权实例总数的分数
增加min_*超参数或减少max_*超参数将使模型正则化。
注意
其他算法首先训练没有限制的决策树,然后修剪(删除)不必要的节点。如果一个节点的子节点都是叶节点,并且它提供的纯度改进不具有统计显著性,则认为该节点是不必要的。标准统计检验,如χ²检验(卡方检验),用于估计改进纯粹是由于偶然性导致的概率(称为零假设)。如果这个概率,称为p 值,高于给定阈值(通常为 5%,由超参数控制),则认为该节点是不必要的,其子节点将被删除。修剪将继续进行,直到所有不必要的节点都被修剪。
让我们在 moons 数据集上测试正则化,该数据集在第五章中介绍。我们将训练一个没有正则化的决策树,另一个使用min_samples_leaf=5。以下是代码;图 6-3 显示了每棵树的决策边界:
from sklearn.datasets import make_moons
X_moons, y_moons = make_moons(n_samples=150, noise=0.2, random_state=42)
tree_clf1 = DecisionTreeClassifier(random_state=42)
tree_clf2 = DecisionTreeClassifier(min_samples_leaf=5, random_state=42)
tree_clf1.fit(X_moons, y_moons)
tree_clf2.fit(X_moons, y_moons)
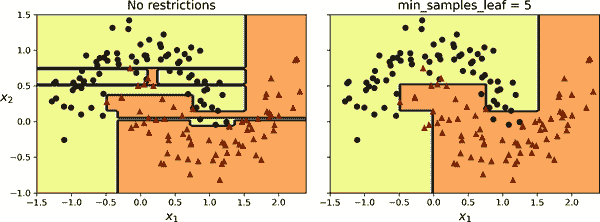
图 6-3. 未正则化树的决策边界(左)和正则化树(右)
左边的未正则化模型明显过拟合,右边的正则化模型可能会更好地泛化。我们可以通过在使用不同随机种子生成的测试集上评估这两棵树来验证这一点:
>>> X_moons_test, y_moons_test = make_moons(n_samples=1000, noise=0.2,
... random_state=43)
...
>>> tree_clf1.score(X_moons_test, y_moons_test)
0.898
>>> tree_clf2.score(X_moons_test, y_moons_test)
0.92
事实上,第二棵树在测试集上有更好的准确性。
回归
决策树也能够执行回归任务。让我们使用 Scikit-Learn 的DecisionTreeRegressor类构建一个回归树,对一个带有max_depth=2的嘈杂二次数据集进行训练:
import numpy as np
from sklearn.tree import DecisionTreeRegressor
np.random.seed(42)
X_quad = np.random.rand(200, 1) - 0.5 # a single random input feature
y_quad = X_quad ** 2 + 0.025 * np.random.randn(200, 1)
tree_reg = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg.fit(X_quad, y_quad)
生成的树在图 6-4 中表示。

图 6-4. 用于回归的决策树
这棵树看起来与您之前构建的分类树非常相似。主要区别在于,每个节点不是预测一个类别,而是预测一个值。例如,假设您想对一个新实例进行预测,其中x[1] = 0.2。根节点询问x[1] ≤ 0.197。由于不是,算法转到右子节点,询问x[1] ≤ 0.772。由于是,算法转到左子节点。这是一个叶节点,它预测value=0.111。这个预测是与该叶节点关联的 110 个训练实例的目标值的平均值,导致这 110 个实例的均方误差等于 0.015。
这个模型的预测在左边的图 6-5 中表示。如果设置max_depth=3,则得到右边的预测。请注意,每个区域的预测值始终是该区域实例的目标值的平均值。该算法分割每个区域的方式是使大多数训练实例尽可能接近该预测值。

图 6-5. 两个决策树回归模型的预测
CART 算法的工作方式与之前描述的相同,只是现在它试图以最小化 MSE 的方式分割训练集,而不是试图最小化不纯度。方程 6-4 显示了算法试图最小化的成本函数。
方程 6-4. CART 回归的成本函数
J(k,tk)=mleftmMSEleft+mrightmMSErightwhereMSEnode=∑i∈node(y</mo></mover><mtext>node</mtext></msub><mo>-</mo><msup><mi>y</mi><mrow><mo>(</mo><mi>i</mi><mo>)</mo></mrow></msup><mo>)</mo></mrow><mn>2</mn></msup></mrow><msub><mi>m</mi><mi>node</mi></msub></mfrac></mtd></mtr><mtr><mtd><msub><mover><mi>y</mi><mo>node=∑i∈nodey(i)mnode
就像分类任务一样,决策树在处理回归任务时容易过拟合。没有任何正则化(即使用默认超参数),您会得到图 6-6 左侧的预测结果。这些预测显然严重过拟合了训练集。只需设置min_samples_leaf=10就会得到一个更合理的模型,如图 6-6 右侧所示。

图 6-6。未正则化回归树的预测(左)和正则化树(右)
对轴方向的敏感性
希望到目前为止您已经相信决策树有很多优点:它们相对容易理解和解释,简单易用,多功能且强大。然而,它们也有一些局限性。首先,正如您可能已经注意到的,决策树喜欢正交的决策边界(所有分割都垂直于一个轴),这使它们对数据的方向敏感。例如,图 6-7 显示了一个简单的线性可分数据集:在左侧,决策树可以轻松分割它,而在右侧,数据集旋转了 45°后,决策边界看起来过于复杂。尽管两个决策树都完美拟合了训练集,但右侧的模型很可能泛化效果不佳。

图 6-7。对训练集旋转的敏感性
限制这个问题的一种方法是对数据进行缩放,然后应用主成分分析转换。我们将在第八章中详细讨论 PCA,但现在您只需要知道它以一种减少特征之间相关性的方式旋转数据,这通常(不总是)使决策树更容易处理。
让我们创建一个小型流水线,对数据进行缩放并使用 PCA 进行旋转,然后在该数据上训练DecisionTreeClassifier。图 6-8 显示了该树的决策边界:正如您所看到的,旋转使得只使用一个特征z[1]就可以很好地拟合数据集,该特征是原始花瓣长度和宽度的线性函数。以下是代码:
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
pca_pipeline = make_pipeline(StandardScaler(), PCA())
X_iris_rotated = pca_pipeline.fit_transform(X_iris)
tree_clf_pca = DecisionTreeClassifier(max_depth=2, random_state=42)
tree_clf_pca.fit(X_iris_rotated, y_iris)
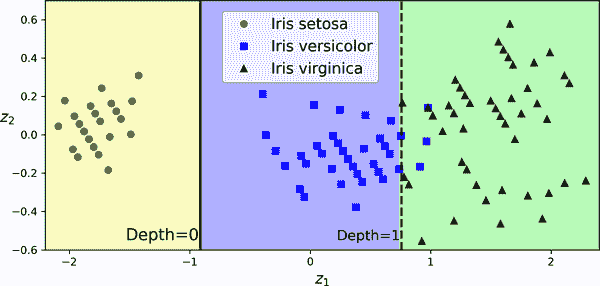
图 6-8。树在经过缩放和 PCA 旋转的鸢尾花数据集上的决策边界
决策树具有高方差
更一般地,决策树的主要问题是它们具有相当高的方差:对超参数或数据进行微小更改可能会产生非常不同的模型。实际上,由于 Scikit-Learn 使用的训练算法是随机的——它在每个节点随机选择要评估的特征集,即使在完全相同的数据上重新训练相同的决策树也可能产生非常不同的模型,例如图 6-9 中所示的模型(除非您设置random_state超参数)。如您所见,它看起来与先前的决策树非常不同(图 6-2)。

图 6-9. 在相同数据上重新训练相同模型可能会产生非常不同的模型
幸运的是,通过对许多树的预测进行平均,可以显著减少方差。这样的树集成称为随机森林,它是当今最强大的模型之一,您将在下一章中看到。
练习
-
在一个包含一百万实例的训练集上训练(无限制)的决策树的大致深度是多少?
-
节点的基尼不纯度通常低于还是高于其父节点的?它通常低于/高于,还是总是低于/高于?
-
如果一个决策树对训练集过拟合,尝试减小
max_depth是一个好主意吗? -
如果一个决策树对训练集欠拟合,尝试对输入特征进行缩放是一个好主意吗?
-
在包含一百万实例的训练集上训练一个决策树需要一个小时,那么在包含一千万实例的训练集上训练另一个决策树大约需要多长时间?提示:考虑 CART 算法的计算复杂度。
-
在给定训练集上训练一个决策树需要一个小时,如果您增加特征数量会需要多长时间?
-
按照以下步骤为 moons 数据集训练和微调决策树:
-
使用
make_moons(n_samples=10000, noise=0.4)生成一个 moons 数据集。 -
使用
train_test_split()将数据集分割为训练集和测试集。 -
使用网格搜索结合交叉验证(借助
GridSearchCV类)来找到DecisionTreeClassifier的良好超参数值。提示:尝试不同的max_leaf_nodes值。 -
使用这些超参数在完整的训练集上训练模型,并在测试集上评估模型的性能。您应该获得大约 85%到 87%的准确率。
-
-
按照以下步骤生成一个森林:
-
继续上一个练习,生成 1,000 个训练集的子集,每个子集包含随机选择的 100 个实例。提示:您可以使用 Scikit-Learn 的
ShuffleSplit类来实现。 -
在每个子集上训练一个决策树,使用在前一个练习中找到的最佳超参数值。在测试集上评估这 1,000 个决策树。由于它们是在较小的数据集上训练的,这些决策树可能表现得比第一个决策树更差,仅获得大约 80%的准确率。
-
现在是魔法时刻。对于每个测试集实例,生成 1,000 个决策树的预测,并仅保留最频繁的预测(您可以使用 SciPy 的
mode()函数)。这种方法为您提供了测试集上的多数投票预测。 -
在测试集上评估这些预测:您应该获得比第一个模型稍高的准确率(大约高 0.5%到 1.5%)。恭喜,您已经训练了一个随机森林分类器!
-
这些练习的解决方案可在本章笔记本的末尾找到,网址为https://homl.info/colab3。
¹ P 是可以在多项式时间内解决的问题集(即数据集大小的多项式)。NP 是可以在多项式时间内验证解决方案的问题集。NP-hard 问题是可以在多项式时间内减少到已知 NP-hard 问题的问题。NP-complete 问题既是 NP 又是 NP-hard。一个重要的数学问题是 P 是否等于 NP。如果 P ≠ NP(这似乎是可能的),那么任何 NP-complete 问题都不会找到多项式算法(除非有一天在量子计算机上)。
² 有关更多细节,请参阅 Sebastian Raschka 的有趣分析。
第七章:集成学习和随机森林
假设您向成千上万的随机人提出一个复杂的问题,然后汇总他们的答案。在许多情况下,您会发现这种汇总的答案比专家的答案更好。这被称为群体的智慧。类似地,如果您汇总一组预测器(如分类器或回归器)的预测,通常会比最佳个体预测器的预测更好。一组预测器称为集成;因此,这种技术称为集成学习,集成学习算法称为集成方法。
作为集成方法的一个示例,您可以训练一组决策树分类器,每个分类器在训练集的不同随机子集上训练。然后,您可以获得所有单独树的预测,得到得票最多的类别就是集成的预测(请参见第六章中的最后一个练习)。这样的决策树集成称为随机森林,尽管它很简单,但这是当今最强大的机器学习算法之一。
正如在第二章中讨论的那样,您通常会在项目结束时使用集成方法,一旦您已经构建了几个良好的预测器,将它们组合成一个更好的预测器。事实上,在机器学习竞赛中获胜的解决方案通常涉及几种集成方法,最著名的是Netflix Prize 竞赛。
在本章中,我们将研究最流行的集成方法,包括投票分类器、装袋和粘贴集成、随机森林和提升,以及堆叠集成。
投票分类器
假设您已经训练了几个分类器,每个分类器的准确率约为 80%。您可能有一个逻辑回归分类器,一个 SVM 分类器,一个随机森林分类器,一个k最近邻分类器,也许还有几个(请参见图 7-1)。
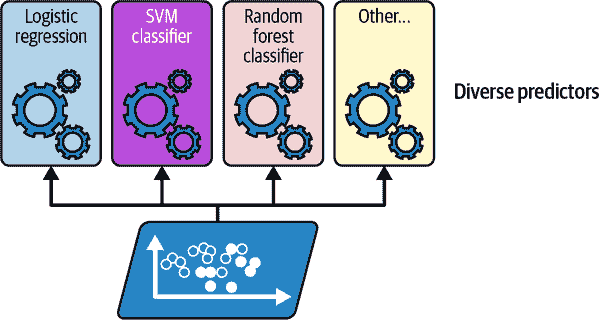
图 7-1. 训练多样化的分类器
创建一个更好的分类器的一个非常简单的方法是汇总每个分类器的预测:得票最多的类别是集成的预测。这种多数投票分类器称为硬投票分类器(请参见图 7-2)。
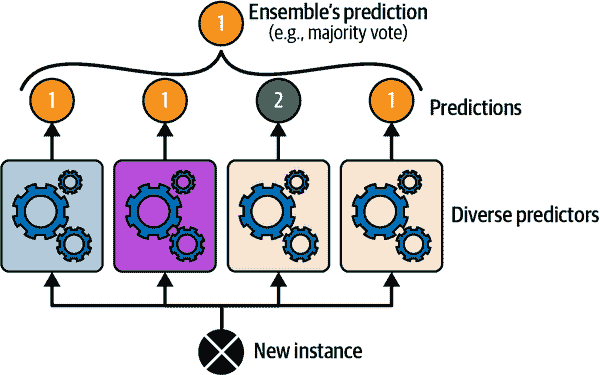
图 7-2. 硬投票分类器预测
令人惊讶的是,这种投票分类器通常比集成中最好的分类器的准确率更高。事实上,即使每个分类器都是弱学习器(意味着它的表现仅略好于随机猜测),只要集成中有足够数量的弱学习器并且它们足够多样化,集成仍然可以是一个强学习器(实现高准确率)。
这是如何可能的?以下类比可以帮助解开这个谜团。假设您有一个略带偏见的硬币,正面朝上的概率为 51%,反面朝上的概率为 49%。如果您抛掷它 1,000 次,通常会得到大约 510 次正面和 490 次反面,因此大多数是正面。如果您进行计算,您会发现在 1,000 次抛掷后获得大多数正面的概率接近 75%。您抛掷硬币的次数越多,概率就越高(例如,进行 10,000 次抛掷后,概率超过 97%)。这是由于大数定律:随着您不断抛掷硬币,正面的比例越来越接近正面的概率(51%)。图 7-3 显示了 10 组有偏硬币抛掷。您可以看到随着抛掷次数的增加,正面的比例接近 51%。最终,所有 10 组数据最终都接近 51%,它们始终保持在 50%以上。

图 7-3. 大数定律
类似地,假设你构建一个包含 1,000 个分类器的集成,这些分类器单独的正确率仅为 51%(略高于随机猜测)。如果你预测多数投票的类别,你可以期望达到高达 75%的准确性!然而,这仅在所有分类器完全独立,产生不相关错误时才成立,而这显然不是事实,因为它们是在相同数据上训练的。它们很可能会产生相同类型的错误,因此会有很多错误类别的多数投票,降低了集成的准确性。
提示
集成方法在预测器尽可能独立时效果最好。获得多样化分类器的一种方法是使用非常不同的算法对它们进行训练。这增加了它们会产生非常不同类型错误的机会,提高了集成的准确性。
Scikit-Learn 提供了一个非常容易使用的VotingClassifier类:只需给它一个名称/预测器对的列表,然后像普通分类器一样使用它。让我们在 moons 数据集上尝试一下(在第五章介绍)。我们将加载并拆分 moons 数据集为训练集和测试集,然后创建和训练一个由三个不同分类器组成的投票分类器:
from sklearn.datasets import make_moons
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
voting_clf = VotingClassifier(
estimators=[
('lr', LogisticRegression(random_state=42)),
('rf', RandomForestClassifier(random_state=42)),
('svc', SVC(random_state=42))
]
)
voting_clf.fit(X_train, y_train)
当你拟合VotingClassifier时,它会克隆每个估计器并拟合这些克隆。原始估计器可以通过estimators属性获得,而拟合的克隆可以通过estimators_属性获得。如果你更喜欢字典而不是列表,可以使用named_estimators或named_estimators_。首先,让我们看看每个拟合分类器在测试集上的准确性:
>>> for name, clf in voting_clf.named_estimators_.items():
... print(name, "=", clf.score(X_test, y_test))
...
lr = 0.864
rf = 0.896
svc = 0.896
当你调用投票分类器的predict()方法时,它执行硬投票。例如,投票分类器为测试集的第一个实例预测类别 1,因为三个分类器中有两个预测该类别:
>>> voting_clf.predict(X_test[:1])
array([1])
>>> [clf.predict(X_test[:1]) for clf in voting_clf.estimators_]
[array([1]), array([1]), array([0])]
现在让我们看看投票分类器在测试集上的表现:
>>> voting_clf.score(X_test, y_test)
0.912
就是这样!投票分类器的表现优于所有个体分类器。
如果所有分类器都能估计类别概率(即它们都有predict_proba()方法),那么你可以告诉 Scikit-Learn 预测具有最高类别概率的类别,这是所有个体分类器的平均值。这被称为软投票。它通常比硬投票表现更好,因为它更加重视高置信度的投票。你只需要将投票分类器的voting超参数设置为"soft",并确保所有分类器都能估计类别概率。这在SVC类中默认情况下不适用,因此你需要将其probability超参数设置为True(这将使SVC类使用交叉验证来估计类别概率,从而减慢训练速度,并添加一个predict_proba()方法)。让我们试一试:
>>> voting_clf.voting = "soft"
>>> voting_clf.named_estimators["svc"].probability = True
>>> voting_clf.fit(X_train, y_train)
>>> voting_clf.score(X_test, y_test)
0.92
仅通过使用软投票,我们达到了 92%的准确性,不错!
Bagging 和 Pasting
获得多样化分类器的一种方法是使用非常不同的训练算法,正如刚才讨论的。另一种方法是对每个预测器使用相同的训练算法,但在训练集的不同随机子集上训练它们。当采样有替换时,这种方法称为bagging(bootstrap 聚合的缩写)。当采样无替换时,它被称为pasting。
换句话说,bagging 和 pasting 都允许训练实例在多个预测器之间多次采样,但只有 bagging 允许训练实例在同一个预测器中多次采样。这种采样和训练过程在图 7-4 中表示。

图 7-4。Bagging 和 Pasting 涉及在训练集的不同随机样本上训练多个预测器
一旦所有预测器都训练完毕,集成可以通过简单地聚合所有预测器的预测来对新实例进行预测。聚合函数通常是分类的统计模式(即最频繁的预测,就像硬投票分类器一样),或者是回归的平均值。每个单独的预测器的偏差比在原始训练集上训练时更高,但聚合减少了偏差和方差。通常,集成的结果是,与在原始训练集上训练的单个预测器相比,集成具有类似的偏差但更低的方差。
正如你在图 7-4 中看到的,预测器可以通过不同的 CPU 核心甚至不同的服务器并行训练。同样,预测也可以并行进行。这是 Bagging 和 Pasting 如此受欢迎的原因之一:它们的扩展性非常好。
Scikit-Learn 中的 Bagging 和 Pasting
Scikit-Learn 为 Bagging 和 Pasting 提供了一个简单的 API:BaggingClassifier类(或用于回归的BaggingRegressor)。以下代码训练了一个由 500 个决策树分类器组成的集成:每个分类器都是在从训练集中随机抽取的 100 个训练实例上进行训练的(这是 Bagging 的一个示例,但如果你想使用 Pasting,只需设置bootstrap=False)。n_jobs参数告诉 Scikit-Learn 要使用多少 CPU 核心进行训练和预测,-1告诉 Scikit-Learn 使用所有可用的核心:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500,
max_samples=100, n_jobs=-1, random_state=42)
bag_clf.fit(X_train, y_train)
注意
如果基本分类器可以估计类概率(即具有predict_proba()方法),BaggingClassifier会自动执行软投票而不是硬投票,决策树分类器就是这种情况。
图 7-5 比较了单个决策树的决策边界和一个由 500 棵树组成的 Bagging 集成的决策边界(来自前面的代码),它们都是在 moons 数据集上训练的。正如你所看到的,集成的预测很可能比单个决策树的预测更好地泛化:集成具有可比较的偏差,但方差更小(在训练集上大致产生相同数量的错误,但决策边界不那么不规则)。
Bagging 在每个预测器训练的子集中引入了更多的多样性,因此 Bagging 的偏差比 Pasting 略高;但额外的多样性也意味着预测器之间的相关性更低,因此集成的方差降低。总的来说,Bagging 通常会产生更好的模型,这解释了为什么通常会优先选择它。但是如果你有多余的时间和 CPU 计算能力,你可以使用交叉验证来评估 Bagging 和 Pasting,并选择最好的方法。

图 7-5。单个决策树(左)与由 500 棵树组成的 Bagging 集成(右)
袋外评估
在 Bagging 中,某些训练实例可能会被任何给定的预测器多次抽样,而其他实例可能根本不被抽样。默认情况下,BaggingClassifier使用替换抽样(bootstrap=True)对m个训练实例进行抽样,其中m是训练集的大小。通过这个过程,可以在数学上证明,每个预测器平均只有约 63%的训练实例被抽样。剩下的 37%未被抽样的训练实例被称为袋外(OOB)实例。请注意,它们对于所有预测器来说并不是相同的 37%。
可以使用 OOB 实例评估装袋集成,无需单独的验证集:实际上,如果有足够的估计器,那么训练集中的每个实例很可能是几个估计器的 OOB 实例,因此这些估计器可以用于为该实例进行公平的集成预测。一旦您对每个实例进行了预测,就可以计算集成的预测准确性(或任何其他度量)。
在 Scikit-Learn 中,您可以在创建BaggingClassifier时设置oob_score=True来请求训练后自动进行 OOB 评估。以下代码演示了这一点。生成的评估分数可在oob_score_属性中获得:
>>> bag_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500,
... oob_score=True, n_jobs=-1, random_state=42)
...
>>> bag_clf.fit(X_train, y_train)
>>> bag_clf.oob_score_
0.896
根据这个 OOB 评估,这个BaggingClassifier在测试集上可能会达到约 89.6%的准确率。让我们验证一下:
>>> from sklearn.metrics import accuracy_score
>>> y_pred = bag_clf.predict(X_test)
>>> accuracy_score(y_test, y_pred)
0.92
我们在测试中获得了 92%的准确率。OOB 评估有点太悲观了,低了 2%多一点。
每个训练实例的 OOB 决策函数也可以通过oob_decision_function_属性获得。由于基本估计器具有predict_proba()方法,决策函数返回每个训练实例的类概率。例如,OOB 评估估计第一个训练实例属于正类的概率为 67.6%,属于负类的概率为 32.4%:
>>> bag_clf.oob_decision_function_[:3] # probas for the first 3 instances
array([[0.32352941, 0.67647059],
[0.3375 , 0.6625 ],
[1\. , 0\. ]])
随机补丁和随机子空间
BaggingClassifier类还支持对特征进行抽样。抽样由两个超参数控制:max_features和bootstrap_features。它们的工作方式与max_samples和bootstrap相同,但用于特征抽样而不是实例抽样。因此,每个预测器将在输入特征的随机子集上进行训练。
当处理高维输入(例如图像)时,这种技术特别有用,因为它可以显着加快训练速度。对训练实例和特征进行抽样被称为随机补丁方法。保留所有训练实例(通过设置bootstrap=False和max_samples=1.0)但对特征进行抽样(通过将bootstrap_features设置为True和/或将max_features设置为小于1.0的值)被称为随机子空间方法。
对特征进行抽样会导致更多的预测器多样性,以换取更低的方差稍微增加一点偏差。
随机森林
正如我们所讨论的,随机森林是一组决策树的集成,通常通过装袋方法(有时是粘贴)进行训练,通常将max_samples设置为训练集的大小。您可以使用RandomForestClassifier类来训练随机森林分类器,该类更方便且针对决策树进行了优化(类似地,还有一个用于回归任务的RandomForestRegressor类)。以下代码使用 500 棵树训练了一个随机森林分类器,每棵树最多限制为 16 个叶节点,使用所有可用的 CPU 核心:
from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16,
n_jobs=-1, random_state=42)
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)
除了一些例外,RandomForestClassifier具有DecisionTreeClassifier的所有超参数(用于控制树的生长方式),以及BaggingClassifier的所有超参数来控制集成本身。
随机森林算法在生长树时引入了额外的随机性;在分裂节点时不是搜索最佳特征(参见第六章),而是在一组随机特征中搜索最佳特征。默认情况下,它对特征进行采样n(其中n是特征的总数)。该算法导致更大的树多样性,这(再次)以更低的方差换取更高的偏差,通常产生更好的模型。因此,以下BaggingClassifier等同于之前的RandomForestClassifier:
bag_clf = BaggingClassifier(
DecisionTreeClassifier(max_features="sqrt", max_leaf_nodes=16),
n_estimators=500, n_jobs=-1, random_state=42)
额外树
在随机森林中生长树时,在每个节点只考虑一组随机特征进行分裂(如前所述)。还可以通过为每个特征使用随机阈值而不是搜索最佳阈值(正如常规决策树所做)来使树更加随机。为此,只需在创建DecisionTreeClassifier时设置splitter="random"。
这样极端随机树的森林被称为极端随机树(或简称为额外树)集成。再次,这种技术以更低的方差换取更高的偏差。相比于常规随机森林,额外树分类器的训练速度也更快,因为在每个节点为每个特征找到最佳阈值是生长树中最耗时的任务之一。
您可以使用 Scikit-Learn 的ExtraTreesClassifier类创建一个额外树分类器。其 API 与RandomForestClassifier类相同,只是bootstrap默认为False。同样,ExtraTreesRegressor类与RandomForestRegressor类具有相同的 API,只是bootstrap默认为False。
提示
很难事先确定RandomForestClassifier的表现是好还是坏于ExtraTreesClassifier。通常,唯一的方法是尝试两者并使用交叉验证进行比较。
特征重要性
随机森林的另一个很好的特性是它可以轻松测量每个特征的相对重要性。Scikit-Learn 通过查看使用该特征的树节点平均减少不纯度的程度来衡量特征的重要性,跨森林中的所有树。更准确地说,这是一个加权平均值,其中每个节点的权重等于与其相关联的训练样本数(参见第六章)。
Scikit-Learn 在训练后自动计算每个特征的重要性得分,然后将结果进行缩放,使所有重要性的总和等于 1。您可以使用feature_importances_变量访问结果。例如,以下代码在鸢尾花数据集上训练一个RandomForestClassifier(在第四章介绍),并输出每个特征的重要性。看起来最重要的特征是花瓣长度(44%)和宽度(42%),而花萼长度和宽度相比之下不太重要(分别为 11%和 2%):
>>> from sklearn.datasets import load_iris
>>> iris = load_iris(as_frame=True)
>>> rnd_clf = RandomForestClassifier(n_estimators=500, random_state=42)
>>> rnd_clf.fit(iris.data, iris.target)
>>> for score, name in zip(rnd_clf.feature_importances_, iris.data.columns):
... print(round(score, 2), name)
...
0.11 sepal length (cm)
0.02 sepal width (cm)
0.44 petal length (cm)
0.42 petal width (cm)
同样,如果您在 MNIST 数据集上训练随机森林分类器(在第三章介绍),并绘制每个像素的重要性,则会得到图 7-6 中所代表的图像。
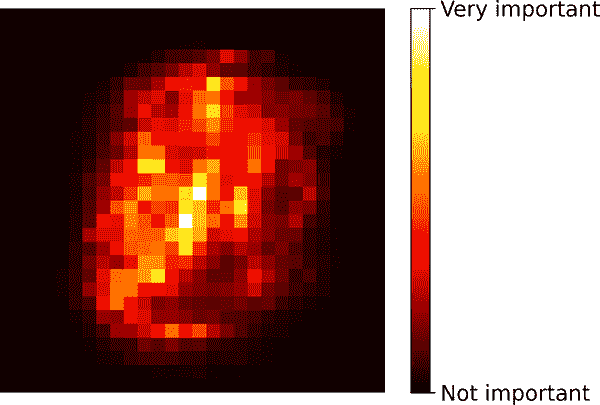
图 7-6. MNIST 像素重要性(根据随机森林分类器)
随机森林非常方便,可以快速了解哪些特征实际上很重要,特别是如果您需要执行特征选择时。
提升
Boosting(最初称为hypothesis boosting)指的是任何可以将几个弱学习器组合成一个强学习器的集成方法。大多数提升方法的一般思想是顺序训练预测器,每个预测器都试图纠正其前身。有许多提升方法可用,但目前最流行的是AdaBoost(缩写为adaptive boosting)和gradient boosting。让我们从 AdaBoost 开始。
AdaBoost
新预测器纠正其前身的一种方法是更多地关注前身欠拟合的训练实例。这导致新的预测器越来越关注困难的情况。这是 AdaBoost 使用的技术。
例如,在训练 AdaBoost 分类器时,算法首先训练一个基本分类器(如决策树),并使用它对训练集进行预测。然后增加被错误分类的训练实例的相对权重。然后训练第二个分类器,使用更新后的权重,再次对训练集进行预测,更新实例权重,依此类推(参见图 7-7)。
图 7-8 显示了在 moons 数据集上的五个连续预测器的决策边界(在这个例子中,每个预测器都是一个具有 RBF 核的高度正则化的 SVM 分类器)。第一个分类器错误地预测了许多实例,因此它们的权重被提升。因此,第二个分类器在这些实例上做得更好,依此类推。右侧的图表示相同序列的预测器,只是学习率减半(即,在每次迭代中,错误分类的实例权重提升要少得多)。正如您所看到的,这种顺序学习技术与梯度下降有一些相似之处,只是 AdaBoost 不是调整单个预测器的参数以最小化成本函数,而是逐渐将预测器添加到集成中,使其变得更好。

图 7-7。AdaBoost 顺序训练与实例权重更新
一旦所有预测器都训练完毕,集成就会像装袋或粘贴一样进行预测,只是预测器根据它们在加权训练集上的整体准确性具有不同的权重。

图 7-8。连续预测器的决策边界
警告
这种顺序学习技术有一个重要的缺点:训练不能并行化,因为每个预测器只能在前一个预测器训练和评估之后进行训练。因此,它的扩展性不如装袋或粘贴。
让我们更仔细地看看 AdaBoost 算法。每个实例权重w^((i))最初设置为 1/m。首先训练一个预测器,并在训练集上计算其加权错误率r[1];参见方程 7-1。
方程 7-1。第 j 个预测器的加权错误率
rj = ∑ i=1 y^ j (i) ≠ y (i) m w(i) 其中 y^ j(i) 是 第 jth 预测器的 预测对于 第 i th 实例
然后使用方程 7-2 计算预测器的权重α[j],其中η是学习率超参数(默认为 1)。¹⁵ 预测器越准确,其权重就越高。如果它只是随机猜测,那么它的权重将接近于零。然而,如果它经常错误(即比随机猜测更不准确),那么它的权重将是负数。
方程 7-2. 预测器权重
α j = η log 1-r j r j
接下来,AdaBoost 算法使用方程 7-3 更新实例权重,提升错误分类实例的权重。
方程 7-3. 权重更新规则
对于 i = 1 , 2 , ⋯ , m w (i) ← w (i) 如果 y j ^ (i) = y (i) w (i) exp ( α j ) 如果 y j ^ (i) ≠ y (i)
然后对所有实例权重进行归一化(即除以∑i=1mw(i))。
最后,使用更新后的权重训练一个新的预测器,并重复整个过程:计算新预测器的权重,更新实例权重,然后训练另一个预测器,依此类推。当达到所需数量的预测器或找到一个完美的预测器时,算法停止。
为了进行预测,AdaBoost 简单地计算所有预测器的预测值,并使用预测器权重α[j]对它们进行加权。预测的类别是获得加权投票多数的类别(参见方程 7-4)。
方程 7-4. AdaBoost 预测
y ^ ( x ) = argmax k ∑ j=1 y ^ j (x)=k N α j where N is the number of predictors
Scikit-Learn 使用了 AdaBoost 的多类版本称为SAMME¹⁶(代表使用多类指数损失函数的逐步增加建模)。当只有两个类别时,SAMME 等同于 AdaBoost。如果预测器可以估计类别概率(即,如果它们有一个predict_proba()方法),Scikit-Learn 可以使用 SAMME 的变体称为SAMME.R(R代表“真实”),它依赖于类别概率而不是预测,并通常表现更好。
以下代码基于 Scikit-Learn 的AdaBoostClassifier类训练了一个基于 30 个决策树桩的 AdaBoost 分类器(正如您所期望的那样,还有一个AdaBoostRegressor类)。决策树桩是一个max_depth=1的决策树——换句话说,由一个决策节点和两个叶节点组成的树。这是AdaBoostClassifier类的默认基础估计器:
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=30,
learning_rate=0.5, random_state=42)
ada_clf.fit(X_train, y_train)
提示
如果您的 AdaBoost 集成对训练集过拟合,可以尝试减少估计器的数量或更强烈地正则化基础估计器。
梯度提升
另一个非常流行的提升算法是梯度提升。¹⁷ 就像 AdaBoost 一样,梯度提升通过顺序添加预测器到集成中,每个预测器都纠正其前任。然而,与 AdaBoost 在每次迭代中调整实例权重不同,这种方法试图将新的预测器拟合到前一个预测器产生的残差错误上。
让我们通过一个简单的回归示例,使用决策树作为基础预测器;这被称为梯度树提升,或梯度提升回归树(GBRT)。首先,让我们生成一个带有噪声的二次数据集,并将DecisionTreeRegressor拟合到它:
import numpy as np
from sklearn.tree import DecisionTreeRegressor
np.random.seed(42)
X = np.random.rand(100, 1) - 0.5
y = 3 * X[:, 0] ** 2 + 0.05 * np.random.randn(100) # y = 3x² + Gaussian noise
tree_reg1 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg1.fit(X, y)
接下来,我们将在第一个预测器产生的残差错误上训练第二个DecisionTreeRegressor:
y2 = y - tree_reg1.predict(X)
tree_reg2 = DecisionTreeRegressor(max_depth=2, random_state=43)
tree_reg2.fit(X, y2)
然后我们将在第二个预测器产生的残差错误上训练第三个回归器:
y3 = y2 - tree_reg2.predict(X)
tree_reg3 = DecisionTreeRegressor(max_depth=2, random_state=44)
tree_reg3.fit(X, y3)
现在我们有一个包含三棵树的集成。它可以通过简单地将所有树的预测相加来对新实例进行预测:
>>> X_new = np.array([[-0.4], [0.], [0.5]])
>>> sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
array([0.49484029, 0.04021166, 0.75026781])
图 7-9 在左列中表示这三棵树的预测,右列中表示集成的预测。在第一行中,集成只有一棵树,因此其预测与第一棵树的预测完全相同。在第二行中,新树是在第一棵树的残差错误上训练的。您可以看到集成的预测等于前两棵树的预测之和。类似地,在第三行中,另一棵树是在第二棵树的残差错误上训练的。您可以看到随着树被添加到集成中,集成的预测逐渐变得更好。
您可以使用 Scikit-Learn 的GradientBoostingRegressor类更轻松地训练 GBRT 集合(还有一个用于分类的GradientBoostingClassifier类)。就像RandomForestRegressor类一样,它有用于控制决策树增长的超参数(例如max_depth,min_samples_leaf),以及用于控制集合训练的超参数,比如树的数量(n_estimators)。以下代码创建了与前一个相同的集合:
from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=3,
learning_rate=1.0, random_state=42)
gbrt.fit(X, y)

图 7-9。在这个梯度提升的描述中,第一个预测器(左上角)被正常训练,然后每个连续的预测器(左中和左下)都是在前一个预测器的残差上进行训练;右列显示了结果集合的预测
learning_rate超参数缩放每棵树的贡献。如果将其设置为一个较低的值,比如0.05,则需要更多的树来拟合训练集,但预测通常会更好地泛化。这是一种称为缩减的正则化技术。图 7-10 显示了使用不同超参数训练的两个 GBRT 集合:左侧的集合没有足够的树来拟合训练集,而右侧的集合有大约适量的树。如果添加更多的树,GBRT 将开始过拟合训练集。

图 7-10。GBRT 集合,预测器不足(左)和刚好足够(右)
要找到最佳数目的树,可以像往常一样使用GridSearchCV或RandomizedSearchCV进行交叉验证,但也有一种更简单的方法:如果将n_iter_no_change超参数设置为一个整数值,比如 10,那么GradientBoostingRegressor将在训练过程中自动停止添加更多的树,如果看到最后的 10 棵树没有帮助。这只是早停(在第四章中介绍),但需要一点耐心:它容忍在停止之前几次迭代没有进展。让我们使用早停来训练集合:
gbrt_best = GradientBoostingRegressor(
max_depth=2, learning_rate=0.05, n_estimators=500,
n_iter_no_change=10, random_state=42)
gbrt_best.fit(X, y)
如果将n_iter_no_change设置得太低,训练可能会过早停止,模型会欠拟合。但如果设置得太高,它将过拟合。我们还设置了一个相当小的学习率和一个较高数量的估计器,但由于早停,训练集合中实际的估计器数量要低得多:
>>> gbrt_best.n_estimators_
92
当设置了n_iter_no_change时,fit()方法会自动将训练集分成一个较小的训练集和一个验证集:这使得它可以在每次添加新树时评估模型的性能。验证集的大小由validation_fraction超参数控制,默认为 10%。tol超参数确定了仍然被视为微不足道的最大性能改进。默认值为 0.0001。
GradientBoostingRegressor类还支持一个subsample超参数,指定用于训练每棵树的训练实例的分数。例如,如果subsample=0.25,则每棵树都是在选择的 25%训练实例上随机训练的。现在你可能已经猜到了,这种技术以更低的方差换取更高的偏差。它还显著加快了训练速度。这被称为随机梯度提升。
基于直方图的梯度提升
Scikit-Learn 还提供了另一种针对大型数据集进行优化的 GBRT 实现:基于直方图的梯度提升(HGB)。它通过对输入特征进行分箱,用整数替换它们来工作。箱数由max_bins超参数控制,默认为 255,不能设置得比这更高。分箱可以大大减少训练算法需要评估的可能阈值数量。此外,使用整数可以使用更快速和更节省内存的数据结构。构建箱的方式消除了在训练每棵树时对特征进行排序的需要。
因此,这种实现的计算复杂度为O(b×m),而不是O(n×m×log(m)),其中b是箱数,m是训练实例数,n是特征数。实际上,这意味着 HGB 在大型数据集上的训练速度可以比常规 GBRT 快数百倍。然而,分箱会导致精度损失,这起到了正则化的作用:根据数据集的不同,这可能有助于减少过拟合,也可能导致欠拟合。
Scikit-Learn 提供了两个 HGB 类:HistGradientBoostingRegressor和HistGradientBoostingClassifier。它们类似于GradientBoostingRegressor和GradientBoostingClassifier,但有一些显著的区别:
-
如果实例数大于 10,000,则自动启用提前停止。您可以通过将
early_stopping超参数设置为True或False来始终启用或关闭提前停止。 -
不支持子采样。
-
n_estimators被重命名为max_iter。 -
唯一可以调整的决策树超参数是
max_leaf_nodes、min_samples_leaf和max_depth。
HGB 类还有两个很好的特性:它们支持分类特征和缺失值。这在预处理方面简化了很多。但是,分类特征必须表示为从 0 到小于max_bins的整数。您可以使用OrdinalEncoder来实现。例如,以下是如何为第二章介绍的加利福尼亚住房数据集构建和训练完整管道的方法:
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.preprocessing import OrdinalEncoder
hgb_reg = make_pipeline(
make_column_transformer((OrdinalEncoder(), ["ocean_proximity"]),
remainder="passthrough"),
HistGradientBoostingRegressor(categorical_features=[0], random_state=42)
)
hgb_reg.fit(housing, housing_labels)
整个管道和导入一样简短!不需要填充器、缩放器或独热编码器,非常方便。请注意,categorical_features必须设置为分类列的索引(或布尔数组)。在没有进行任何超参数调整的情况下,该模型的 RMSE 约为 47,600,这还算不错。
提示
Python ML 生态系统中还提供了几种经过优化的梯度提升实现:特别是XGBoost、CatBoost和LightGBM。这些库已经存在了几年。它们都专门用于梯度提升,它们的 API 与 Scikit-Learn 的非常相似,并提供许多附加功能,包括 GPU 加速;您一定要去了解一下!此外,TensorFlow 随机森林库提供了各种随机森林算法的优化实现,包括普通随机森林、极端树、GBRT 等等。
堆叠
本章我们将讨论的最后一种集成方法称为堆叠(缩写为堆叠泛化)。它基于一个简单的想法:不要使用微不足道的函数(如硬投票)来聚合集成中所有预测器的预测,为什么不训练一个模型来执行这种聚合呢?图 7-11 展示了这样一个集成在新实例上执行回归任务。底部的三个预测器中的每一个都预测不同的值(3.1、2.7 和 2.9),然后最终的预测器(称为混合器或元学习器)将这些预测作为输入,做出最终的预测(3.0)。

图 7-11。使用混合预测器聚合预测
要训练混合器,首先需要构建混合训练集。您可以对集成中的每个预测器使用cross_val_predict(),以获取原始训练集中每个实例的样本外预测(图 7-12),并将这些用作输入特征来训练混合器;目标可以简单地从原始训练集中复制。请注意,无论原始训练集中的特征数量如何(在本例中只有一个),混合训练集将包含每个预测器的一个输入特征(在本例中为三个)。一旦混合器训练完成,基本预测器将最后一次在完整的原始训练集上重新训练。

图 7-12。在堆叠集成中训练混合器
实际上可以通过这种方式训练几个不同的混合器(例如,一个使用线性回归,另一个使用随机森林回归),以获得一个完整的混合器层,并在其上再添加另一个混合器以生成最终预测,如图 7-13 所示。通过这样做,您可能会挤出更多的性能,但这将在训练时间和系统复杂性方面付出代价。

图 7-13。多层堆叠集成中的预测
Scikit-Learn 提供了两个用于堆叠集成的类:StackingClassifier和StackingRegressor。例如,我们可以用StackingClassifier替换本章开始时在 moons 数据集上使用的VotingClassifier:
from sklearn.ensemble import StackingClassifier
stacking_clf = StackingClassifier(
estimators=[
('lr', LogisticRegression(random_state=42)),
('rf', RandomForestClassifier(random_state=42)),
('svc', SVC(probability=True, random_state=42))
],
final_estimator=RandomForestClassifier(random_state=43),
cv=5 # number of cross-validation folds
)
stacking_clf.fit(X_train, y_train)
对于每个预测器,堆叠分类器将调用predict_proba()(如果可用);如果不可用,它将退而求其次调用decision_function(),或者作为最后手段调用predict()。如果您没有提供最终的估计器,StackingClassifier将使用LogisticRegression,而StackingRegressor将使用RidgeCV。
如果您在测试集上评估这个堆叠模型,您会发现 92.8%的准确率,比使用软投票的投票分类器稍好,后者获得了 92%。
总之,集成方法是多才多艺、强大且相当简单易用的。随机森林、AdaBoost 和 GBRT 是您应该为大多数机器学习任务测试的第一批模型,它们在异构表格数据方面表现尤为出色。此外,由于它们需要非常少的预处理,因此非常适合快速搭建原型。最后,像投票分类器和堆叠分类器这样的集成方法可以帮助将系统的性能推向极限。
练习
-
如果您在完全相同的训练数据上训练了五个不同的模型,并且它们都达到了 95%的精度,是否有可能将这些模型组合以获得更好的结果?如果可以,如何?如果不行,为什么?
-
硬投票分类器和软投票分类器之间有什么区别?
-
将一个装袋集成的训练分布到多个服务器上是否可以加快训练速度?那么对于粘贴集成、提升集成、随机森林或堆叠集成呢?
-
什么是袋外评估的好处?
-
什么使得额外树集成比常规随机森林更随机?这种额外的随机性如何帮助?额外树分类器比常规随机森林慢还是快?
-
如果您的 AdaBoost 集成对训练数据拟合不足,应该调整哪些超参数,如何调整?
-
如果您的梯度提升集成对训练集过拟合,应该增加还是减少学习率?
-
加载 MNIST 数据集(在第三章中介绍),将其分为训练集、验证集和测试集(例如,使用 50,000 个实例进行训练,10,000 个用于验证,10,000 个用于测试)。然后训练各种分类器,如随机森林分类器、额外树分类器和 SVM 分类器。接下来,尝试将它们组合成一个集成,使用软投票或硬投票在验证集上优于每个单独的分类器。一旦找到一个,尝试在测试集上运行。它的表现比单个分类器好多少?
-
运行上一个练习中的各个分类器,对验证集进行预测,并使用结果预测创建一个新的训练集:每个训练实例是一个向量,包含所有分类器对图像的预测集合,目标是图像的类别。在这个新的训练集上训练一个分类器。恭喜您——您刚刚训练了一个混合器,它与分类器一起形成了一个堆叠集成!现在在测试集上评估集成。对于测试集中的每个图像,使用所有分类器进行预测,然后将预测结果输入混合器以获得集成的预测。它与您之前训练的投票分类器相比如何?现在尝试使用
StackingClassifier。性能更好吗?如果是,为什么?
这些练习的解决方案可以在本章笔记本的末尾找到,网址为https://homl.info/colab3。
¹ 想象从一副牌中随机抽取一张卡片,写下来,然后将其放回到牌组中再抽取下一张卡片:同一张卡片可能被多次抽样。
² Leo Breiman,“Bagging 预测器”,机器学习 24, no. 2 (1996): 123–140。
³ 在统计学中,带替换的重采样被称为自助法。
⁴ Leo Breiman,“在大型数据库和在线分类中粘贴小投票”,机器学习 36, no. 1–2 (1999): 85–103。
⁵ 偏差和方差在第四章中介绍过。
⁶ max_samples也可以设置为 0.0 到 1.0 之间的浮点数,此时采样实例的最大数量等于训练集大小乘以max_samples。
⁷ 当m增长时,这个比率接近 1 – exp(–1) ≈ 63%。
⁸ Gilles Louppe 和 Pierre Geurts,“随机补丁上的集成”,计算机科学讲义 7523 (2012): 346–361。
⁹ 何天金,“用于构建决策森林的随机子空间方法”,IEEE 模式分析与机器智能 20, no. 8 (1998): 832–844。
¹⁰ 何天金,“随机决策森林”,第三届文档分析与识别国际会议论文集 1 (1995): 278。
¹¹ 如果您想要一个除决策树以外的袋子,BaggingClassifier 类仍然很有用。
¹² Pierre Geurts 等,“极端随机树”,机器学习 63, no. 1 (2006): 3–42。
¹³ Yoav Freund 和 Robert E. Schapire, “一个决策理论的在线学习泛化及其在 Boosting 中的应用”, 计算机与系统科学杂志 55, no. 1 (1997): 119–139.
¹⁴ 这仅供说明目的。SVMs 通常不是 AdaBoost 的好基础预测器;它们速度慢且在其中不稳定。
¹⁵ 原始的 AdaBoost 算法不使用学习率超参数。
¹⁶ 更多细节请参见 Ji Zhu 等人的 “多类别 AdaBoost”, 统计学及其界面 2, no. 3 (2009): 349–360.
¹⁷ 梯度提升首次在 Leo Breiman 的 1997 年论文 “Arcing the Edge” 中引入,并在 Jerome H. Friedman 的 1999 年论文 “Greedy Function Approximation: A Gradient Boosting Machine” 中进一步发展。
¹⁸ David H. Wolpert, “堆叠泛化”, 神经网络 5, no. 2 (1992): 241–259.
第八章:降维
许多机器学习问题涉及每个训练实例数千甚至数百万个特征。所有这些特征不仅使训练变得极其缓慢,而且还会使找到一个好的解决方案变得更加困难,您将会看到。这个问题通常被称为维度灾难。
幸运的是,在现实世界的问题中,通常可以大大减少特征的数量,将一个棘手的问题转变为一个可处理的问题。例如,考虑 MNIST 图像(在第三章介绍):图像边缘的像素几乎总是白色,因此您可以完全从训练集中删除这些像素,而不会丢失太多信息。正如我们在上一章中看到的,(图 7-6)证实这些像素对于分类任务是完全不重要的。此外,两个相邻的像素通常高度相关:如果将它们合并成一个像素(例如,通过取两个像素强度的平均值),您不会丢失太多信息。
警告
降低维度确实会导致一些信息丢失,就像将图像压缩为 JPEG 可能会降低其质量一样,因此,即使它会加快训练速度,但可能会使您的系统表现稍微变差。它还会使您的流程管道变得更加复杂,因此更难维护。因此,我建议您在考虑使用降维之前,首先尝试使用原始数据训练系统。在某些情况下,降低训练数据的维度可能会过滤掉一些噪音和不必要的细节,从而导致更高的性能,但一般情况下不会;它只会加快训练速度。
除了加快训练速度,降维对于数据可视化也非常有用。将维度降低到二维(或三维)使得可以在图表上绘制高维训练集的简化视图,并经常通过直观地检测模式(如聚类)获得一些重要的见解。此外,数据可视化对于向非数据科学家(特别是将使用您的结果的决策者)传达您的结论至关重要。
在本章中,我们将首先讨论维度灾难,并了解高维空间中发生的情况。然后我们将考虑降维的两种主要方法(投影和流形学习),并将介绍三种最流行的降维技术:PCA、随机投影和局部线性嵌入(LLE)。
维度灾难
我们习惯于生活在三维空间中¹,当我们尝试想象高维空间时,我们的直觉会失败。即使是基本的四维超立方体在我们的脑海中也难以想象(见图 8-1),更不用说一个弯曲在 1000 维空间中的 200 维椭球了。

图 8-1. 点、线段、正方形、立方体和四维立方体(0D 到 4D 超立方体)²
事实证明,许多事物在高维空间中表现出非常不同。例如,如果在一个单位正方形(一个 1×1 的正方形)中随机选择一个点,它只有约 0.4%的机会位于距离边界不到 0.001 的位置(换句话说,随机点在任何维度上“极端”的可能性非常小)。但在一个 10000 维单位超立方体中,这个概率大于 99.999999%。高维超立方体中的大多数点都非常靠近边界。³
这里有一个更棘手的差异:如果你在单位正方形中随机选择两个点,这两点之间的距离平均约为 0.52。如果你在 3D 单位立方体中随机选择两个点,平均距离将约为 0.66。但是如果你在一个 100 万维单位超立方体中随机选择两个点呢?平均距离,信不信由你,将约为 408.25(大约1,000,0006)!这是违反直觉的:当两点都位于同一个单位超立方体内时,它们怎么会相距如此遥远呢?嗯,在高维空间中有很多空间。因此,高维数据集很可能非常稀疏:大多数训练实例可能相互之间相距很远。这也意味着新实例很可能与任何训练实例相距很远,使得预测比在低维度中不可靠得多,因为它们将基于更大的外推。简而言之,训练集的维度越高,过拟合的风险就越大。
理论上,解决维度灾难的一个方法可能是增加训练集的大小,以达到足够密度的训练实例。不幸的是,在实践中,达到给定密度所需的训练实例数量随着维度的增加呈指数增长。仅仅具有 100 个特征——明显少于 MNIST 问题中的特征数量——这些特征范围从 0 到 1,你需要的训练实例数量将超过可观察宇宙中的原子数量,以便训练实例在平均情况下相距 0.1,假设它们均匀分布在所有维度上。
降维的主要方法
在我们深入研究具体的降维算法之前,让我们看一看降维的两种主要方法:投影和流形学习。
投影
在大多数实际问题中,训练实例并不均匀分布在所有维度上。许多特征几乎是恒定的,而其他特征高度相关(正如前面讨论的 MNIST)。因此,所有训练实例都位于(或接近)高维空间中的一个更低维度子空间内。这听起来很抽象,让我们看一个例子。在图 8-2 中,你可以看到由小球表示的 3D 数据集。

图 8-2. 一个接近 2D 子空间的 3D 数据集
注意到所有训练实例都接近一个平面:这是高维(3D)空间中的一个低维(2D)子空间。如果我们将每个训练实例垂直投影到这个子空间上(如短虚线连接实例到平面),我们得到了在图 8-3 中显示的新的 2D 数据集。哇!我们刚刚将数据集的维度从 3D 降低到 2D。请注意,轴对应于新特征z[1]和z[2]:它们是平面上投影的坐标。

图 8-3. 投影后的新 2D 数据集
流形学习
然而,投影并不总是降维的最佳方法。在许多情况下,子空间可能扭曲变化,例如在著名的瑞士卷玩具数据集中所示的图 8-4。

图 8-4. 瑞士卷数据集
简单地投影到平面上(例如,通过删除x[3])会将瑞士卷的不同层压缩在一起,如图 8-5 的左侧所示。你可能想要的是展开瑞士卷,以获得图 8-5 右侧的 2D 数据集。

图 8-5. 投影到平面上压缩(左)与展开瑞士卷(右)
瑞士卷是一个 2D 流形的例子。简单地说,一个 2D 流形是一个可以在更高维空间中弯曲和扭曲的 2D 形状。更一般地,一个d维流形是一个n维空间的一部分(其中d < n),在局部上类似于一个d维超平面。在瑞士卷的情况下,d = 2,n = 3:它在局部上类似于一个 2D 平面,但在第三维中卷曲。
许多降维算法通过对训练实例所在的流形进行建模来工作;这称为流形学习。它依赖于流形假设,也称为流形假设,即大多数真实世界的高维数据集接近一个低维流形。这种假设经常在实践中被观察到。
再次想想 MNIST 数据集:所有手写数字图像都有一些相似之处。它们由连接的线条组成,边界是白色的,它们大致居中。如果您随机生成图像,只有极小的一部分会看起来像手写数字。换句话说,如果您尝试创建一个数字图像,可用的自由度要比您允许生成任何图像时的自由度大大降低。这些约束往往会将数据集压缩到一个低维流形中。
流形假设通常伴随着另一个隐含的假设:如果在流形的低维空间中表达任务(例如分类或回归),那么任务会更简单。例如,在图 8-6 的顶部行中,瑞士卷被分为两类:在 3D 空间中(左侧)决策边界会相当复杂,但在 2D 展开的流形空间中(右侧)决策边界是一条直线。
然而,这种隐含的假设并不总是成立。例如,在图 8-6 的底部行,决策边界位于x[1] = 5。这个决策边界在原始的 3D 空间中看起来非常简单(一个垂直平面),但在展开的流形中看起来更复杂(四个独立线段的集合)。
简而言之,在训练模型之前减少训练集的维度通常会加快训练速度,但并不总是会导致更好或更简单的解决方案;这完全取决于数据集。
希望您现在对维度诅咒有了一个很好的理解,以及降维算法如何对抗它,特别是在流形假设成立时。本章的其余部分将介绍一些最流行的降维算法。
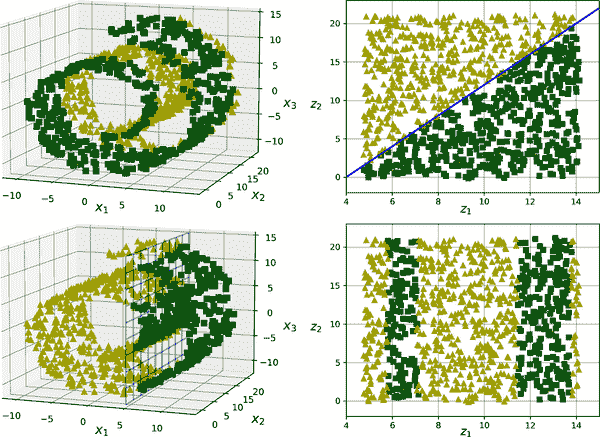
图 8-6。降维后决策边界可能并不总是更简单
PCA
主成分分析(PCA)是迄今为止最流行的降维算法。首先它确定与数据最接近的超平面,然后将数据投影到该超平面上,就像在图 8-2 中一样。
保留方差
在将训练集投影到低维超平面之前,您首先需要选择正确的超平面。例如,一个简单的 2D 数据集在图 8-7 的左侧表示,以及三个不同的轴(即 1D 超平面)。右侧是数据集投影到每个轴上的结果。正如您所看到的,对实线的投影保留了最大的方差(顶部),而对虚线的投影保留了很少的方差(底部),对虚线的投影保留了中等数量的方差(中部)。

图 8-7。选择要投影的子空间
选择保留最大方差量的轴似乎是合理的,因为它很可能会比其他投影丢失更少的信息。另一个证明这种选择的方法是,它是最小化原始数据集与其在该轴上的投影之间的均方距离的轴。这是PCA背后的相当简单的想法。⁴
主成分
PCA 确定在训练集中占据最大方差量的轴。在图 8-7 中,它是实线。它还找到第二个轴,与第一个轴正交,占剩余方差的最大部分。在这个 2D 示例中没有选择:它是虚线。如果是高维数据集,PCA 还会找到第三个轴,与前两个轴正交,以及第四个、第五个等等——与数据集中的维数一样多的轴。
第i轴称为数据的第i个主成分(PC)。在图 8-7 中,第一个 PC 是向量c[1]所在的轴,第二个 PC 是向量c[2]所在的轴。在图 8-2 中,前两个 PC 位于投影平面上,第三个 PC 是与该平面正交的轴。在投影之后,在图 8-3 中,第一个 PC 对应于z[1]轴,第二个 PC 对应于z[2]轴。
注意
对于每个主成分,PCA 找到一个指向 PC 方向的零中心单位向量。由于两个相对的单位向量位于同一轴上,PCA 返回的单位向量的方向不稳定:如果稍微扰动训练集并再次运行 PCA,则单位向量可能指向与原始向量相反的方向。但是,它们通常仍然位于相同的轴上。在某些情况下,一对单位向量甚至可能旋转或交换(如果沿这两个轴的方差非常接近),但是它们定义的平面通常保持不变。
那么如何找到训练集的主成分呢?幸运的是,有一种称为奇异值分解(SVD)的标准矩阵分解技术,可以将训练集矩阵X分解为三个矩阵U Σ V^⊺的矩阵乘法,其中V包含定义您正在寻找的所有主成分的单位向量,如方程 8-1 所示。
第 8-1 方程。主成分矩阵
V = ∣ ∣ ∣ c 1 c 2 ⋯ c n ∣ ∣ ∣
以下 Python 代码使用 NumPy 的svd()函数获取在图 8-2 中表示的 3D 训练集的所有主成分,然后提取定义前两个 PC 的两个单位向量:
import numpy as np
X = [...] # create a small 3D dataset
X_centered = X - X.mean(axis=0)
U, s, Vt = np.linalg.svd(X_centered)
c1 = Vt[0]
c2 = Vt[1]
警告
PCA 假定数据集围绕原点居中。正如您将看到的,Scikit-Learn 的 PCA 类会为您处理数据的中心化。如果您自己实现 PCA(如前面的示例中),或者使用其他库,请不要忘记首先对数据进行中心化。
投影到 d 维
一旦确定了所有主成分,您可以通过将数据集投影到由前 d 个主成分定义的超平面上来将数据集的维度降低到 d 维。选择这个超平面可以确保投影尽可能保留更多的方差。例如,在 Figure 8-2 中,3D 数据集被投影到由前两个主成分定义的 2D 平面上,保留了数据集大部分的方差。因此,2D 投影看起来非常像原始的 3D 数据集。
将训练集投影到超平面上,并获得降维后的数据集 X[d-proj],维度为 d,计算训练集矩阵 X 与矩阵 W[d] 的矩阵乘法,其中 W[d] 定义为包含 V 的前 d 列的矩阵,如 Equation 8-2 所示。
Equation 8-2. 将训练集投影到 d 维
X d-proj = X W d
以下 Python 代码将训练集投影到由前两个主成分定义的平面上:
W2 = Vt[:2].T
X2D = X_centered @ W2
就是这样!现在你知道如何通过将数据集投影到任意维度来降低数据集的维度,同时尽可能保留更多的方差。
使用 Scikit-Learn
Scikit-Learn 的 PCA 类使用 SVD 来实现 PCA,就像我们在本章中之前所做的那样。以下代码应用 PCA 将数据集的维度降低到两个维度(请注意,它会自动处理数据的居中):
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X2D = pca.fit_transform(X)
在将 PCA 转换器拟合到数据集后,其 components_ 属性保存了 W[d] 的转置:它包含了前 d 个主成分的每一行。
解释方差比
另一个有用的信息是每个主成分的解释方差比,可以通过 explained_variance_ratio_ 变量获得。该比率表示数据集方差沿着每个主成分的比例。例如,让我们看看在 Figure 8-2 中表示的 3D 数据集的前两个主成分的解释方差比:
>>> pca.explained_variance_ratio_
array([0.7578477 , 0.15186921])
这个输出告诉我们大约 76% 的数据集方差沿着第一个主成分,大约 15% 沿着第二个主成分。这留下了约 9% 给第三个主成分,因此可以合理地假设第三个主成分可能携带的信息很少。
选择正确的维度数量
不要随意选择要降维到的维度数量,更简单的方法是选择维度数量,使其总和占方差的足够大比例,比如 95%(当然,有一个例外,如果你是为了数据可视化而降维,那么你会希望将维度降低到 2 或 3)。
以下代码加载并拆分 MNIST 数据集(在 Chapter 3 中介绍),并在不降维的情况下执行 PCA,然后计算保留训练集 95% 方差所需的最小维度数量:
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', as_frame=False)
X_train, y_train = mnist.data[:60_000], mnist.target[:60_000]
X_test, y_test = mnist.data[60_000:], mnist.target[60_000:]
pca = PCA()
pca.fit(X_train)
cumsum = np.cumsum(pca.explained_variance_ratio_)
d = np.argmax(cumsum >= 0.95) + 1 # d equals 154
然后,您可以将 n_components=d,再次运行 PCA,但有一个更好的选择。而不是指定要保留的主成分数量,您可以将 n_components 设置为介于 0.0 和 1.0 之间的浮点数,表示您希望保留的方差比例:
pca = PCA(n_components=0.95)
X_reduced = pca.fit_transform(X_train)
实际的主成分数量是在训练过程中确定的,并存储在 n_components_ 属性中:
>>> pca.n_components_
154
另一个选项是将解释的方差作为维度数量的函数绘制出来(简单地绘制cumsum;参见图 8-8)。曲线通常会出现一个拐点,解释的方差增长速度会变慢。在这种情况下,您可以看到将维度降低到约 100 维不会丢失太多解释的方差。

图 8-8。解释的方差作为维度数量的函数
最后,如果您将降维作为监督学习任务(例如分类)的预处理步骤,则可以像调整任何其他超参数一样调整维度数量(参见第二章)。例如,以下代码示例创建了一个两步流水线,首先使用 PCA 降低维度,然后使用随机森林进行分类。接下来,它使用RandomizedSearchCV来找到 PCA 和随机森林分类器的超参数的良好组合。此示例进行了快速搜索,仅调整了 2 个超参数,在仅训练了 1,000 个实例的情况下运行了仅 10 次迭代,但如果您有时间,请随时进行更彻底的搜索:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV
from sklearn.pipeline import make_pipeline
clf = make_pipeline(PCA(random_state=42),
RandomForestClassifier(random_state=42))
param_distrib = {
"pca__n_components": np.arange(10, 80),
"randomforestclassifier__n_estimators": np.arange(50, 500)
}
rnd_search = RandomizedSearchCV(clf, param_distrib, n_iter=10, cv=3,
random_state=42)
rnd_search.fit(X_train[:1000], y_train[:1000])
让我们看看找到的最佳超参数:
>>> print(rnd_search.best_params_)
{'randomforestclassifier__n_estimators': 465, 'pca__n_components': 23}
有趣的是最佳组件数量是多么低:我们将一个 784 维数据集减少到只有 23 维!这与我们使用了随机森林这一强大模型有关。如果我们改用线性模型,例如SGDClassifier,搜索会发现我们需要保留更多维度(约 70 个)。
用于压缩的 PCA
降维后,训练集占用的空间大大减少。例如,将 PCA 应用于 MNIST 数据集并保留 95%的方差后,我们只剩下 154 个特征,而不是原始的 784 个特征。因此,数据集现在不到原始大小的 20%,而且我们仅损失了 5%的方差!这是一个合理的压缩比率,很容易看出这种大小的减小会极大地加快分类算法的速度。
还可以通过应用 PCA 投影的逆变换将缩减的数据集解压缩回 784 维。这不会给您原始数据,因为投影丢失了一些信息(在丢弃的 5%方差内),但它可能接近原始数据。原始数据和重构数据(压缩然后解压缩)之间的均方距离称为重构误差。
inverse_transform()方法让我们将降维后的 MNIST 数据集解压缩回 784 维:
X_recovered = pca.inverse_transform(X_reduced)
图 8-9 展示了原始训练集中的一些数字(左侧),以及压缩和解压缩后的相应数字。您可以看到存在轻微的图像质量损失,但数字仍然基本完整。

图 8-9。保留 95%方差的 MNIST 压缩
逆变换的方程式显示在方程 8-3 中。
方程 8-3。PCA 逆变换,回到原始维度数量
X recovered = X d-proj W d ⊺
随机 PCA
如果将svd_solver超参数设置为"randomized",Scikit-Learn 将使用一种称为随机 PCA的随机算法,快速找到前d个主成分的近似值。其计算复杂度为O(m × d²) + O(d³),而不是完整 SVD 方法的O(m × n²) + O(n³),因此当d远小于n时,它比完整 SVD 快得多:
rnd_pca = PCA(n_components=154, svd_solver="randomized", random_state=42)
X_reduced = rnd_pca.fit_transform(X_train)
提示
默认情况下,svd_solver 实际上设置为 "auto":Scikit-Learn 在 max(m, n) > 500 且 n_components 是小于 min(m, n) 的 80%的整数时,自动使用随机化 PCA 算法,否则使用完整的 SVD 方法。因此,即使删除了 svd_solver="randomized" 参数,上述代码也会使用随机化 PCA 算法,因为 154 < 0.8 × 784。如果要强制 Scikit-Learn 使用完整的 SVD 以获得稍微更精确的结果,可以将 svd_solver 超参数设置为 "full"。
增量 PCA
PCA 的前述实现的一个问题是,为了使算法运行,整个训练集必须适合内存。幸运的是,已经开发出了增量 PCA(IPCA)算法,允许您将训练集分成小批次,并逐个小批次馈送这些数据。这对于大型训练集以及在线应用 PCA(即,随着新实例的到来而进行)非常有用。
以下代码将 MNIST 训练集分成 100 个小批次(使用 NumPy 的 array_split() 函数),并将它们馈送给 Scikit-Learn 的 IncrementalPCA 类来将 MNIST 数据集的维度降低到 154 维,就像以前一样。请注意,您必须对每个小批次调用 partial_fit() 方法,而不是对整个训练集调用 fit() 方法:
from sklearn.decomposition import IncrementalPCA
n_batches = 100
inc_pca = IncrementalPCA(n_components=154)
for X_batch in np.array_split(X_train, n_batches):
inc_pca.partial_fit(X_batch)
X_reduced = inc_pca.transform(X_train)
或者,您可以使用 NumPy 的 memmap 类,它允许您像在内存中一样操作存储在磁盘上的二进制文件中的大数组;该类仅在需要时将数据加载到内存中。为了演示这一点,让我们首先创建一个内存映射(memmap)文件,并将 MNIST 训练集复制到其中,然后调用 flush() 来确保任何仍在缓存中的数据被保存到磁盘。在现实生活中,X_train 通常不会完全适合内存,因此您需要逐块加载它并将每个块保存到 memmap 数组的正确部分:
filename = "my_mnist.mmap"
X_mmap = np.memmap(filename, dtype='float32', mode='write', shape=X_train.shape)
X_mmap[:] = X_train # could be a loop instead, saving the data chunk by chunk
X_mmap.flush()
接下来,我们可以加载 memmap 文件并像常规 NumPy 数组一样使用它。让我们使用 IncrementalPCA 类来降低其维度。由于该算法在任何给定时间仅使用数组的一小部分,内存使用保持在控制之下。这使得可以调用通常的 fit() 方法而不是 partial_fit() 方法,这非常方便:
X_mmap = np.memmap(filename, dtype="float32", mode="readonly").reshape(-1, 784)
batch_size = X_mmap.shape[0] // n_batches
inc_pca = IncrementalPCA(n_components=154, batch_size=batch_size)
inc_pca.fit(X_mmap)
警告
只有原始的二进制数据保存在磁盘上,因此在加载时需要指定数组的数据类型和形状。如果省略形状,np.memmap() 将返回一个一维数组。
对于非常高维的数据集,PCA 可能太慢了。正如您之前看到的,即使使用随机化 PCA,其计算复杂度仍然是 O(m × d²) + O(d³),因此目标维数 d 不应太大。如果您处理的数据集具有成千上万个特征或更多(例如,图像),那么训练可能会变得非常缓慢:在这种情况下,您应该考虑使用随机投影。
随机投影
正如其名称所示,随机投影算法使用随机线性投影将数据投影到较低维度的空间。这听起来可能很疯狂,但事实证明,这样的随机投影实际上很可能相当好地保留距离,正如 William B. Johnson 和 Joram Lindenstrauss 在一个著名的引理中数学上证明的那样。因此,两个相似的实例在投影后仍然保持相似,而两个非常不同的实例在投影后仍然保持非常不同。
显然,你丢弃的维度越多,丢失的信息就越多,距离就会变得更加扭曲。那么你如何选择最佳的维度数量呢?Johnson 和 Lindenstrauss 提出了一个方程,确定保留的最小维度数量,以确保——高概率下——距离不会改变超过给定的容差。例如,如果你有一个包含m=5,000 个实例,每个实例有n=20,000 个特征的数据集,你不希望任意两个实例之间的平方距离变化超过ε=10%,⁶,那么你应该将数据投影到d维度,其中d≥4 log(m) / (½ ε² - ⅓ ε³),即 7,300 维度。这是一个相当显著的降维!请注意,这个方程不使用n,它只依赖于m和ε。这个方程由johnson_lindenstrauss_min_dim()函数实现:
>>> from sklearn.random_projection import johnson_lindenstrauss_min_dim
>>> m, ε = 5_000, 0.1
>>> d = johnson_lindenstrauss_min_dim(m, eps=ε)
>>> d
7300
现在我们可以生成一个形状为[d, n]的随机矩阵P,其中每个项都是从均值为 0,方差为 1 / d的高斯分布中随机抽样的,然后用它将数据集从n维度投影到d维度:
n = 20_000
np.random.seed(42)
P = np.random.randn(d, n) / np.sqrt(d) # std dev = square root of variance
X = np.random.randn(m, n) # generate a fake dataset
X_reduced = X @ P.T
这就是全部!它简单高效,无需训练:算法需要创建随机矩阵的唯一信息是数据集的形状。数据本身根本没有被使用。
Scikit-Learn 提供了一个GaussianRandomProjection类,可以做我们刚才做的事情:当你调用它的fit()方法时,它使用johnson_lindenstrauss_min_dim()来确定输出的维度,然后生成一个随机矩阵,存储在components_属性中。然后当你调用transform()时,它使用这个矩阵来执行投影。在创建转换器时,如果你想调整ε,可以设置eps(默认为 0.1),如果你想强制特定的目标维度d,可以设置n_components。以下代码示例给出了与前面代码相同的结果(你也可以验证gaussian_rnd_proj.components_等于P):
from sklearn.random_projection import GaussianRandomProjection
gaussian_rnd_proj = GaussianRandomProjection(eps=ε, random_state=42)
X_reduced = gaussian_rnd_proj.fit_transform(X) # same result as above
Scikit-Learn 还提供了第二个随机投影转换器,称为SparseRandomProjection。它以相同的方式确定目标维度,生成相同形状的随机矩阵,并执行相同的投影。主要区别在于随机矩阵是稀疏的。这意味着它使用的内存要少得多:在前面的例子中,约 25 MB,而不是将近 1.2 GB!而且它也更快,无论是生成随机矩阵还是降维:在这种情况下,大约快 50%。此外,如果输入是稀疏的,转换会保持稀疏(除非你设置dense_output=True)。最后,它享有与之前方法相同的保持距离性质,降维的质量是可比较的。简而言之,通常最好使用这个转换器而不是第一个,特别是对于大型或稀疏数据集。
稀疏随机矩阵中非零项的比率r称为其密度。默认情况下,它等于1/n。有了 20,000 个特征,这意味着随机矩阵中大约 141 个单元格中只有 1 个是非零的:这是相当稀疏的!如果你愿意,你可以将density超参数设置为另一个值。稀疏随机矩阵中的每个单元格有一个概率r是非零的,每个非零值要么是–v,要么是+v(两者概率相等),其中v=1/dr。
如果你想执行逆变换,你首先需要使用 SciPy 的pinv()函数计算组件矩阵的伪逆,然后将减少的数据乘以伪逆的转置:
components_pinv = np.linalg.pinv(gaussian_rnd_proj.components_)
X_recovered = X_reduced @ components_pinv.T
警告
如果组件矩阵很大,计算伪逆可能需要很长时间,因为pinv()的计算复杂度是O(dn²)(如果d<n),否则是O(nd²)。
总之,随机投影是一种简单、快速、内存高效且令人惊讶地强大的降维算法,尤其在处理高维数据集时应该牢记。
注意
随机投影并不总是用于降低大型数据集的维度。例如,Sanjoy Dasgupta 等人的一篇2017 年论文显示,果蝇的大脑实现了一种类似随机投影的模拟,将密集的低维嗅觉输入映射到稀疏的高维二进制输出:对于每种气味,只有少数输出神经元被激活,但相似的气味会激活许多相同的神经元。这类似于一个名为局部敏感哈希(LSH)的著名算法,通常用于搜索引擎以将相似的文档分组。
LLE
局部线性嵌入(LLE)是一种非线性降维(NLDR)技术。它是一种流形学习技术,不依赖于投影,不同于 PCA 和随机投影。简而言之,LLE 首先衡量每个训练实例与其最近邻的线性关系,然后寻找训练集的低维表示,以便最好地保留这些局部关系(稍后详细介绍)。这种方法使其特别擅长展开扭曲的流形,尤其是在噪声不多时。
以下代码制作了一个瑞士卷,然后使用 Scikit-Learn 的LocallyLinearEmbedding类来展开它:
from sklearn.datasets import make_swiss_roll
from sklearn.manifold import LocallyLinearEmbedding
X_swiss, t = make_swiss_roll(n_samples=1000, noise=0.2, random_state=42)
lle = LocallyLinearEmbedding(n_components=2, n_neighbors=10, random_state=42)
X_unrolled = lle.fit_transform(X_swiss)
变量t是一个包含每个实例沿瑞士卷轴位置的 1D NumPy 数组。在这个示例中我们没有使用它,但它可以用作非线性回归任务的目标。
生成的 2D 数据集显示在图 8-10 中。如您所见,瑞士卷完全展开,实例之间的距离在局部上得到很好保留。然而,在较大尺度上距离并没有得到保留:展开的瑞士卷应该是一个矩形,而不是这种被拉伸和扭曲的带状。尽管如此,LLE 在对流形建模方面做得相当不错。
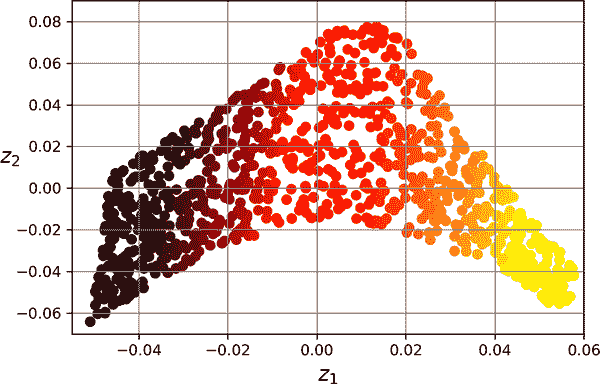
图 8-10。使用 LLE 展开的瑞士卷
LLE 的工作原理如下:对于每个训练实例x((*i*)),算法识别其*k*个最近邻居(在前面的代码中*k*=10),然后尝试将**x**((i))重构为这些邻居的线性函数。更具体地说,它尝试找到权重w[i,j],使得x^((i))和∑ j=1 m w i,j x (j)的平方距离尽可能小,假设如果x((*j*))不是**x**((i))的k个最近邻居之一,则w[i,j]=0。因此,LLE 的第一步是方程 8-4 中描述的约束优化问题,其中W是包含所有权重w[i,j]的权重矩阵。第二个约束只是为每个训练实例x^((i))归一化权重。
方程 8-4。LLE 第 1 步:线性建模局部关系
W ^ = argmin W ∑ i=1 m x (i) -∑ j=1 m w i,j x (j) 2 subject to w i,j = 0 if x (j) is not one of the k n.n. of x (i) ∑ j=1 m w i,j = 1 for i = 1 , 2 , ⋯ , m
在这一步之后,权重矩阵 W ^(包含权重 w^i,j)编码了训练实例之间的局部线性关系。第二步是将训练实例映射到一个 d 维空间(其中 d < n),同时尽可能保持这些局部关系。如果 z^((i)) 是在这个 d 维空间中 x^((i)) 的映像,那么我们希望 z^((i)) 和 ∑ j=1 m w ^ i,j z (j) 之间的平方距离尽可能小。这个想法导致了方程 8-5 中描述的无约束优化问题。它看起来与第一步非常相似,但是不是保持实例固定并找到最佳权重,而是相反的:保持权重固定并找到实例映像在低维空间中的最佳位置。注意,Z 是包含所有 z^((i)) 的矩阵。
方程 8-5. LLE 步骤 2:在保持关系的同时降低维度
Z ^ = argmin Z ∑ i=1 m z (i) -∑ j=1 m w ^ i,j z (j) 2
Scikit-Learn 的 LLE 实现具有以下计算复杂度:O(m log(m)n log(k))用于查找k个最近邻居,O(mnk³)用于优化权重,O(dm²)用于构建低维表示。不幸的是,最后一项中的m²使得这个算法在处理非常大的数据集时效率低下。
正如您所看到的,LLE 与投影技术有很大不同,它显著更复杂,但也可以构建更好的低维表示,特别是在数据是非线性的情况下。
其他降维技术
在我们结束本章之前,让我们快速看一下 Scikit-Learn 中提供的其他几种流行的降维技术:
sklearn.manifold.MDS
多维缩放(MDS)在尝试保持实例之间的距离的同时降低维度。随机投影可以用于高维数据,但在低维数据上效果不佳。
sklearn.manifold.Isomap
Isomap通过将每个实例连接到其最近邻来创建图,然后在尝试保持实例之间的测地距离的同时降低维度。图中两个节点之间的测地距离是这两个节点之间最短路径上的节点数。
sklearn.manifold.TSNE
t-分布随机邻域嵌入(t-SNE)在尝试保持相似实例接近和不相似实例分开的同时降低维度。它主要用于可视化,特别是用于在高维空间中可视化实例的聚类。例如,在本章末尾的练习中,您将使用 t-SNE 来可视化 MNIST 图像的 2D 地图。
sklearn.discriminant_analysis.LinearDiscriminantAnalysis
线性判别分析(LDA)是一种线性分类算法,在训练过程中学习类别之间最具区分性的轴。然后可以使用这些轴来定义一个超平面,将数据投影到该超平面上。这种方法的好处是投影将尽可能地使类别保持分开,因此 LDA 是在运行另一个分类算法之前降低维度的好技术(除非仅使用 LDA 就足够)。
图 8-11 展示了 MDS、Isomap 和 t-SNE 在瑞士卷上的结果。MDS 成功将瑞士卷展平而不丢失其全局曲率,而 Isomap 则完全丢失了曲率。根据下游任务的不同,保留大尺度结构可能是好事或坏事。t-SNE 在展平瑞士卷方面做得相当不错,保留了一些曲率,并且还放大了聚类,将卷撕裂开。同样,这可能是好事或坏事,取决于下游任务。
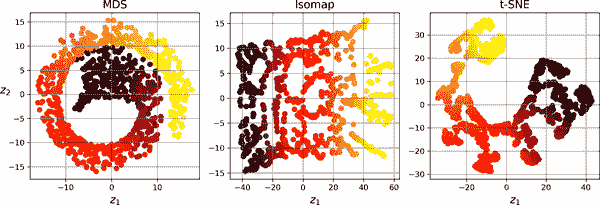
图 8-11。使用各种技术将瑞士卷降维为 2D
练习
-
降低数据集维度的主要动机是什么?主要缺点是什么?
-
维度诅咒是什么?
-
一旦数据集的维度降低了,是否可以反转操作?如果可以,如何操作?如果不行,为什么?
-
PCA 能用于降低高度非线性数据集的维度吗?
-
假设您对一个 1000 维数据集执行 PCA,将解释的方差比设置为 95%。结果数据集将有多少维度?
-
在什么情况下会使用常规 PCA、增量 PCA、随机 PCA 或随机投影?
-
如何评估数据集上降维算法的性能?
-
链两种不同的降维算法有意义吗?
-
加载 MNIST 数据集(在第三章介绍)并将其分为训练集和测试集(取前 60000 个实例进行训练,剩下的 10000 个进行测试)。在数据集上训练一个随机森林分类器并计时,然后评估测试集上的结果模型。接下来,使用 PCA 降低数据集的维度,解释方差比为 95%。在降维后的数据集上训练一个新的随机森林分类器并查看所需时间。训练速度快了吗?接下来,在测试集上评估分类器。与之前的分类器相比如何?再尝试使用
SGDClassifier。现在 PCA 有多大帮助? -
使用 t-SNE 将 MNIST 数据集的前 5000 个图像降至 2 维,并使用 Matplotlib 绘制结果。您可以使用散点图,使用 10 种不同的颜色表示每个图像的目标类别。或者,您可以用散点图中的每个点替换为相应实例的类别(从 0 到 9 的数字),甚至绘制数字图像本身的缩小版本(如果绘制所有数字,可视化将太混乱,因此您应该绘制一个随机样本或仅在没有其他实例已经绘制在附近距离的情况下绘制一个实例)。您应该得到一个具有良好分离的数字簇的漂亮可视化效果。尝试使用其他降维算法,如 PCA、LLE 或 MDS,并比较结果的可视化效果。
这些练习的解决方案可在本章笔记本的末尾找到,网址为https://homl.info/colab3。
([1])嗯,如果计算时间,那就是四维,如果你是弦理论学家,那就更多了。
([2])在https://homl.info/30观看一个在 3D 空间中投影的旋转四维立方体。图片由维基百科用户 NerdBoy1392 提供(知识共享署名-相同方式共享 3.0)。转载自https://en.wikipedia.org/wiki/Tesseract。
([3])有趣的事实:如果考虑足够多的维度,你认识的任何人可能在至少一个维度上是极端的(例如,他们在咖啡中放多少糖)。
([4])Karl Pearson,“关于空间中点系统的最佳拟合线和平面”,伦敦、爱丁堡和都柏林哲学杂志和科学杂志 2,第 11 号(1901 年):559-572。
([5])Scikit-Learn 使用 David A. Ross 等人描述的算法,“用于稳健视觉跟踪的增量学习”,国际计算机视觉杂志 77,第 1-3 号(2008 年):125-141。
([6])ε是希腊字母ε,通常用于表示微小值。
([7])Sanjoy Dasgupta 等人,“一个基本计算问题的神经算法”,Science 358,第 6364 号(2017 年):793-796。
([8])Sam T. Roweis 和 Lawrence K. Saul,“通过局部线性嵌入进行非线性降维”,Science 290,第 5500 号(2000 年):2323-2326。
第九章:无监督学习技术
尽管今天大多数机器学习应用都是基于监督学习的(因此,这也是大部分投资的方向),但绝大多数可用数据是无标签的:我们有输入特征X,但没有标签y。计算机科学家 Yann LeCun 曾经说过,“如果智能是一个蛋糕,无监督学习就是蛋糕,监督学习就是蛋糕上的糖衣,而强化学习就是蛋糕上的樱桃。”换句话说,无监督学习中有巨大的潜力,我们只是刚刚开始探索。
假设你想创建一个系统,该系统将拍摄制造生产线上每个物品的几张照片,并检测哪些物品有缺陷。你可以相当容易地创建一个系统,自动拍照,这可能每天给你数千张照片。然后你可以在短短几周内构建一个相当大的数据集。但是等等,没有标签!如果你想训练一个普通的二元分类器,预测物品是否有缺陷,你需要将每张图片标记为“有缺陷”或“正常”。这通常需要人类专家坐下来手动查看所有图片。这是一项漫长、昂贵和繁琐的任务,因此通常只会在可用图片的一小部分上进行。结果,标记的数据集将非常小,分类器的性能将令人失望。此外,每当公司对其产品进行任何更改时,整个过程都需要从头开始。如果算法只能利用无标签数据而无需人类标记每张图片,那不是很好吗?这就是无监督学习的作用。
在第八章中,我们看了最常见的无监督学习任务:降维。在本章中,我们将看一些更多的无监督任务:
聚类
目标是将相似的实例分组到簇中。聚类是数据分析、客户细分、推荐系统、搜索引擎、图像分割、半监督学习、降维等领域的重要工具。
异常检测(也称为离群检测)
目标是学习“正常”数据的外观,然后利用它来检测异常实例。这些实例被称为异常值或离群值,而正常实例被称为内群值。异常检测在各种应用中非常有用,如欺诈检测、制造中检测有缺陷的产品、识别时间序列中的新趋势,或在训练另一个模型之前从数据集中去除离群值,这可以显著提高结果模型的性能。
密度估计
这是估计生成数据集的随机过程的概率密度函数(PDF)的任务。密度估计通常用于异常检测:位于非常低密度区域的实例可能是异常值。它还可用于数据分析和可视化。
准备好享用蛋糕了吗?我们将从两个聚类算法k-means 和 DBSCAN 开始,然后讨论高斯混合模型,看看它们如何用于密度估计、聚类和异常检测。
聚类算法:k 均值和 DBSCAN
当您在山上徒步时,偶然发现了一种您以前从未见过的植物。您四处看看,发现了更多。它们并不完全相同,但它们足够相似,让您知道它们很可能属于同一物种(或至少同一属)。您可能需要植物学家告诉您那是什么物种,但您肯定不需要专家来识别相似外观的对象组。这就是聚类:识别相似实例并将它们分配到集群或相似实例组的任务。
就像分类一样,每个实例被分配到一个组。但是,与分类不同,聚类是一个无监督的任务。考虑图 9-1:左边是鸢尾花数据集(在第四章介绍),其中每个实例的物种(即其类)用不同的标记表示。这是一个带标签的数据集,适合使用逻辑回归、SVM 或随机森林分类器等分类算法。右边是相同的数据集,但没有标签,因此您不能再使用分类算法。这就是聚类算法介入的地方:其中许多算法可以轻松检测到左下角的集群。这也很容易用我们的眼睛看到,但上右角的集群由两个不同的子集群组成并不那么明显。也就是说,数据集有两个额外的特征(萼片长度和宽度)在这里没有表示,聚类算法可以很好地利用所有特征,因此实际上它们相当好地识别了三个集群(例如,使用高斯混合模型,150 个实例中只有 5 个被分配到错误的集群)。

图 9-1. 分类(左)与聚类(右)
聚类在各种应用中使用,包括:
客户细分
您可以根据客户的购买和在您网站上的活动对其进行聚类。这有助于了解您的客户是谁以及他们需要什么,这样您就可以根据每个细分调整您的产品和营销活动。例如,客户细分在推荐系统中可能很有用,以建议其他同一集群中的用户喜欢的内容。
数据分析
当您分析新数据集时,运行聚类算法然后分析每个集群单独可能会有所帮助。
降维
一旦数据集被聚类,通常可以测量每个实例与每个集群的亲和力;亲和力是衡量实例适合集群程度的任何度量。然后,每个实例的特征向量x可以用其集群亲和力的向量替换。如果有k个集群,那么这个向量是k维的。新向量通常比原始特征向量低得多,但它可以保留足够的信息供进一步处理。
特征工程
集群亲和力通常作为额外特征是有用的。例如,我们在第二章中使用k-means 将地理集群亲和特征添加到加利福尼亚住房数据集中,这有助于我们获得更好的性能。
异常检测(也称为离群值检测)
任何对所有集群的亲和力较低的实例可能是异常值。例如,如果您根据网站用户的行为对其进行了聚类,您可以检测到具有异常行为的用户,例如每秒请求的异常数量。
半监督学习
如果您只有少量标签,您可以执行聚类并将标签传播到同一集群中的所有实例。这种技术可以大大增加后续监督学习算法可用的标签数量,从而提高其性能。
搜索引擎
一些搜索引擎允许您搜索与参考图像相似的图像。要构建这样一个系统,您首先需要将聚类算法应用于数据库中的所有图像;相似的图像将最终位于同一聚类中。然后,当用户提供一个参考图像时,您只需要使用训练过的聚类模型来找到这个图像的聚类,然后简单地返回该聚类中的所有图像。
图像分割
通过根据它们的颜色对像素进行聚类,然后用其聚类的平均颜色替换每个像素的颜色,可以大大减少图像中不同颜色的数量。图像分割在许多对象检测和跟踪系统中使用,因为它使得更容易检测每个对象的轮廓。
对于聚类的定义并没有普遍的定义:它真的取决于上下文,不同的算法将捕捉不同类型的聚类。一些算法寻找围绕特定点集中的实例,称为中心点。其他算法寻找连续的密集实例区域:这些聚类可以采用任何形状。一些算法是分层的,寻找聚类的聚类。等等。
在本节中,我们将介绍两种流行的聚类算法,k-均值和 DBSCAN,并探讨它们的一些应用,如非线性降维、半监督学习和异常检测。
k-均值
考虑在图 9-2 中表示的无标签数据集:您可以清楚地看到五个实例的聚类。k-均值算法是一种简单的算法,能够非常快速和高效地对这种数据集进行聚类,通常只需几次迭代。它是由贝尔实验室的斯图尔特·劳埃德(Stuart Lloyd)在 1957 年提出的,作为脉冲编码调制的技术,但直到 1982 年才在公司外部发表。在 1965 年,爱德华·W·福吉(Edward W. Forgy)几乎发表了相同的算法,因此k-均值有时被称为劳埃德-福吉算法。

图 9-2。由五个实例聚类组成的无标签数据集
让我们在这个数据集上训练一个k-均值聚类器。它将尝试找到每个聚类的中心,并将每个实例分配给最近的聚类:
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
X, y = make_blobs([...]) # make the blobs: y contains the cluster IDs, but we
# will not use them; that's what we want to predict
k = 5
kmeans = KMeans(n_clusters=k, random_state=42)
y_pred = kmeans.fit_predict(X)
请注意,您必须指定算法必须找到的聚类数k。在这个例子中,从数据看,k应该设置为 5 是相当明显的,但一般来说并不那么容易。我们将很快讨论这个问题。
每个实例将被分配到五个聚类中的一个。在聚类的上下文中,实例的标签是算法分配给该实例的聚类的索引;这不应与分类中使用的类标签混淆(请记住,聚类是一种无监督学习任务)。KMeans实例保留了它训练过的实例的预测标签,可以通过labels_实例变量获得:
>>> y_pred
array([4, 0, 1, ..., 2, 1, 0], dtype=int32)
>>> y_pred is kmeans.labels_
True
我们还可以看一下算法找到的五个中心点:
>>> kmeans.cluster_centers_
array([[-2.80389616, 1.80117999],
[ 0.20876306, 2.25551336],
[-2.79290307, 2.79641063],
[-1.46679593, 2.28585348],
[-2.80037642, 1.30082566]])
您可以轻松地将新实例分配给最接近的中心点的聚类:
>>> import numpy as np
>>> X_new = np.array([[0, 2], [3, 2], [-3, 3], [-3, 2.5]])
>>> kmeans.predict(X_new)
array([1, 1, 2, 2], dtype=int32)
如果绘制聚类的决策边界,您将得到一个 Voronoi 图:请参见图 9-3,其中每个中心点用 X 表示。

图 9-3。k-均值决策边界(Voronoi 图)
绝大多数实例明显被分配到了适当的聚类中,但有一些实例可能被错误标记,特别是在左上角聚类和中心聚类之间的边界附近。事实上,当聚类的直径差异很大时,k-均值算法的表现并不好,因为在将实例分配给聚类时,它只关心到中心点的距离。
与将每个实例分配到单个簇不同,即所谓的硬聚类,给每个实例分配每个簇的分数可能很有用,即所谓的软聚类。分数可以是实例与质心之间的距离或相似度分数(或亲和度),例如我们在第二章中使用的高斯径向基函数。在KMeans类中,transform()方法测量每个实例到每个质心的距离:
>>> kmeans.transform(X_new).round(2)
array([[2.81, 0.33, 2.9 , 1.49, 2.89],
[5.81, 2.8 , 5.85, 4.48, 5.84],
[1.21, 3.29, 0.29, 1.69, 1.71],
[0.73, 3.22, 0.36, 1.55, 1.22]])
在这个例子中,X_new中的第一个实例距离第一个质心约为 2.81,距离第二个质心约为 0.33,距离第三个质心约为 2.90,距离第四个质心约为 1.49,距离第五个质心约为 2.89。如果你有一个高维数据集,并以这种方式进行转换,你最终会得到一个k维的数据集:这种转换可以是一种非常有效的非线性降维技术。或者,你可以使用这些距离作为额外特征来训练另一个模型,就像第二章中那样。
k 均值算法
那么,算法是如何工作的呢?假设你已经得到了质心。你可以通过将每个实例分配到最接近的质心的簇中来轻松地为数据集中的所有实例打上标签。相反,如果你已经得到了所有实例的标签,你可以通过计算该簇中实例的平均值来轻松地找到每个簇的质心。但是你既没有标签也没有质心,那么你该如何继续呢?首先随机放置质心(例如,通过从数据集中随机选择k个实例并使用它们的位置作为质心)。然后给实例打标签,更新质心,给实例打标签,更新质心,依此类推,直到质心不再移动。该算法保证会在有限步数内收敛(通常非常小)。这是因为实例与最接近的质心之间的均方距离在每一步都只能减小,而且由于它不能为负,因此保证会收敛。
你可以在图 9-4 中看到算法的运行过程:质心被随机初始化(左上角),然后实例被标记(右上角),然后质心被更新(左中),实例被重新标记(右中),依此类推。正如你所看到的,在仅三次迭代中,算法已经达到了一个看似接近最优的聚类。
注意
该算法的计算复杂度通常与实例数m、簇数k和维度数n成线性关系。然而,这仅在数据具有聚类结构时才成立。如果没有,那么在最坏情况下,复杂度可能会随实例数呈指数增长。在实践中,这种情况很少发生,k-均值通常是最快的聚类算法之一。

图 9-4。k-均值算法
尽管算法保证会收敛,但它可能不会收敛到正确的解决方案(即可能会收敛到局部最优解):它是否这样做取决于质心初始化。如果在随机初始化步骤中不幸的话,算法可能会收敛到两种次优解决方案,如图 9-5 所示。

图 9-5。由于不幸的质心初始化而导致次优解决方案
让我们看看通过改进质心初始化方式来减轻这种风险的几种方法。
质心初始化方法
如果你大致知道质心应该在哪里(例如,如果你之前运行过另一个聚类算法),那么你可以将init超参数设置为包含质心列表的 NumPy 数组,并将n_init设置为1:
good_init = np.array([[-3, 3], [-3, 2], [-3, 1], [-1, 2], [0, 2]])
kmeans = KMeans(n_clusters=5, init=good_init, n_init=1, random_state=42)
kmeans.fit(X)
另一个解决方案是使用不同的随机初始化多次运行算法,并保留最佳解决方案。随机初始化的次数由n_init超参数控制:默认情况下等于10,这意味着当您调用fit()时,先前描述的整个算法会运行 10 次,Scikit-Learn 会保留最佳解决方案。但它究竟如何知道哪个解决方案最佳呢?它使用性能指标!该指标称为模型的惯性,它是实例与其最近质心之间的平方距离之和。对于左侧的模型,它大约等于 219.4,在图 9-5 中的右侧模型为 258.6,在图 9-3 中的模型仅为 211.6。KMeans类运行算法n_init次,并保留具有最低惯性的模型。在这个例子中,将选择图 9-3 中的模型(除非我们在n_init连续的随机初始化中非常不幸)。如果您感兴趣,可以通过inertia_实例变量访问模型的惯性:
>>> kmeans.inertia_
211.59853725816836
score()方法返回负惯性(它是负数,因为预测器的score()方法必须始终遵守 Scikit-Learn 的“分数越高越好”的规则:如果一个预测器比另一个更好,则其score()方法应返回更高的分数):
>>> kmeans.score(X)
-211.5985372581684
k-means 算法的一个重要改进k-means++是由 David Arthur 和 Sergei Vassilvitskii 在2006 年的一篇论文中提出的。他们引入了一个更智能的初始化步骤,倾向于选择彼此相距较远的质心,这一改进使k-means 算法更不可能收敛到次优解。该论文表明,为更智能的初始化步骤所需的额外计算是非常值得的,因为这使得可以大大减少运行算法以找到最佳解决方案的次数。k-means++初始化算法的工作方式如下:
-
从数据集中均匀随机选择一个质心c^((1))。
-
选择一个新的质心c((*i*)),以概率选择实例**x**((i)) Dx(i)2 / ∑j=1mDx(j)2的概率,其中 D(x((*i*)))是实例**x**((i))与已选择的最近质心之间的距离。这种概率分布确保距离已选择的质心更远的实例更有可能被选择为质心。
-
重复上一步,直到所有k个质心都被选择。
KMeans类默认使用此初始化方法。
加速的 k 均值和小批量 k 均值
另一个对k-means 算法的改进是由 Charles Elkan 在2003 年的一篇论文中提出的。在一些具有许多簇的大型数据集上,通过避免许多不必要的距离计算,可以加速算法。Elkan 通过利用三角不等式(即,直线始终是两点之间的最短距离^(4)并跟踪实例和质心之间的距离的下限和上限来实现这一点。但是,Elkan 的算法并不总是加速训练,有时甚至会显著减慢训练速度;这取决于数据集。但是,如果您想尝试一下,请设置algorithm="elkan"。
k-means 算法的另一个重要变体是由 David Sculley 在2010 年的一篇论文中提出的。⁵ 该算法不是在每次迭代中使用完整数据集,而是能够使用小批量数据,每次迭代时轻微移动质心。这加快了算法的速度(通常提高了三到四倍),并使其能够对不适合内存的大型数据集进行聚类。Scikit-Learn 在MiniBatchKMeans类中实现了这个算法,您可以像使用KMeans类一样使用它:
from sklearn.cluster import MiniBatchKMeans
minibatch_kmeans = MiniBatchKMeans(n_clusters=5, random_state=42)
minibatch_kmeans.fit(X)
如果数据集不适合内存,最简单的选择是使用memmap类,就像我们在第八章中对增量 PCA 所做的那样。或者,您可以一次传递一个小批量到partial_fit()方法,但这将需要更多的工作,因为您需要执行多次初始化并自行选择最佳的初始化。
尽管小批量k-means 算法比常规k-means 算法快得多,但其惯性通常略差一些。您可以在图 9-6 中看到这一点:左侧的图比较了在先前的五个斑点数据集上使用不同数量的簇k训练的小批量k-means 和常规k-means 模型的惯性。两条曲线之间的差异很小,但是可见的。在右侧的图中,您可以看到小批量k-means 在这个数据集上大约比常规k-means 快 3.5 倍。

图 9-6。小批量k-means 的惯性高于k-means(左侧),但速度更快(右侧),特别是当k增加时
寻找最佳簇的数量
到目前为止,我们将簇的数量k设置为 5,因为通过观察数据,很明显这是正确的簇数量。但通常情况下,要知道如何设置k并不那么容易,如果将其设置为错误的值,结果可能会非常糟糕。如您在图 9-7 中所见,对于这个数据集,将k设置为 3 或 8 会导致相当糟糕的模型。
您可能会认为您可以选择惯性最低的模型。不幸的是,事情并不那么简单。k=3 的惯性约为 653.2,远高于k=5(211.6)。但是对于k=8,惯性只有 119.1。当我们增加k时,惯性并不是一个好的性能指标,因为它会不断降低。事实上,簇越多,每个实例距离其最近的质心就越近,因此惯性就会越低。让我们将惯性作为k的函数绘制出来。当我们这样做时,曲线通常包含一个称为“拐点”的拐点(见图 9-8)。

图 9-7。簇数量的错误选择:当k太小时,独立的簇会合并在一起(左侧),当k太大时,一些簇会被切割成多个部分(右侧)

图 9-8。将惯性作为簇数量k的函数绘制出来
正如您所看到的,随着k增加到 4,惯性迅速下降,但随着继续增加k,下降速度变得更慢。这条曲线大致呈手臂形状,并且在k=4 处有一个拐点。因此,如果我们不知道更好的选择,我们可能会认为 4 是一个不错的选择:任何更低的值都会有戏剧性的效果,而任何更高的值都不会有太大帮助,我们可能只是无缘无故地将完全良好的簇一分为二。
选择最佳聚类数值的技术相当粗糙。一个更精确(但也更耗费计算资源)的方法是使用轮廓分数,它是所有实例的平均轮廓系数。实例的轮廓系数等于(b - a)/ max(a, b),其中a是同一簇中其他实例的平均距离(即平均簇内距离),b是最近簇的平均距离(即到下一个最近簇实例的平均距离,定义为最小化b的簇,不包括实例自己的簇)。轮廓系数的取值范围在-1 到+1 之间。接近+1 的系数意味着实例很好地位于自己的簇内,并远离其他簇,而接近 0 的系数意味着它靠近簇边界;最后,接近-1 的系数意味着实例可能被分配到错误的簇。
要计算轮廓分数,您可以使用 Scikit-Learn 的silhouette_score()函数,将数据集中的所有实例和它们被分配的标签传递给它:
>>> from sklearn.metrics import silhouette_score
>>> silhouette_score(X, kmeans.labels_)
0.655517642572828
让我们比较不同聚类数的轮廓分数(参见图 9-9)。

图 9-9. 使用轮廓分数选择聚类数k
正如您所看到的,这种可视化比之前的更丰富:虽然它确认k=4 是一个非常好的选择,但它也突出了k=5 也相当不错,比k=6 或 7 好得多。这在比较惯性时是看不到的。
当我们绘制每个实例的轮廓系数时,按照它们被分配的簇和系数值进行排序,可以获得更具信息量的可视化结果。这被称为轮廓图(参见图 9-10)。每个图包含一个刀形图形,表示一个簇。形状的高度表示簇中实例的数量,宽度代表簇中实例的轮廓系数排序(宽度越宽越好)。
垂直虚线代表每个聚类数的平均轮廓分数。当一个簇中的大多数实例的系数低于这个分数时(即如果许多实例停在虚线之前,停在左边),那么这个簇就相当糟糕,因为这意味着它的实例与其他簇太接近。在这里我们可以看到当k=3 或 6 时,我们得到了糟糕的簇。但是当k=4 或 5 时,簇看起来相当不错:大多数实例延伸到虚线右侧,接近 1.0。当k=4 时,索引为 1 的簇(从底部数第二个)相当大。当k=5 时,所有簇的大小相似。因此,尽管k=4 的整体轮廓分数略高于k=5,但使用k=5 似乎是个好主意,以获得大小相似的簇。

图 9-10. 分析不同k值的轮廓图
k 均值的限制
尽管 k 均值有许多优点,尤其是快速和可扩展,但并不完美。正如我们所看到的,需要多次运行算法以避免次优解,而且您需要指定聚类数,这可能会很麻烦。此外,当聚类具有不同大小、不同密度或非球形形状时,k 均值的表现并不好。例如,图 9-11 显示了 k 均值如何对包含三个椭圆形簇的数据集进行聚类,这些簇具有不同的维度、密度和方向。
正如您所看到的,这两种解决方案都不太好。左侧的解决方案更好,但仍然将中间簇的 25%切断并分配给右侧的簇。右侧的解决方案只是糟糕透顶,尽管其惯性更低。因此,根据数据的不同,不同的聚类算法可能表现更好。在这些类型的椭圆形簇上,高斯混合模型效果很好。

图 9-11。k-means 未能正确聚类这些椭圆形斑点
提示
在运行k-means 之前,对输入特征进行缩放很重要(请参阅第二章)。否则,聚类可能会被拉伸得很长,k-means 的性能会很差。缩放特征并不能保证所有聚类都是漂亮的球形,但通常有助于k-means。
现在让我们看看我们可以从聚类中受益的几种方式。我们将使用k-means,但请随意尝试其他聚类算法。
使用聚类进行图像分割
图像分割是将图像分割成多个段的任务。有几种变体:
-
在颜色分割中,具有相似颜色的像素被分配到同一段。在许多应用中,这已经足够了。例如,如果您想要分析卫星图像以测量某个区域的总森林面积,颜色分割可能就足够了。
-
在语义分割中,属于相同对象类型的所有像素都被分配到同一段。例如,在自动驾驶汽车的视觉系统中,所有属于行人图像的像素可能被分配到“行人”段(将包含所有行人的一个段)。
-
在实例分割中,属于同一独立对象的所有像素都分配给同一段。在这种情况下,每个行人将有一个不同的段。
今天在语义或实例分割方面的最新技术是基于卷积神经网络的复杂架构(请参阅第十四章)。在本章中,我们将专注于(简单得多的)颜色分割任务,使用k-means。
我们将首先导入 Pillow 包(Python Imaging Library 的继任者),然后使用它加载ladybug.png图像(请参见图 9-12 中左上角的图像),假设它位于filepath处:
>>> import PIL
>>> image = np.asarray(PIL.Image.open(filepath))
>>> image.shape
(533, 800, 3)
图像表示为 3D 数组。第一维的大小是高度;第二维是宽度;第三维是颜色通道的数量,在这种情况下是红色、绿色和蓝色(RGB)。换句话说,对于每个像素,有一个包含红色、绿色和蓝色强度的 3D 向量,取值范围为 0 到 255 的无符号 8 位整数。一些图像可能具有较少的通道(例如灰度图像,只有一个通道),而一些图像可能具有更多的通道(例如具有额外alpha 通道用于透明度的图像,或者卫星图像,通常包含用于额外光频率的通道(如红外线))。
以下代码将数组重塑为 RGB 颜色的长列表,然后使用k-means 将这些颜色聚类为八个簇。它创建一个segmented_img数组,其中包含每个像素的最近簇中心(即每个像素的簇的平均颜色),最后将此数组重塑为原始图像形状。第三行使用了高级 NumPy 索引;例如,如果kmeans_.labels_中的前 10 个标签等于 1,则segmented_img中的前 10 种颜色等于kmeans.cluster_centers_[1]:
X = image.reshape(-1, 3)
kmeans = KMeans(n_clusters=8, random_state=42).fit(X)
segmented_img = kmeans.cluster_centers_[kmeans.labels_]
segmented_img = segmented_img.reshape(image.shape)
这输出了图 9-12 右上方显示的图像。您可以尝试不同数量的簇,如图所示。当您使用少于八个簇时,请注意瓢虫鲜艳的红色未能获得自己的簇:它与环境中的颜色合并在一起。这是因为k-means 更喜欢相似大小的簇。瓢虫很小——比图像的其他部分小得多——所以即使它的颜色很鲜艳,k-means 也无法为其分配一个簇。

图 9-12. 使用k-means 进行图像分割,使用不同数量的颜色簇
这并不太难,对吧?现在让我们看看聚类的另一个应用。
使用聚类进行半监督学习
聚类的另一个用例是在半监督学习中,当我们有大量未标记的实例和很少带标签的实例时。在本节中,我们将使用数字数据集,这是一个简单的类似 MNIST 的数据集,包含 1,797 个灰度 8×8 图像,代表数字 0 到 9。首先,让我们加载并拆分数据集(已经洗牌):
from sklearn.datasets import load_digits
X_digits, y_digits = load_digits(return_X_y=True)
X_train, y_train = X_digits[:1400], y_digits[:1400]
X_test, y_test = X_digits[1400:], y_digits[1400:]
我们假装只有 50 个实例的标签。为了获得基准性能,让我们在这 50 个带标签的实例上训练一个逻辑回归模型:
from sklearn.linear_model import LogisticRegression
n_labeled = 50
log_reg = LogisticRegression(max_iter=10_000)
log_reg.fit(X_train[:n_labeled], y_train[:n_labeled])
然后我们可以在测试集上测量这个模型的准确率(请注意测试集必须带标签):
>>> log_reg.score(X_test, y_test)
0.7481108312342569
模型的准确率只有 74.8%。这并不好:实际上,如果您尝试在完整的训练集上训练模型,您会发现它将达到约 90.7%的准确率。让我们看看如何做得更好。首先,让我们将训练集聚类成 50 个簇。然后,对于每个簇,我们将找到距离质心最近的图像。我们将称这些图像为代表性图像:
k = 50
kmeans = KMeans(n_clusters=k, random_state=42)
X_digits_dist = kmeans.fit_transform(X_train)
representative_digit_idx = np.argmin(X_digits_dist, axis=0)
X_representative_digits = X_train[representative_digit_idx]
图 9-13 显示了 50 个代表性图像。

图 9-13. 五十个代表性数字图像(每个簇一个)
让我们看看每个图像并手动标记它们:
y_representative_digits = np.array([1, 3, 6, 0, 7, 9, 2, ..., 5, 1, 9, 9, 3, 7])
现在我们有一个只有 50 个带标签实例的数据集,但它们不是随机实例,而是每个实例都是其簇的代表性图像。让我们看看性能是否有所提高:
>>> log_reg = LogisticRegression(max_iter=10_000)
>>> log_reg.fit(X_representative_digits, y_representative_digits)
>>> log_reg.score(X_test, y_test)
0.8488664987405542
哇!我们的准确率从 74.8%跳升到 84.9%,尽管我们仍然只在 50 个实例上训练模型。由于标记实例通常成本高昂且繁琐,特别是当必须由专家手动完成时,将代表性实例标记而不仅仅是随机实例是一个好主意。
但也许我们可以再进一步:如果我们将标签传播到同一簇中的所有其他实例怎么办?这被称为标签传播:
y_train_propagated = np.empty(len(X_train), dtype=np.int64)
for i in range(k):
y_train_propagated[kmeans.labels_ == i] = y_representative_digits[i]
现在让我们再次训练模型并查看其性能:
>>> log_reg = LogisticRegression()
>>> log_reg.fit(X_train, y_train_propagated)
>>> log_reg.score(X_test, y_test)
0.8942065491183879
我们又获得了显著的准确率提升!让我们看看如果忽略距离其簇中心最远的 1%实例是否能做得更好:这应该消除一些异常值。以下代码首先计算每个实例到其最近簇中心的距离,然后对于每个簇,将 1%最大的距离设置为-1。最后,它创建一个不包含这些标记为-1 距离的实例的集合:
percentile_closest = 99
X_cluster_dist = X_digits_dist[np.arange(len(X_train)), kmeans.labels_]
for i in range(k):
in_cluster = (kmeans.labels_ == i)
cluster_dist = X_cluster_dist[in_cluster]
cutoff_distance = np.percentile(cluster_dist, percentile_closest)
above_cutoff = (X_cluster_dist > cutoff_distance)
X_cluster_dist[in_cluster & above_cutoff] = -1
partially_propagated = (X_cluster_dist != -1)
X_train_partially_propagated = X_train[partially_propagated]
y_train_partially_propagated = y_train_propagated[partially_propagated]
现在让我们再次在这部分传播的数据集上训练模型,看看我们能获得什么准确率:
>>> log_reg = LogisticRegression(max_iter=10_000)
>>> log_reg.fit(X_train_partially_propagated, y_train_partially_propagated)
>>> log_reg.score(X_test, y_test)
0.9093198992443325
很棒!只有 50 个带标签的实例(平均每类只有 5 个示例!)我们获得了 90.9%的准确率,实际上略高于我们在完全带标签的数字数据集上获得的性能(90.7%)。这在一定程度上要归功于我们删除了一些异常值,另一部分原因是传播的标签实际上相当不错——它们的准确率约为 97.5%,如下面的代码所示:
>>> (y_train_partially_propagated == y_train[partially_propagated]).mean()
0.9755555555555555
提示
Scikit-Learn 还提供了两个可以自动传播标签的类:sklearn.semi_supervised包中的LabelSpreading和LabelPropagation。这两个类构建了所有实例之间的相似性矩阵,并迭代地将标签从有标签的实例传播到相似的无标签实例。还有一个非常不同的类叫做SelfTrainingClassifier,在相同的包中:你给它一个基础分类器(比如RandomForestClassifier),它会在有标签的实例上训练它,然后用它来预测无标签样本的标签。然后,它会使用它最有信心的标签更新训练集,并重复这个训练和标记的过程,直到不能再添加标签为止。这些技术并非万能之策,但它们偶尔可以为你的模型提供一点提升。
在我们继续讨论高斯混合模型之前,让我们看一下 DBSCAN,这是另一种流行的聚类算法,它基于局部密度估计展示了一种非常不同的方法。这种方法允许算法识别任意形状的簇。
DBSCAN
带有噪声的基于密度的空间聚类应用(DBSCAN)算法将连续的高密度区域定义为簇。它的工作原理如下:
-
对于每个实例,算法计算距离它小于一个小距离ε(epsilon)的实例有多少个。这个区域被称为实例的ε-邻域。
-
如果一个实例在其ε-邻域中至少有
min_samples个实例(包括自身),那么它被视为核心实例。换句话说,核心实例是位于密集区域的实例。 -
所有在核心实例邻域中的实例都属于同一个簇。这个邻域可能包括其他核心实例;因此,一长串相邻的核心实例形成一个单一的簇。
-
任何不是核心实例且其邻域中没有核心实例的实例都被视为异常。
如果所有簇都被低密度区域很好地分隔开,这个算法就会很有效。Scikit-Learn 中的DBSCAN类使用起来就像你期望的那样简单。让我们在第五章中介绍的 moons 数据集上测试一下:
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=1000, noise=0.05)
dbscan = DBSCAN(eps=0.05, min_samples=5)
dbscan.fit(X)
现在所有实例的标签都可以在labels_实例变量中找到:
>>> dbscan.labels_
array([ 0, 2, -1, -1, 1, 0, 0, 0, 2, 5, [...], 3, 3, 4, 2, 6, 3])
请注意,一些实例的簇索引等于-1,这意味着它们被算法视为异常值。核心实例的索引可以在core_sample_indices_实例变量中找到,核心实例本身可以在components_实例变量中找到:
>>> dbscan.core_sample_indices_
array([ 0, 4, 5, 6, 7, 8, 10, 11, [...], 993, 995, 997, 998, 999])
>>> dbscan.components_
array([[-0.02137124, 0.40618608],
[-0.84192557, 0.53058695],
[...],
[ 0.79419406, 0.60777171]])
这种聚类在图 9-14 的左图中表示。正如你所看到的,它识别出了相当多的异常值,以及七个不同的簇。多么令人失望!幸运的是,如果我们通过增加eps到 0.2 来扩大每个实例的邻域,我们得到了右侧的聚类,看起来完美。让我们继续使用这个模型。

图 9-14。使用两个不同邻域半径的 DBSCAN 聚类
令人惊讶的是,DBSCAN类没有predict()方法,尽管它有一个fit_predict()方法。换句话说,它不能预测一个新实例属于哪个簇。这个决定是因为不同的分类算法对不同的任务可能更好,所以作者决定让用户选择使用哪个。此外,这并不难实现。例如,让我们训练一个KNeighborsClassifier:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=50)
knn.fit(dbscan.components_, dbscan.labels_[dbscan.core_sample_indices_])
现在,给定一些新实例,我们可以预测它们最有可能属于哪些簇,甚至为每个簇估计一个概率:
>>> X_new = np.array([[-0.5, 0], [0, 0.5], [1, -0.1], [2, 1]])
>>> knn.predict(X_new)
array([1, 0, 1, 0])
>>> knn.predict_proba(X_new)
array([[0.18, 0.82],
[1\. , 0\. ],
[0.12, 0.88],
[1\. , 0\. ]])
请注意,我们只在核心实例上训练了分类器,但我们也可以选择在所有实例上或除异常值外的所有实例上进行训练:这个选择取决于最终的任务。
决策边界在图 9-15 中表示(十字表示X_new中的四个实例)。请注意,由于训练集中没有异常值,分类器总是选择一个集群,即使该集群很远。很容易引入一个最大距离,这样远离两个集群的两个实例将被分类为异常值。要做到这一点,使用KNeighborsClassifier的kneighbors()方法。给定一组实例,它返回训练集中k个最近邻居的距离和索引(两个矩阵,每个有k列):
>>> y_dist, y_pred_idx = knn.kneighbors(X_new, n_neighbors=1)
>>> y_pred = dbscan.labels_[dbscan.core_sample_indices_][y_pred_idx]
>>> y_pred[y_dist > 0.2] = -1
>>> y_pred.ravel()
array([-1, 0, 1, -1])

图 9-15. 两个集群之间的决策边界
简而言之,DBSCAN 是一个非常简单但功能强大的算法,能够识别任意形状的任意数量的集群。它对异常值具有鲁棒性,只有两个超参数(eps和min_samples)。然而,如果集群之间的密度差异显著,或者某些集群周围没有足够低密度的区域,DBSCAN 可能无法正确捕捉所有集群。此外,它的计算复杂度大约为O(m²n),因此不适用于大型数据集。
提示
您可能还想尝试层次 DBSCAN(HDBSCAN),它在scikit-learn-contrib项目中实现,通常比 DBSCAN 更好地找到不同密度的集群。
其他聚类算法
Scikit-Learn 实现了几种更多的聚类算法,你应该看一看。我无法在这里详细介绍它们所有,但这里是一个简要概述:
凝聚聚类
从底向上构建一个集群的层次结构。想象许多微小的气泡漂浮在水面上,逐渐相互连接,直到形成一个大的气泡群。类似地,在每次迭代中,凝聚聚类将最近的一对集群连接起来(从单个实例开始)。如果你画出一棵树,每对合并的集群都有一个分支,你将得到一个二叉树的集群,其中叶子是单个实例。这种方法可以捕捉各种形状的集群;它还会生成一个灵活且信息丰富的集群树,而不是强迫你选择特定的集群规模,并且可以与任何成对距离一起使用。如果提供一个连接矩阵,它可以很好地扩展到大量实例,连接矩阵是一个稀疏的 m × m 矩阵,指示哪些实例对是邻居(例如,由 sklearn.neighbors.kneighbors_graph() 返回)。没有连接矩阵,该算法在大型数据集上的扩展性不佳。
BIRCH
平衡迭代减少和层次聚类(BIRCH)算法专门设计用于非常大的数据集,只要特征数量不太大(<20),它可能比批量k-means 更快,结果类似。在训练过程中,它构建一个树结构,包含足够的信息,可以快速将每个新实例分配到一个集群,而无需将所有实例存储在树中:这种方法允许它在处理大型数据集时使用有限的内存。
均值漂移
该算法首先在每个实例上放置一个圆圈;然后对于每个圆圈,计算其中所有实例的平均值,并将圆圈移动,使其位于平均值中心。接下来,迭代这个平移步骤,直到所有圆圈停止移动(即,直到它们每个都位于包含的实例的平均值上)。均值漂移将圆圈移动到更高密度的方向,直到每个圆圈找到局部密度最大值。最后,所有圆圈已经定居在同一位置(或足够接近)的实例被分配到同一个簇。均值漂移具有与 DBSCAN 相同的一些特性,例如它可以找到任意形状的任意数量的簇,它只有很少的超参数(只有一个——圆圈的半径,称为带宽),并且依赖于局部密度估计。但与 DBSCAN 不同的是,均值漂移在簇内密度变化时倾向于将簇切割成片。不幸的是,它的计算复杂度为O(m²n),因此不适用于大型数据集。
亲和传播
在这个算法中,实例之间反复交换消息,直到每个实例都选出另一个实例(或自己)来代表它。这些被选出的实例被称为典范。每个典范和所有选举它的实例形成一个簇。在现实生活中的政治中,你通常希望投票给一个观点与你相似的候选人,但你也希望他们赢得选举,所以你可能会选择一个你不完全同意的候选人,但他更受欢迎。你通常通过民意调查来评估受欢迎程度。亲和传播以类似的方式工作,它倾向于选择位于簇中心附近的典范,类似于k-means。但与k-means 不同的是,你不必提前选择簇的数量:它是在训练过程中确定的。此外,亲和传播可以很好地处理不同大小的簇。不幸的是,这个算法的计算复杂度为O(m²),因此不适用于大型数据集。
谱聚类
该算法使用实例之间的相似性矩阵,并从中创建一个低维嵌入(即,降低矩阵的维度),然后在这个低维空间中使用另一个聚类算法(Scikit-Learn 的实现使用k-means)。谱聚类可以捕捉复杂的簇结构,也可以用于切割图形(例如,识别社交网络上的朋友簇)。当实例数量较大时,它不会很好地扩展,并且当簇的大小差异很大时,它的表现也不好。
现在让我们深入研究高斯混合模型,它可以用于密度估计、聚类和异常检测。
高斯混合模型
高斯混合模型(GMM)是一个概率模型,假设实例是从几个高斯分布的混合中生成的,这些分布的参数是未知的。从单个高斯分布生成的所有实例形成一个簇,通常看起来像一个椭圆体。每个簇可以具有不同的椭圆形状、大小、密度和方向,就像图 9-11 中所示。当你观察一个实例时,你知道它是从高斯分布中生成的一个,但你不知道是哪一个,也不知道这些分布的参数是什么。
有几种 GMM 变体。在GaussianMixture类中实现的最简单的变体中,你必须事先知道高斯分布的数量k。假定数据集X是通过以下概率过程生成的:
-
对于每个实例,从k个簇中随机选择一个。选择第j个簇的概率是簇的权重ϕ^((j)).⁶ 选择第i个实例的簇的索引被记为z^((i)).
-
如果第i个实例被分配到第j个聚类(即z^((i)) = j),则该实例的位置x((*i*))是从具有均值**μ**((j))和协方差矩阵Σ((*j*))的高斯分布中随机抽样的。这表示**x**((i)) ~ 𝒩(μ^((j)), Σ^((j))).
那么,您可以用这样的模型做什么呢?嗯,给定数据集X,您通常会从估计权重ϕ和所有分布参数μ((1))到**μ**((k))和Σ((1))到**Σ**((k))开始。Scikit-Learn 的GaussianMixture类使这变得非常容易:
from sklearn.mixture import GaussianMixture
gm = GaussianMixture(n_components=3, n_init=10)
gm.fit(X)
让我们看看算法估计的参数:
>>> gm.weights_
array([0.39025715, 0.40007391, 0.20966893])
>>> gm.means_
array([[ 0.05131611, 0.07521837],
[-1.40763156, 1.42708225],
[ 3.39893794, 1.05928897]])
>>> gm.covariances_
array([[[ 0.68799922, 0.79606357],
[ 0.79606357, 1.21236106]],
[[ 0.63479409, 0.72970799],
[ 0.72970799, 1.1610351 ]],
[[ 1.14833585, -0.03256179],
[-0.03256179, 0.95490931]]])
太好了,运行得很顺利!事实上,三个聚类中有两个分别生成了 500 个实例,而第三个聚类只包含 250 个实例。因此,真实的聚类权重分别为 0.4、0.4 和 0.2,这大致是算法找到的。同样,真实的均值和协方差矩阵与算法找到的相当接近。但是如何实现的呢?这个类依赖于期望最大化(EM)算法,它与k-means 算法有许多相似之处:它也随机初始化聚类参数,然后重复两个步骤直到收敛,首先将实例分配给聚类(这称为期望步骤),然后更新聚类(这称为最大化步骤)。听起来很熟悉,对吧?在聚类的背景下,您可以将 EM 视为k-means 的一种泛化,它不仅找到聚类中心(μ((1))到**μ**((k))),还找到它们的大小、形状和方向(Σ((1))到**Σ**((k))),以及它们的相对权重(ϕ((1))到*ϕ*((k)))。不过,与k-means 不同,EM 使用软聚类分配,而不是硬分配。对于每个实例,在期望步骤中,算法根据当前的聚类参数估计它属于每个聚类的概率。然后,在最大化步骤中,每个聚类使用数据集中的所有实例进行更新,每个实例的权重由估计的属于该聚类的概率加权。这些概率称为聚类对实例的责任。在最大化步骤中,每个聚类的更新将主要受到它最负责的实例的影响。
警告
不幸的是,就像k-means 一样,EM 可能会收敛到较差的解决方案,因此需要多次运行,仅保留最佳解决方案。这就是为什么我们将n_init设置为 10。请注意:默认情况下,n_init设置为 1。
您可以检查算法是否收敛以及需要多少次迭代:
>>> gm.converged_
True
>>> gm.n_iter_
4
现在您已经估计了每个聚类的位置、大小、形状、方向和相对权重,模型可以轻松地将每个实例分配到最可能的聚类(硬聚类),或者估计它属于特定聚类的概率(软聚类)。只需使用predict()方法进行硬聚类,或者使用predict_proba()方法进行软聚类:
>>> gm.predict(X)
array([0, 0, 1, ..., 2, 2, 2])
>>> gm.predict_proba(X).round(3)
array([[0.977, 0\. , 0.023],
[0.983, 0.001, 0.016],
[0\. , 1\. , 0\. ],
...,
[0\. , 0\. , 1\. ],
[0\. , 0\. , 1\. ],
[0\. , 0\. , 1\. ]])
高斯混合模型是一种生成模型,这意味着您可以从中抽样新实例(请注意,它们按簇索引排序):
>>> X_new, y_new = gm.sample(6)
>>> X_new
array([[-0.86944074, -0.32767626],
[ 0.29836051, 0.28297011],
[-2.8014927 , -0.09047309],
[ 3.98203732, 1.49951491],
[ 3.81677148, 0.53095244],
[ 2.84104923, -0.73858639]])
>>> y_new
array([0, 0, 1, 2, 2, 2])
还可以估计模型在任何给定位置的密度。这是通过使用score_samples()方法实现的:对于给定的每个实例,该方法估计该位置处的概率密度函数(PDF)的对数。得分越高,密度越大:
>>> gm.score_samples(X).round(2)
array([-2.61, -3.57, -3.33, ..., -3.51, -4.4 , -3.81])
如果计算这些分数的指数,您将得到给定实例位置处 PDF 的值。这些不是概率,而是概率密度:它们可以取任何正值,而不仅仅是 0 到 1 之间的值。要估计实例将落入特定区域的概率,您需要在该区域上积分(如果在可能实例位置的整个空间上这样做,结果将为 1)。
图 9-16 显示了聚类均值、决策边界(虚线)和该模型的密度轮廓。

图 9-16. 训练的高斯混合模型的聚类均值、决策边界和密度轮廓
太棒了!算法显然找到了一个很好的解决方案。当然,我们通过使用一组二维高斯分布生成数据使其任务变得容易(不幸的是,现实生活中的数据并不总是如此高斯和低维)。我们还给出了正确的聚类数。当维度很多、聚类很多或实例很少时,EM 可能会难以收敛到最佳解决方案。您可能需要通过限制算法需要学习的参数数量来降低任务的难度。一种方法是限制聚类可以具有的形状和方向的范围。这可以通过对协方差矩阵施加约束来实现。为此,请将covariance_type超参数设置为以下值之一:
"spherical"
所有聚类必须是球形的,但它们可以具有不同的直径(即,不同的方差)。
"diag"
聚类可以采用任何椭球形状的任何大小,但椭球体的轴必须与坐标轴平行(即,协方差矩阵必须是对角线的)。
"tied"
所有聚类必须具有相同的椭球形状、大小和方向(即,所有聚类共享相同的协方差矩阵)。
默认情况下,covariance_type等于"full",这意味着每个聚类可以采用任何形状、大小和方向(它有自己的无约束协方差矩阵)。图 9-17 显示了当covariance_type设置为"tied"或"spherical"时 EM 算法找到的解决方案。

图 9-17. 绑定聚类(左)和球形聚类(右)的高斯混合模型
注意
训练GaussianMixture模型的计算复杂度取决于实例数m、维度数n、聚类数k以及协方差矩阵的约束。如果covariance_type为"spherical"或"diag",则为O(kmn),假设数据具有聚类结构。如果covariance_type为"tied"或"full",则为O(kmn² + kn³),因此不适用于大量特征。
高斯混合模型也可以用于异常检测。我们将在下一节中看到如何使用。
使用高斯混合模型进行异常检测
使用高斯混合模型进行异常检测非常简单:位于低密度区域的任何实例都可以被视为异常。您必须定义要使用的密度阈值。例如,在一个试图检测有缺陷产品的制造公司中,有缺陷产品的比例通常是众所周知的。假设等于 2%。然后,您将密度阈值设置为导致有 2%的实例位于低于该阈值密度区域的值。如果您注意到您得到了太多的假阳性(即被标记为有缺陷的完全良好产品),您可以降低阈值。相反,如果您有太多的假阴性(即系统未标记为有缺陷的有缺陷产品),您可以增加阈值。这是通常的精确度/召回率权衡(参见第三章)。以下是使用第四百分位数最低密度作为阈值(即,大约 4%的实例将被标记为异常)来识别异常值的方法:
densities = gm.score_samples(X)
density_threshold = np.percentile(densities, 2)
anomalies = X[densities < density_threshold]
图 9-18 将这些异常值表示为星号。
一个密切相关的任务是新颖性检测:它与异常检测不同之处在于,算法被假定在一个未被异常值污染的“干净”数据集上进行训练,而异常检测则不做出这种假设。事实上,异常值检测通常用于清理数据集。
提示
高斯混合模型尝试拟合所有数据,包括异常值;如果异常值过多,这将使模型对“正常性”的看法产生偏见,一些异常值可能会被错误地视为正常值。如果发生这种情况,您可以尝试拟合模型一次,使用它来检测并删除最极端的异常值,然后再次在清理后的数据集上拟合模型。另一种方法是使用鲁棒协方差估计方法(参见EllipticEnvelope类)。

图 9-18. 使用高斯混合模型进行异常检测
就像k-means 一样,GaussianMixture算法要求您指定聚类数。那么如何找到那个数字呢?
选择聚类数
使用k-means,您可以使用惯性或轮廓分数来选择适当的聚类数。但是对于高斯混合,当聚类不是球形或大小不同时,使用这些度量是不可靠的。相反,您可以尝试找到最小化理论信息准则的模型,例如贝叶斯信息准则(BIC)或阿凯克信息准则(AIC),在方程 9-1 中定义。
方程 9-1. 贝叶斯信息准则(BIC)和阿凯克信息准则(AIC)
B I C = log ( m ) p - 2 log ( L ^ ) A I C = 2 p - 2 log ( L ^ )
在这些方程中:
-
m 一如既往是实例的数量。
-
p 是模型学习的参数数量。
-
L^ 是模型的似然函数的最大化值。
BIC 和 AIC 都惩罚具有更多要学习的参数(例如更多聚类)的模型,并奖励拟合数据良好的模型。它们通常选择相同的模型。当它们不同时,BIC 选择的模型往往比 AIC 选择的模型更简单(参数更少),但往往不那么适合数据(特别是对于更大的数据集)。
要计算 BIC 和 AIC,请调用bic()和aic()方法:
>>> gm.bic(X)
8189.747000497186
>>> gm.aic(X)
8102.521720382148
图 9-20 显示了不同聚类数k的 BIC。如您所见,当k=3 时,BIC 和 AIC 都最低,因此这很可能是最佳选择。

图 9-20. 不同聚类数k的 AIC 和 BIC
贝叶斯高斯混合模型
与手动搜索最佳聚类数不同,您可以使用BayesianGaussianMixture类,该类能够将权重等于(或接近)零的不必要聚类。将聚类数n_components设置为一个您有充分理由认为大于最佳聚类数的值(这假设对问题有一些最小的了解),算法将自动消除不必要的聚类。例如,让我们将聚类数设置为 10,看看会发生什么:
>>> from sklearn.mixture import BayesianGaussianMixture
>>> bgm = BayesianGaussianMixture(n_components=10, n_init=10, random_state=42)
>>> bgm.fit(X)
>>> bgm.weights_.round(2)
array([0.4 , 0.21, 0.4 , 0\. , 0\. , 0\. , 0\. , 0\. , 0\. , 0\. ])
完美:该算法自动检测到只需要三个簇,并且得到的簇几乎与图 9-16 中的簇相同。
关于高斯混合模型的最后一点说明:尽管它们在具有椭圆形状的簇上表现很好,但在形状非常不同的簇上表现不佳。例如,让我们看看如果我们使用贝叶斯高斯混合模型来对月亮数据集进行聚类会发生什么(参见图 9-21)。
糟糕!该算法拼命搜索椭圆体,因此找到了八个不同的簇,而不是两个。密度估计并不太糟糕,因此这个模型可能可以用于异常检测,但它未能识别出这两个月亮。为了结束本章,让我们快速看一下几种能够处理任意形状簇的算法。

图 9-21. 将高斯混合拟合到非椭圆形簇
其他用于异常和新颖性检测的算法
Scikit-Learn 实现了其他专门用于异常检测或新颖性检测的算法:
快速 MCD(最小协方差行列式)
由EllipticEnvelope类实现,该算法对于异常值检测很有用,特别是用于清理数据集。它假设正常实例(内点)是从单个高斯分布(而不是混合)生成的。它还假设数据集中混入了未从该高斯分布生成的异常值。当算法估计高斯分布的参数(即围绕内点的椭圆包络的形状)时,它会小心地忽略那些最有可能是异常值的实例。这种技术提供了对椭圆包络更好的估计,从而使算法更好地识别异常值。
孤立森林
这是一种用于异常值检测的高效算法,特别适用于高维数据集。该算法构建了一个随机森林,其中每棵决策树都是随机生长的:在每个节点,它随机选择一个特征,然后选择一个随机阈值(在最小值和最大值之间)来将数据集分成两部分。数据集逐渐以这种方式被切割成片段,直到所有实例最终与其他实例隔离开来。异常通常远离其他实例,因此平均而言(在所有决策树中),它们往往比正常实例更快地被隔离。
局部离群因子(LOF)
这个算法也适用于异常值检测。它比较了给定实例周围的实例密度与其邻居周围的密度。异常通常比其k个最近邻更孤立。
一类 SVM
这个算法更适合用于新颖性检测。回想一下,一个核化的 SVM 分类器通过首先(隐式地)将所有实例映射到高维空间,然后在这个高维空间中使用线性 SVM 分类器来分离两个类别(参见第五章)。由于我们只有一个类的实例,一类 SVM 算法尝试在高维空间中将实例与原点分离。在原始空间中,这将对应于找到一个包含所有实例的小区域。如果一个新实例不在这个区域内,那么它就是异常值。有一些需要调整的超参数:用于核化 SVM 的通常超参数,以及一个边际超参数,对应于新实例被错误地认为是新颖的概率,而实际上是正常的。它的效果很好,特别是对于高维数据集,但像所有的 SVM 一样,它不适用于大型数据集。
PCA 和其他具有inverse_transform()方法的降维技术
如果将正常实例的重建误差与异常的重建误差进行比较,后者通常会大得多。这是一种简单而通常相当有效的异常检测方法(请参阅本章的练习以获取示例)。
练习
-
你如何定义聚类?你能说出几种聚类算法吗?
-
聚类算法的主要应用有哪些?
-
描述两种在使用k-means 时选择正确聚类数量的技术。
-
什么是标签传播?为什么要实现它,以及如何实现?
-
你能说出两种可以扩展到大型数据集的聚类算法吗?还有两种寻找高密度区域的算法吗?
-
你能想到一个使用主动学习会有用的用例吗?你会如何实现它?
-
异常检测和新颖性检测之间有什么区别?
-
什么是高斯混合模型?可以用它来做什么任务?
-
你能说出使用高斯混合模型时找到正确聚类数量的两种技术吗?
-
经典的 Olivetti 人脸数据集包含 400 张灰度 64×64 像素的人脸图像。每个图像被展平为大小为 4,096 的 1D 向量。共有 40 个不同的人被拍摄(每人 10 次),通常的任务是训练一个模型,可以预测每张图片中代表的是哪个人。使用
sklearn.datasets.fetch_olivetti_faces()函数加载数据集,然后将其分为训练集、验证集和测试集(注意数据集已经在 0 到 1 之间缩放)。由于数据集相当小,您可能希望使用分层抽样来确保每个集合中每个人的图像数量相同。接下来,使用k-means 对图像进行聚类,并确保有一个良好数量的聚类(使用本章讨论的技术之一)。可视化聚类:您是否在每个聚类中看到相似的面孔? -
继续使用 Olivetti 人脸数据集,训练一个分类器来预测每张图片中代表的是哪个人,并在验证集上评估它。接下来,使用k-means 作为降维工具,并在减少的集合上训练一个分类器。寻找能让分类器获得最佳性能的聚类数量:你能达到什么性能?如果将减少集合的特征附加到原始特征上(再次搜索最佳聚类数量),会怎样?
-
在 Olivetti 人脸数据集上训练一个高斯混合模型。为了加快算法速度,您可能需要降低数据集的维度(例如,使用 PCA,保留 99%的方差)。使用模型生成一些新的面孔(使用
sample()方法),并可视化它们(如果使用了 PCA,您需要使用其inverse_transform()方法)。尝试修改一些图像(例如旋转、翻转、变暗)并查看模型是否能检测到异常(即,比较正常图像和异常的score_samples()方法的输出)。 -
一些降维技术也可以用于异常检测。例如,取 Olivetti 人脸数据集并使用 PCA 进行降维,保留 99%的方差。然后计算每个图像的重建误差。接下来,取出前面练习中构建的一些修改后的图像,并查看它们的重建误差:注意它有多大。如果绘制一个重建图像,你会看到原因:它试图重建一个正常的脸。
这些练习的解决方案可在本章笔记本的末尾找到,网址为https://homl.info/colab3。
¹ 斯图尔特·P·劳埃德,“PCM 中的最小二乘量化”,IEEE 信息理论交易 28, no. 2(1982):129–137。
² 大卫·阿瑟和谢尔盖·瓦西利维茨基,“k-Means++: 小心播种的优势”,第 18 届 ACM-SIAM 离散算法研讨会论文集(2007 年):1027–1035。
³ 查尔斯·埃尔坎,“使用三角不等式加速 k 均值”,第 20 届国际机器学习会议论文集(2003 年):147–153。
⁴ 三角不等式是 AC ≤ AB + BC,其中 A、B 和 C 是三个点,AB、AC 和 BC 是这些点之间的距离。
⁵ 大卫·斯卡利,“Web 规模的 K 均值聚类”,第 19 届国际万维网会议论文集(2010 年):1177–1178。
⁶ Phi(ϕ或φ)是希腊字母表的第 21 个字母。