1.Flume介绍
Flume 是一种分布式、可靠且可用的服务,用于高效收集、聚合和移动大量日志数据。它具有基于流数据流的简单而灵活的架构。它具有鲁棒性和容错性,具有可调的可靠性机制和许多故障转移和恢复机制。它使用简单的可扩展数据模型,允许在线分析应用程序。
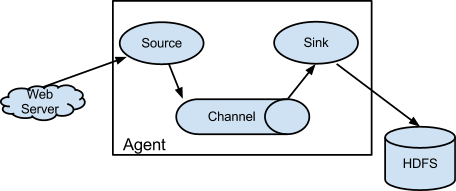
Flume是一个即装即用的传输组件,下载安装后配置conf文件即可使用,非常方便。支持文件存储压缩、多进程传输、动态修改配置文件、负载均衡和错误恢复等。
2.场景分析
在使用flume将kafka中数据流保存到HDFS中时,由于数据量过大,2g~5g/min,数据传输慢,主要瓶颈在于为hdfs保存:采取的解决办法主要为:
- 将file channel 调整为 memory channel,降低本地磁盘压力
- 将sink单进程调整为多进程
💡
多sink可以直接按常规配置,这样的话每个sink会启动一个sinkrunner,相当于每个线程一个sink,互不干扰,负载均衡是通过channel实现的,效率会提高为n倍,如果在此基础上加入sinkgroup,则sinkgroup会启动一个sinkrunner,就是单线程,sinkgroup从channel中读取数据,然后分发到下面挂载的sink中,效率和单sink一样,没有提高,但是可以实现两个sink的负载均衡或者热备模式。
3.问题解决
配置文件
#定义组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1 k2
#配置source
a1.sources.r1.type= org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 2000
a1.sources.r1.kafka.consumer.group.id= xxx
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = xxx:9092
a1.sources.r1.kafka.topics = xxx,xxxx
a1.sources.r1.kafka.consumer.auto.offset.reset = latest
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type =xxxx$Builder
#memory channel
a1.channels.c1.type = memory
#channel的event个数
a1.channels.c1.capacity = 20000
#事务event个数
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 2147483648
#配置channel
#a1.channels.c1.type = file
#a1.channels.c1.checkpointDir =/data/xxx
#a1.channels.c1.dataDirs = /data/module/xxx
#a1.channels.c1.maxFileSize = 2147483648
#a1.channels.c1.capacity = 2000000
#a1.channels.c1.transactionCapacity=20000
#a1.channels.c1.keep-alive = 6
#a1.chhannels.c1.checkpointInterval=60000
#a1.minimumRequirdSpace=26214400
#配置sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path =/hadoop/dm_dw/tmp_data/log/%{table}/%Y%m%d/%H
a1.sinks.k1.hdfs.filePrefix = log1
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 360
a1.sinks.k1.hdfs.rollSize = 1174405120
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.batchSize=3000
#控制输出文件类型
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
#配置sink2
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path =/hadoop/dm_dw/tmp_data/log/%{table}/%Y%m%d/%H
a1.sinks.k2.hdfs.filePrefix = log2
a1.sinks.k2.hdfs.round = false
a1.sinks.k2.hdfs.rollInterval = 360
a1.sinks.k2.hdfs.rollSize = 1174405120
a1.sinks.k2.hdfs.rollCount = 0
a1.sinks.k2.hdfs.batchSize=3000
#控制输出文件类型
a1.sinks.k2.hdfs.fileType = CompressedStream
a1.sinks.k2.hdfs.codeC = gzip
#组装
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
#k1.batchSize+k2.batchSize < c1.capacity
启动命令
nohup /data/module/flume-1.9.0/bin/flume-ng agent -Xms1024m -Xmx2048m -n a1 -c /data/module/flume-1.9.0/conf -f /data/module/flume-1.9.0/job/test.conf -Dflume.monitoring.type=http -Dflume.monitoring.port=36001 >/dev/null 2>&1 &