文章目录
- MySQL如何定位慢查询
- 找到了这个执行慢的SQL语句,如何分析
- MySQL的引擎
- InnoDB
- MyISAM
- 索引
- 什么是索引?
- 索引的优缺点
- 索引底层数据结构
- 索引的分类
- MySQL超大分页怎么处理
- 什么是最左匹配原则
- 创建索引的原则
- 索引失效的场景
- 事务
- 什么是事务?
- 隔离性中的不同隔离级别
- 事务实现的原理
- 隔离级别的实现原理(MVCC)
- MySQL中的锁机制
- SQL优化
- 表的设计优化
- SQL语句优化
- 主从复制,读写分离
- 主从同步原理
- 分库分表
MySQL如何定位慢查询
回答这个问题首先一定要结合业务场景(我们当时有一个接口测试时候响应非常慢,压测大概5秒钟)
可以使用开源工具:阿尔萨斯(Arthas)、普罗米修斯(Prometheus)、Skywalking
- SkyWalking:在这个监控中会有相应的指标的数据,可以实时查看接口的情况,并且对接口的响应情况进行了排序,访问越慢的接口会排在前面,当知道哪个接口访问的比较慢,在Skywalking中有一个追踪的功能,可以详细查看接口的执行情况,这个接口在什么阶段耗时多久可以非常清晰的呈现出来,其中也包含了SQL的执行和耗时,如果真的是某个SQL执行比较耗时就可以迅速定位哪个SQL耗时比较久,这个就是使用工具的方式定位慢查询。
- 第二种是使用MySQL自带的慢日志,慢查询日志记录了所有执行时间超过指定参数(long_quary_time,单位s,默认10)的所有SQL语句的日志,如果要开启慢日志,就要在MySQL的配置文件(/etc/my.cnf)中配置以下信息
 - 一般在项目中设置执行时间2秒,如果有SQL语句的执行时间超过2秒就会记录在localhost-show.log日志文件中。
- 一般在项目中设置执行时间2秒,如果有SQL语句的执行时间超过2秒就会记录在localhost-show.log日志文件中。
找到了这个执行慢的SQL语句,如何分析
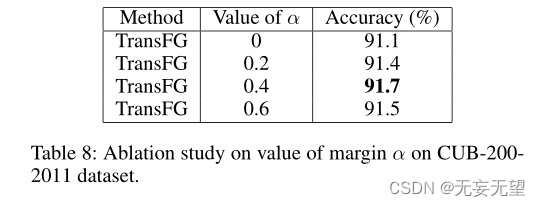
可以使用explain或者desc来获取MySQL如何执行select语句的信息。其中可以查询到这个SQL语句执行过程中的一些字段。 主要是通过key和key_len来进行判断是否可能会命中索引。
- possible_key:这条SQL语句在执行过程中可能使用到的索引。
- key:当前SQL实际命中的索引。
- key_len:当前使用到的索引实际占用的大小。
- Extra:额外的优化建议,如果出现Using index condition这种情况,说明索引的使用是有优化的空间。
- type:SQL连接的类型,通过type可以判断这条SQL编写的好坏,性能由好到坏分为NULL、system、const、eq_ref、ref、range、index、all。如果这条SQL类型index或all那么这条SQL就需要进行优化了。
- system:查询系统中的表。
- const:根据主键查询。
- eq_ref:逐渐索引查询或唯一索引查询。
- ref:索引查询。
- range:范围查询。
- index:索引树扫描。
- all:全盘扫描。
MySQL的引擎
MySQL的默认存储引擎是InnoDB,并且所有的存储引擎中只有InnoDB是事务性存储引擎。
InnoDB
InnoDB是MySQL的默认存储引擎,支持ACID事务,支持行级锁,外键约束等特性。
MyISAM是MySQL的另一种常见的存储引擎,具有较低的存储空间和内存消耗,适用于大量读操作的场景。然而,MyISAM不支持事务、行级锁和外键约束,因此在并发写入和数据完整性方面有一定的限制。主要用户查询多,增删改较少的场景。
Memory引擎将数据存储在内存中,适用于对性能要求较高的读操作,但是在服务器重启或崩溃时数据会丢失。它不支持事务、行级锁和外键约束。
优点: InnoDB是事务型存储引擎,它支持ACID特性,支持行级锁(一个事务对某行数据操作时,只会锁定某一行数据,不锁定其他行,效率高),提供了更好的MVCC机制,支持外键约束,支持缓存,支持全文索引。
缺点: 相较于MyISAM,InnoDB的存储和管理需要更多的内存和磁盘空间,同时也对CPU的要求较高。
MyISAM
优点: MyISAM简单易于管理,支持表锁(进行dml操作时会锁定整张表),主要用户查询多,增删改较少的场景。支持全文索引,存储表的总行数。
缺点: MyISAM不支持事务和行级锁,不支持主外键
总结
- InnoDB 支持行级别的锁粒度,MyISAM 不支持,只支持表级别的锁粒度。
- MyISAM 不提供事务支持。InnoDB 提供事务支持,实现了 SQL 标准定义了四个隔离级别。
- MyISAM 不支持外键,而 InnoDB 支持。
- MyISAM 不支持 MVCC,而 InnoDB 支持。
- 虽然 MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是两者的实现方式不太一样。
- MyISAM 不支持数据库异常崩溃后的安全恢复,而 InnoDB 支持。
- InnoDB 的性能比 MyISAM 更强大。
索引
什么是索引?
索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。它出现的作用就是为了加快查询效率。
索引的作用就相当于书的目录。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
索引的优缺点
优点:
- 使用索引可以大大加快 数据的检索速度(大大减少检索的数据量), 这也是创建索引的最主要的原因。
- 提高数据库检索效率,降低数据库的IO成本(不需要全表扫描)。
- 通过索引列对数据进行排序,降低数据排序成本,降低了CPU的消耗。
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
缺点:
- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
- 索引需要使用物理文件存储,也会耗费一定空间。
大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
索引底层数据结构
常见的索引结构有: B 树, B+树 和 Hash。在 MySQL 中,无论是 Innodb 还是 MyIsam,都使用了 B+树作为索引结构。B+树索引按照索引列的值进行排序,并将数据分层存储在索引树的节点中,这样可以通过比较索引值,快速定位到符合条件的数据行。
为什么不使用红黑树呢,红黑树是平衡的二叉树,也是能够稳定查找数据。但是红黑树是二叉树,每个节点最多只能两个孩子节点,所以当某个数据库表中的数据非常大的时候,红黑树将非常的高,查找效率也会不大。B+树是多叉树,阶数更多,路径更短。
数据库的索引和数据都是存储在硬盘中的,我们可以把读取一个节点当作一次批判IO操作。B+树存储千万级的数据只需要3-4层高度就可以满足,着意味着千万级的表查询目标数据最多需要3-4次磁盘IO,所以相较于B树和红黑树磊说,磁盘读写代价更低,查询效率高。
B+和B,B+树旨在叶子节点存储数据,而B树非叶子节点也要存储数据,所以B+树的单个节点的数据量更小,在相同的磁盘IO次数下,就能查询更多的节点。还有B+树叶子节点采用的是双链表结构,适合MySQL中常见的基于范围的顺序查找,B树在这一点是无法做到的。
B+和Hash,Hash在做等职查询的时候效率非常快,搜索复杂度仅为O(1),但是Hash表不适合做范围查询,它更适合做等值的查询,这也是B+树索引要比Hash表索引有更广泛适用场景的原因。
索引的分类
底层存储方式:
聚簇索引:所查即所得,找到了索引就是找到了数据,创建原则就是有主键就默认主键。数据与索引是放在一块的,B+树的叶子节点存放了整行数据,并且有且只有一个。
非聚簇索引(二级索引):索引和数据是分离的,B+树的叶子节点存储的是对应的主键,需要根据主键,再次回表查询,在MyISAM引擎中,除了主键列,其他都是非聚簇索引。
回表查询:通过二级索引找到对应的主键值,然后通过主键去聚簇索引中查找整行数据,这个过程就是回表。
判断聚簇索引和非聚簇索引的方法

按照应用维度分:
主键索引:查询加速,列值唯一(不能为NULL),表中只有一个
唯一索引:查询加速,列值唯一
覆盖索引: 查询使用了索引,返回的列中必须在索引中全部能找见。使用id查询,直接走聚集索引查询,一次可以查询到所有的数据,性能高。如果返回的列中没有创建索引,就会触发回表查询,所以在平时的开发中尽量避免使用select*。
联合索引(聚集索引):多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
全文索引:对文本的内容进行分词,与其他索引类型不同,全文索引并不存储整个字符串的值,而是存储关键字
MySQL超大分页怎么处理
超大分页一般是在数据量比较大的时候,我们使用limit分页查询,并且需要对数据进行排序,这个时候效率就很低,我们可以采用覆盖索引和子查询来解决。先分页查询数据的id字段,确定了id之后,再用子查询来过滤,只查询这个id列表中的数据就可以了,因为查询id的时候走的是覆盖索引,所以效率会提升很多。
什么是最左匹配原则
创建索引的原则
哪些情况创建索引
- 针对数据量大,查询比较频繁的表建立索引。(单表数据超过10万数据)
- 频繁作为查询条件的字段应该创建索引(条件where、排序order by、分组group by后面的语句)
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率也就越高。
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
- 要控制索引创建的数量,索引并不是越多越好,索引越多,维护索引所需的代价就约大,而且还会影响增删改的效率。
哪些情况不建议创建索引
- 表记录太少
- 经常增删改的表,提高了查询速度,同时降低了更新表的速度
- where条件里用不到的字段
- 数据重复且分布均匀的表字段
索引失效的场景
- 违反最左前缀法则,最左前缀法则就是如果索引了多个列,查询的话就要从索引的最左前列开始,并且不跳过索引中间的列,如果直接使用右边的列索引,或者跳过中间的列索引进行查询(跳之前的索引没有失效),索引就会失效。
- 范围查询右边的列索引会失效。
- 在索引列上进行运算操作。
- 字符串不加单引号(类型转换)。
- 以%开头的Like模糊查询,索引失效,单结尾不会失效。
事务
什么是事务?
事务就是逻辑上的一组操作,在同一个事务中,如果有多条sql语句执行,要么都执行,要么都不执行。
关系型数据库都有ACID的特点
A(原子性)、C(一致性)、I(隔离性)、D(持久性)
原子性:事务是一个不可分割的工作单位,事务的中间操作要么全部完成,要么全部不做,不可能停滞在中间环节。
隔离性:并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的
持久性:事务一旦提交,数据就持久保存在硬盘中
一致性:执行事务前后,数据保持一致,比如转账,不管成功与否,转账人与收账人总金额保持不变
只有保证了事务的持久性、原子性、隔离性之后,一致性才能得到保障。
隔离性中的不同隔离级别
查看隔离级别
SELECT @@global.transaction_isolation,@@transaction_isolation;
设置隔离级别
-- 设置左边的
SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
-- 设置右边的
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
读未提交:一个事务可以读取到另一个事务未提交的数据,这会带来脏读(垃圾数据,因为A事务可能会回滚),幻读,不可重复读问题,将隔离级别改为读已提交,可以解决脏读问题。
读已提交:一个事务只能读取另一个事务已经提交的数据,其避免了脏读,但仍然存在不可重复读和幻读问题
不可重复度: A事务中对数据库进行了两次查询,在两次查询中,B事务修改了数据库中的数据,导致A事务中两次查询的数据不同,这就是不可重复度
可重复读:同一个事务中多次读取相同的数据返回的结果是一样的,可以避免脏读和不可重复读,但可能会导致幻读。
幻读: 可重复读隔离级别—>一个事务查询一个范围内的数据时,另一个并发事务向这个范围内添加了一个新的数据,当之间的事务再次查询这个范围的数据时,就会发现之前没有的记录,这就是幻读。
串行化:最高的隔离级别,事务串行执行,事务不存在并发执行,可以避免脏读、不可重复读和幻读,但是效率低下.
事务实现的原理

在MySQL中提供了两种概念,一个缓冲池(buffer pool),一个数据页(page)。
- 缓冲池:主内存中的一个区域,里面可以缓存磁盘中经常操作的真实数据,在执行增删改查操作时,先操作缓冲池中的数据(若缓冲池没有数据,则先从磁盘加载并缓存),以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度。
- 数据页:是InnoDB存储引擎磁盘管理的最小单位,每个页的大小默认为16KB。页中存储的是行数据。
- redolog:内存中缓冲池中存储的页还没有同步磁盘中这个页就是一个脏页,只有将这个脏页中的数据同步到磁盘中数据才能真正算是持久化,这是后如果服务器宕机,就会造成数据的丢失。
- MySQL中引入了一个日志文件就是redolog,重做日志,记录的是事务提交时数据页的物理修改,是用来实现事务的持久性的。redolog主要分为两部分,重做日志缓冲(redolog buffer)和重做日志文件(redolog file),前者在内存中,后者在磁盘中并有两份文件,当事务提交之后会把所有修改的信息都存到该日志文件中,用于刷新脏页到磁盘过程中发生错误,进行数据恢复时使用。
- 如果直接使用buffer pool也是可以的,但是会有严重的性能问题。当一个事务中有大量的update操作,在保存数据到磁盘过程中是随机的磁盘IO。而redolog在数据同步过程中是顺序的磁盘IO,日志文件都是追加。这种机制就叫做WAL(Write-Ahead Logging)。
- undolog:用来保证事务的原子性和一致性,主要提供回滚和MVCC。
- 回滚:undolog里面记录的是逻辑日志,记录的都是执行过程操作相反的操作,当事务回滚的时候能撤销所有已经执行的sql语句。
InnoDB存储引擎提供了两种事务日志,redolog(重做日志)和undolog(回滚日志),redolog用于保证事务持久性,undolog则是事务原子性和一致性实现的。
**原子性的实现:**当事务回滚时能撤销所有已执行的sql语句。这个操作依赖的时undolog日志,undolog属于逻辑日志,里面记录的都是执行过所有操作的相反操作,用于回滚后将已执行的sql语句进行撤销。
**持久性的实现:**redolog叫做重做日志,用于记录事务中所有的修改操作,包括修改前和修改后的数据,这样即使系统崩溃,这些修改也不会丢失,系统恢复后,MySQL可以读取日志,重新执行这些操作。
隔离级别的实现原理(MVCC)
多版本并发控制 Multi-Version Concurrent Control,是MySQL提高性能的一种方式,就是配合undolog使事务可以并发执行。
读未提交: 没有特殊的并发控制机制,读操作不会获取任何锁,在读取数据之前不会进行任何检查。
读已提交: 读已提交又称当前读,每次读的时候都会给版本链拍照,所以读到的数据都是最新的(已提交)。这是通过在读取数据时加上共享锁,然后在读取完成后立即释放锁来实现的。
可重复读: 快照读使用行级锁或快照隔离,当事务开始之后,第一次读取会给版本拍照,下次读取直接从版本快照中直接读取,所以一个事务中读取到的数据是一直的。
每次执行修改操作时,MySQL不会直接修改原始数据,而是创建一个新的版本。这个新版本包含了修改后的数据,以及生成这个版本的事务ID。当一个事务需要读取数据时,MySQL会根据事务的隔离级别和事务ID,从版本链中选择一个合适的版本。这样,即使在并发执行多个事务的情况下,每个事务也都能看到一个一致的数据视图。
MySQL中的锁机制
MySQL中的锁按粒度分,主要分为全局锁、表锁、行级锁
然后全局锁主要分为共享锁和排他锁,在全局锁中,是锁住所有的数据库表,放置的是备份操作中进行的操作影响最终备份的结果,共享锁可以和共享锁不排斥,共享锁和排他锁排斥,即加共享锁时,排他锁只能等候,排他锁和任何锁都互斥。
表锁主要分为表锁,元数据锁,意向锁,表锁也主要分为共享锁和排他锁,在元数据锁中,对一张表进行操作的时候,数据库会自动添加元数据锁,然后操作完成自动关闭。意向锁就是当修改一行数据时,有一个表锁,这时候要加表锁的话需要去进行全表查询,所以数据库就是用意向锁,当进行增删操作时,添加行锁,同时为这个表添加一个意向锁,当有其他表锁过来是,先去判断意向锁是不是排斥的,如果排斥就等待,这里意向锁和意向锁之间不会排斥。
行级锁分为行锁、间隙锁、临键锁,行锁分为共享锁和排他锁,间隙锁的话就是用来锁住数据与数据之间的间隙,防止事务在操作过程中突然添加数据,出现幻读,临键锁是锁住中间的间隙和两边的数据,方式出现幻读。
MySQL中的锁主要分为两种:共享锁和排他锁,共享锁允许多个事务同时获取相同资源的读取访问权限,而排他锁则只允许一个事务获取资源的写入访问权限。
SQL优化
表的设计优化
- 设置合适的数值,根据实际情况而定。
- 设置合适的字符串类型(char和varchar)。
- 尽量使用数值代替字符串类型,比如主键优先使用int类型,性别、状态,使用1,0替代。
SQL语句优化
- 避免使用select*,务必指明字段名称。
- SQL语句要避免索引失效的写法。
- 尽量使用union all代替union,union会多一次过滤,效率低。
- 避免在where子句中对字段进行表达式操作。
- 能用inner join就用inner join,如果必须使用其他的必须以小表驱动,内连接会自己对两个表进行优化,优先将小表放在外面。而left join和right join不会自动优化。
主从复制,读写分离
如果数据库场景读的操作比较多的时候,为了避免写的操作所造成的性能影响,可以采用读写分离的架构。不让数据的写入影响了读操作。
主从同步原理


MySQL主从复制的核心就是二进制日志,二进制日志(binlog)记录了所有的DDL(数据定义语言)和DML(数据操纵语言)语句,但不包括数据查询语句。
- DDL:创建表,修改表,删除表的操作语句。
- DML:增删改。
- 主从同步的过程是,当主库对数据进行操作时,将这些变化的数据写入到binlog日志中,从库有一个IOthread线程专门去主库中的binlog日志中读取数据,读取完成之后,就将数据写入到从库的中继日志(relaylog)中,然后由从库中的SQLthread线程去读取relaylog,将里面的命令重新执行。
分库分表
数据量特别大,比如一张表的数据超过500万,就可以考虑。
但是现在分库分表用的比较少了,因为现在硬件的性能非常高,一般一张MySQL表里面的数据都可以存到1亿左右,而且还不卡,因为都是通过内存淘汰链表和Free链表来更新数据。目前最多就是用用分库,分表几乎用不到了,因为10年前那会一张表一般就存储2000万数据。





![[Tomcat问题]--使用Tomcat 10.x部署项目时,出现实例化Servlet类[xxx]异常](https://img-blog.csdnimg.cn/img_convert/dad5cef90b1200f27f051ee7335444ec.png)