1.摘要
细粒度视觉分类(FGVC)是一项非常具有挑战性的任务,它旨在从子类别中识别对象,这是由于类间固有的微妙差异。现有的大部分工作主要是通过重用骨干网络提取检测到的判别区域的特征来解决这一问题。然而,这种策略不可避免地使管道变得复杂,并将建议的区域推到包含对象的大多数部分,从而无法定位真正重要的部分。近年来,视觉变压器(vision transformer, ViT)在传统的分类任务中表现出了强大的性能。变压器的自关注机制将每个补丁令牌链接到分类令牌。
在这项工作中,我们首先评估了ViT框架在细粒度识别设置中的有效性。然后,由于注意链接的强度可以直观地视为令牌重要性的指标,我们进一步提出了一种新的部件选择模块,该模块可以应用于大多数变压器架构,我们将变压器的所有原始注意权重集成到注意图中,以指导网络有效准确地选择判别图像补丁并计算它们之间的关系。使用对比损失来扩大混淆类的特征表示之间的距离。
我们将基于增强变压器的模型命名为transferg,并通过在五个流行的细粒度基准上进行实验来展示它的价值,在这些基准上我们实现了最先进的性能。为了更好地理解我们的模型,给出了定性结果。
2.问题
细粒度视觉分类旨在对给定对象类别的子类别进行分类,例如鸟类的子类别(Wah et al . 2011;Van Horn et al . 2015),汽车(Krause et al . 2013),飞机(Maji et al . 2013)。由于类间变化小,类内变化大,并且缺乏注释数据,特别是对于长尾类,一直被认为是一项非常具有挑战性的任务。得益于深度神经网络的进步(Krizhevsky, Sutskever, and Hinton 2012;Simonyan and Zisserman 2014;He et al . 2016),近年来FGVC的性能取得了稳步的进步。为了避免劳动密集型的部分注释,社区目前专注于弱监督的FGVC只有图像级别的标签。目前的方法大致可以分为两类,即定位方法和特征编码方法。与特征编码方法相比,定位方法具有显式捕获子类之间细微差异的优点,具有更强的可解释性和更好的结果
2.1发现
早期的定位方法依赖于零件的注释来定位判别区域,而最近的研究(Ge, Lin, and Yu 2019a;Liu et al . 2020;丁等人
2019)主要采用区域建议网络(RPN)来提出包含区分区域的边界框。在获得选定的图像区域后,将其调整为预定义的大小并再次通过骨干网络转发,以获取信息丰富的局部特征。一种典型的策略是单独使用这些局部特征进行分类,并采用秩损失(Chen等人)2009),以保持边界框的质量与其最终概率输出之间的一致性。然而,这种机制忽略了所选区域之间的关系,因此不可避免地鼓励RPN提出包含大部分对象的大边界框,而无法定位真正重要的区域。有时这些边界框甚至可以包含大面积的背景。并导致混淆。此外,与骨干网相比,优化目标不同的RPN模块使网络更难训练,骨干网的重用使整个管道变得复杂。
2.2发展
最近,视觉变压器(Dosovitskiy et al . 2020)在分类任务中取得了巨大的成功,这表明将纯变压器直接应用于图像补丁序列,利用其固有的注意机制可以捕获图像中的重要区域。下游任务的一系列扩展工作,如目标检测(Carion等2020)和语义分割(Zheng等2021;谢等2021;Chen et al . 2021)证实了它具有很强的捕捉全球和本地特征的能力。
Transformer的这些能力使其天生适合FGVC任务,因为Transformer的早期远程“接受野”(Dosovitskiy et al . 2020)使其能够定位早期处理层中的细微差异及其空间关系。相比之下,cnn主要利用图像的局部性,只捕获非常高层的弱远程关系。此外,细粒度类之间的细微差异只存在于某些地方,因此将捕捉细微差异的过滤器卷积到图像的所有地方是不合理的。
2.3创新
基于这一观点,本文首次探讨了视觉变换在细粒度视觉分类中的潜力。我们发现,直接将ViT应用于FGVC已经产生了令人满意的效果,并且可以根据FGVC的特性进行大量的调整,以进一步提高性能。具体来说,我们提出了零件选择模块,该模块可以找到识别区域并去除冗余信息。引入对比损失使模型更具判别性。我们将这个新颖而简单的基于变压器的框架命名为transition,并在五种流行的细粒度视觉分类基准(CUB-200-2011, Stanford Cars, Stanford Dogs, nabbirds, iNat2017)上对其进行了广泛的评估。性能比较的概述可以在图1中看到,我们的transfer在大多数数据集上优于现有的具有不同主干的SOTA CNN方法。综上所述,我们在这项工作中做出了几项重要贡献:
- 1。据我们所知,我们是第一个验证视觉转换器在细粒度视觉分类上的有效性的人,它为使用RPN模型设计主导的CNN主干提供了一种替代方案。
- 2. 我们介绍了一种新的神经结构,用于细粒度视觉分类,它自然地关注对象的最具区别性的区域,并在几个基准上实现了SOTA性能。
- 3. 可视化结果说明了我们的transferg能够准确捕获判别图像区域,并帮助我们更好地理解它是如何做出正确预测的。
2.4 补充
Fine-Grained Visual Classification
在解决细粒度视觉分类问题方面已经做了很多工作,它们大致可以分为两类:定位方法(Ge, Lin, and Yu 2019a;Liu et al . 2020;Yang et al . 2021)和特征编码方法(Yu et al . 2018;郑等人2019;Gao et al . 2020)。前者侧重于训练一个检测网络来定位判别部分区域,并再利用这些区域进行分类。后者的目标是通过计算高阶信息或寻找对比对之间的关系来学习更多信息特征。
Localization FGVC Methods
此前,一些著作(Branson et al . 2014;Wei, Xie, and Wu(2016)尝试利用零件标注来监督本地化过程的学习过程。然而,由于这种标注成本高且通常不可用,因此仅使用图像级标签的弱监督部件建议受到越来越多的关注。Ge等人(Ge, Lin, and Y u 2019a)利用Mask R-CNN和基于crf的分割交替提取对象实例和判别区域。Yang等人(Yang et al 2021)提出了一种基于区域特征构建的数据库对全局分类结果进行重新排序的重新排序策略。然而,这些方法都需要一个专门设计的模块来提出潜在的区域,这些选择的区域需要再次通过主干转发进行最终分类,这在我们的模型中是不需要的,从而保持了我们管道的简单性。
Feature-encoding Methods
另一种方法侧重于丰富特征表示以获得更好的分类结果。Yu et al (Yu et al 2018)提出了一个分层框架来进行跨层双线性池化。Zheng等人(Zheng et al, 2019)采用群体卷积的思想,首先根据信道的语义将信道分成不同的组,然后在不改变维数的情况下在每组内进行双线性池化,从而可以直接集成到任何现有的主干中。
然而,这些方法通常是不可解释的,因为人们不知道是什么使模型区分具有细微差异的子类别,而我们的模型会删除不重要的图像补丁,只保留那些包含大部分信息的图像补丁进行细粒度识别。
Transformer
器翻译的研究(Dai et al . 2019;Devlin等人2018;V aswani等人
2017)。受此启发,近年来许多研究尝试将变压器应用于计算机视觉领域。最初,变压器用于处理CNN骨干网为视频提取的顺序特征(Girdhar et al 2019)。后来,变压器模型被进一步扩展到其他流行的计算机视觉任务,如物体检测(Carion et al 2020;Zhu et al . 2020),分割(Xie et al . 2021;Wang等2021),目标跟踪(Sun et al . 2020)。最近,纯变压器模型正变得越来越流行。ViT (Dosovitskiy et al 2020)是第一个表明将纯变压器直接应用于图像补丁序列可以产生最先进的图像分类性能的工作
在此基础上,郑等人(Zheng et al 2021)提出了SETR,利用ViT作为分割的编码器。He et al (He et al 2021)提出了TransReID,该方法将侧信息与JPM一起嵌入到变压器中,以提高对象重新识别的性能。在这项工作中,我们将ViT扩展到细粒度的视觉分类,并证明了它的有效性。
3.网络
3.1整体结构
我们建议的转型框架。图像被分割成小块(此处显示的是一个不重叠的分割)并投影到嵌入空间中。变压器编码器的输入包括补丁嵌入以及可学习的位置嵌入。在最后一个变压器层之前,应用部件选择模块(PSM)来选择与判别图像补丁对应的令牌,并仅使用这些选择的令牌作为输入。最好以彩色观看。

属于是特征增强,重新标定注意力权重
3.2Vision Transformer as Feature Extractor
Image Sequentialization
在ViT之后,我们首先将输入图像预处理成一系列平坦的补丁xp。然而,原始的分割方法将图像分割成不重叠的小块,特别是在分割判别区域时,会损害局部相邻结构。
为了解决这一问题,我们提出了使用滑动窗口生成重叠补丁的方法。具体地说,我们用分辨率H * W表示输入图像,图像patch的大小为P,滑动窗口的步长为s。因此,输入图像将被分割成N个patch,其中

这样,两个相邻的斑块共享一个大小为(P−S) * P的重叠区域,这有助于更好地保留局部区域信息。一般来说,步长S越小,性能越好。但是减小S同时需要更多的计算成本,所以这里需要做一个权衡。
在vit中,切块操作是将图像切成均等大小,不重合的小切块,确实减弱了每个切块之间的联系。使用滑动窗口生成重叠补丁的方法理论上可以加强小切块之间的联系
Patch Embedding.
我们使用可训练的线性投影将矢量化的patch xp映射到潜在的d维嵌入空间。在patch embedding中加入一个可学习的位置embedding来保留位置信息,方法如下:
![]()
式中N为图像patch的个数,E∈R(p2·C)∗D为patch的嵌入投影,Epos∈RN∗D为位置嵌入。
Transformer编码器(V aswani et al 2017)包含L层多头自注意(MSA)和多层感知器(MLP)块。因此,第l层的输出可以写成:

式中LN(·)为层归一化操作,zl为编码后的图像表示。ViT利用最后一个编码器层z0L的第一个令牌作为全局特征的表示,并将其转发给分类器头,以获得最终的分类结果,而不考虑其余令牌中存储的潜在信息。
3.3TransFG Architecture
虽然我们的实验表明,纯视觉转换器可以直接应用于细粒度视觉分类并取得令人印象深刻的结果,但它不能很好地捕获FGVC所需的局部信息。为此,我们提出了零件选择模块(PSM),并应用对比特征学习来扩大混淆子类别之间的表示距离。我们提出的transg框架如图2所示
Part Selection Module
在细粒度视觉分类中,最重要的问题之一是如何准确定位相似子类别之间细微差异的判别区域。例如,图3显示了来自CUB-200-2011(引文)数据集的一对令人困惑的图像。为了区分这两种鸟类,模型需要能够捕捉到非常小的差异,即眼睛和喉咙的颜色。在传统的基于cnn的方法中,广泛引入区域建议网络和弱监督分割策略来解决这一问题。
视觉变形模型具有先天的多头注意机制,非常适合于此。为了充分利用注意力信息,我们将输入更改为最后一个Transformer Layer。假设模型有K个自注意头,输入到最后一层的隐藏特征记为zL−1 = [z0L−1;z1L−1,z2L−1,···,zNL−1]。前几层的注意权值可以写成:
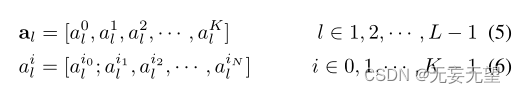
往届作品(Serrano and Smith 2019;Abnar和Zuidema 2020)认为,由于嵌入缺乏令牌可识别性,原始注意力权重不一定对应于输入令牌的相对重要性,特别是对于模型的更高层。为此,我们建议对前几层的注意权值进行整合。具体地说,我们递归地将矩阵乘法应用于所有层中的原始注意力权重

由于最终捕获了信息如何从输入层传播到更高层的嵌入,与单层原始注意权值aL−1相比,它可以作为选择判别区域的更好选择。然后,我们选择A1, A2,···,AK相对于最终K个不同注意头的最大值的指标。
图像特征推理过程中,由transformer encoder块进行层层编码,一种可能的情况是,在前面层中的权重信息到了后面几层被减弱或者隐去,但是前面几层的权重信息对于最终任务是有用的。
这些位置被用作我们模型的索引,以提取zL−1中相应的标记。最后,我们将选择的标记与分类标记连接起来作为输入序列,表示为:
![]()
通过将原始的整个输入序列替换为与信息区域相对应的标记,并将分类标记作为输入连接到最后一个Transformer Layer,我们不仅保留了全局信息,而且还迫使最后一个Transformer Layer专注于不同子类别之间的细微差异,同时放弃了不太具有区别性的区域,如背景或共同特征。
Contrastive Feature Learning
在ViT之后,我们仍然采用PSM模块的第一个令牌zi进行分类。简单的交叉熵损失不足以完全监督特征的学习,因为子类别之间的差异可能很小。为此,我们采用对比损失Lcon,使不同标签对应的分类令牌的相似性最小化,并使具有相同标签y的样本的分类令牌的相似性最大化。为了防止损失被容易负的(相似度较小的不同类别样本)所主导,我们引入了一个常数裕度α,只有相似度大于α的负对才会导致损失Lcon。形式上,批量大小为B的对比损失表示为:

其中zi和zj经过l2归一化预处理,因此Sim(zi, zj)是zi和zj的点积。
综上所述,我们的模型是用交叉熵损失Lcross和对比Lcon之和来训练的,可以表示为:
![]()
其中Lcross(y, y0)是预测标签y0和真实标签y之间的交叉熵损失。
4.实验
4.1实验设置
4.1.1 数据集
CUB-200-2011 (Wahet al. 2011), Stanford Cars (Krause et al. 2013),
StanfordDogs (Khosla et al. 2011), NABirds (Van Horn et al. 2015)
and iNat2017 (Van Horn et al. 2018).
4.1.2 实验细节
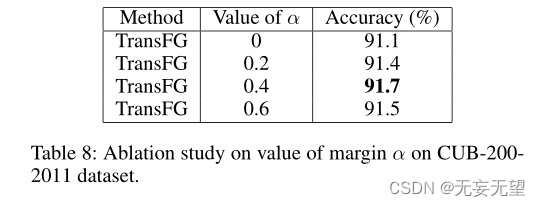
除非另有说明,否则我们按如下方式实现transferg。首先,我们将输入图像的大小调整为448∗448,除了iNat2017上的304∗304,以进行公平的比较(随机裁剪用于训练,中心裁剪用于测试)。我们将图像分割为大小为16的小块,滑动窗口的步长设置为12。因此式1中的H、W、P、S分别为448、448、16、12。Eq 9中的边际α设置为0.4。我们从ImageNet21k上预训练的官方vit - b16模型加载中间权重。批量大小设置为16。SGD优化器的动量为0.9。除Stanford Dogs数据集为0.003,iNat2017数据集为0.01外,初始化学习率为0.03。我们采用余弦退火作为优化器的调度程序。
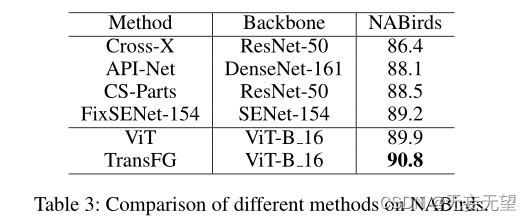
4.2对比试验



4.3消融实验



5.结语
在这项工作中,我们提出了一个新的细粒度识别框架,并在四个常见的细粒度基准上取得了最先进的结果。我们利用自注意机制来捕捉最具歧视性的区域。与其他方法产生的边界框相比,我们选择的图像补丁要小得多,因此通过显示哪些区域真正有助于细粒度分类变得更有意义。这种小图像补丁的有效性还来自于Transformer Layer处理这些区域之间的内在关系,而不是依赖于每个区域单独产生结果。为了提高分类令牌的判别能力,引入了对比损失。在传统的学术数据集和大规模的竞争数据集上进行了实验,以证明我们的模型在多场景下的有效性。定性可视化进一步显示了我们方法的可解释性。
随着transferg取得的有希望的结果,我们相信基于转换器的模型在细粒度任务上有很大的潜力,我们的transferg可以成为未来工作的起点。