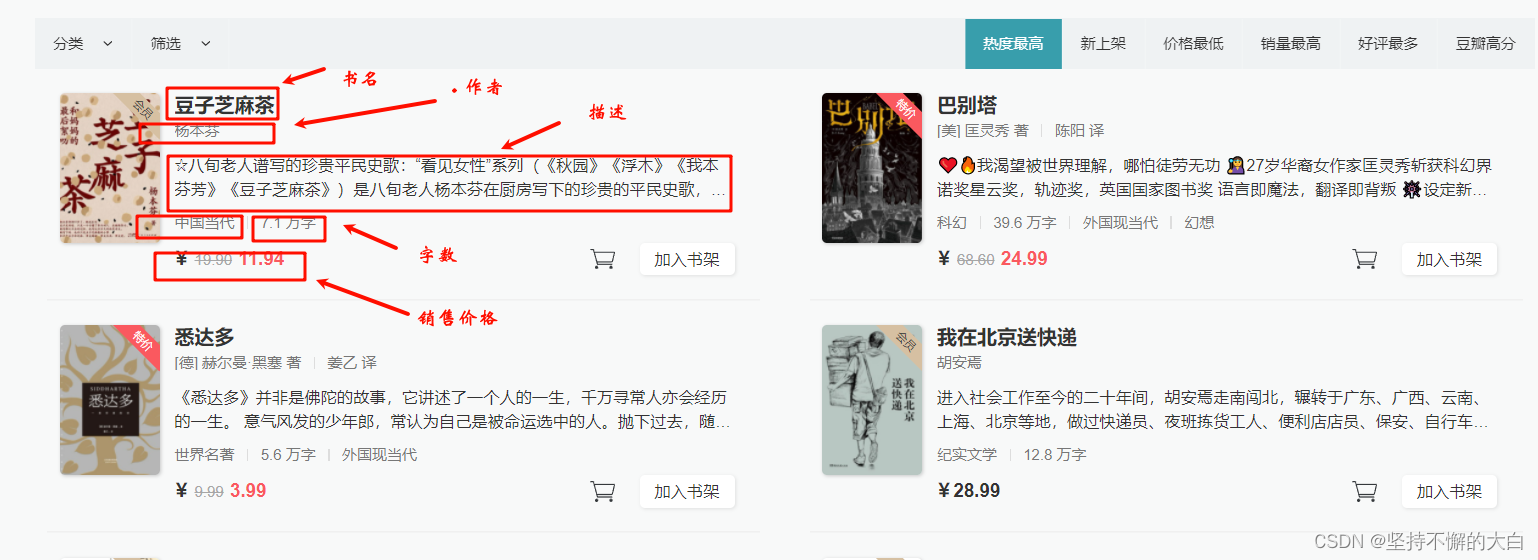
接着上一篇文章:Python爬虫从基础到入门:找数据接口,接下来实战一下,以获取豆瓣阅读这个网站热度最高的书籍信息为例,网址为:豆瓣阅读

Python爬虫从基础到入门:数据接口实战--获取豆瓣阅读热度最高的书本信息
- 1. 分析网站数据
- 2. 查看该接口信息
- 3. 编写抓取代码
1. 分析网站数据
也就是辨别网站是静态页面还是使用了ajax技术渲染出来。这里可以看本专栏第一篇文章的讲述:Python爬虫从基础到入门:认识爬虫,豆瓣阅读网站使用的是ajax技术渲染数据,因此需要找到对应接口即可。
打开浏览器的开发者模式,选择网络,选择XHR,找到对应接口,即可查看到对应书籍的相关信息。
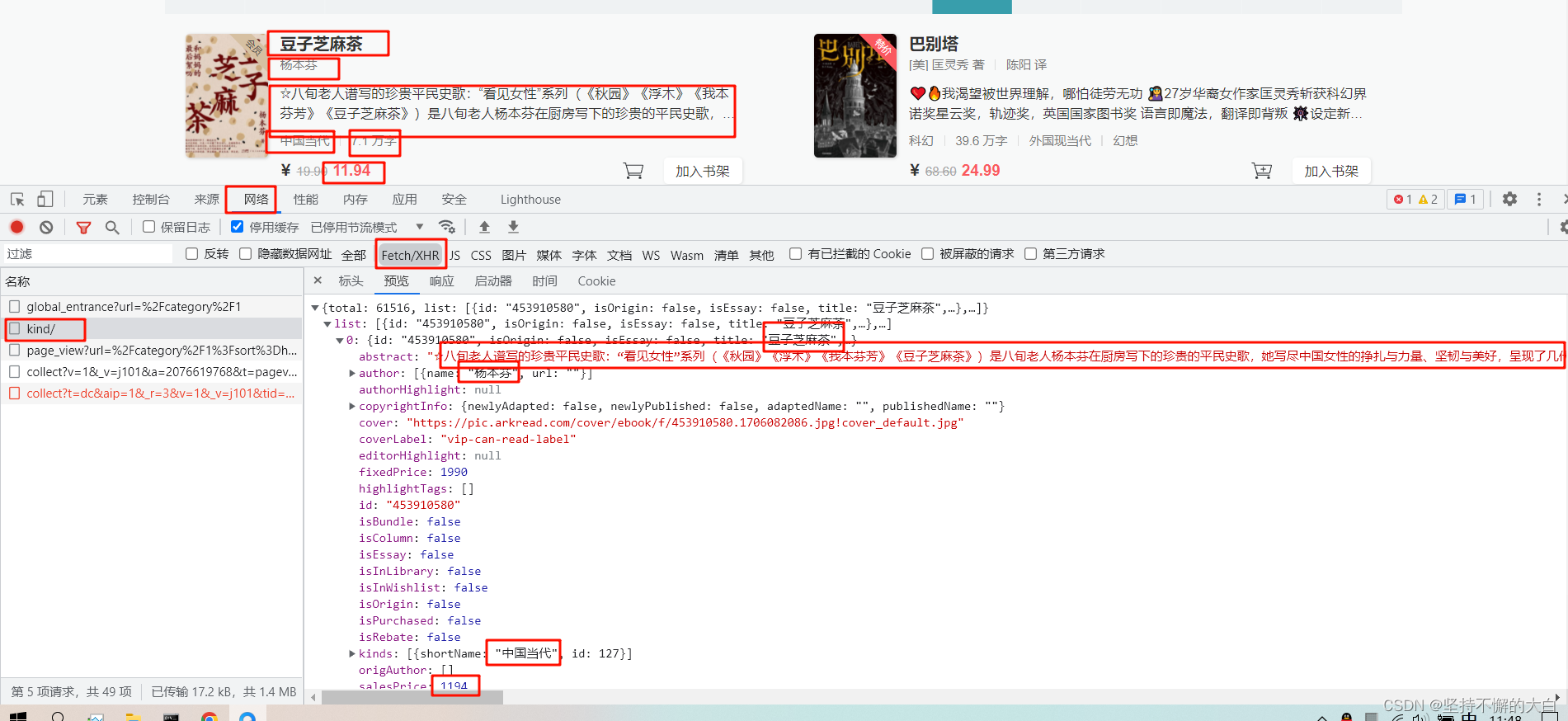
2. 查看该接口信息
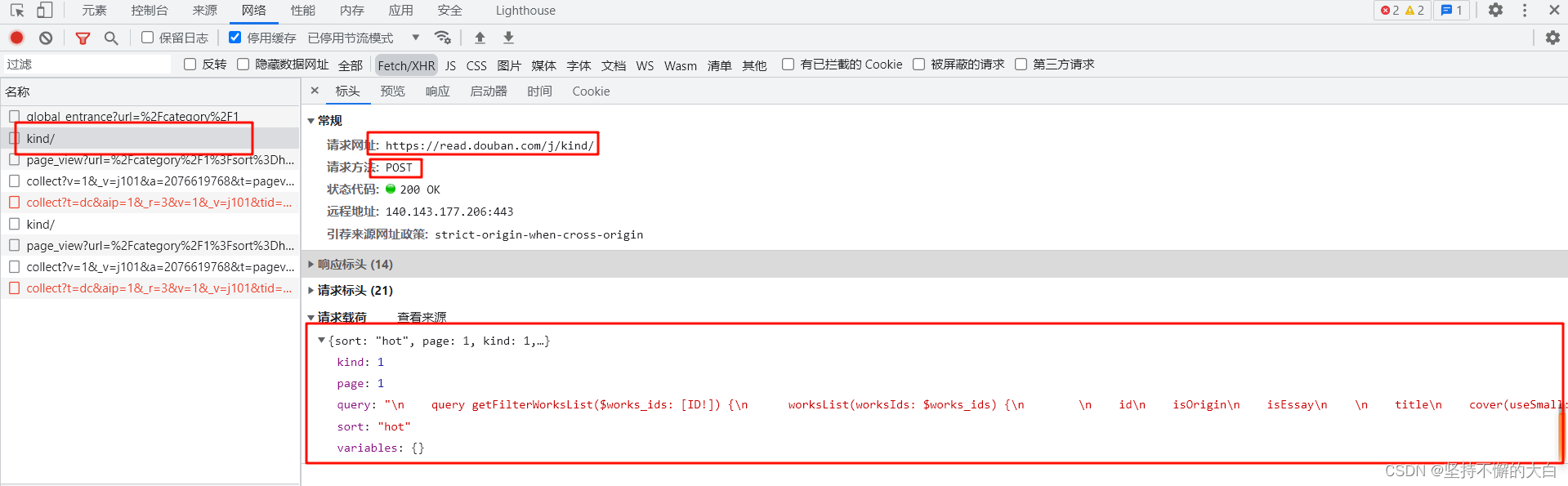
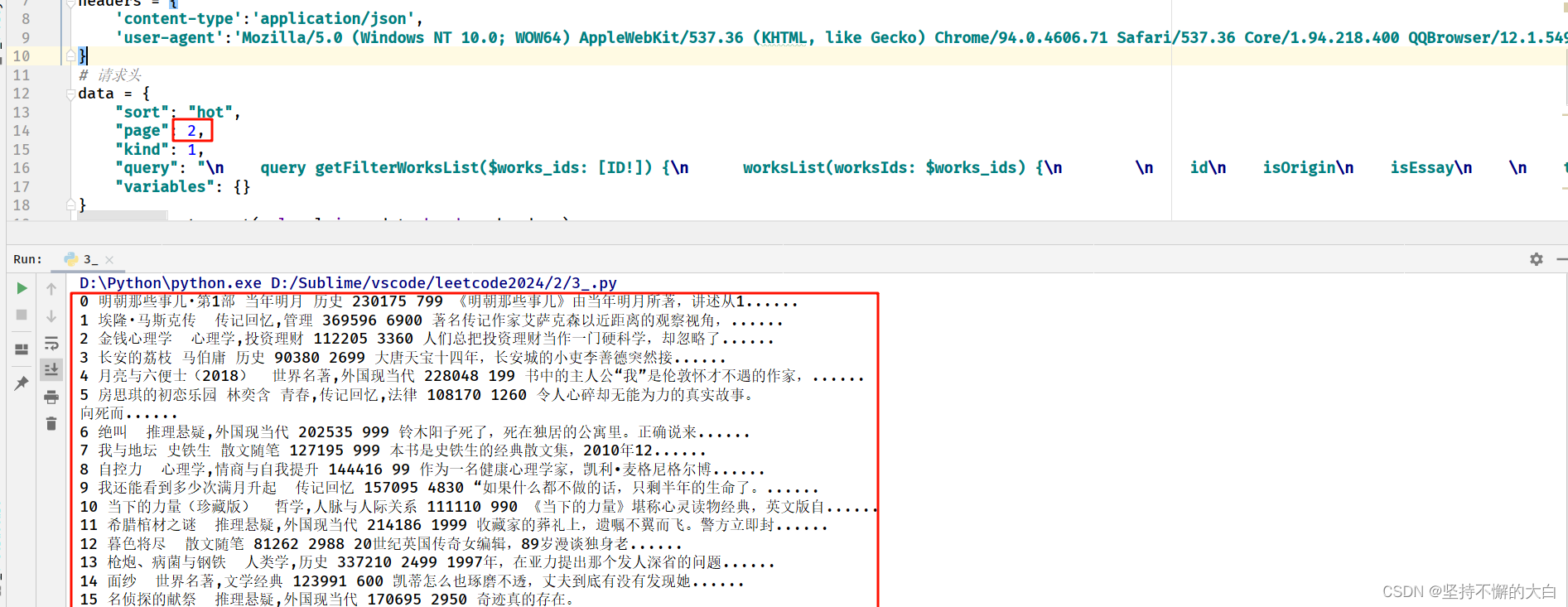
通过上图分析,该即可为:
请求方式:post
请求地址:https://read.douban.com/j/kind/
请求参数:
{
"sort": "hot",
"page": 1,
"kind": 1,
"query": "\n query getFilterWorksList($works_ids: [ID!]) {\n worksList(worksIds: $works_ids) {\n \n id\n isOrigin\n isEssay\n \n title\n cover(useSmall: false)\n url\n isBundle\n coverLabel(preferVip: true)\n \n \n url\n title\n\n \n author {\n name\n url\n }\n origAuthor {\n name\n url\n }\n translator {\n name\n url\n }\n\n \n abstract\n authorHighlight\n editorHighlight\n\n \n isOrigin\n kinds {\n \n name @skip(if: true)\n shortName @include(if: true)\n id\n \n }\n ... on WorksBase @include(if: true) {\n wordCount\n wordCountUnit\n }\n ... on WorksBase @include(if: false) {\n inLibraryCount\n }\n ... on WorksBase @include(if: false) {\n \n isEssay\n \n ... on EssayWorks {\n favorCount\n }\n \n \n \n averageRating\n ratingCount\n url\n isColumn\n isFinished\n \n \n \n }\n ... on EbookWorks @include(if: false) {\n \n ... on EbookWorks {\n book {\n url\n averageRating\n ratingCount\n }\n }\n \n }\n ... on WorksBase @include(if: false) {\n isColumn\n isEssay\n onSaleTime\n ... on ColumnWorks {\n updateTime\n }\n }\n ... on WorksBase @include(if: true) {\n isColumn\n ... on ColumnWorks {\n isFinished\n }\n }\n ... on EssayWorks {\n essayActivityData {\n \n title\n uri\n tag {\n name\n color\n background\n icon2x\n icon3x\n iconSize {\n height\n }\n iconPosition {\n x y\n }\n }\n \n }\n }\n highlightTags {\n name\n }\n ... on WorksBase @include(if: false) {\n fanfiction {\n tags {\n id\n name\n url\n }\n }\n }\n \n \n ... on WorksBase {\n copyrightInfo {\n newlyAdapted\n newlyPublished\n adaptedName\n publishedName\n }\n }\n\n isInLibrary\n ... on WorksBase @include(if: false) {\n \n fixedPrice\n salesPrice\n isRebate\n \n }\n ... on EbookWorks {\n \n fixedPrice\n salesPrice\n isRebate\n \n }\n ... on WorksBase @include(if: true) {\n ... on EbookWorks {\n id\n isPurchased\n isInWishlist\n }\n }\n ... on WorksBase @include(if: false) {\n fanfiction {\n fandoms {\n title\n url\n }\n }\n }\n ... on WorksBase @include(if: false) {\n fanfiction {\n kudoCount\n }\n }\n \n }\n }\n ",
"variables": {}
}
请求头为:
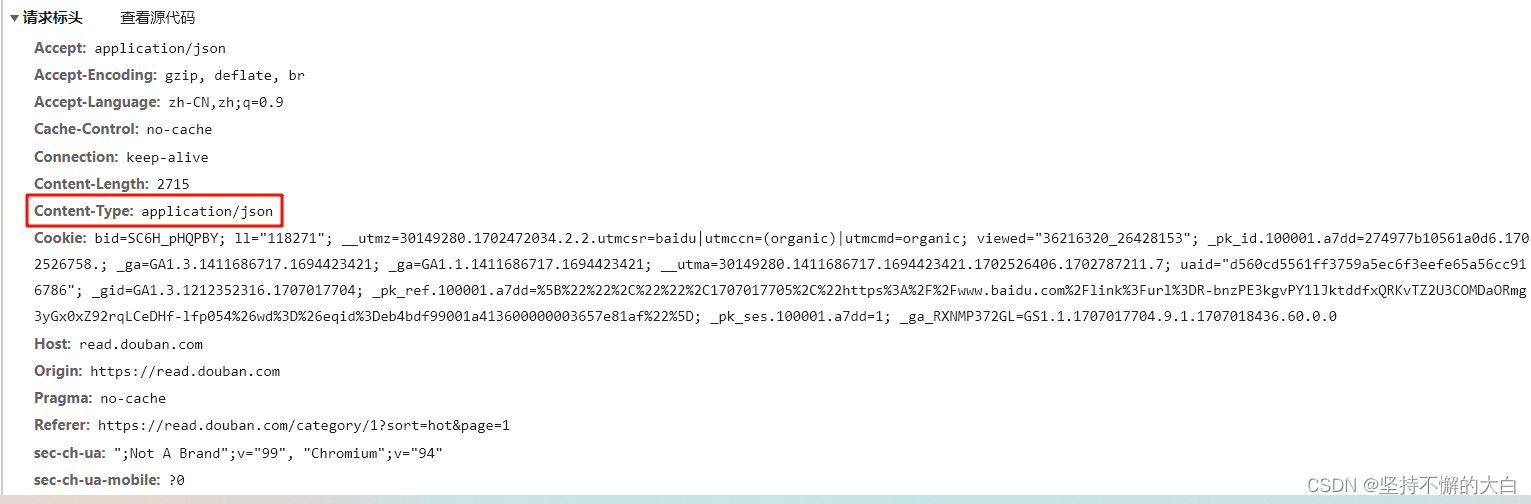
注意必须要添加请求头参数,否则响应状态码为418,而不是200。
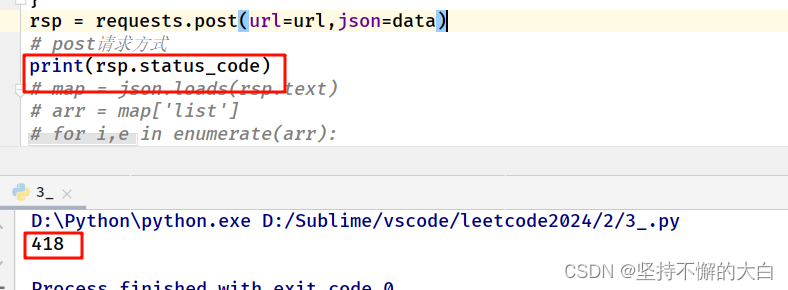
响应码为:418原因为:

所有需要添加请求头,并在请求头中添加用户代理这个字段才行。
3. 编写抓取代码
参考代码如下:
import requests
import json
url = 'https://read.douban.com/j/kind/'
# 请求地址
headers = {
'content-type':'application/json',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.218.400 QQBrowser/12.1.5496.400',
}
# 请求头
data = {
"sort": "hot",
"page": 1,
"kind": 1,
"query": "\n query getFilterWorksList($works_ids: [ID!]) {\n worksList(worksIds: $works_ids) {\n \n id\n isOrigin\n isEssay\n \n title\n cover(useSmall: false)\n url\n isBundle\n coverLabel(preferVip: true)\n \n \n url\n title\n\n \n author {\n name\n url\n }\n origAuthor {\n name\n url\n }\n translator {\n name\n url\n }\n\n \n abstract\n authorHighlight\n editorHighlight\n\n \n isOrigin\n kinds {\n \n name @skip(if: true)\n shortName @include(if: true)\n id\n \n }\n ... on WorksBase @include(if: true) {\n wordCount\n wordCountUnit\n }\n ... on WorksBase @include(if: false) {\n inLibraryCount\n }\n ... on WorksBase @include(if: false) {\n \n isEssay\n \n ... on EssayWorks {\n favorCount\n }\n \n \n \n averageRating\n ratingCount\n url\n isColumn\n isFinished\n \n \n \n }\n ... on EbookWorks @include(if: false) {\n \n ... on EbookWorks {\n book {\n url\n averageRating\n ratingCount\n }\n }\n \n }\n ... on WorksBase @include(if: false) {\n isColumn\n isEssay\n onSaleTime\n ... on ColumnWorks {\n updateTime\n }\n }\n ... on WorksBase @include(if: true) {\n isColumn\n ... on ColumnWorks {\n isFinished\n }\n }\n ... on EssayWorks {\n essayActivityData {\n \n title\n uri\n tag {\n name\n color\n background\n icon2x\n icon3x\n iconSize {\n height\n }\n iconPosition {\n x y\n }\n }\n \n }\n }\n highlightTags {\n name\n }\n ... on WorksBase @include(if: false) {\n fanfiction {\n tags {\n id\n name\n url\n }\n }\n }\n \n \n ... on WorksBase {\n copyrightInfo {\n newlyAdapted\n newlyPublished\n adaptedName\n publishedName\n }\n }\n\n isInLibrary\n ... on WorksBase @include(if: false) {\n \n fixedPrice\n salesPrice\n isRebate\n \n }\n ... on EbookWorks {\n \n fixedPrice\n salesPrice\n isRebate\n \n }\n ... on WorksBase @include(if: true) {\n ... on EbookWorks {\n id\n isPurchased\n isInWishlist\n }\n }\n ... on WorksBase @include(if: false) {\n fanfiction {\n fandoms {\n title\n url\n }\n }\n }\n ... on WorksBase @include(if: false) {\n fanfiction {\n kudoCount\n }\n }\n \n }\n }\n ",
"variables": {}
}
rsp = requests.post(url=url,json=data,headers=headers)
# post请求方式
map = json.loads(rsp.text)
arr = map['list']
for i,e in enumerate(arr):
title = e['title']
# 书籍名
author = ",".join([e2['name'] for e2 in e['author']])
# 作者,可能零个或多个
des = e['abstract']
# 描述
kind = ','.join([e2['shortName'] for e2 in e['kinds']])
# 类别 ,一个或多个
wordCount = e['wordCount']
# 字数
price = e['salesPrice']
# 价格
print(i,title,author,kind,wordCount,price,des[:20]+'......')
运行结果如下:

这是第一页的数据,如果需要采集第二页的数据,只需要更改请求参数中的字段page的值即可,如下: