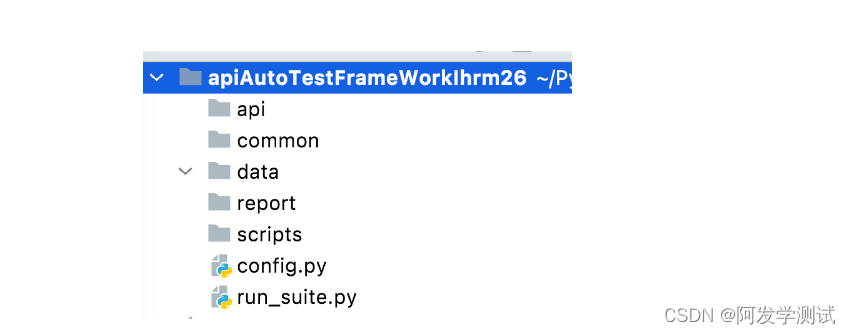
接口自动化测试框架
目录结构
7 部分(5个目录、2个文件):
api/: 存储接口对象层(自己封装的 接口)
scripts/: 存储测试脚本层 (unittest框架实现的 测试类、测试方法)
data/: 存储 .json 数据文件
report/: 存储 生成的 html 测试报告
common/: 存储 通用的 工具方法
config.py: 存储项目的配置信息(全局变量)
run_suite.py: 组装测试用例、生成测试报告的 代码

一、Requests框架
简介:
Requests库 是 Python编写的,基于urllib 的 HTTP库,使用方便。
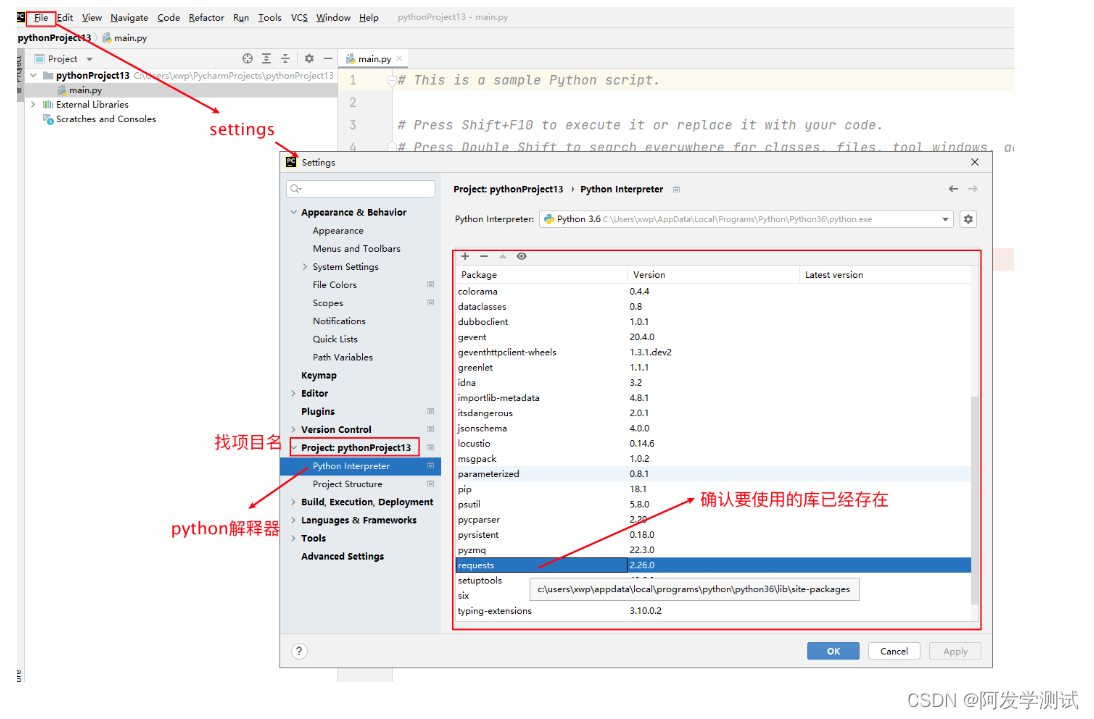
安装:
pip install requests
查验:
- 步骤1:pip 中查验
# 方法1
pip list
# 方法2
pip show 库名
- 步骤2:pycharm 中查验

设置http请求语法
resp = requests.请求方法(url='URL地址', params={k:v}, headers={k:v},data={k:v}, json={k:v}, cookies='cookie数据'(如:令牌))
请求方法:
get请求 - get()
post请求 - post()
put请求 - put()
delete请求 - delete()
url: 待请求的url - string类型
params:查询参数 - 字典
headers:请求头 - 字典
data:表单格式的 请求体 - 字典
json:json格式的 请求体 - 字典
cookies:cookie数据 - string类型
resp:响应结果
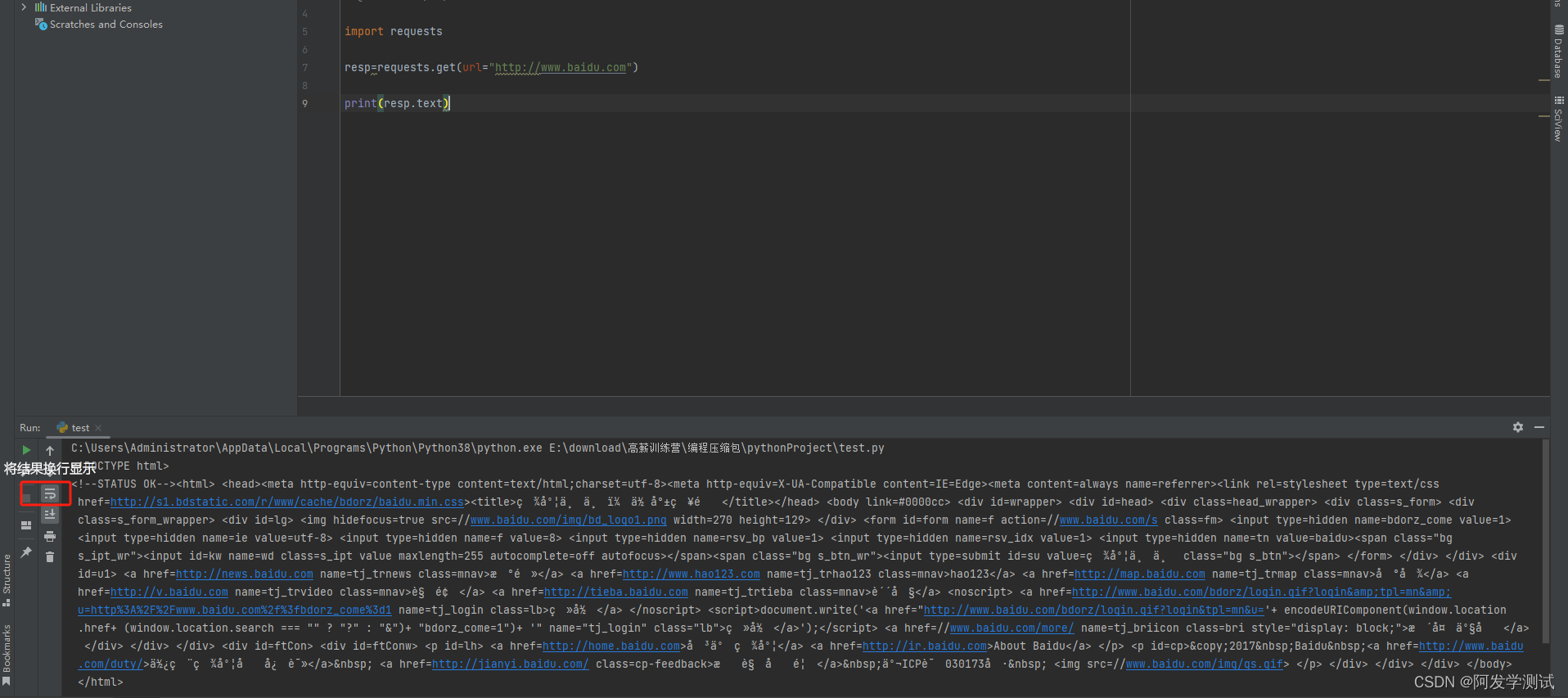
入门案例
使用Requests库访问 百度 http://www.baidu.com
import requests
resp=requests.get(url="http://www.baidu.com")
print(resp.text)
案例
使用Requests库,完成 平安保险核保接口调用。返回 ”200“ 即可。
import requests
import json
url = "http://mcp-test-health.pingan.com.cn/gateway/mcp/outChannel/validate.do"
params = {"c": "WI"}
headers = {"Content-Type": "application/json"}
body = {
"requestId": "hebaojiaoyanma_3453946894536",
"c": "WI",
"data": {
"productId": "A100000013",
"outChannelOrderId": "66323958403338552251",
"effDate": "2020-12-20",
"applyDate": "2020-12-19",
"totalPremium": "357.00",
"isNoticeConfirm": "Y",
"isShareCoverage": "N",
"discount": "1",
"applicant": {
"name": "士发放",
"birthday": "1980-01-01",
"sex": "M",
"idType": "1",
"idno": "110101198001010117",
"contactInfo": {
"mobile": "16351656161",
"email": "123@qq.com",
"contactAddress": {
"provinceCode": "110000",
"cityCode": "110000",
"areaCode": "110101"
}
},
"extend": {
"taxType": "null",
"realCheckType": "1"
}
},
"insurants": [
{
"seqno": "1",
"name": "华东师范",
"birthday": "1998-12-22",
"sex": "F",
"idType": "2",
"idno": "41151990221",
"socialSecurity": "Y",
"relationshipWithApplicant": "2",
"relationshipWithPrimaryInsurant": "1",
"contactInfo": {
"email": "123@qq.com"
},
"coverages": [
{
"planType": "0",
"sumInsured": "100000.00",
"benLevel": "09",
"period": "12",
"periodDay": "0",
"paymentPeriod": "12",
"paymentPeriodDay": "0",
"actualPrem": "357.00",
"units": ""
}
],
"healthNotes": [
{
"questionId": "P19100001",
"answer": "Y",
"healthNoteSeq": "1"
}
],
"isRenewal": "N",
"extend": {
"realCheckType": "1"
},
"realCheck": True
}
],
"channelInfo": {
"mainAgentNo": "H2604Z5I3H",
"sellerCode": "H2604Z5I3H",
"sellerName": "",
"independentPromoter": "H2604Z5I1B"
},
"serviceAgreementInfo": {
"premType": "5"
},
"authInfo": {
"initialChargeMode": "9"
},
"others": {
"imgCheckType": "1",
"assignEffdate": "Y",
"extraInfo": {
}
}
}
}
response = requests.post(url, params=params, headers=headers, data=json.dumps(body))
print(response.status_code)
print(response.json())
运行结果:

获取指定响应数据
常用:
- 获取 URL:resp.url
- 获取 响应状态码:resp.status_code
- 获取 Cookie:resp.cookies
- 获取 响应头:resp.headers
- 获取 响应体:
文本格式:resp.text
json格式:resp.json()
import requests
resp = requests.get(url="http://www.baidu.com")
# - 获取 URL:resp.url
print("url =", resp.url)
# - 获取 响应状态码:resp.status_code
print("status_code =", resp.status_code)
# - 获取 Cookie:resp.cookies
print("cookies =", resp.cookies)
# - 获取 响应头:resp.headers
print("headers =", resp.headers)
# - 获取 响应体:
# - 文本格式:resp.text
print("body_text =", resp.text)
# - json格式:resp.json() 当显示 JSONDecodeError 错误时,说明 resp 不能转换为 json格式数据。
print("body_json =", resp.json())
二、UnitTest框架
UnitTest 是开发人员用来实现 “单元测试” 的框架。测试工程师,可以在自动化 “测试执行” 时使用。
使用 UnitTest 的好处:
- 方便管理、维护测试用例。
- 提供丰富的断言方法。
- 生成测试报告。(需要插件 HTMLTestReport)
unittest的用例规则:
1、测试文件必须导包:import unittest
2、测试类必须继承 unittest.TestCase
3、测试方法必须以 test_开头
1.TestCase(测试用例)
# 1、导包
import unittest
# 2、定义测试类从 TestCase 类继承
class TestDemo(unittest.TestCase):
# 3、测试方法定义必须以 test 开头。 建议添加 编号!
def test_method1(self):
print('测试方法1-1')
def test_method2(self):
print('测试方法1-2')
2.Fixture(测试夹具)
是一种代码结构,在某些特定情况下,会自动执行。
1、方法级别的 setUp(self) tearDown(self) 每个普通方法执行 之前/之后 自动运行。
def setUp(self):
# 执行测试前的准备工作,在每个测试方法执行前都会调用
print("setUp() method is called.")
def tearDown(self):
# 执行测试后的清理工作,在每个测试方法执行后都会调用
print("tearDown() method is called.")
场景:当你要登录自己的用户名账户的时候,都会输入网址,当你准备不用这个页面了,都会关闭当前页面;
1、输入网址 (方法级别)
2、关闭当前页面 (方法级别)
2、类级别的 setUpClass(cls) tearDownClass(cls) 在类内所有方法直 之前/之后 运行一次。
注意:类方法必须使用 @classmethod修饰
@classmethod
def setUpClass(cls):
print('-----------1.打开浏览器')
@classmethod
def tearDownClass(cls):
print('------------5、关闭浏览器')
场景:你上网的整个过程都首先需要打开浏览器,关闭浏览器,而他们整个过程都需要执行一次,那么就可以用类级别。
3.TestSuite(测试套件)和TestLoader(测试加载)
-
TestSuite(测试套件)
用来组装,打包 ,管理多个TestCase(测试用例)文件的
# 1、实例化测试集对象
suite = unittest.TestSuite()
# 2、添加指定类的全部测试方法。
suite.addTest(unittest.makeSuite(类名))
-
TestLoader(测试加载)
- 将符合条件的测试方法添加到测试套件中
- 搜索指定目录文件下指定字母开头的模块文件下test开始的方法,并将这些方法添加到测试套件中,最后返回测试套件
- 与Testsuite功能一样,对他功能的补充,用来组装测试用例
# suite = unittest.TestLoader().discover(搜索目录, 搜索文件名)
suite = unittest.TestLoader().discover("./", "test*.py")
TestSuite与TestLoader区别:
共同点:都是测试套件
不同点:实现方式不同
TestSuite: 要么添加指定的测试类中所有test开头的方法,要么添加指定测试类中指定某个test开头的方法
TestLoader: 搜索指定目录下指定字母开头的模块文件中以test字母开头的方法并将这些方法添加到测试套件中,最后返回测试套件
4.TestRunner(测试执行)
TestRunner(测试执行):用来执行 TestSuite(测试套件的)
# 1、实例化运行对象
runner = unittest.TextTestRunner();
# runner = HTMLTestReport("./report1.html", description="描述信息", title="报告标题")
# 2、使用运行对象去执行套件对象
# 运⾏对象.run(套件对象)
runner.run(suite)
5.断言
1、什么是断言:
让程序代替人工自动的判断预期结果和实际结果是否相符
断言的结果:
1)、True,用例通过
2)、False,代码抛出异常,用例不通过
3)、在unittest中使用断言,需要通过 self.断言方法
2、为什么要断言:
自动化脚本执行时都是无人值守,需要通过断言来判断自动化脚本的执行是否通过
注:自动化脚本不写断言,相当于没有执行测试一个效果。
常用断言
- self.assertEqual(ex1, ex2) # 判断ex1 是否和ex2 相等
- self.assertIn(ex1, ex2) # ex2是否包含 ex1 注意:所谓的包含不能跳字符
- self.assertTrue(ex) # 判断ex是否为True
assertEqual(参1,参2) :
参1:预期结果。 参2:实际结果。
成功:完全相等。断言通过。不报错!
失败:报错!
assertIn(参1,参2):
参1:预期结果。参2:实际结果。
成功:实际结果中,包含预期结果。断言通过。不报错!
失败:报错!
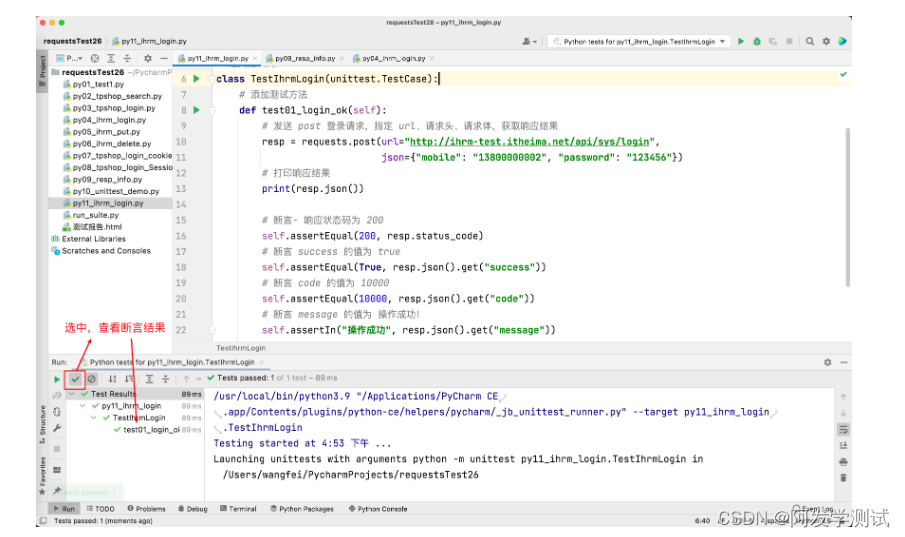
示例1
import requests
# 定义测试类
class TestIhrmLogin(unittest.TestCase):
# 添加测试方法
def test01_login_ok(self):
# 发送 post 登录请求,指定 url、请求头、请求体,获取响应结果
resp = requests.post(url="http://ihrm-test.itheima.net/api/sys/login",
json={"mobile": "13800000002", "password": "123456"})
# 打印响应结果
print(resp.json())
# 断言- 响应状态码为 200
self.assertEqual(200, resp.status_code)
# 断言 success 的值为 true
self.assertEqual(True, resp.json().get("success"))
# 断言 code 的值为 10000
self.assertEqual(10000, resp.json().get("code"))
# 断言 message 的值为 操作成功!
self.assertIn("操作成功", resp.json().get("message"))
示例2
1.测试类
"""
unittest 测试框架代码所处文件要求: 遵守 标识符命名规范:
1. 只能使用 字母、数字、下划线
2. 数字不能开头
3. 避免使用 关键字、已知函数名
类:首字母必须大写。建议以 Test 开头
方法:必须 test 开头,建议 编号
"""
import unittest
def add(x,y):
return x+y
class TestAdd(unittest.TestCase):
def setUp(self) -> None:
print("-------开始运行------")
def tearDown(self) -> None:
print("------结束运行-------")
@classmethod
def setUpClass(cls) -> None:
print("======开始程序=====")
@classmethod
def tearDownClass(cls) -> None:
print("======结束程序=====")
# 自定义测试方法
def test01_add(self):
print("测试方法1")
ret = add(10,20)
#断言响应结果
self.assertEqual(30,ret)
def test02_add(self):
print("测试方法2")
ret = add(100, 200)
# 断言
self.assertEqual(300, ret)
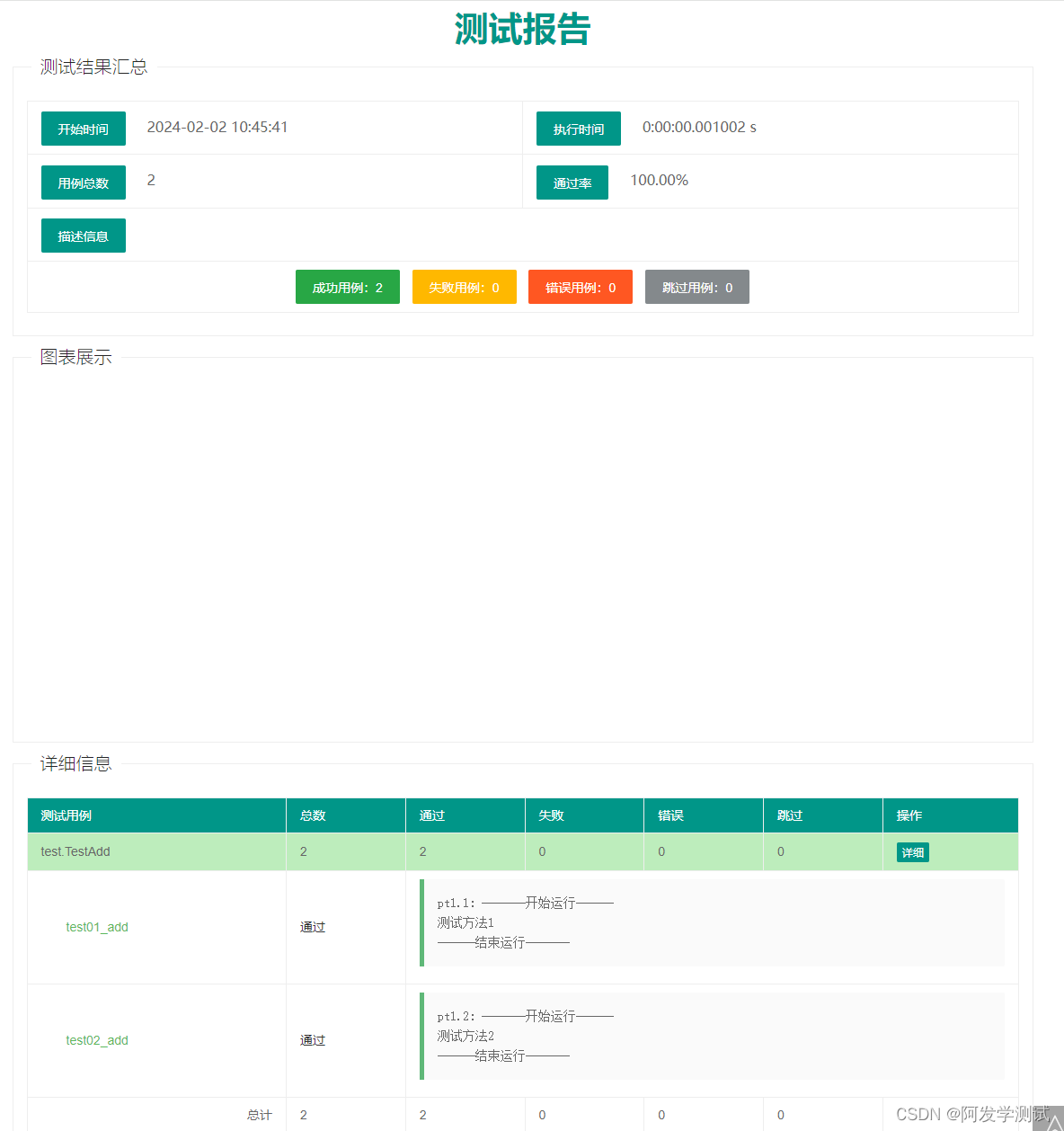
2.生成测试报告(HTMLTestReport)
import unittest
from htmltestreport import HTMLTestReport
# 创建 suite 实例
from test import TestAdd
suite = unittest.TestSuite()
# 指定测试类,添加 测试方法
suite.addTest(unittest.makeSuite(TestAdd))
# 创建 HTMLTestReport 实例
runner = HTMLTestReport("测试报告.html")
# 调用 run() 传入 suite
runner.run(suite)

6.跳过
对于一些未完成的或者不满足测试条件的测试函数和测试类, 不想执行,可以使用跳过
"""
使用方法,装饰器完成
代码书写在 TestCase 文件
"""
# 直接将测试函数标记成跳过
@unittest.skip('跳过条件')
# 根据条件判断测试函数是否跳过 , 判断条件成立, 跳过
@unittest.skipIf(判断条件,'跳过原因')
import unittest
version = 20
class TestDemo1(unittest.TestCase):
@unittest.skip('直接跳过')
def test_method1(self):
print('测试用例1-1')
@unittest.skipIf(version > 19, '版本大于19,测试跳过')
def test_method2(self):
print('测试用例1-2')
运行结果:
三.BeautifulReport框架
接上面的案例
import unittest
from BeautifulReport import BeautifulReport
from test import TestAdd
# 创建 suite 实例
suite=unittest.TestSuite()
# 指定测试类,添加 测试方法
suite.addTest(unittest.makeSuite(TestAdd))
# 运行测试并生成报告
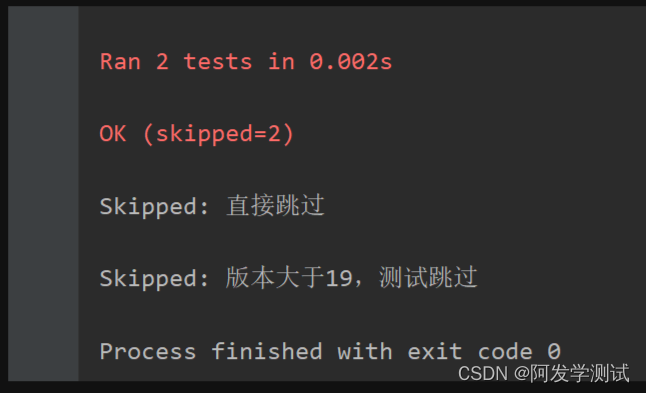
result = BeautifulReport(suite)
result.report(
description='接口自动化测试用例',
filename='test_report.html'
)
四.Ddt框架
ddt:data-driver tests
数据驱动: 是以数据来驱动整个测试用例的执行, 也就是测试数据决定测试结果
数据驱动解决的问题是:
1)、代码和数据分离,避免代码冗余
2)、不写重复的代码逻辑;
语法:
1、使用数据驱动,要在class前加上修饰器 @ddt
import unittest
from ddt import ddt, data
@ddt
class TestDemo(unittest.TestCase):
# 单一参数
@data('17611110000', '17611112222')
def test_1(self, phone):
print('测试一电话号码:', phone)
if __name__ == '__main__':
unittest.main()
else:
pass
运行结果:

2、在实际中不可能是单一参数进行传参,将会使用多个参数进行传参:
注意事项:
1)、多个数据传参的时候@data里面是要用列表形式
2)、会用到 @unpack 装饰器 进行拆包,把对应的内容传入对应的参数;
import unittest
from ddt import ddt, data, unpack
@ddt
class TestDemo(unittest.TestCase):
# 多参数数据驱动
@data(["user1", "password1"],
["user2", "password2"],
["user3", "password3"])
# unpack 是进行拆包,不然会把列表里面的数据全部传到username这个一个参数,我们要实现列表中的两个数据分别传入对应的变量中
@unpack
def test_2(self, username, password):
print('测试:', username, password)
if __name__ == '__main__':
unittest.main()
else:
pass
运行结果:

五.Openpyxl框架(也是数据驱动)
ddt框架都是数据在代码当中的,假如要测试n个手机号这样的数据,全部写在 @data 装饰器里面就很麻烦,这就引出了数据驱动里面的代码和数据的分离。
将数据放入一个文本文件中,从文件读取数据, 如JSON、 excel、 xml、 txt等格式文件
- Openpyxl 是用于读取Exel格式数据的工具
import openpyxl
def read_excel_value(file_path, row, column):
# 打开Excel文件
workbook = openpyxl.load_workbook(file_path)
# 选择第一个工作表(如果有多个工作表的话)
# worksheet = workbook.active
worksheet = workbook['Sheet1']
# 读取指定行和列的值
value = worksheet.cell(row=row, column=column).value
return value
file_path = './case/A1000013.xlsx'
value1 = read_excel_value(file_path, 2, 2)
value2 = read_excel_value(file_path, 3, 2)
print(value1)
print(value2)
运行结果:

六.Logging框架
日志简介
- 什么是日志
- 日志也叫 log,通常对应的 xxx.log 的日志文件。文件的作用是记录系统运行过程中,产生的信息。
- 搜集日志的作用
- 查看系统运行是否正常。
- 分析、定位 bug。
日志的级别
- logging.DEBUG:调试级别【高】
- logging.INFO:信息级别【次高】
- logging.WARNING:警告级别【中】
- logging.ERROR:错误级别【低】
- logging.CRITICAL:严重错误级别【极低】
特性:
- 日志级别设定后,只有比该级别低的日志会写入日志。
- 如:设定日志级别为 info。 debug 级别的日志信息,不会写入。infowarning、error、critical 会写入

日志代码实现分析
日志代码,无需手写实现。会修改、调用即可!
代码分析
import logging.handlers
import logging
import time
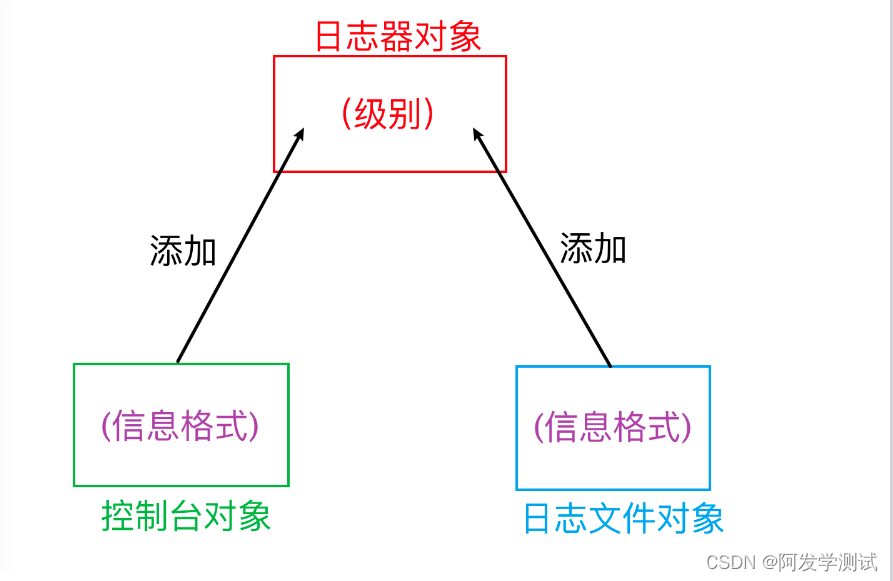
# 1. 创建日志器对象
logger = logging.getLogger()
# 2. 设置日志打印级别
logger.setLevel(logging.DEBUG)
# logging.DEBUG 调试级别
# logging.INFO 信息级别
# logging.WARNING 警告级别
# logging.ERROR 错误级别
# logging.CRITICAL 严重错误级别
# 3.1 创建 输出到控制台 处理器对象
st = logging.StreamHandler()
# 3.2 创建 输出到日志文件 处理器对象
fh = logging.handlers.TimedRotatingFileHandler('a.log', when='midnight', interval=1,
backupCount=3, encoding='utf-8')
# when 字符串,指定日志切分间隔时间的单位。midnight:凌晨:12点。
# interval 是间隔时间单位的个数,指等待多少个 when 后继续进行日志记录
# backupCount 是保留日志文件的个数
# 4. 创建日志信息格式
fmt = "%(asctime)s %(levelname)s [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s"
formatter = logging.Formatter(fmt)
# 5.1 日志信息格式 设置给 控制台处理器
st.setFormatter(formatter)
# 5.2 日志信息格式 设置给 日志文件处理器
fh.setFormatter(formatter)
# 6.1 给日志器对象 添加 控制台处理器
logger.addHandler(st)
# 6.2 给日志器对象 添加 日志文件处理器
logger.addHandler(fh)
# 7. 打印日志
while True:
# logging.debug('我是一个调试级别的日志')
# logging.info('我是一个信息级别的日志')
logging.warning('test log sh-26')
# logging.error('我是一个错误级别的日志')
# logging.critical('我是一个严重错误级别的日志')
time.sleep(1)
日志使用
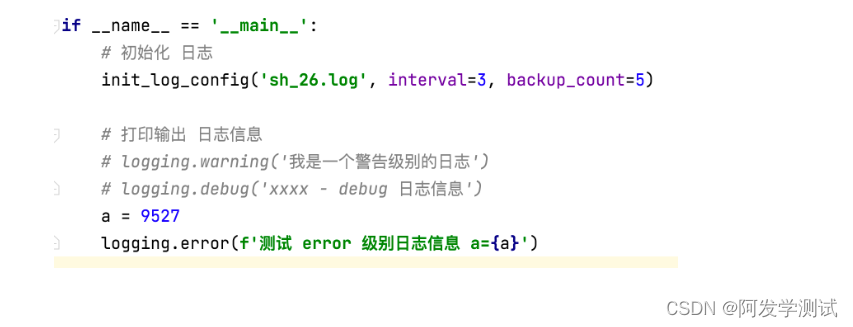
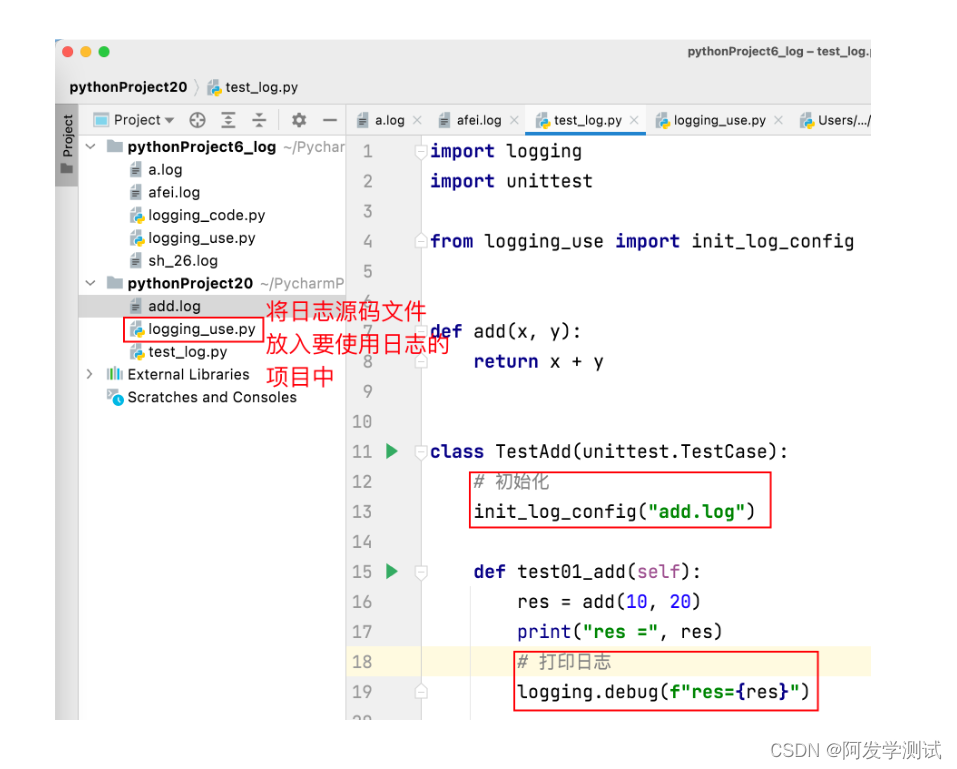
可修改的位置

使用步骤:
- 调用 init_log_config() 函数,初始化日志信息。
- 指定 日志级别,打印 日志信息。
七.Pymysql框架
数据库操作应用场景
-
校验 测试数据
- 接口发送请求后明确会对数据库中的某个字段进行修改,但,响应结果中无该字段数据时。
- 如:ihrm 删除员工接口。 is_delete 字段,没有 在响应结果中出现! 需要 借助数据库 校验!
- 接口发送请求后明确会对数据库中的某个字段进行修改,但,响应结果中无该字段数据时。
-
构造 测试数据
- 测试数据使用一次就失效。
- 如:ihrm 添加员工接口,使用的手机号!
- 测试前,无法保证测试数据是否存在。
- 如:ihrm 查询员工接口,使用的 员工id
- 测试数据使用一次就失效。
操作步骤
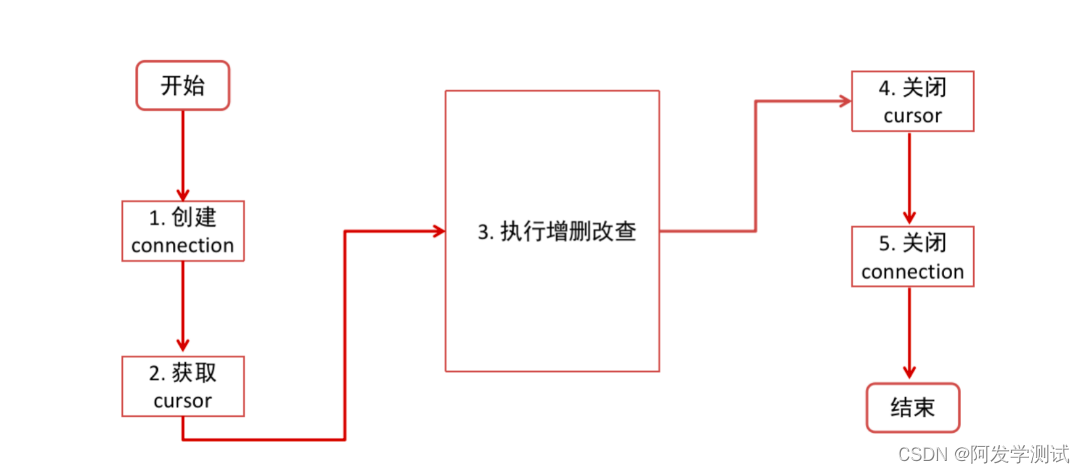
- 导包 import pymysql
- 创建连接。 conn = pymysql.connect(host,port, user, password, database, charset)
- 获取游标。 cursor = conn.cursor()
- 执行 SQL。 cursor.execute( ”sql语句“ )
- 查询语句(select)
- 处理结果集(提取数据 fetch*)
- 增删改语句(insert、update、delete)
- 成功:提交事务 conn.commit()
- 失败:回滚事务 conn.rollback()
- 查询语句(select)
- 关闭游标。cursor.close()
- 关闭连接。conn.close()
1.PyMySQL连接数据库
建立连接方法
conn = pymysql.connect(host="", port=0,
user="", password="", database="", charset="")
host:数据库所在主机 IP地址 - string
port:数据库使用的 端口号 - int
user:连接数据库使用的 用户名 - string
password:连接数据库使用的 密码 - string
database:要连接的那个数据库的名字 - string
charset:字符集。常用 utf8 - string
conn:连接数据库的对象。
入门案例
查询数据库,获取MySQL服务器 版本信息
# 1. 导包
import pymysql
# 2. 建立连接
conn = pymysql.connect(host="211.103.136.244", port=7061, user="student",password="iHRM_student_2021", database="test_db", charset="utf8")
# 3. 获取游标
cursor = conn.cursor()
# 4. 执行 sql 语句(查询)
cursor.execute("select version()")
# 5. 获取结果
res = cursor.fetchone()
print("res =", res[0])
# 6. 关闭游标
cursor.close()
# 7. 关闭连接
conn.close()
2.PyMySQL操作数据库
查询操作流程
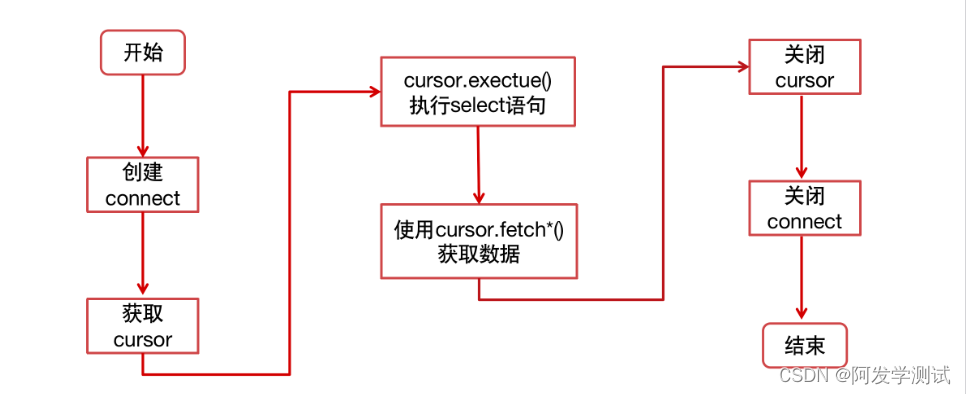
cursor游标
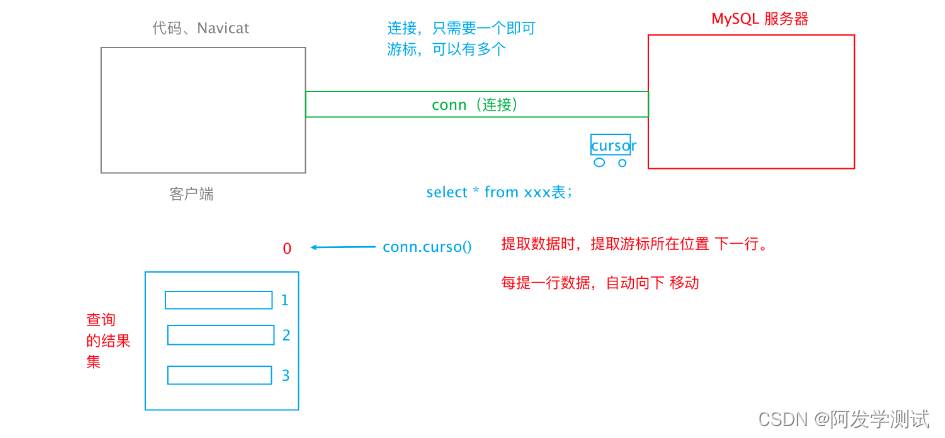
常用方法
- fetchone():从结果集中,提取一行。
- fetchmany(size):从结果集中,提取 size 行。
- fetchall():提取所有结果集。
- 属性rownumber:可以设置游标位置。
案例
查询t_book表,获取 第一条 数据
查询t_book表,获取 前两条 数据
查询t_book表,获取 全部 数据
查询t_book表,获取 第3条和第4条 数据
# 1. 导包
import pymysql
# 2. 建立连接
conn = pymysql.connect(host="211.103.136.244", port=7061, user="student",
password="iHRM_student_2021", database="test_db", charset="utf8")
# 3. 获取游标
cursor = conn.cursor() # 指向 0 号位置。
# 4. 执行 sql 语句(查询)--- t_book
cursor.execute("select * from t_book;")
# 5. 获取结果 - 提取第一条
res1 = cursor.fetchone()
print("res1 =", res1)
# 修改游标位置:回零
cursor.rownumber = 0
# 5. 获取结果 - 提取前 2 条
res2 = cursor.fetchmany(2)
print("res2 =", res2)
# 修改游标位置:回零--查询全部数据
cursor.rownumber = 0
res3 = cursor.fetchall()
print("res3 =", res3)
# 修改游标位置:指向第 2 条记录
cursor.rownumber = 2
res4 = cursor.fetchmany(2)
print("res4 =", res4)
# 6. 关闭游标
cursor.close()
# 7. 关闭连接
conn.close()
事务的概念
- 事务,是关系型数据库(mysql)特有的概念。
- 事务,可以看做一个虚拟的 容器,在容器中存放一系列的数据库操作,看做一个整体。内部的所有操作,要
么都一次性全部成功,只要有一个失败,就全部失败!
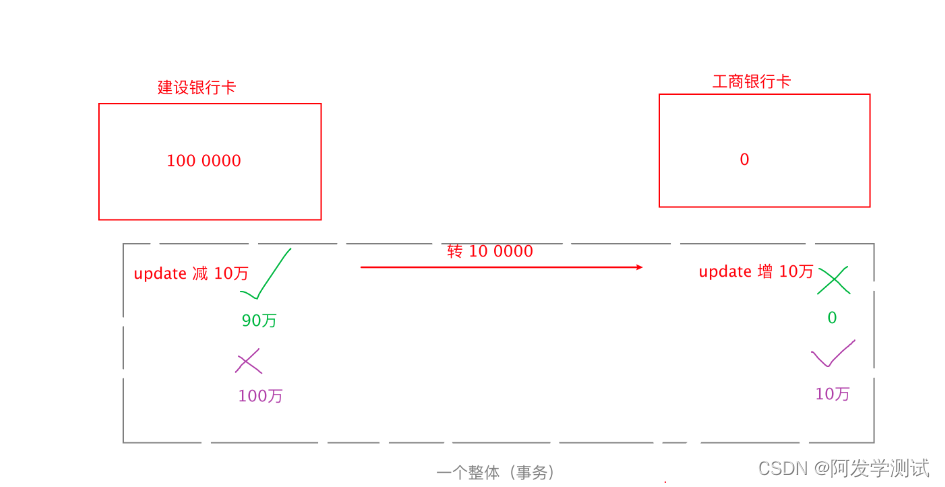
- 事务操作:只有 2 种情况
- 提交:conn.commit()
- 回滚: conn.rollback()
八、jenkins
持续集成
概念:
- 团队成员将自己的工作成果,持续集成到一个公共平台的过程。成员可以每天集成一次,也可以一天集成多
次。
相关工具:
- 本地代码管理:git
- 远程代码管理:gitee(国内)、github(国外)、gitlib(公司私有服务器)
- 持续集成:jenkins
持续集成,可以自动构建执行代码,定时发送邮件。