1.意义
两个假设:一个是假设源信号是相互统计独立的,另一个是假设己知源信号的统计分布特征。
另一个假设是信号的非高斯性,现实世界的许多信号,诸如绝大多数的语音信号和图像信号即是服从非高斯分布的这个假设的可应用性,带来了独立成分分析的重要特征,即
实际信号的统计特性仅用普通的基于二阶统计量方法是不能反映的,独立成分分析追求的是信号的高阶统计信息,
2.定义
ICA与其它的方法重要的区别在于,它寻找满足统计独立和非高斯的成分。
与因子分析区别:
在因子分析中,经常声称因子之间是统计独立的,这个说法只是部分正确,因为因子分析假设因子是服从高斯分布的,找到独立的方法相当容易(对于高斯分布的成分来说,不相关与独立是等价的)。
而在现实世界中,数据通常并不服从高斯分布,假设成分服从高斯分布的方法在这种情况下是失效的.
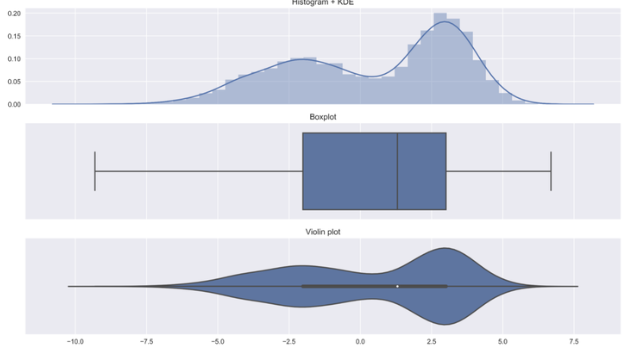
超高斯分布的(supergaussian).这意味着随机变量更经常的在零附近取值,与相同方差的高斯密度相比,超高斯分布在零点更尖!
问题提炼:
ICA任务:在只知道观测信号X的T个样本x(1),…,x(T),且在源信号S和混合矩阵A未知的条件下,假设源信号si(0=1,…,n)之间是相互统计独立的,来求解混合矩阵A和源信号s。
注意:
①一般的,在标准的独立成分分析中最多只允许有一个成分服从高斯分布。如果独立成分中有两个以上的高斯成分,用标准的独立成分分析来处理这样的数据是不可能的。标准的独立成分分析只挖掘数据的非高斯结构
ICA参考:
ICA全,多链接(含matlab code)
MLE原理版-好
面最广,可参考要了解的all知识点。但逻辑深入解释不清楚
FastICA 知乎原理过程
FastICA 知乎原理过程基础上理解 csdn(含matlab code)
辨析
白化 -预处理过程之一
对数据做白化处理必须满足两个条件:
使数据的不同维度去相关;
使数据每个维度的方差为1;
条件1要求数据的协方差矩阵是个对角阵;条件2要求数据的协方差矩阵是个单位矩阵。
目的:降低输入的冗余性。
ICA中:去除各观测信号之间的相关性,从而简化了后续独立分量的提取过程,而且,通常情况下,比不对数据进行白化处理相比,算法的收敛性较好。
经过白化处理的输入数据具有如下性质:
(i)特征之间相关性较低;(ii)所有特征具有相同的方差。
PCA白化,ZCA白化

经过 PCA 白化以后,其协方差矩阵是一个单位矩阵,即各维度变得不相关,且每个维度方差都是 1。
特征值分解、奇异值分解
只是对方阵而言

补充:特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么
EVD SVD逻辑很清楚版
PCA、ICA
PCA:数据降维,但是只对符合高斯分布的样本点比较有效
梯度下降法意义
为什么需要梯度下降?
因为相对一个函数直接求导等于0(MLE求解过程),从而求得位置参数,计算机更适合迭代,在计算量较小时,直接求导得到解析解速度占优,而在深度学习中全部是以矩阵的方式进行求导,且数据量很大,所以计算机更适合迭代式的梯度下降从而得到数值解。不能直接求导

梯度下降
梯度下降法与牛顿法比较 GD-牛顿
比较 较全
牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。
如果更通俗地说的话,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。(牛顿法目光更加长远,所以少走弯路;相对而言,梯度下降法只考虑了局部的最优,没有全局思想。)
【鞍点】在高维非凸优化问题中,鞍点相对于局部最小值的数量非常多,而且鞍点处的损失值相对于局部最小值处也比较大。而二阶优化算法是寻找梯度为0的点,所以很容易陷入鞍点;而梯度下降法目标寻找更小f(x),更容易逃离鞍点。
=======
拓展
e.g:
信号处理领域有如下约定:峰度值为正值的随机变量称为超高斯分布的随机变量(super-gaussian);–拉普拉斯分布(Laplacian distribution)
峰度值为负值的随机变量称为亚高斯分布的随机变量(sub-gaussian);–均匀分布(Uniform distribution)
而高斯分布的随机变量的峰度值为零。
e.g:
盲源分离问题(blind source separation,BSS).盲指的是源信号未知,混合系统未知(混合系数未知)。