目录
- 涉及资源:
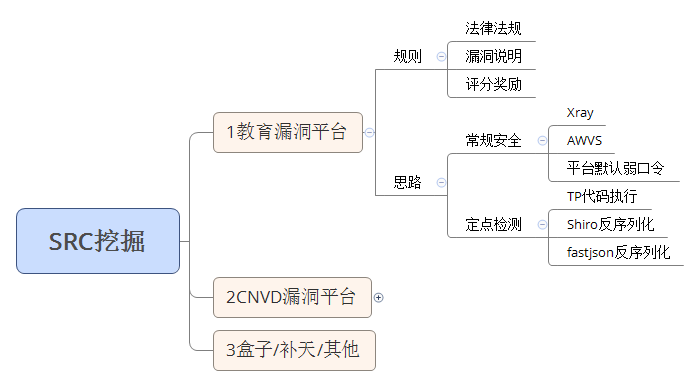
专属SRC范围小,所以难度大一些

CNVD挖到的漏洞要有一些影响面,才能拿到证书

教育漏洞平台给的面是很大的,给很多目标,我们按照常规思路来讲的话,自己去手工测试和提交这些漏洞,这个是不现实的,因为要花很多时间,用手工去挖掘漏洞,效率不高,而且非常麻烦,不可能每个网站,我们都去搞一下
像edu这种平台,我们去提交漏洞,如果是小白,没有办法找到漏洞,只能去挖自己学校的漏洞去提交,那么它只能提交这个学校的漏洞,其它学校的漏洞就不知道了,那就会对我们小礼品和排名都会有影响
我们挖edu,一般利用的都是批量,先用脚本把目标的信息资产给爬下来,然后使用扫描器对信息资产进行扫描,然后对扫描完的结果进行验证
定点检测可以根据最新的漏洞,影响面比较大的漏洞,这些漏洞在网上都有利用的代码和批量检测的脚本,如果是最新的漏洞那可能只会有一些漏洞详情,它不会有这些批量漏洞检测脚本
这个时候就需要我们单独开发,所以这里就会涉及到python的知识点,或者你懂其它的语言你能写出来也可以
定点检测就是根据特定的漏洞进行检测,例如TP代码执行、Shiro反序列化、fastjson反序列化
2020年漏洞复现大全:https://github.com/TimelineSec/2020-Vulnerabilities
这个项目就是之前人整理的漏洞复现项目,这个资料就是让你了解漏洞是如何实现的,资料再结合你的开发知识,去写那个批量的脚本
一般的漏洞复现,我们是可以使用脚本去写poc的,如果碰到复现过程复杂的,那可能会复现不出来
大部分都是web类的,无非是用python里面的请求库去实现,如果还有一些不能实现的话,那就需要你单独去实现
我们在挖src的时候,挖出来漏洞就可以了,不要去把它数据搞出来呀什么的,大家只需要验证漏洞的存在性就可以了,不要去影响它业务的正常功能,你乱搞的话,可能就GG了

危害比较小或者无关紧要的就不会收了,提交漏洞尽量写的详细,图片上传上去,不要说单独的文字说一下,写漏洞详情的时候,文字表达能力也是重要的,漏洞危害写的玄乎一点,说不定等级就会评高了,比如我们写个sql漏洞,看这个权限低的,只能注入到漏洞,把它写上去能获取到什么数据库权限,搞几个截图,它就会认为的确会获取到数据库权限,能在后期做很多事情,这样子它就会把你评到高危漏洞
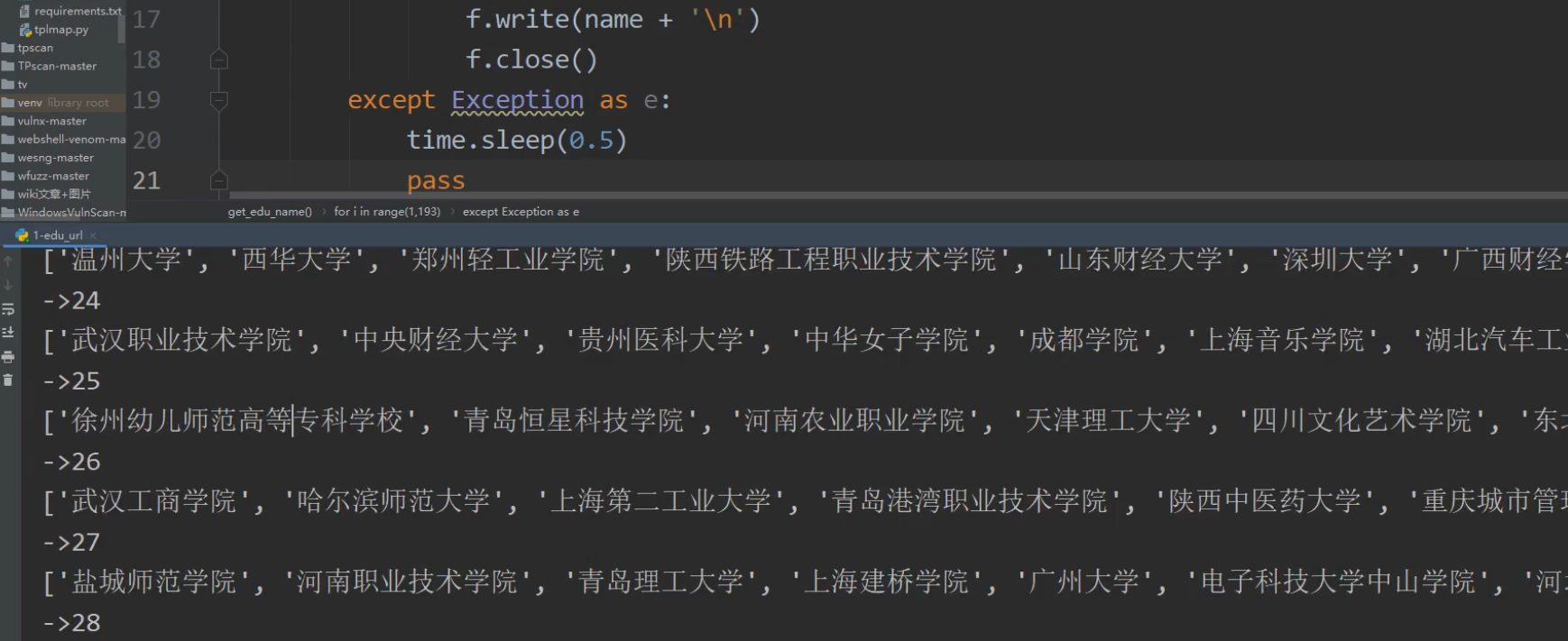
使用脚本爬取edu网站上的目标信息
import requests # requests模块是用来发送网络请求的 安装:pip install requests
from lxml import html # lxml 提取HTML数据,安装:pip install lxml
import threading # 导入threading模块实现多线程
# 从教育漏洞报告平台中提取之前网络安全的前辈提交的漏洞报告
etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
def src_tiqu(Start,End):
"""
src_tiqu 从教育漏洞报告平台中提取之前网络安全的前辈提交的漏洞报告
:param Start: 开始爬取的页数
:param End: 结束爬取的页数
:return: None
"""
for i in range(Start,End + 1):
url='https://src.sjtu.edu.cn/list/?page='+str(i) # range(num1,num2) 创建一个数序列如:range(1,10) [1,2,...,9] 不包括num2自身
print(f'正在读取{Start}~{End}页数据')
try:
data = requests.get(url).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据
# print(data.decode('utf-8')) # 请求返回的HTML代码
soup = etree.HTML(data)
result = soup.xpath('//td[@class="am-text-center"]/a/text()') # 提取符合标签为td属性class值为am-text-center这个标签内的a标签text()a标签的值/内容
results = '\n'.join(result).split() # join()将指定的元素以\n换行进行拆分在拼接 split()方法不传参数就是清除两边的空格
print(results)
for edu in results: # 遍历results列表拿到每一项
# print(edu)
with open(r'src_edu.txt', 'a+', encoding='utf-8') as f: # open()打开函数 with open打开函数与open()的区别就是使用完成后会自动关闭打开的文件 a+:以读写模式打开,如果文件不存在就创建,以存在就追加 encoding 指定编码格式
f.write(edu + '\n')
except Exception as e:
pass
if __name__ == '__main__': # __main__ 就是一个模块的测试变量,在这个判断内的代码只会在运行当前模块才会执行,在模块外部引入文件进行调用是不会执行的
yeshu = int(input("您要爬取多少页数据(整数):"))
thread = 10 # 控制要创建的线程
# 创建多线程,这个循环的次数越多创建的线程的次数就越多,线程不是越多越好,建议5到10个
for x in range(1,thread + 1):
i = int(yeshu / thread) # 页数除线程数(目的是让每一个线程都获取部分数据,分工)
End = int(i * x) # 结束的页数,设yeshu=50: 5、10、15、20、25...
Start = int(i * (x-1) +1) # 开始的页数, 1、6、11、16、21
# 我上面这样写的目的就是,让线程分工合作。如:线程1就去获取1 -5页的数据、线程2就去获取6 -10页的数据...
print(Start,End)
t = threading.Thread(target=src_tiqu,kwargs={"Start":Start,"End":End}) # 创建线程对象,target=执行目标任务名,args 以元组的形式传参,kwargs 以字典的形式传参
t.start() # 启动线程,让他开始工作
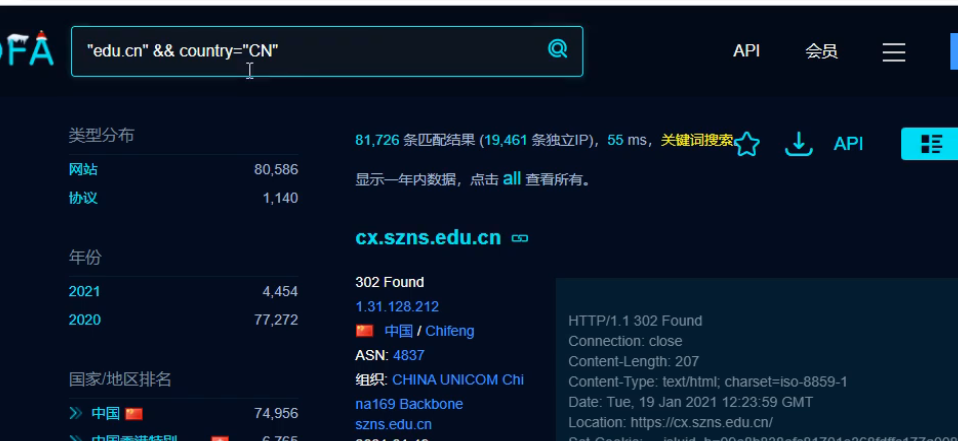
使用fofa收集目标信息
import requests # requests模块是用来发送网络请求的 安装:pip install requests
import base64
from lxml import html # lxml 提取HTML数据,安装:pip install lxml
import time
import threading # 导入threading模块实现多线程
def fofa_tiqu(Start,End):
# 循环切换分页
search_data = '"edu.cn"&& country="CN"' # edu.cn搜索的关键字, country 查询的国家 CN 中国
url = 'https://fofa.info/result?qbase64=' # fofa网站的url ?qbase64= 请求参数(需要base64字符串格式的参数)
search_data_bs = str(base64.b64encode(search_data.encode("utf-8")), "utf-8") # 把我们的搜索关键字加密成base64字符串
headers = { # 请求的头部,用于身份验证
# cookie 要改成你自己的,我的账号一退出,这cookie就会过期了
'cookie':'fofa_token=eyJhbGciOiJIUzUxMiIsImtpZCI6Ik5XWTVZakF4TVRkalltSTJNRFZsWXpRM05EWXdaakF3TURVMlkyWTNZemd3TUdRd1pUTmpZUT09IiwidHlwIjoiSldUIn0.eyJpZCI6MjUxMjA0LCJtaWQiOjEwMDE0MzE2OSwidXNlcm5hbWUiOiLpk7bmsrMiLCJleHAiOjE2ODAzNzI2NTd9.h_uVySL9-8aIk2TLbK8UseKkbJBxW2pIXvQ1WwnWRhh-fGoneK48kDQ5XYsTemRThPINHj_tLfNmd9WLJ8pDxg;'
}
# 循环爬取数据
for yeshu in range(Start,End + 1): # range(num1,num2) 创建一个数序列如:range(1,10) [1,2,...,9] 不包括num2自身
try:
# print(yeshu) # 1,2,3,4,5,6,7,8,9
urls = url + search_data_bs + "&page=" + str(yeshu) # 拼接网站url,str()将元素转换成字符串,page页数, page_size每页展示多少条数据
print(f"正在提取第{yeshu}页数据-{urls}")
# urls 请求的URL headers 请求头,里面包含身份信息
result = requests.get(urls, headers=headers).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据
etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
# print(result.decode('utf-8')) # 查看返回结果
soup = etree.HTML(result) # result.decode('utf-8') 请求返回的HTML代码
ip_data = soup.xpath('//span[@class="hsxa-host"]/a[@target="_blank"]/@href') # 公式://标签名称[@属性='属性的值'] ,意思是先找span标签class等于hsxa-host的然后在提取其内部的a标签属性为@target="_blank"的href属性出来(就是一个筛选数据的过程,筛选符合条件的)
# set() 将容器转换为集合类型,因为集合类型不会存储重复的数据,给ip去下重
ipdata = '\n'.join(set(ip_data)) # join()将指定的元素以\n换行进行拆分在拼接(\n也可以换成其他字符,不过这里的需求就是把列表拆分成一行一个ip,方便后面的文件写入)
if 'http' in ipdata: # 判断ipdata中是否存在http字符串,存在说明数据获取成功
print(f"第{yeshu}页数据{ipdata}")
with open(r'ip.txt', 'a+') as f: # open()打开函数 a+:以读写模式打开,如果文件不存在就创建,以存在就追加
f.write(ipdata) # write() 方法写入数据
except Exception as e:
pass
if __name__ == '__main__': # __main__ 就是一个模块的测试变量,在这个判断内的代码只会在运行当前模块才会执行,在模块外部引入文件进行调用是不会执行的
yeshu = int(input("您要爬取多少页数据(整数):"))
thread = 5 # 控制要创建的线程,本来开10个但是太快了服务器反应不过来,获取到的数据少了很多
# 创建多线程,这个循环的次数越多创建的线程的次数就越多,线程不是越多越好,建议5到10个
for x in range(1,thread + 1):
i = int(yeshu / thread) # 页数除线程数(目的是让每一个线程都获取部分数据,分工)
End = int(i * x) # 结束的页数,设yeshu=50: 5、10、15、20、25...
Start = int(i * (x-1) +1) # 开始的页数, 1、6、11、16、21
# 我上面这样写的目的就是,让线程分工合作。如:线程1就去获取1 -5页的数据、线程2就去获取6 -10页的数据...
# print(Start,End)
t = threading.Thread(target=fofa_tiqu,kwargs={"Start":Start,"End":End}) # 创建线程对象,target=执行目标任务名,args 以元组的形式传参,kwargs 以字典的形式传参
t.start() # 启动线程,让他开始工作
有了这些信息之后,就可以用awvs和xray进行批量的测试
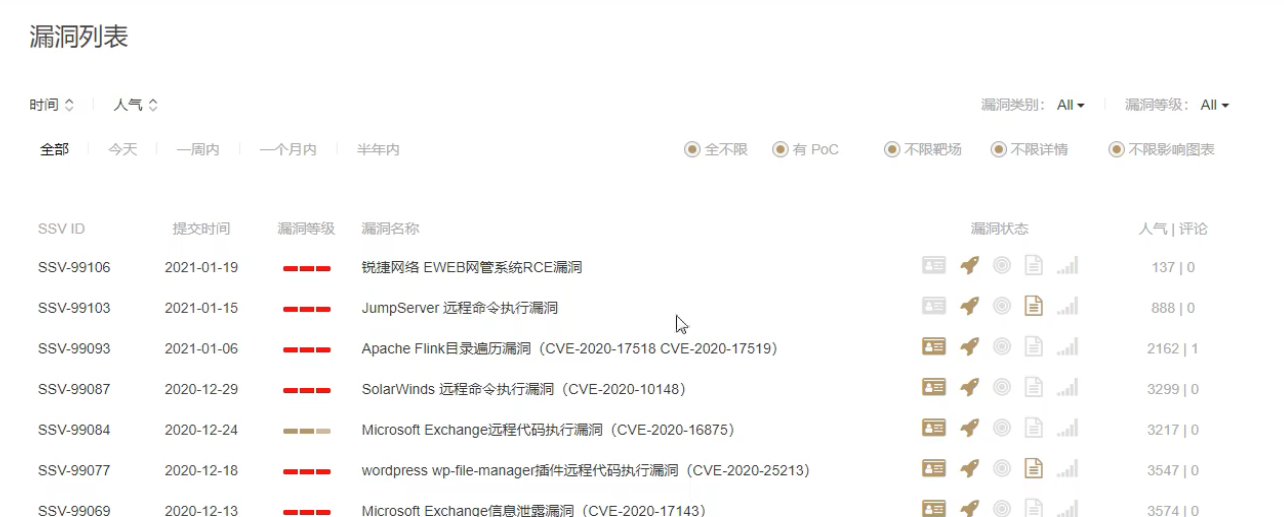
进行特定检测的时候,一定要选取一些漏洞层面高的,又是比较新的漏洞,你如果用一些老的,就没什么意义,在官网这个地方找有POC的就完事了

这个就是它的poc
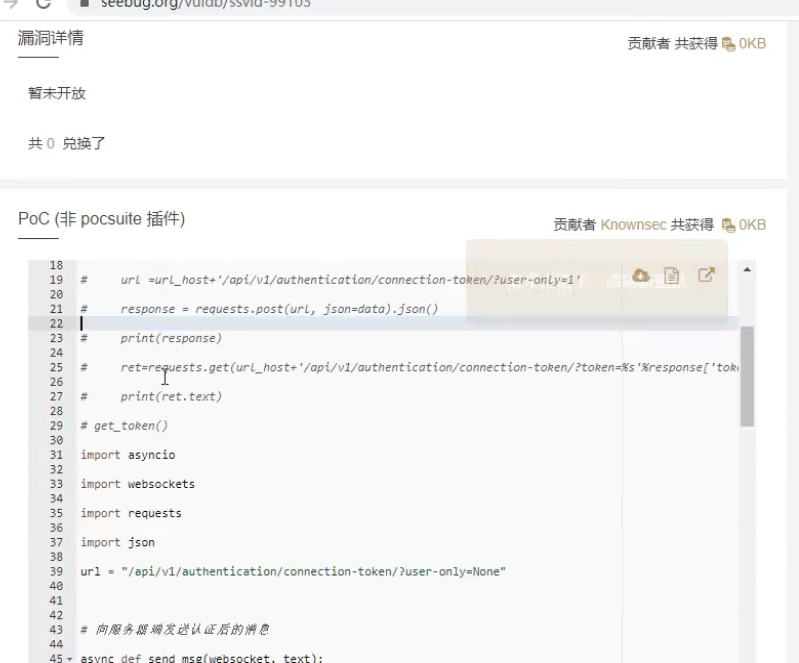
我们可以根据我们的python知识,把poc改成批量的
fofa搜索这个漏洞的edu资产
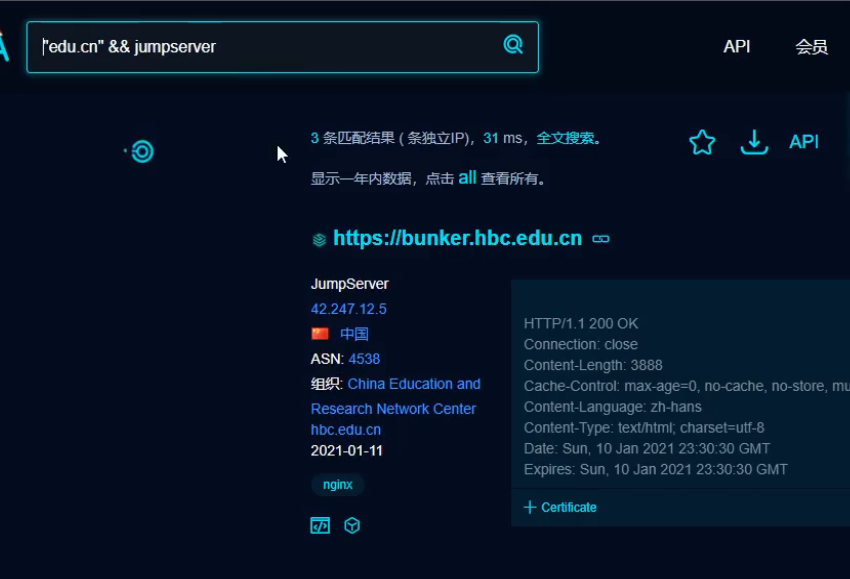
我们可以在网上搜索有没有这个漏洞的复现文章
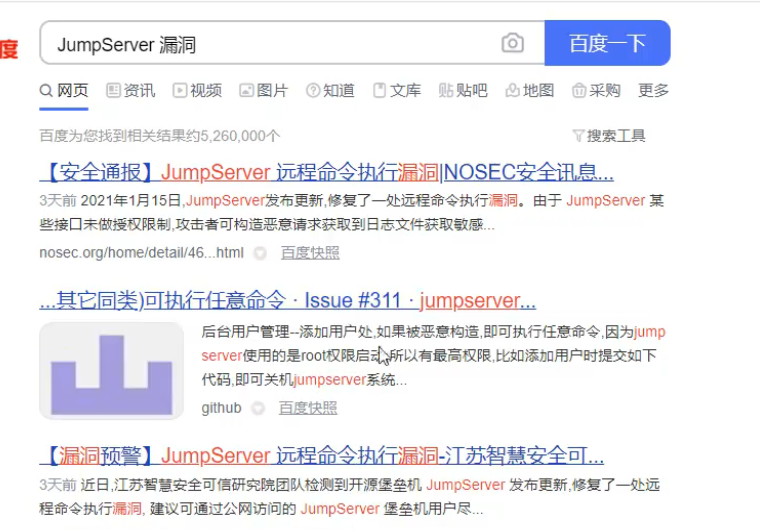
通过关键字利用fofa,把它一筛,进行批量化的特定检测
我们跑50万个域名,那怕万分之一的概率命中,就有50个,50个一提交,那排名不是就嗖的一下上去了吗,这种批量挖漏洞是没有什么技术讲究的
像专属SRC就是要人工去测试了,不能用批量化的思路去弄,因为它的范围太小了,目标里面可能有业务
涉及资源:
知道创宇:https://www.seebug.org/
360网络空间测绘:https://quake.360.net/quake/#/index
2020年漏洞复现大全:https://github.com/TimelineSec/2020-Vulnerabilities
大部分设备的默认口令:https://github.com/ihebski/DefaultCreds-cheat-sheet