目录
认识线程(Thread)
概念
为什么会有线程的出现?
刨根问底。为什么进程的创建与销毁效率很低呢?
多线程的轻量体现:
进程与线程的区别
第一个多线程程序
抢占式执行是啥
JDK中jconsole工具的使用
创建线程
多线程并发执行演示
Thread 类及常见方法
Thread 的常见构造方法
Thread 的常见属性
前台线程和后台线程分别适用于哪些场景呢?
启动线程
start与run的区别
中断线程
Interrupt的运行机制
等待一个线程-join()
join的一些方法
获取当前线程引用
休眠当前线程
认识线程(Thread)
概念
什么是线程?
一个线程就是一个“执行流”,每个线程之间都可以按照顺序执行自己的代码,多个线程之间“同时”执行的多份代码。
为什么会有线程的出现?
首先, 并发编程在日常生活中不可缺少. 其次,虽然多进程也能实现 并发编程, 但是线程比进程更轻量。
谈到线程,避免不了的是想到进程(进程的一些概念,在博主的另一篇文章——进程的相关介绍),其实我们知道,进程存在的意义:让操作系统可以同时执行多个任务,进而实现“并发编程”效果。
既然进程和线程都可以实现并发编程,那为什么还需要线程的出现呢?
:因为频繁的创建/销毁进程,这个操作比较低效。
🎈🎈例如:写一个服务器程序,就可以针对每个客户端分别创建一个进程,去提供服务,
服务器这里可能会出现多个客户端来来回回,每次客户端出现,就需要创建一个进程来服务,客户端离开,就需要销毁进程,上述过程中,进程的创建与销毁太频繁,效率是比较低的。
刨根问底。为什么进程的创建与销毁效率很低呢?
首先我们需要了解,进程的创建与销毁所对应的步骤:
进程的创建:
- 创建PCB
- 给进程分配资源(内存/文件),赋值到PCB中。
- 把PCB插入链表中。
进程的销毁的步骤:
- 把PCB从链表中删除
- 把PCB中持有的链表资源进行释放
- 销毁PCB
上述过程中:给进程分配资源,以及将PCB中持有的资源释放,这两者对于操作系统的开销是巨大的。
多线程的轻量体现:
只有创建第一个线程的时候,需要2.申请资源,后续再创建新的线程,都是共用同一份资源(节约了申请资源的开销),销毁进程的时候,也只是销毁到最后一个的时候,才真正的释放资源,前面的线程销毁,都不必真释放资源。
✨✨注意:这里所说的并发编程:并发+并行。
总得来说:
首先, "并发编程" 成为 "刚需".
- 单核 CPU 的发展遇到了瓶颈. 要想提高算力, 就需要多核 CPU. 而并发编程能更充分利用多核 CPU资源.
- 有些任务场景需要 "等待 IO", 为了让等待 IO 的时间能够去做一些其他的工作, 也需要用到并发编程.
其次,虽然 多进程 也能实现 并发编程, 但是线程比进程更轻量.
- 创建线程比创建进程更快.
- 销毁线程比销毁进程更快.
- 调度线程比调度进程更快.
最后, 线程虽然比进程轻量, 但是人们还不满足, 于是又有了 "线程池"(ThreadPool) 和 "协程"
(Coroutine)。
进程与线程的区别
- 进程之间包含线程,每个进程至少有一个线程的存在,即主线程。
- 线程比进程更轻量,创建更快,销毁也更快。
- 同一个进程的多个线程之间共用同一份内存/文件资源。进程和进程之间的区别,则是独立的内存/文件资源。
- 进程是系统分配资源的最小单位,线程是系统调度的最小单位。
第一个多线程程序
感受多线程程序和普通程序的区别:
- 每个线程都是一个独立的执行流
- 多个线程之间是 "并发" 执行的
简易版本:
/**
* 标准库中,提供了一个Thread类,使用的时候就可以继承这个类,这就相当于
* 是对操作系统中的线程进行封装
*/
class MyThread extends Thread {
//这里需要重写run方法,run里面的逻辑就是这个线程需要执行的工作
//创建子类,并且重写run方法,相当于是重新安排工作。
@Override
public void run() {
System.out.println("hello thread!");
}
}
public class Demo1 {
public static void main(String[] args) {
//这里需要注意的是:创建一个MyThread实例,创建实例,并不会在系统中真的创建一个线程
//调用start方法的时候,才是真正创建一个新的线程。
//而新的线程就会启动run里面的逻辑,直到run里面的代码执行完,新的线程就运行结束
MyThread t = new MyThread();
t.start();
}
}运行结果:
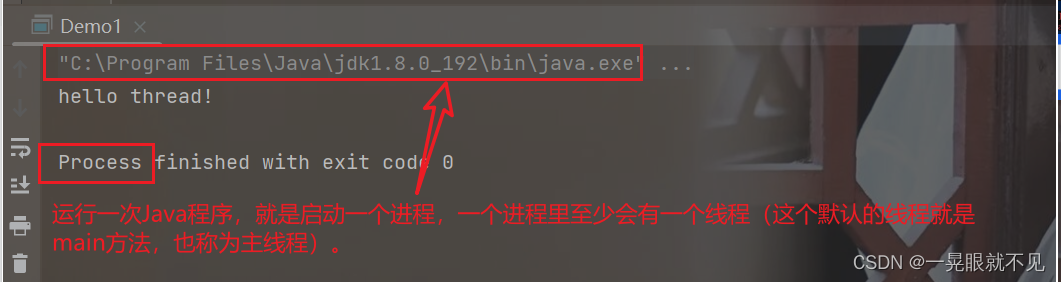
需要注意的是:
main主线程,和MyThread创建出来的新线程,是一个“并发执行”的关系。(这里的并发,仍是指,并发+并行)。
剖析:
在这个代码中,其实只有一个进程,两个线程,一个是main方法对应的主线程(JVM创建的,main就相当于线程的入口方法),另一个线程是MyThread, run就是这个新线程的入口方法。
小进阶:
/**
* Created with IntelliJ IDEA.
* Description:
* User: 86136
* Date: 2023-01-04
* Time: 15:44
*/
/**
* 标准库中,提供了一个Thread类,使用的时候就可以继承这个类,这就相当于
* 是对操作系统中的线程进行封装
*/
class MyThread extends Thread {
//这里需要重写run方法,run里面的逻辑就是这个线程需要执行的工作
//创建子类,并且重写run方法,相当于是重新安排工作。
@Override
public void run() {
System.out.println("hello thread!");
//在重写的方法中无法通过throws抛出异常。
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public class Demo1 {
public static void main(String[] args) {
//这里需要注意的是:创建一个MyThread实例,创建实例,并不会在系统中真的创建一个线程
//调用start方法的时候,才是真正创建一个新的线程。
//而新的线程就会启动run里面的逻辑,直到run里面的代码执行完,新的线程就运行结束
MyThread t = new MyThread();
t.start();
while(true) {
System.out.println("hello main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
运行结果:

通过观察可以发现:
hello main 和 hello thread 是随机打印出来的,可以得知:操作系统调度线程的时候,是一个“随机”的过程,执行sleep,线程会进入阻塞,sleep时间到,线程恢复就绪状态,参与线程调度,党两个线程都参与调度的时候,谁先谁后,是不确定的。
需要注意的是,这里的随机,并不是数学上概率中的 严格随机,但确实是不能确定的。
抢占式执行是啥
诙谐一点可以说,抢占式执行是多线程编程的“万恶之源”,给多线程编程带来了很多变数,因为写代码的时候可能某些调度顺序下,代码没问题,但是某些调度下就会出现bug,因此编写多线程代码时候,需要考虑所有的可能出现的调度情况,保证每种情况下,都不会出现bug。
JDK中jconsole工具的使用
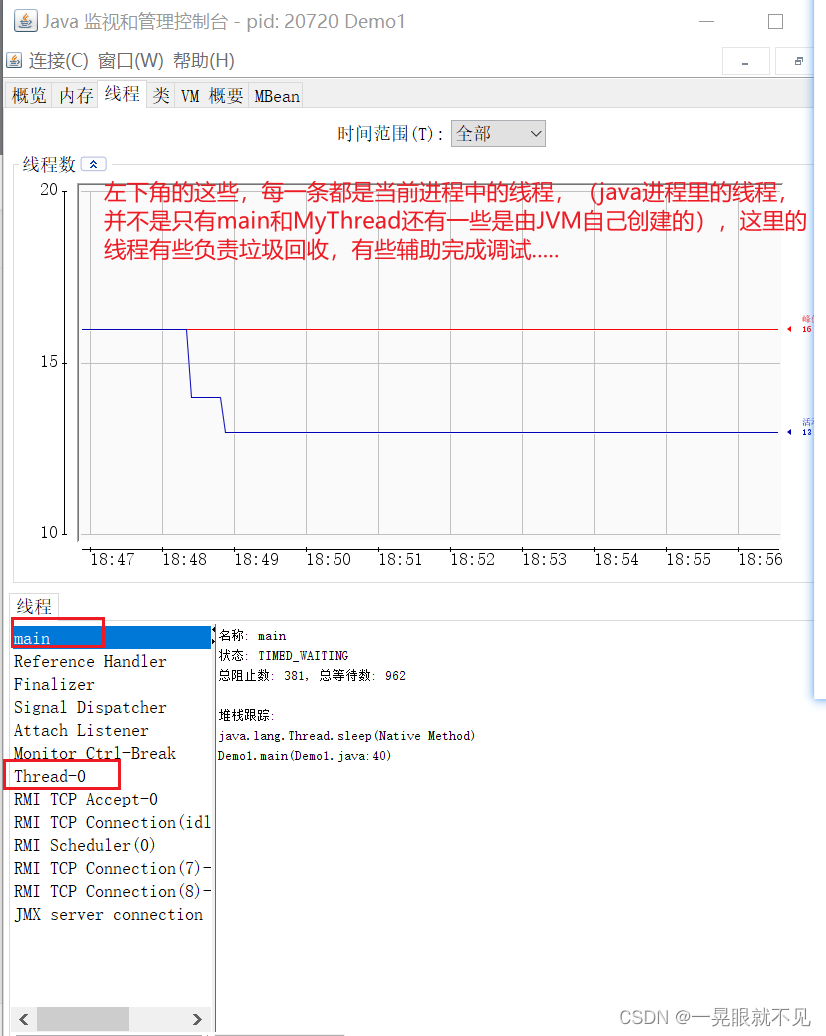
可以利用JDK中的Jconsole来确认 运行中 的程序是不是两个线程。
如果大家忘记自己的jdk放在哪里可以通过idea查看:

后在jdk的bin文件夹中可以找到jconsole(打开里面没有东西的话,需要使用管理员身份打开)。
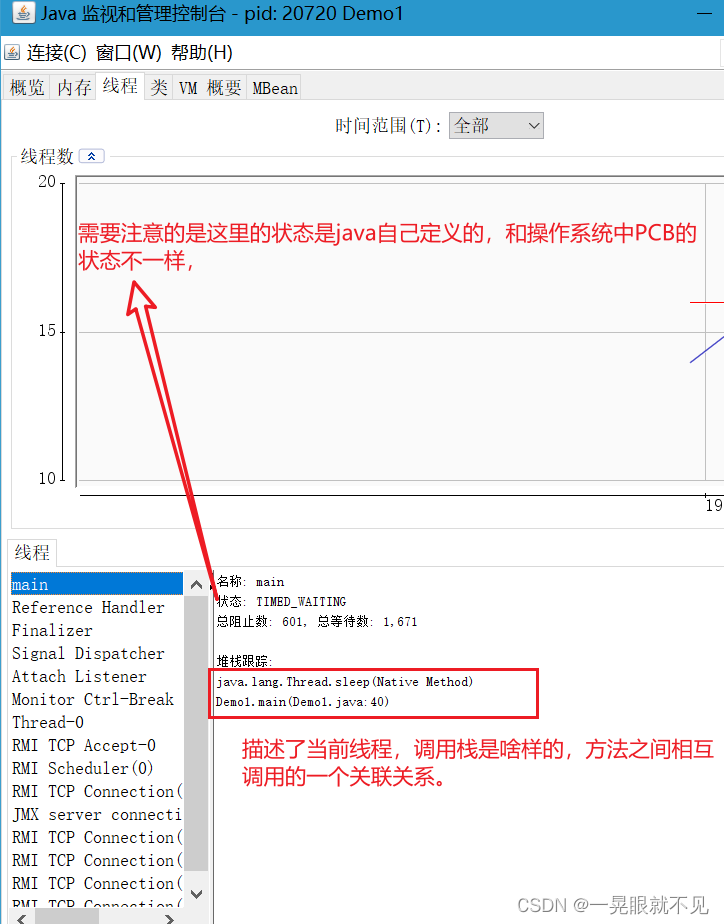
创建线程
上述我们使用了继承Thread,重写run的方法
其实还有多种方法
实现Runnable接口,重写run
/**
* Created with IntelliJ IDEA.
* Description:
* User: 86136
* Date: 2023-01-04
* Time: 19:20
*/
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
//通过重写Runnable 来实现创建线程
/**
* 这样作的好处是把线程干的活和线程本身分开了,使用Runnable来专门表示”线程要完成的工作“
*/
public class Demo2 {
public static void main(String[] args) {
MyRunnable runnable = new MyRunnable();
Thread t = new Thread(runnable);
t.start();
while (true) {
System.out.println("hello main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
使用匿名内部类,实现 创建thread子类的方法
/**
* Created with IntelliJ IDEA.
* Description:
* User: 86136
* Date: 2023-01-04
* Time: 19:35
*/
//使用匿名内部类,来创建 Thread 子类
public class demo3 {
public static void main(String[] args) {
//创建Thread的子类,同时实例化一个对象
Thread t = new Thread() {
@Override
public void run() {
while (true) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
t.start();
while(true) {
System.out.println("hello main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
使用匿名内部类,实现 实现Runnable接口的方式
/**
* Created with IntelliJ IDEA.
* Description:
* User: 86136
* Date: 2023-01-04
* Time: 19:47
*/
public class Demo4 {
public static void main(String[] args) {
Thread t = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
t.start();
}
}
lambda表达式
/**
* Created with IntelliJ IDEA.
* Description:
* User: 86136
* Date: 2023-01-04
* Time: 19:51
*/
public class Demo5 {
public static void main(String[] args) {
Thread t = new Thread(() -> {
while (true) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
}
}
多线程并发执行演示
多线程能够更充分的利用多核CPU,提高程序的效率,以下演示:
/**
* Created with IntelliJ IDEA.
* Description:
* User: 86136
* Date: 2023-01-04
* Time: 20:09
*/
public class demo6 {
public static final long COUNT = 10_0000_0000;
public static void main(String[] args) throws InterruptedException {
// serial();
concurrency();
}
//串行执行任务
public static void serial() {
//记录一个毫秒级别的时间戳
long beg = System.currentTimeMillis();
long a = 0;
for (long i = 0; i < COUNT; i++) {
a++;
}
a = 0;
for (long i = 0; i < COUNT; i++) {
a++;
}
long end = System.currentTimeMillis();
System.out.println("执行的时间间隔:" + (end - beg) +"ms");
}
//并发执行
public static void concurrency() throws InterruptedException {
long beg = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
long a = 0;
for (long i = 0; i < COUNT; i++) {
a++;
}
});
Thread t2 = new Thread(() -> {
long a = 0;
for (long i = 0; i < COUNT; i++) {
a++;
}
});
t1.start();
t2.start();
//当main执行完t1.start 和 t2.start 之后,仍然会继续往前走
//如果t1和t2还没执行完,就计算时间是不合适的,所以需要使用join方法,
//等待main线程执行完t1和t2后才停止计时
t1.join();
t2.join();
long end = System.currentTimeMillis();
System.out.println("执行的时间间隔:" + (end - beg) +"ms");
}
}
通过观察我们可以发现并行执行(图右)比串行执行快了许多
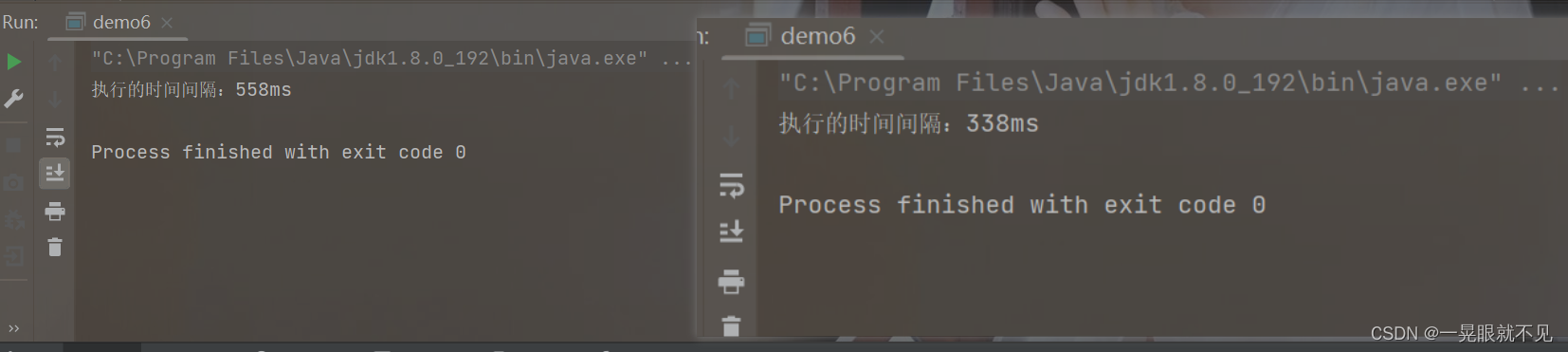
需要注意的是:这里虽然快了许多,但是并没有达到百分之50,是因为并发执行(微观上是 并行+并发),这两个方式在线程执行的过程中,多少次是并发,多少次是并行,是无法确认的。
Thread 类及常见方法
Thread 类是 JVM 用来管理线程的一个类,换句话说,每个线程都有一个唯一的 Thread 对象与之关联。
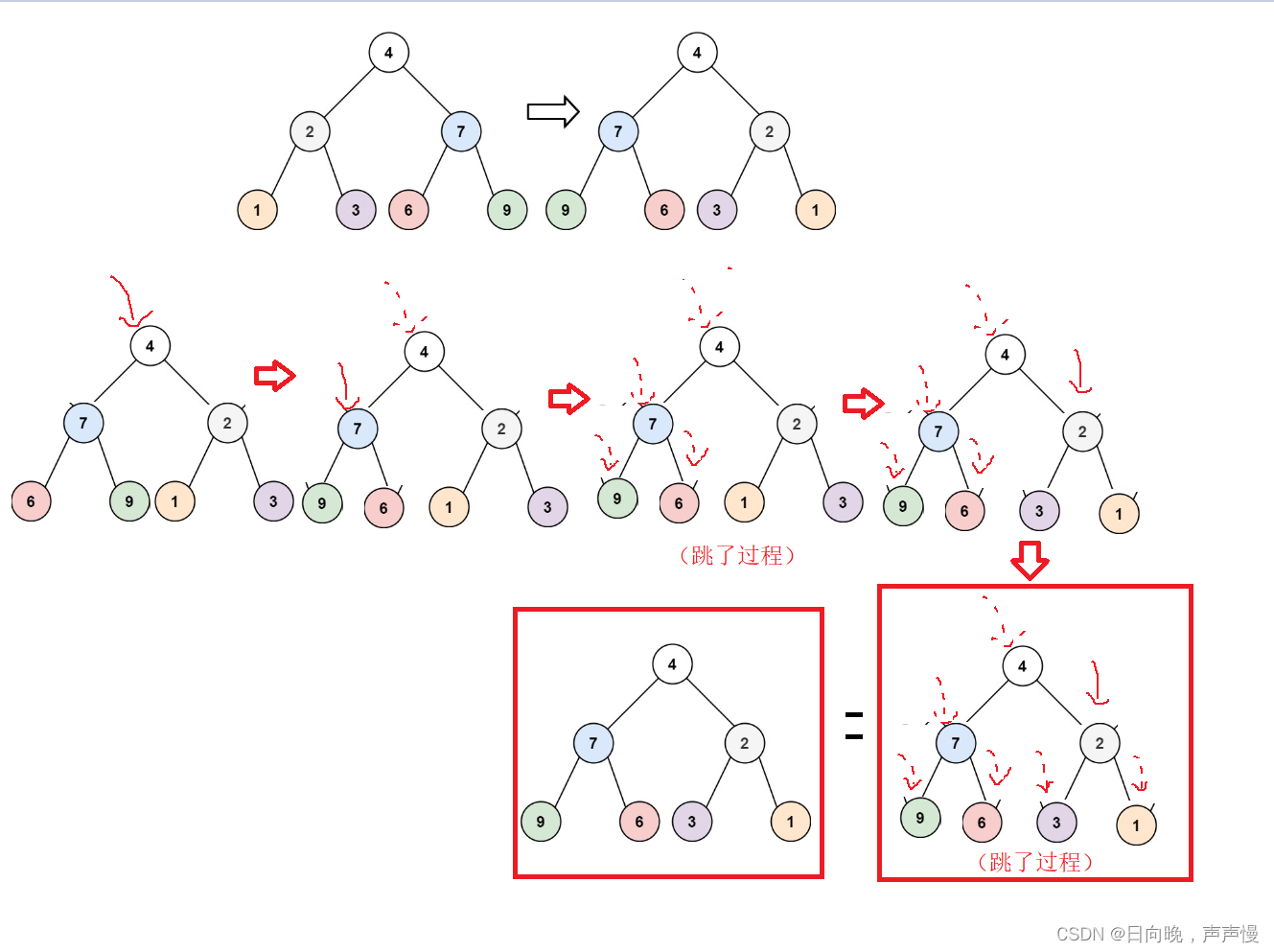
用我们上面的例子来看,每个执行流,也需要有一个对象来描述,类似下图所示,而 Thread 类的对象就是用来描述一个线程执行流的,JVM 会将这些 Thread 对象组织起来,用于线程调度,线程管理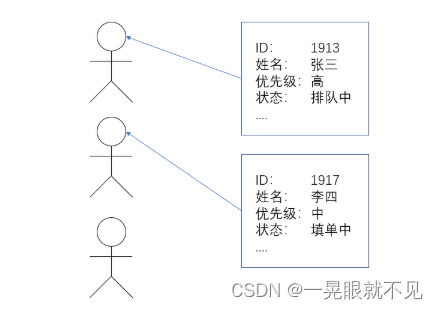
Thread 的常见构造方法
| 方法 | 说明 |
| Thread() | 创建线程对象 |
| Thread(Runnable target) | 使用 Runnable 对象创建线程对象 |
| Thread(String name) | 创建线程对象,并命名 |
| Thread(Runnable target, String name) | 使用 Runnable 对象创建线程对象,并命名 |
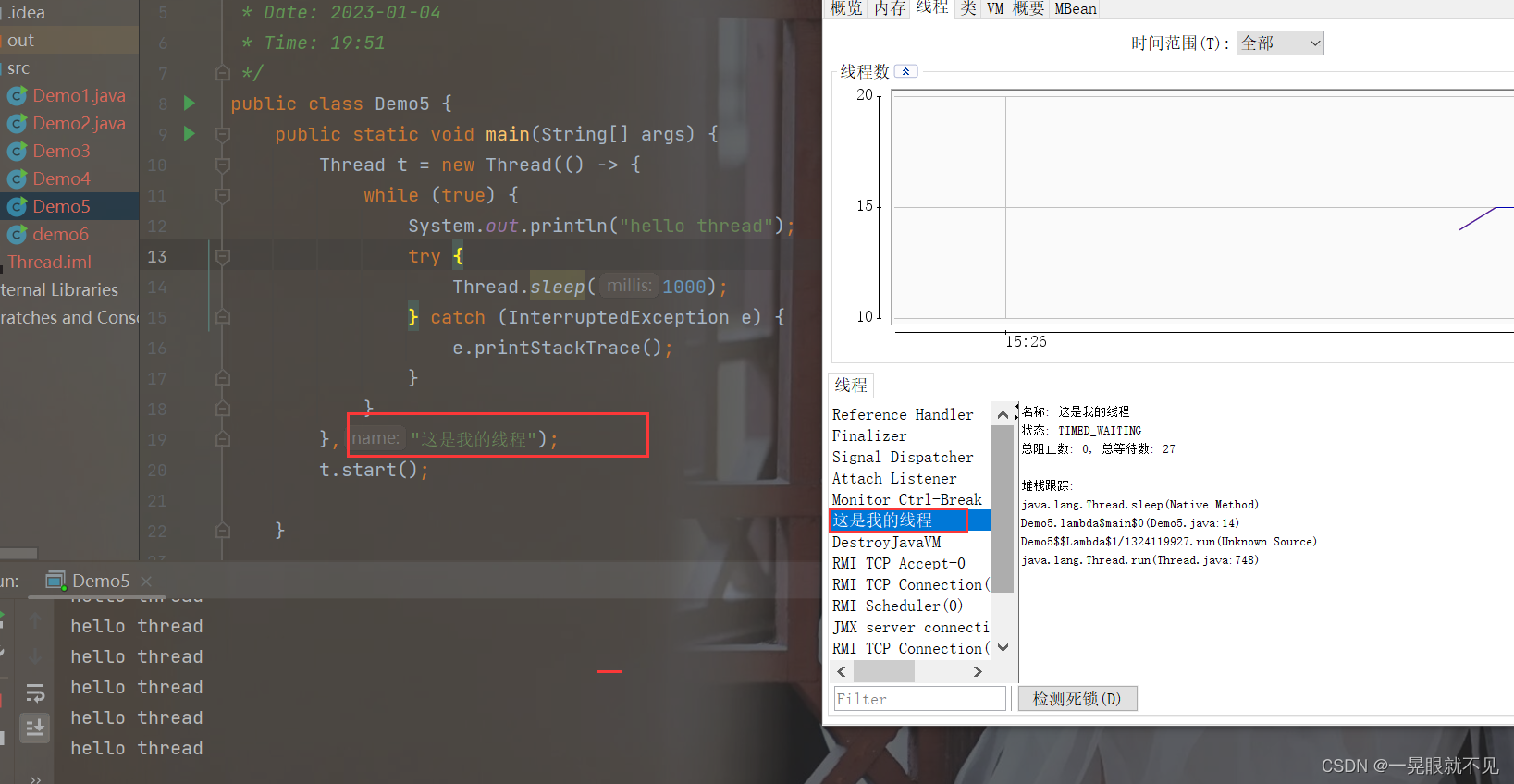
这里需要注意的一点是:
虽然我们可以通过在创建线程的时候,给线程起一个名字(这个名字是允许重复的),这个名字不同于变量名,例如下图中“这是我的线程”才是这个线程的名字,这个是属于 即是在代码中存在,又是在程序运行中存在的。ps:如果不手动给线程起名字,默认JVM会按照thread-0,thread-1.......这样的形式来命名。
Thread 的常见属性
| 属性 | 获取方法 |
| ID | getId() |
| 名称 | getName() |
| 状态 | getState() |
| 优先级 | getPriority() |
| 是否后台线程 | isDaemon() |
| 是否存活 | isAlive() |
| 是否被中断 | isInterrupted() |
- ID 是线程的唯一标识,不同线程不会重复,需要注意的是:这是Java中给 Thread 对象安排的身份标识 和 操作系统内核的PCB的PID,以及和操作系统提供的线程API中的 线程ID 是不同的,但是效果是相同的,比如一个人在不同人的面前被称呼方式不同,但是都代表的这个人。
- 名称是各种调试工具用到,这里的name是上面构造方法中所指定的name。
- 状态表示线程当前所处的一个情况,下面我们会进一步说明
- 作用是获取线程优先级,优先级高的线程理论上来说更容易被调度到
- 关于后台线程,需要记住一点:JVM会在一个进程的所有非后台线程结束后,才会结束运行。
- 线程是否存活 isAlive判断的是内核中的线程存不存在,Thread对象虽然和内核中的线程是一一对应的关系,但是生命周期并非完全相同,Thread对象出来时候,内核里的线程还不一定有,调用start方法,内核线程才有,当内核里的线程执行完成了(run方法结束了),内核里的线程就会销毁了,但是Thread对象还在。
- 线程的中断问题,下面我们进一步说明
这里针对第五点进行展开描述:
Daemon(守护/精灵),这里其实翻译的不好,其实应该译为后台线程,在日常开发的过程中,默认创建的线程是“前台线程” ,而前台线程会阻止进程进行退出,如果main执行完成了,前台线程还未执行完成,那么进程是不会退出的。
如果是后台线程,后台线程不阻止进程退出,如果main等其他前台线程执行完了(main也是前台线程),这时候即使后台线程还没执行完成,进程也会退出。
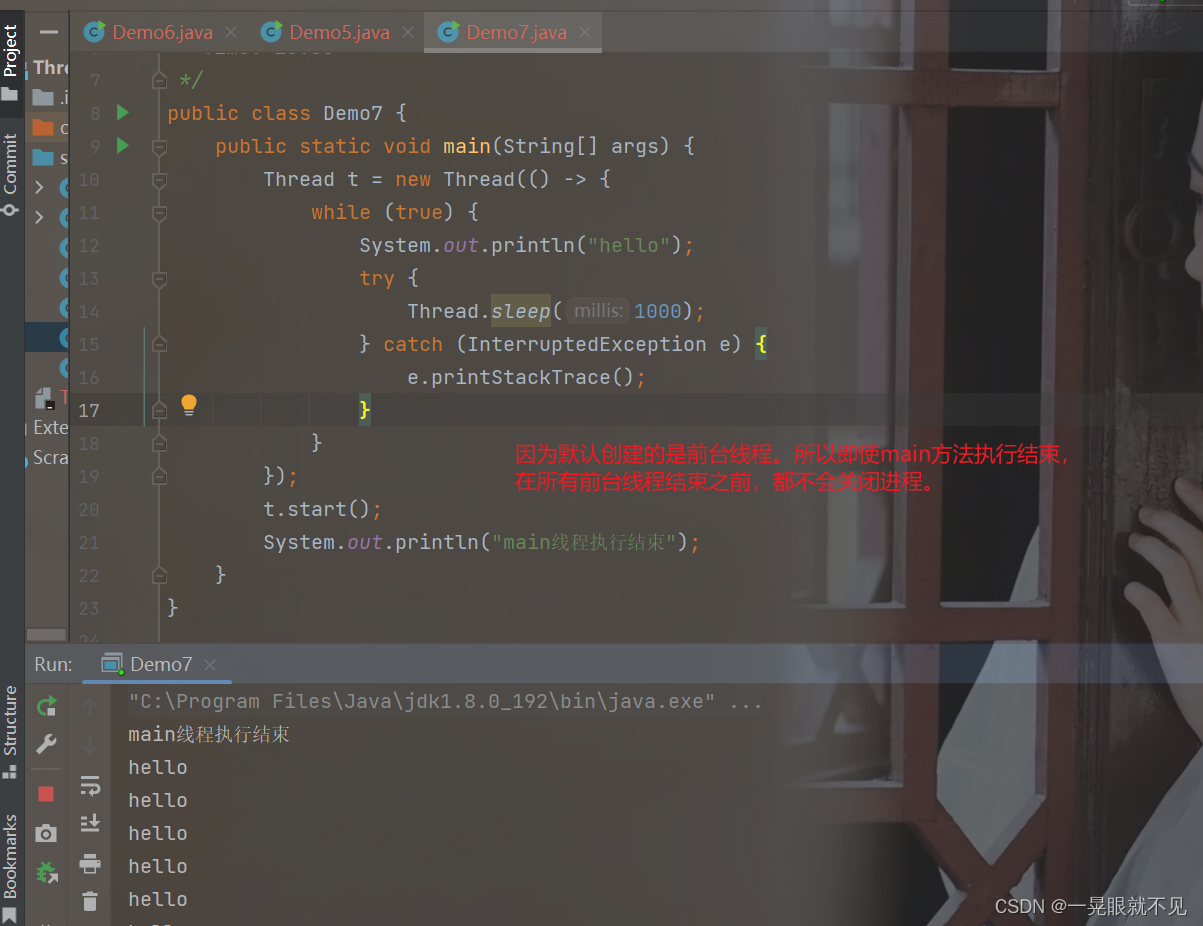
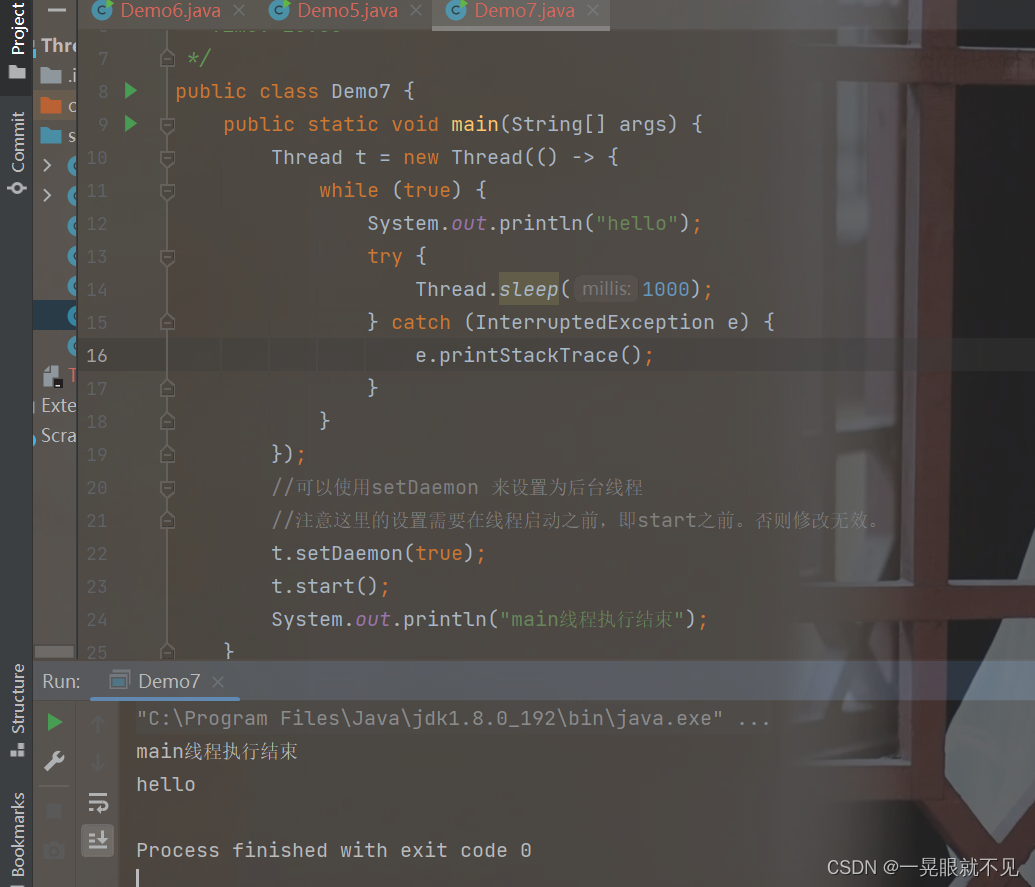
前台线程和后台线程分别适用于哪些场景呢?
比如:想通过多线程来计算一组数据的时候,但是计算时间可能比较久,
如果计算机数据很重要,比如转账信息等,就不应该是后台线程,因为需要保证每一笔转账都完成,这样才能结束程序。
如果是不是很重要的数据,如微信的运动步数,其实实时显示的数据是有延迟的,好比在23:55时候,一顿狂跑,但是在00:00时候系统重置了数据,这时候因为这是后台线程的原因,所以这一顿狂跑时候的步数就不会被记录。
启动线程
start与run的区别
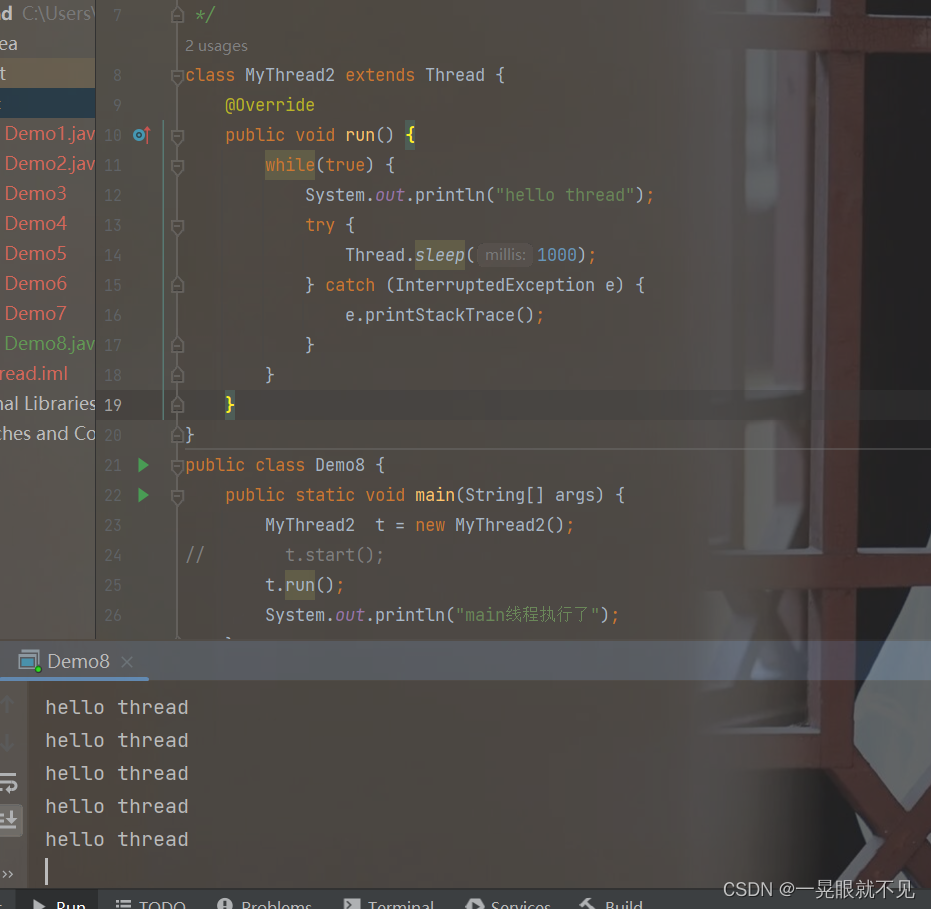
直接调用run并没有创建线程,只是在原来的线程中运行代码,调用start,则是创建了线程,在新线程中执行代码(和原来的线程是并发的)
总结一句话!! 调用start才会真正的创建线程,不调用start没创建线程(这里的创建没创建线程指的是:是否在内核里创建PCB)
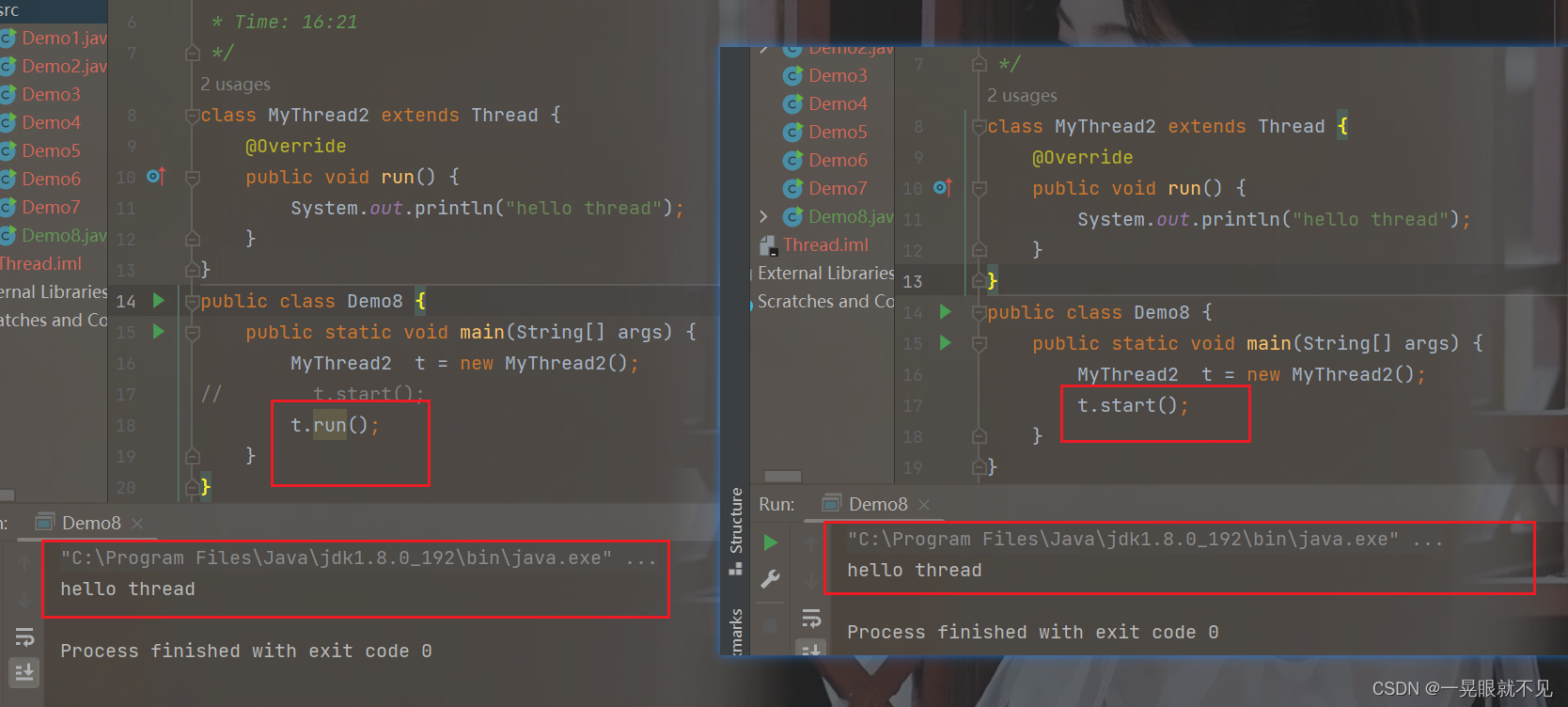
结合实例,如果没调用start直接使用run,那么就是在当前的main线程中直接执行代码,而如果调用了start,则是创建一个新的线程执行这个代码。
相同的,因为没有创建一个新的线程,所以代码会一直打印hello thread而无法打印”main线程执行了“的内容。
中断线程
用途:如果想让线程提前结束(本质是让加速完成任务),需要使用线程中断方法来执行。
目前常见的有以下两种方式:
- 通过定义一个标志位来确认是否结束
- 调用 interrupt() 方法来通知
针对第一种情况:
public class Demo9 {
//因为多个线程公用同一份内存空间所以在main线程中修改可以影响到其他线程
private static boolean isQuit = false;
public static void main(String[] args) {
Thread t = new Thread(() -> {
while(!isQuit) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("t线程执行完成了");
});
t.start();
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
isQuit = true;
System.out.println("设置t线程结束");
}
}
运行结果:
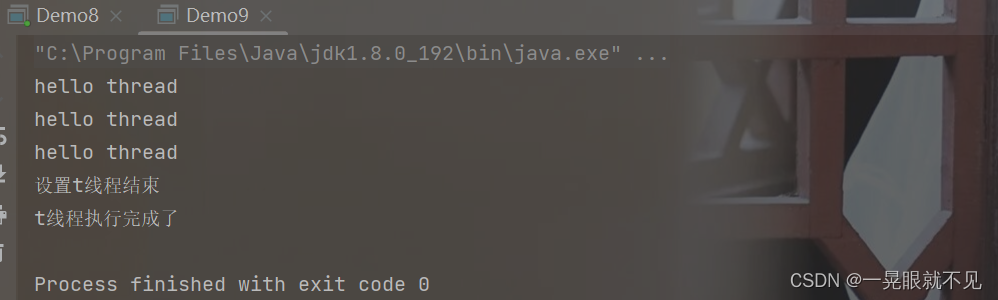
针对第二种情况:
/**
* Created with IntelliJ IDEA.
* Description:
* User: 86136
* Date: 2023-01-05
* Time: 16:42
*/
public class Demo10 {
//因为多个线程公用同一份内存空间所以在main线程中修改可以影响到其他线程
private static boolean isQuit = false;
public static void main(String[] args) {
Thread t = new Thread(() -> {
//这里的currentThread()方法是Thread类的静态方法,通过这个方法,就可以拿到当前线程的实例,即拿到当前线程对应的 Thread对象。
while(!Thread.currentThread().isInterrupted()) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// e.printStackTrace();
break;
}
}
System.out.println("t线程执行完成了");
});
t.start();
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
t.interrupt();
System.out.println("设置t线程结束");
}
}
运行结果:
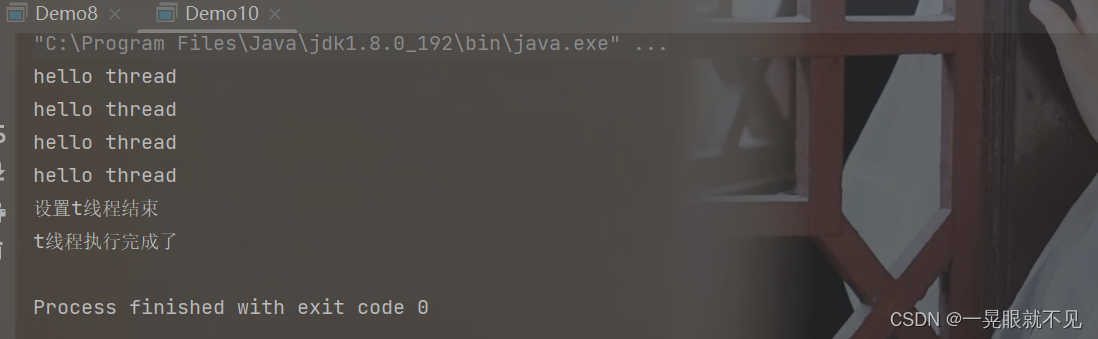
Interrupt的运行机制
interrupt有两种运行机制
- 线程在运行时,会设置标志位为true(Thread.currentThread().isInterrupted())。
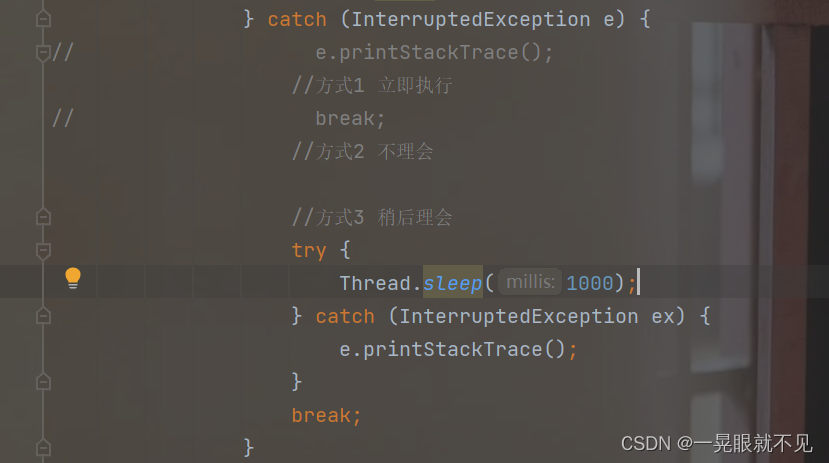
- 线程处于阻塞状态(sleep),不会设置标志位,而是触发一个InterruptedException 这个异常会把sleep提取唤醒,这时需要配合break才能顺利结束循环。
其实这就相当于让线程自身自己处理,并非强制杀死,比如可以 选择:立即结束线程,不理会,过会理会(这些都取决于代码的编写情况)
等待一个线程-join()
线程之间的调度顺序。是不确定的,可以通过一些特殊操作,来对线程的执行顺序,做出干预,其中的join就是一个方法,控制线程之间的结束顺序。
例如,在main中调用t.join 效果就是 让main线程中阻塞等待,等到t执行完成,main才继续执行。
简单来说就是main线程进入阻塞,则不参加CPU的调度,t线程继续参加调度。
示例:
public class Demo11 {
public static void main(String[] args) {
Thread t = new Thread(() -> {
for (int i = 0; i < 5; i++) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
System.out.println("main 线程 join 之前");
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("main线程join之后");
}
}
运行结果: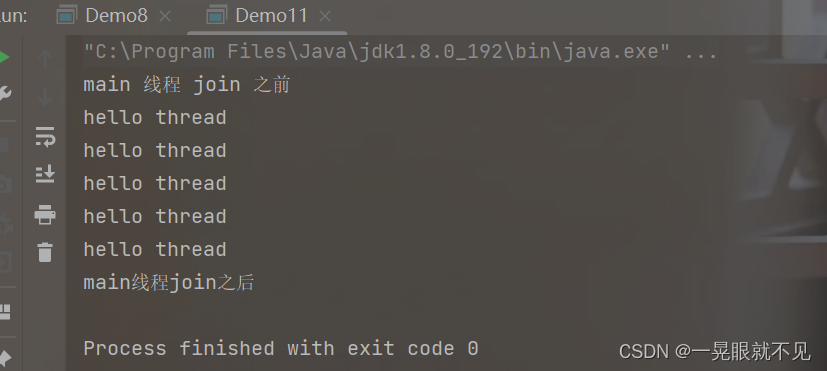
需要注意的是:
这里的”main线程 join之前“ 其实并不是100%出现在t线程之前的,虽然是大概率事件(主要看操作系统的调度,为什么说是大概率呢?因为start之后,内核要创建线程,是需要开销的)
当然,join也是很聪明的,如果在调用join之前,t线程已经结束,那么就不需要再等待了。
join的一些方法
| 方法 | 说明 |
| public void join() | 等待线程结束,无限的等待 |
| public void join(long millis) | 等待线程结束,最多等 millis 毫秒 |
| public void join(long millis, int nanos) | 同理,但可以更高精度 |
获取当前线程引用
这个方法之前在中断线程的第二类方法时介绍过了:
| 方法 | 说明 |
| public static Thread currentThread(); | 返回当前线程对象的引用 |
休眠当前线程
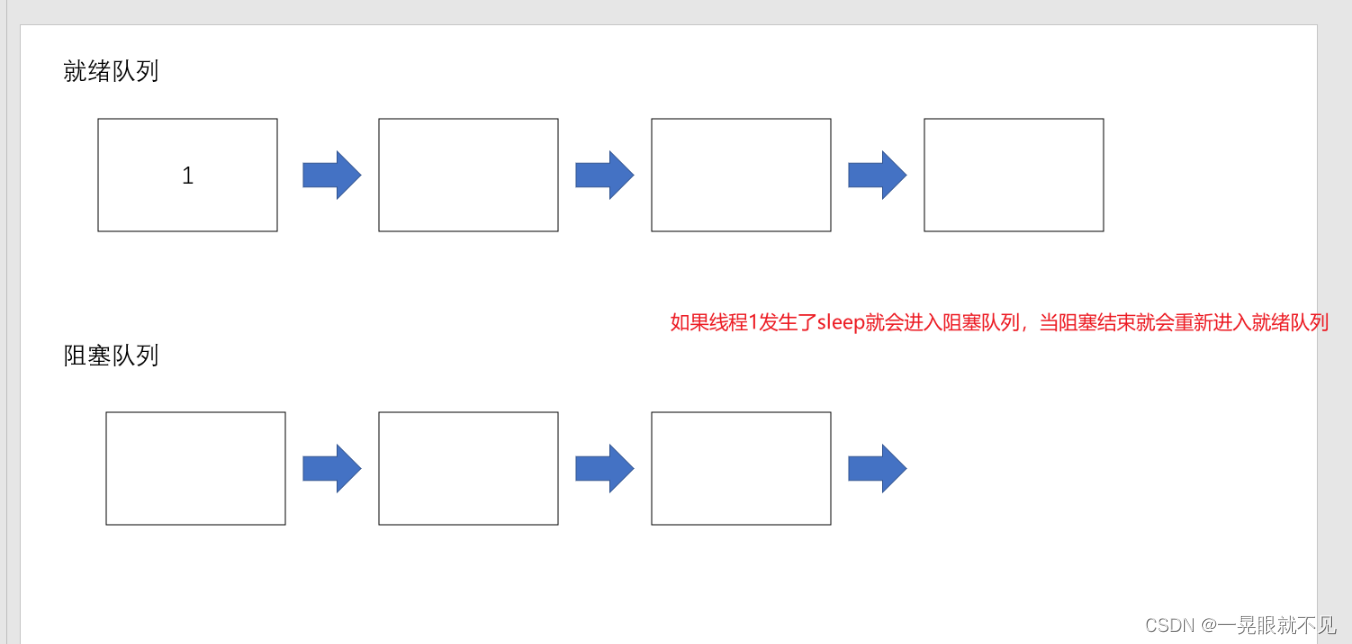
也是我们比较熟悉一组方法,有一点要记得,因为线程的调度是不可控的,所以,这个方法只能保证实际休眠时间是大于等于参数设置的休眠时间的,另外
操作系统管理这里线程的PCB时候,是有多个链表的,当调用了sleep,则这个PCB就会被PCB就会被移动到另外的”阻塞队列“中。
| 方法 | 说明 |
| public static void sleep(long millis) throws InterruptedException | 休眠当前线程 millis 毫秒 |
| public static void sleep(long millis, int nanos) throws InterruptedException | 可以更高精度的休眠 |
当某个线程,sleep时间到了,就会被移动到之前的就绪队列中,移动到就绪队列后,也并不是立刻就能上CPU上执行,还得看操作系统的具体的调度情况。