🚩🚩🚩Transformer实战-系列教程总目录
有任何问题欢迎在下面留言
Transformer实战-系列教程1:Transformer算法解读1
Transformer实战-系列教程2:Transformer算法解读2
5、Multi-head机制
在4中我们的输入是X( x 1 x_1 x1、 x 2 x_2 x2、…、 x n x_{n} xn)经过一次self-Attention计算后得到Z( z 1 z_1 z1、 z 2 z_2 z2、…、 z n z_{n} zn),这可以当成是单头注意力机制。

而多头注意力机制,假如是8头,输入X,同时生成8个Z,即有 Z 0 Z_0 Z0、 Z 1 Z_1 Z1、…、 Z 7 Z_7 Z7,而每一个Z的计算都是同时计算和生成的,每一个Z对应的 W Q W^Q WQ 、 W K W^K WK 、 W V W^V WV 可学习参数与生成Q、K、V还有经过softmax计算相关性的权重都是不一样的,而这8个Z拼接在一起再经过一层全连接生成新的Z,这个新的Z的维度和原来的Z的维度可以相同也可以不相同
不同的注意力结果,得到的特征向量表达也不相同
所以Multi-head机制实际上就是将self-Attention堆叠多层
6、位置信息表达
RNN之所以能够和CNN并立很久的原因,就是因为RNN相对于CNN能够比较好的提取出时序信息,即时间特征、前后序列特征。
在前面的self-Attention和Multi-head机制都没有计算时序信息,如果不计算时序信息,下面的这句话是不是一样的意思呢?
我打你
你打我
这两句话之所以意思完全不同,是因为它们的时序信息不同所以才有完全不同的意义。
以这句话为例:
The animal didn’t cross the street because it was too tired.
不考虑标点和缩写
上面的单词对应了这个位置索引:
[0,1,2,3,4,5,6,7,8,9,10]
每一个单词都对应了768个维度索引:
[0,1,2,3,4,5,6,7,…,765,766,767]
那么根据位置索引和维度索引可以计算出11x768个角度值,再将这个角度值通过正余弦的计算,就可以得到11个768维的向量
Transformer 中的位置编码使用正弦和余弦函数的组合来生成每个位置的编码,公式如下:
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
、
P
E
(
p
o
s
,
2
i
+
1
)
=
c
o
s
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
PE(pos, 2i) =sin(pos / 10000^{2i/d_{model}}) 、 PE(pos, 2i+1) =cos(pos / 10000^{2i/d_{model}})
PE(pos,2i)=sin(pos/100002i/dmodel)、PE(pos,2i+1)=cos(pos/100002i/dmodel)
- P E ( p o s , 2 i ) PE(pos, 2i) PE(pos,2i) 和 P E ( p o s , 2 i + 1 ) PE(pos, 2i+1) PE(pos,2i+1) 分别表示位置 pos 的编码在维度2i和(2i+1) 上的值
- i 是维度索引
- d m o d e l d_{model} dmodel,是模型中嵌入向量的维度
原始输入的 x 1 x_1 x1,它对应的位置编码信息的数据维度和 x 1 x_1 x1是完全一样的
import numpy as np
# 定义位置编码函数
def positional_encoding(position, d_model):
angle_rads = np.arange(position)[:, np.newaxis] / np.power(10000, (2 * (np.arange(d_model)[np.newaxis, :] // 2)) / d_model)
# 将 sin 应用于数组的偶数索引(indices);2i
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# 将 cos 应用于数组的奇数索引(indices);2i+1
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return pos_encoding
# 生成位置编码
position = 10 # 为前10个位置生成编码
d_model = 512 # 嵌入向量的维度
pos_encoding = positional_encoding(position, d_model)
# 打印位置编码的形状和部分值
pos_encoding.shape, pos_encoding[0, :4, :4] # 查看前4个位置的前4维度的编码
[[ 0. , 1. , 0. , 1. ],
[ 0.84147098, 0.54030231, 0.82185619, 0.56969501],
[ 0.90929743, -0.41614684, 0.93641474, -0.35089519],
[ 0.14112001, -0.9899925 , 0.24508542, -0.96950149]]
这是一个位置编码的小例子
7、Decoder
在前面介绍了self-Attention、Multi-head、位置信息计算等内容,这些都是Encoder编码器的部分,就是将原始的文本编码成特征,与编码器对应的还有Decoder解码器
解码器与编码器有所不同:
- Attention计算不同
- 加入了MASK机制
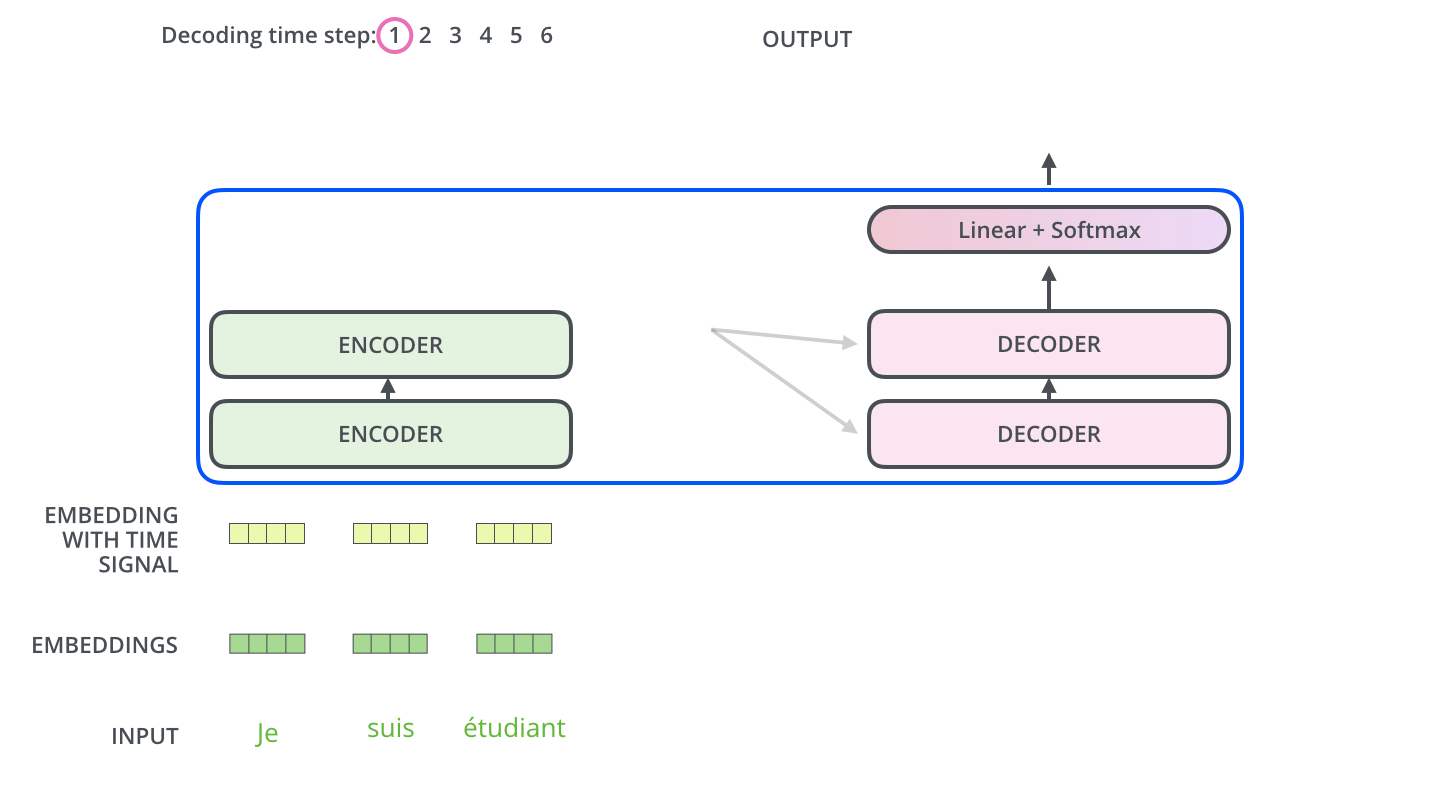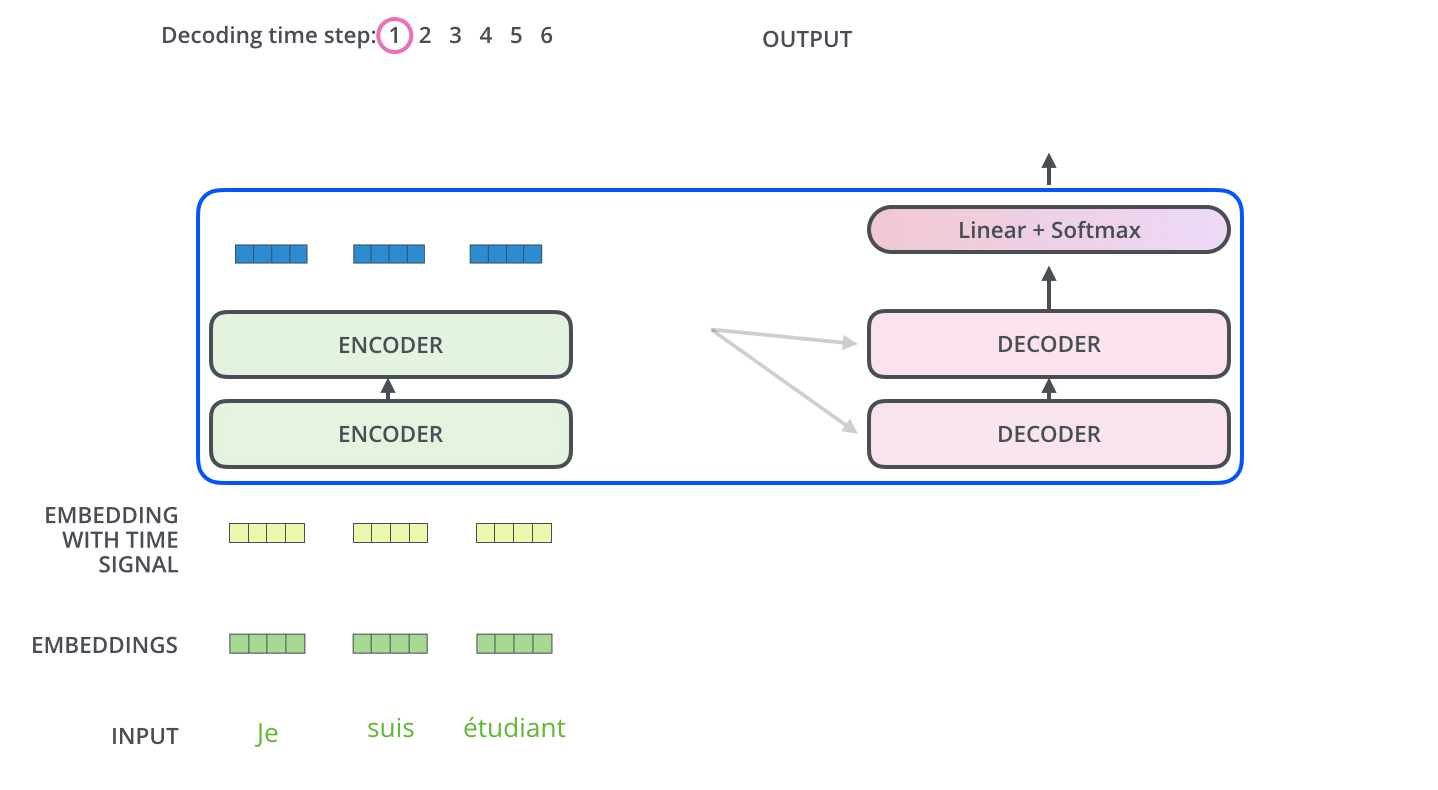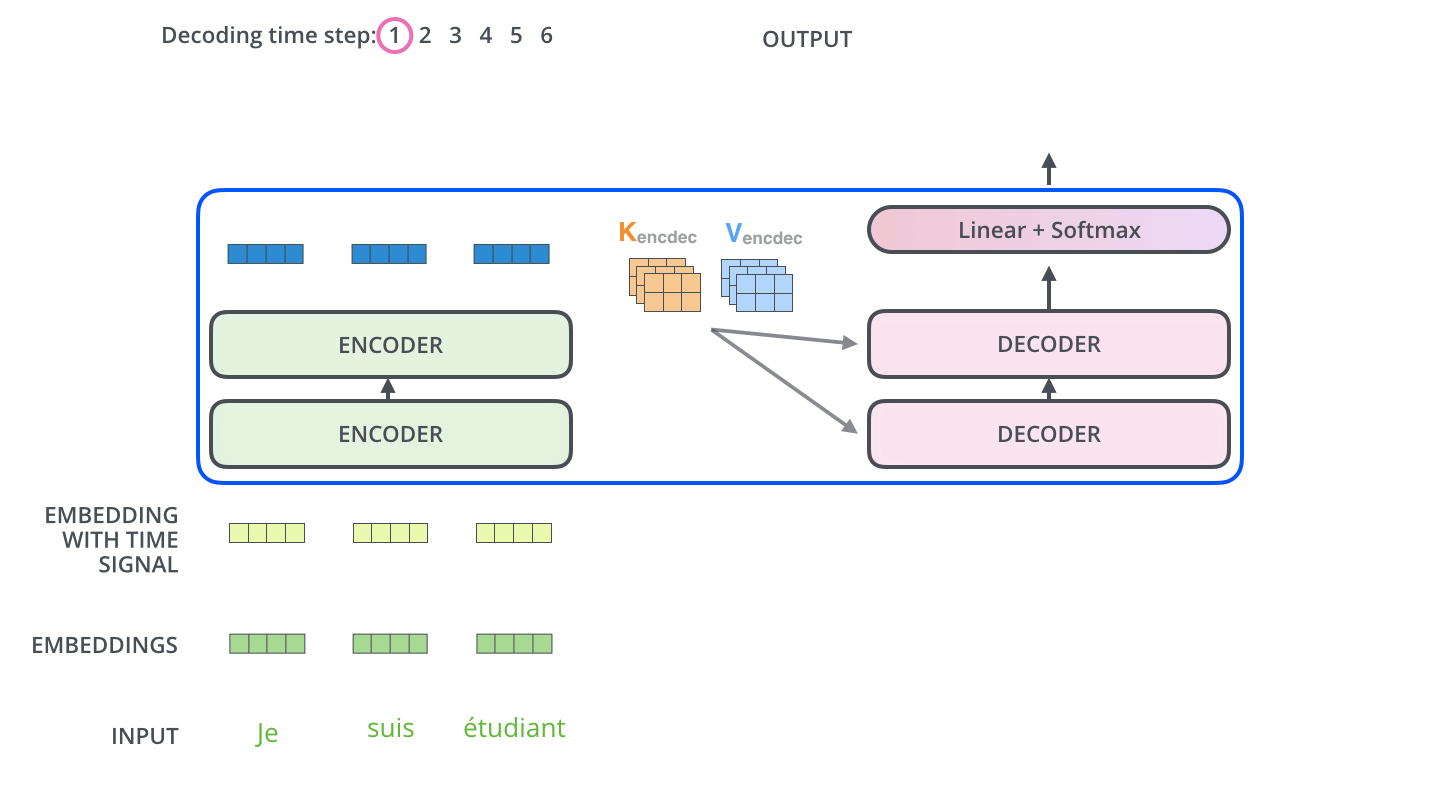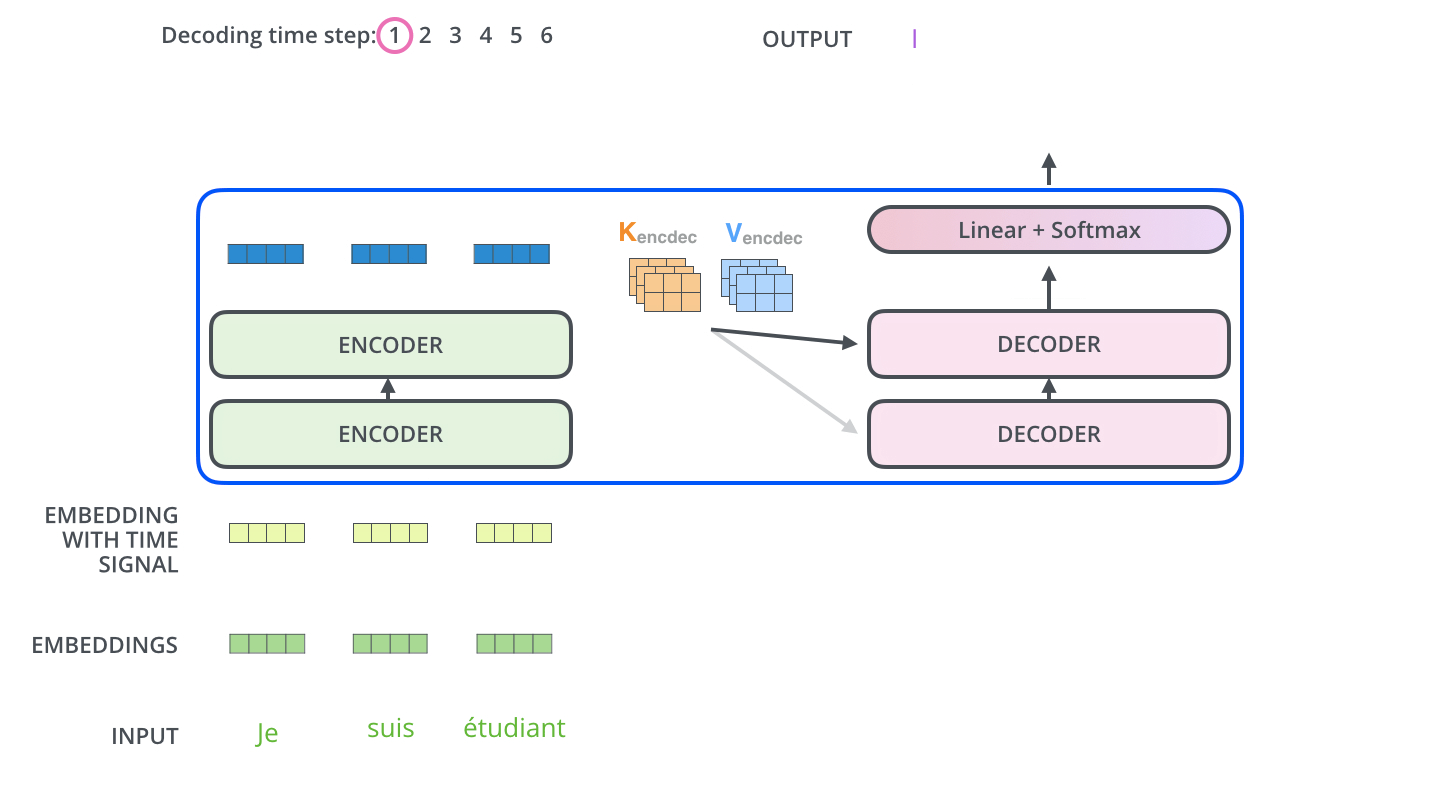
如图所示,这是一个使用Transformer架构将法语翻译成英语的任务,法语输入3个单词,英语输出4个单词,左边为编码器,右边为解码器
- Je suis étudiant经过编码器变成了Z={ z 1 z_1 z1、 z 2 z_2 z2、 z 3 z_3 z3 } 3个向量
- Z直接对应生成K={ k 1 k_1 k1、 k 2 k_2 k2、 k 3 k_3 k3 } 和V={ v 1 v_1 v1、 v 2 v_2 v2、 v 3 v_3 v3 } ,其中 k i k_i ki= v i v_i vi= z i z_i zi
- 解码器的Q从上一个解码器的输出得到,比如上一个解码器的输出为I,那么I经过embbeding后在全连接层维度变换成和K、V一样的维度得到Q
- 但是第一个没有上一个解码器的输出怎么办呢?将“开始符号”进行embbeding
- 现在Q、K、V都有了,同样进行自注意力的计算,生成解码器自己的Z向量
- Z向量首先会经过包含激活函数ReLU、层归一化Layer Normalization、全连接层,然后依次经过残差连接、全连接层、softmax得到一个两万分类(假设语料表为两万词)的概率,选取概率最高的那个单词,假设就是I
- I经过embbeding后,再经过一层全连接层进行维度变换生成新的Q向量
- 如此循环直到生成“停止符号”
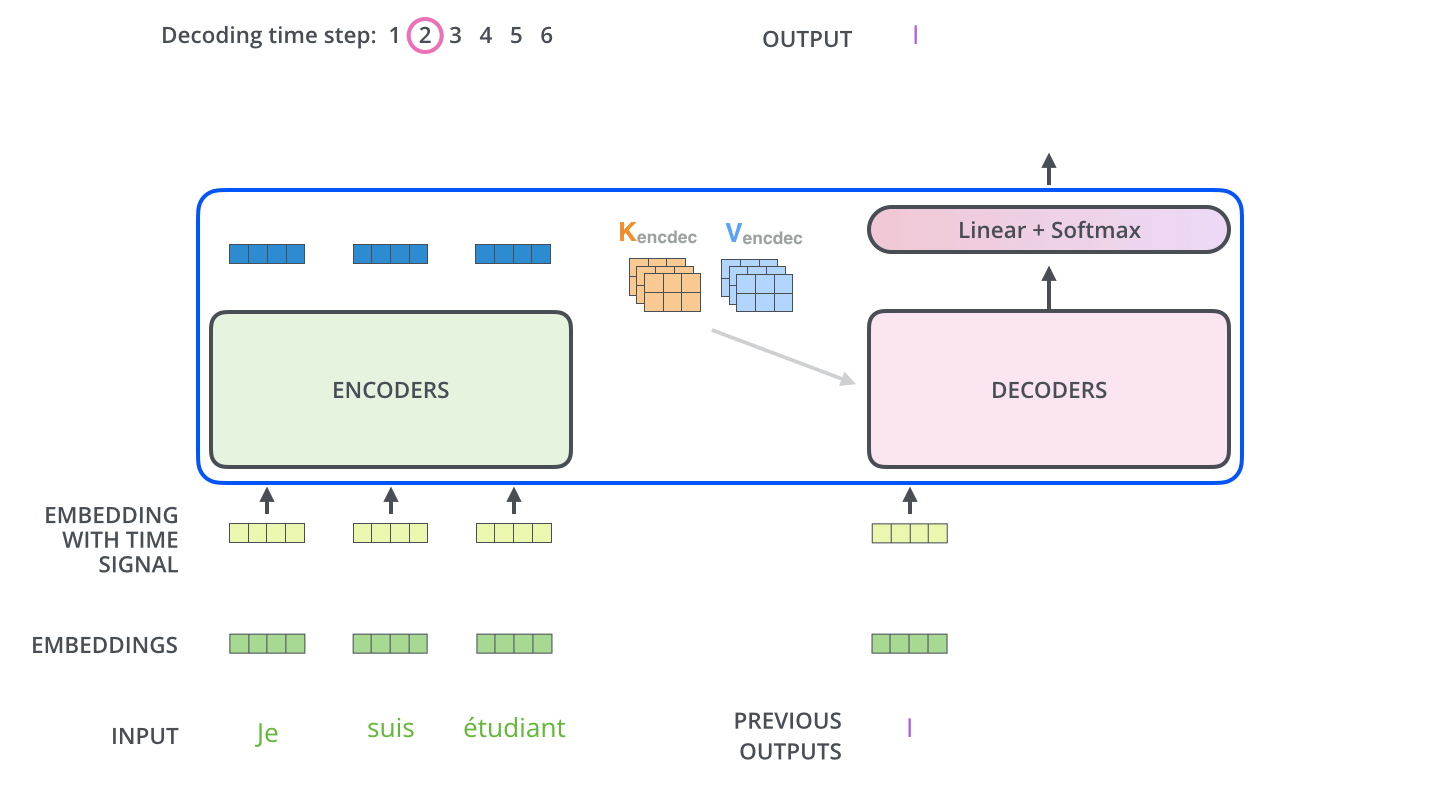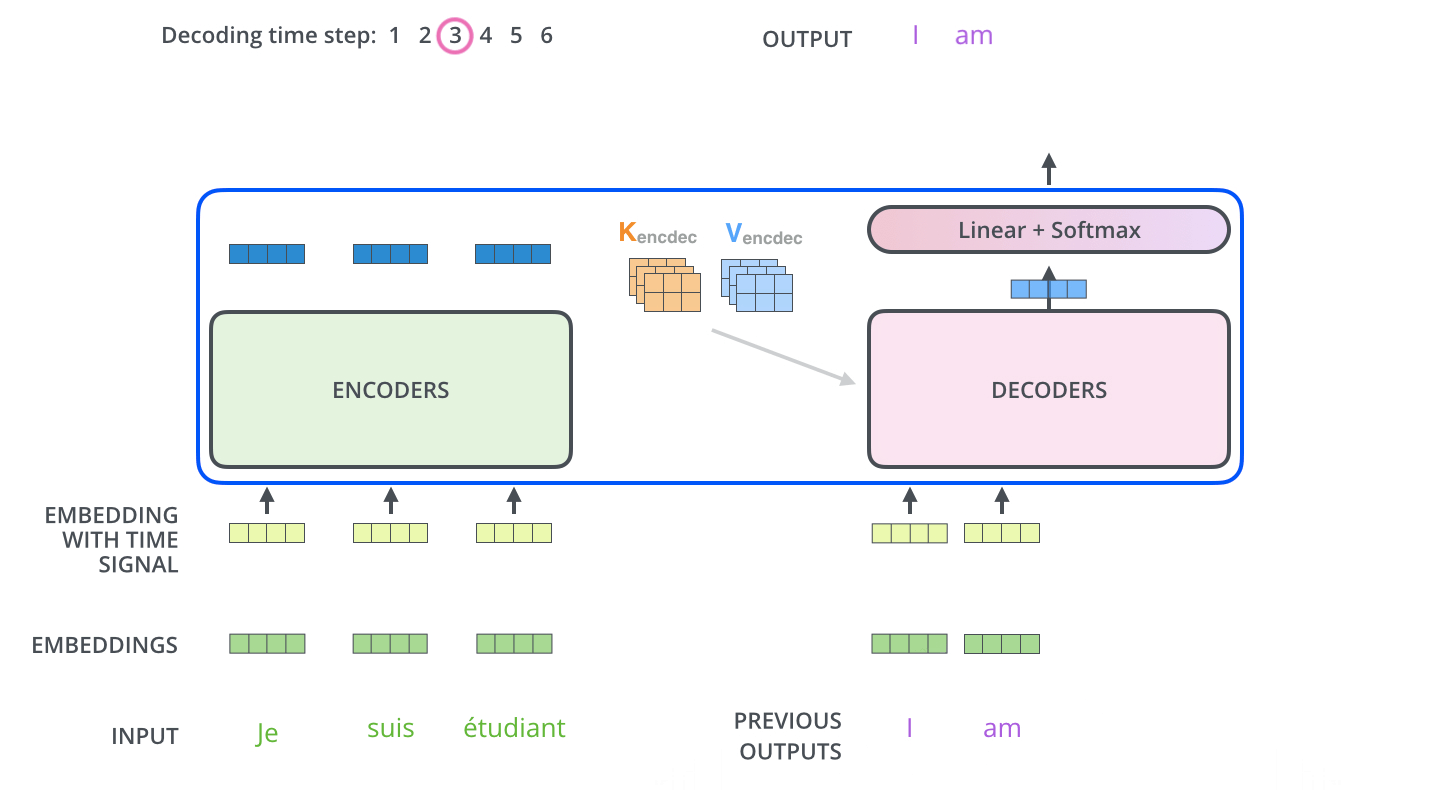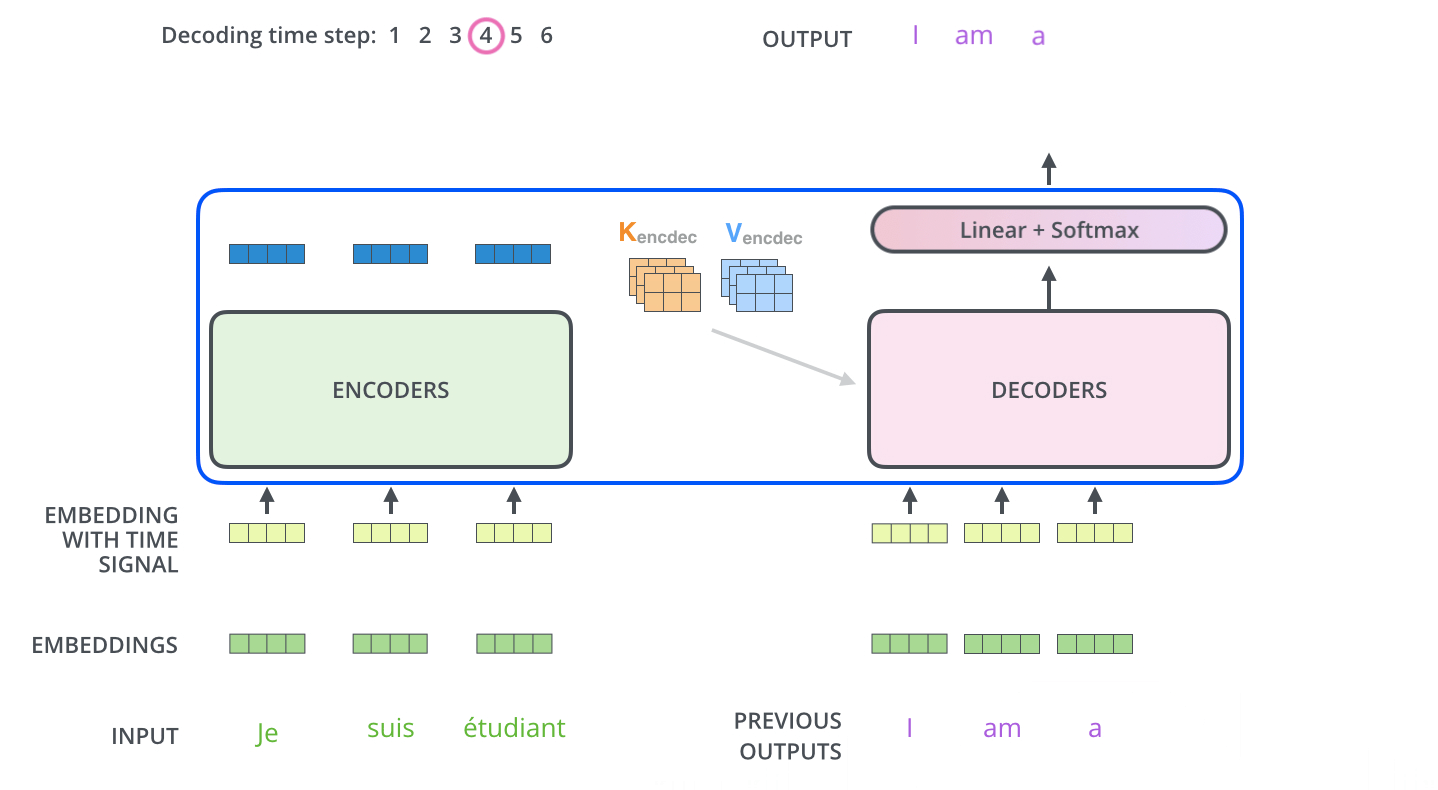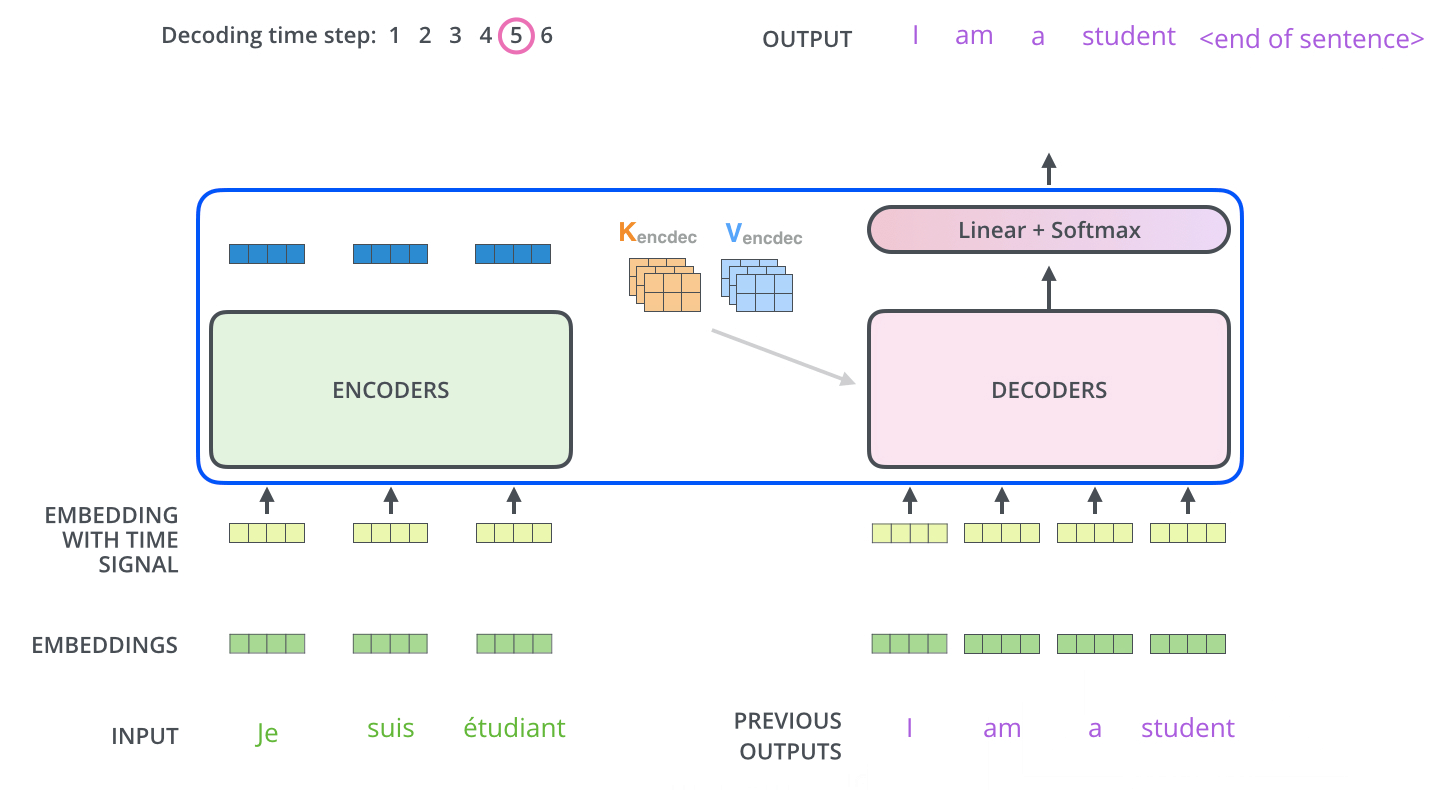
8、输出层
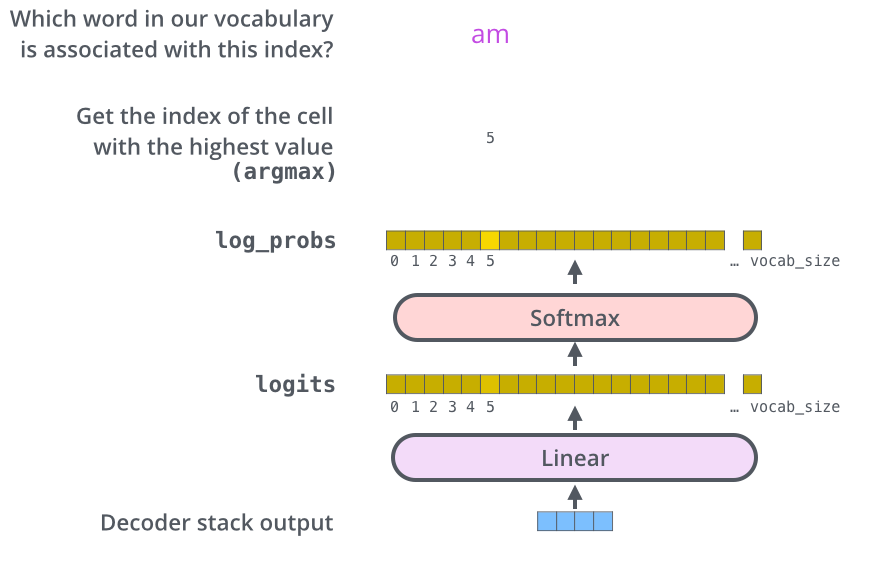
解码器是不断的生成一个向量,这个向量在解析成一个单词,也就是说会一个一个单词的生成。
这个单词如何生成呢?主要是最后的线性层和Softmax层
线性层是一个简单的全连接神经网络,它将解码器产生的向量投影到一个更大的向量中,称为 logits 向量。
假设我们的模型从训练数据中可以统计到10000个不同的单词(那这一万个单词就是我们的语料表)。这使得
logits 向量有 10,000 个单元格——每个单元格对应一个唯一单词的分数。这就是我们解释线性层模型输出的方式。
然后,softmax 层将这些分数转换为概率(全部为正,全部加起来为 1.0)。选择概率最高的单元格,并生成与其关联的单词作为该时间步的输出。
Transformer实战-系列教程1:Transformer算法解读1
Transformer实战-系列教程2:Transformer算法解读2