一、PPO简介
TRPO(Trust Range Policy Optimate)算法每一步更新都需要大量的运算,于是便有其改进版本PPO在2017年被提出。PPO 基于 TRPO 的思想,但是其算法实现更加简单。TRPO 使用泰勒展开近似、共轭梯度、线性搜索等方法直接求解。PPO 的优化目标与 TRPO 相同,但 PPO 用了一些相对简单的方法来求解。具体来说, PPO 有两种形式,一是PPO-惩罚,二是PPO-截断,我们接下来对这两种形式进行介绍。
二、PPO两种形式
2.1 PPO-Penalty
用拉格朗日乘数法直接将KL散度的限制放入目标函数,变成一个无约束的优化问题。同时还需要更新KL散度的系数。
a
r
g
m
a
x
θ
E
a
−
v
π
θ
k
E
a
−
π
θ
k
(
⋅
∣
s
)
[
π
θ
(
a
∣
s
)
π
θ
k
(
a
∣
s
)
A
π
θ
k
(
s
,
a
)
−
β
D
K
L
[
π
θ
k
(
⋅
∣
s
)
,
π
θ
(
⋅
∣
s
)
]
]
arg max_{\theta} E_{a- v^{\pi_{\theta_k}}}E_{a-\pi_{\theta_k}}( \cdot|s)[\frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)}A^{\pi_{\theta_k}}(s, a) - \beta D_{KL}[\pi_{\theta_k}(\cdot|s), \pi_{\theta}(\cdot|s)]]
argmaxθEa−vπθkEa−πθk(⋅∣s)[πθk(a∣s)πθ(a∣s)Aπθk(s,a)−βDKL[πθk(⋅∣s),πθ(⋅∣s)]]
令
d
k
=
D
K
L
v
π
θ
k
[
π
θ
k
(
⋅
∣
s
)
,
π
θ
(
⋅
∣
s
)
]
d_k=D^{v^{\pi_{\theta_k}}}_{KL}[\pi_{\theta_k}(\cdot|s), \pi_{\theta}(\cdot|s)]
dk=DKLvπθk[πθk(⋅∣s),πθ(⋅∣s)]
- 如果 d k < δ / 1.5 d_k < \delta /1.5 dk<δ/1.5, 那么 β k + 1 = β k / 2 \beta_{k+1} = \beta_k/2 βk+1=βk/2
- 如果 d k > δ ∗ 1.5 d_k > \delta *1.5 dk>δ∗1.5, 那么 β k + 1 = β k ∗ 2 \beta_{k+1} = \beta_k * 2 βk+1=βk∗2
- 否则 β k + 1 = β k \beta_{k+1} = \beta_k βk+1=βk
相对PPO-Clip来说计算还是比较复杂,我们来看PPO-Clip的做法
2.2 PPO-Clip
ppo-Clip直接在目标函数中进行限制,保证新的参数和旧的参数的差距不会太大。
a
r
g
m
a
x
θ
E
a
−
v
π
θ
k
E
a
−
π
θ
k
(
⋅
∣
s
)
[
m
i
n
(
π
θ
(
a
∣
s
)
π
θ
k
(
a
∣
s
)
A
π
θ
k
(
s
,
a
)
,
c
l
i
p
(
π
θ
(
a
∣
s
)
π
θ
k
(
a
∣
s
)
,
1
−
ϵ
,
1
+
ϵ
)
A
π
θ
k
(
s
,
a
)
)
]
arg max_{\theta} E_{a- v^{\pi_{\theta_k}}}E_{a-\pi_{\theta_k}}( \cdot|s)[min(\frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)}A^{\pi_{\theta_k}}(s, a), clip(\frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)}, 1-\epsilon, 1+\epsilon )A^{\pi_{\theta_k}}(s, a))]
argmaxθEa−vπθkEa−πθk(⋅∣s)[min(πθk(a∣s)πθ(a∣s)Aπθk(s,a),clip(πθk(a∣s)πθ(a∣s),1−ϵ,1+ϵ)Aπθk(s,a))]
就是将新旧动作的差异限定在
[
1
−
ϵ
,
1
+
ϵ
]
[1-\epsilon, 1+\epsilon]
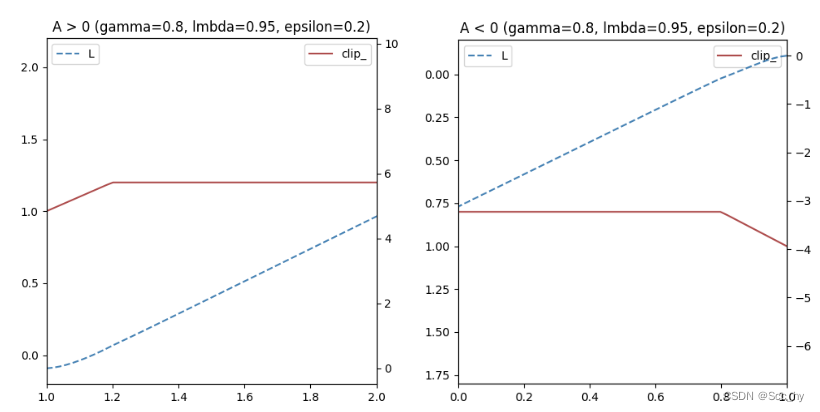
[1−ϵ,1+ϵ]。如果A > 0,说明这个动作的价值高于平均,最大化这个式子会增大
π
θ
(
a
∣
s
)
π
θ
k
(
a
∣
s
)
\frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)}
πθk(a∣s)πθ(a∣s),但是不会让超过
1
+
ϵ
1+\epsilon
1+ϵ。反之,A<0,最大化这个式子会减少
π
θ
(
a
∣
s
)
π
θ
k
(
a
∣
s
)
\frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)}
πθk(a∣s)πθ(a∣s),但是不会让超过
1
−
ϵ
1-\epsilon
1−ϵ。
可以简单绘制如下
绘图脚本
def plot_pip_clip(td_delta):
gamma = 0.8
lmbda = 0.95
epsilon = 0.2
A = []
pi_pi = []
adv = 0
for delta in td_delta[::-1]:
adv = gamma * lmbda * adv + delta
# A > 0
A.append(adv)
# Pi_pi > 1
pi_pi.append((1+delta)/1)
A = np.array(A)
pi_pi = np.array(pi_pi)
clip_ = np.clip(pi_pi, 1-epsilon, 1+epsilon)
L = np.where(pi_pi * A < clip_ * A, pi_pi * A, clip_ * A)
print(clip_)
fig, axes = plt.subplots(figsize=(4, 4))
axes2 = axes.twinx()
axes.plot(pi_pi, clip_, label='clip_', color='darkred', alpha=0.7)
axes2.plot(pi_pi, L, label='L', color='steelblue', linestyle='--')
axes.set_title(f'A > 0 (gamma={gamma}, lmbda={lmbda}, epsilon={epsilon})')
axes.set_xlim([1, 2])
axes.set_ylim([min(clip_)-max(clip_), max(clip_)+min(clip_)])
if pi_pi[-1] < pi_pi[0]:
# axes.set_xlim([1, 0])
axes.set_xlim([0, 1])
axes.set_ylim([max(clip_)+min(clip_), min(clip_)-max(clip_)])
axes.set_title(f'A < 0 (gamma={gamma}, lmbda={lmbda}, epsilon={epsilon})')
axes.legend()
axes2.legend(loc="upper left")
plt.show()
td_delta = np.linspace(0, 2, 100)[::-1]
plot_pip_clip(td_delta)
td_delta = -np.linspace(0, 2, 100)[::-1]
plot_pip_clip(td_delta)
三、Pytorch实践
PPO-Clip更加简洁,同时大量的实验也表名PPO-Clip总是比PPO-Penalty 效果好。所以我们就用PPO-Clip去倒立钟摆中实践。
我们这次用Pendulum-v1action 也同样用连续变量。
这里我们需要做一个转化,一个连续的action力矩(一维的连续遍历)。
- 将连续变量的每个dim都拟合为一个正态分布
- 训练的时候训练action每个维度的均值和方差
- 最终进行action选择的时候基于均值和方差所再拟合正态曲线进行抽样。
所以我们的策略网络按如下方法构造。
class policyNet(nn.Module):
"""
continuity action:
normal distribution (mean, std)
"""
def __init__(self, state_dim: int, hidden_layers_dim: typ.List, action_dim: int):
super(policyNet, self).__init__()
self.features = nn.ModuleList()
for idx, h in enumerate(hidden_layers_dim):
self.features.append(nn.ModuleDict({
'linear': nn.Linear(hidden_layers_dim[idx-1] if idx else state_dim, h),
'linear_action': nn.ReLU(inplace=True)
}))
self.fc_mu = nn.Linear(hidden_layers_dim[-1], action_dim)
self.fc_std = nn.Linear(hidden_layers_dim[-1], action_dim)
def forward(self, x):
for layer in self.features:
x = layer['linear_action'](layer['linear'](x))
mean_ = 2.0 * torch.tanh(self.fc_mu(x))
# np.log(1 + np.exp(2))
std = F.softplus(self.fc_std(x))
return mean_, std
3.1 构建智能体(PPO-Clip)
完整脚本可以参看笔者的github: PPO_lr.py
网络如下方法构造
def compute_advantage(gamma, lmbda, td_delta):
td_delta = td_delta.detach().numpy()
adv_list = []
adv = 0
for delta in td_delta[::-1]:
adv = gamma * lmbda * adv + delta
adv_list.append(adv)
adv_list.reverse()
return torch.FloatTensor(adv_list)
class PPO:
"""
PPO算法, 采用截断方式
"""
def __init__(self,
state_dim: int,
hidden_layers_dim: typ.List,
action_dim: int,
actor_lr: float,
critic_lr: float,
gamma: float,
PPO_kwargs: typ.Dict,
device: torch.device
):
self.actor = policyNet(state_dim, hidden_layers_dim, action_dim).to(device)
self.critic = valueNet(state_dim, hidden_layers_dim).to(device)
self.actor_opt = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)
self.critic_opt = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)
self.gamma = gamma
self.lmbda = PPO_kwargs['lmbda']
self.ppo_epochs = PPO_kwargs['ppo_epochs'] # 一条序列的数据用来训练的轮次
self.eps = PPO_kwargs['eps'] # PPO中截断范围的参数
self.count = 0
self.device = device
def policy(self, state):
state = torch.FloatTensor([state]).to(self.device)
mu, std = self.actor(state)
action_dist = torch.distributions.Normal(mu, std)
action = action_dist.sample()
return [action.item()]
def update(self, samples: deque):
self.count += 1
state, action, reward, next_state, done = zip(*samples)
state = torch.FloatTensor(state).to(self.device)
action = torch.tensor(action).view(-1, 1).to(self.device)
reward = torch.tensor(reward).view(-1, 1).to(self.device)
reward = (reward + 8.0) / 8.0 # 和TRPO一样,对奖励进行修改,方便训练
next_state = torch.FloatTensor(next_state).to(self.device)
done = torch.FloatTensor(done).view(-1, 1).to(self.device)
td_target = reward + self.gamma * self.critic(next_state) * (1 - done)
td_delta = td_target - self.critic(state)
advantage = compute_advantage(self.gamma, self.lmbda, td_delta.cpu()).to(self.device)
mu, std = self.actor(state)
action_dists = torch.distributions.Normal(mu.detach(), std.detach())
# 动作是正态分布
old_log_probs = action_dists.log_prob(action)
for _ in range(self.ppo_epochs):
mu, std = self.actor(state)
action_dists = torch.distributions.Normal(mu, std)
log_prob = action_dists.log_prob(action)
# e(log(a/b))
ratio = torch.exp(log_prob - old_log_probs)
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1 - self.eps, 1 + self.eps) * advantage
actor_loss = torch.mean(-torch.min(surr1, surr2)).float()
critic_loss = torch.mean(
F.mse_loss(self.critic(state).float(), td_target.detach().float())
).float()
self.actor_opt.zero_grad()
self.critic_opt.zero_grad()
actor_loss.backward()
critic_loss.backward()
self.actor_opt.step()
self.critic_opt.step()
3.2 智能体训练
class Config:
num_episode = 1200
state_dim = None
hidden_layers_dim = [ 128, 128 ]
action_dim = 20
actor_lr = 1e-4
critic_lr = 5e-3
PPO_kwargs = {
'lmbda': 0.9,
'eps': 0.2,
'ppo_epochs': 10
}
gamma = 0.9
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
buffer_size = 20480
minimal_size = 1024
batch_size = 128
save_path = r'D:\TMP\ac_model.ckpt'
# 回合停止控制
max_episode_rewards = 260
max_episode_steps = 260
def __init__(self, env):
self.state_dim = env.observation_space.shape[0]
try:
self.action_dim = env.action_space.n
except Exception as e:
self.action_dim = env.action_space.shape[0]
print(f'device={self.device} | env={str(env)}')
def train_agent(env, cfg):
ac_agent = PPO(
state_dim=cfg.state_dim,
hidden_layers_dim=cfg.hidden_layers_dim,
action_dim=cfg.action_dim,
actor_lr=cfg.actor_lr,
critic_lr=cfg.critic_lr,
gamma=cfg.gamma,
PPO_kwargs=cfg.PPO_kwargs,
device=cfg.device
)
tq_bar = tqdm(range(cfg.num_episode))
rewards_list = []
now_reward = 0
bf_reward = -np.inf
for i in tq_bar:
buffer_ = replayBuffer(cfg.buffer_size)
tq_bar.set_description(f'Episode [ {i+1} / {cfg.num_episode} ]')
s, _ = env.reset()
done = False
episode_rewards = 0
steps = 0
while not done:
a = ac_agent.policy(s)
n_s, r, done, _, _ = env.step(a)
buffer_.add(s, a, r, n_s, done)
s = n_s
episode_rewards += r
steps += 1
if (episode_rewards >= cfg.max_episode_rewards) or (steps >= cfg.max_episode_steps):
break
ac_agent.update(buffer_.buffer)
rewards_list.append(episode_rewards)
now_reward = np.mean(rewards_list[-10:])
if bf_reward < now_reward:
torch.save(ac_agent.actor.state_dict(), cfg.save_path)
bf_reward = now_reward
tq_bar.set_postfix({'lastMeanRewards': f'{now_reward:.2f}', 'BEST': f'{bf_reward:.2f}'})
env.close()
return ac_agent
print('=='*35)
print('Training Pendulum-v1')
env = gym.make('Pendulum-v1')
cfg = Config(env)
ac_agent = train_agent(env, cfg)
四、训练出的智能体观测
最后将训练的最好的网络拿出来进行观察
ac_agent.actor.load_state_dict(torch.load(cfg.save_path))
play(gym.make('Pendulum-v1', render_mode="human"), ac_agent, cfg)