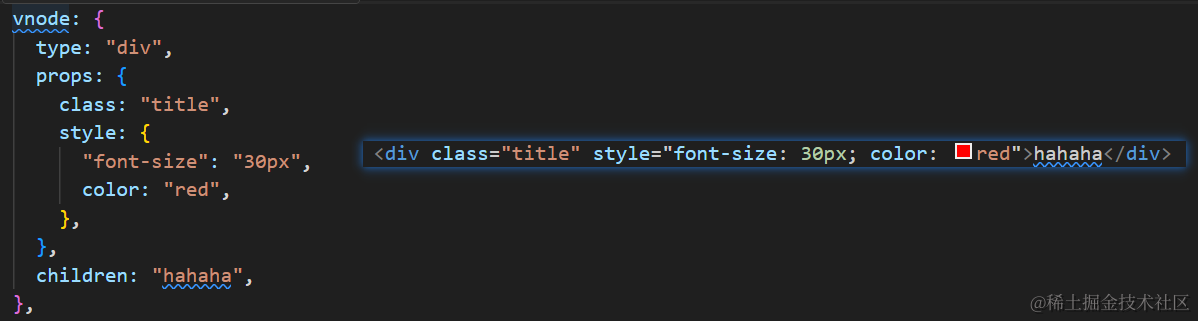
1 布隆过滤器概述
1.1 概述
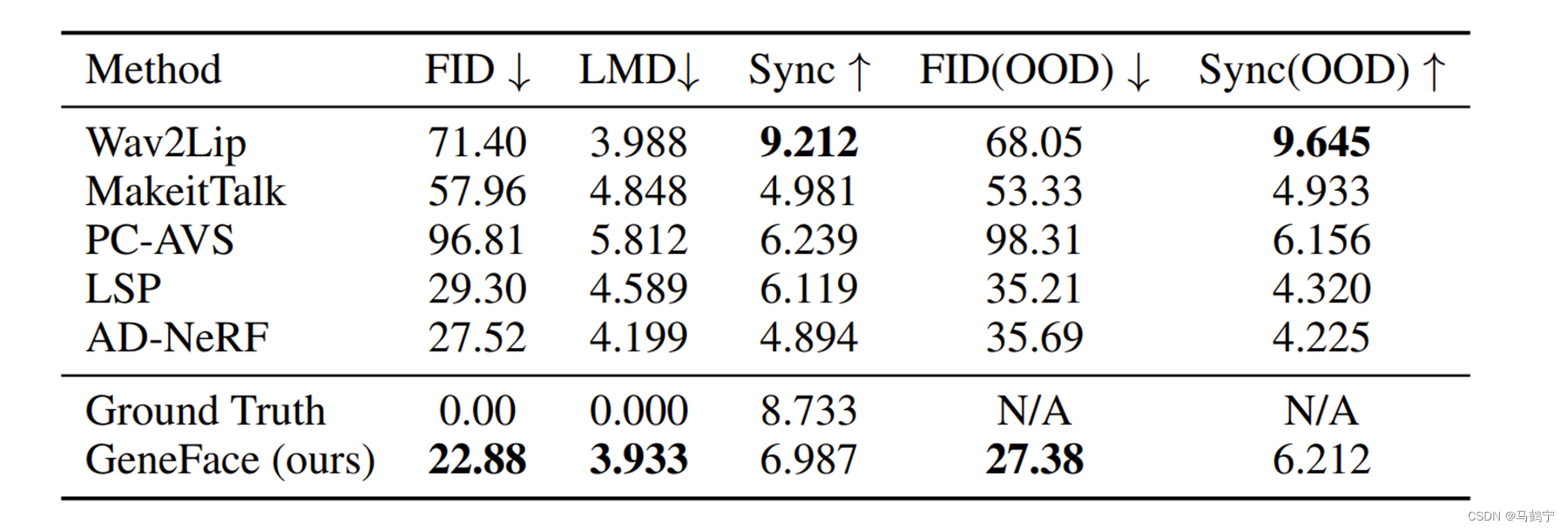
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是由一个很长的二进制向量(数组)和一系列随机映射函数(hash函数)组成,它不存放数据的明细内容,仅仅标识一个数据是否存在的信息。布隆过滤器可以用于检索一个元素在一个数组或集合中是否存在。
它的优点是空间效率和查询时间都比一般的算法要好,缺点是有一定的误判率(hash冲突导致的)和数据删除困难。
1.2 基本原理
布隆过滤器的基本原理如下所述:
- 数据存储到布隆过滤器:创建一个指定长度的数组,数组元素的初始值均为0。通过一个或多个Hash函数将数据映射成该数组中的一个点或者多个点,并将这些点位的元素值设置为非0。
- 判断某个数据在布隆过滤器中是否存在:通过hash函数计算某个数据在数组上对应的所有点是不是都非0。如果都非0,则该数据可能存在;如果有一个为0,则该数据一定不存在。
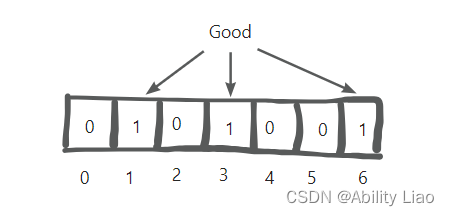
举例:当向过滤器存入 “Good” 时,假设过滤器的 3 个哈希函数输出 1、3、6,则把数组相应位置的元素置为 1。
2 布隆过滤器的使用
下面是对布隆过滤器的简单使用。采用的过滤器是guava中对布隆过滤器的实现。
2.1 依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.1-jre</version>
</dependency>2.2 主要的方法
创建布隆过滤器:BloomFilter#create
往过滤器中插入数据: BloomFilter#put
判断数据在过滤器中是否可能存在:BloomFilter#mightContain
2.3 使用示例
import com.google.common.base.Charsets;
import com.google.common.collect.Lists;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.util.List;
public class BloomFilterDemo {
public static void main(String[] args) {
// 过滤器中存储数据
int total = 1000000;
List<String> baseList = Lists.newArrayList();
for (int i = 0; i < total; i++) {
baseList.add("" + i);
}
// 待匹配的数据
// 布隆过滤器应该匹配到的数据量:1000000
List<String> inputList = Lists.newArrayList();
for (int i = 0; i < total + 10000; i++) {
inputList.add("" + i);
}
// (1)条件:expectedInsertions:100w,fpp:3%
// 结果:numBits:约729w(数组size:约729w/64),numHashFunctions:5
System.out.println("expectedInsertions:100w,fpp:3%,匹配到的数量 " + bloomFilterCheck(baseList, inputList, baseList.size(), 0.03));
// (2)条件:expectedInsertions:100w,fpp:0.0001%
// 结果:numBits:约2875w(数组size:约2875w/64),numHashFunctions:20
System.out.println("expectedInsertions:100w,fpp:0.0001%,匹配到的数量 " + bloomFilterCheck(baseList, inputList, baseList.size(), 0.000001));
// (3)条件:expectedInsertions:1000w,fpp:3%
// 结果:numBits:约7298w(数组size:约7298w/64),numHashFunctions:5
System.out.println("expectedInsertions:1000w,fpp:3%,匹配到的数量 " + bloomFilterCheck(baseList, inputList, baseList.size() * 10, 0.03));
}
/**
* 布隆过滤器
*
* @param baseList 过滤器中存储的数据
* @param inputList 待匹配的数据
* @param expectedInsertions 可能插入到过滤器中的总数据量
* @param fpp 误判率
* @return 在布隆过滤器中可能存在数据量
*/
private static int bloomFilterCheck(List<String> baseList, List<String> inputList, int expectedInsertions, double fpp) {
// 创建布隆过滤器
BloomFilter<String> bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), expectedInsertions, fpp);
// 初始化数据到过滤器中
for (String string : baseList) {
// 在对应索引位置存储非0的hash值
bf.put(string);
}
// 判断值是否存在过滤器中
int count = 0;
for (String string : inputList) {
if (bf.mightContain(string)) {
count++;
}
}
return count;
}
}运行结果
expectedInsertions:100w,fpp:3%,匹配到的数量 1000309
expectedInsertions:100w,fpp:0.0001%,匹配到的数量 1000000
expectedInsertions:1000w,fpp:3%,匹配到的数量 1000000结论:
expectedInsertions 和 fpp 决定了布隆过滤器的大小(数组大小),fpp 决定了哈希函数的个数。而布隆过滤器的大小和哈希函数的个数共同决定了布隆过滤器的误判率。
因此使用此过滤器时,需要根据存储到过滤器中的数据量,通过测试后,设置相对合理的expectedInsertions 和 fpp值,从而较小误判率。
3 参考文献
(1) 什么是布隆过滤器?如何使用?