- 数据操作语句(DML)
- 多表/关联查询
- Mysql中的函数
- 事务
- 执行流程
- 数据库的备份与还原
- 数据库表设计三范式
一、数据操作语句(DML)
- 插入数据
语法:
1.1插入(insert [into])或添加一条数据
-- 指定列表添加,只添加指定列的数据,其他列为默认值
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
-- 添加所有列的数据,值的顺序必须与表字段的顺序一致
INSERT INTO table_name
VALUES(value1,value2,value3...);
1.2 一次性添加多条数据
-- 指定列表添加,只添加指定列的数据,其他列为默认值
INSERT INTO table_name (column1,column2,column3...)VALUES
(value1,value2,value3...),
(value1,value2,value3...),
(value1,value2,value3...)..;
-- 添加所有列的数据,值的顺序必须与表字段的顺序一致
INSERT INTO table_name VALUES
(value1,value2,value3...),
(value1,value2,value3...),
(value1,value2,value3...)..;
- 修改数据
语法:
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
-- 注意注意:如果省略了where子句,则全表的数据都会被修改
-- 注意注意:修改时没有FROM
- 删除数据
语法:
DELETE FROM tablename [WHERE condition]; # 不会还原数据库表
TRUNCATE TABLE tablename; # 初始化表
Drop table tablename # 删除表
-- drop效率 > truncat > delete
-- 如果没有指定 WHERE 子句,MySQL 表中的所有记录将被删除。
-- 可以在 WHERE 子句中指定任何条件
-- 可以在单个表中一次性删除记录。
二、多表/关联查询
概念:实际应用中所需要的数据,经常会需要查询两个或两个以上的表。这种查询两个或两个以上数据表或视图的查询叫做连接查询或多表查询,连接查询的多个表通常有关联字段,所以也可以叫关联查询
- 笛卡尔积
概念:假设两个表的记录条数分别是X和Y,笛卡尔积将返回X * Y条记录。
注意:当两个表关联查询时,不写连接条件,得到的结果即是笛卡尔积。
例子:假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)}
SELECT COUNT(*) FROM emp; -- 14条记录
SELECT COUNT(*) FROM dept; -- 4条记录
SELECT * FROM emp, dept; -- 56条记录(14 * 4)
在实际运行环境下,应避免使用笛卡尔积。我们应该怎么去避免笛卡尔积?
- 使用WHERE加入有效的连接条件
- 连接 n张表,至少需要 n-1个连接条件
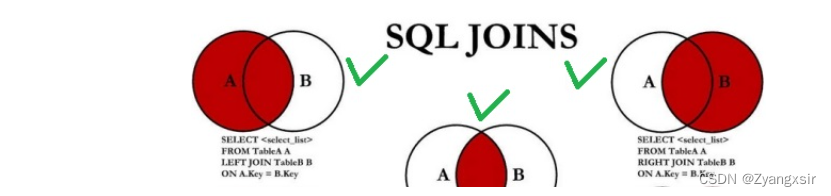
- 内连接
概念:内连接返回的仅是符合连接条件的行,不满足的过滤掉
语法:[INNER] JOIN … ON …,其中INNER可以省略
分类:
- 显示内连接 (SELECT * FROM abc INNER JOIN cde ON abc.c = cde.c;)
- 隐式内连接 (SELECT * FROM abc , cde WHERE abc.c = cde.c;)
区别:where擅长条件判断,join擅长表与表之间的联合查询,在多表查询的时候join更优where
表中使用别名:
- 使用别名在多个表中区分相同的列,在不同表中具有相同列名的列可以用表的别名加以区分
- 使用表名前缀可以提高执行效率
- 如果使用了表的别名,则不能再使用表的真名,而且表的字段要加上表别名
- 外连接
概念:返回那些不满足连接条件的记录
语法:LEFT/RIGHT [OUTER] JOIN ON
- 左外连接:把左表的所有数据全部查询数来,连接不上的用null值代替
- 右外连接:把右表的所有数据全部查询数来,连接不上的用null值代替
SELECT <selectList>
FROM A LEFT/RIGHT [OUTER] JOIN B
ON A.column_name = B.column_name;
- 子查询
概念:在SELECT查询中,在WHERE查询条件中的限制条件不是一个确定的值,而是来自于另外一个查询的结果。为了给查询提供数据而首先执行的查询语句叫做子查询
子查询:嵌入在其它SQL语句中的SELECT语句,大部分时候出现在WHERE子句中。子查询嵌入的语句称作主查询或父查询。主查询可以是SELECT语句,也可以是其它类型的语句
例子:
SELECT *FROM product p WHERE p.category_id = (SELECT category_id FROM product WHERE product_name= '罗技M90');
- 自连接
概念:把一张表看成两张表来做关联查询,一定要取别名 - 自连接是特殊的内连接,外连接或子查询
注意:一般自连接都有一个关联自己表的字段
三. Mysql中的函数
- 聚集/合函数
概念:聚集/聚合函数作用于一组数据,并对一组数据返回一个值,聚集函数会忽略NULL值
- COUNT:统计结果记录数,如果列的值为NULL,不会计算在内的,即会忽略NULL值
- MAX: 统计计算最大值
- MIN: 统计计算最小值
- SUM: 统计计算求和
- AVG: 统计计算平均值,如果列的值为NULL,不会计算在内的,即会忽略NULL值
- 字符串函数
2.1 LENGTH(s):返回字符串s的长度(字节数)
(1) SELECT LENGTH('你好123'); --> 9(UTF-8)
(2) select length("ABCss111"); --> 8
2.2 CONCAT(s1,s2,…):将字符串s1,s2等多个字符串合并为一个字符串。
注意:如果有任何参数为null,则函数返回null。如果参数是数字,则自动转换为字符串
(1) SELECT CONCAT('12','34'); --> 1234
(2) SELECT CONCAT('My',null,'QL'); --> NULL
(3) SELECT CONCAT(12.3, 'mysql'); --> 12.3mysql
2.3 UPPER(s):将字符串s的所有字母变成大写字母
SELECT UPPER('abc'); --> ABC
2.4 LOWER(s):将字符串s的所有字母变成小写字母
SELECT LOWER('ABC'); --> abc
2.5 TRIM(s):去掉字符串s开始和结尾处的空格
SELECT TRIM(' abc dd '); --> abc dd
- 日期函数
3.1 CURDATE(),CURRENT_DATE(),CURRENT_DATE:返回当前日期
SELECT CURDATE(); --> 2018-07-10
3.2 CURTIME(),CURRENT_TIME(),CURRENT_TIME:返回当前时间
SELECT CURTIME(); --> 09:02:12
3.3 NOW():返回当前日期和时间 (一般都用这个)
SELECT NOW(); --> 2018-07-10 09:04:34
3.4 YEAR(d):接受date参数,并返回日期的年份
(1) SELECT YEAR('2018-07-10 12:12:12'); --> 2018
(2) SELECT YEAR('2018-07-10'); --> 2018
- 控制流程函数
4.1 IF(test,arg1,arg2):如果test是真,返回arg1;否则返回arg2;
(1) SELECT IF(1 = 1,2,3); --> 2
(2) SELECT IF(1 = 2,2,3); --> 3
4.2 case — when — then — end;
case
when 条件1 then 要显示的值或语句;
when 条件2 then 要显示的值或语句;
...
else 要显示的值或语句;
end # 这里注意不要打;号,因为后面还有写from 表名
--------------------------------------------------------------------------------
-- 案例
SELECT
salary,
CASE
WHEN salary > 20000 THEN
'A'
WHEN salary > 15000 THEN
'B'
WHEN salary > 10000 THEN
'C'
ELSE 'D'
END AS 工资级别
FROM
employees;
四. 事务
概念:把多个操作看成是一个不可分割的工作单位,要么同时成功,要么同时失败
作用:
- 确保数据库的完整性和一致性(数据库操作要么全部完成,要么全部不完成)
- 实现并发控制(某一时刻只有一个用户或进程对数据执行修改操作)
- 简化复杂操作(然后一次性提交或回滚,而不是逐个处理)
- 支持回滚操作(撤销自事务开始以来的所有操作)
- 提高性能(减少磁盘I/O操作的次数)
事务操作:
MYSQL中有两种方式进行事务的操作:
- 自动提交事务:即执行一条sql语句提交一次事务,默认MySQL的事务是自动提交
- 手动提交事务:先开启,再提交
-- 开启事务
begin;
-- 张三账户扣钱
update t_account set balance = (balance-100) where id = 1;
-- 李四账户加钱
update t_account set balance = (balance+100) where id = 2;
-- 如果成功执行
commit ;
-- 如果失败执行
rollback ;
事务四大特性(简称ACID):
- 原子性(Atomicity):事务必须是一个原子的操作序列单元,事务中操作在一次执行过程中,只允许出现两种状态之一
- 一致性(Consistency):一个事务在执行之前和执行之后,数据库都必须处以一致性状态。
- 隔离性(Isolation):一个事务的执行不能被其它事务干扰。
- 持久性(Duration):事务一旦提交后,数据库中的数据必须被永久的保存下来。
五. 执行流程
- 关键字执行流程
写的顺序:select…from…join…on…where…group by…having…order by…limit…
执行顺序:from…join…on…where…group by…having…select…order by…limit…
- FROM:决定从哪一个表查询
- JOIN:决定跟哪一个表关联
- ON:决定关联表的共同条件
- WHERE:决定从表中哪一些开始查询(条件过滤,学会善用条件过滤)
- GROUP BY:决定按照什么分组进行组内查询,一般跟聚集函数联合使用,MySql数据库此时可以使用别名
- HAVING:在组内条件过滤,一般使用SELECT语句中的聚集函数作为过滤条件
- SELECT:决定显示哪一些字段
- DISTINCT:根据select中的字段决定显示哪一些不重复的字段
- ORDER BY:决定显示的排序规则
- LIMIT:决定每一页显示多少条件记录
- 子查询的执行流程
概念:从最里面(深)的查询语句开始执行,逐级向外执行,直到最后一层
注意:子查询一般是用在where语句和from语句中,执行流程满足上面的执行流程
六. 数据的备份与恢复
方式一:在dos命令行窗口进行,若操作系统版本高,则使用管理员模式
- 导出:
mysqldump -u账户 -p密码 数据库名称 > 脚本文件存储地 mysqldump -uroot -padmin jdbcdemo> C:/shop_bak.sql
- 导入:
mysql -u账户 -p密码 数据库名称 < 脚本文件存储地址 mysql -uroot -padmin jdbcdemo< C:/shop_bak.sql
方式二:使用可视化导入导出:Navicat工具的导入和导出/Navicat工具的备份和还原
七. 数据库表设计三范式
数据库表设计三范式(简称3NF):以后设计数据库表都需要遵守数据库三范式进行设计
第一范式:列唯一
列不可再分,保持原子性,关系型数据库默认支持
第二范式:行唯一
需要加一列作为唯一标识。这列被称为主键【非空且唯一】,并且行中每一列数据都与主键相关
第三范式:如果一张表的数据能够通过其他表推导出来,不应该单独设计,通过外键的方式关联查询出来
作用:减少数据冗余
反3FN:适当的反第三范式可以有效提高系统查询性能(变多表查询为单表查询)
原则上是不能违反三范式的,但是有的时候我们为了增强查询效率【不用关联查询,直接单表查询】,会设计一些冗余字段,变多表查询为单表查询
总结:三大范式只是一般设计数据库的基本理念,可以建立冗余较小、结构合理的数据库。特殊情况,特殊对待,数据库设计最重要的是看需求跟性能(需求>性能>表结构)
课程总结:
1. DML - 数据操作语言
增删改:
2.多表查询=关联查询
笛卡尔积:多张表查询的时候没有写连接条件
内连接:只查询连接上的,连接不上的不查询。关键字:[inner] join... on
外连接:查询左表或右表的所有数据,连接不上的用null值替换。关键字:left/right join... on
子查询:查询的条件或表不是确定的,是要通过查询语句查询出来。这个查询语句就是子查询。外部的查询主查询
自连接:特殊的内连接,外连接或子查询。自己连自己
一般自连接都有一个连接自己的字段:parent_id
3.mysql函数
聚合函数:count()、max()、min()、sum()、avg()
concat():拼接字符串 length()
now(),year(now())
if(1=2,2,3)
case...then...
4.事务
事务是将多个操作看成一个整体,要么都成功,要么都失败
事务的sql:begin,commit,rollback
事务四大特性:原子性,一致性,隔离性,持久性
5.执行流程
from -> join...on -> where -> group by -> having -> select -> order by -> limit
6.数据的备份(导出)和还原(导入)
客户端操作:
命令操作:mysqldump -uroot -p123456 数据库>d:/sql/zxzz.sql
mysql -uroot -p123456 数据库<d:/sql/zxzz.sql
7.数据库设计三范式:
列唯一(列不可再分) - 关系型数据库默认支持
行唯一 - 要设计主键
如果一个表的数据可以通过另外一个查询出来,数据不应该单独设计。而是设计外键关联查询
反3FN - 为了提高查询效率,减少关联表的查询
要么都成功,要么都失败
事务的sql:begin,commit,rollback
事务四大特性:原子性,一致性,隔离性,持久性
5.执行流程
from -> join…on -> where -> group by -> having -> select -> order by -> limit
6.数据的备份(导出)和还原(导入)
客户端操作:
命令操作:mysqldump -uroot -p123456 数据库>d:/sql/zxzz.sql
mysql -uroot -p123456 数据库<d:/sql/zxzz.sql
7.数据库设计三范式:
列唯一(列不可再分) - 关系型数据库默认支持
行唯一 - 要设计主键
如果一个表的数据可以通过另外一个查询出来,数据不应该单独设计。而是设计外键关联查询
反3FN - 为了提高查询效率,减少关联表的查询