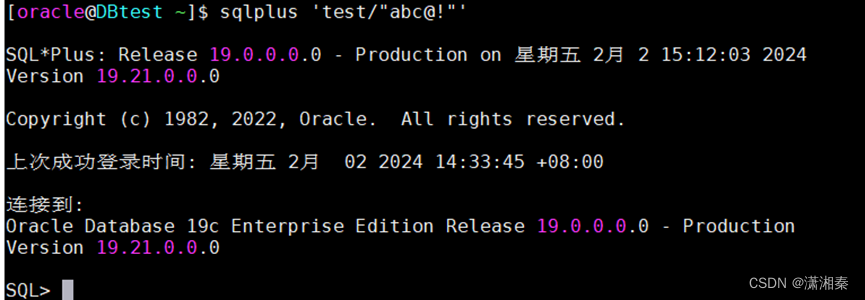
文章目录
- 前言
- pipeline
- audio-to-motion
- Motion domain adaptation
- 可视化
- Motion-to-image
- Head-NeRF
- Torso-NeRF
- 结果对比
前言
语音驱动的说话人视频合成旨在根据一段输入的语音,合成对应的目标人脸说话视频。高质量的说话人视频需要满足两个目标:
(1)合成的视频画面应具有较高的保真度;
(2)合成的人脸面部表情应与输入的驱动语音保证高度对齐。
基于NeRF的说话人视频合成算法,仅需要3-5分钟左右的目标人说话视频作为训练数据,即可合成该目标人说任意语音的视频,在实现第二个目标还面临许多挑战。
- 对域外驱动音频的弱泛化能力:由于训练数据集仅包括数分钟的说话人语音-面部表情的成对数据,模型对不同说话人、不同语种、不同表现形式等域外音频难以生成准确的面部表情。
- “平均脸”问题:由于相同的语音可能有多种合理的面部动作,使用确定性的回归模型来学习这样一个语音到动作的映射可能导致过于平滑的面部动作和较低的表情表现力。
pipeline
GeneFace 采用 3D 人脸关键点作为中间变量,提出了一个三阶段的框架:
- Audio-to-motion:在大规模唇语识别数据集上学习语音到动作的映射高泛化能力。我们设计了一个变分动作生成器来学习这个语音到面部动作的映射。
- Motion domain adaptation:提出了一种基于对抗训练的域适应方法,以训练一个人脸动作的后处理网,从而弥合大规模唇语识别数据集与目标人视频之间的域差距。
- Motion-to-image:设计了一个基于 NeRF 的渲染器(3DMM NeRF Renderer),它以预测的 3D 人脸关键点为条件来渲染高保真的说话人视频。
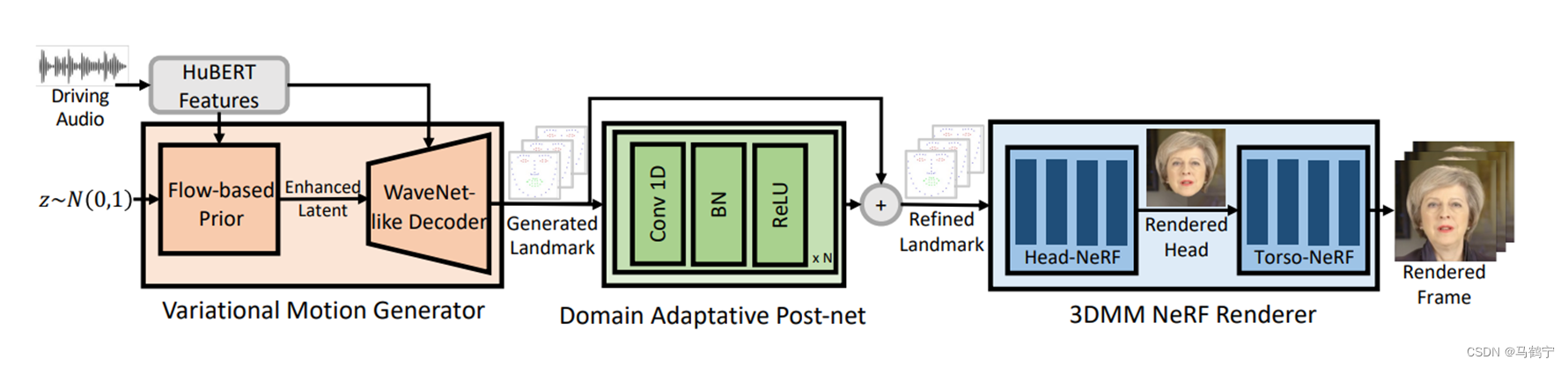
audio-to-motion
audio2motion在一个大的数据上进行训练,适用于所有的说话人视频,仅需要训练一次。

语义信息:利用 HuBERT 模型从原始音频中提取语音表征。
动作表示:为了能在欧几里得空间中表示详细的面部运动,从重建的3D头部网格中选择68个关键点,使用它们的位置作为动作表示。
| 编码器 | 解码器 | 流模型 |
|---|---|---|
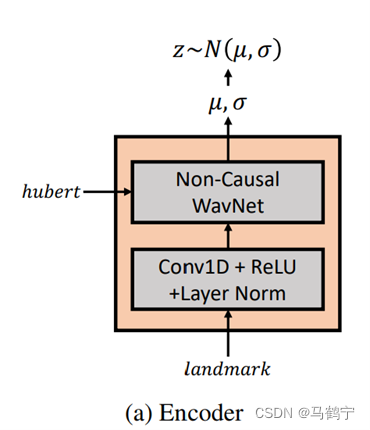 | 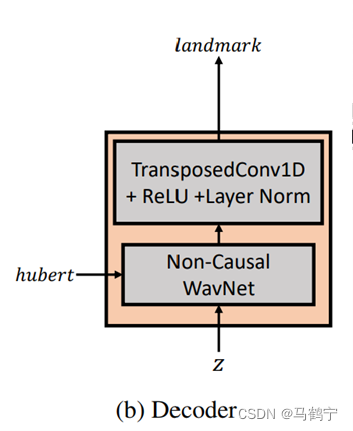 | 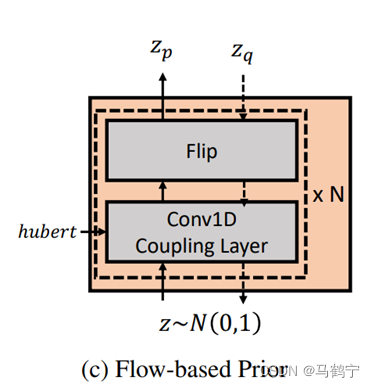 |
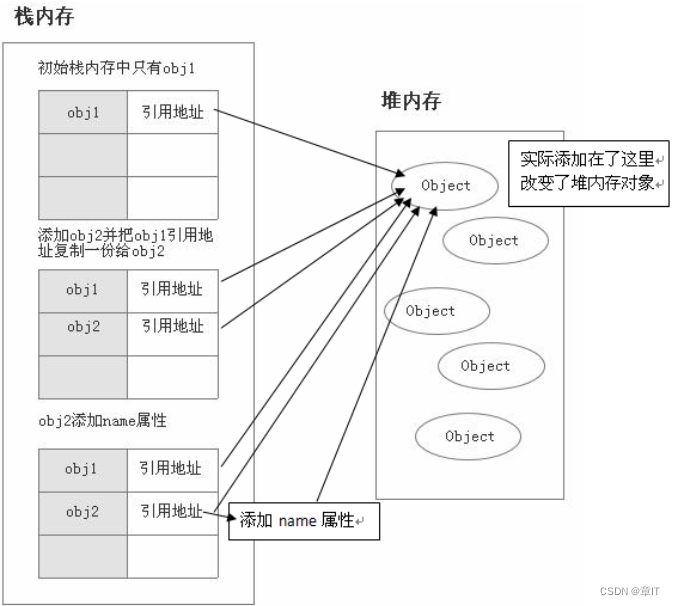
原始变分自编码器的高斯先验从两个方面限制了3D标志序列生成过程的性能:
- 每个时间索引的数据点彼此独立,给序列生成任务引入了噪声,因为帧之间存在坚实的时序相关性。
- 优化VAE先验将后验分布推向均值,限制了多样性和破坏了生成能力
为此,利用归一化流为VAE提供复杂且与时间相关的先验分布。流模型,一种比较独特的生成模型,通过一系列可逆变换建立较为简单的先验分布与较为复杂的实际数据分布之间的映射关系。
Motion domain adaptation
在给定的多说话人数据集上训练variational motion generator时,模型可以很好地处理各种音频输入。然而,由于目标人物视频的规模相对较小(大约4-5分钟),与多说话人唇读数据集(大约数百小时)相比,预测的3D landmark与目标人物领域之间存在领域偏差。因此需要将VAE预测的3D landmark 细化为Personalize domain。
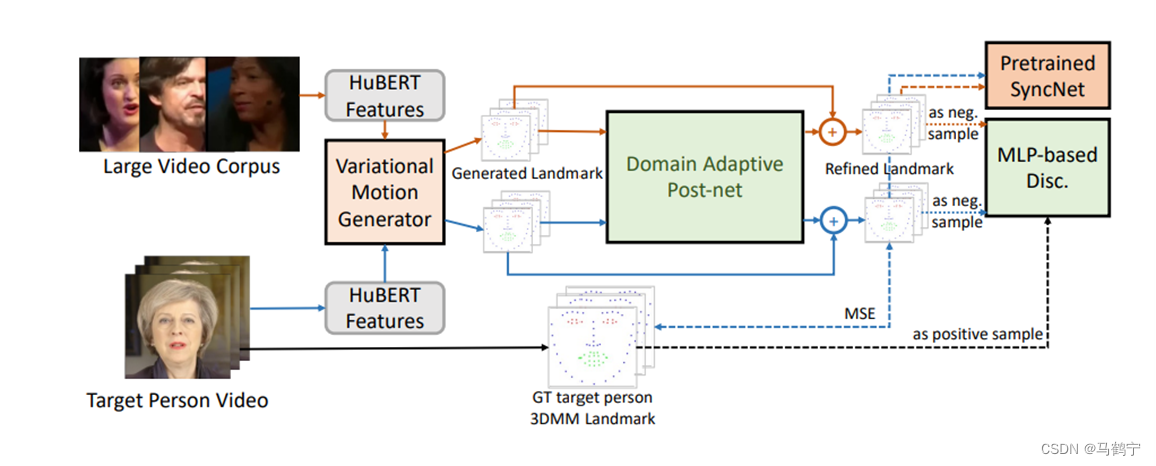 要求:
要求:
- 保证输入序列的时间一致性和嘴唇同步
- 将每一帧正确地映射到目标人领域
方案:为了满足第一点,使用1D卷积为后处理网络的结构,并采用同步专家来监督嘴唇同步。对于第二点,我们联合训练一个MLP结构的帧级鉴别器,该鉴别器测量每个关键点帧与目标人的身份相似性。
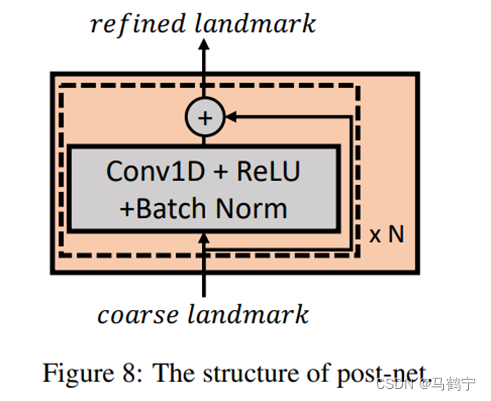
postnet模型仅适用于对应的说话人视频,所以对每个新的说话人视频都需要训练一个新的postnet。而且训练postnet时,既需要大的说话人数据集,也需要对应的说话人数据集。
可视化
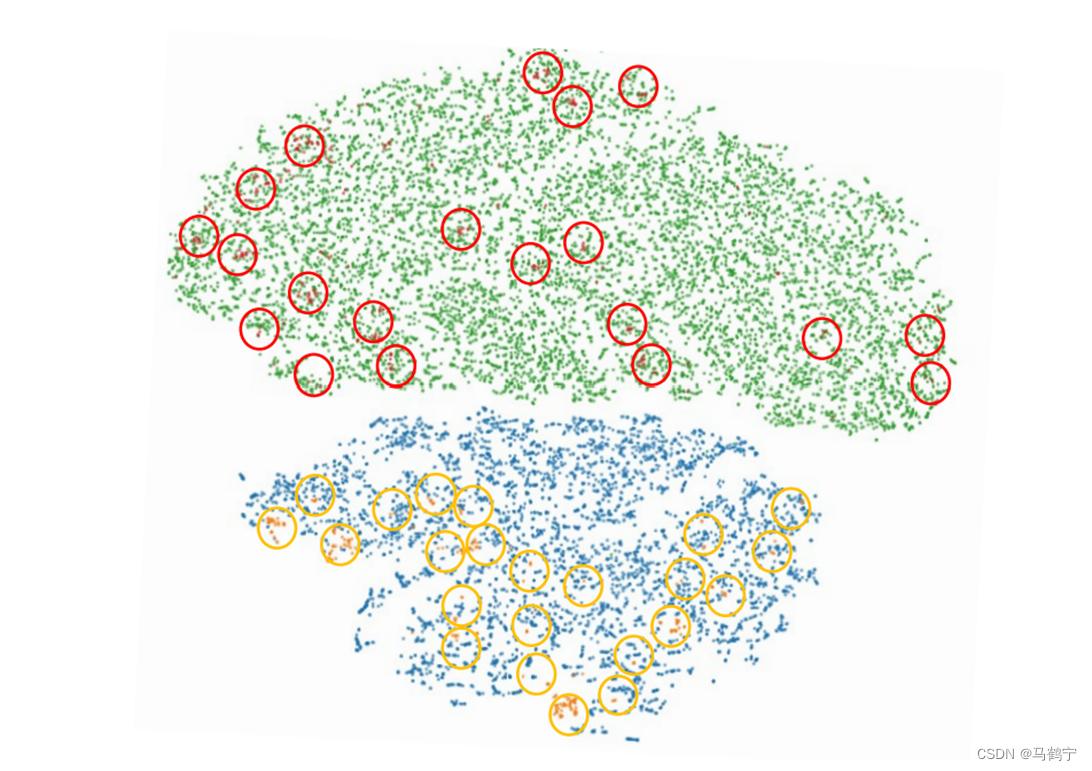
- 绿色点表示LRS3数据集的gt landmarks.
- 蓝色点表示特定人视频的gt landmarks
- 红色点表示无域自适应时的预测landmarks
- 黄色点表示有域自适应时的预测landmarks
可以从上图中看出,post-net模型将预测的人脸landmarks从大数据集的空间域迁移到特定人的域中,这样更能保证嘴型的同步性。
Motion-to-image
NeRF将一个连续的场景表示为一个输入为5D向量的函数,它的输入由一个空间点的3D位置
x
=
(
x
,
y
,
z
)
\mathbf{x} = \left( x, y, z \right)
x=(x,y,z)和它的2D视角方向
d
=
(
θ
,
ϕ
)
\mathbf{d} = \left( \theta, \phi \right)
d=(θ,ϕ),输出为对应3D位置的颜色
c
=
(
r
,
g
,
b
)
\mathbf{c} = \left(r,g,b \right)
c=(r,g,b)和体素密度
σ
\sigma
σ。NeRF函数用公式表示就是:
F
(
x
,
d
)
→
(
c
,
σ
)
F \left( \mathbf{x}, \mathbf{d} \right) \rightarrow \left( c, \sigma \right)
F(x,d)→(c,σ)
以3DMM landmark作为条件变量,基于NeRF进行三维重建,需要先对头部进行重建,然后以头部为条件变量,重建躯干。
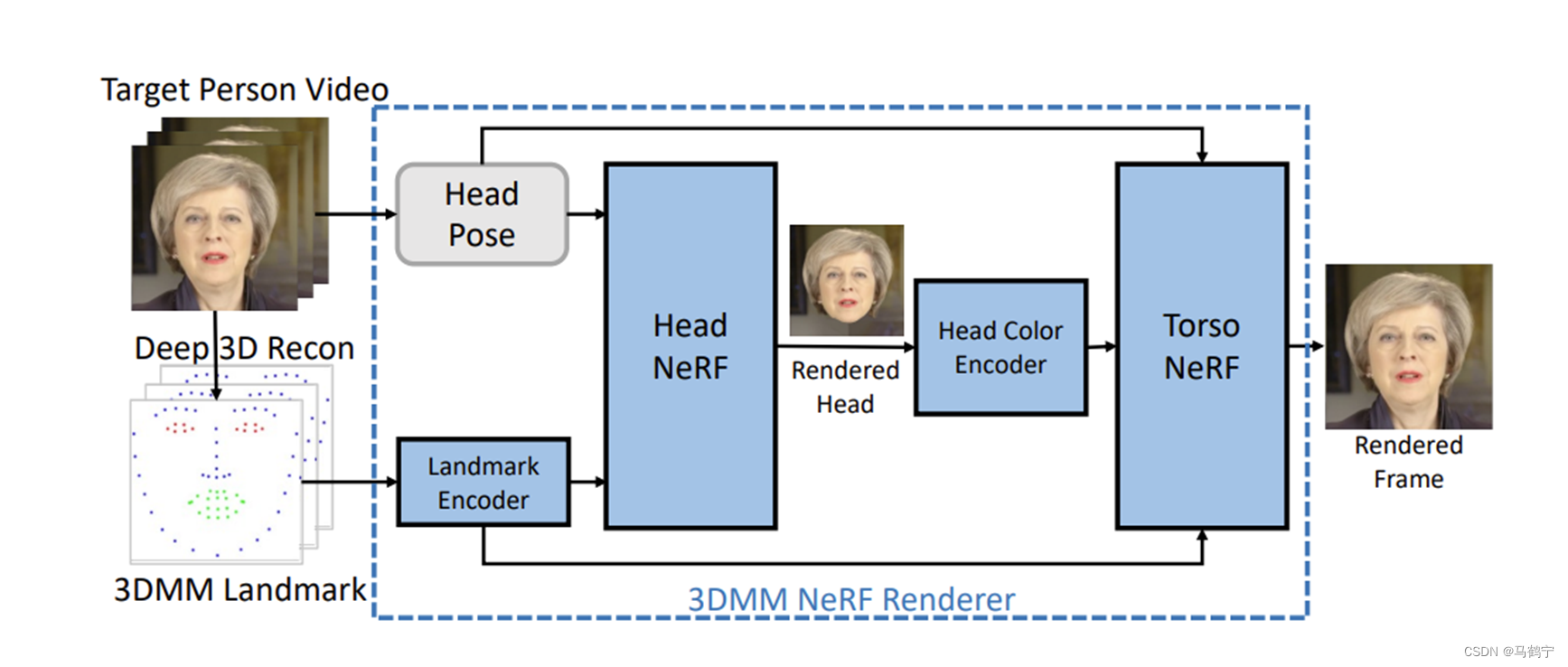
Head-NeRF
将landmark
l
l
l作为NeRF的条件变量,用公式表示如下:
F
θ
(
x
,
d
,
l
)
→
(
c
,
σ
)
F_{\theta} \left( \mathbf{x}, \mathbf{d}, l \right) \rightarrow \left( c, \sigma \right)
Fθ(x,d,l)→(c,σ)
颜色
C
C
C计算的公式如下所示:

Torso-NeRF
基于head-NeRF的输出颜色
C
h
e
a
d
C_{head}
Chead作为torso-NeRF像素级的条件,torso-NeRF的公式表示如下:
F
t
o
r
s
o
(
x
,
C
h
e
a
d
,
d
0
,
Π
,
l
)
→
(
c
,
σ
)
F_{torso} \left( x, C_{head},d_{0}, \Pi ,l \right) \rightarrow \left( c, \sigma \right)
Ftorso(x,Chead,d0,Π,l)→(c,σ)
结果对比
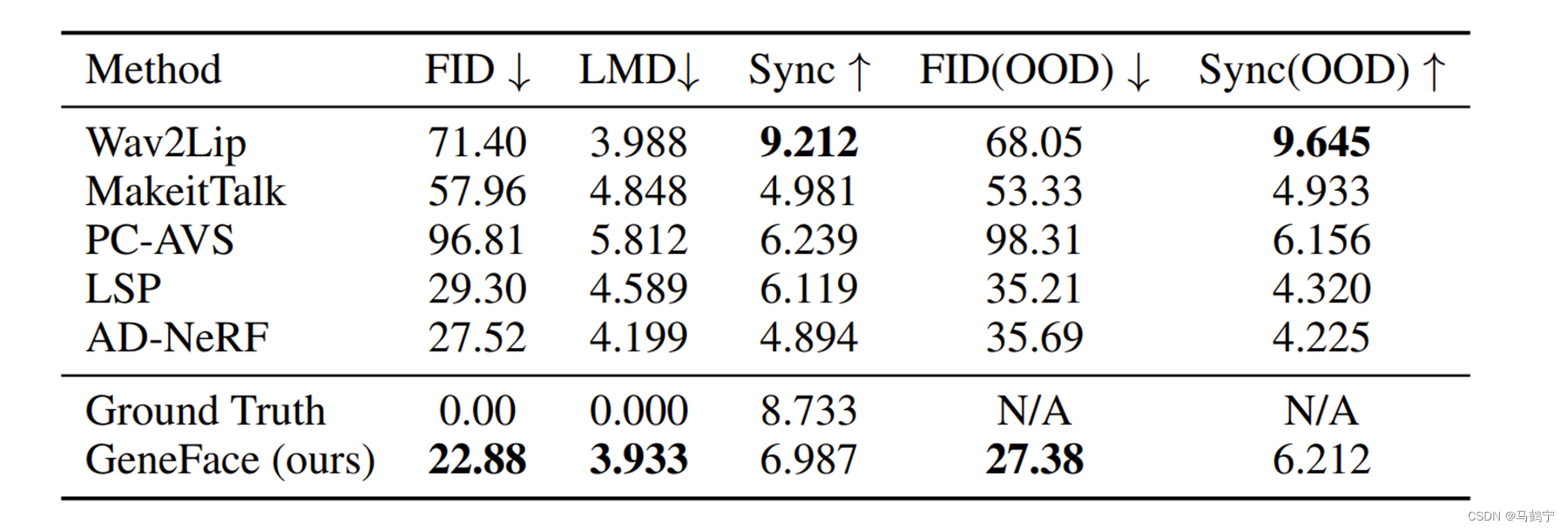
- FID(Frechet Inception Distance score),是计算真实图像和生成图像的特征向量之间距离的一种度量。分数越低代表两组图像越相似。
- LMD(Landmark Distance)是用于评估面部图像生成质量的指标,它用于度量生成的面部图像与真实面部图像之间的面部特征点的距离,以衡量生成的面部图像与真实面部图像之间的相似性。LMD得分越低,面部图像生成质量越高。