欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送!
在我后台回复 「资料」 可领取
编程高频电子书!
在我后台回复「面试」可领取硬核面试笔记!文章导读地址:点击查看文章导读!
感谢你的关注!
快手后端一面:G1、IOC、AOP、并发、JVM生产问题定位、可重复读、ThreadLocal
题目分析
1、G1 垃圾回收的过程
G1 的垃圾回收过程如下:
1、初始标记:标记一下 GC Roots 能直接关联到的对象,需要停顿线程,但耗时很短
2、并发标记:是从 GC Roots 开始对堆中对象进行可达性分析,找出存活的对象,这阶段耗时较长,但可与用户程序并发执行
3、最终标记:修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录
4、筛选回收:对各个 Region 的回收价值和成本进行排序,根据用户所期望的 GC 停顿时间来制定回收计划
扩展:
既然提到 GC Roots,那么面试官可能会问一下,GC Roots 包含哪些对象,这个不用全部背出来,但是你要了解一下
GC Roots 主要包含的对象:
-
虚拟机栈中引用的对象
如:各个线程被调用的方法中所使用的参数、局部变量等
-
本地方法栈内的本地方法引用的对象
-
方法区中引用类型的静态变量
-
方法区中常量引用的对象
如:字符串常量池里的引用
-
所有被
synchronized持有的对象 -
Java 虚拟机内部的引用
如:基本数据类型对应的 Class 对象、异常对象(如 NullPointerException、OutOfMemoryError)、系统类加载器
2、什么是 IOC 和 AOP 呢?
这个也是比较常见的面试题了,没有什么难度
IOC:
Spring IOC 是为了去解决 类与类之间的耦合 问题的
如果不用 Spring IOC 的话,如果想要去使用另一个类的对象,必须通过 new 出一个实例对象使用:
UserService userService = new UserServiceImpl();
这样存在的问题就是,如果在很多类中都使用到了 UserServiceImpl 这个对象,但是如果因为变动,不去使用 UserServiceImpl 这个实现类,而要去使用 UserManagerServiceImpl 这个实现类,那么我们要去很多创建这个对象的地方进行修改,这工作量是巨大的
有了 IOC 的存在,通过 Spring 去统一管理对象实例,我们使用 @Resource 直接去注入这个
@Resource
UserService userServiceImpl;
如果要切换实现类,通过注解 @Service 来控制对哪个实现类进行扫描注册到 Spring 即可,如下
@Controller
public class UserController {
@Resource
private UserService userService;
// 方法...
}
public class UserService implements UserService {}
@Service
public class UserManagerServiceImpl implements UserService {}
AOP:
Spring AOP 主要是 去做一个切面的功能 ,可以将很多方法中 通用的一些功能从业务逻辑中剥离出来 ,剥离出来的功能通常与业务无关,如 日志管理、事务管理等,在切面中进行管理
Spring AOP 实现的底层原理就是通过动态代理来实现的,JDK 动态代理和 CGLIB 动态代理
Spring AOP 会根据目标对象是否实现接口来自动选择使用哪一种动态代理,如果目标对象实现了接口,默认情况下会采用 JDK 动态代理,否则,使用 CGLIB 动态代理
JDK 动态代理和 CGLIB 动态代理具体的细节这里就不讲了,可以参考之前我写的文章
3、Spring MVC 处理一个请求的过程?
Spring MVC 的执行流程,其实一句话就是通过 url 找到对应的处理器,执行对应的处理器即可(也就是 Controller),我也画了一张流程图,看着复杂,其实就是找到对应的 Handler 再执行,这里是通过 HandlerAdpter 来执行对应的 Handler
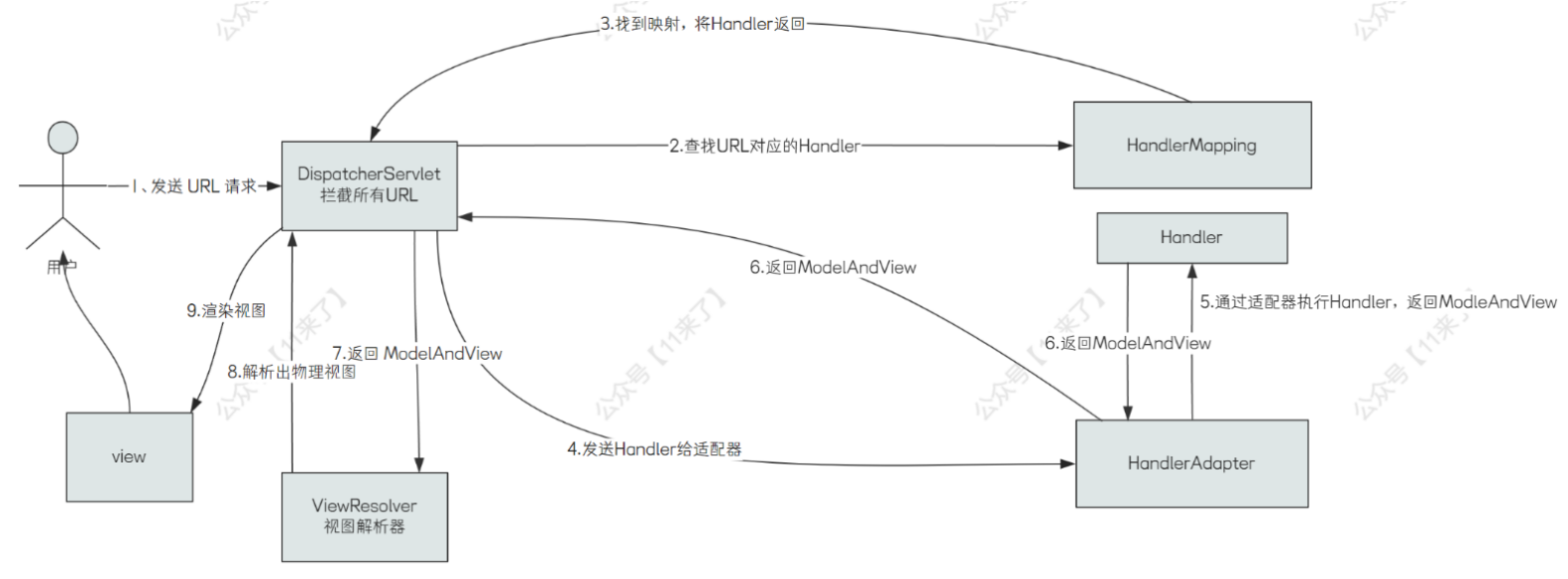
这里通过 Adapter 来执行 Handler 就使用了 适配器模式,那么适配器模式有什么好处呢?
让相互之间不兼容的类可以一起工作,客户端可以调用适配器的方法来适配不同的逻辑,这里举个例子:
如下,AdvancedMediaPlayer 是用来被适配的类,可以看到被适配的类中有两个不同的方法,要在不同的情况下调用不同的方法,那么就创建了 MediaPlayerAdapter 适配器类,定义一个 play() 方法,根据传入的类型不同,调用不同的方法,那么如果后来增加被适配的类,那么我们只需要在适配器中添加一个 if 条件即可完成扩展,这就是适配器模式的优势
public interface MediaPlayer {
void play(String audioType, String fileName);
}
// 被适配的类
public class AdvancedMediaPlayer {
public void playMp4(String fileName) {
System.out.println("Playing MP4 file: " + fileName);
}
public void playVlc(String fileName) {
System.out.println("Playing VLC file: " + fileName);
}
}
// 适配器
public class MediaPlayerAdapter implements MediaPlayer {
private AdvancedMediaPlayer advancedMediaPlayer;
public MediaPlayerAdapter(AdvancedMediaPlayer advancedMediaPlayer) {
this.advancedMediaPlayer = advancedMediaPlayer;
}
@Override
public void play(String audioType, String fileName) {
if ("mp4".equals(audioType)) {
advancedMediaPlayer.playMp4(fileName);
} else if ("vlc".equals(audioType)) {
advancedMediaPlayer.playVlc(fileName);
} else {
throw new IllegalArgumentException("Unsupported media type: " + audioType);
}
}
}
4、过滤器和拦截器的区别?
过滤器和拦截器的区别在于它们的位置不同,以及语义有一些区别
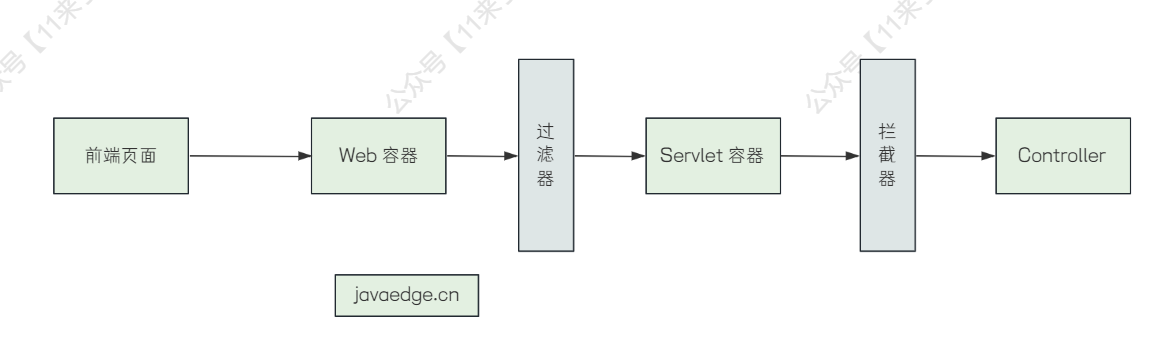
首先,过滤器的位置是处于 Web 容器和 Servlet 容器之间的,主要是提供一些通用任务的处理,例如日志记录、用户授权、请求校验等功能
而拦截器是 Spring 中的概念,它的位置处于 SpringMVC 的 DispatchServlet 和 Controller 之间,主要用来对 Spring MVC 请求进行前置和后置处理
过滤器是 Servlet 规范中的一部分,而拦截器是 Spring MVC 中的一部分,
一般来说,使用过滤器对做一些简单的预处理或或处理的操作,使用拦截器可以更加细粒度的控制请求,并进行相应的处理
过滤器的使用:
通过实现 javax.servlet.Filter 接口来完成
@Component
public class MyFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
// 初始化逻辑
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
// 处理请求和响应的逻辑
chain.doFilter(request, response); // 继续处理请求
}
@Override
public void destroy() {
// 销毁逻辑
}
}
拦截器的使用:
通过实现 HandlerInterceptor 接口来完成
// 创建拦截器
@Component
public class MyInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
// 请求处理前执行的逻辑
return true; // 返回true继续处理请求,返回false则中断请求
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) {
// 请求处理后执行的逻辑
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {
// 请求处理完成后执行的逻辑
}
}
// 注册拦截器
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Autowired
private MyInterceptor myInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(myInterceptor)
.addPathPatterns("/**") // 指定拦截路径
.excludePathPatterns("/login") // 排除路径
.order(1); // 设置拦截器顺序
}
}
5、ConcurrentHashMap 如何实现互斥?
这里互斥指的应该就是线程之间的互斥,也就是 ConcurrentHashMap 如何保证线程安全了
这里最重要的就是,了解 ConcurrentHashMap 在插入元素的时候,在哪里通过 CAS 和 synchronized 进行加锁了,是对什么进行加锁
对于 ConcurrentHashMap 来说:
- 在 JDK1.7 中,通过
分段锁来实现线程安全,将整个数组分成了多段(多个 Segment),在插入元素时,根据 hash 定位元素属于哪个段,对该段上锁即可 - 在 JDK1.8 中,通过
CAS + synchronized来实现线程安全,相比于分段锁,锁的粒度进一步降低,提高了并发度
这里说一下在 插入元素 的时候,如何做了线程安全的处理(JDK1.8):
在将节点往数组中存放的时候(没有哈希冲突),通过 CAS 操作进行存放
如果节点在数组中存放的位置有元素了,发生哈希冲突,则通过 synchronized 锁住这个位置上的第一个元素
那么面试官可能会问 ConcurrentHashMap 向数组中存放元素的流程,这里我给写一下(主要看一下插入元素时,在什么时候加锁了):
-
根据 key 计算出在数组中存放的索引
-
判断数组是否初始化过了
-
如果没有初始化,先对数组进行初始化操作,通过 CAS 操作设置数组的长度,如果设置成功,说明当前线程抢到了锁,当前线程对数组进行初始化
-
如果已经初始化过了,判断当前 key 在数组中的位置上是否已经存在元素了(是否哈希冲突)
-
如果当前位置上没有元素,则通过 CAS 将要插入的节点放到当前位置上
-
如果当前位置上有元素,则对已经存在的这个元素通过 synchronized 加锁,再去遍历链表,通过将元素插到链表尾
6.1 如果该位置是链表,则遍历该位置上的链表,比较要插入节点和链表上节点的 hash 值和 key 值是否相等,如果相等,说明 key 相同,直接更新该节点值;如果遍历完链表,发现链表没有相同的节点,则将新插入的节点插入到链表尾即可
6.2 如果该位置是红黑树,则按照红黑树的方式写入数据
-
判断链表的大小和数组的长度是否大于预设的阈值,如果大于则转为红黑树
当链表长度大于 8 并且数组长达大于 64 时,才会将链表转为红黑树
6、JVM 堆内存缓慢增长如何定位哪行代码出问题?
这里说一下如何通过 Java VisualVM 工具来定位 JVM 堆内存缓慢增长的问题
堆内存缓慢增长,可能是内存泄漏,也可能是 GC 效率低等原因
下边这段为演示代码:
public static void main(String[] args) throws InterruptedException {
List<Object> strs = new ArrayList<>();
while (true) {
strs.add(new DatasetController());
Thread.sleep(10);
}
}
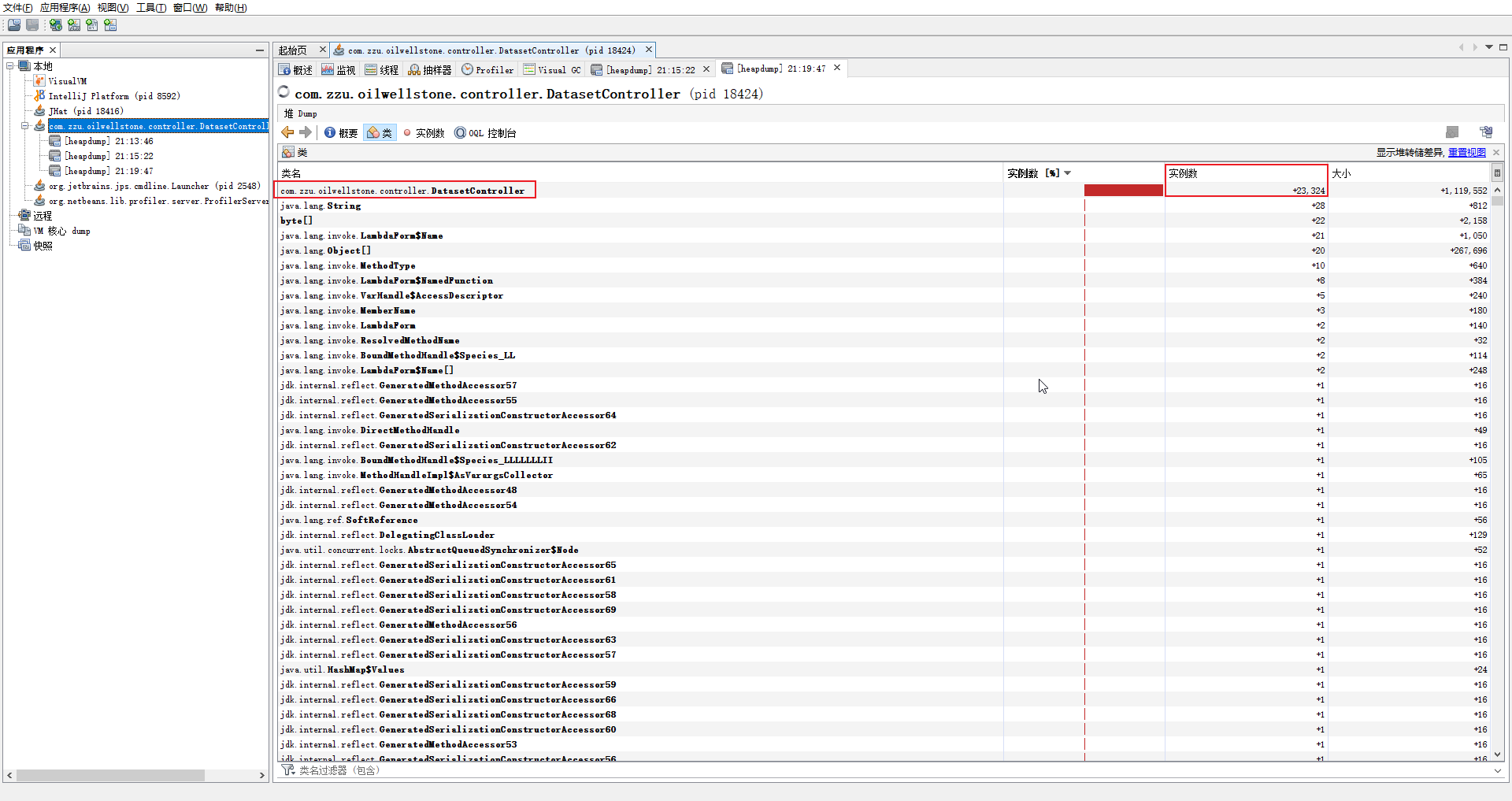
可以通过命令 jvisualvm 来启动 Java VisualVM,隔一段时间生成一份堆 dump 文件,也就是堆转储文件
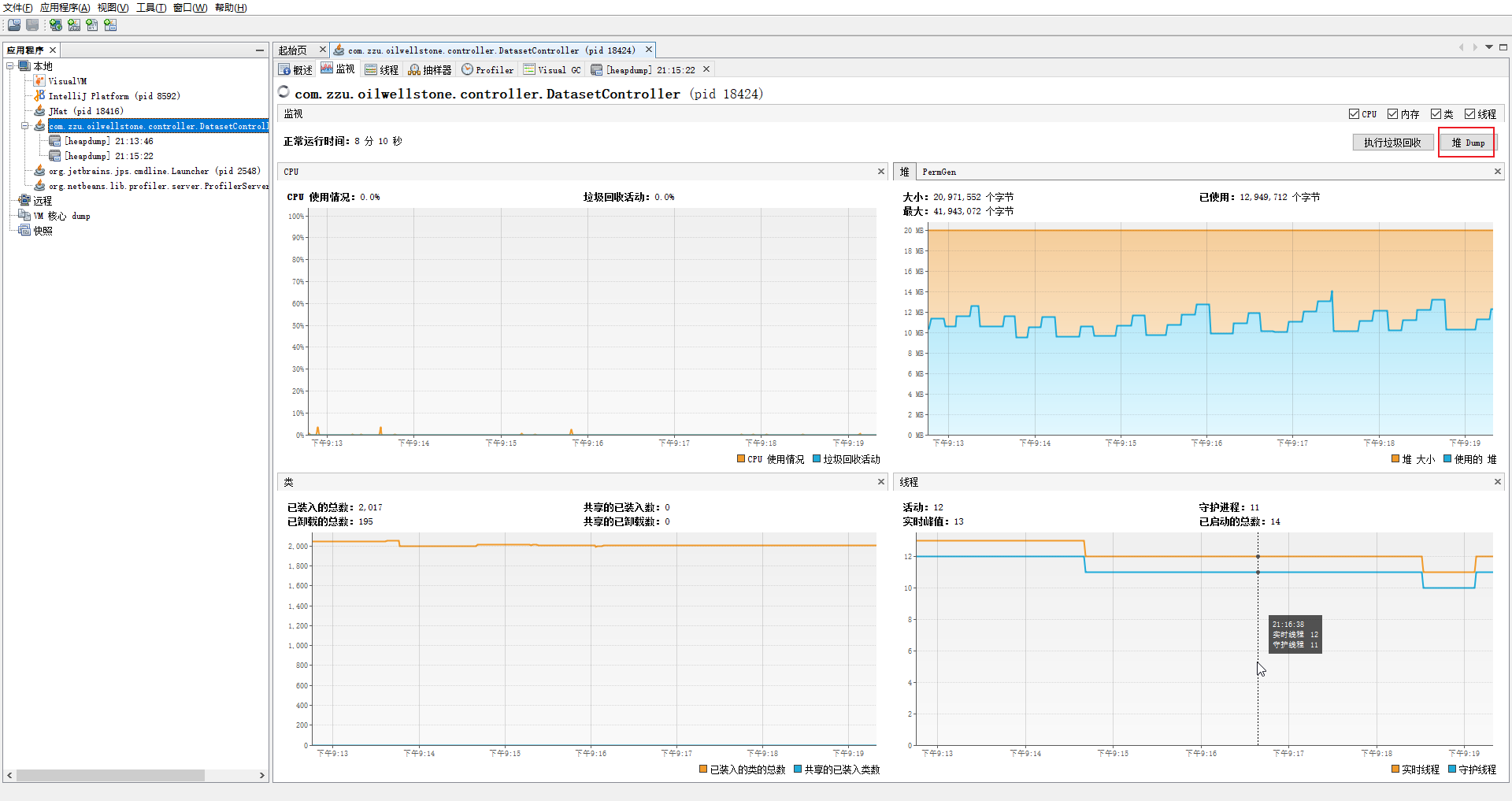
通过不同时间点的堆转储文件之间的 对比 来分析是因为哪些对象增长的比较多
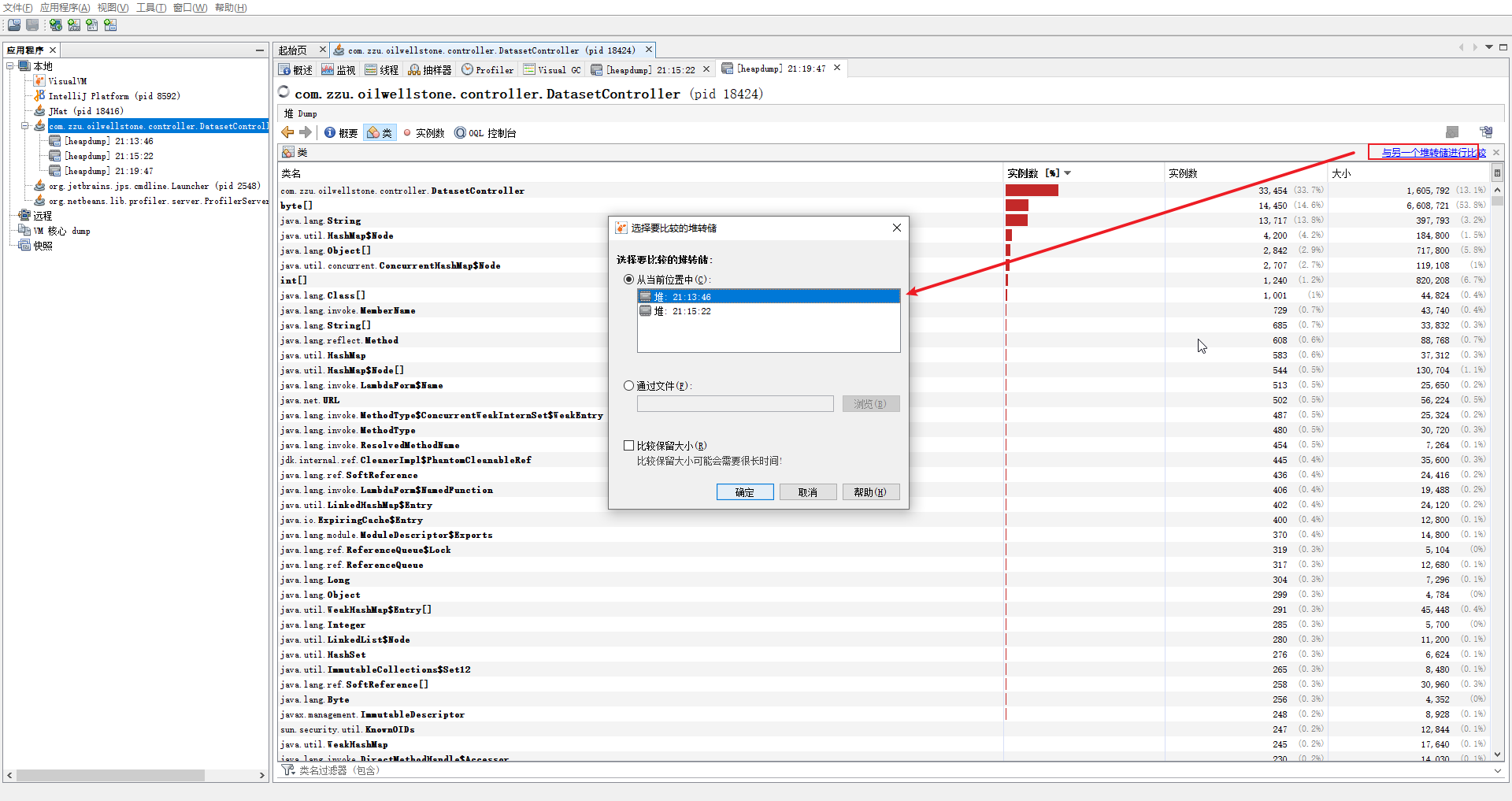
下边这张图就是两个堆转储文件之间的对比图,可以发现 DatasetController 这个实例对象相比于上个堆转储文件增长了 2 w 多个数量,那么就可以去分析一下哪里的代码创建了这个对象,就可以定位到问题代码
7、如何确定哪个对象占用堆内存大?
上边通过 VisualVM 工具分析堆转出快照就可以直接找到哪个对象占用的空间比较大了
8、讲讲调度线程池 ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor 用于执行周期性的任务,该线程池继承自 ThreadPoolExecutor 类
public class ScheduledTaskExample {
public static void main(String[] args) {
// 创建一个固定大小为5的线程池
ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(5);
// 安排任务在延迟1秒后执行,之后每隔2秒执行一次
executor.scheduleAtFixedRate(() -> {
System.out.println("任务执行了:" + System.currentTimeMillis());
}, 1, 2, TimeUnit.SECONDS);
// 让主线程等待一段时间,以便观察任务执行
try {
Thread.sleep(15000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 关闭线程池
executor.shutdown();
}
}
上边给出一个简单的用法,将任务提交到 ScheduledThreadPoolExecutor 中,在提交任务后,延迟 1s 开始执行,之后每 2 s 执行一次
下面简单说一下他的实现原理:
ScheduledThreadPoolExecutor 通过内部的一个延迟队列 DelayedWorkQueue 来存储待执行的任务,当线程从任务队列取出任务时会判断是单次执行还是周期执行的任务,如果是周期执行,那么在任务完成之后,重新放入到队列中去
9、可重复读的实现机制?
可重复读是 MySQL 中的一种事务隔离级别,是通过多版本并发控制(MVCC)来实现的
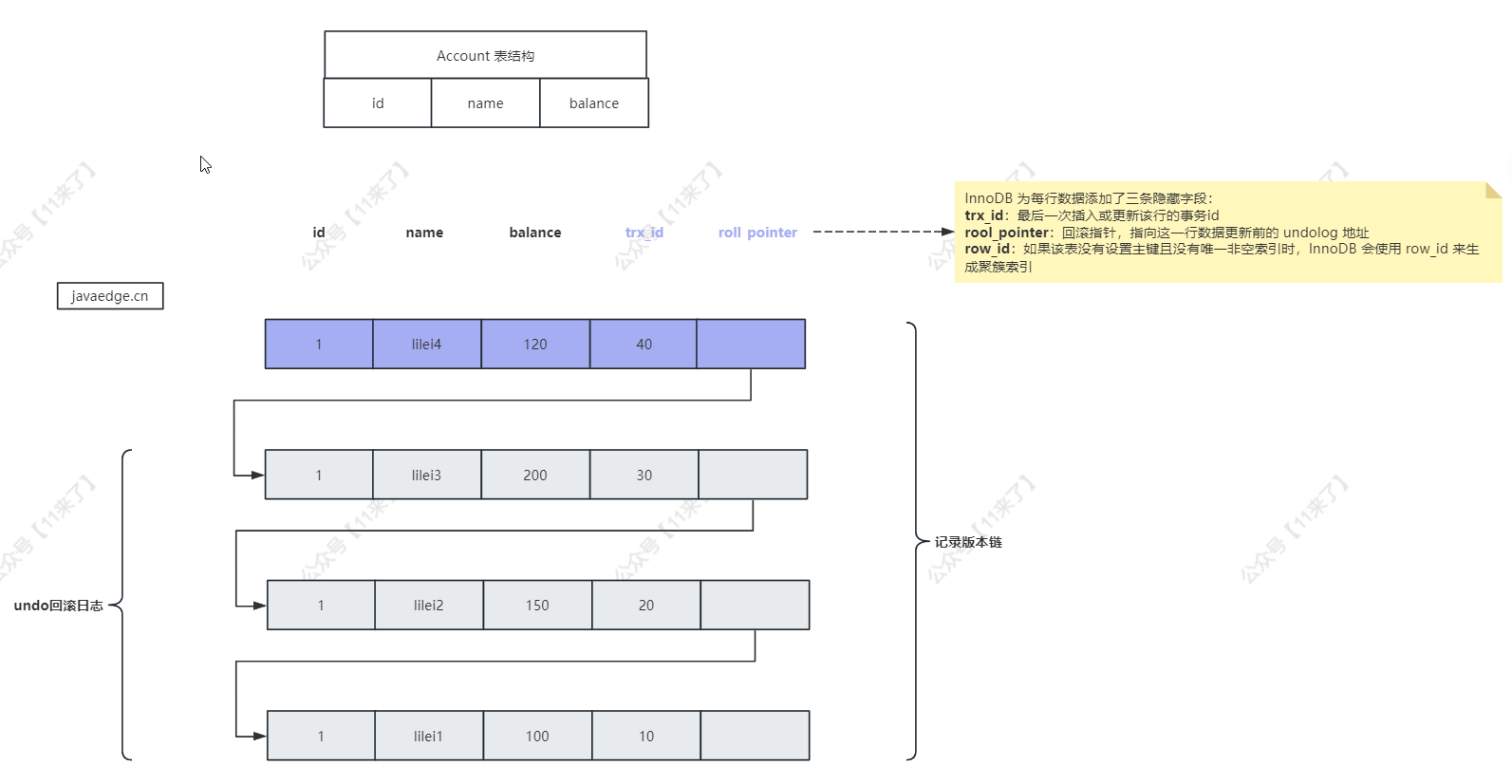
在可重复读隔离级别下,每个事务在开始时会创建一个 Read View,Read View 包含了在事务开始时活跃的所有事务ID(即那些尚未提交的事务ID),这个 Read View 在整个事务的生命周期内保持不变,Read View 主要包含以下几个参数:
- m_ids:表示生成 ReadView 时,当前系统中活跃(未提交)的事务 id 数组
- min_trx_id:表示生成 ReadView 时,当前系统中活跃的事务中最小的事务 id,也就是 m_ids 中的最小值
- max_trx_id:表示生成 ReadView 时,已经创建的最大事务 id
(事务创建时,事务 id 是自增的) - creator_trx_id:表示生成 ReadView 的事务的事务 id
那么在事务里的 sql 查询会根据 ReadView 去数据的版本链中判断哪些数据是可见的:
- 如果 row 的 trx_id < min_trx_id,表示这一行数据的事务 id 比 ReadView 中活跃事务的最小 id 还要小,表示这行数据是已提交事务生成的,因此该行数据可见
- 如果 row 的 trx_id > max_id,表示这一行数据是由将来启动的事务生成的,不可见(如果 row 的 trx_id 就是当前事务自己的 id,则可见)
- 如果 row 的 min_id <= trx_id <= max_id,则有两种情况:
- 如果 trx_id 在 ReadView 的活跃事务 id 数组(m_ids)中,则表明该事务还未提交,则该行数据不可见
- 如果不在,则表明该事务已经提交,可见
注意:
- 执行 start transaction 之后,并不会立即生成事务 id,而是在该事务中,第一次修改 InnoDB 时才会为该事务生成事务 id
- MVCC 机制就是通过 ReadView 和 undo 日志进行对比,拿到当前事务可见的数据
10、讲讲 ThreadLocal 的原理以及如果对 key 的弱引用被垃圾回收是否会造成内存泄露?
ThreadLocal 用于存储线程本地的变量,如果创建了一个 ThreadLocal 变量,在多线程访问这个变量的时候,每个线程都会在自己线程的本地内存中创建一份变量的副本,从而起到线程隔离的作用
Thread、ThreadLocal、ThreadLocalMap 之间的关系:
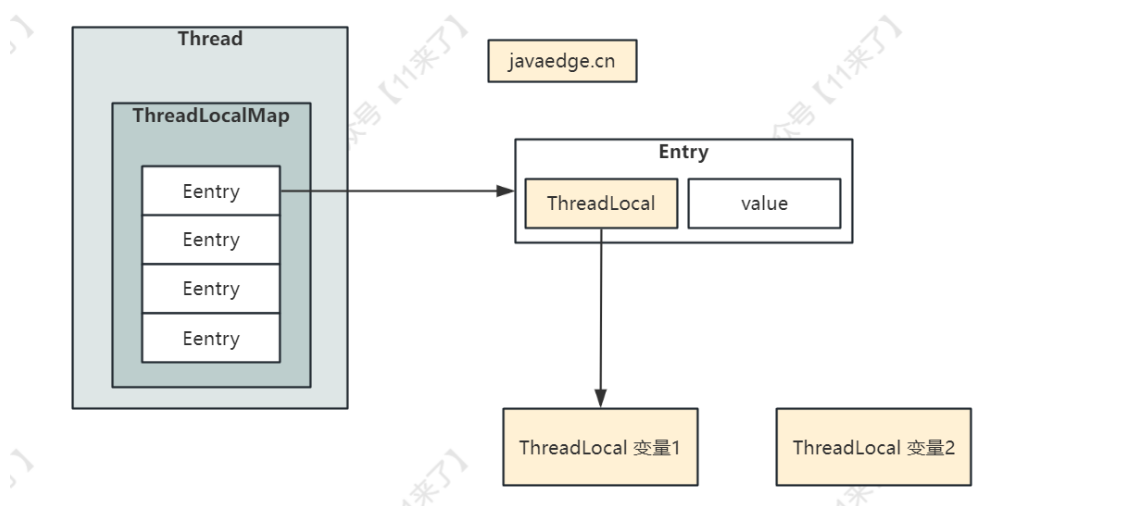
每一个Thread对象均含有一个ThreadLocalMap类型的成员变量threadLocals,它存储本线程所有的ThreadLocal对象及其对应的值
ThreadLocalMap由一个个的Entry<key,value>对象构成,Entry继承自weakReference<ThreadLocal<?>>,一个Entry由ThreadLocal对象和Object构成
- Entry 的 key 是ThreadLocal对象,并且是一个弱引用。当指向key的强引用消失后,该key就会被垃圾收集器回收
- Entry 的 value 是对应的变量值,Object 对象
当执行set方法时,ThreadLocal首先会获取当前线程 Thread 对象,然后获取当前线程的ThreadLocalMap对象,再以当前ThreadLocal对象为key,获取对应的 value。
由于每一条线程均含有各自私有的 ThreadLocalMap 对象,这些容器相互独立互不影响,因此不会存在线程安全性问题,从而也就无需使用同步机制来保证多条线程访问容器的互斥性
如果对 key 的弱引用被垃圾回收了之后可能会造成内存泄漏!
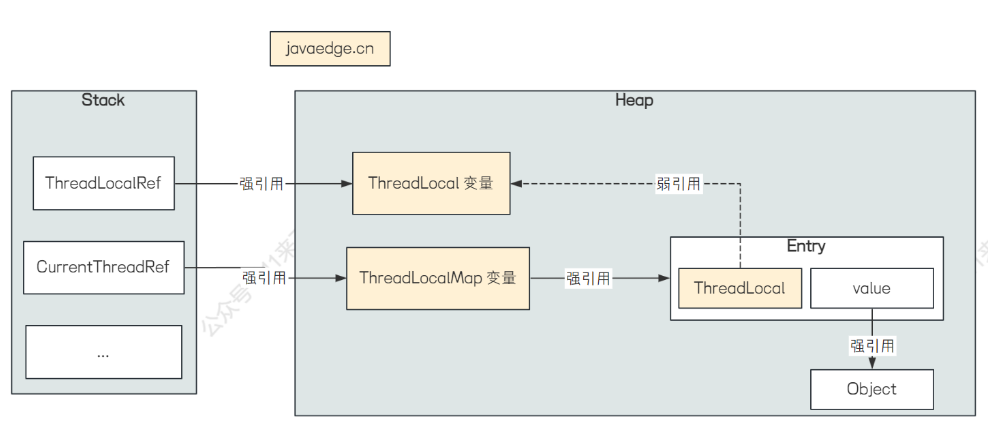
这里假设将 ThreadLocal 定义为方法中的局部变量,那么当线程进入该方法的时候,就会将 ThreadLocal 的引用给加载到线程的栈 Stack 中
如上图所示,在线程栈 Stack 中,有两个变量,ThreadLocalRef 和 CurrentThreadRef,分别指向了声明的局部变量 ThreadLocal ,以及当前执行的线程
而 ThreadLocalMap 中的 key 是弱引用,当线程执行完该方法之后,Stack 线程栈中的 ThreadLocalRef 变量就会被弹出栈,因此 ThreadLocal 变量的强引用消失了,那么 ThreadLocal 变量只有 Entry 中的 key 对他引用,并且还是弱引用,因此这个 ThreadLocal 变量会被回收掉,导致 Entry 中的 key 为 null,而 value 还指向了对 Object 的强引用,因此 value 还一直存在 ThreadLocalMap 变量中,由于 ThreadLocal 被回收了,无法通过 key 去访问到这个 value,导致这个 value 一直无法被回收,ThreadLocalMap 变量的生命周期是和当前线程的生命周期一样长的,只有在当前线程运行结束之后才会清除掉 value,因此会导致这个 value 一直停留在内存中,导致内存泄漏
当然 JDK 的开发者想到了这个问题,在使用 set get remove 的时候,会对 key 为 null 的 value 进行清理,使得程序的稳定性提升。
当然,我们要保持良好的编程习惯,在线程对于 ThreadLocal 变量使用的代码块中,在代码块的末尾调用 remove 将 value 的空间释放,防止内存泄露。
因此 ThreadLocal 正确的使用方法为:
- 每次使用完 ThreadLocal 都调用它的 remove() 方法清除数据
- 将 ThreadLocal 变量定义成 private static final,这样就一直存在 ThreadLocal 的强引用,也能保证任何时候都能通过 ThreadLocal 的弱引用访问到 Entry 的 value 值,进而清除掉