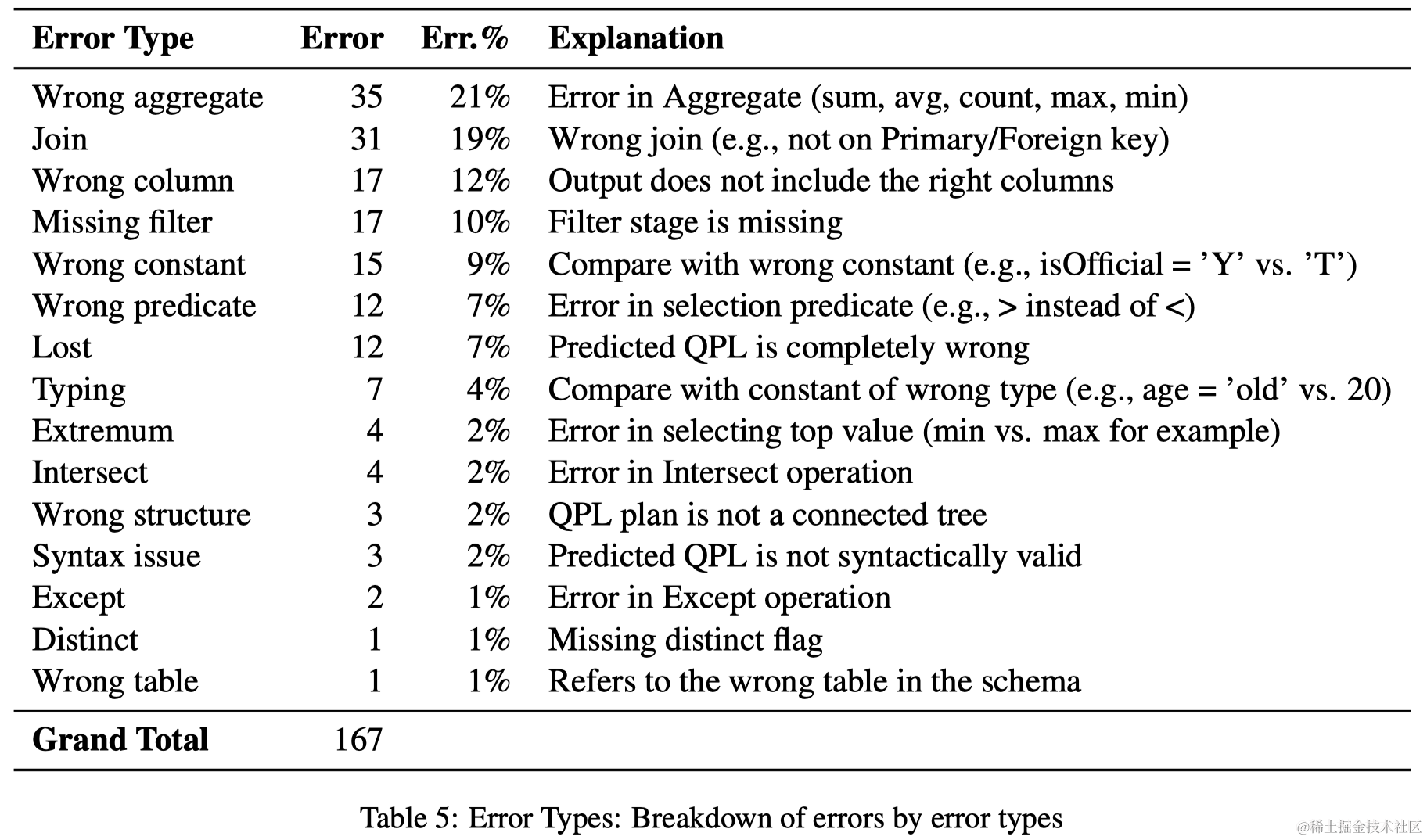
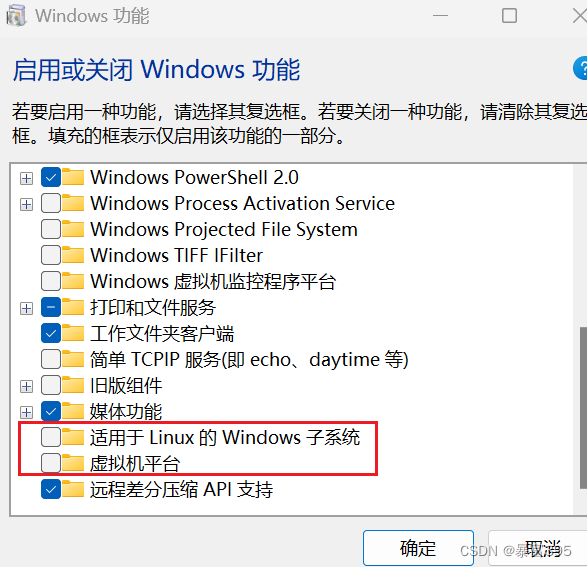
1.异常处理,使代码更加健壮

静态cookie可视绕过登录的限制

 快代理是一个代理平台
快代理是一个代理平台

# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=0&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=20&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=40&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=60&limit=20
# page 1 2 3 4
# start 0 20 40 60
# start (page-1)*20
#下载豆瓣电影前10页的数据
#(1) 请求对象的定制
#(2) 获取响应数据
#(3) 下载数据
import urllib.parse
import urllib.request
def create_request(page):
base_url='https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
data={
'start':(page-1)*20,
'limit':20
}
data=urllib.parse.urlencode(data)
url=base_url+data
headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request = urllib.request.Request(url=url,headers=headers)
return request
def get_content(request):
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
return content
def down_load(page,content):
with open('douban_'+str(page)+'.json','w',encoding='utf-8') as fp:
fp.write(content)
if __name__ == '__main__':
start_page=int(input('请输入起始的页码:'))
end_page=int(input('请输入结束的页码:'))
for page in range(start_page,end_page+1):
request=create_request(page)
content=get_content(request)
down_load(page,content)
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=0&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=20&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=40&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=60&limit=20
# page 1 2 3 4
# start 0 20 40 60
# start (page-1)*20
#下载豆瓣电影前10页的数据
#(1) 请求对象的定制
#(2) 获取响应数据
#(3) 下载数据
import urllib.parse
import urllib.request
def create_request(page):
base_url='https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
data={
'start':(page-1)*20,
'limit':20
}
data=urllib.parse.urlencode(data)
url=base_url+data
headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request = urllib.request.Request(url=url,headers=headers)
return request
def get_content(request):
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
return content
def down_load(page,content):
with open('douban_'+str(page)+'.json','w',encoding='utf-8') as fp:
fp.write(content)
if __name__ == '__main__':
start_page=int(input('请输入起始的页码:'))
end_page=int(input('请输入结束的页码:'))
for page in range(start_page,end_page+1):
request=create_request(page)
content=get_content(request)
down_load(page,content)
#2.练习
# 1页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# post
# cname: 北京
# pid:
# pageIndex: 1
# pageSize: 10
# 2页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# post
# cname: 北京
# pid:
# pageIndex: 2
# pageSize: 10
import urllib.request
import urllib.parse
def create_request(page):
base_url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data={
'cname': '北京',
'pid':'',
'pageIndex': page,
'pageSize': '10'
}
data=urllib.parse.urlencode(data).encode('utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request = urllib.request.Request(url=base_url,headers=headers,data=data)
return request
def get_content(request):
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
return content
def down_load(page,content):
with open('kfc_'+str(page)+'.json','w',encoding='utf-8') as fp:
fp.write(content)
if __name__ == '__main__':
start_page=int(input('请输入起始页码:'))
end_page=int(input('请输入结束页码:'))
for page in range(start_page,end_page+1):
request=create_request(page)
content=get_content(request)
down_load(page,content)
#3.练习
import urllib.request
import urllib.error
url = 'http://www.doudan1111.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
try:
request=urllib.request.Request(url=url,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
print(content)
except urllib.error.HTTPError:
print('系统正在升级')
except urllib.error.URLError:
print('我都说了 系统正在升级...')
#4.练习
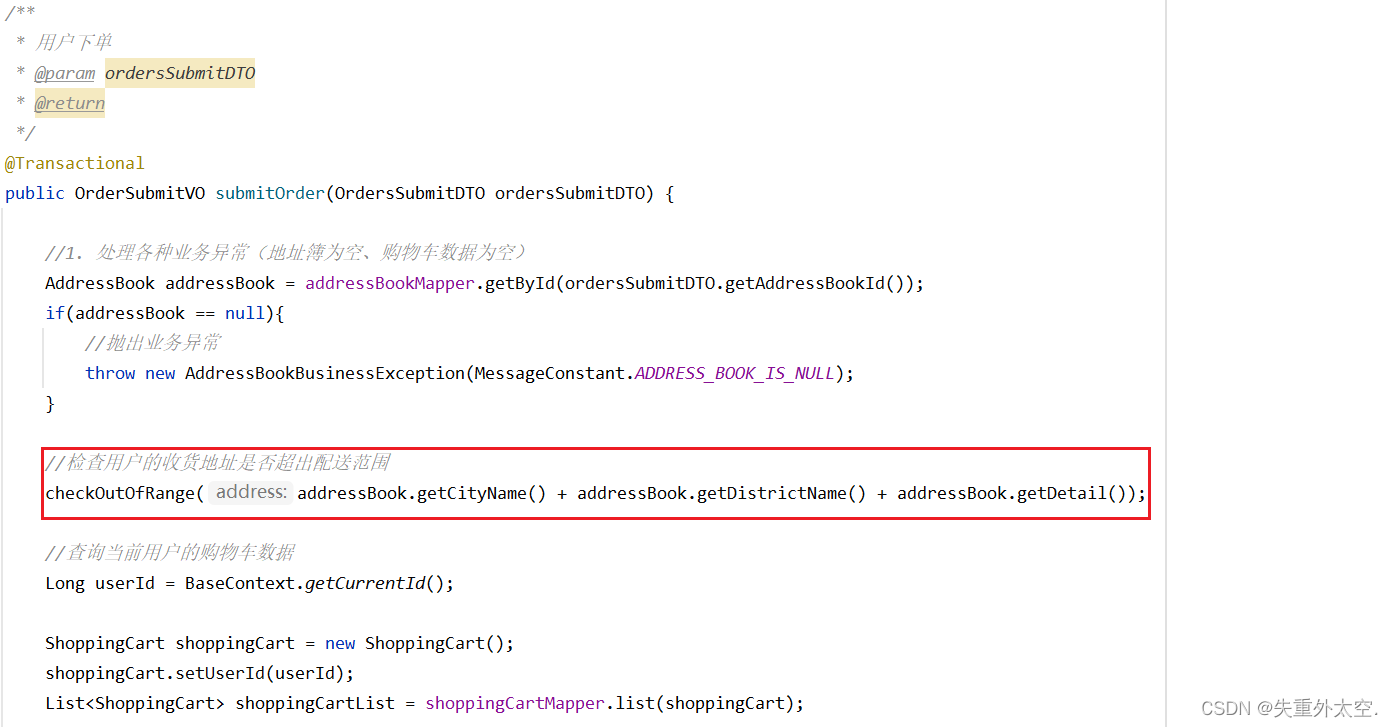
# 适用的场景:数据采集的时候 需要绕过登陆 然后进入到某个页面
# 个人信息页面是utf-8 但是还报错了编码错误 因为并没有进入到个人信息页面 而是跳转到了登陆页面
# 那么登陆页面不是utf-8 所以报错
# 什么情况下访问不成功?
# 因为请求头的信息不够 所以访问不成功
import urllib.request
url='https://weibo.cn/6451491586/info'
headers = {
# ':authority': 'weibo.cn',
# ':method': 'GET',
# ':path': '/6451491586/info',
# ':scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
# 'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
# cookie中携带着你的登陆信息 如果有登陆之后的cookie 那么我们就可以携带着cookie进入到任何页面
'cookie': '_T_WM=24c44910ba98d188fced94ba0da5960e; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFxxfgNNUmXi4YiaYZKr_J_5NHD95QcSh-pSh.pSKncWs4DqcjiqgSXIgvVPcpD; SUB=_2A25MKKG_DeRhGeBK7lMV-S_JwzqIHXVv0s_3rDV6PUJbktCOLXL2kW1NR6e0UHkCGcyvxTYyKB2OV9aloJJ7mUNz; SSOLoginState=1630327279',
# referer 判断当前路径是不是由上一个路径进来的 一般情况下 是做图片防盗链
'referer': 'https://weibo.cn/',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
#请求对象定制
request=urllib.request.Request(url=url,headers=headers)
#模拟浏览器向服务器发送请求
response=urllib.request.urlopen(request)
#获取相应数据
content=response.read().decode('utf-8')
#将数据保存到本地
with open ('weibo.html','w',encoding='utf-8') as fp:
fp.write(content)
#5.练习
import urllib.request
url='http://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request=urllib.request.Request(url=url,headers=headers)
#获取hanlder对象
handler=urllib.request.HTTPHandler()
#获取opener对象
opener=urllib.request.build_opener(handler)
#调用open方法
response=opener.open(request)
content=response.read().decode('utf-8')
print(content)
#6.练习
import urllib.request
url='http://www.baidu.com/s?wd=ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
#请求对象定制
request=urllib.request.Request(url=url,headers=headers)
#模拟浏览器访问服务器
proxies={
'http':'118.24.219.151:16817'
}
handler=urllib.request.ProxyHandler(proxies=proxies)
opener=urllib.request.build_opener(handler)
response=opener.open(request)
#获取响应信息
content=response.read().decode('utf-8')
#保存
with open('daili.html','w',encoding='utf-8') as fp:
fp.write(content)
#7.练习
import urllib.request
import random
proxies_pool=[ {'http':'118.24.219.151:16817'},
{'http':'118.24.219.151:16817'},
]
proxies=random.choice(proxies_pool)
url='http://www.baidu.com/s?wd=ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request=urllib.request.Request(url=url,headers=headers)
handler=urllib.request.ProxyHandler(proxies=proxies)
opene=urllib.request.build_opener(handler)
response=opener.open(request)
content=response.read().decode('utf-8')
with open (daili.html','w',encoding='utf-8')
fp.write(content)
#8.练习
xpath要用到
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>Title</title>
</head>
<body>
<ul>
<li id="l1" class="c1">北京</li>
<li id="l2">上海</li>
<li id="c3">深圳</li>
<li id="c4">武汉</li>
</ul>
<!-- <ul>-->
<!-- <li>大连</li>-->
<!-- <li>锦州</li>-->
<!-- <li>沈阳</li>-->
<!-- </ul>-->
</body>
</html>
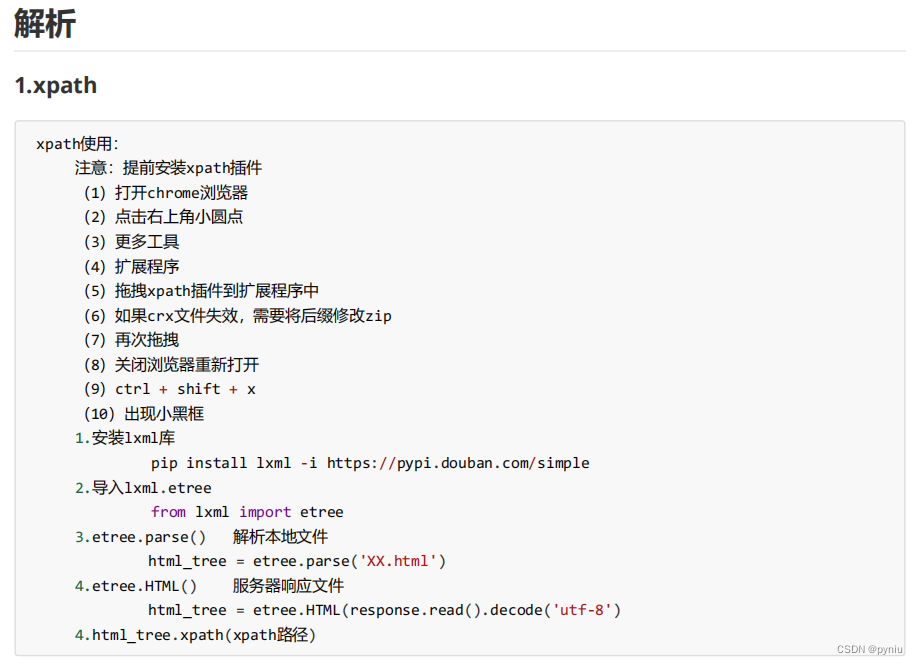
from lxml import etree
# xpath解析
# (1)本地文件 etree.parse
# (2)服务器响应的数据 response.read().decode('utf-8') ** etree.HTML()
#tree.xpath('xpath路径')
#查找下面的li
#li_list=tree.xpath('//body/ul/li')
#查找id为l1的li标签 注意引号的问题
#li_list=tree.xpath('//ul/li[@id="l1"]/text()')
#查找id为l1标签的class的属性值
#li=tree.xpath('//ul/li[@id="l1"]/@class')
#查找id包含1的li标签
#li_list=tree.xpath('//ul/li[contains(@id,"l")]/text()')
# 查询id的值以l开头的li标签
# li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')
#查询id为l1和class为c1的
# li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')
li_list=tree.xpath('//ul/li[@id="l1"]/text()|//ul/li[@id="l2"]/text()')
print(li_list)
print(len(li_list))