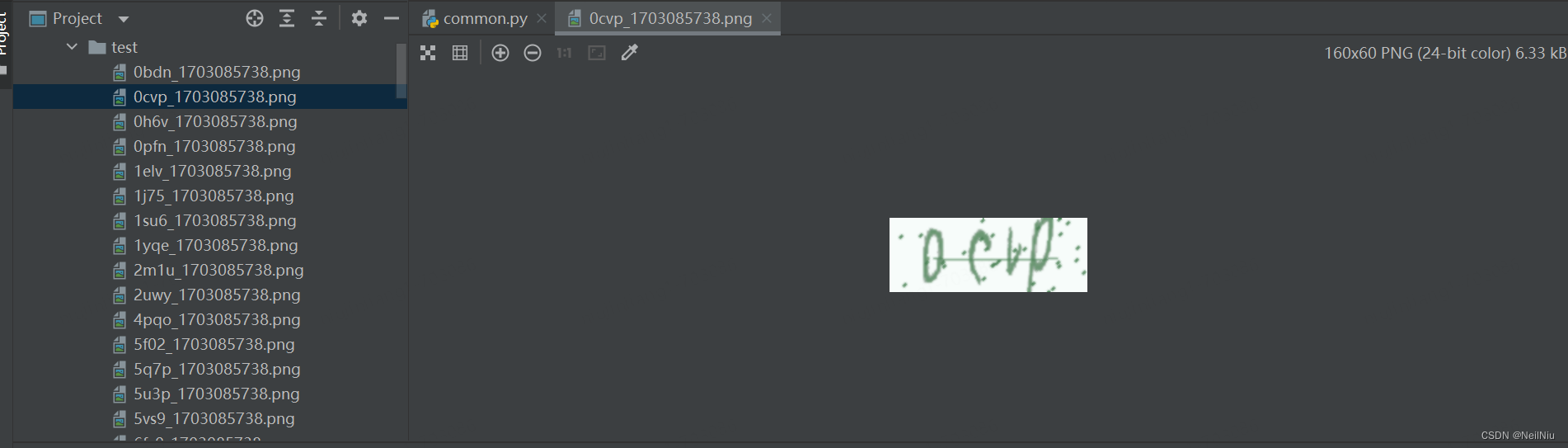
## 一、生成测试集数据
pip install captcha
common.py
import random
import time
captcha_array = list("0123456789abcdefghijklmnopqrstuvwxyz")
captcha_size = 4
from captcha.image import ImageCaptcha
if __name__ == '__main__':
for i in range(10):
image = ImageCaptcha()
image_text = "".join(random.sample(captcha_array, captcha_size))
image_path = "./datasets/train/{}_{}.png".format(image_text, int(time.time()))
image.write(image_text, image_path)
生成验证码
二、one-hot编码将类别变量转换为机器学习算法易于利用的一种形式的过程。
one_hot.py
import common
import torch
import torch.nn.functional as F
def text2vec(text):
# 将文本转换为变量
vectors = torch.zeros((common.captcha_size, common.captcha_array.__len__()))
# vectors[0,0] = 1
# vectors[1,3] = 1
# vectors[2,4] = 1
# vectors[3, 1] = 1
for i in range(len(text)):
vectors[i, common.captcha_array.index(text[i])] = 1
return vectors
def vectotext(vec):
vec=torch.argmax(vec, dim=1)
text_label=""
for v in vec:
text_label+=common.captcha_array[v]
return text_label
if __name__ == '__main__':
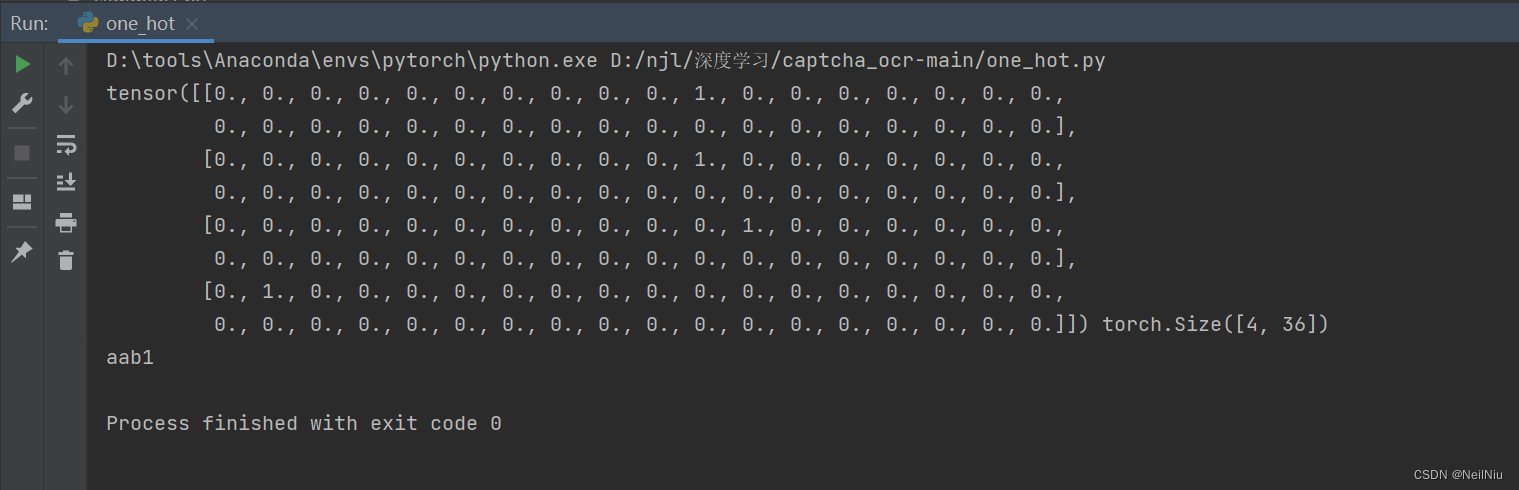
vec=text2vec("aab1")
print(vec, vec.shape)
print(vectotext(vec))
三、 然后继续添加
my_datasets.py
import os
from PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
import one_hot
class mydatasets(Dataset):
def __init__(self,root_dir):
super(mydatasets, self).__init__()
self.list_image_path=[ os.path.join(root_dir,image_name) for image_name in os.listdir(root_dir)]
self.transforms=transforms.Compose([
transforms.Resize((60,160)),
transforms.ToTensor(),
transforms.Grayscale()
])
def __getitem__(self, index):
image_path = self.list_image_path[index]
img_ = Image.open(image_path)
image_name=image_path.split("\\")[-1]
img_tesor=self.transforms(img_)
img_lable=image_name.split("_")[0]
img_lable=one_hot.text2vec(img_lable)
img_lable=img_lable.view(1,-1)[0]
return img_tesor,img_lable
def __len__(self):
return self.list_image_path.__len__()
if __name__ == '__main__':
d=mydatasets("datasets/train")
img,label=d[0]
writer=SummaryWriter("logs")
writer.add_image("img",img,1)
print(img.shape)
writer.close()
dataLoader 加载dataset
就是数据加载器,结合了数据集和取样器,并且可以提供多个线程处理数据集。在训练模型时使用到此函数,用来把训练数据分成多个小组,此函数每次抛出一组数据。直至把所有的数据都抛出,就是做一个数据的初始化。
四、训练
五、CNN卷积神经网络
model.py
import torch
from torch import nn
import common
class mymodel(nn.Module):
def __init__(self):
super(mymodel, self).__init__()
self.layer1 = nn.Sequential(
# 卷积层
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, padding=1),
# 激活层
nn.ReLU(),
# 池化层
nn.MaxPool2d(kernel_size=2) #[6, 64, 30, 80]
)
self.layer2 = nn.Sequential(
# 卷积层
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1),
# 激活层
nn.ReLU(),
# 池化层
nn.MaxPool2d(2) #[6, 128, 15, 40]
)
self.layer3 = nn.Sequential(
# 卷积层
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, padding=1),
# 激活层
nn.ReLU(),
# 池化层
nn.MaxPool2d(2) # [6, 256, 7, 20]
)
self.layer4 = nn.Sequential(
# 卷积层
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, padding=1),
# 激活层
nn.ReLU(),
# 池化层
nn.MaxPool2d(2) # [6, 512, 3, 10]
)
# self.layer5 = nn.Sequential(
# nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
# nn.ReLU(),
# nn.MaxPool2d(2) # [6, 512, 1, 5]
# )
self.layer6 = nn.Sequential(
# 展平
nn.Flatten(), #[6, 2560] [64, 15360]
# 线性层
nn.Linear(in_features=15360, out_features=4096),
# 防止过拟合
nn.Dropout(0.2), # drop 20% of the neuron
# 激活曾
nn.ReLU(),
# 线性层
nn.Linear(in_features=4096, out_features=common.captcha_size*common.captcha_array.__len__())
)
def forward(self,x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
#x = x.view(1,-1)[0]#[983040]
x = self.layer6(x)
# x = x.view(x.size(0), -1)
return x;
if __name__ == '__main__':
data = torch.ones(64, 1, 60, 160)
model = mymodel()
x = model(data)
print(x.shape)

六、训练
train.py
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from my_datasets import mydatasets
from model import mymodel
if __name__ == '__main__':
train_datas = mydatasets("datasets/train")
test_data = mydatasets("datasets/test")
train_dataloader = DataLoader(train_datas, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
# m = mymodel().cuda() 没有GPU
m = mymodel()
# MultiLabelSoftMarginLoss 多标签交叉熵损失函数
# 优化器 Adam 一般要求学习率比较小
# 先将梯度归零 zero_grad
# 反向传播计算 backward
# loss_fn = nn.MultiLabelSoftMarginLoss().cuda() 没有GPU
loss_fn = nn.MultiLabelSoftMarginLoss()
optimizer = torch.optim.Adam(m.parameters(), lr=0.001)
w = SummaryWriter("logs")
total_step = 0
for i in range(10):
# print("外层训练次数{}".format(i))
for i,(imgs, targets) in enumerate(train_dataloader):
# imgs = imgs.cuda() 没有GPU
# targets = targets.cuda() 没有GPU
outputs = m(imgs)
loss = loss_fn(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%10 == 0:
total_step += 1
print("训练{}次,loss:{}".format(total_step*10, loss.item()))
w.add_scalar("loss", loss, total_step)
w.close()
torch.save(m, "model.pth")
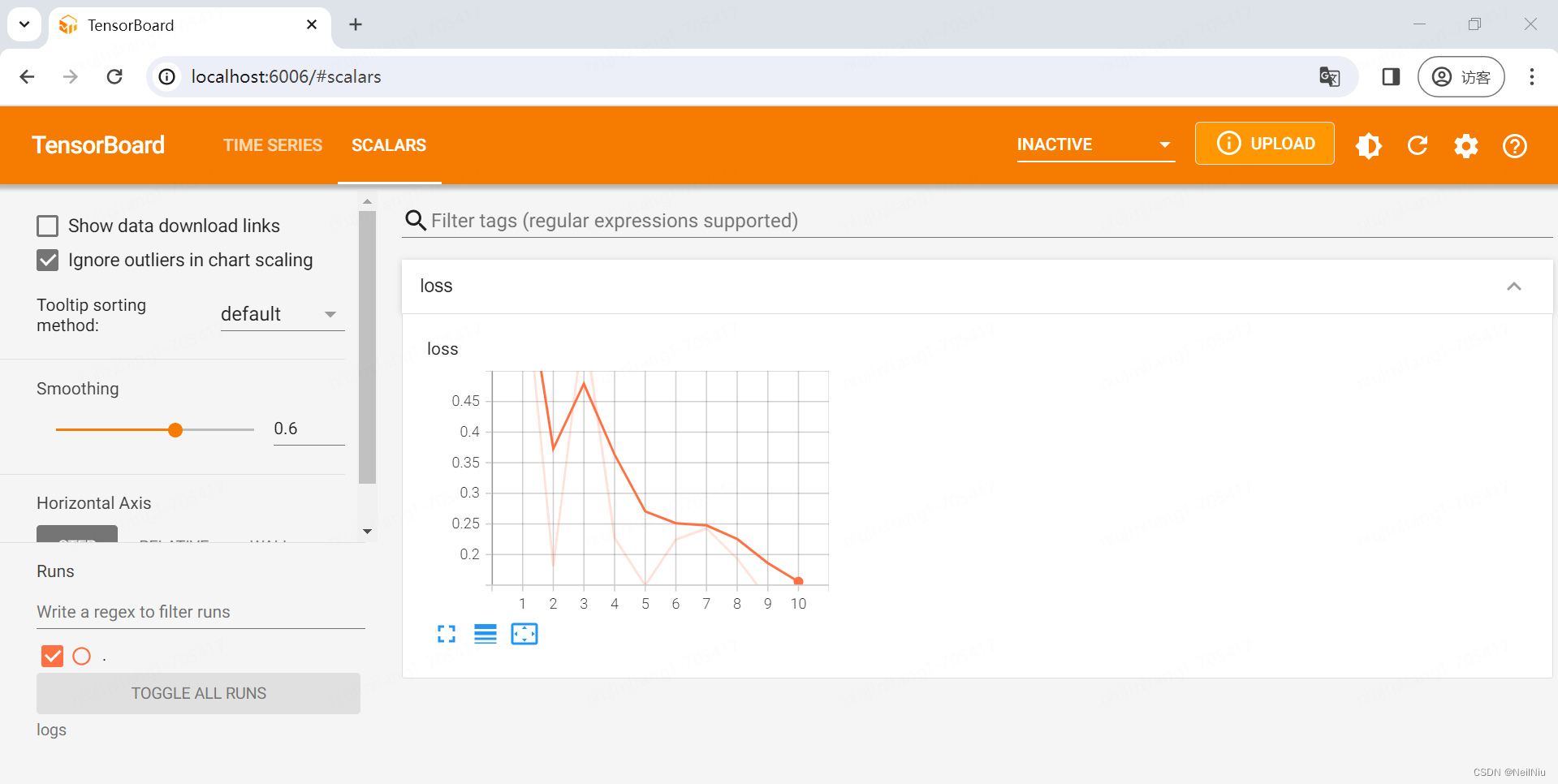
tensorboard --logdir=logs
使用tensorboard 查看损失率,接近零了。
七、图片预测
model.train() 和 model.eval()一般在模型训练和评价的时候会加上这两句,主要是针对由于model在训练时和评价时Batch Normalization 和Dropout方法模式不同,例如model指定t因此,在使用PyTorch进行训练和测试时一定注意要把rain/eval
predict.py
from PIL import Image
from torch.utils.data import DataLoader
import one_hot
import model
import torch
import common
import my_datasets
from torchvision import transforms
def test_pred():
# m = torch.load("model.pth").cuda() 没有GPU
m = torch.load("model.pth")
m.eval()
test_data = my_datasets.mydatasets("datasets/test")
test_dataloader = DataLoader(test_data, batch_size=1, shuffle=False)
test_length = test_data.__len__()
correct = 0
for i, (imgs, lables) in enumerate(test_dataloader):
# imgs = imgs.cuda() 没有GPU
# lables = lables.cuda() 没有GPU
lables = lables.view(-1, common.captcha_array.__len__())
lables_text = one_hot.vectotext(lables)
predict_outputs = m(imgs)
predict_outputs = predict_outputs.view(-1, common.captcha_array.__len__())
predict_labels = one_hot.vectotext(predict_outputs)
if predict_labels == lables_text:
correct += 1
print("预测正确:正确值:{},预测值:{}".format(lables_text, predict_labels))
else:
print("预测失败:正确值:{},预测值:{}".format(lables_text, predict_labels))
# m(imgs)
print("正确率{}".format(correct / test_length * 100))
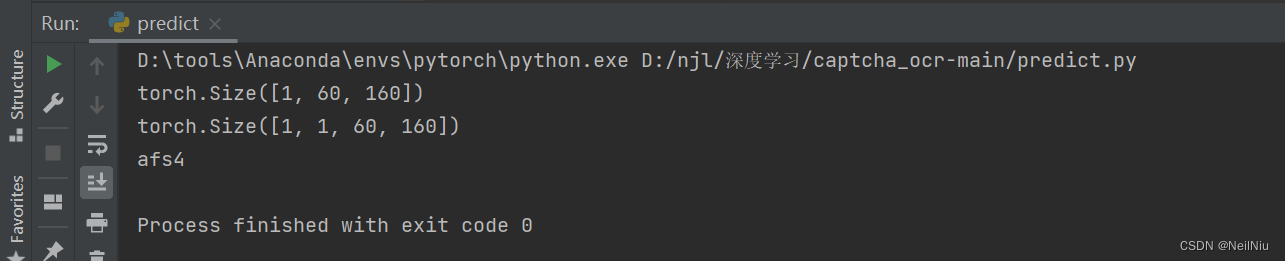
def pred_pic(pic_path):
img = Image.open(pic_path)
tersor_img = transforms.Compose([
transforms.Grayscale(),
transforms.Resize((60, 160)),
transforms.ToTensor()
])
# img = tersor_img(img).cuda() 没有GPU
img = tersor_img(img)
print(img.shape)
img = torch.reshape(img, (-1, 1, 60, 160))
print(img.shape)
# m = torch.load("model.pth").cuda() 没有GPU
m = torch.load("model.pth")
outputs = m(img)
outputs = outputs.view(-1, len(common.captcha_array))
outputs_lable = one_hot.vectotext(outputs)
print(outputs_lable)
if __name__ == '__main__':
# test_pred()
pred_pic("./datasets/test/5ogl_1705418909.png")

预测值是一样的,需要找一些真实的验证码图片